- Linux Sandboxing
- Layered approach
- Sandbox types summary
- The setuid sandbox
- User namespaces sandbox
- The seccomp-bpf sandbox
- The seccomp sandbox
- SELinux
- Developing and debugging with sandboxing
- Linux-vserver или каждому сервису по песочнице
- Настройка корневой системы для запуска linux-vserver
- Создание нового vserver’а
- Linux Sandbox
- Linux особенности песочниц
- Cuckoo Sandbox
- LiSA Sandbox
- Limon Sandbox
- drakvuf Sandbox
- Detux
Linux Sandboxing
Chromium uses a multiprocess model, which allows to give different privileges and restrictions to different parts of the browser. For instance, we want renderers to run with a limited set of privileges since they process untrusted input and are likely to be compromised. Renderers will use an IPC mechanism to request access to resource from a more privileged (browser process). You can find more about this general design here.
We use different sandboxing techniques on Linux and Chrome OS, in combination, to achieve a good level of sandboxing. You can see which sandboxes are currently engaged by looking at chrome://sandbox (renderer processes) and chrome://gpu (gpu process).
We have a two layers approach:
- Layer-1 (also called the “semantics” layer) prevents access to most resources from a process where it’s engaged. The setuid sandbox is used for this.
- Layer-2 (also called “attack surface reduction” layer) restricts access from a process to the attack surface of the kernel. Seccomp-BPF is used for this.
You can disable all sandboxing (for testing) with —no-sandbox .
Layered approach
One notable difficulty with seccomp-bpf is that filtering at the system call interface provides difficult to understand semantics. One crucial aspect is that if a process A runs under seccomp-bpf , we need to guarantee that it cannot affect the integrity of process B running under a different seccomp-bpf policy (which would be a sandbox escape). Besides the obvious system calls such as ptrace() or process_vm_writev() , there are multiple subtle issues, such as using open() on /proc entries.
Our layer-1 guarantees the integrity of processes running under different seccomp-bpf policies. In addition, it allows restricting access to the network, something that is difficult to perform at the layer-2.
Sandbox types summary
| Name | Layer and process | Linux flavors where available | State |
|---|---|---|---|
| Setuid sandbox | Layer-1 in Zygote processes (renderers, PPAPI, NaCl, some utility processes) | Linux distributions and Chrome OS | Enabled by default (old kernels) and maintained |
| User namespaces sandbox | Modern alternative to the setuid sandbox. Layer-1 in Zygote processes (renderers, PPAPI, NaCl, some utility processes) | Linux distributions and Chrome OS (kernel >= 3.8) | Enabled by default (modern kernels) and actively developed |
| Seccomp-BPF | Layer-2 in some Zygote processes (renderers, PPAPI, NaCl), Layer-1 + Layer-2 in GPU process | Linux kernel >= 3.5, Chrome OS and Ubuntu | Enabled by default and actively developed |
| Seccomp-legacy | Layer-2 in renderers | All | Deprecated |
| SELinux | Layer-1 in Zygote processes (renderers, PPAPI) | SELinux distributions | Deprecated |
| AppArmor | Outer layer-1 in Zygote processes (renderers, PPAPI) | Not used | Deprecated |
The setuid sandbox
Also called SUID sandbox, our main layer-1 sandbox.
A SUID binary that will create a new network and PID namespace, as well as chroot() the process to an empty directory on request.
To disable it, use —disable-setuid-sandbox . (Do not remove the binary or unset CHROME_DEVEL_SANDBOX , it is not supported).
User namespaces sandbox
The namespace sandbox aims to replace the setuid sandbox. It has the advantage of not requiring a setuid binary. It’s based on (unprivileged) user namespaces in the Linux kernel. It generally requires a kernel >= 3.10, although it may work with 3.8 if certain patches are backported.
Starting with M-43, if the kernel supports it, unprivileged namespaces are used instead of the setuid sandbox. Starting with M-44, certain processes run in their own PID namespace, which isolates them better.
The seccomp-bpf sandbox
Also called seccomp-filters sandbox.
Our main layer-2 sandbox, designed to shelter the kernel from malicious code executing in userland.
Also used as layer-1 in the GPU process. A BPF compiler will compile a process-specific program to filter system calls and send it to the kernel. The kernel will interpret this program for each system call and allow or disallow the call.
