- Регулярные выражения Linux
- Регулярные выражения Linux
- Примеры использования регулярных выражений
- Выводы
- Основы Linux от основателя Gentoo. Часть 2 (1/5): Регулярные выражения
- Предисловие
- Об этом самоучителе
- Регулярные выражения
- Что такое «регулярное выражение»?
- В сравнении с глоббингом
- Простая подстрока
- Понимание простой подстроки
- Метасимволы
- Использование []
- Использование [^]
- Отличающийся синтаксис
- Матасимвол *
- Начало и конец строки
- Полнострочные регулярки
- Об авторах
- Daniel Robbins
- Chris Houser
- Aron Griffis
Регулярные выражения Linux
Регулярные выражения — это очень мощный инструмент для поиска текста по шаблону, обработки и изменения строк, который можно применять для решения множества задач. Вот основные из них:
- Проверка ввода текста;
- Поиск и замена текста в файле;
- Пакетное переименование файлов;
- Взаимодействие с сервисами, таким как Apache;
- Проверка строки на соответствие шаблону.
Это далеко не полный список, регулярные выражения позволяют делать намного больше. Но для новых пользователей они могут показаться слишком сложными, поскольку для их формирования используется специальный язык. Но учитывая предоставляемые возможности, регулярные выражения Linux должен знать и уметь использовать каждый системный администратор.
В этой статье мы рассмотрим регулярные выражения bash для начинающих, чтобы вы смогли разобраться со всеми возможностями этого инструмента.
