- Руководство по Jupyter Notebook для начинающих
- Настройка Jupyter Notebook
- Основы Jupyter Notebook
- Добавление описания к notebook
- Интерактивная наука о данных
- Подписывайтесь на канал в Дзене
- Введение в Python. Установка Anaconda Navigator и Jupyter Notebook
- Установка Anaconda Navigator
- Работа с Jupyter Notebook
- IPython и Jupyter Notebook — установка и знакомство
- IPython
- Jupyter Notebook
- Jupyter Notebook для начинающих: учебник
- Пример анализа данных в блокноте Jupyter
- Инсталяция
- Создание вашего первого блокнота
- Запуск Jupyter
- Что за файл ipynb?
- Интерфейс Notebook
- Ячейки (Cell)
- Горячие клавиши
- Markdown
- Ядра (Kernels)
- Выбор ядра
- Пример анализа
- Названия для ноутбуков
- Настройка
- Сохранение и контрольная точка
- Изучение нашего набора данных
- Графики с matplotlib
- Делимся своими ноутбуками
- Прежде чем поделиться
- Экспорт ваших ноутбуков
- GitHub
- Nbviewer
- Заключение
Руководство по Jupyter Notebook для начинающих


Jupyter Notebook — это мощный инструмент для разработки и представления проектов Data Science в интерактивном виде. Он объединяет код и вывод все в виде одного документа, содержащего текст, математические уравнения и визуализации.
Такой пошаговый подход обеспечивает быстрый, последовательный процесс разработки, поскольку вывод для каждого блока показывается сразу же. Именно поэтому инструмент стал настолько популярным в среде Data Science за последнее время. Большая часть Kaggle Kernels (работы участников конкурсов на платформе Kaggle) сегодня созданы с помощью Jupyter Notebook.
Этот материал предназначен для новичков, которые только знакомятся с Jupyter Notebook, и охватывает все этапы работы с ним: установку, азы использования и процесс создания интерактивного проекта Data Science.
Настройка Jupyter Notebook
Чтобы начать работать с Jupyter Notebook, библиотеку Jupyter необходимо установить для Python. Проще всего это сделать с помощью pip:
Лучше использовать pip3 , потому что pip2 работает с Python 2, поддержка которого прекратится уже 1 января 2020 года.
Теперь нужно разобраться с тем, как пользоваться библиотекой. С помощью команды cd в командной строке (в Linux и Mac) в первую очередь нужно переместиться в папку, в которой вы планируете работать. Затем запустите Jupyter с помощью следующей команды:
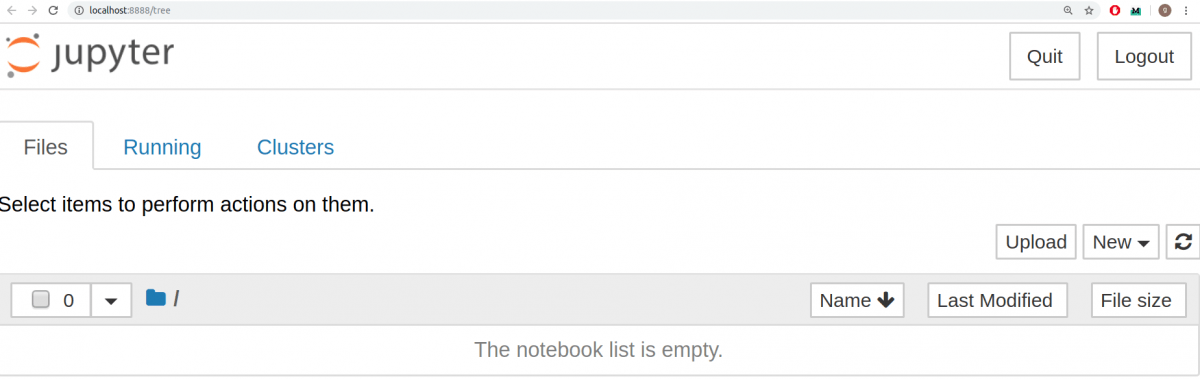
Это запустит сервер Jupyter, а браузер откроет новую вкладку со следующим URL: https://localhost:8888/tree. Она будет выглядеть приблизительно вот так:






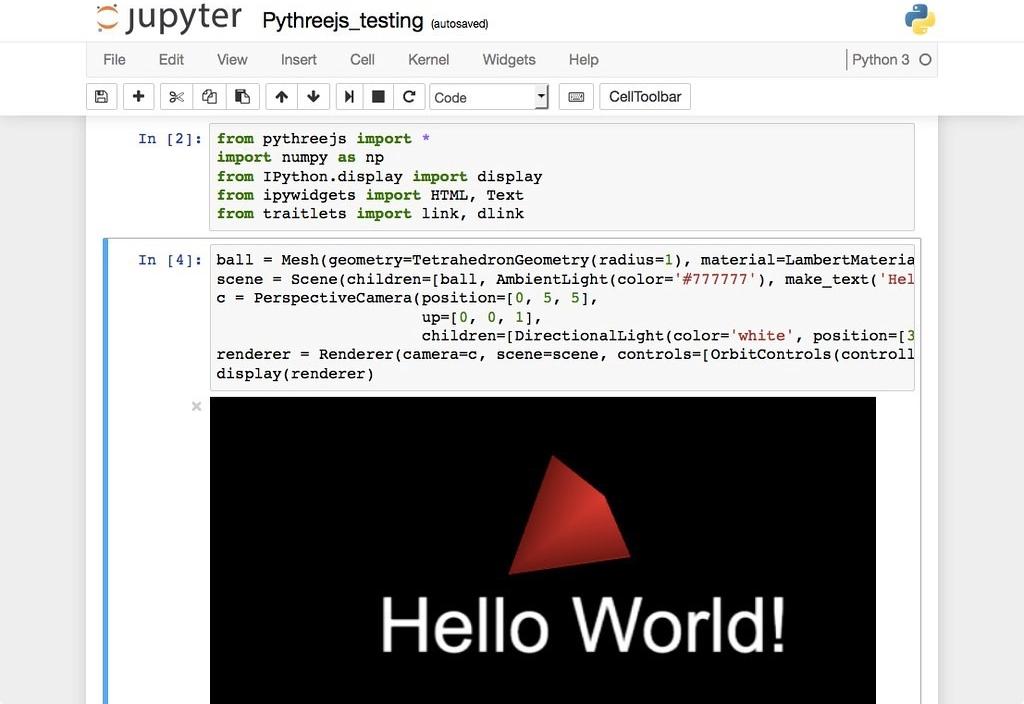
Отлично. Сервер Jupyter работает. Теперь пришло время создать первый notebook и заполнять его кодом.
