- Кластеры в Linux
- Общие сведения о кластерах
- Собираем свой кластер
- Программное обеспечение
- Использование PVM
- Как создать высокопроизводительный вычислительный кластер на Linux
- Шаг 1. Аппаратное обеспечение
- Шаг 2. Сеть
- Шаг 3. Сгруппировать компьютеры
- Шаг 4. Скачать пакеты Rocks
- Шаг 5. Загрузить главный узел и выбрать источник установки
- Шаг 6. Подтвердить выбор
- Шаг 7. Настроить кластер
- Шаг 8. Настроить сеть кластера
- Шаг 9. Настроить публичную сеть
- Шаг 10. Задать пароль root и временную зону
- Шаг 11. Разбить диск на разделы
- Шаг 12. Войти в систему
- Шаг 13. Установить вычислительный узел
- Шаг 14. Первый вычислительный узел
- Шаг 15. Остальные вычислительные узлы
- Шаг 16. Быстрая проверка работоспособности
- Шаг 17. Установить кластерное ПО
- Вывод
- Источники информации
Кластеры в Linux
Тема данной статьи — параллельные вычисления в Linux. В этой статье рассмотрены общие вопросы по организации кластеров, кластерное программное обеспечение, в частности PVM. В конце статьи вы найдете ссылки на дополнительную литературу по этому вопросу.
Общие сведения о кластерах
Сначала нужно вообще разобраться что же такое кластер. Как правило, кластер состоит из узлов (отдельных компьютеров) и объединяющей их сети. Для построения сети обычно используется технология Fast Ethernet (100Mbit/sec), но в простейшем случае (например, создание кластера в домашних условиях или в демонстративных целях) подойдет и один сегмент Ethernet на 10Mbit/sec.
Обычно кластеры используются научно-исследовательскими организациями для моделирования различного рода задач или проведения сложных расчетов. Цена суперкомпьютеров является недоступной большинства для организаций такого рода, поэтому появилась идея собрать свой «суперкомпьютер» из «подручного материала» — рабочих станций на базе процессоров Intel. Производительность процессоров производства Intel сейчас практически достигла уровня процессоров архитектуры RISC (процессоры Intel включая Pentium III используют архитектуру CISC, а P4 — VLIW).
Собираем свой кластер
Конфигурация узлов кластера зависит от задач, которые они будут выполнять. Если ваша цель — само создание кластера без решения каких-нибудь важных задач, подойдут и старенькие машины с 486-ым процессором (желательно DX2 или DX4). Для решения относительно важных задач подойдут компьютеры с процессорами Pentium II от 400Mhz или Pentium III (от 600Mhz).
Обратите внимание на объем оперативной памяти. В первом случае (486/демонстрация работы кластера) достаточным будет 16-32MB (желательно). Во втором — минимум 64Мб, рекомендуется 128Мб ОЗУ.
При использовании многопроцессорных машин объем ОЗУ желательно увеличить до уровня Nx64Mb, где N — это количество процессоров, то есть по 64Мб на каждый процессор. Обычно используются двухпроцессорные машины — в этом случае минимальный объем ОЗУ будет равен 126Мб, а рекомендуемый — 128Мб.
Один компьютер (узел) будет центральным. Желательно, чтобы он был более мощным, чем остальные узлы кластера. На нем нужно установить более мощный процессор, в два раза большим объем оперативной памяти, чем на остальных узлах (минимум 128Мб). Желательно на центральном компьютере использовать SCSI-диск, но подойдет и ATA133 / 7200 rpm. Лучше поставить быстрый SCSI, а на узлах вообще отказаться от жесткого диска — так будет дешевле. Все эти требования — желательные, но не обязательные.
Если вы откажетесь от использования жестких дисков на узлах кластера, операционная система будет загружаться по сети, но об этом мы поговорим немного позже. В этом случае вы получите лишь выигрыш во времени: операционную систему и программное обеспечение нужно будет настраивать только один раз.
Вполне возможен отказ и от видеоплат при сборке узлов кластера (на центральном узле видеоплата все-таки будет нужна).
Теперь поговорим о сети. Как я уже писал, желательно использовать Fast Ethernet. Если количество узлов довольно велико (от 20), для уменьшения коллизий необходимо разбить на отдельные сегменты или использовать для их соединения коммутатор (swith), а не повторитель (hub).
В некоторых случаях имеет смысл разбить сеть на сегменты даже при небольшом числе узлов (от 8), например, если вы используете Ethernet (10Mbit/sec).
При использовании Ethernet отказываться от жестких дисков не рекомендуется: кластер будет работать ужасно медленно, будет возникать огромное число коллизий.
Одним из самых эффективных решений для связи узлов кластера является использование 1.28GBit-ных коммутаторов Myrinet. Также можно использовать технологию Gigabit Ethernet.
