- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Загрузка ЦПУ в Linux — насколько варит ваш котелок
- Методы проверки
- Проверяем загрузку процессора с помощью команды top
- Немного более модный способ: htop
- Прочие способы проверки степени загрузки ЦПУ
- Как настроить оповещения о слишком высокой нагрузке на процессор
- Заключение
- Как просмотреть нагрузку на процессор в Linux
- Команда ps
- Команда top
- Мониторинг использования CPU на сервере Linux
- Требования
- Основные понятия
- Загрузка и использование ЦП
- Ненормированные и нормированные значения
- Отображение информации о ЦП
- Оптимальные значения загрузки и использования ЦП
- Мониторинг ЦП
- Утилита uptime
- Утилита top
- Заглавный блок
- Таблица процессов
- Заключение
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Загрузка ЦПУ в Linux — насколько варит ваш котелок
Понимать состояние ваших серверов с точки зрения их загрузки и производительности — крайне важная задача. В этой статье мы опишем несколько самых популярных методов для проверки и мониторинга загрузки ЦПУ на Linux хосте.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена


Методы проверки
Проверяем загрузку процессора с помощью команды top
Отличным способом проверки загрузки является команда top. Вывод этой команды выглядит достаточно сложным, зато если вы в нем разберетесь, то точно сможете понять какие процессы занимают большую часть ваших вычислительных мощностей.
Команда состоит всего из трех букв: top
У вас откроется окно в терминале, которое будет отображать запущенные сервисы в реальном времени, долю системных ресурсов, которую эти сервисы потребляют, общую сводку по загрузке CPU и т.д
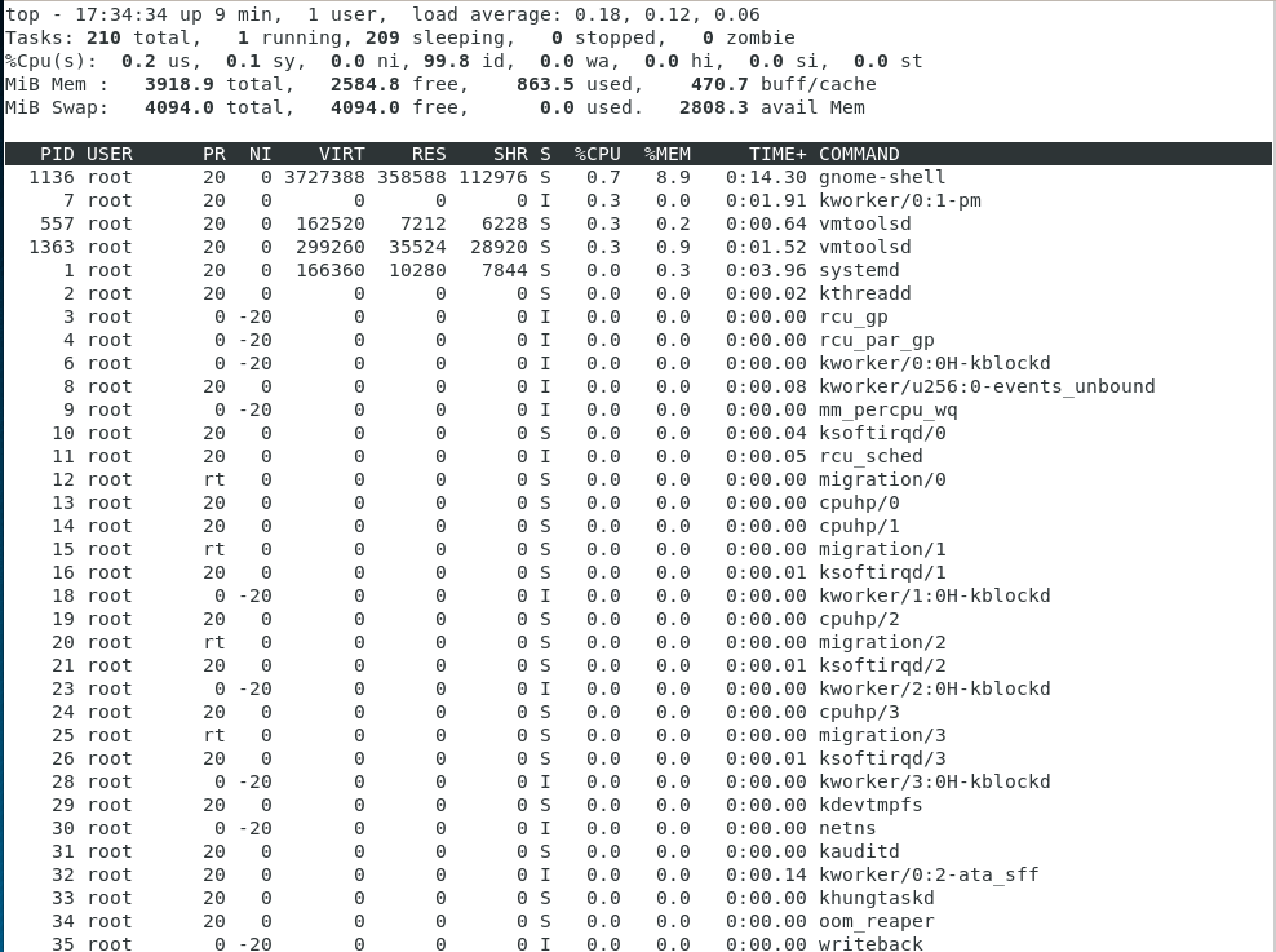
Будем идти по порядку: первая строчка отображает системное время, аптайм, количество активных пользовательских сессий и среднюю загруженность системы. Средняя загруженность для нас особенно важна, т.к дает понимание о среднем проценте утилизации ресурсов за некоторые промежутки времени.
Три числа показывают среднюю загрузку: за 1, 5 и 15 минут соответственно. Считайте, что эти числа — это процентная загрузка, т.е 0.2 означает 20%, а 1.00 — стопроцентную загрузку. Это звучит и выглядит достаточно логично, но иногда там могут проскакивать странные значения — вроде 2.50. Это происходит из-за того, что этот показатель не прямое значение загрузки процессора, а нечто вроде общего количества «работы», которое ваша система пытается выполнить. К примеру, значение 2.50 означает, что текущая загрузка равна 250% и ваша система на 150% перегружена.