Основы Jupyter Notebook
Для создания notebook выберите «New» в верхнем меню, а потом «Python 3». Теперь страница в браузере будет выглядеть вот так:
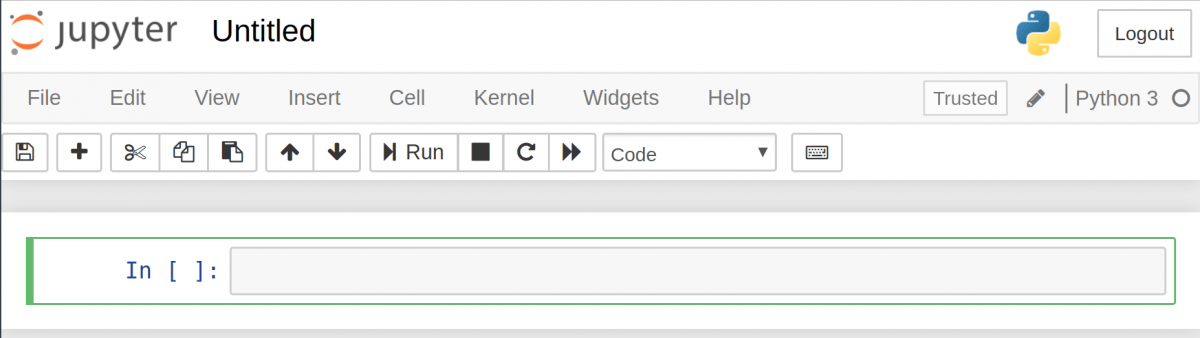
Обратите внимание на то, что в верхней части страницы, рядом с логотипом Jupyter, есть надпись Untitled — это название notebook. Его лучше поменять на что-то более понятное. Просто наведите мышью и кликните по тексту. Теперь можно выбрать новое название. Например, George’s Notebook .
Теперь напишем какой-нибудь код!
Перед первой строкой написано In [] . Это ключевое слово значит, что дальше будет ввод. Попробуйте написать простое выражение вывода. Не забывайте, что нужно пользоваться синтаксисом Python 3. После этого нажмите «Run».
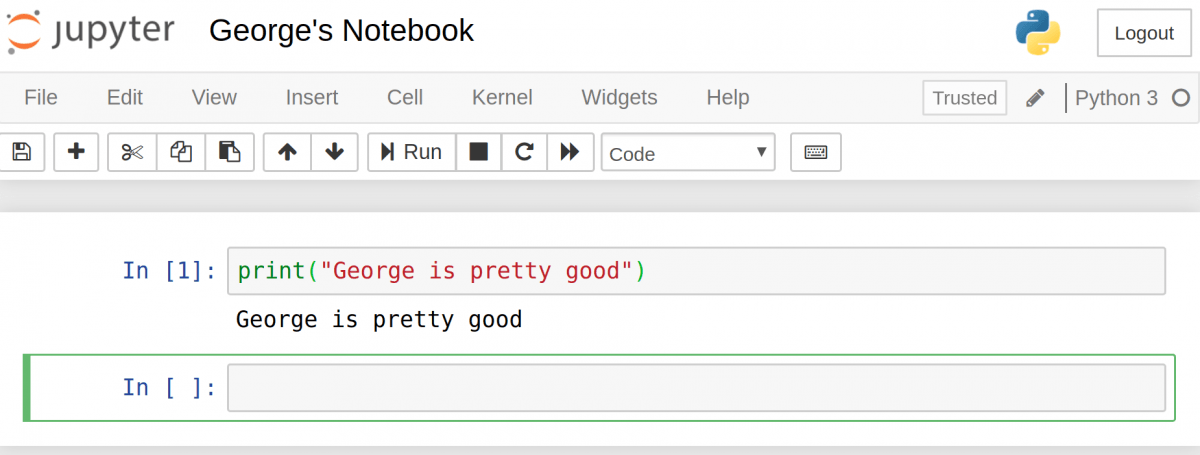
Вывод должен отобразиться прямо в notebook. Это и позволяет заниматься программированием в интерактивном формате, имея возможность отслеживать вывод каждого шага.
Также обратите внимание на то, что In [] изменилась и вместе нее теперь In [1] . Число в скобках означает порядок, в котором эта ячейка будет запущена. В первой цифра 1 , потому что она была первой запущенной ячейкой. Каждую ячейку можно запускать индивидуально и цифры в скобках будут менять соответственно.
Рассмотрим пример. Настроим 2 ячейки, в каждой из которых будет разное выражение print . Сперва запустим вторую, а потом первую. Можно увидеть, как в результате цифры в скобках меняются.
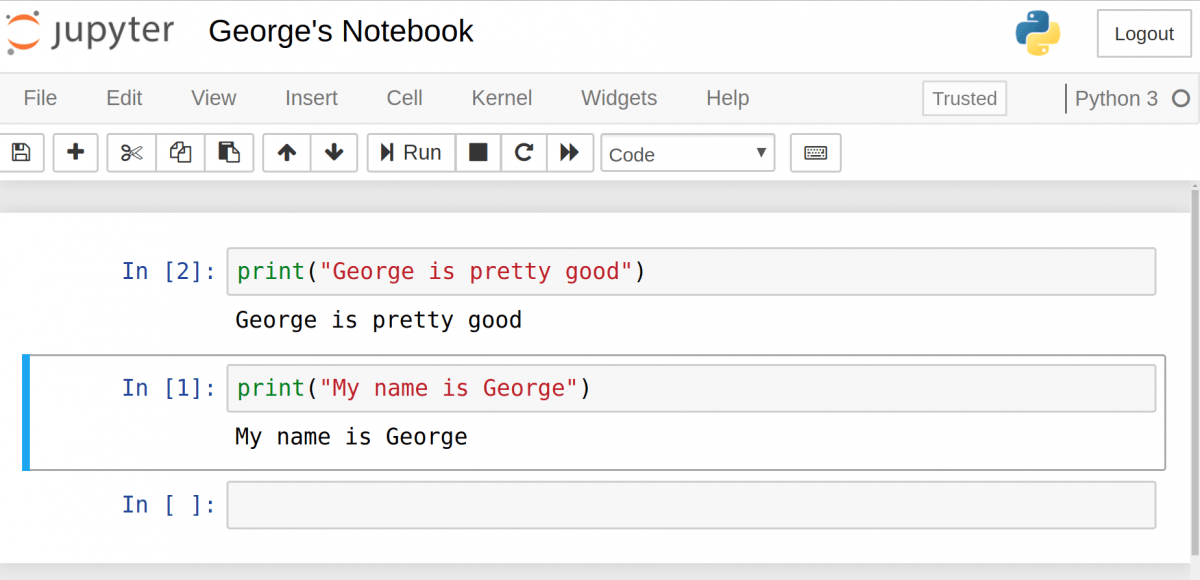







Если есть несколько ячеек, то между ними можно делиться переменными и импортами. Это позволяет проще разбивать весь код на связанные блоки, не создавая переменную каждый раз. Главное убедиться в запуске ячеек в правильном порядке, чтобы переменные не использовались до того, как были созданы.
Добавление описания к notebook
В Jupyter Notebook есть несколько инструментов, используемых для добавления описания. С их помощью можно не только оставлять комментарии, но также добавлять заголовки, списки и форматировать текст. Это делается с помощью Markdown.
Первым делом нужно поменять тип ячейки. Нажмите на выпадающее меню с текстом «Code» и выберите «Markdown». Это поменяет тип ячейки.