Программное обеспечение
В качестве операционных систем можно использовать:
- Linux
- FreeBSD
- Windows NT
Предпочтительнее использовать любую Unix-систему, так как именно эти операционные системы наиболее эффективнее используют сетевые ресурсы. Оптимальным решением является операционная система Linux — она бесплатна и довольно проста в настройке.
Можно использовать любую Linux-систему с версией ядра 2.2.* и выше. Я бы порекомендовал использовать шестую версию Linux RedHat, так как она нетребовательна к системным ресурсам (минимальная конфигурация — 486 33Mhz/8MB RAM/120MB HDD) и в состав дистрибутива входит относительно новое программное обеспечение по сравнению с версией 5.2, которую также можно использовать для построения кластера. Версия ядра, используемая этим дистрибутивом (RH 6), 2.2.5-15.
После установки и настройки (настройки сети) операционной системы нужно установить специальные компиляторы. Дело в том, что бесплатно распространяемые компиляторы gcc/g77/egcs не обеспечивают необходимого уровня оптимизации программ для процессоров Intel (PII, PIII). Рекомендуется использовать коммерческие компиляторы, например, входящие в проект PGI Workstation.
При использовании Windows NT как операционной системы кластера можно также выбрать компилятор компании Intel, оптимизированный для платформы Intel. Ознакомиться с этим компилятором вы можете на сайте http://developer.intel.com/ .
В первом и во втором случае доступны тестовые версии компиляторов. Shareware-версию пакета PGI вы можете скачать на сайте PGI Group — http://www.pgroup.com/register_home.html . А тестовую (14 дней) версию компилятора Intel можно скачать на сайте Intel.
После установки компиляторов нужно установить среду распределения задач. В этой статье я опишу работу со средой PVM, хотя доступны и другие средства — MPI , Condor .
MPI CHameleon представляет собой реализацию промышленного стандарта MPI 1.1. MPI CHameleon позволяет программам выполнятся внутри локальной системы или на сетевом кластере с использованием TCP-соединений.
Среда Condor обеспечивает равномерную нагрузку на кластер путем миграции процессов между несколькими машинами.
Я выбрал более простой вариант — PVM (Parallel Virtual Machine). PVM обеспечивает условия для выполнения одной (или нескольких — в большинстве случаем) задач на нескольких машинах. Другими словами PVM просто распределяет процессы на узлах кластера также как планировщик заданий операционной системы распределяет процессорное время для выполнения нескольких задач.
PVM может работать на следующих архитектурах:
Это дадеко не все архитектуры, которые поддерживает PVM. Список всех доступных архитектур вы найдете в документации pvm. Интересующие нас (точнее, доступные нам) архитектуры выделены жирным шрифтом.
Работа с «параллельной машиной» довольно проста. Нужно установить ее на всех машинах кластера. Мой «кластер» состоял из двух машин класса Pentium (100 и 150Mhz) с объемом ОЗУ по 32Мб и одной (центральной) Celeron 433 (128Mb). От сетевой загрузки я отказался из-за использование 10Mbit-го Ethernet’a. К тому же на всех узлах уже были установлены жесткие диски. На центральном была установлена ОС Linux Mandrake 7, а на вспомогательных машинах Linux RedHat 6.0 Hedwig. Я не устанавливал каких-нибудь коммерческих комплиляторов, а использовал те, которые входят в состав дистрибутива.
Кстати, PVM может работать и на платформе Windows 9x, но вот этого не рекомендую делать. Ради интереса я установил PVM для Windows 98. Скорость работы даже тестовых приложений (не говоря уже о реальных расчетах) была значительно ниже. То, что кластер работает медленнее было видно даже «невооруженным глазом». Скорее всего, это объясняется неэффективной работой Windows с сетью. К тому же, довольно часто весь кластер «зависал» даже при выполнении тестовых задач, которые входят в состав пакета PVM.
Использование PVM
PVM компилируется с помощью привычной тройки команды:
configure; make; make install
Перед запуском make установите переменную окружения PVM_ROOT. В этой переменной окружения нужно указать каталог, в котором находятся каталоги PVM (например, $HOME/pvm, если вы распаковали архив в свой домашний каталог). Еще одной важной переменной окружения является PVM_ARCH. В ней содержится название архитектуры операционной системы. Данная переменная должна устанавливаться автоматически, но если этого не произошло (как в моем случае), нужно установить архитектуру самостоятельно. При использовании Linux эта переменная должна содержать значение LINUX.
Как я уже писал, нужно установить PVM на всех узлах кластера. Вся параллельная машина состоит из демона pvmd и консоли pvm. Назначение опций запуска демона можно узнать, выполнив команду man pvmd. На центральной машине нужно запустить демон pvmd и выполнить команду:
pvm
Этим мы запустим консоль, с помощью которой мы будем управлять всем кластером.