Вторая строчка достаточна понятна и просто показывает количество задач, запущенных в системе и их текущий статус.
Третья строчка позволит вам отследить загрузку ЦПУ с подробной статистикой. Но здесь нужно сделать некоторые комментарии:
- us: процент времени, когда ЦПУ был загружен и которое было затрачено на user space (созданные/запущенные пользователем процессы)
- sy: процент времени, когда ЦПУ был загружен и которое было затрачено на на kernel (системные процессы)
- ni: процент времени, когда ЦПУ был загружен и которое было затрачено на приоритезированные пользовательские процессы (системные процессы)
- id: процент времени, когда ЦПУ не был загружен
- wa: процент времени, когда ЦПУ ожидал отклика от устройств ввода — вывода (к примеру, ожидание завершения записи информации на диск)
- hi: процент времени, когда ЦПУ получал аппаратные прерывания (например, от сетевого адаптера)
- si: процент времени, когда ЦПУ получал программные прерывания (например, от какого-то приложения адаптера)
- st: сколько процентов было «украдено» виртуальной машиной — в случае, если гипервизору понадобилось увеличить собственные ресурсы
Следующие две строчки показывают сколько занято/свободно оперативно памяти и файла подкачки, и не так релевантны относительно задачи проверки нагрузки на процессор. Под информацией о памяти вы увидите список процессов и процент ЦПУ, который они тратят.
Также вы можете нажимать на кнопку t, чтобы прокручивать между различными вариантами вывода информации и использовать кнопку q для выхода из top
Немного более модный способ: htop
Существует более удобная утилита под названием htop, которая предоставляет достаточно удобный интерфейс с красивым форматированием. Установка утилиты экстремально проста:
Для Ubuntu и Debian:
sudo apt-get install htop
Для CentOS и Red Hat:
yum install htop
dnf install htop
После установки просто введите команду ниже:

Как видно на скриншоте, htop гораздо лучше подходит для простой проверки степени загрузки процессора. Выход также осуществляется кнопкой q
Прочие способы проверки степени загрузки ЦПУ
Есть еще несколько полезных утилит, и одна из них (а точнее целый набор) называется sysstat.
