- Аналитика логов Nginx с помощью Amazon Athena и Cube.js
- Собираем логи Nginx
- S3 для хранения
- Создаем схему в консоли Athena
- Создаем Kinesis Firehose Stream
- Fluentd
- Athena
- Сканирование всех записей на каждый запрос
- Настраиваем Amazon Glue Crawler
- Партицированные таблицы
- Собираем дэшборд с помощью Cube.js
- Сбор и анализ логов Nginx с помощью Graylog2
- Aug 21, 2017 14:51 · 467 words · 3 minute read nginx logs graylog2
- Просмотр и анализ логов сайта на Linux сервере
- Важные логи сайта
- Расположение логов
- Стандартные пути до Error.log
- Nginx
- Php-Fpm
- Apache (CentOS)
- Apache (Ubuntu, Debian)
- Стандартные пути до Access.log
- Nginx
- Php-Fpm
- Apache (CentOS)
- Apache (Ubuntu, Debian)
- Чтение записей в логах
- Примеры записей
- Error.log
- Access.log
- Просмотр логов сервера с помощью команды tail
- Первый вариант использования Tail
- Второй вариант использования Tail
- Аналог команды Tail
- Изменение стандартного количества строк для вывода
- Просмотр логов с помощью ISPManager
- Программы для анализа логов
- Статические программы
- WebLog Expert
- Web Log Explorer
- Программы для анализа в режиме реального времени
- GoAccess
- Logstash
- Ведения логов медленных запросов сервера
- MySQL
- PHP-FPM
- Анализ логов медленных запросов
- Ведение логов в Logrotate
Аналитика логов Nginx с помощью Amazon Athena и Cube.js
Обычно для мониторинга и анализа работы Nginx используют коммерческие продукты или готовые open-source альтернативы, такие как Prometheus + Grafana. Это хороший вариант для мониторинга или real-time аналитики, но не слишком удобный для исторического анализа. На любом популярном ресурсе объем данных из логов nginx быстро растет, и для анализа большого объема данных логично использовать что-то более специализированное.
В этой статье я расскажу, как можно использовать Athena для анализа логов, взяв для примера Nginx, и покажу, как из этих данных собрать аналитический дэшборд, используя open-source фреймворк cube.js. Вот полная архитектура решения:

Для сбора информации мы используем Fluentd, для процессинга — AWS Kinesis Data Firehose и AWS Glue, для хранения — AWS S3. С помощью этой связки можно хранить не только логи nginx, но и другие эвенты, а также логи других сервисов. Вы можете заменить некоторые части на аналогичные для вашего стэка, например, можно писать логи в kinesis напрямик из nginx, минуя fluentd, или использовать logstash для этого.
