- Development Prism
- Tuesday, 6 July 2010
- PowerShell — AWK для Windows?
- Gawk for Windows
- Version
- Description
- Homepage
- Download
- Аналоги awk для windows
- Bash-скрипты, часть 8: язык обработки данных awk
- Особенности вызова awk
- Чтение awk-скриптов из командной строки
- Позиционные переменные, хранящие данные полей
- Использование нескольких команд
- Чтение скрипта awk из файла
- Выполнение команд до начала обработки данных
- Выполнение команд после окончания обработки данных
- Встроенные переменные: настройка процесса обработки данных
- Встроенные переменные: сведения о данных и об окружении
- Пользовательские переменные
- Условный оператор
- Цикл while
- Цикл for
- Форматированный вывод данных
- Встроенные математические функции
- Строковые функции
- Пользовательские функции
- Итоги
Development Prism
Tuesday, 6 July 2010
PowerShell — AWK для Windows?
В жизни программиста нередко возникает такой момент, когда нужно автоматически перелопатить много текстовой информации, извлекая из неё что-то, либо модифицируя. Программисты и администраторы Unix всегда под рукой имеют целую кучу средств. Bash предоставляет базовые возможности вроде замены подстроки; для более мощных преобразований есть sed и awk.
Для меня всегда было загадкой, что же делать бедным программистам, живущим на Windows? Конечно, всегда можно поставить cygwin и использовать те же самые bash, sed и awk. Можно сразу взять быка за рога и установить Perl или Python. Но всё это какие-то . неродные что ли решения. Вот были бы какие-нибудь стандартные программы для таких операций. С помощью стандартного коммандного процесора cmd заниматься текстовыми преобразованиями весьма проблематично.
Итак, где же решение? Довольно давно на горизонте Windows замаячил инновационный шелл под скромным названием PowerShell. От всех остальных шеллов в мире он отличается объектной-ориентированностью и строгой динамической типизацией. Как это выглядит на практике, объяснять довольно долго, и об этом прекрасно рассказано в книге «PowerShell in Action». Получилось непривычно, но вполне эффективно. Ладно, шелл шеллом, а как быть с обработкой текстовых данных? Способен ли этот шелл заменить собой AWK для Windows? Как выяснилось, ответ положительный.
Перед нами простой AWK скрипт, который обновляет два определения в rpm .spec-файле:
Он не претендует на шедевральность, страдает повторами, но своё дело делает исправно. Как он работает? Awk читает $SPEC_FILE построчно и каждую строку передаёт в скрипт, предварительно разбив её на поля по пробелам. Каждое поле доступно в виде переменной вида $n, где n — число от 0 до количества полей. Так, строка «Hello World» будет разбита следующим образом: $0 = «Hello World», $1 = «Hello», $2 = «World». Сам скрипт организован в виде последовательности шаблонов и соответствующих им действий. Если шаблон соответствует текущей строке, то соответствующее действие выполняется. Действие без шаблона выполняется для каждой строки, если до него доходит управление. Шаблон в awk понятие довольно общее — это может быть регулярное выражение или условное выражение, которое может сопровождаться побочными эффектами, например, выделением подгрупп из поля с помощью регулярного выражения.
Предоположим, что у нас есть следующая спека:
После применения скрипта, полагая что
PKG_NAME=NEW_PACKAGE и REQUIRED_PKG_NAME=OLD_PACKAGE ,
получим:
Как достичь аналогичного результата в PowerShell? Как оказалось, очень просто. В PowerShell есть интересный оператор switch . Может он неожиданно много. На первый взгляд, он ничем принципиально не отличается от аналогичных операторов в языках типа C. Но в PowerShell этот оператор гораздо более гибок. Нас интересуют следующие его свойства:
- Он может содержать в качестве шаблонов произвольные типы PowerShell, в частности строки;
- Он может принимать параметры (оператор, который принимает параметры, с ума сойти), которые влияют на интерпретацию шаблонов и анализируемого выражения. Мы применим:
- -regex : интерпретирует шаблон-строку как регулярное выражение и проверяет анализируемое значение на соответствие ему;
- -file : интерпретирует анализируемое выражение как имя файла, и построчно (звучит знакомо 🙂 ) передаёт его в оператор switch .
Итак, аналогичный скрипт на PowerShell:
Он удивительно похож на исходный. Впрочем, это, скорее, не удивительно, потому что, по утверждению создателей PowerShell, они учли весь тридцатилетний опыт Unix-шеллов и опыт современных скриптовых языков как Perl и Python. Хочется отметить следующие особенности:
- Автоматическая переменная $matches , которая чудесным образом появляется после выполнения операции соответствия регулярному выражению.
- Другая чудо-переменная: $_ — обозначает анализируемое выражение, то есть всю текущую строку в данном случае.