Установка для Ubuntu и Debian:
sudo apt-get install sysstat
Установка для CentOS и Red Hat:
yum install sysstat
Как только вы установите systat, вы сможете выполнить команду mpstat — опять же, практически тот же вывод, что и у top, но в гораздо лаконичнее.

Следующая утилита в этом пакете это sar. Она наиболее полезна, если вы ее вводите вместе с каким-нибудь числом, например 6. Это определяет временной интервал, через который команда sar будет выводить информацию о загрузке ЦПУ.

К примеру, проверяем загрузку ЦПУ каждые 6 секунд:
Если же вы хотите остановить вывод после нескольких итераций, например 10, добавьте еще одно число:
Так вы также увидите средние значения за 10 выводов.
Как настроить оповещения о слишком высокой нагрузке на процессор
Одним из самых правильных способов является написание простого bash скрипта, который будет отправлять вам алерты о слишком высокой степени утилизации системных ресурсов.
Скрипт будет использовать обработчик sed и среднюю загрузку от команды sar. Как только нагрузка на сервер будет превышать 85%, администратор будет получать письмо на электронную почту. Соответственно, значения в скрипте можно изменить под ваши требования — к примеру поменять тайминги, выводить алерт в консоль, отправлять оповещения в лог и т.д.
Естественно, для выполнения этого скрипта нужно будет запустить его по крону:
Для ежеминутного запуска введите:
Заключение
Соответственно, лучшим способом будет комбинировать эти способы — например использовать htop при отладке и экспериментах, а для постоянного контроля держать запущенным скрипт.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена
Источник
Как просмотреть нагрузку на процессор в Linux
В Linux потребление ресурсов CPU, с сортировкой по наибольшей загрузке, можно посмотреть при помощи двух команд: ps и top.
Важный нюанс: Значение в столбце «CPU» в обоих командах считается от загрузки одного ядра процессора. Таким образом сумма процентов на многоядерных машинах будет больше 100%. К примеру для четырехядерного процессора суммарный процент потребления всех процессов не может превышать 400%.
Рассмотрим каждую из команд подробней.
Команда ps
Для запуска введите в консоли ОС команду:
Пример вывода команды:
Важными столбцами являются:
- USER Пользователь, от имени которого работает процесс
- PID Идентификатор процесса
- %CPU Процент загрузки ядра
Согласно данному выводу можно понять, что экземпляр программы dd с PID=31712 практически полностью использует одно ядро процессора.
Команда top
Также загрузку процессора можно посмотреть в интерактивном режиме при помощи команды top. Для запуска введите в консоли ОС команду:
Пример вывода команды:
Важными столбцами являются:
- USER Пользователь, от имени которого работает процесс
- PID Идентификатор процесса
- %CPU Процент загрузки ядра
Согласно данному выводу видно, что два процесса браузера Chromium используют по 40% возможностей одного из ядер процессора.
Источник
Мониторинг использования CPU на сервере Linux
Объем памяти, размер кеша, скорость чтения и записи на диск, скорость и доступность вычислительной мощности – это ключевые элементы, влияющие на производительность любой инфраструктуры.
Данное руководство ознакомит с базовыми понятиями мониторинга CPU. Вы узнаете, как использовать утилиты uptime и top, чтобы узнать о нагрузке и использовании ЦП.
Требования
- Сервер Linux.
- Утилиты uptime и top должны быть установлены по умолчанию. Если это не так, установите их вручную.
Основные понятия
Прежде чем приступить к работе с утилитами, нужно понять, как измеряется использование ЦП и к каким результатам нужно стремиться.
Загрузка и использование ЦП
Загрузка (CPU Load) и использование процессора (CPU Utilization) – два разных способа взглянуть на использование вычислительной мощности компьютера.
Чтобы оценить основное различие между ними, попробуйте представить, что процессоры – это кассиры в продуктовом магазине, а задачи – это клиенты, которых нужно обслужить. Загрузка процессора – это, по сути, одна очередь, в которой клиенты ждут, пока освободиться один из кассиров. Нагрузка – это в данном случае количество клиентов в очереди, включая тех, что уже на кассе. Чем длиннее очередь, тем дольше ждать.
