- Конвертирование файлов в кодировку UTF-8 в Linux
- Конвертирование файлов из UTF-8 в ASCII
- Конвертирование нескольких файлов в кодировку UTF-8
- Преобразование UTF-16 в UTF-8 под Windows и Linux, в C
- 7 ответов
- Одминский блог
- Смена кодировки сайта из CP1251 на UTF-8
- bradleypeabody / gist:185b1d7ed6c0c2ab6cec
- This comment has been minimized.
- ivanmay commented Jul 23, 2014
- This comment has been minimized.
- MathewT commented Jul 21, 2015
- This comment has been minimized.
- ik5 commented Aug 19, 2015
- This comment has been minimized.
- ping1990 commented Nov 12, 2015
- This comment has been minimized.
- bassu commented Apr 10, 2016
- This comment has been minimized.
- Tanz0rz commented Sep 28, 2016
- This comment has been minimized.
- vinniyo commented Feb 28, 2017
- This comment has been minimized.
- akirabbq commented Nov 10, 2017 •
- This comment has been minimized.
- juergenhoetzel commented Dec 8, 2018
- Как я боролся с кодировками в консоли
Конвертирование файлов в кодировку UTF-8 в Linux
Оригинал: How to Convert Files to UTF-8 Encoding in Linux
Автор: Aaron Kili
Дата публикации: 2 ноября 2016 года
Перевод: А. Кривошей
Дата перевода: ноябрь 2017 г.
В этом руководстве мы рассмотрим кодировки символов и разберем несколько примеров преобразования файлов из одной кодировки в другую с помощью утилиты командной строки. Затем мы покажем, как преобразовать файлы в Linux из любой кодировки (charset) в UTF-8.
Как вы, наверное, уже знаете, компьютер не понимает и не хранит информацию в виде букв, цифр или чего-либо еще. Он работает только с битами. Бит имеет только два возможных значения — 0 или 1, true или false, да или нет. Все остальное кодируется последовательностями битов.
Простыми словами, кодировка символов — это способ кодировки различных символов определенными последовательностями нулей и единиц. Когда мы вводим текст и сохраняем его в файл, слова и предложения, которые мы набираем, состоят из разных символов, а символы преобразуются в биты с помощью кодировки.
Существуют различные схемы кодирования, такие как ASCII, ANSI, Unicode и другие. Ниже приведен пример кодировки ASCII.
В Linux для преобразования текста из одной кодировки в другую используется утилита командной строки iconv.
Вы можете проверить кодировку файла с помощью команды file, используя флаг -i или -mime, который печатает строку типа mime, как в приведенных ниже примерах:

Синтаксис команды iconv следующий:
Где -f или —from-code задает входную кодировку, а -t или —to-encoding задает конечную кодировку.
Для того, чтобы вывести список всех доступных опций, введите:
Конвертирование файлов из UTF-8 в ASCII
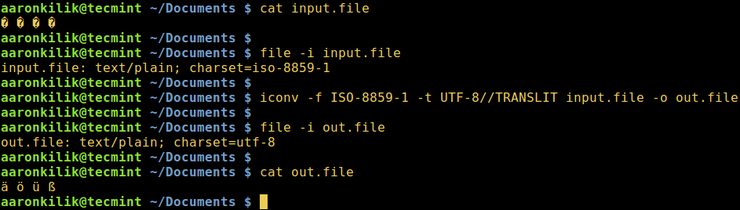
Далее мы научимся конвертировать текст из одной кодировки в другую. Приведенная ниже команда преобразует текст из ISO-8859-1 в кодировку UTF-8.
Рассмотрим файл input.file, который содержит следующие символы:
(Прим: вы увидите эти символы на снимке ниже)
Начнем с проверки кодировки файла, затем просмотрим его содержимое. Мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы затем проверяем содержимое выходного файла и новую кодировку, как показано ниже.
Примечание. Если в команду добавлена строка //IGNORE, то символы, которые не могут быть преобразованы, и ошибка выводятся после преобразования.
Далее, если добавлена строка //TRANSLIT, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы при необходимости и по возможности транслитерируются. Это означает, что если символ не может быть представлен в целевой кодировке, его можно аппроксимировать одним или несколькими похожими символами.
Далее, любой символ, который не может быть транслитерирован и которого нет в целевой кодировке, заменяется в выводе вопросительным знаком (?).
Конвертирование нескольких файлов в кодировку UTF-8
Возвращаясь к основной теме нашей статьи, мы можем написать небольшой скрипт для преобразования нескольких или всех файлов в каталоге в кодировку UTF-8, под названием encoding.sh:
Сохраните этот файл и сделайте скрипт исполняемым. Запускайте его из той директории, где расположены ваши файлы.