- Получившиеся строки не печатаются (print, echo, write) и не возвращаются (return), не собираются в массив, а эмитируются (emit). Эмитирование — это неявное возвращение результата. Так, в Bash’е результат выполнения скрипта — это результат последней команды в нём, если нет явного вызова exit. В Groovy, функции возращают результат последнего выражения, если не указано слово return, и если функция не типа void. В PowerShell функция (или любой скрипт-блок как в switch) может эмитировать любое количество результатов, и возвращаются они все. По умолчанию, эмитированые значения выводятся на экран. Но мы перехватываем результат оператора switch c помощью нотации подвыражения $( ) . Таким образом, эмитированый результат оператора становится значением подвыражения, а с этим значением можно сделать всё что угодно — хоть переменной присвоить, хоть в файл вывести.
Выразительные возможности PowerShell и оператора switch вполне соответствуют возможностям языка AWK. Из отличий хочется прежде всего упомянуть отсутствие автоматического разбиения на поля по разделителю. Строка обрабатывается целиком. Но называть это минусом я бы не стал. По моему (впрочем, небольшому) опыту, обработка строки целиком нередко оказывается даже более удобной. Кроме того, строку всегда можно разбить на поля с помощью методов String.split или Regex.split. Не стоит забывать, что ноги у PowerShell растут напрямую из .NET. PowerShell позволяет использовать более органичный синтаксис для перехвата групп регулярного выражения, чем AWK (там пришлось бы использовать такой шаблон: match($0, /%define name/, matches) ).
PS: Написав всё это, я осознал, что данная задача настолько тривиальна, что можно было бы вполне обойтись двумя заменами регулярных выражений по всему тексту файла. Тем не менее, она неплохо иллюстрирует сходства и различия подхода к обработке текста в AWK и PowerShell.
Gawk for Windows
Gawk: pattern scanning and processing language
Version
Description
Several kinds of tasks occur repeatedly when working with text files. You might want to extract certain lines and discard the rest. Or you may need to make changes wherever certain patterns appear, but leave the rest of the file alone. Writing single-use programs for these tasks in languages such as C, C++ or Pascal is time-consuming and inconvenient. Such jobs are often easier with awk. The awk utility interprets a special-purpose programming language that makes it easy to handle simple data-reformatting jobs. The GNU implementation of awk is called gawk; it is fully compatible with the System V Release 4 version of awk. gawk is also compatible with the POSIX specification of the awk language. This means that all properly written awk programs should work with gawk. Thus, we usually don’t distinguish between gawk and other awk implementations. Using awk allows you to:
- Manage small, personal databases
- Generate reports
- Validate data
- Produce indexes and perform other document preparation tasks
- Experiment with algorithms that you can adapt later to other computer languages.
In addition, gawk provides facilities that make it easy to:
- Extract bits and pieces of data for processing
- Sort data
- Perform simple network communications.
The Win32 port has some limitations, In particular the ‘|&’ operator and TCP/IP networking are not supported.
Homepage
Download
| Description | Download | Size | Last change | Md5sum | ||||
|---|---|---|---|---|---|---|---|---|
| • Complete package, except sources | Setup | 5219803 | 10 February 2008 | 1fdd86c1d73496817588f12a2a2e3a43 | ||||
| • Sources | Setup | 1835124 | 10 February 2008 | af227dfd10480e843d5232d131029c1f | ||||
| • Binaries | Zip | 1448542 | 10 February 2008 | f875bfac137f5d24b38dd9fdc9408b5a | ||||
| • Documentation | Zip | 4908800 | 29 December 2007 | 110365c9193c8e99033d50abde55aa02 | ||||
| • Sources | Zip | 3126204 | 10 February 2008 | 299f9fd976aded253a5a4610ca0f2b11 | ||||
| • Original source | http://ftp.gnu.org/gnu/gawk/gawk-3.1.6.tar.gz | |||||||
You can also download the files from the GnuWin32 files page. New releases of the port of this package can be monitored.
Аналоги awk для windows
Аналоги Linux-программ в Windows:)) [20.03.2005]
30.01.2005 В первой серьезной попытке проверить акутальность таблицы и ссылок стало совершенно очевидно, что plainHTML тут не уместен, без бд и дружелюбных сркиптов управления контентом тут не обойстись, куда и предполагается направить усилия, а пока «as is»
20.03.2005 Ведется работа по созданию wiki варианта по этому адресу: http://www.freesource.info/wiki/WinLinTable/
Для добавления программы в таблицу отправьте письмо на forgarb@mail.ru и укажите в нем название программы, платформу, описание (зачем нужна эта программа, какие задачи с помощью нее решаются, . ), и ссылку на официальный сайт этой программы (если есть). Все комментарии, замечания, исправления и предложения принимаются там же
Правила заполнения таблицы:
1) На несколько программ Windows можно привести один их общий Линукс аналог, и наоборот — на одну программу Windows можно приводить сразу несколько Linux аналогов.
2) Не стоит стрелять из пушки по воробью — стоит приводить программы одинаковых весовых категорий (например, все же не очень корректно приводить OpenOffice как аналог блокнота). По возможности размер программ (в мегабайтах) и доступность должны быть сопоставимы.
3) Стабильность Linux-программы должна быть такой же, как у программы для Windows, а лучше — выше :).
4) Желательна ссылка на то, где можно взять программу для Линукс.
5) Если Windows программа имеет графический интерфейс, то и Линукс программа должна его иметь (ну, или хотя бы доступный и рабочий FrontEnd к консольной программе).