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- — указывает сколько раз (n) нужно повторить предыдущий символ;
- — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- [az] — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- [^az] — любой символ, кроме тех, что указаны в скобках;
- [a-z] — любой символ из указанного диапазона;
- [^a-z] — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту.
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Примеры использования регулярных выражений
Теперь, когда мы рассмотрели основы и вы знаете как все работает, осталось закрепить полученные знания про регулярные выражения linux grep на практике. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать команду egrep:
egrep «^s» /etc/passwd
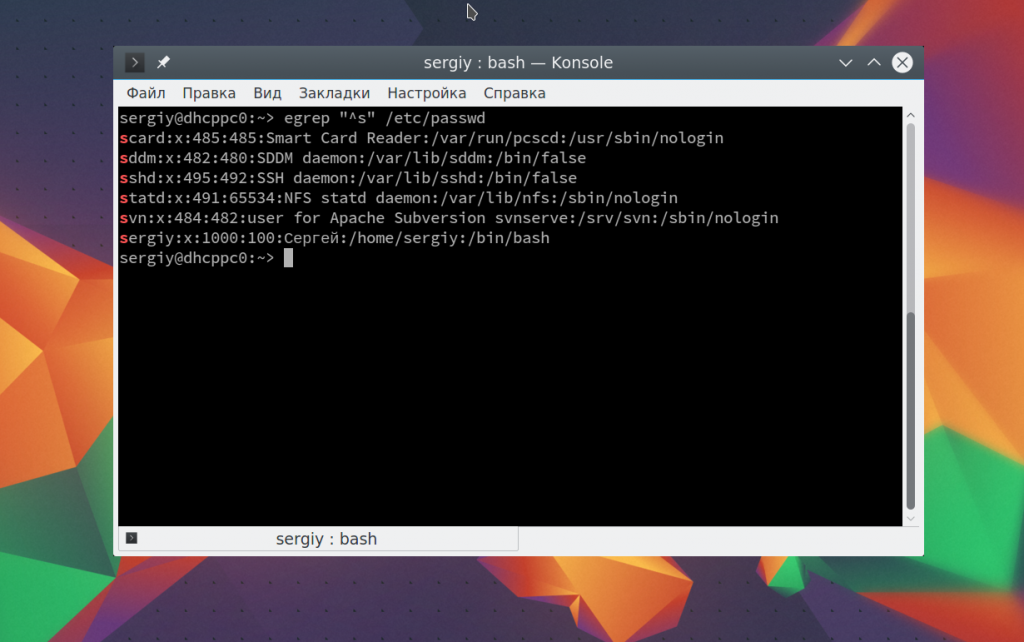
Если мы хотим отбирать строки по последнему символу в строке, что для этого можно использовать $. Например, выберем всех системных пользователей, без оболочки, записи о таких пользователях заканчиваются на false:
egrep «false$» /etc/passwd
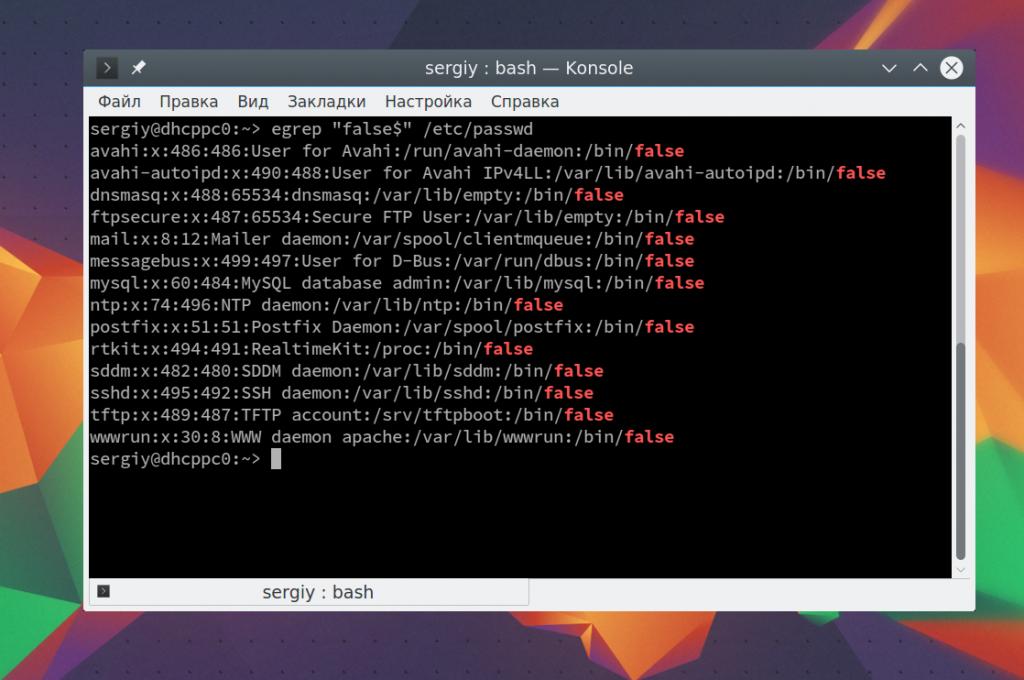
Чтобы вывести имена пользователей, которые начинаются на s или d используйте такое выражение:
egrep «^[sd]» /etc/passwd
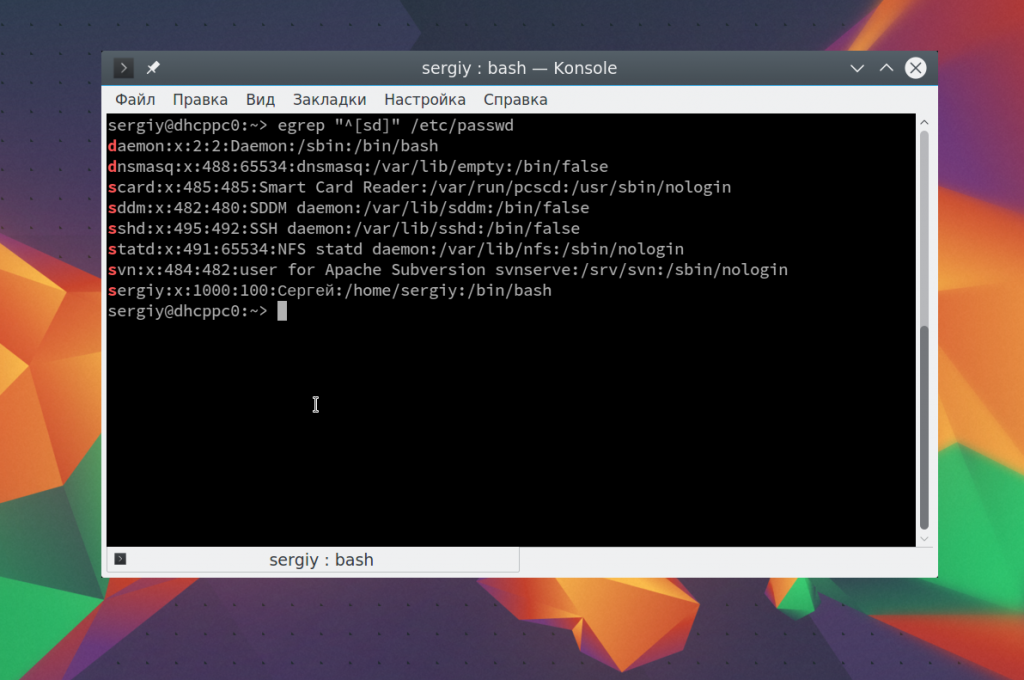 Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
egrep «^[s|d]» /etc/passwd
