- Как пользоваться программой ABBYY FineReader
- Что представляет собой приложение от ABBYY?
- Несколько режимов работы
- Какие ещё есть функции?
- Изменение текста
- Abbyy FineReader — Файн Ридер скачать бесплатно на русском
- При помощи программы Файн Ридер можно:
- Как сканировать и распознать документ:
- Настройки Файн Ридер программы:
- Как это работает: FineReader
- Немного истории
- Базовые принципы
- Процесс распознавания
- Не только OCR
Как пользоваться программой ABBYY FineReader
Один из популярнейших функционалов по работе со сканированием и обработкой файлов различного типа — Файн Ридер. Функционал программного продукта был разработан российской компанией ABBYY, он позволяет не только распознавать, но и обрабатывать документы (переводить, менять форматы и другое). Многие пользователи могут только установить, а как пользоваться ABBYY FineReader, сразу разобраться не могут. На многие вопросы вы сможете найти ответы в этой статье.

Программа позволяет сканировать и распознавать текст — и не только
Что представляет собой приложение от ABBYY?
Чтобы подробно разобраться, что это за программа ABBYY FineReader 12, необходимо подробно рассмотреть все её возможности. Первой и самой простой функцией является сканирование документа. Существует два варианта сканирования: с распознаванием и без него. В случае обычного сканирования печатного листа вы получите изображение, которое сканировали в указанной папке на вашем компьютерном устройстве.

Поместите документ в сканер для того, чтобы перевести его в электронный вид
Вы должны самостоятельно решить, для чего нужен FineReader именно вам, так как утилита имеет значительный функционал, например, вы можете самостоятельно выбрать в каком цвете хотите получить изображение, есть возможность перевести все фото в чёрно-белый. В чёрно-белом цвете распознавание происходит быстрее, качество обработки возрастает.
Если же вас интересует функция распознавания текста ABBYY FineReader, перед сканированием вам нужно нажать специальную кнопку. В этом случае есть несколько вариантов получения информации. Стандартно на ваш экран выведется распознанный кусок листа, который вы сможете скопировать или отредактировать вручную.
Если вы выберите другие функции, то сможете сразу получить файл Word-документом или Excel-таблицей. Выбирать функции очень просто, меню интуитивно понятно, легко настраивается благодаря тому, что все нужные вам кнопки перед глазами.
Несколько режимов работы
Чтобы полностью разобраться, как пользоваться ABBYY FineReader 12, необходимо попробовать два режима работы «Тщательный» и «Быстрое распознавание». Второй режим подходит для высококачественных изображений, а первый — для низкокачественных файлов. Режим «Тщательный» в 3–5 раз дольше обрабатывает файлы.
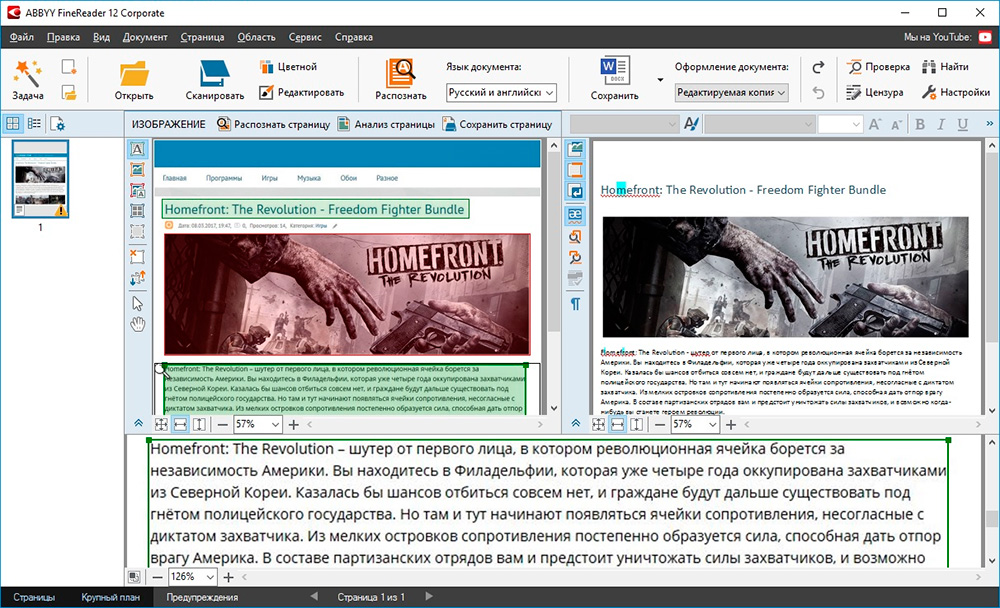
На иллюстрации показан результат работы программы — распознавание текста с изображения
Какие ещё есть функции?
