Элементарный Bash скрипт для резервного копирования данных
Привет хабралюди, сейчас я расскажу как можно немного автоматизировать рутиную работу по подготовке бэкапов.
В данном случае, мы не будем использовать мощные программы, или даже целые системы для резервного копирования данных, ограничимся самым доступным что у нас есть. А именно — Bash скриптом.
Что должен выполнять наш скрипт?
Бэкапить веб проект, а именно:
— Делать резервную копию базы MySQL.
— Делать резервную копию файлов.
— Структурировать это.
И так, вот наш скрипт:
#!/bin/bash
PROJNAME= #Имя проекта
CHARSET= #Кодировка базы данных (utf8)
DBNAME= #Имя базы данных для резервного копирования
DBFILENAME= #Имя дампа базы данных
ARFILENAME= #Имя архива с файлами
HOST= #Хост MySQL
USER= #Имя пользователя базы данных
PASSWD= #Пароль от базы данных
DATADIR= #Путь к каталогу где будут храниться резервные копии
SRCFILES= #Путь к каталогу файлов для архивирования
PREFIX=`date +%F` #Префикс по дате для структурирования резервных копий
#start backup
echo «[———————————[`date +%F—%H-%M`]———————————]»
echo «[———-][`date +%F—%H-%M`] Run the backup script. »
mkdir $DATADIR/$PREFIX 2> /dev/null
echo «[++———][`date +%F—%H-%M`] Generate a database backup. »
#MySQL dump
mysqldump —user=$USER —host=$HOST —password=$PASSWD —default-character-set=$CHARSET $DBNAME > $DATADIR/$PREFIX/$DBFILENAME-`date +%F—%H-%M`.sql
if [[ $? -gt 0 ]];then
echo «[++———][`date +%F—%H-%M`] Aborted. Generate database backup failed.»
exit 1
fi
echo «[++++——][`date +%F—%H-%M`] Backup database [$DBNAME] — successfull.»
echo «[++++++—-][`date +%F—%H-%M`] Copy the source code project [$PROJNAME]. »
#Src dump
tar -czpf $DATADIR/$PREFIX/$ARFILENAME-`date +%F—%H-%M`.tar.gz $SRCFILES 2> /dev/null
if [[ $? -gt 0 ]];then
echo «[++++++—-][`date +%F—%H-%M`] Aborted. Copying the source code failed.»
exit 1
fi
echo «[++++++++—][`date +%F—%H-%M`] Copy the source code project [$PROJNAME] successfull.»
echo «[+++++++++-][`date +%F—%H-%M`] Stat datadir space (USED): `du -h $DATADIR | tail -n1`»
echo «[+++++++++-][`date +%F—%H-%M`] Free HDD space: `df -h /home|tail -n1|awk ‘
echo «[++++++++++][`date +%F—%H-%M`] All operations completed successfully!»
exit 0
Запускать можно парой способов:
— Простой запуск: ./backup.sh
— Запуск + запись в лог: ./backup.sh | tee backup.log
— а еще его можно в cron запихать: 00 20 * * 7 root sh /home/bond/backup.sh | tee /home/bond/backup/backup.log
После успешного завершения скрипта, мы увидим следующее:
$ sudo sh backup.sh
[———————————[2009-02-14—12-28]———————————]
[———-][2009-02-14—12-28] Run the backup script.
[++———][2009-02-14—12-28] Generate a database backup.
[++++——][2009-02-14—12-29] Backup database [images] — successfull.
[++++++—-][2009-02-14—12-29] Copy the source code project [itmages].
[++++++++—][2009-02-14—12-29] Copy the source code project [itmages] — successfull.
[+++++++++-][2009-02-14—12-29] Stat datadir space (USED): 1,3G /home/bond/backup
[+++++++++-][2009-02-14—12-29] Free HDD space: 49G
[++++++++++][2009-02-14—12-29] All operations completed successfully!
bond@serv:
В итоге наши бэкапы складываются в каталог который вы указали, + резервные копии лежат в каталогах именованых по дате.
Источник
Cron в Ubuntu. + bash-cкрипт резервного копирования
Иногда системным администраторам, программистам, web-дизайнерам и много кому ещё нужно запускать одни и те же команды или скрипт с некоторой периодичностью. Для таких целей используется специальная утилита Cron , встроенная во все дистрибутивы Unix. Пользоваться Cron’ом необычайно легко. Сейчас расскажу как.
