- Google Диск в качестве резервного хранилища для VPS сервера на базе Linux
- Back up your Google Drive files from Linux
- Scenario
- Solution
- Installation
- Configuration
- Some examples
- Backup files
- Conclusion
- How to install & use the Google Backup and Sync on Ubuntu
- Linux: Подключение Google Drive или бэкап для бедных
- Дубликаты не найдены
- Автоматизация бэкапов.
- Мини сервер для бекапов часть 1 (подготовительная)
Google Диск в качестве резервного хранилища для VPS сервера на базе Linux
Пришла идея делать backup сервера VPS на CentOS 7 в Google drive, не пропадать же зря 15 гигам халявного места. Немного поискал и нашел пару статей на эту тему, тема оказалась не нова, и сначала поставил утилиту от самой корпорации добра, вот статья на эту тему Backing up a Directory to Google Drive on CentOS 7.
Но мне это не подходит, так как есть скрипт, который выполняется по расписанию, и в нем я решил проверять файлы по дате создания и не плодить миллион архивов, а для этого нужно смонтировать Google Drive в папку.
Утилита от Google умеет только закачивать и скачивать файлы, проверить по дате и удалить все старше 3х дней не получилось.
Спасение нашлось в google-drive-ocamlfuse, статей на эту тему не мало, но есть одно, но, утилита требует GUI интерфейс, а в частности любой браузер. В браузер передается с генерированная ссылка.
Google как известно авторизует пользователей по OAuth. В моем VPS естественно не о каком GUI речь не идет, только консоль.
На помощь пришла статья с github Headless Usage & Authorization. Предлагаю вам мой вольный перевод.
1. Устанавливаем по инструкции google-drive-ocamlfuse
2. Входим в свой google accaunt. Переходим на страницу https://code.google.com/apis/console/ и создаем Новый проект в верхнем левом углу (Project → Create project).
3. В левой панельке ищем Библиотеки-Drive API (Library → Drive API) и включаем её (Enable).
4. Дальше переходим на Учетные данные (Credentials). Создаем нового пользователя Create credentials → OAuth client ID. Выбираем Other в предложенных вариантах. Получаем ID и секретный ключ.
5. Возвращаемся в консоль и пишем:
6. Получаем сообщение в котором есть ссылка:
Копируем ссылку в браузер и получаем код верификации.
7. Копируем полученный код верификации и вставляем его обратно:
После этого будет создана папка с приложением (
/.gdfuse/me/), его мы и будем использовать для монтирование нашего диска. Монтируем в папку:
В оригинальной инструкции описаны действия которые нужно сделать при возникновении ошибок, но у меня все получилось с первого раза.
Источник
Back up your Google Drive files from Linux

Dec 1, 2015 · 3 min read

Scenario
Can we really trust Google? Users and companies are using Google Drive to store all their files on the cloud more and more, without any other copy of their data. Is that secure?
This is a very controversial topic and is not the aim of this post to talk about that practice. Instead, I’d like to share a solution to download all our Google Drive data to our local computer or server.
Yes, I know; we can do that e asily using the Drive client. But how to do that from Linux? And how to automatize also the backup of our Google Docs & Spreadsheets?

Solution
Currently there is not any official Drive client for Linux. Instead, there are a lot of alternatives on GitHub.
My favorite one is Drive (very original name), which is very similar to git on its syntax. It was initially developed by @rakyll and currently there is a very active fork maintained by @Emmanuel T Odeke
Installation
Fortunately, the installation is quite easy on Ubuntu based distributions:
Alternatively, you also can get the latest code from Github, but remember that you need Go 1.3.x or higher. In order to do this on Ubuntu 14.04 I suggest you to download the binary package and to follow these instructions.
Configuration
Finally, we have to initialize the Drive directory, where we’ll store our files:
Once we accept the request, we will have an authorization code that we have to paste in the console. Our credentials will be stored on “.gd/credentials.json”
Some examples
So now yes, we can start using drive:
Backup files
One of the most interesting features of this project is that we can export Google Docs and Spreadsheets to odt/doc/xls/… format.
Note: this feature was recently improved. I recommend you to use the latest version from GitHub or to wait for 0.3.4 version release.
As you can see, it exports the files under filename_exports directory by default.