Распознавание текста в программе ABBYY FineReader не единственная полезная функция. Для большего удобства пользователей имеется возможность переводить документ в необходимые пользователю форматы (pdf, doc, xls и др.).
Изменение текста
Чтобы понять, как в Файн Ридере изменить текст, пользователю необходимо открыть вкладку «Сервис» — «Проверка». После этого откроется окно, которое позволит редактировать шрифт, менять символы, цвета и др. Если вы редактируете изображение, то стоит открыть «Редактор изображений», он практически полностью соответствует простой рисовалке Paint, но сделать минимальные правки позволит.
Теперь вы знаете, для каких целей служит программа FineReader, и сможете правильно её применять у себя дома или в офисе. Функционал приложения огромен, воспользуйтесь им и вы сможете убедиться в незаменимости этого программного продукта при обработке документов и файлов во время офисной работы.
Abbyy FineReader — Файн Ридер скачать бесплатно на русском
Abbyy FineReader – это широко известная программа для сканирования документов и распознавания текста. На сегодняшний день она является наиболее популярной благодаря понятному и удобному интерфейсу, большому набору всевозможных функций, связанный со сканированием и работой с готовым документом, а также удобством в использовании.

При помощи программы Файн Ридер можно:
Сканировать любой документ через ваш сканер и после распознать и сохранить для дальнейшего редактирования на компьютере, отправить по электронной почте, сохранить на флешке и т.д. Так же можно переводить изображения, сканы, PDF-файлы, фотографии в другие форматы, например, конвертировать их в таблицы и тексты без необходимости набирать текст заново. При этом распознаются многие форматы изображений, а форматирование текста часто остаётся не тронутым.
Файн Ридер программа для сканирования документов умеет работать со всеми сканерами включая самые популярные такие как Canon (Кэнон), HP, Kyocera (Куосера), Samsung (Самсунг) и другие.

Программа для сканирования может сохранить документ в редакторы — Word (Ворд), Excel (Эксель), OpenOffice, Adobe Acrobat а так же экспортировать файлы в облачные хранилища по вашему выбору.
| Название | Язык | Рейтинг: | Загрузки | |
 | Abbyy FineReader 10 | На Русском | Хорошо 8/10 | Скачать бесплатно >> |
| Abbyy FineReader 11 | На Русском | Очень хорошо 9.7/10 | Скачать бесплатно >> |
| Abbyy FineReader 12 | На Русском | Очень хорошо 9.7/10 | Скачать бесплатно >> |
| Abbyy FineReader 14 | На Русском | Очень хорошо 9.8/10 | Скачать бесплатно >> |
| Abbyy FineReader 15 | На Русском | Очень хорошо 9.8/10 | Скачать бесплатно >> |
Помимо широкого функционала эта программа для скана выпускается более, чем на 170 языках мира, в том числе и на русском. Скорость и эффективность работы, особенно в самой новой версии Abbyy FineReader, удивительны. А улучшенный редактор изображений позволяет сделать предварительную обработку сканов и фотографий.
Можно по своему желанию добавить или снизить яркость и контрастность, скорректировать погрешности, допущенные камерой. Это позволит как можно точнее распознать текст и области рисунков. Удобный и понятный даже впервые столкнувшемуся с программой человеку интерфейс, делает её незаменимым помощником как на рабочем месте, так и дома.
Как сканировать и распознать документ:
Если программа на русском все достаточно просто и понятно, версия скачанная с нашего сайта бесплатна.
На верхней панели достаточно большие значки основных функций, на скрине ниже 11 версия но и в других все примерно одинаково изменены лишь сами значки.
Для того чтоб распознать нужно сначала сканировать со сканера документ либо загрузить картинку например с текстом, после нажать на кнопочку Распознать.