6) Порядок расположения программ в этой таблице: сначала самые лучшие, известные и близкие аналоги (по возможности), а потом — все остальные.
Условные обозначения:
1) По умолчанию большинство программ для Linux, указанных в этой таблице — это свободное программное обеспечение. (Определения Free Software: FSF и Debian). Около проприетарных программ по возможности ставится знак [Prop]. Около несвободных программ (с открытыми исходниками, но под ограниченными лицензиями, и т.д.) ставится знак [NF].
2) Если в поле таблицы нет ничего, кроме «. » — составители таблицы не знают, что туда поместить.
3) Если после названия программы стоит «(. )» — составители таблицы не уверены в том, что данная программа помещена в правильный раздел, или что эта программа существует вообще.
Важное идеологическое различие между Windows и Linux:
Большинство программ для Windows создаются по принципу «все в одном» (каждый разработчик сам реализует все в своем продукте). Так же этот принцип называют «Windows-way».
Идеология UNIX/Linux — один компонент или одна программа должны выполнять только какую-то одну задачу, но зато выполнять её хорошо. («UNIX-way»). Программы под Linux напоминают конструктор LEGO (например, если существует программа для проверки орфографии, то её используют при разработке текстового редактора, или если уже существует мощная консольная программа для скачивания файлов, то проще написать к ней графический интерфейс (a.k.a Front-end), и т.д).
Этот принцип очень важен и его нужно учитывать при поиске аналогов Windows-программ в Linux :).
Внимание! В таблице могут присутствовать ошибки и несоответствия!! (сообщить об ошибке).
Около 90% программ, указанных в колонке «Linux», не являются прямыми и 100-процентными аналогами соответствующих программ из колонки «Windows». Они просто предназначены для той же самой цели. Большинство программ, указанных в таблице, присланы посетителями этой страницы, поэтому составители не несут никакой ответственности за различные несоответствия :).
Для тех, кого больше интересуют Windows-программы:
1) Колонка «Windows» в этой таблице является второстепенной, и поэтому в ней не перечисляется _абсолютно_ весь существующий софт — только самые лучшие и популярные программы.
2) Многие программы для Linux могут быть запущены и под Windows — с помощью CygWin и других эмуляторов Linux.
Программы и игры для Windows, которые можно запустить под Wine/WineX:
1) Официальный каталог Windows-программ, идущих под Wine. (от Codeweavers). В базе данных — более 1000 программ, поэтому каталог имеет разветвлённую структуру и систему навигации.
2) Официальный список Windows-игр, которые запускаются под WineX (от Transgaming). Это — страница для поиска игр, а это — полный список игр, идущих под WineX (очень большой!).
Bash-скрипты, часть 8: язык обработки данных awk

В прошлый раз мы говорили о потоковом редакторе sed и рассмотрели немало примеров обработки текста с его помощью. Sed способен решать многие задачи, но есть у него и ограничения. Иногда нужен более совершенный инструмент для обработки данных, нечто вроде языка программирования. Собственно говоря, такой инструмент — awk.

Утилита awk, или точнее GNU awk, в сравнении с sed, выводит обработку потоков данных на более высокий уровень. Благодаря awk в нашем распоряжении оказывается язык программирования, а не довольно скромный набор команд, отдаваемых редактору. С помощью языка программирования awk можно выполнять следующие действия:
- Объявлять переменные для хранения данных.
- Использовать арифметические и строковые операторы для работы с данными.
- Использовать структурные элементы и управляющие конструкции языка, такие, как оператор if-then и циклы, что позволяет реализовать сложные алгоритмы обработки данных.
- Создавать форматированные отчёты.
Если говорить лишь о возможности создавать форматированные отчёты, которые удобно читать и анализировать, то это оказывается очень кстати при работе с лог-файлами, которые могут содержать миллионы записей. Но awk — это намного больше, чем средство подготовки отчётов.
Особенности вызова awk
Схема вызова awk выглядит так:
Awk воспринимает поступающие к нему данные в виде набора записей. Записи представляют собой наборы полей. Упрощенно, если не учитывать возможности настройки awk и говорить о некоем вполне обычном тексте, строки которого разделены символами перевода строки, запись — это строка. Поле — это слово в строке.
Рассмотрим наиболее часто используемые ключи командной строки awk:
-F fs — позволяет указать символ-разделитель для полей в записи.
-f file — указывает имя файла, из которого нужно прочесть awk-скрипт.
-v var=value — позволяет объявить переменную и задать её значение по умолчанию, которое будет использовать awk.
-mf N — задаёт максимальное число полей для обработки в файле данных.
-mr N — задаёт максимальный размер записи в файле данных.
-W keyword — позволяет задать режим совместимости или уровень выдачи предупреждений awk.
Настоящая мощь awk скрывается в той части команды его вызова, которая помечена выше как program . Она указывает на файл awk-скрипта, написанный программистом и предназначенный для чтения данных, их обработки и вывода результатов.