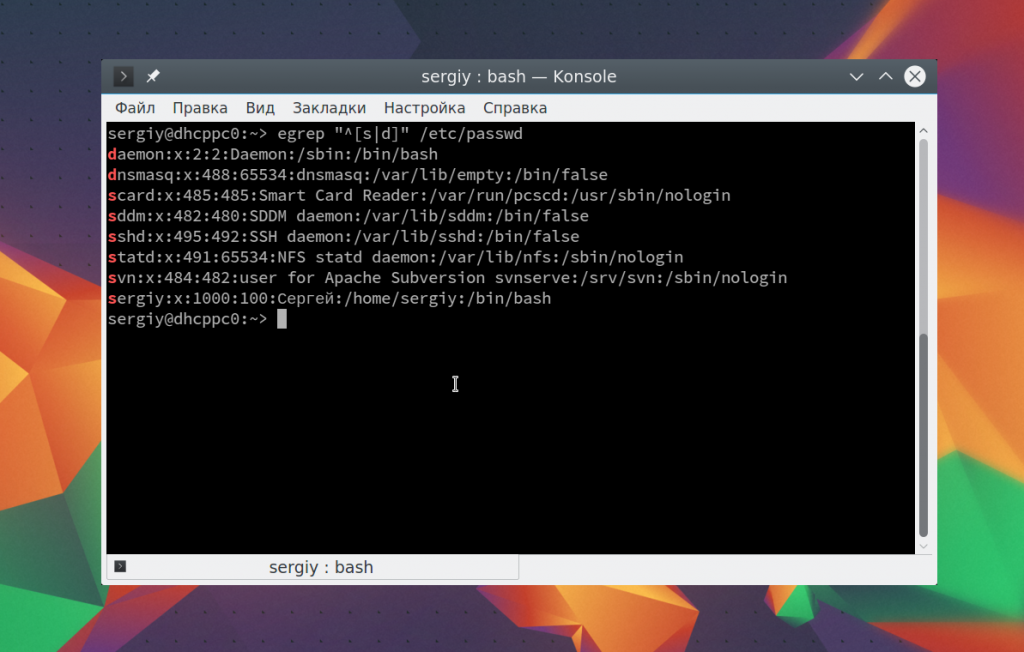
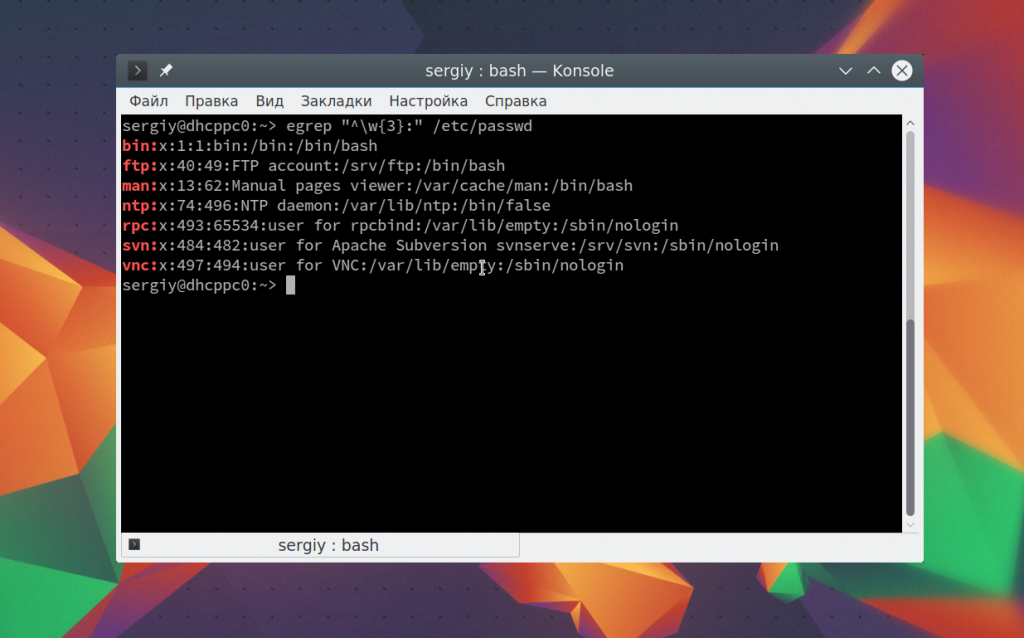
Теперь давайте выберем всех пользователей, длина имени которых составляет не три символа. Имя пользователя завершается двоеточием. Мы можем сказать, что оно может содержать любой буквенный символ, который должен быть повторен три раза, перед двоеточием:
egrep «^\w<3>:» /etc/passwd
Выводы
В этой статье мы рассмотрели регулярные выражения Linux, но это были только самые основы. Если копнуть чуть глубже, вы найдете что с помощью этого инструмента можно делать намного больше интересных вещей. Время, потраченное на освоение регулярных выражений, однозначно будет стоить того.
На завершение лекция от Яндекса про регулярные выражения:
Источник
Основы Linux от основателя Gentoo. Часть 2 (1/5): Регулярные выражения
Предисловие
Об этом самоучителе
Добро пожаловать в «Азы администрирования», второе из четырех обучающих руководств, разработанных чтобы подготовить вас к экзамену 101 в Linux Professional Institute. В данной части мы рассмотрим как использовать регулярные выражения для поиска текста в файлах по шаблонам. Затем, вы познакомитесь со «Стандартом иерархии файловой системы» (Filesystem Hierarchy Standard или сокр. FHS), также мы покажем вам как находить нужные файлы в вашей системе. После чего, вы узнаете как получить полный контроль над процессами в Linux, запуская их в фоновом режиме, просматривая