Использование ЦП оценивает исключительно занятость кассиров и не знает, сколько клиентов в очереди.
Если говорить конкретнее, задачи создают очередь за ресурсами процессоров. Когда подходит очередь той или иной задачи, она должна получить определенное количество времени обработки. Если задача была выполнена, он снимается; в противном случае она возвращается в конец очереди. После этого обрабатывается следующая задача в очереди.
Загрузка ЦП – это длина очереди запланированных задач, включая те, что находятся в обработке. Задачи могут переключаться в пределах миллисекунд, поэтому один снапшот загрузки не так полезен, как среднее значение из нескольких снапшотов, взятых за определенный период времени. Потому загрузка ЦП часто представляется как среднее значение.
Загрузка процессора отображает спрос на процессорное время. Высокий спрос может привести к сбоям и ухудшению производительности.
Использование ЦП сообщает, насколько загружены процессоры, не беря во внимание количество ожидающих задач. Мониторинг использования ЦП может отображать тенденции во времени, выделять пики использования процессора и выявлять нежелательную активность на сервере.
Ненормированные и нормированные значения
В одной процессорной системе общая емкость всегда равна 1. В многопроцессорной системе данные могут отображаться двумя разными способами. Суммарная емкость всех процессоров рассчитывается как 100% независимо от количества процессоров, такое значение считается нормированным. Другой вариант предлагает считать каждый процессор как единицу, так что 2-процессорная система в полном объеме имеет емкость 200%, 4-процессорная система в полном объеме имеет мощность 400% и т. д.
Чтобы правильно интерпретировать загрузку или использование CPU, нужно знать количество процессоров на сервере.
Отображение информации о ЦП
Чтобы узнать количество процессоров, можно использовать команду nproc с опцией –all. Без этого флага команда отобразит количество обрабатывающих блоков, доступных для текущего процесса, что будет меньше общего количества процессоров.
В большинстве современных дистрибутивов Linux также можно использовать команду lscpu, которая отображает не только количество процессоров, но и архитектуру, имя модели, скорость и многое другое:
lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2650L v3 @ 1.80GHz
Stepping: 2
CPU MHz: 1797.917
BogoMIPS: 3595.83
Virtualization: VT-x
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 30720K
NUMA node0 CPU(s): 0,1
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm vnmi ept fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat
Знание точного количества процессоров важно для интерпретации результатов тех или иных утилит.
Оптимальные значения загрузки и использования ЦП
Оптимальное значение использования ЦП зависит от того, какую работу должен выполнять сервер. Стабильно высокое использование процессора негативно влияет на отзывчивость системы. Часто приложениям и пакетным заданиям с интенсивными вычислениями необходим весь или почти весь объем ЦП. Однако, если система должна обслуживать веб-страницы или поддерживать интерактивные сеансы сервисов (например, SSH), тогда может понадобиться свободная вычислительная мощность.
Как и во многих других аспектах производительности, ключом к оптимизации ресурсов является изучение потребностей сервисов системы и мониторинг непредвиденных изменений.
Мониторинг ЦП
Существует множество инструментов для получения данных о состоянии ЦП системы. Мы рассмотрим две команды: uptime и top. Обе утилиты являются частью стандартной установки большинства популярных дистрибутивов Linux и обычно используются для исследования загрузки и использования ЦП.
Примечание: Следующие примеры выполнены на 2-ядерном сервере.
Утилита uptime
Команда uptime позволяет отследить загрузку процессора. Она может быть полезна, если система медленно реагирует на интерактивные запросы (вероятно, ей не хватает системных ресурсов).
Утилита uptime сообщает следующие данные:
- системное время в момент выполнения команды;
- как долго работает сервер;
- сколько подключений пользователей обслуживает машина;
- средняя загрузка процессора за последние одну, пять и пятнадцать минут.
uptime
14:08:15 up 22:54, 2 users, load average: 2.00, 1.37, 0.63
В этом примере команда была запущена в 14:08 на сервере, который работал почти 23 часа. При запуске uptime подключились два пользователя. Этот сервер имеет 2 процессора. За минуту до запуска команды средняя загрузка процессора была 2,00, что означает, что в течение этой минуты процессоры использовали в среднем две задачи, а ожидающих задач не было. Среднее значение загрузки з а5 минут указывает на то, что в течение некоторого интервала времени один из процессоров бездействовал около 60% времени. Среднее за 15 минут значение указывает на то, что было доступно больше времени обработки. Вместе эти три значения показывают увеличение загрузки за последние пятнадцать минут.