We can change that behavior adding -exports-dir parameter to the command or, still better, adding it to the . driverc configuration file:
If you don’t change the exports directory, you should avoid the synchronization of the exported documents using the .driveignore file:

Conclusion
Using Drive project and Cron, we can easily automatize the backup of our Google Drive files from Linux. If we need more and better backups, we always can save these files to Elkarbackup / Rsnapshot periodically 🙂
Источник
How to install & use the Google Backup and Sync on Ubuntu
Cloud storage is really one of the safest and efficient ways of storing numerous files. Multiple options are available for choosing the most appropriate cloud storage, but Google is the favourite for most users, as a single account can give you access to almost everything from the most reliable search results to mail services, which even include the Play Store, and some nifty other services like Google Keep, Google Docs, and what not. You can even download Google Drive on your smartphone and PC to sync files easily on the cloud and access it from everywhere, without the need of opening Google Drive on the web and upload or download them manually.
But in spite of Google Drive being such a mature cloud storage platform, the unavailability of the Google Drive app on Linux is a big drawback. That is a deal breaker for most users who want to ditch Windows and move to Linux. But in spite of the unavailability of the official app, you can use Google Drive for Linux Mint or can use Google Backup and Sync on Linux quite effortlessly with the Google Drive API on Linux, with the help of Gnome. You will be able to access Google Drive as a network drive, which means you can save files directly to it, or open a file from it with minimum hassles. You will have to tinker around with the Linux command line, but trust me, it will be short. To get Google Drive for Linux and Ubuntu, you will just need a single command.
So let’s get started with the tutorial. I will be showing this tutorial on Ubuntu Linux which is no doubt the most popular distribution of Linux, liked by many.
Источник
Linux: Подключение Google Drive или бэкап для бедных

Установка и настройка gdrive
Все действия ниже выполняются на CentOS7. Если вы хотите поставить gdrive на другой linux-дистрибутив, то перейдите на страницу проекта на github и скопируйте необходимую ссылку
# mv drive /usr/sbin/drive
# chmod +x /usr/sbin/drive
Всё, gdrive установлен. Ну очень просто)
Теперь запустим drive для запуска процесса авторизации:
Появится следующее сообщение:
Go to the following link in your browser:
Enter verification code:
Необходимо скопировать и открыть эту ссылку в браузере. После авторизации появится следующая страница:
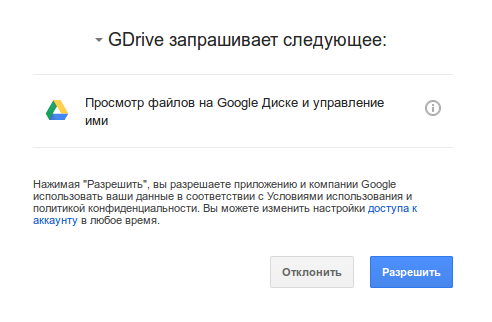
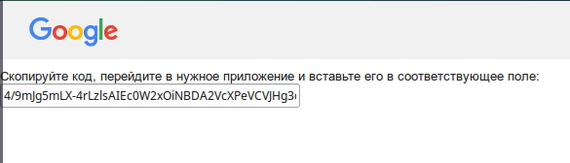
Копипастим этот код в консоль и подтверждаем:
Enter verification code: 5/8r1pjcEwaRzIpF88QdA0CTwV0lacGXAE6x8czOFK6k9
Все gdrive настроен.
Проверим его работу. Создадим простой текстовый файл и скопируем его на гугл-диск:
# echo test > test.txt
# drive upload —file test.txt
—file test.txt — файл, который нужно скопировать.
После выполнения команды drive upload в консоль выводится информация о загруженном файле:
Created: 2016-08-26 12:58:04
Modified: 2016-08-26 12:58:04
Owner: Test Account
MIME Type: text/plain; charset=utf-8
Uploaded ‘test.txt’ at 5.0 B/s, total 5.0 B
Для просмотра содержимого диска используется команда drive list.
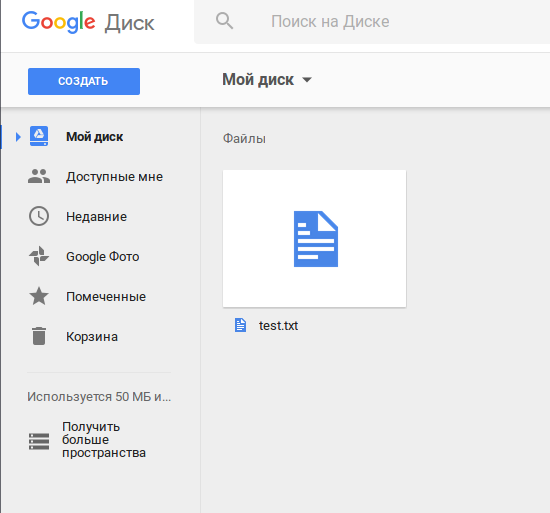
Откроем в браузере наш гугл-диск, чтобы еще раз убедиться, что файл все-таки скопировался:
Для удаления файла необходимо использовать следующую команду:
# drive delete —id 0B4KhH190NxVwZ0VQRzlFbXhkVHM
Removed file ‘test.txt’
— 0B4KhH190NxVwZ0VQRzlFbXhkVHM — Id файла, который нужно удалить.