После запуска консоли вы должны увидеть приглашение, которое свидетельствует о том, что кластер готов к работе:
pvm >
Введите команду conf для печати конфигурации кластера. Вы должны увидеть примерно это:
Листинг 1.
Из листинга 1 видно, что сейчас наш кластер состоит из одной машины — центрального узла, который работает под управлением Linux. Теперь самое время добавить в наш кластер еще два узла. Добавление узлов осуществляется с помощью команды:
add hostname
После успешного добавления узла в кластер он должен быть отображен в списке узлов кластера. Теперь уже можно запускать программы, которые поддерживают PVM. Примеры таких программ вы можете найти в каталоге $PVM_ROOT/bin/$PVM_ARCH/. В нашем случае это будет каталог /root/pvm/bin/LINUX (я установил pvm в каталог /root). Для начала запустим самую простую программу — hello. Прежде чем запустить ее, нужно сделать несколько замечаний:
- Вы не можете запускать процессы прямо из консоли pvm. Консоль служит лишь для управления кластером.
- Запуск задачи осуществляется обычным способом — из консоли операционной системы. Но «распараллеливаться» будут лишь те процессы, которые поддерживают pvm. С помощью команды spawn также можно породить задачу (см. ниже)
При запуске hello вы должны увидеть сообщение
hello, world from hostname ,
где hostname — это узел кластера. Другими словами все узлы кластера должны поприветствовать вас.
Более интересной является программа gexample. После запуска нужно ввести два аргумента: n и число процессоров. Не вдаваясь в математические подробности, она рассчитывает сумму от 1 до n и факториал числа n. Второй аргумент определяет количество процессоров, которые будут задействованы в вычислении. В нашем случае второй аргумент равен трем. Просмотреть список всех задач можно с помощью команды ps -a. Эту команду нужно вводить в консоли pvm, а не в консоли операционной системы! Породить задачу можно также с помощью команды spawn, которая подробно рассмотрена ниже. Назначение всех команд консоли pvm представлено в таблице 1.
Таблица 1.
| Команда | Описание |
| add hostname | Добавляет узел в кластер |
| alias | Определяет псевдоним для команды |
| conf | Выводит текущую конфигурацию кластера |
| delete hostname | Удаляет узел из кластера |
| halt | Останавливает кластер (точнее завершает процесс pvmd — узлы при этом не выключаются, а продолжают работать) |
| help [command] | Выводит список всех команд или краткую справку по указанной команде |
| id | Выводит идентификатор процесса pvm (консоли) |
| jobs | Выводит список выполняемых задач |
| kill TID (task id) | «Убивает» задачу |
| mstat host, tid | Показывает состояние узлов |
| ps -a | Выводит список всех задач параллельной машины |
| pstat task-tid | Показывает состояние задачи |
| quit | Выход из консоли pvm |
| reset | Сброс — завершаются все задачи |
| setenv | Отображает или устанавливает переменные окружения |
| sig signum task | Посылает сигнал задаче |
| spawn [opt] a.out | Порождает задачу. Об этой команде мы поговорим подробнее после этой таблицы. |
| trace | Устанавливает/отображает маску трассировки событий. Более подробное объяснение вы найдете в документации. |
| unalias | Удаляет ранее созданный псевдоним команды |
| version | Отображает версию библиотеки libpvm |
В таблице 1 я описал не все команды консоли pvm, обо всех остальных мы можете прочитать, введя команду man pvm.
Теперь рассмотрим некоторые команды подробнее. Начнем с самой простой — alias. С ее помощью можно определить псевдонимы для часто используемых команд, например
alias ? help
Теперь вместо команды help вы можете просто вводить ?
Команда id выводит идентификатор консоли pvm:
Команда mstat отображает состояние узла, например:
Подобно привычной нам команде ps, команда консоли pvm ps -a также используется для отображения всех выполняемых параллельной машиной задач:
Команда pstat выводит состояние задачи:
Вот теперь мы подошли к одной из самых интересных команд — spawn. Данная команда порождает задачу. С ее помощью можно указать некоторые параметры задачи, например, узел, на котором она должна выполняться.
spawn [opt] a.out
a.out — любой исполнимый бинарный файл — программа, которая даже не поддерживает библиотеку libpvm. Для таких программ также можно указать, на какой машине она будет выполняться. В среде Windows параметр a.out — это exe или com — файл.
Можно указать такие параметры команды spawn:
Таблица 2.
| Параметр | Описание |
| -(count) | Число задач. По умолчанию — 1. |
| -(host) | Определяет узел, на котором будет выполняться задача |
| -(ARCH) | Задает архитектуру узлов, на которых будет выполняться задача. |
| -? | Включает отладку (debugging) |
| -> | Перенаправляет стандартный вывод задачи на консоль |
| ->file (*) | Перенаправляет стандартный вывод задачи в файл |
| ->>file (*) | Дописывает стандартный вывод задачи в файл |
(*) после знака > не должно быть пробела!