Важное замечание. Вы также можете также использовать этот скрипт для преобразования нескольких файлов из одной заданной кодировки в другую (любую), просто меняйте со значения переменных FROM_ENCODING и TO_ENCODING, не забывая об имени выходного файла «$
Для получения дополнительной информации почитайте руководство iconv:
Подводя итог этой статье, необходимо отметить, что понимание способов преобразования текста из одной кодировки в другую — это знания, необходимые каждому пользователю компьютера, а тем более программистам, когда дело касается работы с текстами.
Если вы хотите лучше понять проблему кодировок символов, прочитайте следующие статьи:
Источник
Преобразование UTF-16 в UTF-8 под Windows и Linux, в C
Мне было интересно, есть ли рекомендуемый «перекрестный» метод Windows и Linux для преобразования строк из UTF-16LE в UTF-8? или следует использовать разные методы для каждой среды?
мне удалось google несколько ссылок на «iconv», но для somreason я не могу найти примеры основных преобразований, таких как — преобразование wchar_t UTF-16 в UTF-8.
любой может порекомендовать метод, который будет «перекрестным», и если вы знаете ссылки или руководство с образцами, был бы очень признателен.
Спасибо, Doori Bar
7 ответов
Если вы не хотите использовать ICU,
изменить кодировку на UTF-8 с помощью PowerShell:
с открытым исходным кодом библиотека ICU очень часто используется.
Я тоже столкнулся с этой проблемой, я решаю ее с помощью повысить библиотеку локали
на boost:: locale::conv:: utf_to_utf функция попробуйте преобразовать из буфера, закодированного UTF-16LE в UTF-8, The boost::locale::conv:: from_utf функция попробуйте преобразовать из буфера, закодированного UTF-8 в ANSI, убедитесь, что кодировка правильная (здесь я использую кодировку для Latin-1, ISO-8859-1).
еще одно напоминание, в Linux std:: wstring имеет длину 4 байта, но в Windows std:: wstring имеет длину 2 байта, поэтому вам лучше не использовать std:: wstring для буфера UTF-16LE.
там же utfcpp, которая является библиотекой только для заголовков.
Спасибо, ребята, вот как мне удалось решить «перекрестное» требование windows и linux:
- скачал и установил: MinGW и MSYS
- загрузить libiconv источник
- составлен libiconv via MSYS .
Источник
Одминский блог
Блог о технологиях, технократии и методиках борьбы с граблями
Смена кодировки сайта из CP1251 на UTF-8
Перевозил тут пачку сайтов с LAMP на LNAMP, где фронтэндом выступает NGINX. И все бы ничего, если бы не пачка статических сателлитов в кодировке Windows-1251 (cp1251).
Как тут прикололся девака – при анализе сайта, надо сначала чекать кодировку и в случае обнаружения кодировки сайта cp1251 – проверку возраста можно не осуществлять. Но, тем не менее, в инетах до сих пор встречаются такие мастадонты, которые клепают сайты в кодировке CP1251.
Под апачем, при добавлении сайта в ISP Panel это даже не заметишь, а вот при попытке добавить этот же сайт в Vesta CP, получаешь гемор на задницу с крикозябрами. Поэтому надо редактировать конфиг Nginx, предварительно прикрутив туда виндовую кодировку. Но, насколько я помню, у меня этот танец с бубнами не задался и в тот раз, я просто повесил саты на LAMP.
Так что оставалось либо плясать с бубнами вокруг прикручивания виндовой кодировки к NGINX, либо перекодивать файлы в родную для нжинкса UTF-8. Сделать это можно средствами текстового редактора Notepad++ путем перевода кодировки документа и последующего сохранения; либо же в самом линухе. Как я выше заметил, саты статические, то есть на файлах, без использования базы данных. Поэтому перекодировать надо было именно файлы. С базой данных все происходило бы несколько иначе.
Перекодировка файла из CP1251 в UTF-8 производится в консоли через команду iconv
# iconv -f cp1251 -t utf8 FILE-CP1251 -o FILE-UTF8
либо же можно переписать файл в самого себя
# iconv -f cp1251 -t utf8 file.txt -o file.txt
Но поскольку мне надо было перекодировать большое число файлов php, содержащихся в разных папках, то мне пришлось составить небольшое предложение:
# find /path-to-files/ -type f -name \*php -exec iconv -f cp1251 -t utf-8 ‘<>‘ -o ‘<>‘ \;
Конвертит все в лет.