Скрипт резервного копирования
Дубликаты не найдены
Если вы знаете какие-нибудь другие способы подключения Google Drive на linux — пишите в комментариях.
Но вообще, какой смысл так извращаться использовать сервис, который не поддерживает твою платформу, когда есть столько альтернатив(я уж не говорю про сервисы типа crashplan)? Имхо, даже с OneDrive в линукс работать проще, чем с гуглом, который обещал поддержку ещё лет 5 назад.
Спасибо за наводку на cloudcross, не знал о такой штуке.
Я не очень то и доверяю всем этим облачным ресурсам для хранения критически важной информации, все бэкапы держу на своих серверах. Так спится спокойнее)
Но бывали случаи, что выручал такой вариант, описанный в посте.
Прошло 955 дней (угадайте, как я сюда попал? :)) ) . И ничего не изменилось, всё те же «извращения». Жутко хотелось именно Google Drive на Centos7. Загрузка файлов по id, за что они так с нами?
А как с этой утилитой автоматом удалять старые файлы с GoogleDrive?

Автоматизация бэкапов.
Может и не совсем интересно, но кому-то может понадобиться такой мануал (ни в коем случае не реклама, только в ознакомительных целях). Мне руководитель поставил задачу на работе и вот так я ее решил.
Представим ситуацию, когда, у нас появилось слишком много филиалов и в каждом стоит роутер «Mikrotik» (в моем случае их 50+), Вы всегда делали бэкапы и сливали конфигурацию. НО! К примеру, работаете Вы не один — это раз, надоело вручную заходить и делать бэкапы — это два, даже если уверены в своих коллегах — нужно страховаться — это три. При всем этом роутеров много и количество будет рости. *Нужно автоматизировать это дело* — подумаете Вы, этим собственно и займемся.
— UNIX-подобная система (в моем случае FreeBSD)
— Пара роутеров «Mikrotik» для проверки скрипта
Принцип работы скрипта:
— Скрипт будет заходить на каждый роутер указанный в массиве по SSH, под каким-либо пользователем
— Давать команду на создание бэкапа в двоичном и текстовом виде, а именно в расширениях *.backup и *.rsc
— Сливать файлы на наш сервер по SCP
— Удалять созданные бэкапы на самом роутере
— Проверять в папке с бэкапами, чтоб файлы были не старше трех дней, если старше — то удаляем. Другими словами у нас будут бэкапы за последние три дня.
1: Создадим сначала пользователя, с нужными на правами. Заходим на наш микротик, в меню жмакаем System -> Users и переходим в открывшемся окне на вкладку Group, нажимаем на «+«, чтобы добавить новую группу (я назвал ее script) и назначаем права как на картинке:
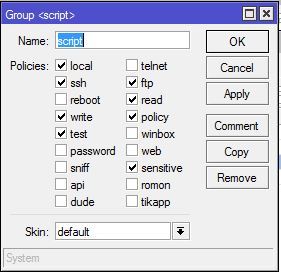
Далее переходим в вкладку Users и там жмем снова «+» вбиваем название пользователя, назначаем нашу созданную группу и пароль. Пусть будет у нас «Валли»

Должно получиться так:
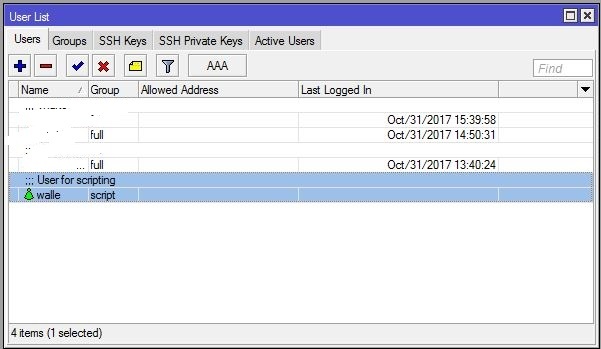
2: Теперь нам нужно сгенерировать публичный ключ — для того, чтобы, скрипт подключался к микротику по ssh не спрашивая пароль т.е. автоматически. Заходим на наш FreeBSD под root’ом (для не знающих команда sudo su) и генерируем ключ командой: ssh-keygen -t dsa.