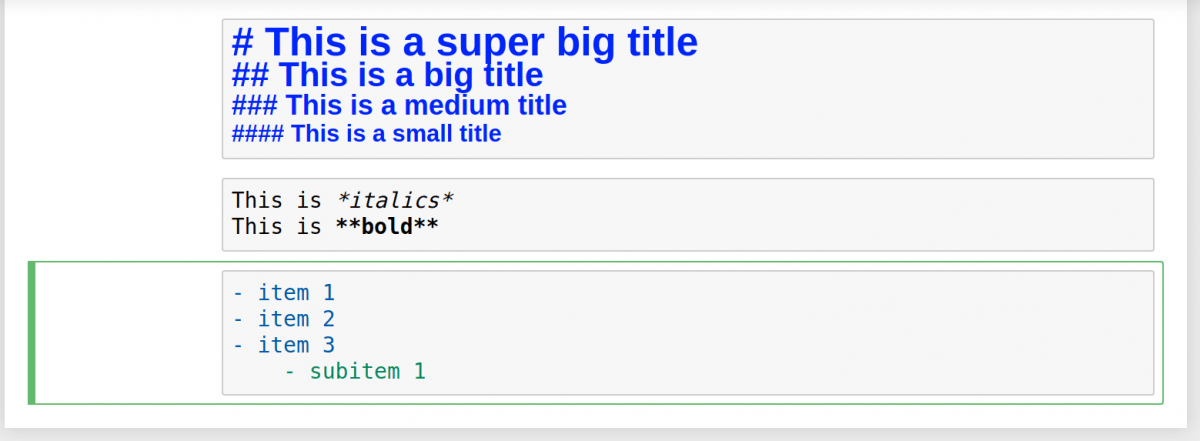
Попробуем несколько вариантов. Заголовки можно создавать с помощью символа # . Один такой символ создаст самый крупный заголовок верхнего уровня. Чем больше # , тем меньше будет текст.
Сделать текст курсивным можно с помощью символов * с двух сторон текста. Если с каждой стороны добавить по два * , то текст станет полужирным. Список создается с помощью тире и пробела для каждого пункта.
Интерактивная наука о данных
Соорудим простой пример проекта Data Science. Этот notebook и код взяты из реального проекта.
Начнем с ячейки Markdown с самым крупным текстом, который делается с помощью одного # . Затем список и описание всех библиотек, которые необходимо импортировать.
Следом идет первая ячейка, в которой происходит импорт библиотек. Это стандартный код для Python Data Science с одним исключение: чтобы прямо видеть визуализации Matplotlib в notebook, нужна следующая строчка: %matplotlib inline .

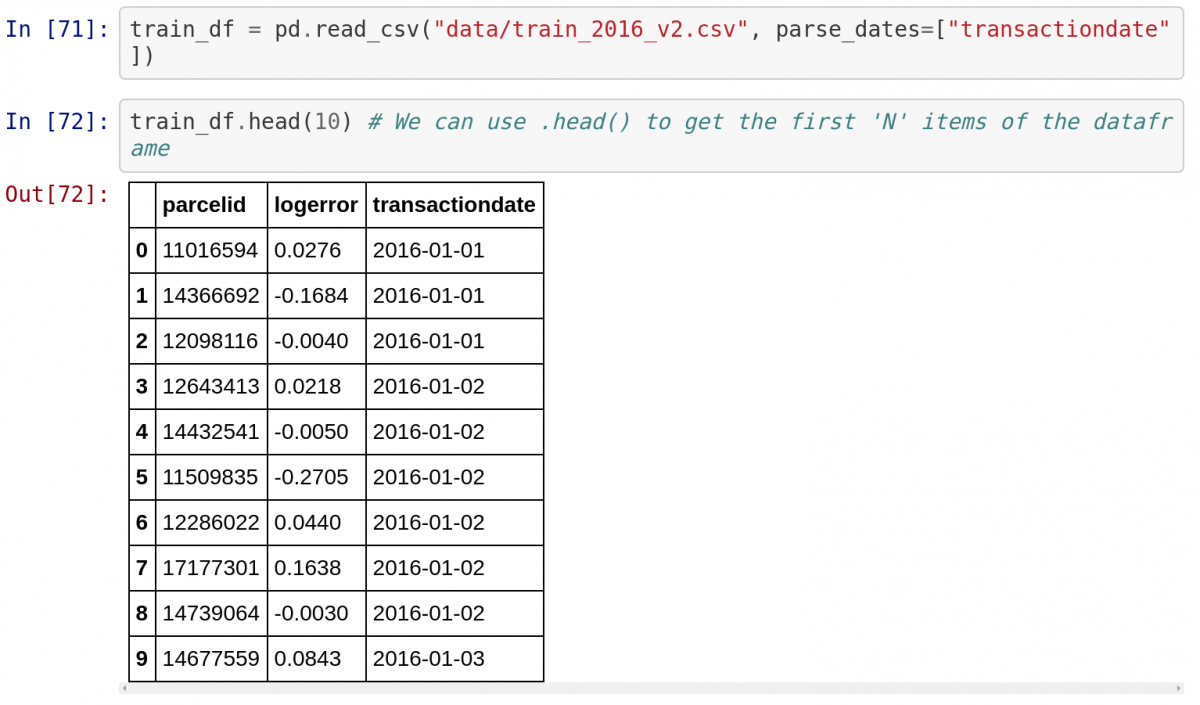
Следом нужно импортировать набор данных из файла CSV и вывести первые 10 пунктов. Обратите внимание, как Jupyter автоматически показывает вывод функции .head() в виде таблицы. Jupyter отлично работает с библиотекой Pandas!
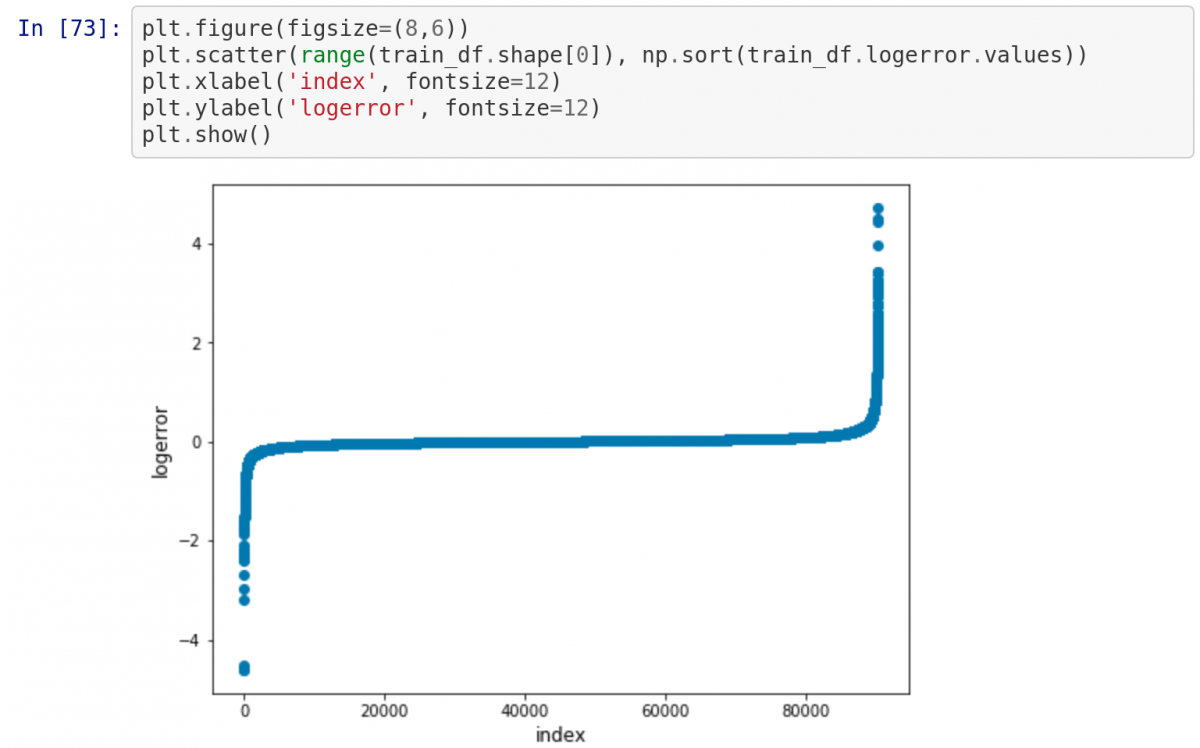
Теперь нарисуем диаграмму прямо в notebook. Поскольку наверху есть строка %matplotlib inline , при написании plt.show() диаграмма будет выводиться в notebook!