Для конвертации кодировок есть еще утилита enconv, входящая в состав пакета enca – вот он как раз конвертит сам в себя по умолчанию, перезаписывая файл выходной кодировкой:
# enconv -c file.txt
но, к сожалению, я его не смог подружить с русским языком, т.к даже при указании языка через ключик -L russian скрипт матерился на ошибки. Но с другой стороны, все нормально решилось и через iconv
Источник
bradleypeabody / gist:185b1d7ed6c0c2ab6cec
| package main |
| // http://play.golang.org/p/fVf7duRtdH |
| import «fmt» |
| import «unicode/utf16» |
| import «unicode/utf8» |
| import «bytes» |
| func main () < |
| b := [] byte < |
| 0xff , // BOM |
| 0xfe , // BOM |
| ‘T’ , |
| 0x00 , |
| ‘E’ , |
| 0x00 , |
| ‘S’ , |
| 0x00 , |
| ‘T’ , |
| 0x00 , |
| 0x6C , |
| 0x34 , |
| ‘\n’ , |
| 0x00 , |
| > |
| s , err := DecodeUTF16 ( b ) |
| if err != nil < |
| panic ( err ) |
| > |
| fmt . Println ( s ) |
| > |
| func DecodeUTF16 ( b [] byte ) ( string , error ) < |
| if len ( b ) % 2 != 0 < |
| return «» , fmt . Errorf ( «Must have even length byte slice» ) |
| > |
| u16s := make ([] uint16 , 1 ) |
| ret := & bytes. Buffer <> |
| b8buf := make ([] byte , 4 ) |
| lb := len ( b ) |
| for i := 0 ; i lb ; i += 2 < |
| u16s [ 0 ] = uint16 ( b [ i ]) + ( uint16 ( b [ i + 1 ]) 8 ) |
| r := utf16 . Decode ( u16s ) |
| n := utf8 . EncodeRune ( b8buf , r [ 0 ]) |
| ret . Write ( b8buf [: n ]) |
| > |
| return ret . String (), nil |
| > |
This comment has been minimized.
Copy link Quote reply
ivanmay commented Jul 23, 2014
Awesome thanks! helped alot 🙂
This comment has been minimized.
Copy link Quote reply
MathewT commented Jul 21, 2015
Thanks for DecodeUTF16. Really helped me out too!! Extremely useful.
This comment has been minimized.
Copy link Quote reply
ik5 commented Aug 19, 2015
This code is for little endian .
For big endian, change the code of line 50 like so:
u16s[0] = uint16(b[i+1]) + (uint16(b[i])
I’m looking for an idea to figure out from the BOM (two first bytes) the endianness, so it will be automatic using this code.
This comment has been minimized.
Copy link Quote reply
ping1990 commented Nov 12, 2015
Thanks very much! helped a lot
This comment has been minimized.
Copy link Quote reply
bassu commented Apr 10, 2016
@ik5: It’s simple. Set i := 2 and read first two bytes outside the loop.
For others, see BOM Faq at Unicode.org, if you haven’t already, which of course is quite a delightful read this evening 🚶
This comment has been minimized.
Copy link Quote reply
Tanz0rz commented Sep 28, 2016
Life saver! You are amazing!
This comment has been minimized.
Copy link Quote reply
vinniyo commented Feb 28, 2017
This comment has been minimized.
Copy link Quote reply
akirabbq commented Nov 10, 2017 •
Incorrect result when decoding any surrogate pair, should take care of the high/low surrogate range.
A quick fix to increase u16s size to 2 u16s := make([]uint16, 2) and:
This comment has been minimized.
Copy link Quote reply
juergenhoetzel commented Dec 8, 2018
golang already has support for decoding []byte into []uint16 (respecting the endianness):
@akirabbq @ik5
complete solution (which also works with surrogate pairs): utf16.go
Источник
Как я боролся с кодировками в консоли
В очередной раз запустив в Windows свой скрипт-информер для СамИздат-а и увидев в консоли «загадочные символы» я сказал себе: «Да уже сделай, наконец, себе нормальный кросс-платформенный логгинг!»
Об этом, и о том, как раскрасить вывод лога наподобие Django-вского в Win32 я попробую рассказать под хабра-катом (Всё ниженаписанное применимо к Python 2.x ветке)
Задача первая. Корректный вывод текста в консоль
Симптомы
До тех пор, пока мы не вносим каких-либо «поправок» в проинициализировавшуюся систему ввода-вывода и используем только оператор print с unicode строками, всё идёт более-менее нормально вне зависимости от ОС.