Для начала создадим какой-нибудь простой bash-скрипт, например скрип резервного копирования и архивирования конфигурационных файлов, в моём случае конфигурационных файлов Apache2 и ftp-сервера.
mkdir / home / user / bash-scripts / backup
cp / etc / apache2 / apache2.conf / home / user / bash-scripts / backup / apache2.conf-backup
cp / etc / apache2 / sites-available / site / home / user / bash-scripts / backup / site-backup
cp / etc / proftpd / proftpd.conf / home / user / bash-scripts / backup / proftpd.conf-backup
tar cvvzf «/home/user/bash-scripts/backup-`date +%F-%X`.tar.gz» / home / user / bash-scripts / backup /
rm -r / home / user / bash-scripts / backup
Этот скрипт копирует конфигурационные файлы и архивирует их в папку, в названии которой присутствует дата и время сохранения. Назовём его ‘ backup-script ‘ а лежать он у нас будет в домашнем каталоге (/home/user/). Теперь нам надо чтобы этот скрипт запускался, ну допустим, каждые 10 минут. Для этого введём команду
Этой командой мы открываем для редактирования файл crontab для данного пользователя, в моём случае это user. Если нашему скрипту нужны права супер пользователя, то нужно редактировать crontab суперпользователя. Делается это командой
sudo crontab -u root -e
Ну и если заменить root а логин другого пользователя, мы будем редактировать его crontab .
Сразу напишу, чтобы посмотреть файл crontab введите команду.
Файл crontab имеет следующую структуру:
поле1 поле2 поле3 поле4 поле5 команда
Значения первых пяти полей:
1.минуты— число от 0 до 59
2.часы — число от 0 до 23
3.день месяца — число от 1 до 31
4.номер месяца в году — число от 1 до 12
5.день недели — число от 0 до 7 (0-Вс,1-Пн,2-Вт,3-Ср,4-Чт,5-Пт,6-Сб,7-Вс)
Все поля обязательны для заполнения. Не сложно догадаться что первые 5 отвечают за определения периодичности запуска команды, а последняя собственно команда или полный путь к скрипту. Таким образом, чтобы запустить наш скрипт резервного копирования раз в 10 минут надо вписать следующую строчку.
*/ 10 * * * * / home / user / backup-script
* — значит все возможные варианты, / служит для определения периодичности выполнения задания. Если нужно будет выполнять скрипт раз в 3 часа впишите в значения часы */3 а в минуты просто *, если раз в сутки — впишите */23 , ну почти сутки. Так же в одно поле можно вводить несколько значений через запятую, например если хотите выполнять скрипт 1ого, 5ого, и 25ог числа каждого месяца введите 1,5,25 вместо третей звёздочки. Ещё можно вводить промежуток времени, если ,допустим, в часы ввести 12-17 то скрипт будет выполняться с 12 до 17 включительно раз в час.
Ну вот и всё, в заключение пару примеров:
0 */ 3 * * 2,5 / home / user / backup-script
#Каждые три часа только по вторникам и пятницам
15 */ 3 * * * / home / user / backup-script
#Каждые три часа в 15 минут
45 15 * * 1 / home / user / backup-script
#По понедельникам в 15:45
13 13 13 * 5 / home / user / backup-script
#в пяnницу 13 числа в 13 часов 13 минут
30 00 * * 0 / home / user / backup-script
#Раз в неделя по воскресеньем в 00:30
Источник
bash: Бэкап без лишнего ПО
Бэкап важной информации — каждый системный администратор сталкивается с такой задачей. Задача казалось бы тривиальная и у многих читателей интереса не вызовет. Но, например, мне бы такая статья в определенный момент помогла бы весьма сильно, поэтому считаю, что этой статье быть.
Задача: Бэкап данных в локальную директорию и на отдельный сервер, с использованием минимума стороннего ПО, логированием и оповещением администратора в jabber при сбоях. Все основные функции большинства ПО для автоматического бэкапа, но без установки оного, а следовательно без его багов (что, собственно, и привело к подобной идее).
А теперь к делу.
Для начала создадим и откроем скрипт
Теперь в скрипте добавим строку
Объявим некоторые переменные.
TN — TASKNAME — имя задания.Используется для вывода в лог и определения названия файла.
Так как заданий несколько (ежемесячное, еженедельное, ежедневное) и писать на каждый случай скрипт было лень, я создал универсальный, в котором надо просто раскомментить нужные строки. Наименование заданий писать надо без пробелов, желательно в латинице, если не хотите проблем с кодировкой и неправильными параметрами команд.
OF — Output File — имя выходного файла. Получается из переменной TN, то есть имени задания.
Объявляем переменную с путем к файлу лога, и далее все сообщения об ошибках и остальном будем выводить в лог.