Утилита uptime сообщает полезные средние значения загрузки ЦП, но для того, чтобы получить более подробную информацию, нужно использовать top.
Утилита top
Как и uptime, утилита top доступна как в Linux, так и в Unix-системах, но помимо отображения средних значений нагрузки для заданных временных интервалов она предоставляет информацию о потреблении ЦП в реальном времени, а также другие полезные показатели производительности. Если uptime запускается и сразу завершает работу, top работает на переднем плане и регулярно обновляется.
Заглавный блок
Первые пять строк содержат сводную информацию о процессах на сервере:
top — 18:31:30 up 1 day, 3:17, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 114 total, 1 running, 113 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.7 us, 0.0 sy, 0.0 ni, 92.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.1 st
KiB Mem : 4046532 total, 3238884 free, 73020 used, 734628 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 3694712 avail Mem
Первая строка почти идентична выводу утилиты uptime. Здесь показаны средние значения за одну, пять и пятнадцать минут. Эта строка отличается от вывода uptime только тем, что вначале указывается утилита top и время последнего обновления данных.
Вторая строка предоставляет краткий обзор состояния задач: общее количество процессов, количество запущенных, спящих, остановленных и зависших процессов.
Третья строка говорит об использовании ЦП. Эти цифры нормируются и отображаются в процентах (без символа %), так что все значения в этой строке должны составлять до 100% независимо от количества процессоров.
Четвертая и пятая строки сообщают об использовании памяти и swap соответственно.
После заглавного блока следует таблица с информацией о каждом отдельном процессе, которую мы вскоре рассмотрим.
В нижеприведенном заглавном блоке среднее значение загрузки за одну минуту превышает число процессоров на .77, что указывает на короткую очередь с небольшим временем ожидания. Общая емкость процессора используется на 100%, и есть много свободной памяти.
top — 14:36:05 up 23:22, 2 users, load average: 2.77, 2.27, 1.91
Tasks: 117 total, 3 running, 114 sleeping, 0 stopped, 0 zombie
%Cpu(s): 98.3 us, 0.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.2 si, 1.3 st
KiB Mem : 4046532 total, 3244112 free, 72372 used, 730048 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 3695452 avail Mem
. . .
Давайте рассмотрим подробнее все компоненты строки CPU.
- us, user: время на un-niced процессы пользователя. Эта категория относится к пользовательским процессам, которые были запущены без явного приоритета планирования. Системы Linux используют команду nice для установки приоритета планирования процесса. «un-niced» означает, что приоритет по умолчанию не менялся с помощью nice. Значения user и nice учитывают все пользовательские процессы. Высокое использование ЦП в этой категории может указывать на неконтролируемый процесс. Вывод в таблице процессов может определить, действительно ли это так.
- sy, system: системные процессы. Большинство приложений имеют как пользовательские компоненты, так и компоненты ядра. Когда ядро Linux создает системные вызовы, проверяет привилегии или взаимодействует с устройствами от имени приложения, здесь отображается использование процессора. Когда процесс выполняется не ядром, он будет отображаться либо в показателе user, либо в nice, если его приоритет был задан с помощью nice.
- ni, nice: niced процессы пользователя. Как и user, это поле отображает задачи, не связанные с ядром. В отличие от user, приоритет планирования для этих задач был установлен с помощью nice. Уровень приоритета (niceness) процесса указан в четвертом столбце таблицы процессов в заголовке NI. Процессы со значением niceness от 1 до 20 имеют пониженный приоритет. Такие процессы, потребляющие много процессорного времени, обычно не создают проблем, потому что задачи с повышенным приоритетом получат вычислительную мощность своевременно. Однако, если задачи с повышенным приоритетом (между -1 и -20) занимают непропорциональное количество CPU, они могут легко повлиять на отзывчивость системы. Обратите внимание, что многие процессы с самым высоким приоритетом планирования (-19 или -20 в зависимости от системы) порождаются ядром для выполнения важных задач, которые влияют на стабильность системы. Если вы не уверены, что точно знаете все процессы, указанные в выводе, лучше исследуйте их, но не останавливайте.