Собираем логи Nginx
По умолчанию, логи Nginx выглядят как-то так:
Их можно распарсить, но гораздо проще поправить конфигурацию Nginx, чтобы он выдавал логи в JSON:
S3 для хранения
Чтобы хранить логи, мы будем использовать S3. Это позволяет хранить и анализировать логи в одном месте, так как Athena может работать с данными в S3 напрямую. Дальше в статье я расскажу, как правильно складывать и процессить логи, но для начала нам нужен чистый бакет в S3, в котором ничего больше храниться не будет. Стоит заранее подумать, в каком регионе вы создадите бакет, потому что Athena доступна не во всех регионах.
Создаем схему в консоли Athena
Создадим таблицу в Athena для логов. Она нужна и для записи, и для чтения, если вы планируете использовать Kinesis Firehose. Открываете консоль Athena и создаете таблицу:
Создаем Kinesis Firehose Stream
Kinesis Firehose запишет данные, полученные от Nginx, в S3 в выбранном формате, разбив по директориям в формате ГГГГ/ММ/ДД/ЧЧ. Это пригодится при чтении данных. Можно, конечно, писать напрямую в S3 из fluentd, но в этом случае придется писать JSON, а это неэффективно из-за большого размера файлов. К тому же, при использовании PrestoDB или Athena, JSON — самый медленный формат данных. Так что открываем консоль Kinesis Firehose, нажимаем «Create delivery stream», выбираем «direct PUT» в поле «delivery»:
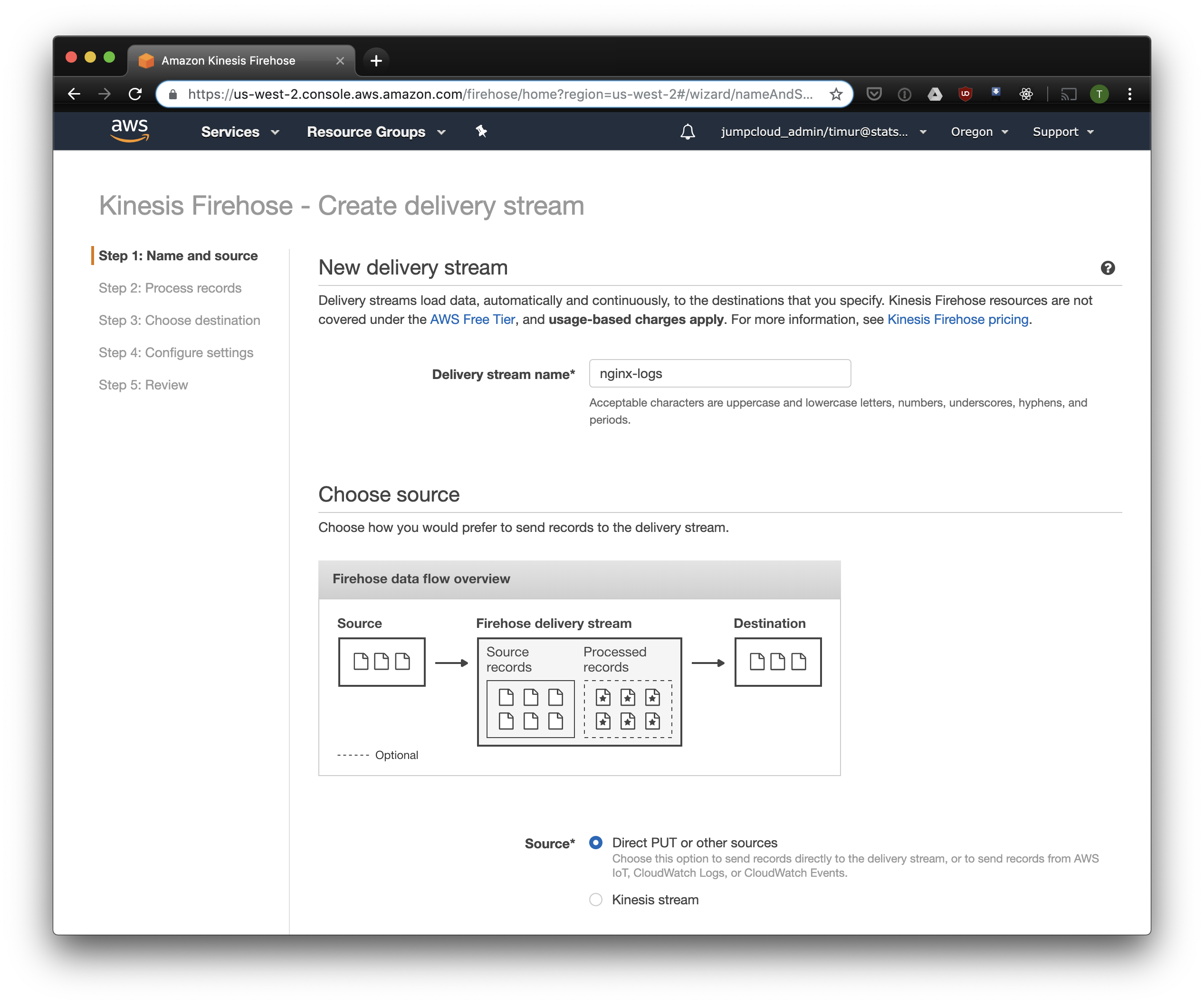
В следующей вкладке выбираем «Record format conversion» — «Enabled» и выбираем «Apache ORC» как формат для записи. Согласно исследованиям некоторого Owen O’Malley, это оптимальный формат для PrestoDB и Athena. В качестве схемы указываем таблицу, которую мы создали выше. Обратите внимание, что S3 location в kinesis можно указать любой, из таблицы используется только схема. Но если вы укажете другой S3 location, то прочитать из этой таблицы эти записи не получится.
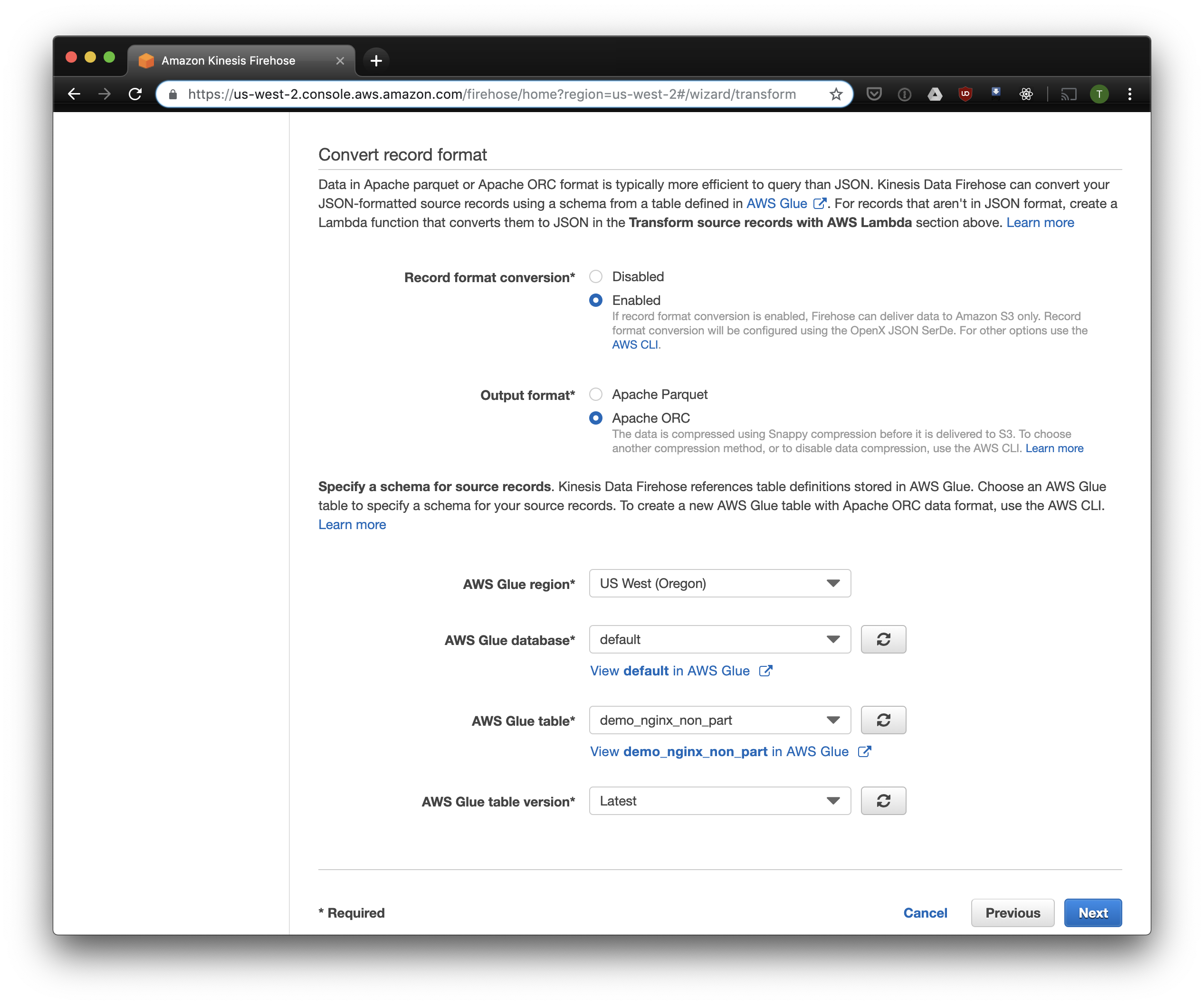
Выбираем S3 для хранения и бакет, который мы создали раньше. Aws Glue Crawler, про который я расскажу чуть позже, не умеет работать с префиксами в S3 бакете, так что его важно оставить пустым.