На этом я завершаю эту небольшую статью о Linux-кластерах. В следующих статьях мы поговорим о других кластерных проектах, в которых используется операционная система Linux. Список дополнительной литературы вы найдете ниже. Если что-нибудь непонятно, пишите — с удовольствием выслушаю ваши вопросы и комментарии, да и команду man тоже никто не отменял.
Источник
Как создать высокопроизводительный вычислительный кластер на Linux
Оригинал: Building a Linux-Based High-Performance Compute Cluster
Автор: Tom Lehmann
Дата: 1 июня 2009
Перевод: Александр Тарасов aka oioki
Дата перевода: 11 августа 2009
Представьте, что у вас есть программа, работающая на относительно новом компьютере с двухъядерным процессором. К сожалению, начальство требует, чтобы эта программа работала быстрее, и чтобы справлялась с большим числом данных за то же самое время. Вы проводите небольшое исследование и обнаруживаете, что для вашей программы существует SMP-версия и версия для кластеров. Сейчас на вашей рабочей станции установлена SMP-версия. Можно увеличить производительность, запустив программу на четырехъядерном (или с большим числом ядер) компьютере, но босс совсем не хочет тратиться на новейшее железо, да еще в нынешнем экономическом климате. Но подождите, у вас же есть 32 старых однопроцессорных компьютера, которые были заменены в прошлом году. Да, у них всего по одному ядру, но все вместе они смогут сделать больше, чем одна двухъядерная машина. Нужно лишь найти способ, как заставить их работать сообща — другими словами, собрать из них кластер.
Так что же такое кластер? Вот одно приемлемое определение: кластер — это группа компьютеров, которые вместе решают одну задачу. Необходимо, чтобы машины кластера были соединены сетью и доверяли друг другу.
Настроить сеть и безопасность кластера возможно и вручную, однако есть более простые способы, и один из них — это воспользоваться какой-нибудь системой установки и настройки кластера. На данный момент одной из наиболее популярных систем подобного рода является пакет Rocks, разрабатываемый командой Калифорнийского университета (University of California, San Diego) при грантовой поддержке Национального научного фонда США (National Science Foundation).
Rocks определяется как пакет развертывания, управления и поддержки кластера. С его помощью можно установить кластер на месте, имея в наличии одно лишь аппаратное обеспечение. Пакет содержит средства для запуска параллельных программ и программы для поддержки и расширения кластера после его первоначальной установки.
Пакет распространяется в виде набора ISO-образов, которые нужно записать на несколько CD или DVD. Затем вы вставляете DVD или CD в машину, которая станет главным узлом и загружаетесь с диска. Дальнейшие действия вам будет подсказывать мастер установки. После ответа на минимальное число вопросов, мастер начнет устанавливать все необходимое для работы главного узла. Последним шагом перед перезагрузкой будет процедура insert-ethers, которая добавляет остальные машины в качестве вычислительных узлов. Чтобы добавить вычислительный узел, нужно загрузить его из сети, и он будет добавлен в кластер и настроен автоматически. После добавления последнего узла, у вас получится функционирующий кластер, пригодный для запуска паралелльных программ.
Таково общее описание процесса, давайте же приступим к построению кластера из невзрачных на первый взгляд компьютеров.
Шаг 1. Аппаратное обеспечение
Первым пунктом по плану является установка аппаратного обеспечения. Основная задача — получить набор соединенных компьютеров. В идеале, машины должны быть максимально идентичными — так, чтобы ни одна из них не была «слабым звеном» во всей группе, что бы приводило к рассинхронизации и увеличению времени параллельного вычисления. В сети также должна быть однородность, ведь в большинстве случаев параллельные вычисления полагаются на постоянные соединения между всеми узлами кластера.
Найдите место, где расположить свои 32 машины, позаботьтесь об их питании и охлаждении. При подключении машин подписывайте их кабели питания, чтобы потом не запутаться.
Итак, мы начинаем с чистого листа, давайте обновим и настроим на каждой системе BIOS. Нужно подвести часы BIOS, чтобы они показывали одно и то же время (погрешность в 5 минут можно считать нормальной). Большинство кластерных систем поддерживают синхронный ход системных часов автоматически, но для этого необходимо, чтобы в самом начале они шли более-менее одинаково.
Наши машины уже использовались ранее, поэтому будет разумным почистить все диски перед загрузкой кластерной программы. Есть много способов очистки диска. К примеру, тщательно вычищает диск программа DBAN (Darik’s Boot and Nuke). Это самодостаточное приложение, которое может по-разному стирать диск, в числе этих методов есть и те, которые одобрены Министерством обороны США.
Запомните, целью является сделать все узлы кластера как можно более похожими. Но это лишь благоприятная цель, но не жесткое требование. Разнородный кластер все равно будет работать, просто в этом случае придется более пристально следить за распределением нагрузки между узлами.