Чтение awk-скриптов из командной строки
Скрипты awk, которые можно писать прямо в командной строке, оформляются в виде текстов команд, заключённых в фигурные скобки. Кроме того, так как awk предполагает, что скрипт представляет собой текстовую строку, его нужно заключить в одинарные кавычки:
Запустим эту команду… И ничего не произойдёт Дело тут в том, что мы, при вызове awk, не указали файл с данными. В подобной ситуации awk ожидает поступления данных из STDIN. Поэтому выполнение такой команды не приводит к немедленно наблюдаемым эффектам, но это не значит, что awk не работает — он ждёт входных данных из STDIN .
Если теперь ввести что-нибудь в консоль и нажать Enter , awk обработает введённые данные с помощью скрипта, заданного при его запуске. Awk обрабатывает текст из потока ввода построчно, этим он похож на sed. В нашем случае awk ничего не делает с данными, он лишь, в ответ на каждую новую полученную им строку, выводит на экран текст, заданный в команде print .

Первый запуск awk, вывод на экран заданного текста
Что бы мы ни ввели, результат в данном случае будет одним и тем же — вывод текста.
Для того, чтобы завершить работу awk, нужно передать ему символ конца файла (EOF, End-of-File). Сделать это можно, воспользовавшись сочетанием клавиш CTRL + D .
Неудивительно, если этот первый пример показался вам не особо впечатляющим. Однако, самое интересное — впереди.
Позиционные переменные, хранящие данные полей
Одна из основных функций awk заключается в возможности манипулировать данными в текстовых файлах. Делается это путём автоматического назначения переменной каждому элементу в строке. По умолчанию awk назначает следующие переменные каждому полю данных, обнаруженному им в записи:
- $0 — представляет всю строку текста (запись).
- $1 — первое поле.
- $2 — второе поле.
- $n — n-ное поле.
Поля выделяются из текста с использованием символа-разделителя. По умолчанию — это пробельные символы вроде пробела или символа табуляции.
Рассмотрим использование этих переменных на простом примере. А именно, обработаем файл, в котором содержится несколько строк (этот файл показан на рисунке ниже) с помощью такой команды:
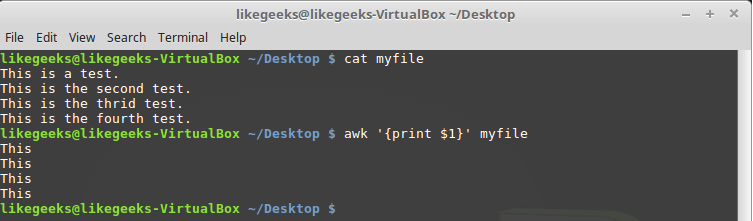
Вывод в консоль первого поля каждой строки
Здесь использована переменная $1 , которая позволяет получить доступ к первому полю каждой строки и вывести его на экран.
Иногда в некоторых файлах в качестве разделителей полей используется что-то, отличающееся от пробелов или символов табуляции. Выше мы упоминали ключ awk -F , который позволяет задать необходимый для обработки конкретного файла разделитель:
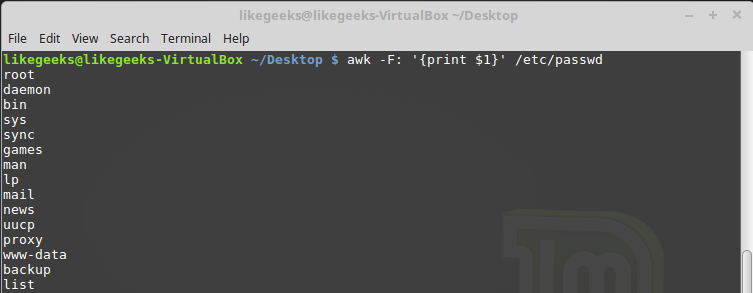
Указание символа-разделителя при вызове awk
Эта команда выводит первые элементы строк, содержащихся в файле /etc/passwd . Так как в этом файле в качестве разделителей используются двоеточия, именно этот символ был передан awk после ключа -F .
Использование нескольких команд
Вызов awk с одной командой обработки текста — подход очень ограниченный. Awk позволяет обрабатывать данные с использованием многострочных скриптов. Для того, чтобы передать awk многострочную команду при вызове его из консоли, нужно разделить её части точкой с запятой:

Вызов awk из командной строки с передачей ему многострочного скрипта
В данном примере первая команда записывает новое значение в переменную $4 , а вторая выводит на экран всю строку.
Чтение скрипта awk из файла
Awk позволяет хранить скрипты в файлах и ссылаться на них, используя ключ -f . Подготовим файл testfile , в который запишем следующее:
Вызовем awk, указав этот файл в качестве источника команд:
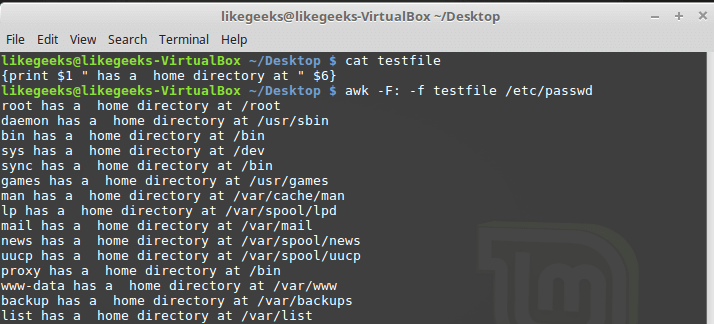
Вызов awk с указанием файла скрипта
Тут мы выводим из файла /etc/passwd имена пользователей, которые попадают в переменную $1 , и их домашние директории, которые попадают в $6 . Обратите внимание на то, что файл скрипта задают с помощью ключа -f , а разделитель полей, двоеточие в нашем случае, с помощью ключа -F .