Будет вопрос в каком каталоге сохранять? я оставляю по дефолту, поэтому Enter, так же будет вопрос о пароле на ключ, оставляем пустой т.е. тоже нажимаем Enter.
Должно получиться так:
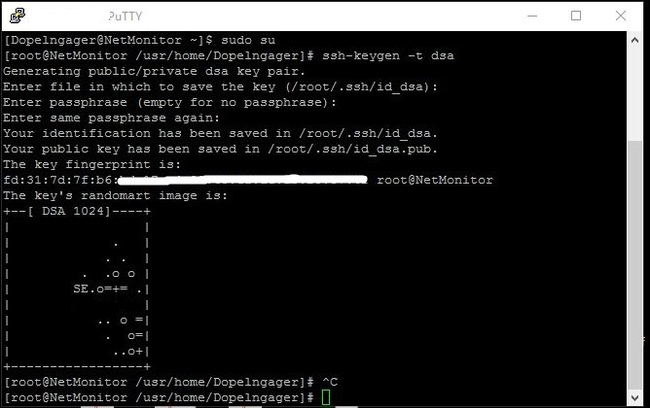
Проверить наличие сгенерированного ключа можно так: ls -lh /root/.ssh/ и увидите в списке свой файл, с названием id_dsa.pub.
3: Следом надо залить ключ на микротик. Возвращаемся к микротику, нажимаем IP -> Services и там есть сервис «ftp«, если он выключен, то включите.
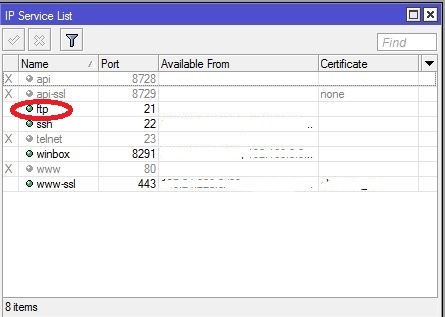
Возвращаемся на сервер и переходим в каталог с нашим ключом: cd /root/.ssh/.
Подключаемся на микротик через FTP командой: ftp 192.168.88.1
Спросит имя пользователя, вводим нашего: walle, следом пароль от него и увидите приветствие микротика:
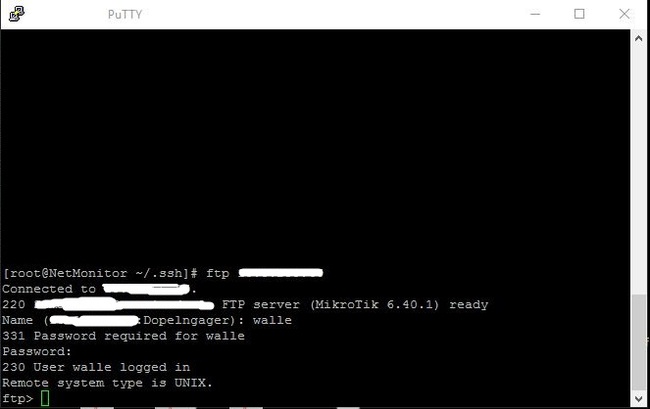
Вводим команду передачи ключа: put id_dsa.pub и .
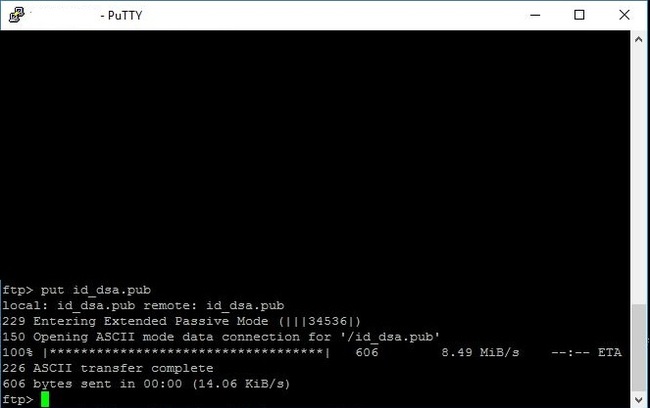
Это говорит о том, что передача успешна и завершилась, вводим: exit.
