- Небольшое руководство по ZFS
- ZFS on Linux: практика применения
- Обзор возможностей
- Аппаратные потребности
- Терминология
- Модели именования устройств
- Включение поддержки ZFS
- Создаём простой пул
- «Избыточные» пулы
- Пул кэшируемый
- О некоторых опциях команды zpool
- Создание файловых систем
- Файловые системы: устанавливаем свойства
- О перемонтировании
- Вместо заключения
- 3 комментария к “ ZFS on Linux: практика применения ”
Небольшое руководство по ZFS
Заметил, что на Хабре много статей про ZFS. И вот, решил написать краткое руководство, как же этой ZFS пользоваться. В качестве ОС буду рассматривать Solaris, т.к. ZFS изначально разрабатывалась для Соляры да и познакомился с ZFS я именно там. Понимаю, что мало у кого стоит Open Solaris на десктопе, а администраторы Solaris и так должны это знать. Но может кому и пригодится.
Для начала, что же такое ZFS и в чем ее преимущества перед существующими файловыми системами.
Приведу лишь краткий список плюсов ZFS.
- ZFS является 128 битной файловой системой. Максимальный размер пула — 16 экзабайт (18млн Терабайт) Максимальное количество файлов в одном пуле — 20х10 12 .
- ZFS является self-healing системой. ZFS использует 256-битный контрольные суммы для проверки данных.
- Позволяет добавлять пулы или же наращивать емкость пула без остановки системы или же приложений
- Очень гибкая организация RAID’ов.
Немного терминологии
- checksum — Контрольная сумма. 256-разрядный хеш-код данных в блоке файловой системы.
- clone — Клон. Файловая система, исходное содержимое которой идентично содержимому снапшота.
- snapshot — Снимок. Образ файловой системы или тома в определенный момент времени, доступный только для чтения.
- dataset — Набор данных. Общее название следующих объектов ZFS: клонов, файловых систем, снимков или томов. Каждый набор данных идентифицируется по уникальному имени в пространстве имен ZFS. Наборы данных определяются с помощью следующего формата: пул/путь[ @снимок]
- pool — Пул. Логическая группа устройств, описывающая размещение и физические характеристики доступного пространства для хранения данных. Из пула берется пространство для наборов данных.
- volume — Том. Набор данных, используемый для эмулирования физического устройства. Например, можно создать том ZFS в качестве устройства подкачки.
Собственно руковдство
В Solaris работа с ZFS идет в основном через 2 команды. Это zpool и zfs.
zpool — работа с пулами. Их создание, изменение, удаление и т.д.
zfs — работа с самой файловой системой.
Итак, из чего же можно создать пул? Да из чего угодно. От файлов под другой фс, до дисков в дисковом массиве.
Примеры создания пула MyPool
# Создание пула из файлов /zfs1/disk01 и /zfs1/disk02 созданных командой mkfile
zpool create MyPool /zfs1/disk01 /zfs1/disk02
# Создание пула используя обычный слайс
zpool create MyPool c1t0d0s0
# Создание пула c зеркалированием и использованием spare дисков.
zpool create MyPool mirror c1t0d0 c2t0d0 mirror c1t0d1 c2t0d1
zpool create MyPool mirror c1t0d0 c2t0d0 spare c3t0d0
Список ваших пулов и их статус можно посмотреть с помощью команда
# zpool list
NAME SIZE USED AVAIL CAP HEALTH ALTROOT
MyPool 191M 94K 191M 0% ONLINE —
zpool status -v
pool: MyPool
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
MyPool ONLINE 0 0 0
/disk1 ONLINE 0 0 0
/disk2 ONLINE 0 0 0
Статусы могут быть следующие
- DEGRADED — Один или несколько устройства верхнего уровня находятся в нерабочем состоянии, т.к. были отключены. Но дальнейшее функционирование возможно.
- FAULTED — Один или несколько устройства верхнего уровня находятся в состоянии FAULT. Дальнейшее функционирование не возможно.
- OFFLINE — Пул был отключен командой «zpool offline».
- ONLINE — Пул находится в состоянии ONLINE и нормально функционирует.
- REMOVED — Устройство (Пул) было физически удалено при работающей системе.
- UNAVAIL — Устройство (Пул) недоступно.
Изменение пула MyPool
#Добавление и удаление элементов (дисков) из пула, не использующего зеркалирование осуществляется с помощью команд:
zpool add MyPool /zfs1/disk3
zpool remove MyPool /disk3
#Добавление и удаление элементов (дисков) из пула, c зеркалированиеv осуществляется с помощью команд:
zpool attach MyPool /disk1 /disk3
zpool detach MyPool /disk1 /disk3
#Ввод элемента в состояние offline с невозможностью чтения/записи до ввода в состояние online (используя ключ -t можно ввести элемент в состояние offline только до ребута)
zpool offline MyPool /disk1
Как это отобразится на Пуле в целом:
zpool status -v
pool: myzfs
state: DEGRADED
status: One or more devices has been taken offline by the administrator.