Остальные опции можно изменять в зависимости от вашей нагрузки, я обычно использую дефолтные. Обратите внимание, что сжатие S3 недоступно, но ORC использует собственное сжатие по умолчанию.
Fluentd
Теперь, когда у нас настроено хранение и получение логов, надо настроить отправку. Мы будем использовать Fluentd, потому что я люблю Ruby, но вы можете использовать Logstash или отправлять логи в kinesis напрямую. Fluentd сервер можно запустить несколькими способами, я расскажу про docker, потому что это просто и удобно.
Для начала, нам нужен файл конфигурации fluent.conf. Создайте его и добавьте source:
type forward
port 24224
bind 0.0.0.0
Теперь можно запустить Fluentd сервер. Если вам нужна более продвинутая конфигурация, на Docker Hub есть подробный гайд, в том числе и о том, как собрать свой образ.
Эта конфигурация использует путь /fluentd/log для кэширования логов перед отправкой. Можно обойтись без этого, но тогда при перезапуске можно потерять все закэшированное непосильным трудом. Порт тоже можно использовать любой, 24224 — это дефолтный порт Fluentd.
Теперь, когда у нас есть запущенный Fluentd, мы можем отправить туда логи Nginx. Мы обычно запускаем Nginx в Docker-контейнере, и в этом случае у Docker есть нативный драйвер логов для Fluentd:
Если вы запускаете Nginx иначе, вы можете использовать лог-файлы, в Fluentd есть file tail plugin.
Добавим в конфигурацию Fluent парсинг логов, настроенный выше:
И отправку логов в Kinesis, используя kinesis firehose plugin:
Athena
Если вы все правильно настроили, то через некоторое время (по-умолчанию Kinesis записывает полученные данные раз в 10 минут) вы должны увидеть файлы логов в S3. В меню «monitoring» Kinesis Firehose можно увидеть, сколько данных записано в S3, а так же ошибки. Не забудьте дать доступ на запись в бакет S3 для роли Kinesis. Если Kinesis что-то не смог распарсить, он сложит ошибки в том же бакете.
Теперь можно посмотреть данные в Athena. Давайте найдем свежие запросы, на которые мы отдали ошибки:
Сканирование всех записей на каждый запрос
Теперь наши логи обработаны и сложены в S3 в ORC, сжаты и готовы к анализу. Kinesis Firehose даже разложил их по директориям на каждый час. Однако, пока таблица не партицирована, Athena будет загружать данные за все время на каждый запрос, за редким исключением. Это большая проблема по двум причинам:
- Объем данных постоянно растет, замедляя запросы;
- Счет за Athena выставляется в зависимости от объема просканированных данных, с минимумом 10 МБ за каждый запрос.
Чтобы исправить это, мы используем AWS Glue Crawler, который просканирует данные в S3 и запишет информацию о партициях в Glue Metastore. Это позволит нам использовать партиции как фильтр при запросах в Athena, и она будет сканировать только директории, указанные в запросе.
Настраиваем Amazon Glue Crawler
Amazon Glue Crawler сканирует все данные в S3 бакете и создает таблицы с партициями. Создайте Glue Crawler из консоли AWS Glue и добавьте бакет, в котором вы храните данные. Вы можете использовать один краулер для нескольких бакетов, в этом случае он создаст таблицы в указанной базе данных с названиями, совпадающими с названиями бакетов. Если вы планируете постоянно использовать эти данные, не забудьте настроить расписание запуска Crawler в соответствии с вашими потребностями. Мы используем один Crawler для всех таблиц, который запускается каждый час.