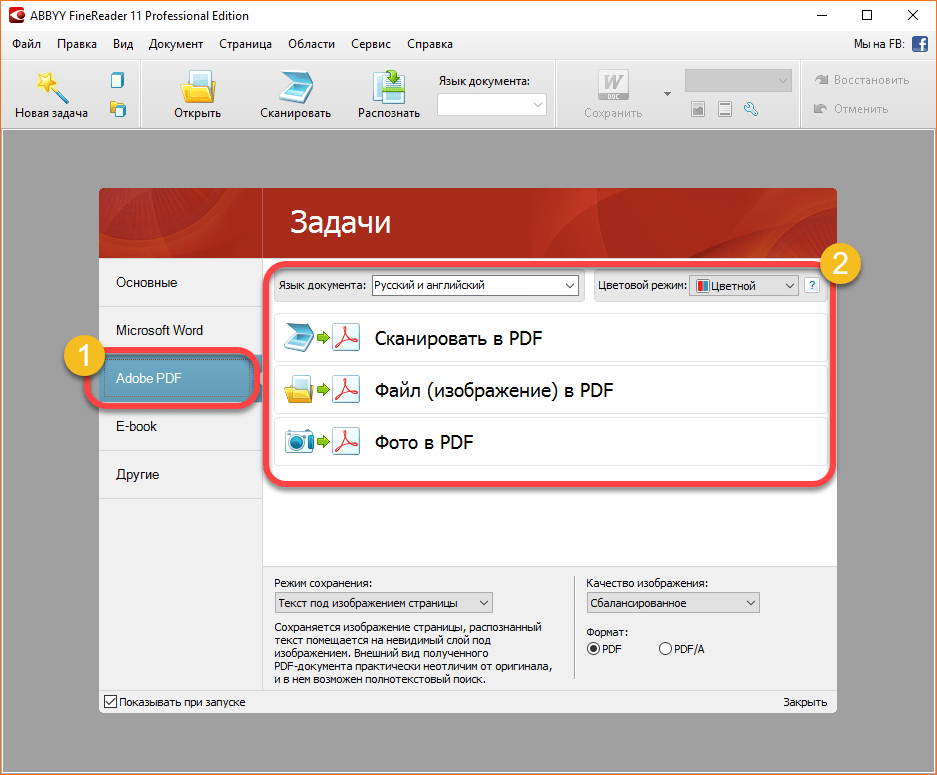
После распознания и корректировки можно сохранять документ в редактируемый а также желаемый формат например ПДФ (PDF).
Настройки Файн Ридер программы:
При обычном использовании например только распознать или только сканировать углубленные настройки вообще не нужны.
Если все же вам необходимы доп. настройки то нажмите Сервис -> Опции. (для версии 11)
Из углубленных функций можно воспользоватся редактором языков если у вас текст который нужно распознать не Русский.
Как это работает: FineReader
Хотя авансы, выданные искусственному интеллекту (ИИ) за последние 50 лет, ни на йоту не приблизили «умные» машины к когнитивным возможностям человека, полностью отрицать успехи в данном направлении было бы несправедливо. Наиболее очевидный и яркий пример — шахматы (не говоря уже о более простых играх). Компьютер пока не может имитировать наше мышление, но он вполне способен компенсировать данный пробел большим объемом специализированной памяти и скоростью перебора. Владимир Крамник охарактеризовал игру победившей его в 2006 г. программы Deep Fritz как «нечеловеческую» в том смысле, что она зачастую противоречила устоявшимся (человеческим) правилам стратегии и тактики.
А чуть более года назад очередное детище IBM, в свое время положившей начало триумфальным шахматным победам компьютеров (знаменитый Deep Blue), под названием Watson совершило новый прорыв, с большим отрывом победив сразу двух чемпионов популярной американской викторины Jeopardy. Показательно, однако, что хотя Watson самостоятельно озвучивал ответы, вопросы ему все же передавались в текстовом виде. Это говорит о том, что успехи во многих сферах приложения ИИ — распознавании речи и образов, машинном переводе — достаточно скромны, хотя это и не мешает нам уже сегодня применять их на практике. Наибольшие же успехи, пожалуй, демонстрируют системы оптического распознавания символов (OCR, Optical Character Recognition), с которыми наверняка так или иначе знакомы почти все пользователи ПК. Тем более, что российские разработки в данной области занимают достойное место в мире — я имею в виду ABBYY FineReader.