Sufficient replicas exist for the pool to continue functioning
in a degraded state.
action: Online the device using ‘zpool online’ or replace the device
with ‘zpool replace’.
scrub: resilver completed with 0 errors on Tue Sep 11 13:39:25 2007
config:
NAME STATE READ WRITE CKSUM
myzfs DEGRADED 0 0 0
mirror DEGRADED 0 0 0
/disk1 OFFLINE 0 0 0
/disk2 ONLINE 0 0 0
#И обратно online
zpool online MyPool /disk1
#Замена одного элемента пула на другой
zpool replace MyPool /disk1 /disk3
Создание и работа с файловой системой
#Создаем файловую систему
zfs create MyPool/systemname
опцией -о мы можем выбрать точку монтирования, отличную от /MyPool/systemname
#Резервируем место под свою файловую систему
zfs set reservation=20m MyPool/systemname
#Устанавливаем квоту для вашей файловой системы, которую вы не сможете превысить
zfs set quota=20m MyPool/systemname
#Включаем компрессию.
zfs set compression=on MyPool/systemname
#Расшариваем нашу файловую систему.
zfs set sharenfs=on MyPool/systemname в NFS
zfs set sharesmb=on MyPool/systemname в SMB
#Снимаем снапшот
zfs snapshot MyPool/systemname@hostname
#Так как снапшот — это просто снимок системы в данный момент, то иногда стоит создавать клона.
zfs clone MyPool/systemname@hostnameyPool/systemname2
#Удаляем файловую систему. Если существуют файловые системы-наследники, надо использовать ключ -f
zfs destroy MyPool/systemname
Как видите, ничего сложного с ZFS на начальном этапе нет. Очень и очень гибкая штука.
Источник
ZFS on Linux: практика применения
Алексей Федорчук
Впервые опубликовано: LinuxFormat , #165-166 и #167 (январь и февраль 2013). По техническим причинам журнальная версия статьи была разбита на две части. Здесь размещается в авторской редакции, как единый материал. Более позднее обобщение материалов по ZFS on Linux — здесь.
Настоящая статья посвящена практическому использованию ZFS в Linux — история вопроса была предметом предыдущей статьи. Оно рассмотрено на примере openSUSE, хотя почти всё из сказанного применимо и к любым другим дистрибутивам – все дистроспецифические детали оговорены явным образом.
Обзор возможностей
Прежде чем погружаться в вопросы, связанные с ZFS, читатель, вероятно, хотел бы убедиться в том, что это стоит делать. То есть – ознакомиться с возможностями, которые она ему предоставляет.
Для начала – немного цифр. В отличие от всех предшествовавших файловых систем и систем размещения данных, ZFS является 128-битной. То есть теоретическое ограничение на её объём и объёмы её составляющих превышают не только реальные, но и воображаемые потребности любого пользователя. По выражению создателя ZFS, Джеффа Бонвика [Jeff Bonwick], для её заполнения данными и их хранения потребовалось бы вскипятить океан.
Так, объём пула хранения данных ( zpool – максимальная единица в системе ZFS) может достигать величины 3×10 23 петабайт (а один петабайт, напомню, это 10 15 или 2 50 байт, в зависимости от системы измерения). Каждый пул может включать в себя до 2 64 устройств (например, дисков), а всего пулов в одной системе может быть тоже не больше 2 64 .
Пул может быть разделён на 2 64 наборов данных ( dataset – в этом качестве выступают, например, отдельные файловые системы), по 2 64 каждая. Правда, ни одна из таких файловых систем не может содержать больше 2 48 файлов. Зато размер любого файла ограничивается опять же значением в 2 64 байт.
Количество таких ограничений можно умножить. Как уже было сказано, они лежат вне пределов человеческого воображения и возможностей. И привожу я их только для того, чтобы вселить в пользователя уверенность: ни он сам, ни его внуки и правнуки в реальности не столкнутся c ограничениями на размер файловой системы или отдельного файла, как это бывало при использовании FAT или ext2fs.
Так что перейду к особенностям ZFS, наиболее интересным, по моему мнению, десктопному пользователю. Здесь в первую очередь надо отметить гибкое управление устройствами. В пул хранения данных можно объединить произвольное (в обозначенных выше пределах) число дисков и их разделов. Устройства внутри пула могут работать в режиме расщепления данных, зеркалирования или избыточности с подсчётом контрольных сумм, подобно RAID’ам уровней 0, 1 и 5, соответственно. В пул можно включать накопители, специально предназначенные для кэширования дисковых операций, что актуально при совместном использовании SSD и традиционных винчестеров.
Пул хранения становится доступным для работы сразу после его создания, без рестарта машины. В процессе работы дополнительные диски или разделы, в том числе и устройства кэширования, могут как присоединяться к пулу, так и изыматься из его состава в «горячем» режиме.
Пул хранения может быть разделён на произвольное количество иерархически организованных файловых систем. По умолчанию размер их не определяется, и растёт по мере заполнения данными. Это избавляет пользователя от необходимости расчёта места, потребного под системные журналы, домашние каталоги пользователей и другие трудно прогнозируемые вещи. С другой стороны, не запрещено при необходимости и квотирование объёма отдельных файловых систем – например, домашних каталогов отдельных излишне жадных пользователей.
Файловые системы ZFS также доступны для размещения на них данных сразу после создания, никаких специальных действий по обеспечению их монтирования не требуется. Создание файловых систем внутри пула – процесс предельно простой: разработчики стремились сделать его не сложнее создания каталогов, и это им вполне удалось. Но при этом составляющие пула остаются именно самостоятельными файловыми системами, которые могут монтироваться со своими специфическими опциями, в зависимости от назначения.