Сделаем запись в лог о начале бэкапа (дата, время, имя задания)
Есть проблема в том что если указывать в параметрах команд (напр. tar) имена каталогов с пробелами, скрипт срабатывает с ошибкой. Решение найдено на просторах интернета — операционная система linux использует пробел в качестве стандартного разделителя параметров команды. Переопределим стандартный разделитель (хранится в переменной $IFS) отличным от пробела, например \n – знаком переноса строки.
Запоминаем старое значение стандартного разделителя
Заменяем стандартный разделитель своим
SRCD — SouRCe Directory — каталог с данными для бэкапа
Теперь можно перечислять несколько каталогов, разделителем будет перенос строк как мы сами указали строкой выше
TGTD — TarGeT Directory — каталог в который будут складываться бэкапы
Естественно мы понимаем что хранить важные бэкапы только на источнике как минимум легкомысленно. Поэтому оставим копию и на удаленном ресурсе, который будем отдельно монтировать с помощью mount и fstab. Сразу поясню почему я использовал mount и fstab, а не один mount — я монтирую этот каталог и в других своих скриптах, а как сказал один из знакомых программистов — хороший программист не будет писать один и тот же код дважды (как-то так, дословно не помню, но надеюсь смысл донес).
Сам процесс архивирования в варианте «Создать новый архив»
и в варианте «Обновить файлы в старом архиве»
Во втором случае лучше вместо $OF использовать конктретное имя файла потому что у меня например ежедневно апдэйтится еженедельный архив, а их $TN (имена задания) не совпадают, соответственно и $OF.
В переменной «?» ханится статус выполнения последней команды. Сохраним его, чтобы воспользоваться позже.
Возвращаем стандартный разделитель к исходному значению
Теперь добавим условие — если процесс упаковки в архив tar закончился с ошибкой, отправляем сообщение админу, удаляем неудачный файл бекапа. Иначе продолжаем дальше — монтируем сетевую шару и кидаем в нее копию архива. После каждой операции проверяем результат выполнения, пишем логи, и либо продолжаем, либо извещаем админа и прерываем процедуру.
В процессе мы копируем архив из локального хванилища в удаленное. Естественно, проверяем, что каждая операция успешно завершена, и пишем все в логи.
Для отсылки сообщения администратору я использую XMPP сообщение, так как в организации поднят Jabber-сервер, и я больше люблю получить быстрое сообщение о сбое, чем лезть в почту, вбивая пароли, тыкая на ссылки, и ожидая пока браузер мне все отобразит. В любом случае никто не мешает вам использовать sendmail вместо sendxmpp.
Файл /usr/local/etc/XMPP_settings следующего содержания:
В файле fstab строка описывающая подключение шары Windows
Теперь осталось только добавить задание в cron. Это можно сделать с помощью файла /etc/crontab, но я, в силу привычки к GUI, оставшейся в наследство от виндовс, пользую вэб-интерфейсы для таких случаев. Команда должна выполняться с правами рута, то бишь, к примеру, sudo bash backup_script. Добавляя команду в cron можно определить что она будет сразу выполняться от имени root`а
В ходе обсуждений затронули проблему разрастания логов. Пошел по простейшему (на мой взгляд) пути: будем хранить только последние N строк лога, например 300. В скрипт добавятся две строки, в которых мы сохраним последние 300 строк лога во временный файл, потом затрем им лог
Источник
Быстрая настройка резервного копирования под Linux и не только (UrBackup)

Примерно год назад у меня возникла «острая» необходимость перевести систему резервного копирования данных в корпоративной сети на бесплатные рельсы. До этого использовался платный продукт от Symantec, по нему, конечно, много нареканий, но он работал, хоть и не всегда справлялся. Как обычно, все надо было сделать «вчера», и я приступил к поиску вариантов.
Для начала начал искать решение для резервного копирования файлов, очевидным решением было простая настройка скриптов на Linux по cron, но это не очень удобное и надежное решение, если серверов более одного(а у меня их около 50-ти) и структура достаточно динамична. Тем более если инфраструктура смешанная, Linux + Windows. Хотелось что-нибудь простое в дальнейшем обслуживании и извлечении самих копий, например, переложить восстановление пользовательских файлов на группу поддержки. Порывшись пару часов в интернете, я наткнулся на интересный проект UrBackup, он удовлетворял всем моим условиям.
Как операционную систему я выбрал CentOS 6 в конфигурации minimal, взять можно тут. Подробно на установке и первичной настройке останавливаться не будут, т.к. манулов по этой процедуре уже достаточно на Хабре. Перейдем к установке виновника топика UrBackup.
Предыдущие версии UrBackup приходилось собирать из исходников, но слава разработчикам, для последних версий появились репозитории для большинства популярных систем. Хотя собрать из исходников проблем не составляло, репозиторий сильно упрощает жизнь, особенно при обновлениях.