Шаг 2. Сеть
Итак, вы настроили все компьютеры в стойке, пришло время настроить коммуникационную сеть. На рисунке 1 показана схема сети простого вычислительного кластера. В такой топологии Ethernet-соединения используются для административных целей, а соединения типа InfiniBand предназначены для вычислительного трафика. Если у вас нет оборудования InfiniBand, то просто проигнорируйте нижнюю часть схемы. Все-таки Ethernet-кабель может нести как админстративную, так и вычислительную нагрузку.
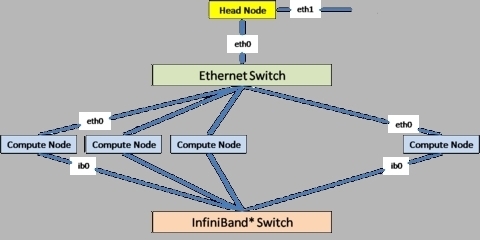
Рисунок 1. Топология сети вычислительного кластера
В данном случае лучше всего будет приобрести один 48-портовый Ethernet-свитч. Если такого нет, всегда можно соединить машины с помощью нескольких меньших свитчей, лишь бы они формировали полное толстое дерево. Как и узлы, входящие в кластер, так и межсоединения между ними должны быть по возможности однородными.
Спланируйте ход всех кабелей, учитывая их толщину. Перед тем, как подключать кабеля, проверьте их. Неприятно осознавать, что кабель поврежден, когда он уже будет переплетен с другими кабелями и будет трудно доступен. Опять же, подпишите концы всех кабелей, чтобы потом было легче устранять неполадки.
Шаг 3. Сгруппировать компьютеры
Теперь вам нужно выбрать один компьютер в качестве главного узла кластера. Все остальные машины будут выполнять вычислительную работу. При подключении вычислительных узлов, система Rocks нумерует их в виде compute-X-Y, где X — номер стойки, а Y — номер машины внутри данной стойки. К примеру, у вас есть 32 узла в 4 стойках. Так вот, если следовать соглашению именования Rocks, тогда сначала пойдет стойка 0. Она содержит главный узел, поэтому нумерация вычислительных узлов в стойке будет от compute-0-0 до compute-0-6. Следующая стойка 1 будет содержать узлы от compute-1-0 до compute-1-7, стойка 2 — от compute-2-0 до compute-2-7 и так далее.
Однако можно поступить проще и считать, что все машины расположены в одной стойке, тогда нумерация вычислительных узлов будет от compute-0-0 и до compute-0-30. Оба способы хороши, какой из них удобнее — решать вам.
Шаг 4. Скачать пакеты Rocks
На этом шаге нужно скачать образ дистрибутива Rocks, который наилучшим образом подходит к машинам вашего будущего кластера. Направляйтесь на веб-сайт Rocks, перейдите во вкладку Download вверху страницы — вы увидите разные версии дистрибутива. На момент написания статьи последней версией была 5.1 (прим. перев. — на момент перевода актуальна версия 5.2 и по сравнению с предыдущей содержит незначительные изменения). Нажмите на ссылке, чтобы узнать подробнее о пакете. В моем случае был выбран образ x86-64 Jumbo DVD. Скачав его, я записал его на чистый DVD. На том же сайте можно найти и документацию — не теряя времени даром, можно ее почитать, пока скачивается образ диска.
Шаг 5. Загрузить главный узел и выбрать источник установки
Загрузите главный узел со свежесозданного DVD-диска Rocks. Если все пройдет гладко, вы увидите экран приглашения, как на рисунке 2.

Рисунок 2. Приветственный экран Rocks
Введите в приглашении boot: строку build — запустится мастер установки. Система начнет загружаться как обыкновенный Linux, после чего пользователь увидит экран начальной настройки Rocks, как на рисунке 3.
Рисунок 3. Экран настройки Rocks Замечание о «роллах»
Пакет Rocks состоит из набора «роллов» (rolls). Некоторые роллы являются неотъемлемыми центральными частями (Base Roll, OS Roll, Kernel Roll и Web Server Roll). Другие обеспечивают кластерные функции (SGE Roll, Java Roll, HPC Roll и Ganglia Roll). Наконец, роллы могут содержать прикладные программы (например, Bio Roll). Каждый такой ролл задокументирован, и вы сами для себя можете решить, нужен он в вашем будущем кластере или нет. Коммерческая версия пакета Rocks — Rocks+ от компании Clustercorp, содержит дополнительный инструментарий, в том числе коммерческие компиляторы от Absoft, Intel и Portland Group, а также отладчик TotalView.
У нас все компоненты уже имеются на диске Jumbo DVD, поэтому нужно в следующем окошке нажать кнопку CD/DVD-Based Roll. После этого появится список отдельных компонентов, которые можно установить с DVD (см. рисунок 4).