Немного истории
Текущая версия ABBYY FineReader имеет номер 11, т. е. приложение прошло достаточно долгий путь развития, и даже история этого процесса представляет определенный интерес. Не претендуя на исчерпывающую летопись, приведу лишь основные вехи за последнее десятилетие, в течение которого я более-менее следил за FineReader:
| Год | Версия | Главные особенности |
| 2003 | 7.0 | Прирост точности распознавания до 25%. Больше всего это отразилось на таблицах, особенно сложных, с окрашенными ячейками, скрытыми разделителями и пр. |
| 2005 | 8.0 | Дальнейшая оптимизация алгоритмов распознавания, в первую очередь направленная на работу не со сканами документов, а с цифровыми фотографиями. Для этого появились дополнительные функции подготовки оригиналов (устранение искажений, выравнивание строк и пр.). |
| 2007 | 9.0 | Появление технологии ADRT, которая учитывает логическую структуру всего обрабатываемого (многостраничного) документа и умеет выделять повторяющиеся элементы (колонтитулы), соединять «перетекающие» объекты (таблицы) и пр. |
| 2009 | 10.0 | Дальнейшее совершенствование ADRT и алгоритмов распознавания, повышение точности обработки оригиналов с низким разрешением до 30%. |
| 2011 | 11.0 | Основное внимание уделено скорости работы программы. «Второе пришествие» черно-белого режима, который на оригиналах хорошего качества дает дополнительное ускорение до 30%. |
Естественно, за это же время в FineReader расширялась поддержка форматов документов, совершенствовались встроенные инструменты и интерфейс, улучшалось воссоздание структуры оригиналов и т. п. Однако выделенные моменты непосредственно связаны с технологиями OCR и неплохо демонстрируют скачкообразный процесс развития, характерный для сложных наукоемких систем, когда после очередного «прорыва» следует некоторый период «затишья», необходимый для совершенствования новых алгоритмов. Они-то и представляют главную ценность любой OCR-программы, и поэтому сколько-нибудь подробная информация о них крайне редко доходит до пользователей. Однако компания ABBYY любезно согласилась приоткрыть завесу тайны, и сегодня мы имеем возможность заглянуть в святая святых FineReader.
Базовые принципы
Итак, поскольку OCR относится к области ИИ, вполне логично, что разработчики стремятся хоть в какой-то степени имитировать деятельность нашего мозга. Конечно, устройство нашей зрительной системы невероятно сложно, но базовые «крупноблочные» принципы ее функционирования достаточно изучены, обычно их выделяют три:
- Целостность (integrity) — объект рассматривается как совокупность своих частей и (для зрительных образов) пространственных отношений между ними. В свою очередь и части получают толкования только в составе всего объекта. Этот принцип помогает строить и уточнять гипотезы, быстро отсекая маловероятные.
- Целенаправленность (purposefulness) — поскольку любая интерпретация данных преследует определенную цель, то и распознавание представляет собой процесс выдвижения гипотез об объекте и целенаправленной их проверки. Система, действующая в соответствии с этим принципом, будет не только экономнее расходовать вычислительные мощности, но и реже ошибаться.
- Адаптивность (adaptability) — система сохраняет накопленную в процессе работы информацию и использует ее повторно, т. е. самообучается. Этот принцип позволяет создавать и накапливать новые знания и избегать повторного решения одних и тех же задач.
FineReader — единственная в мире OCR-система, которая действует в соответствии с вышеописанными принципами на всех этапах обработки документа. Соответствующая технология носит название IPA — по первым буквам английских терминов. К примеру, согласно принципу целостности, фрагмент изображения будет интерпретироваться как символ, только если в нем присутствуют все структурные части подобных объектов, причем находящиеся в определенных взаимоотношениях. Это помогает заменить перебор большого числа эталонов (в поисках более-менее подходящего) целенаправленной проверкой разумного количества гипотез, причем опираясь на накопленные ранее сведения о возможных начертаниях символа в распознаваемом документе.
Однако принципы IPA применяются при анализе не только фрагментов, соответствующих (предположительно) отдельным символам, но и всего исходного изображения страницы. Большинство OCR-систем основываются на распознавании иерархической структуры документа, т. е. страница разбивается на основные структурные элементы, такие как таблицы, изображения, блоки текста, которые, в свою очередь, разделяются на другие характерные объекты — ячейки, абзацы — и так далее, вплоть до отдельных символов.