Партицированные таблицы
После первого запуска краулера в базе данных, указанной в настройках, должны появиться таблицы для каждого просканированного бакета. Откройте консоль Athena и найдите таблицу с логами Nginx. Давайте попробуем что-нибудь прочитать:
Этот запрос выберет все записи, полученные с 6 до 7 утра 8 апреля 2019 года. Но насколько это эффективнее, чем просто читать из не-партицированной таблицы? Давайте узнаем и выберем те же записи, отфильтровав их по таймстемпу:
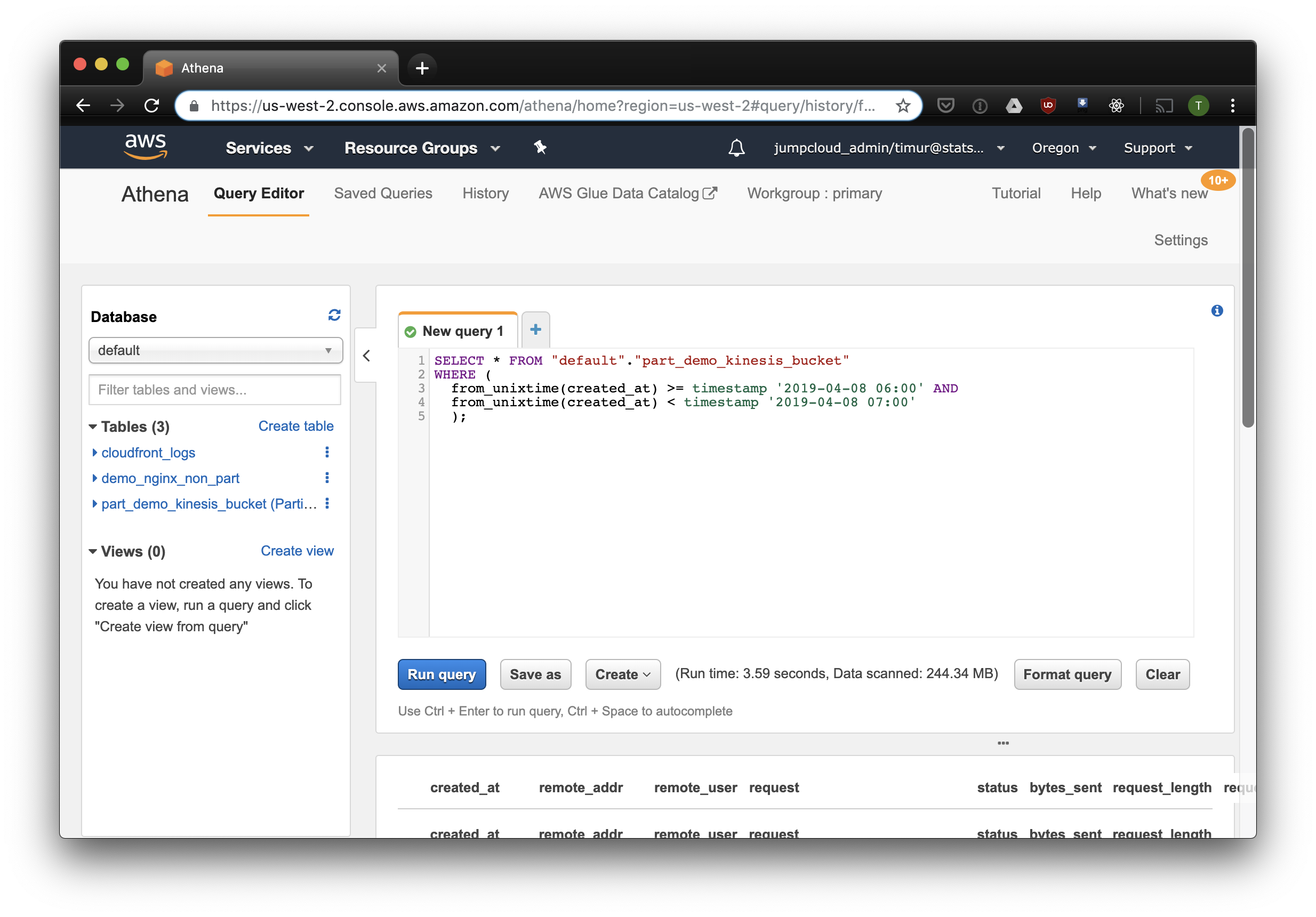
3.59 секунды и 244.34 мегабайт данных на датасете, в котором всего неделя логов. Попробуем фильтр по партициям:
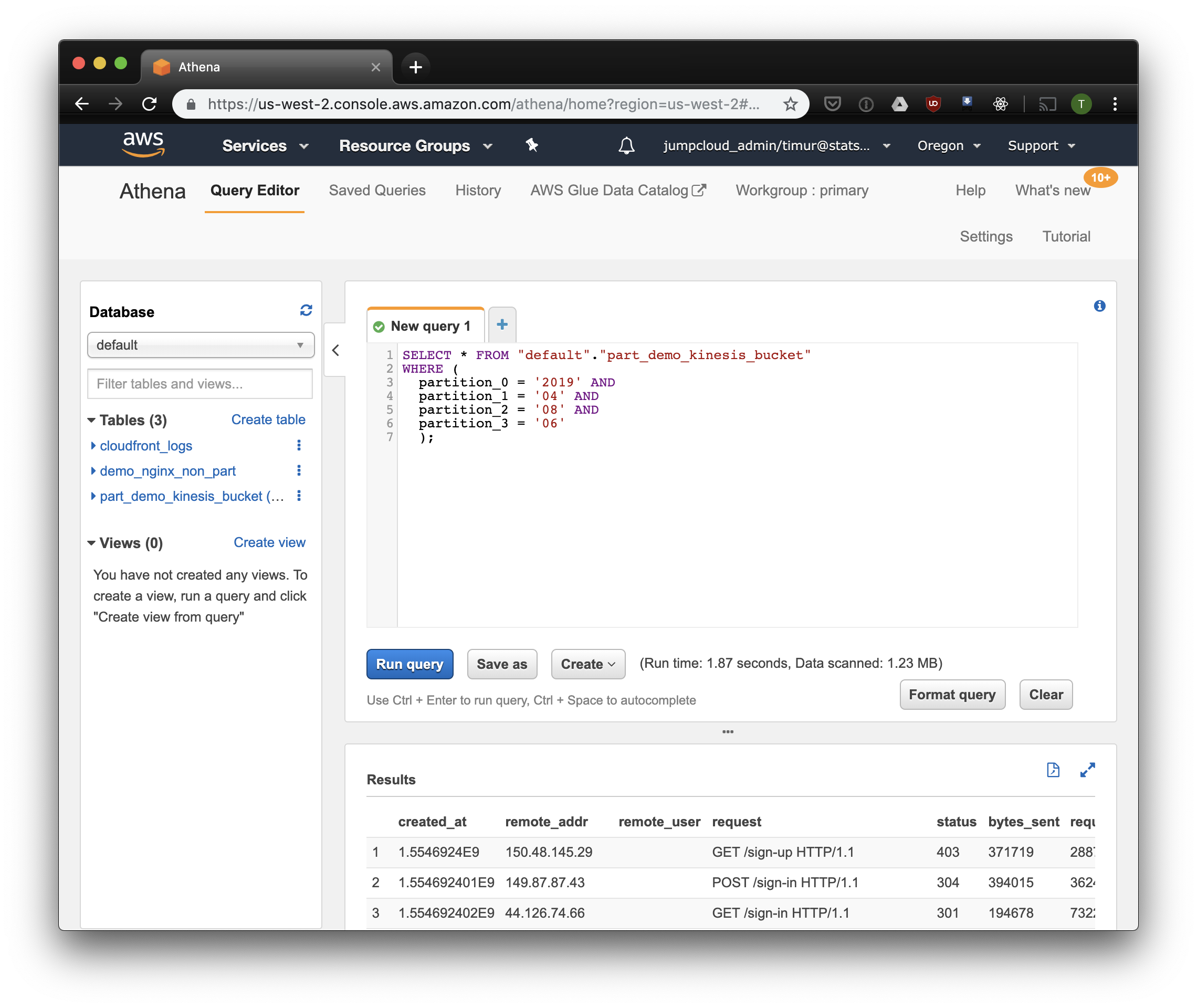
Чуть быстрее, но самое важное — всего 1.23 мегабайта данных! Это было бы гораздо дешевле, если бы не минимальные 10 мегабайт за запрос в прайсинге. Но все равно гораздо лучше, а на больших датасетах разница будет куда более впечатляющей.
Собираем дэшборд с помощью Cube.js
Чтобы собрать дэшборд, мы используем аналитический фреймворк Cube.js. У него довольно много функций, но нас интересуют две: возможность автоматически использовать фильтры по партициям и пре-агрегации данных. Он использует схему данных data schema, написанную на Javascript, чтобы сгененрировать SQL и исполнить запрос к базе данных. От нас требуется лишь указать, как использовать фильтр по партициям в схеме данных.
Создадим новое приложение Cube.js. Так как мы уже используем AWS-стэк, логично использовать Lambda для деплоя. Вы можете использовать express-шаблон для генерации, если планируете хостить Cube.js бэкенд в Heroku или Docker. В документации описаны другие способы хостинга.
Для настройки доступа к базе данных в cube.js используются переменные окружения. Генератор создаст файл .env, в котором вы можете указать ваши ключи для Athena.
Теперь нам потребуется схема данных, в которой мы укажем, как именно хранятся наши логи. Там же можно указать, как считать метрики для дэшбордов.
В директории schema , создайте файл Logs.js . Вот пример модели данных для nginx:
Здесь мы используем переменную FILTER_PARAMS, чтобы сгенерировать SQL запрос с фильтром по партициям.
