- @charset
- Краткая информация
- Версии CSS
- Описание
- Синтаксис
- Значения
- Браузеры
- HTML кодировки
- Кодировка ISO
- Кодировки серии ISO 8859
- Для HTML4:
- Для HTML5:
- Кодировка Windows-1251 (CP1251)
- Кодировки стандарта UNICODE
- Кодировки UTF-8 и Windows 1251 — просто о сложном
- Немного теории
- Недостатки и достоинства
- Базы банных
- Htaccess
@charset
| Internet Explorer | Chrome | Opera | Safari | Firefox | Android | iOS | |
| 6.0+ | 8.0+ | 2.0+ | 9.0+ | 4.0+ | 1.5+ | 1.0+ | 1.0+ |
Краткая информация
| Значение по умолчанию | UTF-8 |
|---|---|
| Ссылка на спецификацию | http://www.w3.org/TR/CSS21/syndata.html#charset |
Версии CSS
Описание
Команда @charset применяется для задания кодировки внешнего CSS-файла. Это имеет значение в том случае, если в CSS-файле используются символы национального алфавита.
Для внешней таблицы стилей браузер последовательно просматривает следующие пункты для определения кодировки таблицы стилей:
- кодировка, которую отдает сервер;
- правило @charset ;
- атрибут charset тега
- ;
- кодировка, установленная в документе через метатег ( ).
Приведенный список имеет четко выраженную иерархию — чем выше находится пункт, тем выше его приоритет. Если ни один из пунктов не найден, будет установлена кодировка UTF-8.
Синтаксис
Значения
Для русского языка обычно указывается кодировка windows-1251 или utf-8. Значение кодировки обязательно должно быть взято в кавычки.
CSS2.1 IE 9 Cr Op Sa Fx
Браузеры
В браузере Internet Explorer до версии 7.0 включительно название кодировки допускается писать без кавычек, что противоречит спецификации CSS.
HTML кодировки
Чтобы правильно отобразить html-документ, браузер должен знать какая кодировка символов использовалась при создании документа.
ASCII — одна из самых старых компьютерных кодировок, в которой каждому символу соответствует строго определенное число. Например, символу «a» соответствует число 97, а символу «A» — число 65.
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
ASCII — это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
Вы можете посмотреть на полный комплект Печатаемых символов ASCII.
Позже ASCII была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в кодировку ASCII символы национальных языков разных стран, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8 (Код Обмена Информацией, 8 бит) — это тоже расширенная кодировка ASCII. KOI8 включала в себя цифры, буквы латинского и русского алфавита, а также знаки пунктуации, спецсимволы и псевдографику.
Кодировка ISO
Организация Международных стандартов (International Standards Organization) создала диапазон кодировок для различных алфавитов/языков.
Кодировки серии ISO 8859
Для документов на английском и большинстве других западноевропейских языков, широко поддерживается кодирование ISO-8859-1.
В HTML ISO-8859-1 является кодировкой по умолчанию (в XHTML и в HTML5 кодировкой по умолчанию является UTF-8).
При использовании кодировки страницы, отличной от ISO-8859-1, вам необходимо указать это в теге .
Для HTML4:
Для HTML5:
Примером ANSI-кодировки является всем известная Windows-1251.
Windows-1251 выгодно отличается от других 8 битных кириллических кодировок (таких как CP866 и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только знак ударения). Она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
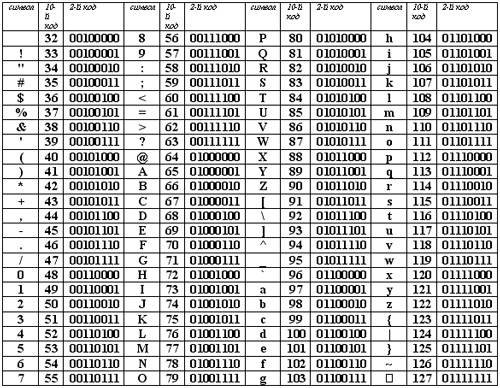
Ниже приведены десятичные значения символов кодировки Windows-1251.
Для отображения символов таблицы в HTML-документе воспользуйтесь следующим синтаксисом:
Кодировка Windows-1251 (CP1251)
402
403
201A
453
201E
2026
2020
2021
20AC
2030
409
2039
40A
40C
40B
40F
452
2018
2019
201C
201D
2022
2013
2014
2122
459
203A
45A
45C
45B
45F
40E
45E
408
A4
490
A6
A7
401
A9
404
AB
AC
AD
AE
407
B0
B1
406
456
491
B5
B6
B7
451
2116
454
BB
458
405
455
457
410
411
412
413
414
415
416
417
418
419
41A
41B
41C
41D
41E
41F
420
421
422
423
424
425
426
427
428
429
42A
42B
42C
42D
42E
42F
430
431
432
433
434
435
436
437
438
439
43A
43B
43C
43D
43E
43F
440
441
442
443
444
445
446
447
448
449
44A
44B
44C
44D
44E
44F
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).
UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
Кодировки UTF-8 и Windows 1251 — просто о сложном

Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
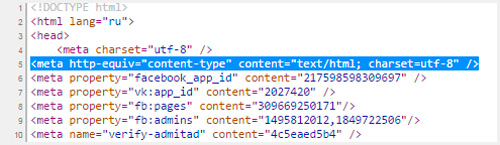
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
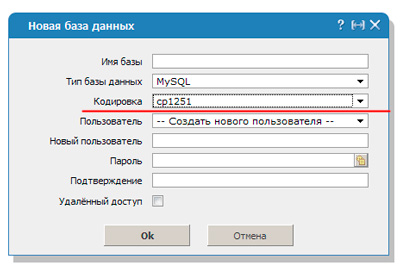
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.