Также обратите внимание на то, как переменные из предыдущих ячеек, содержащие данные из CSV-файла, используются в последующих ячейках в том случае, если по отношению к первым была нажата кнопка «Run».
Это простейший способ создания интерактивного проекта Data Science!
На сервере Jupyter есть несколько меню, с помощью которых от проекта можно получить максимум. С их помощью можно взаимодействовать с notebook, читать документацию популярных библиотек Python и экспортировать проект для последующей демонстрации.
Файл (File): отвечает за создание, копирование, переименование и сохранение notebook в файл. Самый важный пункт в этом разделе — выпадающее меню Download , с помощью которого можно скачать notebook в разных форматах, включая pdf, html и slides для презентаций.
Редактировать (Edit): используется, чтобы вырезать, копировать и вставлять код. Здесь же можно поменять порядок ячеек, что понадобится для демонстрации проекта.
Вид (View): здесь можно настроить способ отображения номеров строк и панель инструментов. Самый примечательный пункт — Cell Toolbar , к каждой ячейке можно добавлять теги, заметки и другие приложения. Можно даже выбрать способ форматирования для ячейки, что потребуется для использования notebook в презентации.
Вставить (Insert): для добавления ячеек перед или после выбранной.
Ячейка (Cell): отсюда можно запускать ячейки в определенном порядке или менять их тип.
Помощь (Help): в этом разделе можно получить доступ к важной документации. Здесь же упоминаются горячие клавиши для ускорения процесса работы. Наконец, тут можно найти ссылки на документацию для самых важных библиотек Python: Numpy, Scipy, Matplotlib и Pandas.
Подписывайтесь на канал в Дзене
Полезный контент для начинающих и опытных программистов в канале Лента Python разработчика — Как успевать больше, делать лучше и не потерять мотивацию.
Введение в Python. Установка Anaconda Navigator и Jupyter Notebook
Корреспондентам «Важных историй» навыки программирования постоянно помогают решать рабочие задачи эффективнее и в разы быстрее. Начнем с необходимого программного обеспечения.
Урок вы можете смотреть или читать – текст лекции сразу после видео.
Установка Anaconda Navigator
Anaconda — это бесплатный (для индивидуальных пользователей) и простой в использовании менеджер инструментов для программирования на разных языках, в том числе на Python. Anaconda Navigator — его графический интерфейс на компьютере, с помощью которого вы запускайте нужные для работы инструменты. Нам пока будет нужен только один из них — Jupyter Notebook.
На официальный сайте в продуктах выбираем Individual Edition и внизу страницы скачиваем подходящий для вашей операционной системы установщик. Открываем скачанный файл и проходим этапы установки. Она займет около 10 минут.
Теперь у вас в списке программ на компьютере появился Anaconda Navigator. Открываем его и видим разные инструменты для работы с данными и их визуализации. Нажимаем на Jupyter Notebook. Он открывается в браузере (который у вас по умолчанию), а не как обычные программы на компьютере.
Работа с Jupyter Notebook
Jupyter Notebook — это, по сути, записная книжка для программирования. Внутри нее будут ваши тетрадки с кодом в формате ipynb (IPython Notebook). Давайте создадим первую. Нажимаем в правом верхнем углу New — Python 3. Назовем тетрадку, например, урок 1. Сохранится затем она автоматически.
Внутри тетрадки есть первая пустая ячейка. В таких ячейках мы будет писать строчки кода и запускать их для получения результата. Чтобы научиться разговаривать на языке Python, мы должны для начала понять, какие типы данных у него есть и как с ними взаимодействовать. Начнем с самых простых.
IPython и Jupyter Notebook — установка и знакомство
IPython
Эту среду можно назвать продвинутым интерпретатором Python. Если Python — механизм решения задач, то IPython — интерактивная панель управления.
Оболочка IPython является интерактивным интерфейсом для Python и имеет множество синтаксических дополнений к нему.
Есть два варианта использования IPython:
1 . Командная строка IPython
2 . Блокнот IPython
Для установки командной строки IPython требуется выполнить команду менеджера пакетов pip:
После мы просто вводим в командной строке IPython и можем работать с новым интерпретатором:
Jupyter Notebook
Блокнот Jupyter — это браузерный графический интерфейс для IPython.
Для установки, нужно скачать и установить пакет Anaconda с официального сайта .
После установки, находим в пуске нужную вкладку:
и запускаем Jupyter Notebook:
Мы видим файловую систему в которой можно выбрать и открыть нужный файл, а также создать новый.
Создадим новый файл, нажав на кнопку New и выбрав Python 3:
Теперь перед нами открыта интерактивная среда. Разберём некоторые особенности:
In и Out — являются переменными, автоматически отражающие историю.
In — логично, это то место куда мы пишем команды. Объект In представляет собой список отслеживающий очередность команд.
Out — словарь связывающий ввод с выводом.
Не все операции генерируют вывод, таким образом не каждый In породит Out после себя. Например оператор import возвращает None , что никак не влияет на объект Out .
Чтобы запустить код, нужно нажать на кнопку Run и тогда, если текущая строка In имеет вывод, то он будет отражен в строке Out
Напишем несколько строк кода, чтобы показать удобство использования объектов In и Out:
Здесь просто импортировали библиотеку и посчитали синус и косинус числа 2. Ничего необычного.
Как упоминалось ранее, In — список, что показывает данный вывод.
In[0] является заглушкой и содержит пустую строку. Это сделано для того, чтобы In[1] ссылался на первую команду. Ведь как мы помним, индексы списков начинаются с нуля .
Можно вывести и весь словарь Out , в котором ключами являются номера строк, а значения самим выводом.
В вычислениях можно использовать и конкретные значения предыдущих Out просто указывая Out[номер строки] . Ровно так же, как мы обратились бы к значению словаря Out по ключу.
Для того, чтобы перемещаться по истории команд, можно использовать стрелки вверх-вниз в панели управления:
С помощью нажатия на Tab , можно просматривать доступные команды модулей:
Получение предыдущего вывода можно осуществить с помощью нижнего подчеркивания:
Также можно использовать двойные и более подчёркивания для доступа к предыдущим командам:
Но конечно намного удобнее оперировать номерами строк:
Думаю, для начала достаточно, синтаксические фишки рассмотрю в следующие разы.
Jupyter Notebook для начинающих: учебник
Jupyter Notebook — невероятно мощный инструмент для интерактивной разработки и представления проектов в области наук о данных. В этой статье вы узнаете, как настроить Jupyter Notebooks на локальном компьютере и как начать использовать его в ваших проектах.
Начнем с определения: что такое «notebook» (блокнот)? Блокнот объединяет код и его вывод в единый документ, который объединяет визуализацию, повествовательный текст, математические уравнения и другие мультимедиа. Этот интуитивно понятный рабочий процесс способствует итеративной и быстрой разработке, что делает ноутбуки все более популярным выбором для представления в данных и их анализа.
