- База знаний wiki
- Содержание
- Проверка состояния жестких дисков в Linux
- Задача:
- Решение:
- Проверка состояния накопителей в Linux
- Проверка накопителей средствами badblocks
- Проверка состояния накопителей при помощи S.M.A.R.T.
- Проверка состояния накопителей при помощи GSmartControl
- Linux: проверка диска
- Что такое битые блоки и почему они появляются
- Проверка диска Linux
- Badblocks
- GParted
- Smartmontools
- Safecopy
- Что делать, если обнаружена ошибка в системной программе Ubuntu
- Заключение
База знаний wiki
Продукты
Статьи
Содержание
Проверка состояния жестких дисков в Linux
Слова для поиска: проверка дисков, hdparm, badblocks, smart, smartctl, iostat, mdstat
Задача:
Проверить состояние жестких дисков на выделенном сервере, наличие сбойных блоков на HDD, анализ S.M.A.R.T
Решение:
В этой статье будут рассмотрены способы проверки и диагностики HDD в Linux. Полученная информация поможет проанализировать состояние жестких дисков, и, если это необходимо, заменить носитель до того, как он вышел из строя неожиданно и в самый не подходящий для этого момент.
Задуматься о состоянии HDD следует по некоторым признакам поведения системы в целом: резко выросла общая нагрузка на дисковую подсистему, упала скорость чтения/записи, другие проблемы косвенно указывающие что с HDD что-то не то.
Ниже я приведу основные команды, выполнять их необходимо из-под учётной записи root
Чтобы получить список подключенных HDD в систему, выполнить:
Мы получим листинг всех подключенных накопителей, их размер и имена устройств в системе.
Для того, чтобы посмотреть какие устройства и куда смонтированы, выполнить:
Узнать сколько на каждом из смонтированном носителе занято пространства, выполнить:
Если мы используем софтовых RAID, его состояние мы можем проверить следующей командой:
Если всё в порядке, то мы увидим что-то подобное:
Из вывода видно состояние raid (active), название устройства raid (md0) и какие устройства в него включены (sdb1[0] sdc1[1]), какой именно raid собран (raid1), в нём два диска и они оба работают в raid ([2/2] [UU])
Смотрим скорость чтения с накопителя
Где /dev/sdX — имя устройства которое необходимо проверить.
Полезной программой для анализа нагрузки на диски является iostat, входящей в пакет sysstat Ставим:
Теперь смотрим вывод iostat по всем дискам в системе:
С интервалом 10 секунд:
Или по определённому накопителю:
Полученные данные покажут нам нагрузку на устройства хранения, статистику по вводу/выводу, процент утилизации накопителя.
Переходим непосредственно к проверке накопителей. Проверка на наличие сбойных блоков осуществляется при помощи программы badblocks. Для проверки жесткого диска на бэдблоки, выполнить:
Где /dev/sdX — имя устройства которое необходимо проверить. Если программа обнаружит наличие сбойных блоков, она выведет их количество на консоль. Выполнение данной операции может занять продолжительное время (до нескольких часов) и желательно её выполнение на размонтированной файловой системе, либо в режиме read-only.
Для того, чтобы записать сбойные блоки, выполняем:
Где /tmp/badblock — файл куда программа запишет номера сбойных блоков.
Теперь при помощи программы e2fsck мы можем пометить сбойные блоки и они будут в дальнейшем игнорироваться системой. ВНИМАНИЕ! Данная операция должна проводиться на размонтированной файловой системе, либо в режиме read-only! Проверенное устройство и устройство на накотором будут помечаться сбойные блоки должно быть одно и тоже!
Если были обнаружены сбойные блоки на диске, есть тенденция появления новых бэдблоков, необходимо задуматься о скорейшем копировании данных и замене данного носителя. Приведённые выше команды помогут выявить сбойные блоки и пометить их как таковые, но не спасут «сыпящийся» диск.
Также в своём инструментарии полезно использовать данные полученные из S.M.A.R.T. дисков.
Ставим пакет smartmontools
Получаем данные S.M.A.R.T. жесткого диска:
Где /dev/sdX — имя устройства которое необходимо проверить.
Вы получите вывод атрибутов S.M.A.R.T., значение каждого из которых хорошо описаны в Википедии
Для сохранности данных настоятельно рекомендуем делать backup (резервное копирование). Это поможет в кратчайшие сроки восстановить необходимые данные и настройки в форс-мажорных обстоятельствах.
Источник
Проверка состояния накопителей в Linux
Обновлено Ноя 6, 2019
Проверка и анализ состояния накопителей в Linux с помощью консольных утилит badblocks, smartmontools и графической программы GSmartControl
- Встроенные жёсткие диски;
- Внешние жёсткие диски;
- USB-флеш-накопители (сленг. флешка);
- Карт памяти.
Проверка накопителей средствами badblocks
Утилита badblocks установлена по-умолчанию.
Для просмотра подключенных накопителей и разделов на них, введите команду:

Для проверки накопителя на битые сектора, выполнить команду:
-v – отображение подробной информации во время работы программы
/dev/sdX – имя устройства, которое необходимо проверить
> badblocks.txt – запись результатов проверки (сохраняется в домашней папке: /home/user)

При наличии битых секторов, можно воспользоваться утилитами: e2fsck (ext2, ext3, ext4), fsck (отличные от ext) для игнорирования системой битых секторов:
Проверка состояния накопителей при помощи S.M.A.R.T.
Установка:
Для проверки накопителя на битые сектора при помощи S.M.A.R.T., выполнить команду:
/dev/sdX – имя устройства, которое необходимо проверить
Проверка состояния накопителей при помощи GSmartControl
Чтобы установить самую свежую стабильную версию GSmartControl в Ubuntu, можно воспользоваться PPA репозиторием. Для этого выполните последовательно в терминале команды:
sudo sh -c “echo ‘deb http://download.opensuse.org/repositories/home:/alex_sh/Ubuntu_16.04/ /’ > /etc/apt/sources.list.d/gsmartcontrol.list”
wget -nv http://download.opensuse.org/repositories/home:alex_sh/Ubuntu_16.04/Release.key -O Release.key sudo apt-key add – Работа с программой:
Выбираем диск и кликаем левой клавишей мыши 2 раза или выбираем диск, потом идём в меню, там жмём на Device, далее жмём View details, далее жмём на вкладку Attributes:
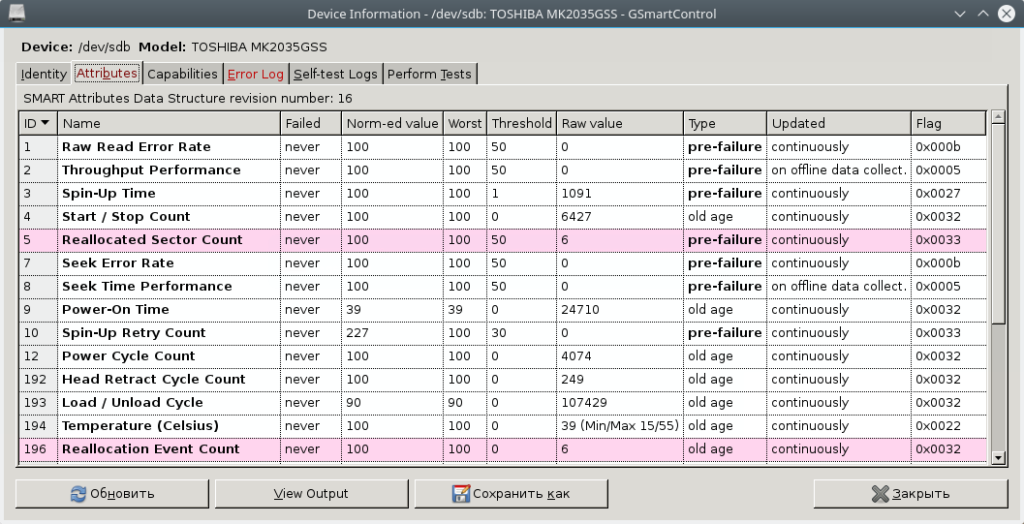
Анализ параметров, выводимых программой
Каждый атрибут имеет величину Value. Value Изменяется в диапазоне от 0 до 255 задается производителем). Низкое значение говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше значение Value атрибута, тем лучше. Raw Value – это значение атрибута во внутреннем формате производителя значение малоинформативно для всех кроме сервисманов. Threshold – минимальное возможное значение атрибута, при котором гарантируется безотказная работа накопителя. SMART. Смотрим состояние жесткого диска. Если VALUE стало меньше THRESH – Атрибут считается failed и отображается в столбце WHEN_FAILED. При значении атрибута меньше Threshold очень вероятен сбой в работе или полный отказ. WORST- минимальное нормализованное значение. Это минимальное значение, которое достигалось с момента включения SMART на диске. Атрибуты бывают критически важными (Pre-fail) и некритически важными (Old_age). Выход критически важного параметра за пределы Threshold фактический означает выход диска из строя, выход за пределы допустимых значений не критически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность.
Критичные атрибуты
Raw Read Error Rate – частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time – время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе. Не ухудшающееся не максимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например просадка по вольтажу блока питания.
Spin Up Retry Count – число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно не максимальное Value) свидетельствует о проблемах в механической части накопителя.