В файле скрипта может содержаться множество команд, при этом каждую из них достаточно записывать с новой строки, ставить после каждой точку с запятой не требуется.
Вот как это может выглядеть:
Тут мы храним текст, используемый при выводе данных, полученных из каждой строки обрабатываемого файла, в переменной, и используем эту переменную в команде print . Если воспроизвести предыдущий пример, записав этот код в файл testfile , выведено будет то же самое.
Выполнение команд до начала обработки данных
Иногда нужно выполнить какие-то действия до того, как скрипт начнёт обработку записей из входного потока. Например — создать шапку отчёта или что-то подобное.
Для этого можно воспользоваться ключевым словом BEGIN . Команды, которые следуют за BEGIN , будут исполнены до начала обработки данных. В простейшем виде это выглядит так:
А вот — немного более сложный пример:
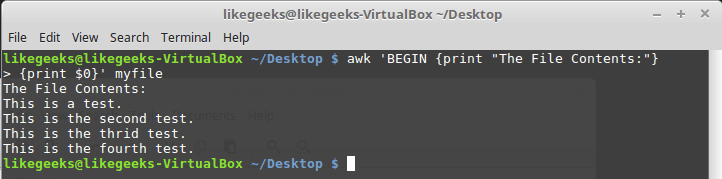
Выполнение команд до начала обработки данных
Сначала awk исполняет блок BEGIN , после чего выполняется обработка данных. Будьте внимательны с одинарными кавычками, используя подобные конструкции в командной строке. Обратите внимание на то, что и блок BEGIN , и команды обработки потока, являются в представлении awk одной строкой. Первая одинарная кавычка, ограничивающая эту строку, стоит перед BEGIN . Вторая — после закрывающей фигурной скобки команды обработки данных.
Выполнение команд после окончания обработки данных
Ключевое слово END позволяет задавать команды, которые надо выполнить после окончания обработки данных:
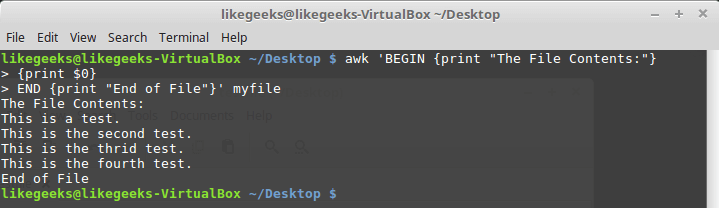
Результаты работы скрипта, в котором имеются блоки BEGIN и END
После завершения вывода содержимого файла, awk выполняет команды блока END . Это полезная возможность, с её помощью, например, можно сформировать подвал отчёта. Теперь напишем скрипт следующего содержания и сохраним его в файле myscript :
Тут, в блоке BEGIN , создаётся заголовок табличного отчёта. В этом же разделе мы указываем символ-разделитель. После окончания обработки файла, благодаря блоку END , система сообщит нам о том, что работа окончена.
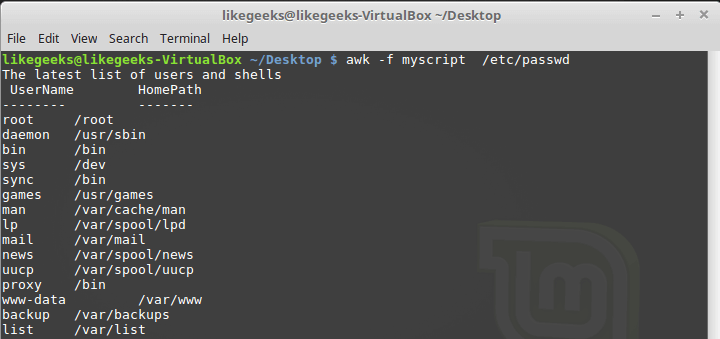
Обработка файла /etc/passwd с помощью awk-скрипта
Всё, о чём мы говорили выше — лишь малая часть возможностей awk. Продолжим освоение этого полезного инструмента.
Встроенные переменные: настройка процесса обработки данных
Утилита awk использует встроенные переменные, которые позволяют настраивать процесс обработки данных и дают доступ как к обрабатываемым данным, так и к некоторым сведениям о них.
Мы уже рассматривали позиционные переменные — $1 , $2 , $3 , которые позволяют извлекать значения полей, работали мы и с некоторыми другими переменными. На самом деле, их довольно много. Вот некоторые из наиболее часто используемых:
FIELDWIDTHS — разделённый пробелами список чисел, определяющий точную ширину каждого поля данных с учётом разделителей полей.