Лучше всего то, что в рамках проекта с открытым исходным кодом Project Jupyter он полностью бесплатен.
Проект Jupyter является преемником более раннего проекта IPython Notebook, который впервые был опубликован в качестве прототипа в 2010 году. Хотя в Jupyter Notebooks можно использовать с многими разными языками программирования, в этой статье основное внимание будет уделено Python, поскольку он является наиболее распространенный вариантом использования.
Чтобы получить максимальную отдачу от этого урока, вы должны быть знакомы с программированием, особенно с Python и pandas. Тем не менее, если у вас есть опыт работы с другим языком, Python в этой статье не будет слишком сложным, а статья все равно будет вам полезной в настройке Jupyter Notebooks локально. Как вы увидите позже в этой статье, Jupyter Notebooks также может выступать в качестве гибкой платформы для работы с pandas и даже с Python.
В этой статье мы:
- Изучим основы установки Jupyter и создания своего первого ноутбука
- Погрузимся глубже и рассмотрим всю важную терминологию
- Расскажем, как легко можно обмениваться блокнотами и публиковать их в Интернете.
Пример анализа данных в блокноте Jupyter
Сначала мы пройдемся по настройке и анализу примера, чтобы ответить на наш вопрос. Итак, допустим, вы аналитик данных, и вам было поручено выяснить, как исторически менялась прибыль крупнейших компаний в США. У нас для этого будет набор данных о компаниях из списка Fortune 500, охватывающих более 50 лет с момента первой публикации списка в 1955 году, собранных из открытого архива Fortune. Для анализа мы создали CSV файл данных, который вы можете скачать отсюда.
Как мы покажем, ноутбуки Jupyter идеально подходят для этого исследования.
И так, давайте продолжим и установим Jupyter.
Инсталяция
Для новичка проще всего начать работу с Jupyter Notebooks, установив дистрибутив Anaconda. Anaconda является наиболее широко используемым дистрибутивом Python для работы с данными и поставляется с предустановленными наиболее популярными библиотеками и инструментами. Некоторые из крупнейших библиотек Python, включенных в Anaconda, включают NumPy, pandas и Matplotlib, хотя вы можете взглянуть на полный список с более чем 1000+ пакетов. Это позволит вам приступить к работе, без хлопот управления бесчисленными установками или беспокойства о зависимостях и проблемах установки, связанных с ОС.
Чтобы установить Анаконду, просто:
- Загрузите последнюю версию Anaconda для Python 3 (игнорируйте Python 2.7).
- Установите Anaconda, следуя инструкциям на странице загрузки и/или в исполняемом файле.
Если вы более продвинутый пользователь с уже установленным Python и предпочитаете управлять своими пакетами вручную, вы можете просто использовать pip для установки Jupyter Notebooks:
Создание вашего первого блокнота
В этом разделе мы научимся запускать и сохранять блокноты, познакомиться с их структурой и рассмотрим их интерфейс. Мы познакомимся с некоторыми основными терминами, которые приведут вас к практическому пониманию того, как самостоятельно использовать Jupyter Notebooks, и подготовимся к следующему разделу, в котором описан пример анализа данных и опробуем на практике все, что мы изучаем здесь.
Запуск Jupyter
В Windows вы можете запустить Jupyter с помощью ярлыка, который Anaconda добавляет в ваше меню «Пуск», которое откроет новую вкладку в веб-браузере по умолчанию, и которая должна выглядеть примерно так, как показано на следующем скриншоте

Это пока не блокнот, но не паникуйте! Это панель инструментов ноутбука, специально разработанная для управления ноутбуками Jupyter. Думайте об этом как о панели запуска.
Имейте в виду, что панель управления предоставит вам доступ только к файлам и подпапкам, содержащимся в каталоге запуска Jupyter; однако каталог запуска может быть изменен. Также можно запустить панель мониторинга в любой системе через командную строку (или терминал в системах Unix), введя команду jupyter notebook; в этом случае текущим рабочим каталогом будет каталог запуска.
Проницательный читатель, возможно, заметил, что URL-адрес панели мониторинга похож на http://localhost:8888/tree. Localhost не является веб-сайтом, но указывает, что контент обслуживается с вашего локального компьютера: с вашего собственного компьютера. Ноутбуки и панель инструментов Jupyter — это веб-приложения, и Jupyter запускает локальный веб сервер Python для обслуживания этих приложений в веб-браузере, что делает его практически независимым от платформы и открывает возможности для более удобного обмена в Интернете.
Интерфейс панели управления в основном не требует пояснений — хотя мы вернемся к нему позже. Так чего же мы ждем? Перейдите в папку, в которой вы хотите создать свой первый блокнот, нажмите кнопку «Создать» в правом верхнем углу и выберите «Python 3» (или выбранную вами версию).

Ваш первый блокнот Jupyter откроется в новой вкладке — каждый блокнот использует свою вкладку, поэтому вы можете открывать несколько блокнотов одновременно. Если вы переключитесь обратно на панель инструментов, вы увидите новый файл Untitled.ipynb и зеленый текст, который говорит о том, что ваш ноутбук работает.
Что за файл ipynb?
Будет полезно понять, что это за файл на самом деле. Каждый файл .ipynb представляет собой текстовый файл, который описывает содержимое вашей записной книжки в формате JSON. Каждая ячейка и ее содержимое, включая вложения изображений, которые были преобразованы в строки текста, перечислены в нем вместе с некоторыми метаданными. Вы можете редактировать их самостоятельно — если знаете, что делаете! — выбрав «Edit> Edit Notebook Metadata» в строке меню в записной книжке.
Вы также можете просмотреть содержимое файлов вашей записной книжки, выбрав «Edit» на панели управления, но ключевое слово здесь — «можете»; нет никакой другой причины, кроме любопытства, делать это, если вы действительно не знаете, что делаете.
Интерфейс Notebook
Теперь, когда перед вами открытый блокнот, надеюсь, его интерфейс не будет выглядеть совершенно чуждым; В конце концов, Jupyter — это просто продвинутый текстовый процессор. Почему бы не осмотреться? Просотрите меню, чтобы почувствовать его, особенно потратьте несколько минут, чтобы прокрутить список команд в палитре команд, который представляет собой небольшую кнопку со значком клавиатуры (или Ctrl + Shift + P).

Вы должны заметить два довольно важных термина, которые, вероятно, являются новыми для вас: cells (ячейки) и kernels (ядра) являются ключом как к пониманию Jupyter, так и к тому, что делает его не просто текстовым процессором. К счастью, эти термины не сложно понять.
- kernel (Ядро) — это «вычислительный движок», который выполняет код, содержащийся в документе ноутбука.
- cell (Ячейка) — это контейнер для текста, который будет отображаться в записной книжке, или код, который будет выполняться ядром записной книжки.
Ячейки (Cell)
Мы вернемся к ядрам чуть позже, но сначала давайте разберемся с ячейками. Ячейки образуют структуру ноутбука. На скриншоте нового блокнота в приведенном выше разделе это поле с зеленым контуром. Есть два основных типа ячеек, которые мы рассмотрим:
- Ячейка кода содержит код, который должен быть выполнен в ядре, и отображает его вывод ниже.
- Ячейка Markdown содержит текст, отформатированный с использованием Markdown, и отображает его вывод на месте при запуске.