Seek Error Rate – частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count – число операций переназначения секторов. SMART в современных дисках способен произвести анализ сектора на стабильность работы “на лету” и в случае признания его сбойным, произвести его переназначение.
Некритичные атрибуты:
Start/Stop Count – полное число запусков/остановов шпинделя. Гарантировано мотор диска способен перенести лишь определенное число включений/выключений. Это значение выбирается в качестве Treshold. Первые модели дисков со скоростью вращения 7200 оборотов/мин имели ненадежный двигатель, могли перенести лишь небольшое их число и быстро выходили из строя.
Power On Hours – число часов проведенных во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF). Обычно величина MTBF огромна, и маловероятно, что этот параметр достигнет критического порога. Но даже в этом случае выход из строя диска совершенно не обязателен.
Drive Power Cycle Count – количество полных циклов включения-выключения диска. По этому и предыдущему атрибуту можно оценить, например, сколько использовался диск до покупки.
Temperatue – Здесь хранятся показания встроенного термодатчика. Температура имеет огромное влияние на срок службы диска (даже если она находится в допустимых пределах). Вернее имеет влияние не на срок службы диска а на частоту возникновения некоторых типов ошибок, которые влияют на срок службы.
Current Pending Sector Count – Число секторов, являющихся кандидатами на замену. Они не были ещё определены как плохие, но считывание их отличается от чтения стабильного сектора, так называемые подозрительные или нестабильные сектора.
Uncorrectable Sector Count – число ошибок при обращении к сектору, которые не были скорректированы. Возможными причинами возникновения могут быть сбои механики или порча поверхности.
UDMA CRC Error Rate – число ошибок, возникающих при передаче данных по внешнему интерфейсу. Могут быть вызваны некачественными кабелями, нештатными режимами работы.
Write Error Rate – показывает частоту ошибок происходящих при записи на диск. Может служить показателем качества поверхности и механики накопителя.
Источник
Linux: проверка диска
Компьютер представляет собой устройство, работа которого основана на взаимодействии множества компонентов. Со временем они могут вызывать сбои в работе. Одной из частых причин неполноценной работы машины становятся битые сектора на диске, поэтому периодически его нужно тестировать. Linux предоставляет для этого все возможности.
Что такое битые блоки и почему они появляются
Блок (сектор) – это маленькая ячейка диска, на которой в виде битов (0 и 1) хранится информация. Когда системе не удается записать очередной бит в ячейку, говорят о битом секторе. Причин возникновения таких блоков может быть несколько:
- брак при производстве;
- отключение питания в процессе записи информации;
- физический износ диска.
Изначально практически на всех носителях имеются нарушения. Со временем их количество может увеличиваться, что говорит о скором выходе устройства из строя. В Linux тестировать диск на ошибки возможно несколькими способами.