Рисунок 4. Экран выбора роллов
В моей установке я выбрал все компоненты, кроме биологических программ (Bio) и средств виртуализации (Xen). Вы можете выбрать, что хотите, но как минимум, нужно установить Base, Web Server, Kernel и OS. Когда определитесь с выбором, нажимайте кнопку Submit.
Шаг 6. Подтвердить выбор
Еще раз появится первый экран, на котором уже будет отображен ваш выбор (см. рисунок 5). Если вы уверены в своем выборе, нажимайте Next для перехода к первым административным этапам установки. Если вы передумали устанавливать какой-либо компонент, нажимайте снова CD/DVD-Based Roll и снова выбирайте.
Рисунок 5. Экран подтверждения выбранных роллов
Шаг 7. Настроить кластер
По мере прохождения всех этих шагов, процедура установки собирает небольшую базу данных MySQL, в которую записывает все подробные настройки вашего кластера. Многие системные файлы (например, /etc/hosts) создаются как результат SQL-запроса из этой базы данных. Если впоследствии вы захотите изменить настройки системы, необходимо будет воспользоваться специальными средствами Rocks, которые сначала изменяют базу данных, а затем выполняют процедуры обновления системных файлов. Это значительно уменьшает вероятность ошибиться при настройке кластера. Хотя и можно редактировать эти автоматически созданные системные файлы, но этого делать не рекомендуется, потому что при следующей отработке средств настройки Rocks ваши изменения будут перезаписаны.
На следующем экране (см. рисунок 6) можно ввести информацию о своем кластере. Если кластер соединен с вашей корпоративной сетью, необходимо ввести полное доменное имя главного узла. Название кластера, которое нужно ввести в поле Cluster Name, будет фигурировать на экранах управления кластером в процессе его работы. Когда вы убедитесь, что все ввели верно, нажмите Next. Дальше будем настраивать сетевое соединение главного узла (eth0).
Рисунок 6. Информация о кластере
Шаг 8. Настроить сеть кластера
На следующем шаге (см. рисунок 7) нужно настроить внутреннюю сеть кластера. В процессе установки интерфейсу eth0 главного узла автоматически назначается IP-адрес 10.1.1.1. Эта подсеть принадлежит к диапазону частных адресов, поэтому вам вряд ли придется ее менять. Однако если в вашей сети уже есть подсеть вида 10.1.X.X, то нужно сменить предлагаемую настройку на что-либо другое, что не будет конфликтовать с вашей существующей сетью. Нажмите Next, чтобы перейти к экрану настройки публичной сети главного узла.
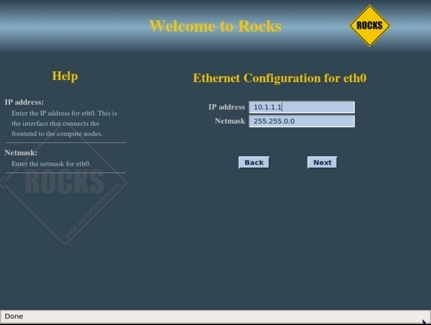
Рисунок 7. Настройка сети
Шаг 9. Настроить публичную сеть
Рисунок 8 показывает настройку «публичного» соединения главного узла — это его соединение с другими компьютерами вашей корпоративной сети. Публичному соединению должен быть сопоставлен статический IP-адрес. В этом примере публичная сеть имеет вид 192.168.0.X с маской 255.255.255.0. Убедитесь, что публичный IP-адрес, назначаемый главному узлу, не будет конфликтовать с другими серверами и рабочими станциями. На следующем экране (см. рисунок 9) указаны IP-адреса шлюза по умолчанию и DNS-сервера для главного узла.
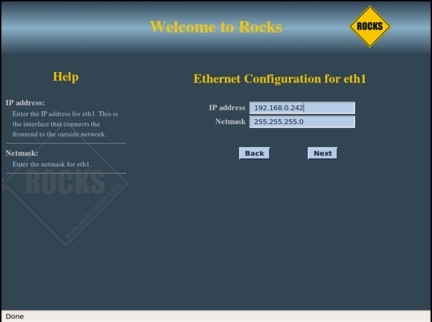
Рисунок 8. Настройка публичной сети главного узла
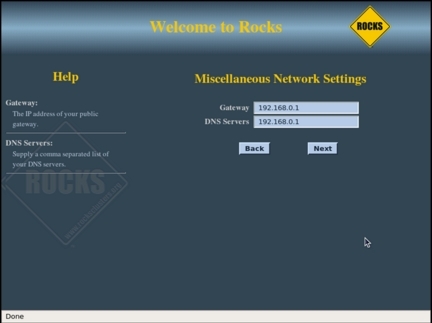
Рисунок 9. Шлюз главного узла и настройки DNS
Шаг 10. Задать пароль root и временную зону
На следующих двух экранах (см. рисунки 10 и 11) нужно будет ввести пароль пользователя root, выбрать временную зону и указать NTP-сервер, с которым будет синхронизироваться главный узел.