FS — уже знакомая вам переменная, позволяющая задавать символ-разделитель полей.
RS — переменная, которая позволяет задавать символ-разделитель записей.
OFS — разделитель полей на выводе awk-скрипта.
ORS — разделитель записей на выводе awk-скрипта.
По умолчанию переменная OFS настроена на использование пробела. Её можно установить так, как нужно для целей вывода данных:
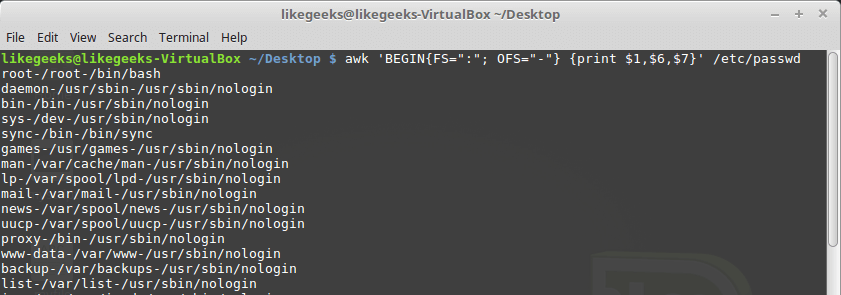
Установка разделителя полей выходного потока
Переменная FIELDWIDTHS позволяет читать записи без использования символа-разделителя полей.
В некоторых случаях, вместо использования разделителя полей, данные в пределах записей расположены в колонках постоянной ширины. В подобных случаях необходимо задать переменную FIELDWIDTHS таким образом, чтобы её содержимое соответствовало особенностям представления данных.
При установленной переменной FIELDWIDTHS awk будет игнорировать переменную FS и находить поля данных в соответствии со сведениями об их ширине, заданными в FIELDWIDTHS .
Предположим, имеется файл testfile , содержащий такие данные:
Известно, что внутренняя организация этих данных соответствует шаблону 3-5-2-5, то есть, первое поле имеет ширину 3 символа, второе — 5, и так далее. Вот скрипт, который позволит разобрать такие записи:
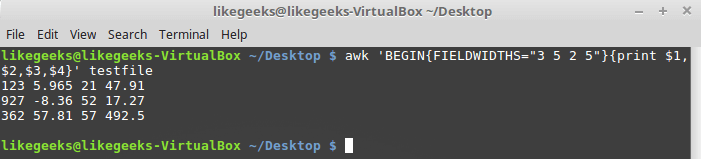
Использование переменной FIELDWIDTHS
Посмотрим на то, что выведет скрипт. Данные разобраны с учётом значения переменной FIELDWIDTHS , в результате числа и другие символы в строках разбиты в соответствии с заданной шириной полей.
Переменные RS и ORS задают порядок обработки записей. По умолчанию RS и ORS установлены на символ перевода строки. Это означает, что awk воспринимает каждую новую строку текста как новую запись и выводит каждую запись с новой строки.
Иногда случается так, что поля в потоке данных распределены по нескольким строкам. Например, пусть имеется такой файл с именем addresses :
Если попытаться прочесть эти данные при условии, что FS и RS установлены в значения по умолчанию, awk сочтёт каждую новую строку отдельной записью и выделит поля, опираясь на пробелы. Это не то, что нам в данном случае нужно.
Для того, чтобы решить эту проблему, в FS надо записать символ перевода строки. Это укажет awk на то, что каждая строка в потоке данных является отдельным полем.
Кроме того, в данном примере понадобится записать в переменную RS пустую строку. Обратите внимание на то, что в файле блоки данных о разных людях разделены пустой строкой. В результате awk будет считать пустые строки разделителями записей. Вот как всё это сделать:

Результаты настройки переменных RS и FS
Как видите, awk, благодаря таким настройкам переменных, воспринимает строки из файла как поля, а разделителями записей становятся пустые строки.
Встроенные переменные: сведения о данных и об окружении
ARGC — количество аргументов командной строки.
ARGV — массив с аргументами командной строки.
ARGIND — индекс текущего обрабатываемого файла в массиве ARGV .
ENVIRON — ассоциативный массив с переменными окружения и их значениями.
ERRNO — код системной ошибки, которая может возникнуть при чтении или закрытии входных файлов.
FILENAME — имя входного файла с данными.
FNR — номер текущей записи в файле данных.
IGNORECASE — если эта переменная установлена в ненулевое значение, при обработке игнорируется регистр символов.
NF — общее число полей данных в текущей записи.
NR — общее число обработанных записей.
Переменные ARGC и ARGV позволяют работать с аргументами командной строки. При этом скрипт, переданный awk, не попадает в массив аргументов ARGV . Напишем такой скрипт:
После его запуска можно узнать, что общее число аргументов командной строки — 2, а под индексом 1 в массиве ARGV записано имя обрабатываемого файла. В элементе массива с индексом 0 в данном случае будет «awk».