Первая ячейка в новой записной книжке всегда является ячейкой кода. Давайте проверим это на классическом примере с Hello World. Введите print (‘Hello World!’) в ячейку и нажмите кнопку запуска на панели инструментов показанная выше или нажмите Ctrl + Enter. Результат должен выглядеть как то так:
Когда вы запустите ячейку, ее вывод будет отображен ниже, а метка слева изменится с In [] на In [1]. Вывод ячейки кода также является частью документа, поэтому вы можете увидеть его в этой статье. Вы всегда можете определить разницу между кодом и ячейками Markdown, потому что ячейки кода имеют эту метку слева, а ячейки Markdown — нет.
Часть «In» метки просто короткая запись слова «Input», а номер метки указывает, когда ячейка была выполнена в ядре — в нашем случае ячейка была выполнена первой. Запустите ячейку снова, и метка изменится на In [2], потому что теперь ячейка была второй, запущенной в ядре. Позже станет понятнее, почему это так полезно, когда мы поближе познакомимся с ядрами.
В строке меню нажмите Insert (Вставить) и выберите Insert Cell Below (Вставить ячейку ниже), чтобы создать новую ячейку кода под первым и попробуйте следующий код, чтобы увидеть, что происходит. Вы замечаете что-то другое?
Эта ячейка не производит никакого вывода, но для ее выполнения требуется три секунды. Обратите внимание, как Jupyter показывает, что ячейка в данный момент работает, изменив метку на In [*].
Как правило, выходные данные ячейки поступают из любых текстовых данных, специально напечатанных во время выполнения ячеек, а также из значения последней строки в ячейке, будь то переменная-одиночка, вызов функции или что-то еще. Например:
Горячие клавиши
Последнее, что вы, возможно, заметили при запуске ваших ячеек, это то, что их рамка стала синей, тогда как она была зеленой, когда вы редактировали ее. Всегда есть одна «активная» ячейка, выделенная рамкой, цвет которой обозначает ее текущий режим, где зеленый означает edit mode (режим редактирования), а синий — command mode (командный режим).
До сих пор мы показали, как запустить ячейку с помощью Ctrl + Enter, но есть еще много других возможностей. Сочетания клавиш являются очень популярным аспектом среды Jupyter, поскольку они обеспечивают быстрый рабочий процесс на основе ячеек. Многие из этих действий вы можете выполнять в активной ячейке, когда она находится в командном режиме.
Ниже вы найдете список некоторых сочетаний клавиш Jupyter. Вам не нужно сразу их запоминать, но список должен дать вам хорошее представление о том, что это возможно.
- Переключение между режимом редактирования и командным режимом с помощью Esc и Enter соответственно.
- В командном режиме:
- Прокрутите свои ячейки вверх и вниз с помощью клавиш «Вверх» и «Вниз».
- Нажмите A или B, чтобы вставить новую ячейку выше или ниже активной ячейки.
- M преобразует активную ячейку в ячейку Markdown.
- Y установит активную ячейку в кодовую ячейку.
- D + D (D дважды) удалит активную ячейку.
- Z отменит удаление ячейки.
- Удерживайте Shift и нажмите Вверх или Вниз, чтобы выбрать несколько ячеек одновременно.
- С выделением нескольких ячеек Shift + M объединит выбранные ячейки.
- Ctrl + Shift + — в режиме редактирования разделит активную ячейку по курсору.
- Вы также можете нажать и Shift + клик на полях слева от ваших ячеек, чтобы выбрать их.
Попробуй это в своей записной книжке. После того, как вы опробуете все команды, создайте новую ячейку Markdown, и мы научимся форматировать текст в наших блокнотах.
Markdown
Markdown — это легкий, простой в освоении язык разметки для форматирования простого текста. Его синтаксис имеет однозначное соответствие с тегами HTML, поэтому некоторые предварительные знания здесь могут быть полезны, но это определенно не является обязательным условием. Давайте рассмотрим основы с кратким примером.
При прикреплении изображений у вас есть три варианта:
- Используйте URL для изображения в Интернете.
- Используйте локальный URL-адрес изображения, которое вы будете хранить рядом с ноутбуком, например, в том же git-репо.
- Добавьте вложение через «Edit> Insert Image»; Это преобразует изображение в строку и сохраняет его в файле .ipynb вашего ноутбука.
- Обратите внимание, что это сделает ваш файл .ipynb намного больше!
У Markdown гораздо больше возможностей, особенно в отношении гиперссылок, а также возможно просто включить простой HTML. Если вы захотите узнать больше, вы можете обратиться к официальному руководству от создателя Markdown, Джона Грубера, на его веб-сайте.
Ядра (Kernels)
За каждым ноутбуком работает ядро. Когда вы запускаете ячейку кода, этот код выполняется в ядре, и любой вывод возвращается обратно в ячейку для отображения. Состояние ядра сохраняется во времени и между ячейками — оно относится к документу в целом, а не к отдельным ячейкам.
Например, если вы импортируете библиотеки или объявляете переменные в одной ячейке, они будут доступны в другой. Таким образом, вы можете думать о документе блокнота как о чем-то сравнимом с файлом сценария, за исключением того, что он является мультимедийным. Давайте попробуем, чтобы почувствовать это. Сначала мы импортируем пакет Python и определим функцию.
Как только мы выполнили ячейку выше, мы можем ссылаться на np и square в любой другой ячейке.
Это будет работать независимо от порядка ячеек в вашем блокноте. Вы можете попробовать сами, давайте снова распечатаем наши переменные.
Здесь нет сюрпризов! Но теперь давайте изменим у.
Как вы думаете, что произойдет, если мы снова запустим ячейку, содержащую наш оператор print? Мы получим на выходе 4 в квадрате 10?
Большую часть времени поток в вашем ноутбуке будет сверху вниз, но часто приходится возвращаться, чтобы внести изменения. В этом случае важен порядок выполнения, указанный слева от каждой ячейки, например, In [6], позволит вам узнать, имеет ли какая-либо из ваших ячеек устаревший вывод. И если вы когда-нибудь захотите сбросить настройки, есть несколько невероятно полезных опций из меню Kernel:
- Restart: перезапускает ядро, таким образом очищая все переменные и т.д., которые были определены.
- Restart & Clear Output: то же, что и выше, но также стирает вывод, отображаемый под ячейками кода.
- Restart & Run All: то же, что и выше, но также будет запускать все ваши ячейки в порядке от первого до последнего.
Если ваше ядро зависло в вычислении, и вы хотите остановить его, вы можете выбрать опцию Interupt.
Выбор ядра
Возможно, вы заметили, что Jupyter дает вам возможность сменить ядро, и на самом деле есть много разных вариантов на выбор. Когда вы создавали новую записную книжку на панели инструментов, выбирая версию Python, вы фактически выбирали, какое ядро использовать.
Существуют не только ядра для разных версий Python, но и более 100 языков, включая Java, C и даже Fortran. Исследователи данных могут быть особенно заинтересованы в ядрах для R и Julia, а также в imatlab и ядре Calysto MATLAB Kernel для Matlab. Ядро SoS обеспечивает многоязычную поддержку в пределах одного ноутбука. Каждое ядро имеет свои собственные инструкции по установке, но, вероятно, потребует от вас выполнения некоторых команд на вашем компьютере.
Пример анализа
Теперь когда мы рассмотрели, что такое Jupyter Notebook, пришло время взглянуть на то, как они используются на практике, что должно дать вам более четкое представление о том, почему они так популярны. Наконец-то пришло время начать работу с тем набором данных Fortune 500, который упоминался ранее. Помните, наша цель — узнать, как исторически менялась прибыль крупнейших компаний США.