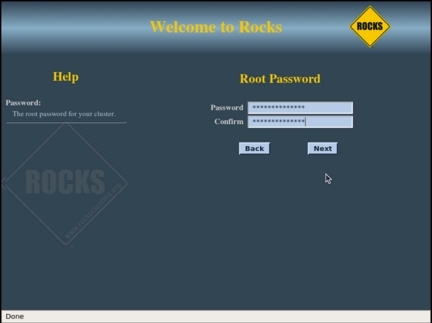
Рисунок 10. Пароль пользователя root
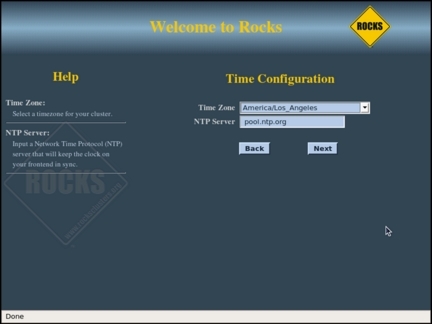
Рисунок 11. Временная зона и NTP-сервер Замечание о времени
Часы всех компьютеров кластера должны быть синхронизированы как можно более точно. Эту проблему полностью решает протокол NTP (Network Time Protocol). Главный узел синхронизирует свое время с одним из публичных NTP-серверов, и в то же время служит сервером времени для машин в локальной сети кластера. Если время на какой-то машине идет слишком медленно или, наоборот, слишком быстро, демон NTP слегка ускорит или замедлит ход часов, таким образом на всех машинах кластера обеспечивается одинаковое системное время.
Шаг 11. Разбить диск на разделы
Последним экраном процесса установки (см. рисунок 12) будет экран разбиения диска на разделы. Можно разбить диск автоматически, либо вручную. Если вы предпочтете автоматическое разбиение, процедура установки разобъет диск следующим образом:
Если на вашем главном узле несколько дисков, и вы хотите переразбить диск по-другому, выбирайте Manual Partitioning. Откроется стандартный (Red Hat) экран разбиения диска, где вы сможете разбить диск как вам захочется (но как минимум потребуется 16 Гб на корневой раздел /, а также нужно создать раздел /export). Когда нажмете здесь Next, начнется автоматическая часть установки (см. рисунки 13-15). По завершении установки главный узел перезагружается, и система встречает вас приветственным экраном (см. рисунок 16).
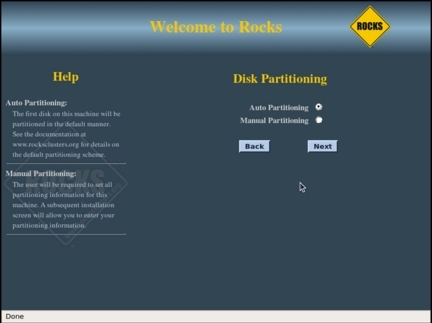
Рисунок 12. Разбиение диска

Рисунок 13. Установка Rocks, момент 1
Рисунок 14. Установка Rocks, момент 2
Рисунок 15. Установка Rocks, момент 3
Рисунок 16. Вход в систему
Шаг 12. Войти в систему
Зайдите в систему как root и подождите две-три минуты. Это время нужно для завершения фоновых процедур, донастраивающих кластер. Запустите сессию терминала (см. рисунок 17), сейчас мы приступим к добавлению узлов к нашему кластеру.
Рисунок 17. Терминал пользователя root
Шаг 13. Установить вычислительный узел
Теперь мы готовы добавлять узлы в кластер. В Rocks для этого имеется команда insert-ethers . У нее немало опций, но в данном примере просто нужно воспользоваться основной функцией добавления узлов в кластер. После вызова команды вы увидите экран, как на рисунке 18.
Рисунок 18. Работает программа insert-ethers
Все, что может быть подключено к сети, Rocks определяет как «устройство» (appliance). Если нечто отвечает на сетевую команду, то это устройство. В нашем случае из устройств будут только вычислительные узлы. На предыдущем экране (см. рисунок 18) уже выбрано Compute, поэтому выбирайте кнопку OK и нажимайте Enter. Появится пустой список, заполненный именами и MAC-адресами узлов, список будет пополняться по мере их добавления (см. рисунок 19).
Рисунок 19. Список установленных устройств (здесь пустой)
Шаг 14. Первый вычислительный узел
Пришла пора запустить первый вычислительный узел. После очистки диска, в большинстве случаев система будет производить PXE-загрузку из сети. Если у вас есть KVM-переключатель, можно зайти на консоль этого узла и своими глазами увидеть процесс сетевой загрузки. Когда вычислительный узел запрашивает IP-адрес для своего интерфейса eth0, его MAC-адрес отобразится в списке Inserted Appliances главного узла (см. рисунок 20).