«Чудеса» начинаются дальше — если мы поменяли какие-либо кодировки (см. чуть дальше) или воспользовались модулем logging для вывода на экран. Вроде бы настроив ожидаемое поведение в Linux, в Windows получаешь «мусор» в utf-8. Начинаешь править под Win — вылезает 1251 в консоли…
Теоретический экскурс
Ищем решение
Очевидно, чтобы избавиться от всех этих проблем, надо как-то привести их к единообразию.
И вот тут начинается самое интересное:
Ага! Оказывается «система» у нас живёт вообще в ASCII. Как следствие — попытка по-простому работать с вводом/выводом заканчивается «любимым» исключением UnicodeEncodeError/UnicodeDecodeError .
Кроме того, как замечательно видно из примера, если в linux у нас везде utf-8, то в Windows — две разных кодировки — так называемая ANSI, она же cp1251, используемая для графической части и OEM, она же cp866, для вывода текста в консоли. OEM кодировка пришла к нам со времён DOS-а и, теоретически, может быть также перенастроена специальными командами, но на практике никто этого давно не делает.
До недавнего времени я пользовался распространённым способом исправить эту неприятность:
И это, в общем-то, работало. Работало до тех пор, пока пользовался print -ом. При переходе к выводу на экран через logging всё сломалось.
Угу, подумал я, раз «оно» использует кодировку по-умолчанию, — выставлю-ка я ту же кодировку, что в консоли:
Уже чуть лучше, но:
- В Win32 текст печатается кракозябрами, явно напоминающими cp1251
- При запуске с перенаправленным выводом опять получаем не то, что ожидалось
- Периодически, при попытке напечатать текст, где есть преобразованный в unicode символ типа ① ( ① ), «любезно» добавленный автором в какой-нибудь заголовок, снова получаем UnicodeEncodeError !
Присмотревшись к первому примеру, нетрудно заметить, что так желаемую кодировку «cp866» можно получить только проверив атрибут соответствующего потока. А он далеко не всегда оказывается доступен.
Вторая часть задачи — оставить системную кодировку в utf-8, но корректно настроить вывод в консоль.
Для индивидуальной настройки вывода надо переопределить обработку выходных потоков примерно так:
Этот код позволяет убить двух зайцев — выставить нужную кодировку и защититься от исключений при печати всяких умляутов и прочей типографики, отсутствующей в 255 символах cp866.
Осталось сделать этот код универсальным — откуда мне знать OEM кодировку на произвольном сферическом компе? Гугление на предмет готовой поддержки ANSI/OEM кодировок в python ничего разумного не дало, посему пришлось немного вспомнить WinAPI
… и собрать всё вместе:
Задача вторая. Раскрашиваем вывод
Насмотревшись на отладочный вывод Джанги в связке с werkzeug, захотелось чего-то подобного для себя. Гугление выдаёт несколько проектов разной степени проработки и удобности — от простейшего наследника logging.StreamHandler , до некоего набора, при импорте автоматически подменяющего стандартный StreamHandler.
Попробовав несколько из них, я, в итоге, воспользовался простейшим наследником StreamHandler, приведённом в одном из комментов на Stack Overflow и пока вполне доволен:
Однако, в Windows всё это работать, разумеется, отказалось. И если раньше можно было «включить» поддержку ansi-кодов в консоли добавлением «магического» ansi.dll из проекта symfony куда-то в недра системных папок винды, то, начиная (кажется) с Windows 7 данная возможность окончательно «выпилена» из системы. Да и заставлять юзера копировать какую-то dll в системную папку тоже как-то «не кошерно».
Снова обращаемся к гуглу и, снова, получаем несколько вариантов решения. Все варианты так или иначе сводятся к подмене вывода ANSI escape-последовательностей вызовом WinAPI для управления атрибутами консоли.
Побродив некоторое время по ссылкам, набрёл на проект colorama. Он как-то понравился мне больше остального. К плюсам именно этого проекта ст́оит отнести, что подменяется весь консольный вывод — можно выводить раскрашенный текст простым print u»\x1b[31;40mЧто-то красное на чёрном\x1b[0m» если вдруг захочется поизвращаться.
Сразу замечу, что текущая версия 0.1.18 содержит досадный баг, ломающий вывод unicode строк. Но простейшее решение я привёл там же при создании issue.
Собственно осталось объединить оба пожелания и начать пользоваться вместо традиционных «костылей»:
Дальше в своём проекте, в запускаемом файле пользуемся:
На этом всё. Из потенциальных доработок осталось проверить работоспособность под win64 python и, возможно, добаботать ColoredHandler чтобы проверял себя на isatty, как в более сложных примерах на том же StackOverflow.
Источник