- Id, idle: время, затраченное на обработчик простоя ядра. Этот показатель отображает процент времени, в течение которого ЦП был доступен и простаивал. Считается, что система разумно использует ЦП, если сумма user, nice и idle близка к 100%.
- wa, IO-wait: время ожидания завершения ввода-вывода. Показатель сообщает, когда процессор начал операцию чтения или записи и ожидает завершения операции ввода-вывода. Задачи чтения и записи для удаленных ресурсов (таких как NFS и LDAP) будут также учитываться. Как и в строке idle, прыжки здесь считаются нормой. Но если показатель сообщает о частых или продолжительных обработках, это может указывать на зависшую задачу или потенциальную проблему с жестким диском.
- hi: время на бслуживание аппаратных прерываний. Это время, затрачиваемое на физические прерывания, отправленные на процессор с периферийных устройств (дисков и аппаратных сетевых интерфейсов). Если значение аппаратного прерывания велико, одно из периферийных устройств может работать неправильно.
- si: время, затраченное на обслуживание программных прерываний. Программные прерывания отправляются процессами, а не физическими устройствами. В отличие от аппаратных прерываний, которые происходят на уровне ЦП, программные прерывания происходят на уровне ядра. Если этот показатель сообщает о высоком использовании вычислительной мощности, исследуйте процессы, которые используют CPU.
- st: время, которое использовал гипервизор. Значение steal сообщает, как долго виртуальный процессор ожидает ответа физического процессора, когда гипервизор обслуживает свои задачи или другой виртуальный процессор. По сути, объем использования ЦП в этом поле указывает, сколько мощности для обработки виртуальной машины готово к использованию, но недоступно приложению, поскольку оно используется физическим хостом или другой виртуальной машиной. Как правило, нормой значения steal считается до 10% в течение коротких периодов времени. Большее значение steal в течение более длительного периода времени указывает на то, что физический сервер имеет больший спрос на CPU, чем он может предоставить.
Таблица процессов
Все процессы, выполняемые на сервере, независимо от их состояния перечисляются под заглавным блоком вывода. Ниже приведены первые шесть строк таблицы процессов из предыдущего примера. По умолчанию таблица процессов сортируется по% CPU, поэтому в начале находятся процессы, которые потребляют больше CPU.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9966 8host 20 0 9528 96 0 R 99.7 0.0 0:40.53 stress
9967 8host 20 0 9528 96 0 R 99.3 0.0 0:40.38 stress
7 root 20 0 0 0 0 S 0.3 0.0 0:01.86 rcu_sched
1431 root 10 -10 7772 4556 2448 S 0.3 0.1 0:22.45 iscsid
9968 root 20 0 42556 3604 3012 R 0.3 0.1 0:00.08 top
9977 root 20 0 96080 6556 5668 S 0.3 0.2 0:00.01 sshd
.
Столбец %CPU представлен как процентное значение, но он не нормируется, поэтому в этой двухъядерной системе общее количество всех значений в таблице процессов должно составлять до 200%, если оба процессора полностью используются.
Примечание: Если вы предпочитаете работать с нормированными значениями, вы можете нажать SHIFT + I, и отображение переключится с режима Irix в режим Solaris. Этот режим выводит ту же информацию, которая усредняется по всему количеству процессоров, так что используемая сумма не будет превышать 100%. Перейдя к режиму Solaris, вы получите краткое сообщение о том, что режим Irix выключен.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10081 8host 20 0 9528 96 0 R 50.0 0.0 0:49.18 stress
10082 8host 20 0 9528 96 0 R 50.0 0.0 0:49.08 stress
1439 root 20 0 223832 27012 14048 S 0.2 0.7 0:11.07 snapd
1 root 20 0 39832 5868 4020 S 0.0 0.1 0:07.31 systemd
Заключение
Теперь вы умеете работать с утилитами uptime и top и интерпретировать их вывод.
Источник