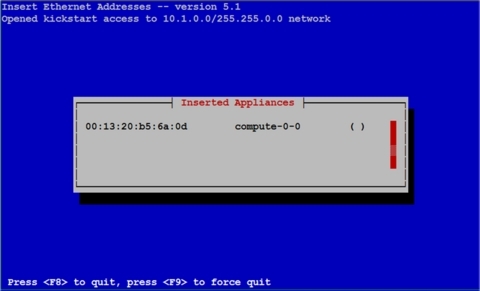
Рисунок 20. Список установленных устройств (добавлен первый узел)
Процедура insert-ethers выводит принятые MAC-адреса и соответствующие имена узлов. Когда узел начнет скачивать свой образ (см. рисунок 21), пустое место ( ) заполнится звездочкой (*) .
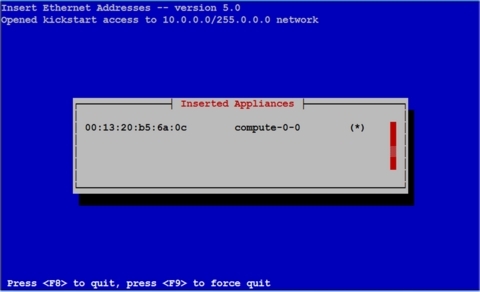
Рисунок 21. Запуск первого узла
Шаг 15. Остальные вычислительные узлы
Запустите аналогичным образом все остальные вычислительные узлы. При подключении большего количества узлов список будет выглядеть как на рисунке 22.
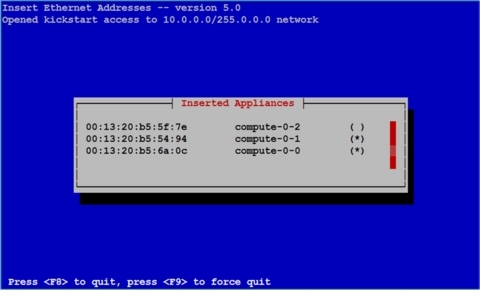
Рисунок 22. Список установленных устройств (добавлено три узла)
Когда последний узел кластера перезагрузится в конце процесса загрузки, нажмите клавишу F8 на главном узле, и установка будет закончена.
Шаг 16. Быстрая проверка работоспособности
Теперь ваш кластер установлен и готов к работе. Первым делом надо проверить работоспособность кластерной функции cluster-fork. Она позволяет запускать одно и то же приложение на всех узлах или подмножестве узлов кластера. На рисунке 23 показан результат выполнения команды uname с помощь cluster-fork.
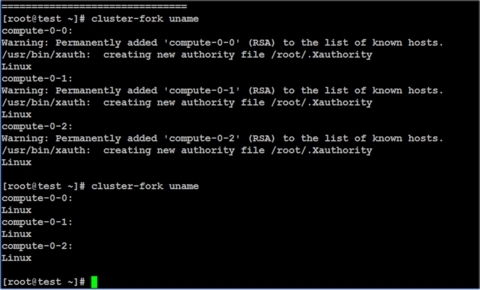
Рисунок 23. Запуск uname через cluster-fork
При первом вызове система добавляет узлы кластера в списки разрешенных хостов. В последующие разы вызов будет просто выполнять необходимую программу. Как видно из рисунка, все узлы кластера живы и готовы к работе.
При желании можно провести более всестороннюю проверку с помощью пакета Intel Cluster Checker. Это приложение полезно как для новых кластеров, так и как средство постоянного контроля существующих кластеров.
Шаг 17. Установить кластерное ПО
Итак, ваш кластер работоспособен, пришла пора увидеть всю его мощь. Довольно интересно параллельное приложение NAMD — симулятор молекулярной динамики от университета штата Иллинойс. Присоединив к нему графический интерфейс VMD, можно сразу получить готовую кластерную среду для химических исследований.
Вывод
Когда рабочая станция не справляется, одним из возможных решений является создание кластера. Правильно настроенный кластер обеспечивает необходимую вычислительную мощность. Хотя возможно настроить кластер вручную, но гораздо удобнее воспользоваться специализированным пакетом, который поможет быстро развернуть и настроить кластерную систему.
Источники информации
Darik’s Boot and Nuke: www.dban.org
Том Леманн (Tom Lehmann) уже более 30 лет работает в корпорации Intel, связан со многими областями компьютерной индустрии. Последние 10 лет его карьеры в Intel он занимается высокопроизводительными вычислениями, и в частности, высокопроизводительными кластерами. На данный момент он является консультантом, работающим над архитектурами систем, интеграцией кластеров Linux-Windows и эмулятором мейнфрейма на базе Linux под названием Hercules. Том, его жена и две его таксы живут в Лас-Вегасе.
Источник