список процессов, отсоединяя их от терминала, и многое другое. Далее последует быстрое введение в конвейеры, перенаправления и команды обработки текста. И наконец, мы познакомим вас с модулями ядра Linux.
В частности эта часть самоучителя (Часть 2) идеальна для тех, кто уже имеет неплохие базовые знания bash и хочет получить качественное введение в основные задачи администрирования Linux. Если в Linux вы новичок, мы рекомендуем вам сперва закончить первую часть данной серии практических руководств. Для некоторых, большая часть данного материала будет новой, более опытные же пользователи Linux могут счесть его отличным средством подвести итог своим базовым навыкам администрирования.
Если вы изучали первый выпуск данного самоучителя с целью, отличной от подготовки к экзамену LPI, то вам, возможно, не нужно перечитывать этот выпуск. Однако, если вы планируете сдавать экзамен, то вам настоятельно рекомендуются перечитать данную, пересмотренную версию самоучителя.
Регулярные выражения
Что такое «регулярное выражение»?
Регулярное выражение (по англ. regular expression, сокр. «regexp» или «regex», в отечестве иногда зовется «регулярка» — прим. пер.) — это особый синтаксис используемый для описания текстовых шаблонов. В Linux-системах регулярные выражения широко используются для поиска в тексте по шаблону, а также для операций поиска и замены на текстовых потоках.