Названия для ноутбуков
Прежде чем начать создавать свой проект, вы, вероятно, захотите дать ему осмысленное имя. Возможно, это несколько сбивает с толку: но вы не можете назвать или переименовать свои записные книжки из самого приложения для записной книжки, а для переименования файла .ipynb необходимо использовать панель мониторинга или файловый браузер. Мы вернемся к информационной панели, чтобы переименовать созданный ранее файл, который будет иметь имя файла по умолчанию для записной книжки Untitled.ipynb.
Вы не можете переименовать ноутбук во время его работы, потому что его сначала нужно выключить. Самый простой способ сделать это — выбрать «File> Close and Halt» в меню ноутбука. Однако вы также можете выключить ядро, перейдя в «Kernel> Shutdown» в приложении для ноутбука или выбрав ноутбук на приборной панели и нажав «Shutdown» (см. Изображение ниже).

Затем вы можете выбрать свой блокнот и нажать «Rename» на панели управления.

Обратите внимание, что закрытие вкладки «notebook» в вашем браузере не «закроет» вашу записную книжку так же, как закрытие документа в традиционном приложении. Ядро ноутбука будет продолжать работать в фоновом режиме и должно быть отключено, прежде чем оно действительно «закроется». Это очень удобно, если вы случайно закрыли вкладку или браузер! Если ядро закрыто, вы можете закрыть вкладку, не беспокоясь о том, работает ли оно по-прежнему или нет.
Как только вы назвали свою записную книжку, откройте ее снова, и мы начнем.
Настройка
Обычно начинают с ячейки кода, специально предназначенной для импорта и настройки, поэтому, если вы решите добавить или изменить что-либо, вы можете просто отредактировать и повторно запустить ячейку, не вызывая побочных эффектов.
Здесь мы импортируем pandas для работы с нашими данными, Matplotlib для построения графиков и Seaborn для улучшения внешнего вида наших графиков. Обычно также импортируется NumPy, но в нашем случае, мы используем его через pandas, и нам не нужно это делать явно. Последняя строка не является командой Python, она является нечто, называемое строковой магией, для инструктирования Jupyter захватывать графики Matplotlib и отображать их в выходных данных ячейки; это одна из ряда расширенных функций, которые выходят за рамки данной статьи.
Давайте продолжим и загрузим наши данные.
Целесообразно делать это в отдельной ячейке на случай, если нам понадобится перезагрузить ее в любой момент.
Сохранение и контрольная точка
Теперь, когда мы начали создавать проект, лучше регулярно сохраняться. Нажатие Ctrl + S сохранит вашу записную книжку, вызвав команду «Save and Checkpoint», но что это за checkpoint (контрольная точка)?
Каждый раз, когда вы создаете новую записную книжку, создается файл контрольной точки, а также файл вашей записной книжки; он будет расположен в скрытом подкаталоге вашего места сохранения с именем .ipynb_checkpoints, и также является файлом .ipynb. По умолчанию Jupyter каждые 120 секунд автоматически сохраняет ваш блокнот в этот файл контрольных точек, не изменяя основной файл блокнота. Когда вы сохраняете и сохраняете контрольную точку, файлы записной книжки и контрольной точки обновляются. Следовательно, контрольная точка позволяет вам восстановить несохраненную работу в случае непредвиденной проблемы. Вы можете вернуться к контрольной точке из меню через «File> Revert to Checkpoint».
Изучение нашего набора данных
Наш блокнот благополучно сохранен, и мы загрузили наш набор данных переменную df в наиболее часто используемую структуру данных pandas, которая называется DataFrame и в основном выглядит как таблица. Давай те посмотрим как выглядят наши данные?
| year | rank | company | revenue (in millions) | profit (in millions) | |
|---|---|---|---|---|---|
| 0 | 1955 | 1 | General Motors | 9823.5 | 806 |
| 1 | 1955 | 2 | Exxon Mobil | 5661.4 | 584.8 |
| 2 | 1955 | 3 | U.S. Steel | 3250.4 | 195.4 |
| 3 | 1955 | 4 | General Electric | 2959.1 | 212.6 |
| 4 | 1955 | 5 | Esmark | 2510.8 | 19.1 |
| year | rank | company | revenue (in millions) | profit (in millions) | |
|---|---|---|---|---|---|
| 25495 | 2005 | 496 | Wm. Wrigley Jr. | 3648.6 | 493 |
| 25496 | 2005 | 497 | Peabody Energy | 3631.6 | 175.4 |
| 25497 | 2005 | 498 | Wendy’s International | 3630.4 | 57.8 |
| 25498 | 2005 | 499 | Kindred Healthcare | 3616.6 | 70.6 |
| 25499 | 2005 | 500 | Cincinnati Financial | 3614.0 | 584 |
У нас есть столбцы, которые нам нужны, и каждая строка соответствует одной компании за один год.
Давайте просто переименуем эти столбцы, чтобы мы могли обратиться к ним позже.
Далее нам нужно изучить наш набор данных. Являются ли они завершенными? Распознало ли pandas их, как ожидалось? Отсутствуют ли в них какие-либо значения?
У нас есть 500 строк за каждый год с 1955 по 2005 год включительно.
Давайте проверим, был ли наш набор данных импортирован, как мы ожидали. Простая проверка состоит в том, чтобы увидеть, были ли типы данных (или dtypes) правильно интерпретированы.
Ооо Похоже, что с колонкой profit что-то не так — мы ожидаем, что это будет float64, как колонка revenue. Это указывает на то, что она, вероятно, содержит нецелые значения, так что давайте посмотрим.
| year | rank | company | revenue | profit | |
|---|---|---|---|---|---|
| 228 | 1955 | 229 | Norton | 135.0 | N.A. |
| 290 | 1955 | 291 | Schlitz Brewing | 100.0 | N.A. |
| 294 | 1955 | 295 | Pacific Vegetable Oil | 97.9 | N.A. |
| 296 | 1955 | 297 | Liebmann Breweries | 96.0 | N.A. |
| 352 | 1955 | 353 | Minneapolis-Moline | 77.4 | N.A. |
Как мы и подозревали! Некоторые значения являются строками, которые использовались для указания отсутствующих данных. Есть ли какие-то другие значения, которые закрались?
Получается, что других значений нет. Это облегчает интерпретацию, но что нам делать? Это зависит от того, сколько значений пропущено.
Это небольшая часть нашего набора данных, хотя и не совсем несущественная, поскольку все еще составляет около 1,5%. Если строки, содержащие N.A., примерно одинаково распределены по годам, самым простым решением было бы просто удалить их. Итак, давайте кратко рассмотрим их распределение.

На первый взгляд, мы видим, что самые недопустимые значения за один год составляют менее 25, а поскольку существует 500 точек данных в год, удаление этих значений будет составлять менее 4% данных для худших лет. Действительно, кроме всплеска около 90-х годов, большинство лет имеют менее половины недостающих значений пика. Для наших целей допустим, что это приемлемо, и мы просто удалим эти строки.
Мы должны проверить, что у нас получилось.
Супер! Мы завершили настройку набора данных.
Если бы вы собирались представить свою записную книжку в виде отчета, вы могли бы избавиться от созданных нами исследовательских ячеек, которые включены здесь в качестве демонстрации процесса работы с записными книжками, и объединить соответствующие ячейки (см. Раздел «Дополнительные функции» ниже для подробностей об этом) для создания единой ячейки настройки набора данных. Это будет означать, что если мы когда-нибудь испортим наш набор данных в другом месте, мы сможем просто повторно запустить ячейку настройки, чтобы восстановить ее.