Работа с параметрами командной строки
Переменная ENVIRON представляет собой ассоциативный массив с переменными среды. Опробуем её:
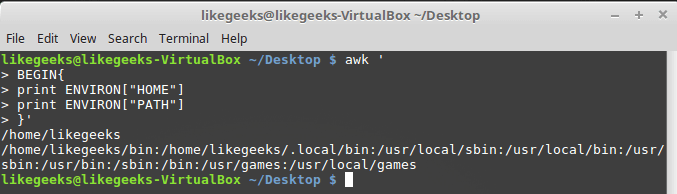
Работа с переменными среды
Переменные среды можно использовать и без обращения к ENVIRON . Сделать это, например, можно так:

Работа с переменными среды без использования ENVIRON
Переменная NF позволяет обращаться к последнему полю данных в записи, не зная его точной позиции:
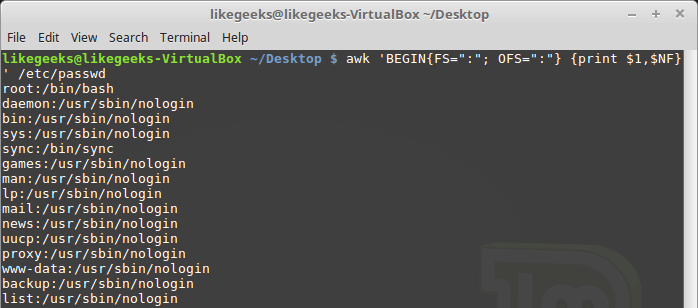
Пример использования переменной NF
Эта переменная содержит числовой индекс последнего поля данных в записи. Обратиться к данному полю можно, поместив перед NF знак $ .
Переменные FNR и NR , хотя и могут показаться похожими, на самом деле различаются. Так, переменная FNR хранит число записей, обработанных в текущем файле. Переменная NR хранит общее число обработанных записей. Рассмотрим пару примеров, передав awk один и тот же файл дважды:
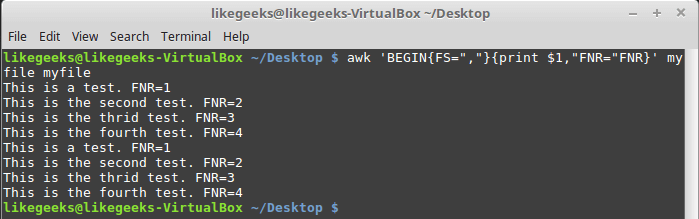
Исследование переменной FNR
Передача одного и того же файла дважды равносильна передаче двух разных файлов. Обратите внимание на то, что FNR сбрасывается в начале обработки каждого файла.
Взглянем теперь на то, как ведёт себя в подобной ситуации переменная NR :
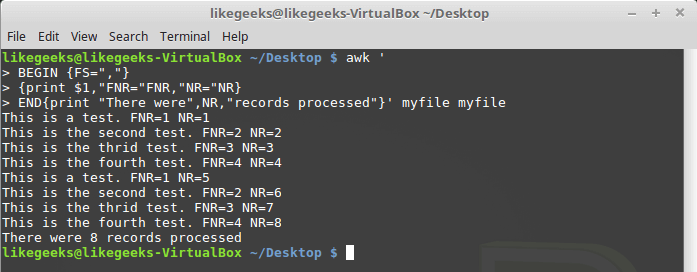
Различие переменных NR и FNR
Как видно, FNR , как и в предыдущем примере, сбрасывается в начале обработки каждого файла, а вот NR , при переходе к следующему файлу, сохраняет значение.
Пользовательские переменные
Как и любые другие языки программирования, awk позволяет программисту объявлять переменные. Имена переменных могут включать в себя буквы, цифры, символы подчёркивания. Однако, они не могут начинаться с цифры. Объявить переменную, присвоить ей значение и воспользоваться ей в коде можно так:
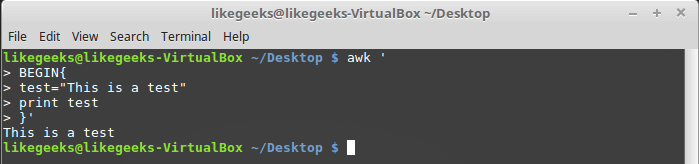
Работа с пользовательской переменной
Условный оператор
Awk поддерживает стандартный во многих языках программирования формат условного оператора if-then-else . Однострочный вариант оператора представляет собой ключевое слово if , за которым, в скобках, записывают проверяемое выражение, а затем — команду, которую нужно выполнить, если выражение истинно.