4. Теперь надо назначить ключик нашему пользователю, переходим на роутер.
Откройте Files, там увидите свой ключик:
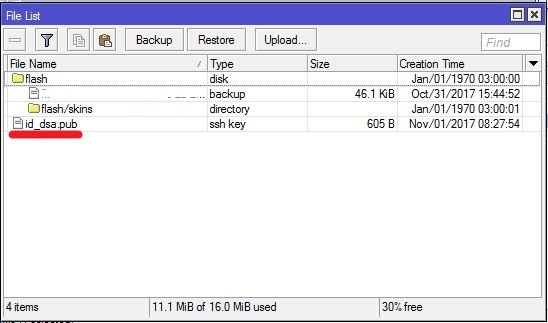
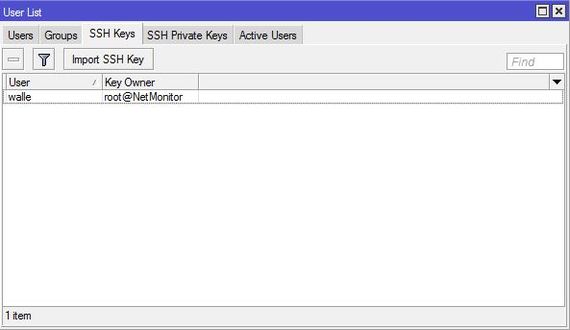
Ключ мы успешно импортировали и он будет работать.
Переходим на наш FreeBSD и пробуем подключиться по SSH с использованием ключа: ssh walle@192.168.88.1.
При первом подключении вам зададут вопрос: Are you sure you want to continue connecting (yes/no)? — отвечаем: yes. Больше спрашивать не будет.
После увидите приветствие роутера.
5. Необходимо на нашем FreeBSD создать папку для бэкапов, сделал я вот такой командой: mkdir /var/mikrotik_backups/.
Назначил полные права папке chmod 777 /var/mikrotik_backups/.
6. Необходимо создать сам файл скрипта: перехожу в свой каталог cd /usr/home/Dopelngager/ и создаем файл скрипта: touch backup_mikrotik.
Назначаю точно так же полные права chmod 777 backup_mikrotik.
7. Пришли теперь к основному, а именно к написанию скрипта.
Открываем файл скрипта командой: ее backup_mikrotik
и записываем в файл вот это:
#!/usr/local/bin/bash
routers=( 192.168.88.1 )
backupdir=»/var/mikrotik_backups/»
privatekey=»/root/.ssh/id_dsa»
login=»walle»
DATE=»`date ‘+%Y-%m-%d’`»
for r in $
cmd_backup=»/system backup save name=$
ssh $
sleep 2
cmd_backup=»/export file=$
ssh $
sleep 5
scp -i $privatekey $
scp -i $privatekey $
ssh $
ssh $
done
find $backupdir* -mtime +3 -exec rm <> \;
Если у вас не один роутер, то, шаги с 1 по 4 нужно сделать с каждым и в скрипт добавить роутеры в строку «routers«, между скобок. ОБЯЗАТЕЛЬНО!: добавлять роутеры через пробел и пробелы около скобок тоже должны быть! Для примера добавим еще один роутер:
routers=( 192.168.88.1 192.168.88.2 ).
Проверим наш скрипт, вводим команду: ./backup_mikrotik
Должен пойти процесс скачивания и сохранения файлов.
8. Остался последний шаг — это добавить скрипт в планировщик.
Вводим команду открытия планировщика Cron: ее /etc/crontab
#backup Mikrotik routers
* 21 * * * root /usr/home/Dopelngager/backup_mikrotik
Сохраняем и необходимо перезапустить cron: /etc/rc.d/cron restart.
Таким образом я запланировал работу скрипта ежедневно в 21 час, еженедельно, ежемесячно, ежегодно. ВАЖНО! Соблюдайте пробелы и табуляции при добавлении записей в файл, cron чувствителен к этим вещам. А лучше про него подробнее почитайте в интернете.
У меня все, надеюсь было полезно. За ошибки и шакальные картинки простите. Unix-подобные системы знаю плохо, только учусь — так что сильно не придирайтесь. Если у кого есть вариант улучшить скрипт или его работу — обязательно приму во внимание.