Мы также задаем метрики и параметры, которые хотим отобразить на дэшборде, и указываем пре-агрегации. Cube.js создаст дополнительные таблицы с пре-агрегированными данными и будет автоматически обновлять данные по мере поступления. Это позволяет не только ускорить запросы, но и снизить стоимость использования Athena.
Добавим эту информацию в файл схемы данных:
Мы указываем в этой модели, что необходимо пре-агрегировать данные для всех используемых метрик, и использовать партицирование по месяцам. Партицирование пре-агрегаций может значительно ускорить сбор и обновление данных.
Теперь мы можем собрать дэшборд!
Бэкенд Cube.js предоставляет REST API и набор клиентских библиотек для популярных фронтенд-фреймворков. Мы воспользуемся React-версией клиента для сборки дэшборда. Cube.js предоставляет лишь данные, так что нам потребуется библиотека для визуализаций — мне нравится recharts, но вы можете использовать любую.
Сервер Cube.js принимает запрос в JSON формате, в котором указаны необходимые метрики. Например, чтобы посчитать, сколько ошибок отдал Nginx по дням, нужно отправить такой запрос:
Установим Cube.js клиент и библиотеку React-компонет через NPM:
Импортим компонетны cubejs и QueryRenderer , чтобы выгрузить данные, и собираем дэшборд:
Исходники дэшборда доступны на CodeSandbox.
Сбор и анализ логов Nginx с помощью Graylog2
Aug 21, 2017 14:51 · 467 words · 3 minute read nginx logs graylog2
Graylog2 — бесплатная open source система для централизованного сбора, хранения и анализа логов. Для работы ему нужна Java, конфигурацию он хранит в MongoDB, для поиска и хранения логов — ElasticSearch.
Давайте разберемся со сбором и анализом логов web-сервера Nginx с помощью Graylog2!
Для «быстрого развертывания» будем использовать docker-контейнеры, поэтому считаем что на вашем хосте уже установлен docker (например, так) и docker-compose .
Если же нет — выполняем следующие шаги для установки docker’а:
Для установки последней версии docker-compose (версию смотрим здесь) используем следующие команды:
Создаем файл docker-compose.yml следующего содержания:
Находясь в каталоге с только что созданным файлом выполняем команду:
После запуска контейнеров необходимо подождать пару минут (при первом запуске Graylog2 стартует дольше), после чего можно залогиниться в web-интерфейс (в нашем примере — по адресу http://graylog.lc:9911) используя стандартный логин и пароль: admin/admin.