Такой анализ может проводиться двумя основными способами: сверху-вниз, т. е. от составных элементов к отдельным символам, или, наоборот, снизу-вверх. Чаще всего применяется один из них, но в ABBYY разработали специальный алгоритм MDA (multilevel document analysis, многоуровневый анализ документа), который сочетает оба. Вкратце он выглядит следующим образом: структура страницы анализируется методом сверху-вниз, а воссоздание электронного документа по окончании распознавания происходит снизу-вверх, однако на всех уровнях дополнительно действует механизм обратной связи. В результате резко снижается вероятность грубых ошибок, связанных с неверным распознаванием высокоуровневых объектов.
Исторически OCR-системы развивались от распознавания отдельных символов. Эта задача и до сих пор является важнейшей и самой трудной, именно с ней связаны наиболее сложные алгоритмы. Однако вскоре стало понятно, что в ее решении может помочь более высокоуровневая информация (к примеру, о языке документа и правильности написания распознанных слов) — так появились контекстная и словарная проверки. Затем стремление сохранять форматирование и воссоздавать физическую структуру (т. е. взаимное расположение различных объектов) документа привело к необходимости подробного анализа целой страницы. Понятно, что это также заметно влияет на общее качество распознавания, поскольку помогает корректно обрабатывать многоколоночную верстку, таблицы и другие приемы «нелинейного» расположения текста.
Большинство современных OCR действуют именно на этих трех уровнях — символов, слов, страниц, — практикуя, как уже было сказано, подходы сверху-вниз или снизу-вверх. Однако ABBYY, в соответствии с принципами IPA, ввела в FineReader еще один уровень — всего многостраничного документа. Прежде всего это понадобилось для корректного воспроизведения логической структуры, которая в современных документах становится все сложнее. Но есть и дополнительные бонусы: повышение точности и ускорение обработки повторяющихся объектов, более корректная идентификация (а значит, и распознавание) «перетекающих» со страницы на страницу объектов.
Именно для этого и была разработана ADRT (Adaptive Document Recognition Technology) — технология анализа и синтеза документа на логическом уровне. В конечном итоге она помогает сделать результат работы FineReader максимально похожим на оригинал. Для этого анализируется изображение всего документа, а распознанные слова объединяются в группы (кластеры) в зависимости от начертания, окружения и местоположения на странице. Таким образом программа как бы видит «логику» разметки документа и в дальнейшем может унифицировать оформление результата.
Благодаря ADRT, FineReader, начиная с версии 9.0, научился обнаруживать, распознавать и воспроизводить следующие структурные части и элементы форматирования документа:
- основной текст;
- верхние и нижние колонтитулы;
- номера страниц;
- заголовки одного уровня;
- оглавление;
- текстовые вставки;
- подписи к рисункам;
- таблицы;
- сноски;
- зоны подписи/печати;
- шрифты и стили.
Процесс распознавания
В соответствии с алгоритмом MDA, собственно распознавание начинается сверху-вниз, с уровня страницы. Понятно, что чем больше неверных решений будет сделано на ранних этапах этого процесса, тем больше будет на следующих. Именно поэтому точность распознавания так сильно зависит от качества оригиналов, но и алгоритмы их предварительной обработки могут иметь существенное значение. Так, по мере роста популярности цветных документов в FineReader появилась процедура адаптивной бинаризации (adaptive binarization, AB). Если отсканировать сразу в черно-белом режиме документ, где присутствуют водяные знаки либо текст расположен на текстурной или цветной подложке, то на изображении неизменно появится «мусор», который затем будет довольно сложно отделить от «полезного» изображения (т. к. исходная информация о нем уже потеряна). Именно поэтому FineReader предпочитает работать с цветными или полутоновыми изображениями, самостоятельно преобразуя их в черно-белые (этот процесс и называется бинаризацией). Но и это не всё. Поскольку цвета текста и фона могут различаться в пределах страницы и даже отдельных строк, AB выделяет слова с более-менее одинаковыми характеристиками и подбирает для каждого оптимальные с точки зрения качества распознавания параметры бинаризации. Именно в этом и состоит адаптивность алгоритма, который, таким образом, является примером использования обратной связи в MDA. Понятно, что эффективность AB сильно зависит от оформления исходных документов — на тестовой базе ABBYY этот алгоритм обеспечил повышение точности распознавания на 14,5%.