Среди других возможностей ZFS, интересных настольному пользователю, можно упомянуть:
- создание снапшотов файловой системы, позволяющих восстановить её состояние в случае ошибки;
- клонирование файловых систем;
- компрессия данных файловой системы и дедупликация (замена повторяющихся данных ссылками на «первоисточник»);
- создание нескольких копий блоков с критически важными данными и, напротив, возможность отключения проверки контрольных сумм для повышения скорости доступа к ним.
В общем, даже если не говорить об быстродействии ZFS (а оно весьма высоко, особенно в многодисковых конфигурациях), перечислять её достоинства можно очень долго. Так долго, что поневоле успеваешь задаться вопросом: а есть ли у неё недостатки?
Разумеется, есть. Хотя большая их часть – скорее особенности: например, ограничения при добавлении или удалении накопителей в пуле, или отсутствие поддержки TRIM.
По большому счёту для пользователя Linux’а у ZFS обнаруживается два кардинальных недостатка: некоторая усложнённость её использования, обусловленная юридическими факторами, и высокие требования к аппаратуре.
Первый недостаток если не ликвидирован, то сглажен трудами Брайана Белендорфа (Brian Behlendorf) со товарищи и майнтайнерами прогрессивных дистрибутивов вкупе с примкнувшими к ним независимыми разработчиками (см. исторический очерк). Аппаратные же претензии ZFS мы сейчас и рассмотрим.
Аппаратные потребности
Итак, ZFS предоставляет пользователю весьма много возможностей. И потому вправе предъявлять немало претензий к аппаратной части – процессору (изобилие возможностей ZFS создает на него достаточную нагрузку), оперативной памяти и дисковой подсистеме.
Впрочем, претензии эти отнюдь не сверхъестественные. Так, процессор подойдёт любой из относительно современных, начиная, скажем, с Core 2 Duo. Минимальный объём памяти определяется в 2 ГБ, с оговоркой, что применение компрессии и дедупликации требуют 8 ГБ и более.
Сама по себе ZFS прекрасно функционирует и на одиночном диске. Однако в полном блеске показывает себя при двух и более накопителях. В многодисковых конфигурациях рекомендуется разнесение накопителей на разные контроллеры: современные SSD способны полностью загрузить все каналы SATA-III, и равномерное распределение нагрузки на пару контроллеров может увеличить быстродействие.
К «железным» претензиям добавляются и притязания программные. В первую очередь, ZFS on Linux требует 64-битной сборки этой ОС, поскольку в 32-разрядных системах действует ограничение на адресное пространство физической памяти. Кроме того, в конфигурации ядра должна быть отключена опция CONFIG_PREEMPT. Поэтому, например, в openSUSE ZFS может использоваться с ядром kernel-default , но не kernel-desktop , каковое, вопреки названию, устанавливается по умолчанию при стандартной настольной инсталляции.
Если вас привлекли достоинства ZFS и не устрашили её «железные» аппетиты, самое время опробовать её в деле. Что потребует знакомства с некоторыми специфическими понятиями.
Терминология
Центральным понятием ZFS является пул хранения данных [ zpool ]. В него может объединяться несколько физических устройств хранения – дисков или дисковых разделов, причём первый вариант рекомендуется. Но не запрещено и создание пула из одного диска или его раздела.
Каждый пул состоит из одного или нескольких виртуальных устройств [ vdev ]. В качестве таковых могут выступать устройства без избыточности (то есть всё те же диски и/или их разделы), или устройства с избыточностью – зеркала и массивы типа RAID-Z.
Зеркальное устройство [ mirror ] – виртуальное устройство, хранящее на двух или более физических устройствах, но при чётном их количестве, идентичные копии данных на случай отказа диска,
RAID-Z – виртуальное устройство на нескольких устройств физических, предназначенное для хранения данных и их контрольных сумм с однократным или двойным контролем чётности. В первом случае теоретически требуется не менее двух, во втором – не менее трёх физических устройств.
Если пул образован устройствами без избыточности (просто дисками или разделами), то одно из vdev , соответствующее ему целиком, выступает в качестве корневого устройства. Пул из устройств с избыточностью может содержать более одного корневого устройства – например, два зеркала.
Пулы, образованные виртуальными устройствами, служат вместилищем для наборов данных [ dataset ]. Они бывают следующих видов:
- файловая система [filesystem] – набор данных, смонтированный в определённой точке и ведущий себя подобно любой другой файловой системе;
- снапшот [ snalishot ] – моментальный снимок текущего состояния файловой системы, доступный только для чтения;
- клон [ clone ] – точная копия файловой системы в момент его создания; создаётся на основе снимка, но, в отличие от него, доступен для записи;
- том [ volume ] – набор данных, эмулирующий физическое устройство, например, раздел подкачки.
Наборы данных пула должны носить уникальные имена такого вида:
Пулы и наборы данных в именуются по правилам пространства имён ZFS, впрочем, довольно простым. Запрещёнными символами для всех являются символы подчёркивания, дефиса, двоеточия, точки и процента. Имя пула при этом обязательно должно начинаться с алфавитного символа и не совпадать с одним из зарезервированных имён – log , mirror , raidz или spare (последнее обозначает имя устройства «горячего» резерва). Все остальные имена, в соответствие с демократическими традициями пространства имён ZFS, разрешены.
А вот об именах физических устройств, включаемых в пул, следует сказать особо.