To help with sandboxing of existing code, the kernel can also synchronously raise a SIGSYS signal. This allows user-land to perform actions such as “log and return errno”, emulate the system call or broker-out the system call (perform a remote system call via IPC). Implementing this requires a low-level async-signal safe IPC facility.
seccomp-bpf is supported since Linux 3.5, but is also back-ported on Ubuntu 12.04 and is always available on Chrome OS. See this page for more information.
See this blog post announcing Chrome support. Or this one for a more technical overview.
This sandbox can be disabled with —disable-seccomp-filter-sandbox .
The seccomp sandbox
Also called seccomp-legacy . An obsolete layer-1 sandbox, then available as an optional layer-2 sandbox.
Deprecated by seccomp-bpf and removed from the Chromium code base. It still exists as a separate project here.
SELinux
Deprecated. Was designed to be used instead of the SUID sandbox.
Old information for archival purposes:
One can build Chromium with selinux=1 and the Zygote (which starts the renderers and PPAPI processes) will do a dynamic transition. audit2allow will quickly build a usable module.
Available since r26257, more information in this blog post (grep for ‘dynamic’ since dynamic transitions are a little obscure in SELinux)
Developing and debugging with sandboxing
Sandboxing can make developing harder, see:
Источник
Linux-vserver или каждому сервису по песочнице
Недавно на хабре публиковались статьи о openvz и lxc. Это напомнило мне, что эта статья всё еще валяется в sandbox’е…
Для целей размещения проектов я применяю такую схему: каждый сервис запускается в изолированной среде: боевой — отдельно, тестовый — отдельно, телефония — отдельно, веб — отдельно. Это снижает риски взлома систем, позволяет бакапить всё и вся одним rsync’ом на соседний сервер по крону, а в случае слёта железа просто поднять на соседнем железе. (А использование drbd + corosync позволяет это делать еще и автоматически)
Для создания изолированной среды есть два подхода, именуемые VDS (виртуализация аппаратуры) и VPS/jail (виртуализация процессного пространства).
Для создания VDS изоляций применяют XEN, VirtualBox, VMWare и прочие виртуальные машины.
Для создания VPS на linux используется либо linux-vserver, либо openvz, либо lxc.
Плюсы VDS: система внутри может быть совершенно любой, можно держать разные версии ядер, можно ставить другую ОС.
Минусы VDS: высокие потери производительности на IO, избыточное потребление CPU и RAM на сервисы, дублирующие запущенные на серверной ОС.
Плюсы VPS: крайне низкая потеря производительности, только на изоляцию, запускаются только те сервисы, которые реально необходимы.
Минусы VPS: можно запустить только linux и ядро будет только той версии, что уже запущено.
Так как мне не нужны разные ОС, то всюду применяю linux-vserver (так уж сложилось исторически, применяю с 2004го года, а openvz вышел в открытый доступ в 2005м), а lxc в моём понимании еще не дорос до продакшена (хотя и очень близок уже).
Приведу цитату из FAQ:
«What is the status of Linux-VServer?
Linux-VServer has more than a decade of maturity and is actively developed. Two projects are similar to Linux-VServer, [LXC], and [OpenVZ]. Of the two, OpenVZ is the more mature and offers some similar functionality to Linux-VServer. LXC is solely based on the kernel mechanisms such as cgroups that are present in modern kernels. These kernel mechanisms will continue to be refined and isolation will mature. As that occurs, Linux-VServer will take advantage of those new features separately from LXC and continue to provide the same robust user interface that it does currently. Currently, LXC offers significantly less functionality and isolation than Linux-vserver. LXC will eventually be a robust wrapper around kernel mechanisms but is still under heavy development and not considered ready for production use.»
Ниже я опишу базовые операции по запуску LAMP сервера в изолированном окружении.
ОС: debian-stable, 64bit
Начиная с Wheezy поддержка vserver командой debian убрана, поэтому использую ядра с repo.psand.net/info
Настройка корневой системы для запуска linux-vserver
После установки — ребут в новое ядро.
Что мы сделали:
- Установили ядро с поддержкой linux-vserver, установили утилиты для создания/управления vserver’ами.
- Установили мой модуль nss_vserver[1] и vslogin, который позволяет логиниться по ssh напрямую внутрь vserver’а
- Настроили интерфейс dummy0, чтобы создать «приватную» сеть для виртуальных машин.
Это позволяет использовать один IP сервера для запуска различных сервисов, разделяя их по логину (например, чтобы войти рутом в виртуальную машину web надо просто логиниться как web-root либо как root@web).
После этого на сервере можно запускать новые сервера, привязывая их к dummy0 интерфейсу.