А вот кстати результат работы срипта:
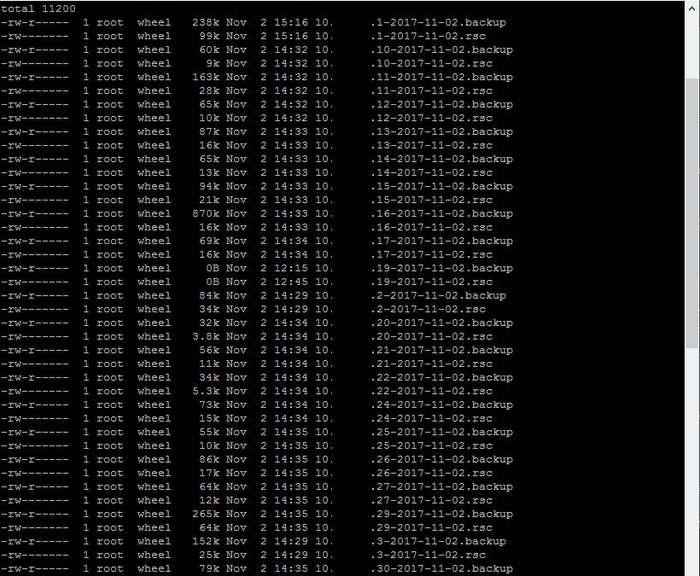

Мини сервер для бекапов часть 1 (подготовительная)
Добрый день, пикабу!
На волне паники, касающейся троянов-шифровальщиков, решил поделиться простой и надежной схемой создания многоуровневых бекапов в корпоративной сети, при минимальной затрате средств. Стоит отметить, что данная система внедрена довольно давно, успешно работает, и защищает не только от троянов, но и от разгильдяйства пользователей, которые могут случайно удалить или запороть какие-либо важные документы.
Сервер для хранения резервных копий можно поднять даже на очень старых машинах.
В данном примере я буду использовать ОС Ubuntu Server 15.04
Дано: небольшая организация с парком в 20 рабочих станций и файловым сервером под управлением Win2k3 Server.
Необходимо: Реализовать механизм резервного копирования данных с минимальными затратами.
Затраты: «какойнибудь комп» (я откопал системник на базе Athlon64 3200+ c 512MB оперативы) и новый жесткий диск (желательно конечно пару для массива). Ессно емкость жесткого диска должна быть больше емкости хранилища на файловом сервере.
В первую очередь, необходимо установить на машинку нашу новую операционку. Гайдов в сети полно, установка несложная, единственные вопросы могут возникнуть с разбивкой дисков, но об этом, а так же об особенностях файловых систем я расскажу в следующих постах. Важно понимать, что систему желательно устанавливать на отдельный диск. Можно небольшой емкости. Даже 80 ГБ для полноценной работы хватит вполне, и еще останется. Что касается диска или массива для хранения данных, его емкость должна быть больше, чем на файловом сервере. Раздел необходимо создавать с файловой системой ext3, ext4 или XFS.
У нас установлена чистая новая ось. Новый жесткий диск (или пара в массиве) установлены и размечены как отдельный раздел. Лично у меня он примонтирован как /back
Далее, необходимо проверить наличие, а в случае отсутствия установить следующие пакеты: openssh-server cifs-utils rsync cron
Делается это следующей командой:
sudo apt-get install openssh-server cifs-utils rsync cron
Затем создадим в системе пользователя, от имени которого процесс бекапа и будет запускаться:
sudo useradd -rm backuper
и зададим ему пароль:
sudo passwd backuper
Следующим шагом будет подключение сетевой папки на файловом сервере в нашу файловую систему. Если в организации поднят домен, то необходимо будет создать отдельного пользователя для доступа к сетевому ресурсу.
Сначала создадим папку, в которую мы ресурс будем подключать. У меня она находится по адресу /mnt/nw делается это командой:
sudo mkdir /mnt/nw
Затем сменим владельца созданной папки и зададим права:
sudo chown backuper:backuper /mnt/nw
sudo chmod 775 /mnt/nw
Чтобы подключиться к сетевому диску, отредактируем файлик /etc/fstab
В его конце надо будет добавить одну строку следующего вида:
//server/share/ /mnt/nw cifs userid=id,passwd=pass,iocharset=utf8,dir_mode=0777,sec=ntlm,file_mode=0775 0 0
где в параметры userid и passwd ставим логин и пароль пользователя, имеющего доступ к ресурсу. А вместо //server/share имя сервера и название шары.
Чтобы немедленно подключить сетевой ресурс, набираем
Все, подготовительная часть завершена, далее необходимо настроить rsync и планировщик cron. Этим мы займемся во 2й части.
Источник