Но наиболее интересное, конечно, начинается, когда процесс распознавания опускается на самые нижние уровни. Так называемая процедура линейного деления разбивает строки на слова, а слова на отдельные буквы; далее, в соответствии с принципом IPA, формирует набор гипотез (т. е. возможных вариантов того, что́ это за символ, на какие символы разбито слово и т. д.) и, снабдив каждую оценкой вероятности, передает на вход механизма распознавания символов. Последний состоит из ряда так называемых классификаторов, каждый из которых также формирует ряд гипотез, ранжированных по предполагаемой степени вероятности. Важнейшей характеристикой любого классификатора является среднее положение правильной гипотезы. Понятно, что чем выше она находится, тем меньше работы для последующих алгоритмов — к примеру, словарной проверки. Но для достаточно отлаженных классификаторов чаще всего оценивают такие характеристики, как точность распознавания по первым трем гипотезам или только по первой — т. е., грубо говоря, способность угадать верный ответ с трех или с одной попытки. ABBYY в своих системах применяет следующие типы классификаторов: растровый, признаковый, признаковый дифференциальный, контурный, структурный и структурный дифференциальный — которые сгруппированы на двух логических уровнях.
Принцип действия РК, или растрового классификатора, основан на попиксельном сравнении изображения символа с эталонами. Последние формируются в результате усреднения изображений из обучающей выборки и приводятся к некой стандартной форме; соответственно, для распознаваемого изображения также предварительно нормализуются размер, толщина элементов, наклон. Этот классификатор отличается простотой реализации, скоростью работы и устойчивостью к дефектам изображений, но обеспечивает сравнительно низкую точность и именно поэтому используется на первом этапе — для быстрого порождения списка гипотез.
Признаковый классификатор (ПК), как и следует из его названия, основывается на наличии в изображении признаков того или иного символа. Если всего таких признаков N, то каждую гипотезу можно представить точкой в N-мерном пространстве; соответственно, точность гипотезы будет оцениваться расстоянием от нее до точки, соответствующей эталону (который также нарабатывается на обучающей выборке). Понятно, что типы и количество признаков в значительной степени определяют качество распознавания, поэтому обычно их достаточно много. Этот классификатор также сравнительно быстр и прост, но не слишком устойчив к различным дефектам изображения. Кроме того, ПК оперирует не исходным изображением, а некой моделью, абстракцией, т. е. не учитывает часть информации: скажем, сам факт наличия каких-то важных элементов ничего не говорит об их взаимном расположении. По этой причине ПК используется не вместо, а вместе с РК.
Контурный классификатор (КК) представляет собой частный случай ПК и отличается тем, что анализирует контуры предполагаемого символа, выделенные из исходного изображения. В общем случае его точность ниже, чем у полновесного ПК.
Признаковый дифференциальный классификатор (ПДК) также похож на ПК, однако используется исключительно для различения похожих друг на друга объектов, таких как «m» и «rn». Соответственно, он анализирует только те области, где скрываются отличия, а на вход ему подаются не только исходные изображения, но и гипотезы, сформированные на ранних стадиях распознавания. Принцип его работы, однако, несколько отличается от ПК. На этапе обучения в N-мерном пространстве формируются два «облака» (групп точек) возможных значений для каждого из двух вариантов, затем строится гиперплоскость, отделяющая «облака» друг от друга и примерно равноудаленная от них. Результат распознавания зависит от того, в какое полупространство попадает точка, соответствующая исходному изображению.
Сам по себе ПДК не выдвигает гипотез, а лишь уточняет имеющиеся (список которых в общем случае сортируется пузырьковым методом), так что прямая оценка его эффективности не проводится, а косвенно ее приравнивают к характеристикам всего первого уровня OCR-распознавания. Однако понятно, что она зависит от корректности подобранных признаков и представительности выборки эталонов, обеспечение чего является достаточно трудоемкой задачей.
Структурно-дифференциальный классификатор (СДК) первоначально применялся для обработки рукописных текстов. Его задача состоит в различении таких похожих объектов, как «C» и «G». Таким образом, СДК основывается на признаках, характерных для каждой пары символов, процесс его обучения еще сложнее, чем у ПДК, а скорость работы ниже, чем у всех предыдущих классификаторов.
Структурный классификатор (СК) является предметом гордости компании ABBYY, первоначально он был разработан для распознавания так называемого рукопечатного текста, т. е. когда человек пишет «печатными» буквами, но впоследствии был применен и для печатного. Он используется на завершающих этапах распознавания и вступает в действие достаточно редко, а именно, только в том случае, когда до него доходят как минимум две гипотезы с достаточно высокими вероятностями.