Всё хорошо, но созданные сервера отвечают на 192.168.1.x, а надо чтобы он был доступен извне.
Для решения этого, на руте нам понадобится еще nginx:
Это позволяет все приходящие запросы на 80й порт раскидывать по разным виртуальным машинам в зависимости от имени.
При необходимости, можно использовать proxy_pass на другой внешний IP, что позволяет перемещать виртуальные сервера по разным машинам без необходимости ожидать полного обновления DNS записей, но это тема для отдельного разговора.
Теперь нам надо создать новую виртуальную машину (номер 57, имя web) в которой установим LAMP.
Создание нового vserver’а
Это устанавливает базовую систему, делает её автозапускаемой при ребуте корневой системы.
Теперь виртуалка готова к установке в неё необходимого софта. Например, обычный LAMP:
Всё! Теперь у вас на сервере работает апач в совершенно изолированной среде.
К проблемам этого подхода относятся:
1. Прямой вход внутрь виртуальных серверов возможен только по паролю.
2. На корневой системе никому нельзя давать доступа, поэтому на корневой системе должен стоять только проверенный минимум софта (ssh, nginx, iptables и больше ничего).
3. При необходимости прямого доступа до каких-либо портов внутри виртуальных машин, проброс нужно делать с помощью iptables.
Моменты, оставленные за кадром для простоты статьи
1. /var/lib/vservers/* желательно размещать на lvm, чтобы иметь возможность управлять выделением места для виртуальных машин независимо.
2. Управление ресурсами: просто созданная виртуальная машина может съесть все ресурсы машины. Подробнее о настройке лимитов linux-vserver.org/Resource_Limits
3. /tmp/. Внутри виртуалок по умолчанию /tmp/ создаётся как ramdisk в 16m размером. Либо сразу перед «vserver $NAME start» исправить /etc/vservers/$NAME/fstab
4. Полезные сведения, информацию и прочее про linux-vserver можно найти на linux-vserver.org
Если будут полезные вопросы, развернутые ответы на них буду выносить в топик.
Источник
Linux Sandbox
Для будущих студентов курса «Administrator Linux. Professional» и всех интересующихся подготовили статью, автором которой является Александр Колесников.
Цель данной статьи показать какие проекты существуют на сегодняшний день для автоматического анализа исполняемых файлов для ОС Linux. Предоставленная информация может быть использована для развертывания тестового стенда для анализа вредоносного кода. Тема может быть актуальна для администраторов и исследователей вредоносного программного обеспечения.
Linux особенности песочниц
Основная проблема песочниц ОС Linux для анализа приложений это ограниченная поддержка процессоров, на которых работает операционная система. Так как использовать для каждой архитектуры свою физическую машину весьма дорого. То как компромисс используют виртуализированные решения типа Hyper-V, VMWare или VBox. Эти решения достаточно хорошо справляются со своей задачей, но они позволяют проводить виртуализацию только на той архитектуре, на которой работает основной хост. Чтобы запустить код для ARM, MIPS и других архитектур, придется обращаться к другим продуктам, которые могут эмулировать необходимые команды процессора. Попробуем собрать как можно больше проектов и посмотреть какие архитектуры процессоров поддерживаются.
Cuckoo Sandbox
Абсолютным лидером среди бесплатных автоматизированных песочниц долгое время была песочница Cuckoo. Эта песочница позволяет настроить любую популярную платформу для запуска приложений. Песочница оснащена веб интерфейсом, который используется для управления песочницей и для получения результатов работы приложений. Архитектура этой песочницы позволяет писать собственные плагины, которые могут изменять характеристики и поведение песочницы в зависимости от запускаемого файла или установленных дополнительных настроек. Общую схему архитектуры можно найти ниже:
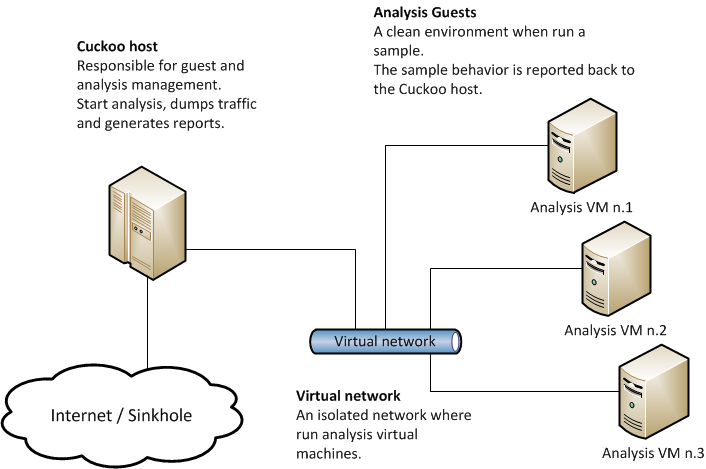
Эта песочница очень популярна для анализа вредоносного программного обеспечения для ОС Windows. Разработчики утверждают, что она так же может работать и с ОС Linux. Разница только будет заключаться в том, что вместо виртуальной машины на Windows, должна быть настроена виртуальная машина на Linux. Попробуем найти еще аналоги.