В сравнении с глоббингом
Как только мы начнем рассматривать регулярные выражения, возможно вы обратите внимание, что их синтаксис очень похож на синтаксис подстановки имен файлов (globbing), который мы рассматривали в первой части. Однако, не стоит заблуждаться, эта схожесть очень поверхностна. Регулярные выражения и глоббинг-шаблоны, даже когда они выглядят похоже, принципиально разные вещи.
Простая подстрока
После этого предостережения, давайте рассмотрим самое основное в регулярных выражениях, простейшую подстроку. Для этого мы воспользуемся «grep», командой, которая сканирует содержимое файла согласно заданному регулярному выражению. grep выводит каждую строчку, которая совпадает с регулярным выражением, игнорируя остальные:
Выше, первый параметр для grep, это regex; второй — имя файла. grep считывал каждую строчку из /etc/passwd и прикладывал на нее простую regex-подстроку «bash» в поисках совпадения. Если совпадение обнаруживалось, то grep выводил всю строку целиком; в противном случае, строка игнорировалась.
Понимание простой подстроки
В общем случае, если вы ищите подстроку, вы просто можете указать её буквально, не используя каких-либо «специальных» символов. Вам понадобиться особо позаботиться, только если ваша подстрока содержит +, ., *, [, ] или \, в этом случае эти символы должны быть экранированы обратным слешем, а подстрока заключаться в кавычки. Вот несколько примеров регулярных выражений в виде простой подстроки:
- /tmp (поиск строки /tmp)
- «\[box\]» (поиск строки [box])
- «\*funny\*» (поиск строки *funny*)
- «ld\.so» (поиск строки ld.so)
Метасимволы
С помощью регулярных выражений используя метасимволы возможно осуществлять гораздо более сложный поиск, чем в примерах, которые недавно рассматривали. Один из таких метасимволов «.» (точка), который совпадает с любым единичным символом:
В этом примере текст dev.sda не появляется буквально ни в одной из строчек из /etc/fstab. Однако, grep сканирует его не буквально по строке dev.sda, а по dev.sda шаблону. Запомните, что «.» будет соответствовать любому единичному символу. Как вы видите, метасимвол «.» функционально эквивалентен тому, как работает метасимвол «?» в glob-подстановках.
Использование []
Если мы хотим задать символ конкретнее, чем это делает «.», то можем использовать [ и ] (квадратные скобки), чтобы указать подмножество символов для сопоставления:
Как вы заметили, в частности, данная синтаксическая конструкция работает идентично конструкции «[]» при glob-подстановке имен файлов. Опять же, в этом заключается одна из неоднозначностей в изучении регулярных выражений: синтаксис похожий, но не идентичный синтаксису glob-подстановок, что сбивает с толку.
Использование [^]
Вы можете обратить значение квадратных скобок поместив ^ сразу после [. В этому случае скобки будут соответствовать любому символу который НЕ перечислен внутри них. И опять, заметьте что [^] мы используем с регулярными выражением, а [!] с glob:
Отличающийся синтаксис
Очень важно отметить, что синтаксис внутри квадратных скобок коренным образом отличается от остальной части регулярного выражения. К примеру, если вы поместите «.» внутрь квадратных скобок, это позволит квадратным скобкам совпадать с «.» буквально, также как 1 и 2 в примере выше. Для сравнения, «.» помещенная вне квадратных скобок, будет интерпретирована как метасимвол, если не приставить «\». Мы можем получить выгоду из данного факта для вывода строк из /etc/fstab которые содержат строку dev.sda, как она записана:
$ grep dev[.]sda /etc/fstab
Также, мы могли бы набрать:
$ grep «dev\.sda» /etc/fstab
Эти регулярные выражения вероятно не удовлетворяют ни одной строчке из вашего /etc/fstab файла.
Матасимвол *
Некоторые метасимволы сами по себе не соответствуют ничему, но изменяют значение предыдущего символа. Один из таких символов, это * (звездочка), который используется для сопоставления нулевому или большему числу повторений предшествующего символа. Заметьте, это значит, что * имеет другое значение в регулярках, нежели в глоббинге. Вот несколько примеров, и обратите особое внимание на те случаи где сопоставление регулярных выражений отличается от glob-подстановок:
- ab*c совпадает с «abbbbc», но не с «abqc» (в случае glob-подстановки, обе строчки будут удовлетворять шаблону. Вы уже поняли почему?)