Тут мы подключаем репозиторий и устанавливаем собственно сервер. Далее, чтобы мы могли подключится к серверу из вне, нам необходимо поправить iptables:
Так же для серверов внутри сети отключаем selinux:
Отключаем selinux без перезагрузки:
Устанавливаем сервис в автозагрузку и запускаем:
Готово. Можно подключаться и настраивать.
Заходим по адресу. При желании выбираем язык и идем в настройки:
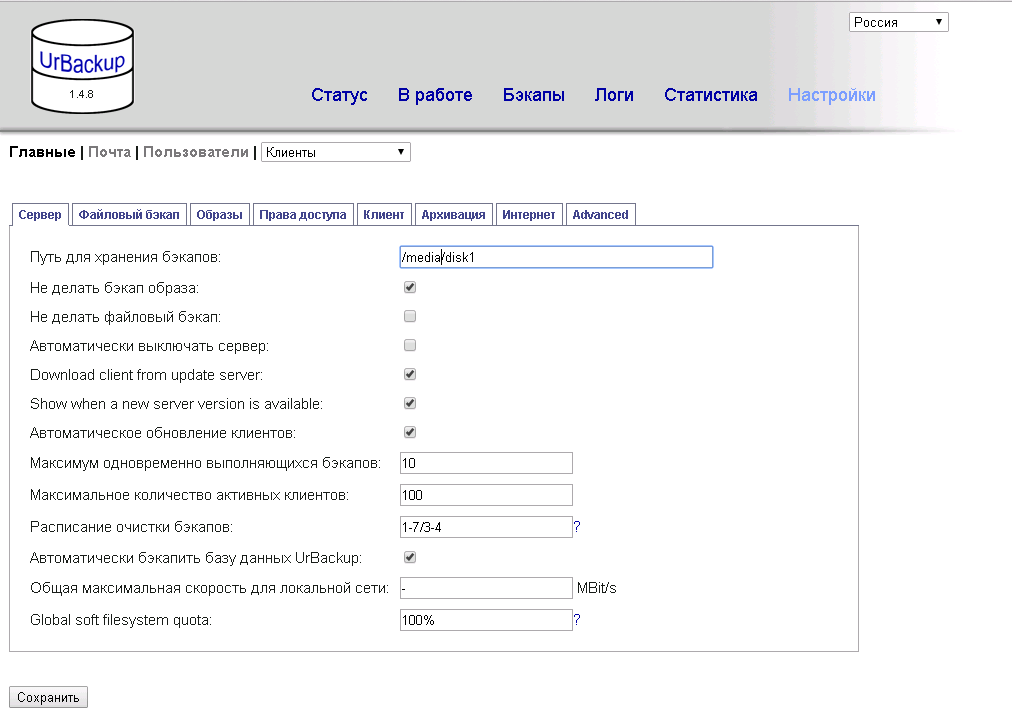
Тут для первичной настройки нам необходимо указать только путь для хранения бекапов. Не забываем нажать кнопку «сохранить» и мы можем переходить к настройке клиентов.
Для начала нам необходимо установить клиент на сервер, который мы хотим копировать. Клиент для Windows систем можно скачать с сайта разработчиков, но так как мы в данный момент рассматриваем linux-системы, рассмотрим установку на тот же CentOS 6:
Добавляем правила в iptables:
Не забываем отключить selinux, если, конечно, в нем нет необходимости. И можно добавлять клиента на сервер. Возвращаемся на сервер. Идем в раздел «статус»:

Вбиваем в поле «Имя/IP» IP-адрес сервера, с которого мы хотим бекапить данные, и нажимаем добавить. Ждем пару минут, пока клиент появится в списке.
Для клиента с GUI этого достаточно, настройки папок для копирования можно сделать прямо на клиенте, резервное копирование начнется по расписанию, но у нас минимальный Linux и мы ставили клиент без GUI, его, как впрочем и полноценного клиента, можно настраивать прямо с сервера.
Идем в настройки:

Выбираем наш сервер из списка и настраиваем «каталоги по умолчанию для бекапа».
Готово. Сервер настроен и работает. Во время работы мы видим нечто подобное:

Сервер работает на удивление быстро и очень компактно использует место на диске, используя подобие дедубликации на основе симлинков.
Это минимальная настройка сервера, при желании можно настроить авторизацию, архивацию, создание образов систем (Windows), резервное копирование через интернет и т.д. В дальнейших статьях планирую рассказать, как на этот же сервер настроить резервное копирование MSSQL и Exchange, если это, конечно, будет интересно читателям.
Источник