Графики с matplotlib
Далее мы можем перейти к решению данного вопроса, построив график средней прибыли за год. Мы можем также рассчитать доход, поэтому сначала мы определим некоторые переменные и метод, чтобы уменьшить наш код.

Вау, это похоже на экспоненту, но у нее есть огромные провалы. Они должны соответствовать рецессии начала 1990-х и пузырю доткомов. Это довольно интересно увидеть в данных. Но почему прибыль возвращается к еще более высоким уровням после каждой рецессии?
Может быть, доходы могут рассказать нам больше.

Это добавляет другую сторону истории. Доходы отнюдь не так сильно пострадали, это отличная бухгалтерская работа для финансовых отделов.
С небольшой помощью Stack Overflow мы можем наложить эти графики с +/- их стандартными отклонениями.

Это ошеломляет, стандартные отклонения огромны. Некоторые компании из списка Fortune 500 зарабатывают миллиарды, в то время как другие теряют миллиарды, и риск увеличивается вместе с ростом прибыли за последние годы. Возможно, некоторые компании работают лучше, чем другие; Являются ли прибыли первых 10% более или менее волатильными, чем нижние 10%?
Есть много вопросов, которые мы могли бы рассмотреть далее, и легко увидеть, как процесс работы в блокноте соответствует собственному мыслительному процессу, поэтому сейчас пришло время подвести этот пример к концу. Этот блокнот помог нам легко исследовать наш набор данных в одном месте без переключения контекста между приложениями, и наша работа сразу становится доступной и воспроизводимой. Если бы мы хотели создать более краткий отчет для конкретной аудитории, мы могли бы быстро реорганизовать нашу работу, объединив ячейки и удалив промежуточный код.
Примечание: оригинальная версия этой статьи использовала as_matrix () вместо .values в приведенном выше фрагменте кода. На момент написания этой статьи команда .as_matrix () все еще существует, но ее планируется удалить в будущей версии pandas, поэтому мы заменили его на значение .values.
Делимся своими ноутбуками
Когда люди говорят о совместном использовании своих ноутбуков, обычно они рассматривают две парадигмы. Чаще всего люди разделяют конечный результат своей работы, что означает обмен неинтерактивными, предварительно отрендеренными версиями своих ноутбуков; однако также существует возможность совместного использования ноутбуков с такими вспомогательными системами контроля версий, как Git.
Так же, в интернете появляются новые компании, предлагающие возможность запуска интерактивных Jupyter Notebooks в облаке.
Прежде чем поделиться
Общий блокнот будет отображаться точно в том состоянии, в котором он находился при экспорте или сохранении, включая вывод любых ячеек кода. Поэтому, чтобы обеспечить совместимость вашего ноутбука, так сказать, есть несколько шагов, которые вы должны предпринять, прежде чем им делиться:
- Кликните “Cell > All Output > Clear”
- Кликните “Kernel > Restart & Run All”
- Дождитесь окончания выполнения ваших ячеек кода и проверьте, что они отработали так, как ожидалось.
Это гарантирует, что ваши записные книжки не будут содержать промежуточный вывод, не будут иметь устаревшее состояние и будут выполнены в порядке на момент публикации.
Экспорт ваших ноутбуков
Jupyter имеет встроенную поддержку экспорта в HTML и PDF, а также в некоторые другие форматы, которые вы можете найти в меню «File> Download As». Если вы хотите поделиться своими записными книжками с небольшой частной группой, этой функция будет достаточно. Но если совместного доступа к экспортированным файлам будет не достаточно, есть также несколько чрезвычайно популярных методов совместного использования файлов .ipynb в Интернете.
GitHub
Поскольку к началу 2018 года количество общедоступных ноутбуков на GitHub превысило 1,8 миллиона, это, безусловно, самая популярная независимая платформа для обмена проектами Jupyter со всем миром. GitHub имеет встроенную поддержку рендеринга файлов .ipynb непосредственно как в репозиториях, так и в списках на своем веб-сайте. Если вы еще не знаете, GitHub — это платформа для размещения кода для контроля версий и совместной работы для репозиториев, созданных с помощью Git. Вам понадобится аккаунт, чтобы воспользоваться их услугами (стандартные аккаунты бесплатны).
Если у вас есть учетная запись GitHub, самый простой способ поделиться записной книжкой через GitHub на самом деле вообще не используя Git. С 2008 года GitHub предоставляет сервис Gist для размещения и совместного использования фрагментов кода, каждый из которых имеет свой собственный репозиторий. Чтобы поделиться блокнотом с помощью Gists:
- Войдите в GitHub и перейдите на gist.github.com.
- Откройте файл .ipynb в текстовом редакторе, выберите его содержимое и скопируйте JSON в память.
- Вставьте скопированное в блокнот JSON в gist.
- Определите имя файла вашего Gist, не забывая добавить .iypnb, иначе это не сработает.
- Нажмите “Create secret gist” или “Create public gist.”
Это должно выглядеть примерно так:

Если вы создали общедоступную Gist, теперь вы сможете поделиться ее URL-адресом с кем угодно, а другие смогут fork and clone вашу работу.
Создание собственного репозитория Git и распространение его на GitHub выходит за рамки данного руководства, но GitHub предоставляет множество руководств, которые помогут вам освоить его самостоятельно.
Дополнительным советом для тех, кто использует git, является добавление исключения в ваш .gitignore для скрытых каталогов .ipynb_checkpoints, которые создает Jupyter, чтобы избежать ненужной фиксации файлов контрольных точек в вашем репо.
Nbviewer
К 2015 году NBViewer стал самым популярным средством рендеринга ноутбуков в Интернете. Если у вас уже есть место для размещения ваших ноутбуков Jupyter в Интернете, будь то GitHub или где-либо еще, NBViewer отобразит ваш блокнот и предоставит совместно используемый URL-адрес вместе с ним. Предоставляется как бесплатный сервис в рамках проекта Jupyter, он доступен по адресу nbviewer.jupyter.org.
Первоначально разработанный до интеграции GitHub с Jupyter Notebook, NBViewer позволяет любому вводить URL-адрес, идентификатор Gist или имя пользователя/репозиторий/файл GitHub, и он отображает блокнот в виде веб-страницы. Идентификатор Gist — это уникальный номер в конце URL; например, строка символов после последнего обратного слеша в https://gist.github.com/username/50896401c23e0bf417e89cd57e89e1de. Если вы введете имя пользователя GitHub или username/репо, вы увидите минимальный файловый браузер, который позволит вам просматривать репозитории пользователя и их содержимое.
URL-адрес, отображаемый NBViewer при отображении записной книжки, является константой в зависимости от URL-адреса записываемой записной книжки, поэтому вы можете поделиться этим с кем угодно, и он будет работать, пока исходные файлы остаются в сети.
Заключение
Начав с основ, мы познакомились с естественным рабочим процессом Jupyter Notebooks, углубились в более продвинутые функции IPython и, наконец, научились делиться своей работой с друзьями, коллегами и миром. И мы сделали все это из самой записной книжки!
Если вы хотите получить вдохновение для своих собственных ноутбуков, Jupyter собрал галерею интересных ноутбуков Jupyter, которые вам могут пригодиться, и на домашней странице Nbviewer есть ссылки на действительно интересные примеры качественных ноутбуков.