Модели именования устройств
В современном Linux’е использование для накопителей имён «верхнего уровня», имеющих вид /dev/sda, не является обязательным, а в некоторых случаях и просто нежелательно. Однако правила менеджера устройств udev позволяют определять и другие модели идентификации накопителей. В частности, штатными средствами дисковой разметки openSUSE предусмотрены варианты идентификации по:
- метке тома ( /dev/disk/by-label );
- идентификатору диска ( /dev/disk/by-id );
- пути к дисковому устройству ( /dev/disk/by-path );
- универсальному уникальному идентификатору, Universally Unique IDentifier ( /dev/disk/by-uuid ).
А с полным списком вариантов идентификации блочных устройств можно ознакомиться, просмотрев имена подкаталогов в каталоге /dev/disk , их содержимое – это символические ссылки на имена «верхнего уровня».
С идентификацией по метке тома и по UUID , вероятно, знакомо большинство читателей. И к тому же в пространстве имён ZFS они не используются. А вот с идентификацией by-path и by-id нужно познакомиться поближе.
Модель именования by-path использует имена устройств, привязанные к их положению на шине PCI и включающие номер шины и канала на ней. Имя дискового устройства выглядит примерно так:
Дисковые разделы маркируются добавлением к имени устройства суффикса part# .
Модель именования by-path идентифицирует устройства вполне однозначно, и особенно эффективна при наличии более чем одного дискового контроллера. Однако сами имена и устройств, и разделов описываются довольно сложной для восприятия последовательностью. Да и в большинстве «десктопных» ситуаций модель эта избыточна.
Модель именования by-id представляет имена носителей информации в форме, наиболее доступной для человеческого понимания. Они образованы из названия интерфейса, имени производителя, номера модели, серийного номера устройства и, при необходимости, номера раздела, например:
Таким образом, все компоненты имени устройства в модели by-id определяются не условиями его подключения или какими-то правилам, а задаются производителем и жестко прошиты в «железе». И потому эта модель является наиболее однозначной для именования устройств. А также, что немаловажно, строится по понятной человеку логике. Не случайно именно она принята по умолчанию в инсталляторе openSUSE.
Какую из моделей именования устройств выбрать для данного пула – зависит от его назначения и масштабов. Имена «верхнего уровня» целесообразно применять для однодисковых пулов (особенно если в машине второго диска нет и не предвидится, как обычно бывает в ноутбуках). Они же, по причине простоты и удобопонятности, рекомендуются для экспериментальных и разрабатываемых пулов. И очень не рекомендуются – во всех остальных случаях, так как зависят от условий подключения накопителей.
Этого недостатка лишена модель by-id : как пишет Брайан, при её использовании «диски можно отключить, случайно смешать и подключить опять произвольным образом – и пул будет по-прежнему корректно работать». Как недостаток её рассматривается сложность конфигурирования больших пулов с избыточностью. И потому она рекомендуется для применения в «десктопных» и «квартирных» (типа семейного сервера) условиях.
Для больших (более 10 устройств) пулов из дисков, подключённых к нескольким контроллерам, рекомендуется идентификация by-path . Однако в наших целях она громоздка и избыточна.
Наконец, ZFS on Linux предлагает и собственную модель идентификации – /dev/disk/zpool , в котором именам by-path ставятся в соответствие уникальные и осмысленные «человекочитаемые» имена, даваемые пользователем. Модель эта рекомендуется для очень больших пулов, каковых на настольной машине ожидать трудно.
Так что дальше я буду использовать имена «верхнего уровня», говоря об абстрактных или экспериментальных ситуациях, и об именах by-id , когда речь зайдёт о практических примерах применения ZFS.
Включение поддержки ZFS
Для практического использования ZFS on Linux перво-наперво необходимо обеспечить её поддержку в вашем дистрибутиве – ибо по причинам, описанным в предыдущей статье, сама собой она не поддерживатся ни в одном Linux’е.
Как это сделать, зависит от дистрибутива. В Сети можно найти подробные инструкции для Ubuntu и Gentoo, которые легко распространяются на клоны обеих систем. Не столько инструкции, сколько руководства к самостоятельному действию имеются на сайте проекта ZFS on Linux для абстрактных RPM- и Deb-based дистрибутивов. Я же расскажу о том, как это делается в openSUSE релизов 12.1 и 12.2.
Как вы наверняка догадались, ZFS не поддерживается в openSUSE ни «искаропки», ни в официальных репозиториях. Но зато в репозиториях неофициальных, так называемых «домашних», пакеты её поддержки представлены аж в двух экземплярах: в munix9 и в ghaskins . Точные их адреса легко найти через систему OBS (Open Builging System) по ключевому слову zfs .
Какому из репозиториев отдать предпочтение – вопрос спорный. Первые свои опыты с ZFS on Linux я проводил, основываясь на пакетах из munix9. И они прошли без всяких осложнений, хотя и велись в сугубо экспериментальном режиме. Однако к моменту понимания, что эта система для меня – «всерьёз и надолго», последняя тогда версия zfs имелась только в репозитории ghaskins . Однако его использование требует некоторых дополнительных манипуляций.
Кроме того, в репозитории ghaskins на данный момент имеются пакеты только для openSUSE релизов 12.1 и 12.2. Репозиторий же munix9 охватывает все актуальные ныне версии SLE и openSUSE. включая Tumbleweed и Factory.