Проверка диска Linux
На ядре Linux работает несколько ОС, среди которых Ubuntu и Debian. Процедура проверки диска универсальная и подходит для каждой из них. О том, что носитель пора тестировать, стоит задуматься, когда на дисковую систему оказывается большая нагрузка, скорость работы с носителем (запись/чтение) значительно уменьшилась, либо эти процедуры и вовсе вызывают ошибки.
Многие знакомы с программой на Windows – Victoria HDD. Разработчики позаботились о написании ее аналогов для Linux.
Badblocks
Badblocks – дисковая утилита, имеющаяся в Ubuntu и других дистрибутивах Linux по умолчанию. Программа позволяет тестировать как жесткий диск, так и внешние накопители.
Перед тем, как тестировать диск в Linux следует проверить, какие накопители подключены к системе, с помощью утилиты fdisk-l. Она также покажет имеющиеся на них разделы.

Теперь можно приступать к непосредственному тестированию на битые сектора. Работа Badblocks организовывается следующим образом:
В записи используются следующие команды и операнды:·
- -v – выводит подробный отчет о проведенной проверке;·
- /dev/sdk 1 – проверяемый раздел;·
- bsector.txt – запись результатов в текстовый файл.

Если при проверке диска нашлись битые блоки, нужно запустить утилиту fsck, либо e2fsck, в зависимости от используемой файловой системы. Они ограничат запись информации в нерабочие сектора. В случае файловых систем ext2, ext3 или ext4 выполняется следующая команда:
В противном случае:
Параметр -l указывает программе, что битые блоки перечислены в файле bsector.txt, и исключать нужно именно их.
GParted
Утилита проверяет файловую систему Linux, не прибегая к текстовому интерфейсу.
Инструмент изначально не содержится в дистрибутивах операционной системы, поэтому ее необходимо установить, выполнив команду:
В главном окне приложения отображаются доступные диски. О том, что носитель пора тестировать, понятно по восклицательному знаку, расположенному рядом с его именем. Запуск проверки производится путем щелчка по пункту «Проверка на ошибки» в подменю «Раздел», расположенном на панели сверху. Предварительно выбирается нужный диск. По завершении сканирования утилита выведет результат.

Проверка HDD и других запоминающих устройств приложением GParted доступна для пользователей ОС Ubuntu, FreeBSD, Centos, Debian и других и других дистрибутивов, работающих на ядре Linux.
Smartmontools
Инструмент позволяет тестировать файловую систему с большей надежностью. В современных жестких дисках имеется встроенный модуль самоконтроля S. M. A. R. T., который анализирует данные накопителя и помогает определить неисправность на первоначальной стадии. Smartmontools предназначен для работы с этим модулем.
Запуск установки производится через терминал:
- apt install smartmontools – для Ubuntu/Debian;
- yum install smartmontools – для CentOS.
Для просмотра информации о состоянии жесткого диска, вводится строка:

Проверка на ошибки занимает различное время, в зависимости от объема диска. По окончании программа выведет результат о наличии битых секторов, либо их отсутствии.
Утилита имеет и другие параметры: -a, —all, -x, —xall. Для получения дополнительной информации вызывается справка:

Safecopy
Когда возникает потребность тестировать винчестер в Linux, стоит быть готовым к любому результату.
Приложение Safecopy копирует данные с поврежденного устройства на рабочее. Источником могут быть как жесткие диски, так и съемные носители. Этот инструмент игнорирует ошибки ввода/вывода, чтения, битые блоки, продолжая беспрерывно работать. Скорость выполнения максимально возможная, которую обеспечивает компьютер.

Для установки Safecopy на Linux в терминал вводится строка:
Сканирование запускается командой:
Здесь первый путь обозначает поврежденный диск, второй – директорию, куда сохранятся файлы.
Программа способна создать образ файловой системы нестабильно работающего запоминающего устройства.
Что делать, если обнаружена ошибка в системной программе Ubuntu
Установка нового программного обеспечения или изменения системных настроек могут вызвать сообщение «Обнаружена ошибка в системной программе». Многие его игнорируют, так как на общей работе оно не отражается.

С проблемой обычно сталкиваются пользователи Ubuntu версии 16.04. Тестировать HDD в этом случае нет необходимости, так как проблема скорее заключается именно в программном сбое. Сообщение оповещает о непредвиденном завершении работы программы и предлагает отправить отчет разработчикам. При согласии откроется окно браузера, где требуется заполнить форму из 4 шагов. Такой вариант вызывает сложности и не гарантирует исчезновения ошибки.
Второй способ поможет избежать появления сообщения лишь в том случае, если оно вызывается одной и той же программой. Для этого при очередном оповещении нужно установить галку на опцию «Не показывать больше для этой программы».
Третий метод – отключить утилиту Apport, которая отвечает в Linux за сбор информации и отправку отчетов. Такой подход полностью исключит всплывание окон с ошибками. Возможно отключение только показа уведомлений, оставляя службу сбора в рабочем состоянии. Для этого необходимо выполнить:
gsettings set com.ubuntu.update-notifier show-apport-crashes false

Данные продолжат собираться в папке /var/crash. Их периодически необходимо чистить, чтобы они не заполняли дисковое пространство:
Для полного отключения служб Apport, в терминал вводится запись:
В появившемся тексте значение поля enable меняется с 1 на 0. В дальнейшем, чтобы снова включить службу, возвращаются настройки по умолчанию.
Заключение
Для предотвращения потери файлов жесткий диск и съемные носители рекомендуется периодически тестировать. Linux предлагает несколько подходов к решению задачи. На выбор предоставляется перечень утилит, которые выявляют поврежденные сектора и обеспечивают перенос информации на нормально функционирующее устройство.
Источник