Качественные характеристики всех классификаторов собраны в следующую таблицу. Они, впрочем, позволяют лишь оценить эффективность алгоритмов друг относительно друга, т. к. не являются абсолютными, а получены на основе обработки конкретной тестовой выборки. Может создаться впечатление, что на последних этапах распознавания борьба идет буквально за доли процента, но на самом деле каждый классификатор вносит существенную лепту в повышение точности распознавания — так, к примеру, СК снижает количество ошибок на ощутимые 20%.
| РК | ПК | КК | ПДК* | СДК** | СК** | |
| Точность по первым трем вариантам, % | 99,29 | 99,81 | 99,30 | 99,87 | 99,88 | — |
| Точность по первому варианту, % | 97,57 | 99,13 | 95,10 | 99,26 | 99,69 | 99,73 |
* оценка всего первого уровня OCR-алгоритма ABBYY
** оценка для всего алгоритма после добавления соответствующего классификатора
Любопытно, однако, что, несмотря на довольно высокую точность, алгоритм собственно распознавания не принимает окончательного решения. В соответствии с принципом MDA, гипотезы выдвигаются на каждом логическом уровне, и число их может расти в геометрической прогрессии. Соответственно, последовательная проверка всех гипотез вряд ли окажется эффективной, и потому в OCR-системах ABBYY применяется метод структурирования гипотез, т. е. отнесения их к тем или иным моделям. Последних существует пара десятков, вот только несколько их типов: словарное слово, несловарное слово, арабские цифры, римские цифры, URL, регулярное выражение — а в каждый может входить множество конкретных моделей (к примеру, слово на одном из известных языков, латиницей, кириллицей и т. д.).
Все финальные действия выполняются уже именно с гипотезами, построенными по моделям. К примеру, контекстная проверка определит язык документа и сразу же существенно понизит вероятность моделей с использованием неправильных алфавитов, а словарная компенсирует погрешности при неуверенном распознавании некоторых символов: так, слово «turn» присутствует в словаре английского языка — в отличие от «tum» (во всяком случае, оно отсутствует среди популярных). Хотя приоритет словаря выше, чем у любого классификатора, он не обязательно является последней инстанцией, и в общем случае не останавливает дальнейшие проверки: во-первых, как говорилось выше, имеется модель несловарного слова, во-вторых, специальная организация словарей позволяет с высокой долей вероятности предположить, может ли какое-то неизвестное слово относиться к тому или иному языку. Тем не менее, словарная проверка (и полнота словарей) оказывает существенное влияние на результат распознавания, и в тестах самой ABBYY сокращает количество ошибок практически вдвое.
Не только OCR
Печатные документы — далеко не единственные, представляющие интерес с точки зрения их оцифровки и автоматической обработки. Довольно часто приходится работать с формами, т. е. документами с предопределенными и фиксированными полями, которые заполняются вручную, но сравнительно аккуратно (так называемыми рукопечатными символами) — примером могут служить различные анкеты. Технология их обработки имеет отдельное название — ICR (intelligent character recognition) — и достаточно существенно отличается от OCR. Так, поскольку в данном случае задача состоит не в воссоздании всего документа, а в извлечении из него конкретных данных, то она распадается на две основные подзадачи: нахождение нужных полей и собственно распознавание их содержимого.
Это достаточно специфическая область, и ABBYY предлагает для нее совершенно отдельный программный продукт ABBYY FlexiCapture. Он предназначен для создания автоматизированных и полуавтоматизированных систем, предполагает настройку на конкретные типы документов, для которых создаются специальные шаблоны, умеет интеллектуально находить на страницах различные поля и верифицировать данные в них и т. д. Однако в самой основе лежат алгоритмы распознавания символов, аналогичные тем, что применяются в FineReader, да и общая схема весьма похожа:
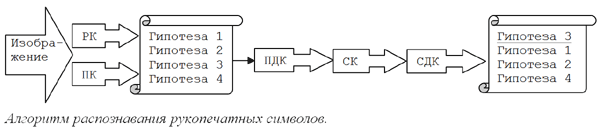
Впрочем, важное отличие все же имеется: структурный классификатор является обязательным участником процесса — это связано со спецификой рукопечатных символов. Кроме того, ICR предполагает большое число специфических дополнительных проверок: например, не является ли символ зачеркнутым, или действительно ли распознанные символы формируют дату.