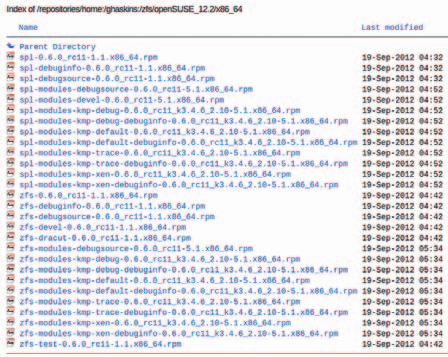
Различаются репозитории и набором пакетов. В ghaskins , кроме «рабочих» модулей zfs и spl для ядра default , можно видеть массу отладочных их сборок (рис. 1).
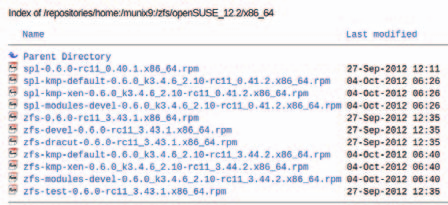
В репозитории munix9 с этим существенно скромнее – имеются модули только для ядра default и для xen (рис. 2)
Так что окончательный выбор я предоставляю читателю. Но на какой бы репозиторий он ни пал, его следует подключить. И сделать это можно любым из трёх способов. Первый – с помощью zypper ’а:
# zypper ar -f [URL] [Name]
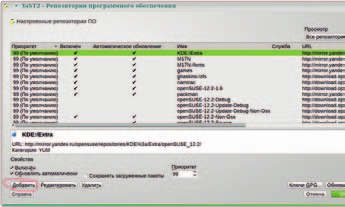
Второй способ – через модуль Репозитории… центра управления YaST2 посредством кнопки Добавить (рис. 3):
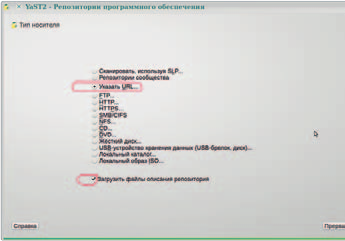
выбора пункта Указать URL (рис. 4):
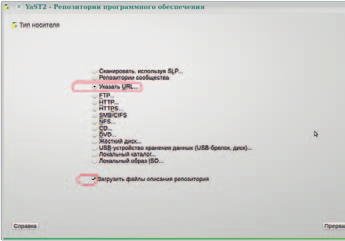
и ввода необходимых значений в поля Имя репозитория и URL (рис. 5):
Наконец, третий способ, для самых ленивых – отыскать пакеты zfs , spl и сопутствующие через OBS и прибегнуть к «установке в один клик». В этом случае подключение репозиториев будет совмещено с установкой пакетов.
В первых двух же вариантах после подключения репозитория надо будет установить (с помощью zypper’а или модуля управления пакетами YaST’а) следующее (пример дан для репозитория munix9 , но из ghaskins потребуются те же компоненты):
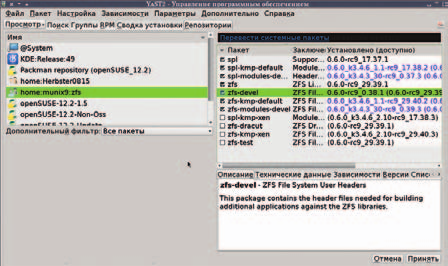
Возможно, не вредным окажется и пакет zfs-test . А вот zfs-dracut , предназначенный для создания initrd с поддержкой ZFS, несмотря на его потенциальную нужность, установить не удастся: требуемый для него пакет dracut в openSUSE пока не поддерживается.
Следует учесть, что при использовании ядра kernel-desktop (а скорее всего, так оно и есть) пакет zfs-kmp-default потянет за собой и соответствующее ядро kernel-default . Пункт загрузки которого будет внесён в меню GRUB, но не будет отмечен как умолчальный – этим надо озаботиться самому.
И, наконец, при использовании пакетов из ghaskins потребуется, скорее всего, сделать в каталогах /etc/init.d/rc3.d и /etc/init.d/rc5.d символические ссылки на файл /etc/init.d/zfs . Иначе файловые системы ZFS, к созданию которых мы приближаемся, не будут автоматически монтироваться при старте и размонтироваться при останове системы.
При использовании репозитория munix9 эти действия будут нечувствительно выполнены в ходе установки пакетов.
Вот теперь можно приступать к применению ZFS в мирных практических целях.
Создаём простой пул
Освоив ранее основные понятия, мы научились понимать ZFS. Для обратной же задачи – чтобы ZFS понимала нас – нужно ознакомиться с её командами. Главные из них – две: zpool для создания и управления пулами, и zfs для создания и управления наборами данных. Немного, правда? Хотя каждая из этих команд включает множество субкоманд, с которыми мы со временем разберёмся.
Очевидно, что работу с ZFS следует начинать с создания пула хранения. Начнём с этого и мы. В простейшем случае однодисковой конфигурации это делается так:
Здесь create – субкоманда очевидного назначня, tank – имя создаваемого пула (оно обычно даётся в примерах, но на самом деле может быть любым – с учётом ограничений ZFS), а dev_name – имя устройства, включаемого в пул. Каковое может строиться по любой из описанных ранее моделей. И, чтобы не повторяться, напомню: все команды по манипуляции с пулами и наборами данных в них выполняются от лица администратора.