Далее скачиваем контент-пак в json-формате по этой ссылке, в web-интерфейсе грейлога переходим на вкладку “System/Content Packs”, выбираем пункт “Import content pack” и загружаем скачанный json-файл.
После успешной загрузки контент пак nginx появится в пункте меню “Web Servers”, где можно ознакомиться с его описанием и обязательно нажать кнопку “Apply content”.
Также необходимо внести минимальное количество правок в конфигурационный(е) файл web-сервера Nginx. В конфигурационные файлы сайтов (секция server ) необходимо добавить следующие директивы:
Формат лога ( graylog2_format ) определяется в основном конфигурационном файле ( nginx.conf ) и выглядит так:
Перечитываете конфиг Nginx командой:
и логи начинают поступать в Graylog2, где с ними можно очень удобно работать.
Кроме того, в составе установленного контент пака есть уже готовый дашборд с основными метриками web-сервера, а именно:
- количество запросов за последние 24 часа (общее число + график, на котором видно динамику изменения кол-ва запросов);
- количество запросов, завершившихся с кодом 4XX за последние 24 часа (общее число + график, на котором видно динамику изменения кол-ва запросов);
- количество запросов, завершившихся с кодом 5XX за последние 24 часа (общее число + график, на котором видно динамику изменения кол-ва запросов);
- версии HTTP-протокола, по которым обращаются к сайту за последние 24 часа (процент + общее число);
- коды ответа на запросы за последние 24 часа (процент + общее число);
- коды ответа на запросы за последний час (процент + общее число).
tweetShare
Просмотр и анализ логов сайта на Linux сервере
Содержание:
Логи сайта — это системные журналы, позволяющие получить информацию о посещении сайта ботами и пользователями, а также выявить скрытые проблемы на сервере — ошибки, битые ссылки, медленные запросы от сервера и многое другое.
Важные логи сайта
- Access.log — логи посещений пользователей и ботов. Позволяет составить более точную и подробную статистику, нежели сторонние ресурсы, выполняющие внешнее сканирование сайта и отправляющие ряд ненужных запросов серверу. Благодаря данному логу можно получить информацию об используемом браузере и IP-адрес посетителя, данные о местонахождении клиента (страна и город) и многое другое. Стоит обратить внимание, если сайт имеет высокую посещаемость, то анализ логов сервера потребует больше времени. Поэтому для составления статистики стоит использовать специализированные программы (анализаторы).
- Error.log — программные ошибки сервера. Стоит внимательно отнестись к анализу данного лога, ведь боты поисковиков, сканируя, получают все данные о работе сайта. При обнаружении большого количества ошибок, сайт может попасть под санкции поисковых систем. В свою очередь из записей данного журнала можно узнать точную дату и время ошибки, IP-адрес получателя, тип и описание ошибки.
- Slow.log (название зависит от используемой оболочки сервера) — в данный журнал записываются медленные запросы сервера. Так принято обозначать запросы с повышенным порогом задержки, выданные пользователю. Этот журнал позволяет выявить слабые места сервера и исправить проблему. Ниже будет рассмотрен способ включить ведение данного лога на разных типах серверов, а также настройка задержки, с которой записи будут заноситься в файл.
Расположение логов
Важно обратить внимание, что местоположение логов сайта по умолчанию зависит от используемого типа оболочки и может быть изменено администратором.
Стандартные пути до Error.log
Nginx
Php-Fpm
Apache (CentOS)
Apache (Ubuntu, Debian)
Стандартные пути до Access.log
Nginx
Php-Fpm
Apache (CentOS)
Apache (Ubuntu, Debian)
Чтение записей в логах
Записи в логах имеют структуру: одно событие – одна строка .
Записи в разных логах имеют общие черты, но количество подробностей отличается. Далее будут приведены примеры строк из разных системных журналов.
Примеры записей
Error.log
В приведенном примере:
- [Sat Sep 1 15:33:40.719615 2019] — дата и время события.
- [:error] [pid 10706] — ошибка и её тип.
- [client 66.249.66.61:60699] — IP-адрес подключившегося клиента.
- PHP Notice: Undefined variable: moduleclass_sfx in — событие PHP Notice. В данной ситуации — обнаружена неизвестная переменная.
- /var/data/www/site.ru/modules/contacts/default.php on line 14 — путь и номер строки в проблемном файле.
Access.log
В приведенном примере:
- 194.61.0.6 — IP-адрес пользователя.
- alex — если пользователь зарегистрирован в системе, то в логах будет указан идентификатор.
- [10/Oct/2019:15:32:22 -0700]— дата и время записи.
- «GET /apache_pb.gif HTTP/1.0» — «GET» означает, что определённый документ со страницы сайта был отправлен пользователю. Существует команда «POST», наоборот отправляет конкретные данные (комментарий или любое другое сообщение) на сервер . Далее указан извлечённый документ «Apache_pb.gif», а также использованный протокол «HTTP/1.0».
- 200 5396 — код и количество байтов документа, которые были возвращены сервером.
- «http://www. www.mysite/myserver.html»— страница, с которой был произведён запрос на извлечение документа «Apache_pb.gif».
- «Mozilla/4.08 [en] (Win98; I ;Nav)» — данные о пользователе, которой произвёл запрос (используемый браузер и операционная система).
Просмотр логов сервера с помощью команды tail
Выполнить просмотр логов в Linux можно с помощью команды tail . Данный инструмент позволяет смотреть записи в логах, выводя последние строки из файла. По умолчанию tail выводит 10 строк.
Первый вариант использования Tail
Аргумент «-f» позволяет команде делать просмотр событий в режиме реального времени, в ожидании новых записей в лог файлах. Для прерывания процесса следует нажать сочетание клавиш «Ctrl+C».