Например, есть такой файл с именем testfile :
Напишем скрипт, который выводит числа из этого файла, большие 20:

Однострочный оператор if
Если нужно выполнить в блоке if несколько операторов, их нужно заключить в фигурные скобки:

Выполнение нескольких команд в блоке if
Как уже было сказано, условный оператор awk может содержать блок else :
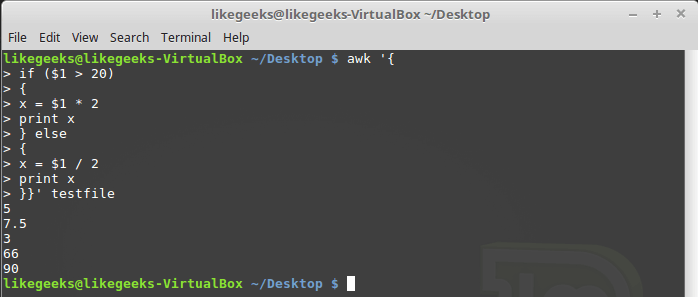
Условный оператор с блоком else
Ветвь else может быть частью однострочной записи условного оператора, включая в себя лишь одну строку с командой. В подобном случае после ветви if , сразу перед else , надо поставить точку с запятой:

Условный оператор, содержащий ветви if и else, записанный в одну строку
Цикл while
Цикл while позволяет перебирать наборы данных, проверяя условие, которое остановит цикл.
Вот файл myfile , обработку которого мы хотим организовать с помощью цикла:
Напишем такой скрипт:
Обработка данных в цикле while
Цикл while перебирает поля каждой записи, накапливая их сумму в переменной total и увеличивая в каждой итерации на 1 переменную-счётчик i . Когда i достигнет 4, условие на входе в цикл окажется ложным и цикл завершится, после чего будут выполнены остальные команды — подсчёт среднего значения для числовых полей текущей записи и вывод найденного значения.
В циклах while можно использовать команды break и continue . Первая позволяет досрочно завершить цикл и приступить к выполнению команд, расположенных после него. Вторая позволяет, не завершая до конца текущую итерацию, перейти к следующей.
Вот как работает команда break :
Команда break в цикле while
Цикл for
Циклы for используются во множестве языков программировании. Поддерживает их и awk. Решим задачу расчёта среднего значения числовых полей с использованием такого цикла:
Начальное значение переменной-счётчика и правило её изменения в каждой итерации, а также условие прекращения цикла, задаются в начале цикла, в круглых скобках. В итоге нам не нужно, в отличие от случая с циклом while , самостоятельно инкрементировать счётчик.
Форматированный вывод данных
Команда printf в awk позволяет выводить форматированные данные. Она даёт возможность настраивать внешний вид выводимых данных благодаря использованию шаблонов, в которых могут содержаться текстовые данные и спецификаторы форматирования.
Спецификатор форматирования — это специальный символ, который задаёт тип выводимых данных и то, как именно их нужно выводить. Awk использует спецификаторы форматирования как указатели мест вставки данных из переменных, передаваемых printf .
Первый спецификатор соответствует первой переменной, второй спецификатор — второй, и так далее.
Спецификаторы форматирования записывают в таком виде:
Вот некоторые из них:
c — воспринимает переданное ему число как код ASCII-символа и выводит этот символ.
d — выводит десятичное целое число.
i — то же самое, что и d .
e — выводит число в экспоненциальной форме.
f — выводит число с плавающей запятой.
g — выводит число либо в экспоненциальной записи, либо в формате с плавающей запятой, в зависимости от того, как получается короче.
o — выводит восьмеричное представление числа.
s — выводит текстовую строку.
Вот как форматировать выводимые данные с помощью printf :
Форматирование выходных данных с помощью printf
Тут, в качестве примера, мы выводим число в экспоненциальной записи. Полагаем, этого достаточно для того, чтобы вы поняли основную идею, на которой построена работа с printf .
Встроенные математические функции
cos(x) — косинус x ( x выражено в радианах).
sin(x) — синус x .
exp(x) — экспоненциальная функция.
int(x) — возвращает целую часть аргумента.
log(x) — натуральный логарифм.
rand() — возвращает случайное число с плавающей запятой в диапазоне 0 — 1.
sqrt(x) — квадратный корень из x .
Вот как пользоваться этими функциями:
Работа с математическими функциями
Строковые функции
Awk поддерживает множество строковых функций. Все они устроены более или менее одинаково. Вот, например, функция toupper :
Использование строковой функции toupper
Эта функция преобразует символы, хранящиеся в переданной ей строковой переменной, к верхнему регистру.
Пользовательские функции
При необходимости вы можете создавать собственные функции awk. Такие функции можно использовать так же, как встроенные:
Использование собственной функции
В примере используется заданная нами функция myprint , которая выводит данные.
Итоги
Сегодня мы разобрали основы awk. Это мощнейший инструмент обработки данных, масштабы которого сопоставимы с отдельным языком программирования.
Вы не могли не заметить, что многое из того, о чём мы говорим, не так уж и сложно для понимания, а зная основы, уже можно что-то автоматизировать, но если копнуть поглубже, вникнуть в документацию… Вот, например, The GNU Awk User’s Guide. В этом руководстве впечатляет уже одно то, что оно ведёт свою историю с 1989-го (первая версия awk, кстати, появилась в 1977-м). Однако, сейчас вы знаете об awk достаточно для того, чтобы не потеряться в официальной документации и познакомиться с ним настолько близко, насколько вам того хочется. В следующий раз, кстати, мы поговорим о регулярных выражениях. Без них невозможно заниматься серьёзной обработкой текстов в bash-скриптах с применением sed и awk.
Уважаемые читатели! Уверены, многие из вас периодически пользуются awk. Расскажите, как он помогает вам в работе?