В случае, если в состав пула включается один диск, и второго не предвидится, можно использовать имя устройства верхнего уровня – например, sda для цельного устройства (обратим внимание, что путь к файлу устройства указывать не нужно). Однако реально такая ситуация маловероятна: загрузка с ZFS проблематична, так что как минимум потребуется раздел с традиционной файловой системой под /boot (и/или под корень файловой иерархии), так что команда примет вид:
Однако если можно ожидать в дальнейшем подсоединения новых накопителей и их включения в существующий пул, то лучше воспользоваться именем по модели by-id , например:
Очевидно, что в случае однодискового пула ни о какой избыточности говорить не приходится. Однако уже при двух дисках возможны варианты. Первый – создание пула без избыточности:
где dev_name1 и dev_name1 – имена устройств в принятой модели именования.
В приведённом случае будет создано нечто вроде RAID’а нулевого уровня, с расщеплением [ stripping ] данных на оба устройства. Каковыми могут быть как дисковые разделы, так и диски целиком. Причём, в отличие от RAID0, диски (или разделы) не обязаны быть одинакового размера:
После чего никаких сообщений не последует. No news – good news, говорят англичане; в данном случае это означает, что пул был благополучно создан. В чём можно немедленно убедиться двумя способами. Во-первых, в корневом каталоге появляется точка его монтирования /mypool . А во-вторых, этой цели послужит субкоманда status :
которая выведет нечто вроде этого:
А с помощью субкоманды list можно узнать объём новообразованного пула:
Легко видеть, что он равен сумме объёмов обеих флэшек, если «маркетинговые» гигабайты пересчитать в «настоящие».
К слову сказать, если дать субкоманду list без указания аргумента – имени пула, то она выведет информацию о всех пулах, задействованных в системе. В моём случае это выглядит так:
Обращаю внимание, что даже чисто информационные субкоманды вроде list и status требуют прав администратора.
Разумеется, два пула в одной, да ещё и настольной, машине – излишняя роскошь. Так что пул, созданный в экспериментальных целях, подлежит уничтожению, что делается с помощью субкоманды destroy :
После чего он пропадёт из списка пулов. А что можно сделать с пулом до его уничтожения, увидим со временем.
«Избыточные» пулы
Избавившись от ставшего ненужным пула, рассмотрим второй вариант – создание пула с зеркальным устройством. Создаём его из двух накопителей одинакового объёма:
Проверка показывает, что итоговый пул, как и следовало ожидать, равен объёму одного накопителя:
При различии объёмов больший диск будет «обрезан» до объёма меньшего.
Полное зеркалирование любыми, по моему мнению, в настольных условиях – роскошь непозволительная: банальные бэкапы данных проще и надёжнее. Тем не менее, не исключаю, что некоторая избыточность на уровне проверки контрольных сумм может оказаться не лишней, да и не столь накладна. Так что давайте посмотрим и на третий вариант пула из более чем одного устройства – RAID-Z.
Теоретически виртуальное устройство с одинарным контролем чётности, как уже говорилось, можно создать при наличии двух устройств физических. Однако практически это оказывается накладно, особенно если устройства не одинакового размера. Поэтому задействуем под него три накопителя:
что даст нам следующую картину:
Впрочем, как мне кажется, в настольных условиях не стоит выделки и эта овчинка.
Пул кэшируемый
И, наконец, последний вариант организации пула из более чем одного устройства – создание пула с кэшированием. Для чего создаём из двух устройств простой пул без избыточности и подсоединяем к нему устройство для кэша:
Очевидно, что устройство для кэширования не должно входить в пул любого рода – ни в простой, ни в избыточный. Что мы и видим в выводе субкоманды list:
где никаких следов его обнаружить не удаётся. Если же появляются сомнения, а подключилось ли оно на самом деле, обращаемся к субкоманде status , которая покажет беспочвенность наших опасений.
Как я уже говорил в обзоре возможностей ZFS, подключение устройства кэширования имеет смысл при наличии большого традиционного винчестера (или винчестеров) и относительно небольшого SSD, которое и играет роль дискового кэша.
О некоторых опциях команды zpool
Команда zpool поддерживает ещё множество субкоманд, предназначенных для экспорта и импорта пула, добавления к нему устройств и изъятия оных, и так далее. Но сейчас я расскажу о некоторых опциях, которые могут оказаться необходимыми при создании пула.
Одна из важный опций – -f : она предписывает принудительное выполнение данной операции и требуется, например, при создании пула из неразмеченных устройств.
Полезной может оказаться опция -n . Она определяет тестовый режим выполнения определённой субкоманды, то есть выводит результат, например, субкоманды zpool create без фактического создания пула. И. соответственно, сообщает об ошибках, если таковые имеются.
Интересна также опция -m mountpoint . Как уже говорилось, при создании пула по умолчанию в корне файловой иерархии создаётся каталог /pool_name , который в дальнейшем будет точкой монтирования файловых систем ZFS. Возможно, что это окажется не самым лучшим местом для их размещения, и, как мы увидим в дальнейшем, это несложно будет изменить. Но можно задать каталог для пула сразу – например, /home/data : это и будет значением опции -m . Никто не запрещает определить в качестве такового и какой-либо из существующих каталогов, если он пуст, иначе автоматическое монтирование файловых систем пула в него окажется невозможным.