LiSA Sandbox
Opensource песочница для анализа кода под ОС Linux. Найти репозиторий песочницы можно тут. Документация гласит, что эта песочница может анализировать исполняемые файлы с платформ:
Подобная эмуляция возможна из-за использования эмулятора Qemu. Также песочница предлагает статический и динамический анализ исполняемого файла. Статический анализ производится за счёт инструмента radare2, а динамический за счет специального расширения ядра, которое собирает события взаимодействия с ОС: файловые операции, сетевые взаимодействия, запуск команд и процессов. В документации описывается, что поддержка такого большого количества процессоров позволяет работать с прошивками устройств. То есть можно просмотреть что выполняет программное обеспечение, которое будет записано на IoT устройства. Весьма полезная фича, учитывая, что вредоносы могут быть записаны в образ прошивки устройств и работать там на постоянной основе.
Из особенностей — использование контейнеров Docker. Это качественно ускоряет настройку песочницы. Интерфейс песочницы:
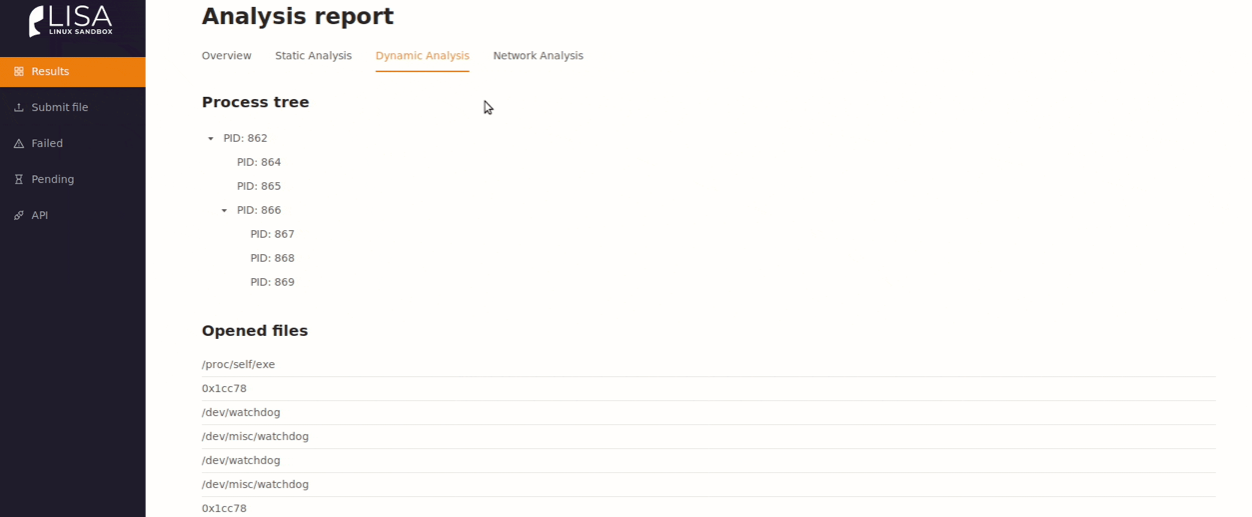
Limon Sandbox
Относительно простой набор скриптов, который используется для анализа приложений. Не имеет возможностей для расширения.(Кроме написания новой логики). Может анализировать приложения теоритически на любом процессоре, так как полностью функционал записан на Python. Найти репозиторий можно здесь. Песочница оперирует следующими инструментами:
Похоже, что данная песочница это просто автоматизированная часть работы аналитика вредоносного программного обеспечения. Вывод скриптов можно увидеть ниже:
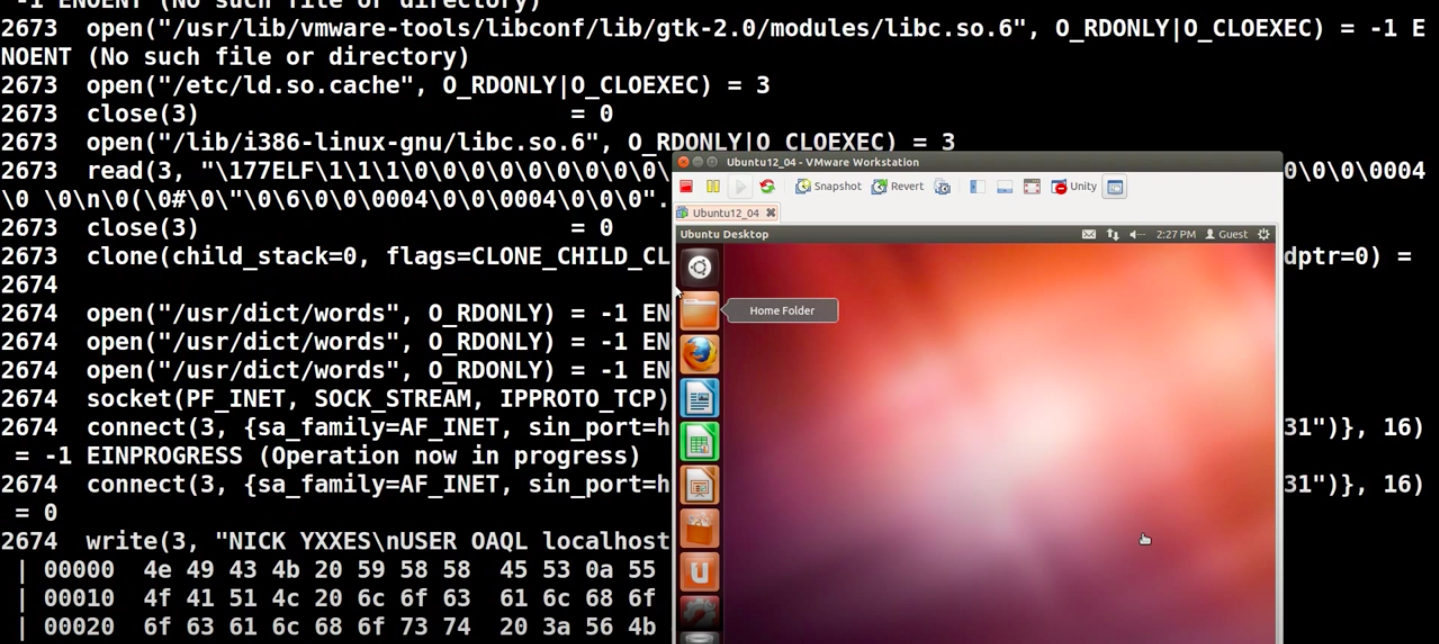
drakvuf Sandbox