На место переменной «/var/log/syslog» в примере следует подставить актуальный адрес до нужных системных журналов.
Второй вариант использования Tail
В Linux логи веб-сервера не ведутся до бесконечности, поскольку это усложняет их дальнейший анализ. При преодолении лимита записей, система переименует переполненный строками файл журнала и отправит в «архив». Вместо старого файла создастся новый, но с прежним названием.
Если будет использоваться аргумент «-f», команда продолжит отслеживание старого, переименованного журнала. Данный метод делает невозможным просмотр логов в реальном времени, поскольку файл более не актуален.
При использовании аргумента «-F», команда, после окончания записи старого журнала, перейдёт к чтению нового файла с логами. В таком случае просмотр логов в режиме реального времени продолжится.
Аналог команды Tail
Отличие команды tailf от предыдущей заключается в том, что она не обращается к файлу и файловой системе в период, когда запись логов не происходит. Это экономит ресурсы системы и заряд, если используется нестационарное устройство — ноутбук, смартфон или планшет.
Недостаток данного способа — проблема с чтением больших файлов. Если системный журнал достаточно большой, возникает вероятность отказа в работе программы.
Изменение стандартного количества строк для вывода
Как и отмечалось выше, по умолчанию выводится 10 строк. Если требуется увеличить или уменьшить их количество, в команду добавляется аргумент «-n» и необходимое число строк.
При использовании данной команды будут показаны последние 100 строк журнала.
Просмотр логов с помощью ISPManager
Если на сервере установлен ISPManager, логи можно легко читать, используя приведенный ниже алгоритм.
- На главной странице, в панели инструментов «WWW» нужно нажать на вкладку «Журналы».
- ISPManager выдаст журналы посещений и серверных ошибок в виде:
- ru.access.log;
- ru.error.log.*
* Вместо «newdomen.ru» из примера в выдаче будет название актуального домена.
Открыть файл лога можно, нажав на «Посмотреть» в верхнем меню.
Программы для анализа логов
Анализировать журналы с большим количеством данных вручную не только сложно, но и чревато ошибками. Для упрощения работы с лог файлами было создано большое количество сервисов и утилит.
Инструменты для анализа логов делятся на два основных типа — статические и работающие в режиме реального времени.
Статические программы
Данный тип выполняет работу только с извлеченными логами, но обеспечивает быструю сортировку данных.
WebLog Expert
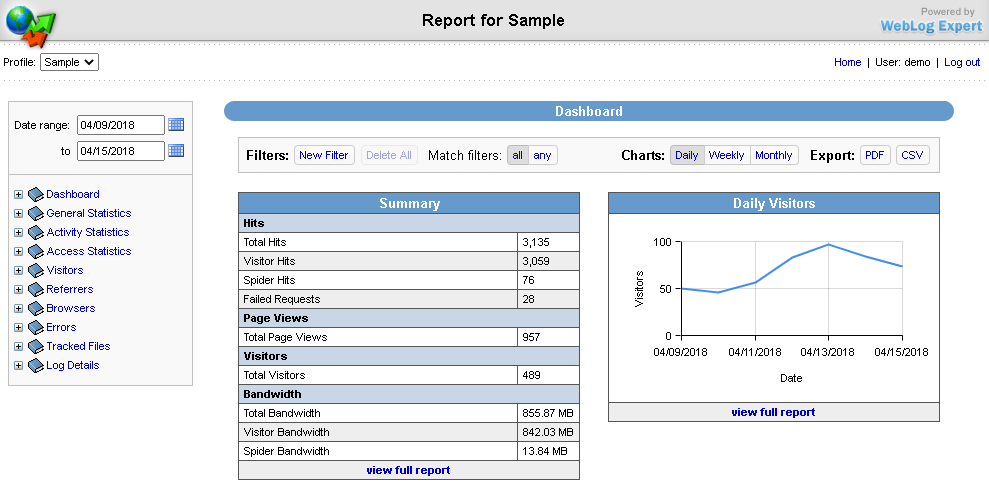
Возможности
- Предоставление информации об активность сайта, количестве посетителей, доступ к файлам, URL страницы, ссылающиеся страницы, информацию о пользователе (браузер и операционная система).
- Создание отчётов в формате HTML (.html), PDF (.pdf), CSV (.csv).
- Поддерживает анализ логов Nginx, Apache, ISS.
- Чтение файлов даже в архивах ZIP (.zip), GZ (.gz).
Web Log Explorer
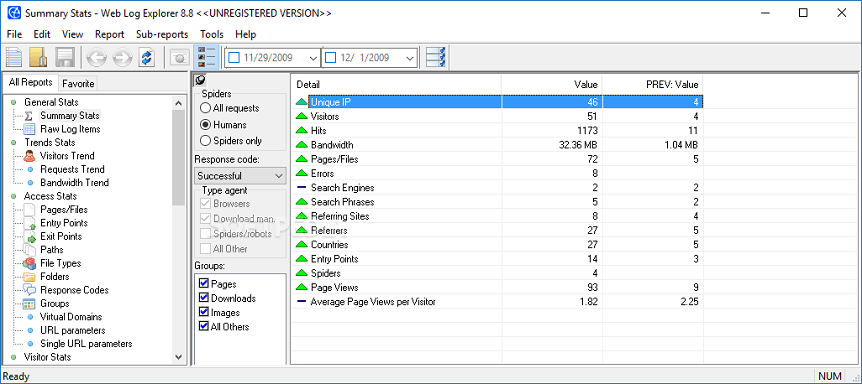
Возможности
- Создание многоуровневых отчётов, включающих количество посетителей, маршруты пользователей по сайту, местоположение хостов (страна и город), указанные в поисковике ключевые слова.