Наконец, нынче важное значение приобретает опция ashift=# , значением которой является размер блока файловой системы в виде степеней двойки. По умолчанию при создании пула размер блока определяется автоматически, и до некоторого времени это было оптимально. Однако затем, с одной стороны, появились диски так называемого Advanced Format, с другой – получили распространение SSD-накопители. И в тех, и в других размер блока равен 4 КБ, хотя в целях совместимости по-прежнему эмулируется блок в 512 байт. В этих условиях автоматика ZFS может работать некорректно, что приводит к падению производительности пула.
Для предотвращения означенного безобразия и была придумана опция ashift . Значение её по умолчанию – 0, что соответствует автоматическому определению размера блока. Прочие же возможные значения лежат в диапазоне от 9 для блока в 512 байт (2 9 = 512) до 16 для 64-килобайтного блока (2 16 = 65536). В интересующем нас случае четырёхкилобайтного блока оно составляет 12 (2 12 = 4096). Именно последнее значение и следует указать явным образом при создании пула из винчестеров AF или SSD-накопителей.
Создание файловых систем
Пулы хранения представляют собой вместилища для наборов данных, для манипуляции которыми предназначена вторая из главнейших команд – zfs. Самыми важными наборами данных являются файловые системы, к рассмотрению которых мы и переходим.
Для создания файловых систем предназначена субкоманда create команды zfs , которая требует единственного аргумента – имени создаваемой ФС и обычно не нуждается ни в каких опциях:
Внутри пула можно создавать сколь угодно сложную иерархию файловых систем. Единственное условие – родительская файловая система для системы более глубокого уровня вложенности должна быть создана заблаговременно. Ниже я покажу это на конкретном примере создания файловых систем внутри каталога /home – наиболее оправданное место для размещения наборов данных ZFS.
Начну я немножечко издалека. При стандартной установке openSUSE не обойтись без создания учетной записи обычного пользователя, и, следовательно, в каталоге /home будет присутствовать по крайней мере один подкаталог – /home/username.
Смонтировать же файловую систему ZFS в непустой каталог невозможно, и, значит, мы не можем сразу прибегнуть к опции -m для определения «постоянной прописки» создаваемого пула.
Поэтому для начала делаем для пула «прописку» во временной точке – пусть это будет традиционный /tank :
Теперь создаём файловую систему для будущего домашнего каталога:
А внутри же неё – необходимые дочерние ветви, как то:
которая потом заменит мой домашний каталог – в нём я не держу ничего, кроме конфигурационных файлов;
это файловая система для моих текущих проектов, и так далее.
Как и было обещано разработчиками ZFS, процедура ничуть не сложнее, чем создание обычных каталогов. Благодаря этому файловые системы можно легко создавать по мере надобности, для решения какой-либо частной задачи. И столь же легко уничтожать их, когда задача эта выполнена. Что делается таким образом:
Использовать субкоманду destroy следует аккуратно: никакого запроса на подтверждение при этом не будет. Правда, и уничтожить файловую систему, занятую в каком-либо текущем процессе, можно только с указанием опции -f , а файловую систему, содержащую системы дочерние, не получится убить и таким образом.
Ни в какой специальной операции монтирования новообразованные файловые системы не нуждаются – оно происходит автоматически в момент их создания, о чём свидетельствует следующая команда:
Для обеспечения монтирования файловых систем ZFS при рестарте машины не требуется и никаких записей в файле /etc/fstab : это также происходит само собой, совершенно нечувствительно для пользователя. Правда, если для файловой системы ZFS определить свойство mountpoint=legacy , то с ней можно управляться и традиционным способом.
Как и для обычного каталога, объём каждой файловой системы ничем не лимитирован, и в момент создания для любой из них потенциально доступно всё пространство пула, которое равномерно уменьшается по мере разрастания файловых систем. На данный момент в моей системе это выглядит так.
Казалось бы, для тех же целей можно ограничиться обычными каталогами. Однако в наборах данных ZFS мы имеем дело с полноценными файловыми системами, для которых могут быть установлены индивидуальные свойства, аналогичные опциям монтирования файловых систем традиционных. Чем мы сейчас и займёмся.
Файловые системы: устанавливаем свойства
При создании файловая система ZFS получает по умолчанию определённый набор свойств, во многом сходный с атрибутами традиционных файловых систем, определяемыми опциями их монтирования. Полный их список можно получить командой
Свойств этих очень много, однако далеко не все они представляют для нас интерес. Важно только помнить, что любое из свойств каждой файловой системы можно поменять с помощью субкоманды set и её параметра вида свойство=значение . Причём изменение свойств для материнской системы рекурсивно распространяется на все дочерние. Однако для любой последней свойства можно изменить в индивидуальном порядке. Что я сейчас и проиллюстрирую на примерах.
Так, абсолютно лишним представляется свойство atime , то есть обновление времени последнего доступа к файлам. Оно, во-первых, снижает быстродействие, с другой – способствует износу SSD-накопителей (правда, нынче и то, и другое чисто символичны). Так что отключаем это свойство для всех файловых систем:
Аналогичным образом расправляемся и со свойством xattr :
А вот дальше можно заняться и индивидуализацией. Как я уже говорил, в момент создания файловые системы ZFS «безразмерны». Если это не подходит, для них можно установить квоты. Однако я этого делать не буду – в моём случае это приводит к потере половины смысла ZFS. А вот зарезервировать место для критически важных каталогов, дабы его не отъела, скажем, мультимедиа, известная своей прожорливостью, будет не лишним. И потому я для файловых систем tank/home/proj и tank/home/alv устанавливаю свойство reservation. Для файловой системы проектов оно будет максимальным:
Для остальных ограничусь более скромным гигабайтом резерва.