Найти репозиторий можно тут. Единственный набор инструментов, который не направлен специально на исследование вредоносного кода. Этот набор используется для изучения программного обеспечения в целом. Записываемые артефакты выполнения приложений настолько подробны, что можно анализировать и вредоносное программное обеспечение. Документация гласит, что этот набор инструментов может работать практически со всеми популярными ОС. Единственное условие, которое нужно выполнить на устройстве — вложенная виртуализация. Все действия песочницы реализуются за счет перехвата системных функций ОС, которая используется в качестве хостовой для исследуемого приложения. К сожалению, для просмотра данных песочницы необходимо самостоятельно парсить данные из json.
Detux
Репозиторий песочницы можно найти здесь. Песочница для анализа вредоносного кода. Умеет анализировать следующие архитектуры:
В качестве базового гипервизора используется проект Qemu. Песочница автоматически собирает трафик и идентификаторы компрометации. Вся информация помещается в отчет. В отличии от аналогов не предоставляет красивого интерфейса, а записывает всё в отчет в формате json.
Как видно из списка выше, выбор хоть и небольшой среди песочниц все-таки есть. Однако, набор инструментов практически везде одинаковый:
кастомный перехватчик для системных вызовов.
Поэтому пользователю придется сделать выбор, будет ли он анализировать данные, которые производит песочница или нет.
Узнать больше о курсе «Administrator Linux. Professional«.
Также приглашаем всех желающих посетить открытый вебинар на тему «Практикум по написанию Ansible роли». В ходе занятия мы научимся писать, тестировать и отлаживать ansible роли. Это важно для тех, кто хочет автоматизировать настройку инфраструктуры, т.к. это один из инструментов, который это позволяет сделать. Присоединяйтесь!
Источник