- ab*c совпадает с «abc», но не с «abbqbbc» (опять же, при glob-подстановке, шаблон сопоставим с обоими строчками)
- ab*c совпадает с «ac», но не с «cba» (в случае глоббинга, ни «ac», ни «cba» не удовлетворяют шаблону)
- b[cq]*e совпадает с «bqe» и с «be» (glob-подстановке удовлетворяет «bqe», но не «be»)
- b[cq]*e совпадает с «bccqqe», но не с «bccc» (при глоббинге шаблон точно так же совпадет с первым, но не со вторым)
- b[cq]*e совпадает с «bqqcce», но не с «cqe» (так же и при glob-подстановке)
- b[cq]*e удовлетворяет «bbbeee» (но не в случае глоббинга)
- .* сопоставим с любой строкой (glob-подстановке удовлетворяют только строки начинающиеся с «.»)
- foo.* совпадет с любой подстрокой начинающийся с «foo» (в случае glob-подстановки этот шаблон будет совпадать со строками, начинающимися с четырех символов «foo.»)
Итак, повторим для закрепления: строчка «ac» подходит под регулярное выражение «ab*c» потому, что звездочка также позволяет повторение предшествующего выражения (b) ноль раз. И опять, ценно отметить для себя, что метасимвол * в регулярках интерпретируется совершенно иначе, нежели символ * в glob-подстновках.
Начало и конец строки
Последние метасимволы, что мы детально рассмотрим, это ^ и $, которые используются для сопостовления началу и концу строки, соответственно. Воспользовавшись ^ в начале вашего regex, вы «прикрепите» ваш шаблон к началу строки. В следующием примере, мы используем регулярное выражение ^#, которое удовлетворяет любой строке начинающийся с символа #:
$ grep ^# /etc/fstab
# /etc/fstab: static file system information.
#
Полнострочные регулярки
^ и $ можно комбинировать, для сопоставлений со всей строкой целиком. Например, нижеследующая регулярка будет соответсвовать строкам начинающимся с символа #, а заканчивающимся символом «.», при произвольном количестве символов между ними:
$ grep ‘^#.*\.$’ /etc/fstab
# /etc/fstab: static file system information.
В примере выше мы заключили наше регулярное выражение в одиночные кавычки, чтобы предотвратить интерпретирование символа $ командной оболочкой. Без одиночных кавычек $ исчез бы из нашей регулярки еще даже до того, как grep мог его увидеть.
Об авторах
Daniel Robbins
Дэниэль Роббинс — основатель сообщества Gentoo и создатель операционной системы Gentoo Linux. Дэниэль проживает в Нью-Мехико со свой женой Мэри и двумя энергичными дочерьми. Он также основатель и глава Funtoo, написал множество технических статей для IBM developerWorks, Intel Developer Services и C/C++ Users Journal.
Chris Houser
Крис Хаусер был сторонником UNIX c 1994 года, когда присоединился к команде администраторов университета Тэйлора (Индиана, США), где получил степень бакалавра в компьютерных науках и математике. После он работал во множестве областей, включая веб-приложения, редактирование видео, драйвера для UNIX и криптографическую защиту. В настоящий момент работает в Sentry Data Systems. Крис также сделал вклад во множество свободных проектов, таких как Gentoo Linux и Clojure, стал соавтором книги The Joy of Clojure.
Aron Griffis
Эйрон Гриффис живет на территории Бостона, где провел последнее десятилетие работая в Hewlett-Packard над такими проектами, как сетевые UNIX-драйвера для Tru64, сертификация безопасности Linux, Xen и KVM виртуализация, и самое последнее — платформа HP ePrint. В свободное от программирования время Эйрон предпочитает размыщлять над проблемами программирования катаясь на своем велосипеде, жонглируя битами, или болея за бостонскую профессиональную бейсбольную команду «Красные Носки».
Источник