Далее, поскольку данные в файловой системе tank/home/proj для меня действительно важны, и шутить с ними я склонен даже гораздо меньше, чем с дамами, предпринимаю дополнительные меры по их сохранности путём удвоения числа копий (по умолчанию оно равно 1):
А для данных не столь важных – тех, что часто проще скачать заново, нежели отыскать на локальной машине, можно выполнить и обратную операцию – отказаться от подсчёта контрольных сумм:
Для файловых систем, содержащих хорошо сжимаемые данные (например, для моего домашнего каталога, где лежат одни dot-файлы), можно включить компрессию:
Я этого не делал: экономия места получается грошовая, а нагрузка на процессор и расход памяти, как говорят, очень приличные. Однако это свойство целесообразно включать в системах с огромными логами, если выделить под них файловую систему в пуле ZFS.
При желании для некоторых файловых систем (например, того же домашнего каталога) можно отключить такие свойства, как exec , setuid , devices – легко догадаться, что результат будет аналогичен указанию опций монтирования noexec , nosuid , nodev для традиционных файловых файловых систем. И, разумеется, для файловых систем, изменение которых нежелательно, можно придать свойство readonly .
Все необходимые свойства файловых систем желательно установить до их наполнения контентом, ибо многие из них (например, компрессия) обратной силы не имеют.
О перемонтировании
После создания файловых систем и задания всех необходимых их свойств наступает психологический момент для перемонтирования их по месту «постоянной прописки» – то есть в каталог /home . Что потребует некоторых подготовительных действий.
Поскольку предполагается, что все новообразованные файловые системы должны быть полностью доступны обычному пользователю (то есть мне, любимому), перво-наперво следует изменить атрибуты из принадлежности – ведь создавались они от имени администратора и принадлежат юзеру по имени root . Для чего даю команду:
Теперь нужно скопировать конфиги из каталога /home/alv в /tank/home/alv :
не забыв про опцию -p для сохранения атрибутов.
Все предыдущие операции можно было выполнять, получив права администратора с помощью команды su (или, при желании, sudo ). Причём где угодно – в текстовом виртуальном терминале или в терминальном окне Иксового сеанса (например, в Konsole KDE). Теперь же потребуется переавторизоваться в «голой» консоли.
Монтирование файловых систем ZFS в каталог с любым содержимым невозможно, так что требуется очистить каталог /home от следов прежней жизнедеятельности пользователя таким образом:
При хоть одном активном пользовательском процессе в ответ на это последует сообщение об ошибке. Так что, возможно, перед этим придётся убить все реликтовые процессы, запущенные в Иксах от имени пользователя. Сначала выявляем их командой
обращая внимание на идентификаторы процессов ( PID ). А затем последовательно мочим их в сортире:
Выполнив все указанные действия, определяем для набора данных tank/home свойство mountpoint, что и осуществит перемонтирование:
Теперь остаётся только с помощью команды ls убедиться, что в /home появились новые подкаталоги с нужными атрибутами:
покажет нам новые точки монтирования файловых систем:
Как я уже говорил выше, при использовании пакетов из репозитория munix9 на этом дело с подготовкой файловых систем ZFS к практической работе можно считать законченным: при перезагрузке машины все они будут благополучно смонтированы в автоматическом режиме. Пакеты же из ghaskins потребуют ещё одного деяния – создания в каталогах /etc/init.d/rc3.d и /etc/init.d/rc5.d символических ссылок на файл /etc/init.d/zfs.
Вместо заключения
За чертой статьи остались многие вопросы применения ZFS, в частности, экспорта и импорта пулов, совместного использования наборов данных в разных дистрибутивах Linux’а (и, возможно, не только его), создания снапшотов и клонов, восстановления после сбоев. Очень интересно изучить проблему размещения на ZFS корня файловой иерархии и возможность загрузки с неё. Однако надеюсь, что рассказанное на предыдущих страницах позволит читателю оценить достоинства ZFS как универсальной комплексной системы размещения данных. Полагаю, что приведённых сведений будет достаточно и для начала практической работы с ней.
3 комментария к “ ZFS on Linux: практика применения ”
«Так, объём пула хранения данных (zpool – максимальная единица в системе ZFS) может достигать величины 3×1023 петабайт (а один петабайт, напомню, это 1015 или 250 байт, в зависимости от системы измерения). Каждый пул может включать в себя до 264 устройств (например, дисков), а всего пулов в одной системе может быть тоже не больше 264.
Пул может быть разделён на 264 наборов данных (dataset – в этом качестве выступают, например, отдельные файловые системы), по 264 каждая. Правда, ни одна из таких файловых систем не может содержать больше 248 файлов. Зато размер любого файла ограничивается опять же значением в 264 байт.»
Что-то вырезало все циркумфлексы.
ага…
«ни одна из таких файловых систем не может содержать больше 248 файлов. Зато размер любого файла ограничивается опять же значением в 264 байт…
…в реальности не столкнутся c ограничениями на размер файловой системы или отдельного файла, как это бывало при использовании FAT или ext2fs»
о чём тута?
Источник