- Поддержка более 43 форматов логов.
- Возможность прямой загрузки логов с FTP, HTTP сервера.
- Чтение архивированных журналов.
Программы для анализа в режиме реального времени
Эти инструменты встраиваются в программную среду сервера, анализируют данные в реальном времени и записывают непрерывный отчёт.
GoAccess
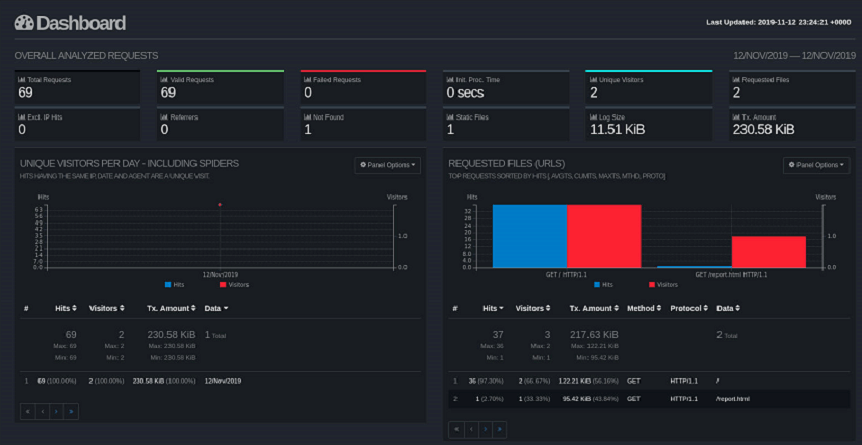
Возможности
- Автоматическая генерация отчёта в формате HTML (.html), JSON (.json), CSV (.csv).
- При подключении к серверу через SSH, возможен анализ в браузере и в терминале
- Поддержка почти всех форматов (Apache, Nginx, Amazon S3, Elastic Load Balancing, CloudFront и др.).
Logstash
Возможности
- Постоянная генерация отчёта в файл JSON (.json).
- Получение и анализ информации из нескольких источников.
- Возможность пересылать журналы с помощью Filebeat.
- Поддержка анализа системных журналов.
- Поддерживается большое количество форматов: от Apache до Log4j (Java).
Ведения логов медленных запросов сервера
Анализ данного лога позволяет определить на какие типы запросов сервер отвечает долго. В идеале задержка должна составлять не более 1 секунды.
На некоторых типах оболочек (MySQL, PHP-FPM) ведение данного лога по умолчанию отключено. Процесс запуска и ведения зависит от сервера.
MySQL
Если сервер управляется с помощью MySQL, то необходимо создать каталог и сам файл для ведения журнала с помощью команд:
Стоит изменить владельца файла, чтобы избежать дальнейших проблем с записью логов. Делается это командой:
После выполнения предыдущих действий, нужно совершить вход в командную строку MySQL под учётной записью суперпользователя:
Для запуска и настройки ведения логов нужно последовательно ввести в терминале следующие команды:
- slow_query_log — запускает ведение журналов медленных запросов.
- slow_launch_time — указывает максимальную задержку отклика, после которой статистика запроса попадёт в журнал. В данном случае запись в логи происходит при преодолении откликом порога 2 секунды.
- slow_query_log_file — задаёт путь до используемого журнала.
Проверить статус и параметры ведения лога медленных запросов можно командой:
Выход из консоли MySQL выполняется командой:
После выполнения всех предыдущих действий, можно просмотреть логи сервера. Для этого в терминале вводится:
PHP-FPM
Для ведения журнала на данной оболочке, необходимо отредактировать параметры в конфигурационном файле. Для этого в терминале вводится команда:
Далее нужно найти строки:
- request_slowlog_timeout = 10s — параметр, позволяющий указать задержку, с которой запись о длительном запросе попадёт в журнал.
- slowlog = /var/log/php-fpm/www-slow.log — параметр, указывающий путь до актуального файла логирования (.log).
После применения изменений, необходимо перезагрузить сервер PHP-FPM. Для этого в консоль вводится команда:
Просмотр логов запускается командой:
Анализ логов медленных запросов
Логи медленных запросов могут за незначительное время вырасти до огромных размеров. Для сортировки и отображения повторяющихся запросов рекомендуется использовать программу MySQLDumpSlow.
Для запуска просмотра логов с помощью этой утилиты, нужно составить команду по приведенному ниже алгоритму:
Ведение логов в Logrotate
На больших ресурсах журналы могут достигать огромных размеров, поэтому нужно своевременно архивировать или очищать логи. С помощью утилиты Logrotate можно управлять ведением журналов: настроить период ротации (архивирование старого журнала и создание нового), период и количество хранения журналов и многое другое.
Изначально программа отсутствует в системе. Ниже приведены команды для инсталляции Logrotate из официальных репозиториев.
Ubuntu, Debian:
CentOS:
После установки необходимо проверить путь для будущих конфигурационных файлов. Для правильной работы они должны находится в папке «logrotate.d». Проверить данный параметр можно открыв конфигурационный файл командой:
В директории «RPM packages drop log rotation information into this directory» должна присутствовать строка:
Теперь создаётся конфигурационный файл «rsyslog.conf». В нём будет находиться конфигурацию по работе с логами. Для создания файла в терминале вводится команда:
В окне терминала откроется текстовой редактор. Теперь нужно внести конфигурацию, как указано в образце. В качестве примера будет использоваться журнал посещений «Access.log» (Nginx).
Теперь остаётся только запустить Logrotate. Для этого вводится команда:
Для проверки правильности работы программы в терминале можно ввести команду:
Начни экономить на хостинге сейчас — 14 дней бесплатно!



