- Создание и настройка виртуальных сетевых интерфейсов в Linux
- 1. Введение
- 2. Временный виртуальный сетевой интерфейс
- 2.1. Отключение виртуального сетевого интерфейса
- 3. Присвоение виртуальному интерфейсу постоянного адреса
- 3.1. Debian / Ubuntu
- 3.1.1. Статический адрес
- 3.1.2. Dhcp
- 3.2. Redhat / Fedora / CentOS
- 3.2.1. Статический адрес
- 3.2.2. Dhcp
- 4. Заключение
- Виртуальный сетевой интерфейс в linux. TAP vs TUN
- Создаем виртуальный интерфейс в linux вручную
- Создаем интерфейс типа tun
- Создаем интерфейс типа tap
- Создаем интерфейс типа dummy
- Создаем виртуальный интерфейс в linux с помощью systemd-networkd
- Создаем интерфейс типа tun
- Создаем интерфейс типа tap
- Создаем интерфейс типа dummy
- Introduction to Linux interfaces for virtual networking
- Bridge
- Bonded interface
- Team device
- VXLAN
- MACVLAN
- IPVLAN
- MACVTAP/IPVTAP
- MACsec
- VXCAN
- IPOIB
- NLMON
- Dummy interface
- Additional resources
- netdevsim interface
Создание и настройка виртуальных сетевых интерфейсов в Linux
1. Введение
Знаете ли вы, что можете присвоить более чем один IP-адрес физическому сетевому интерфейсу? Эта техника очень полезна, например при работе с Apache и виртуальными хостами, так как позволяет получить доступ к одному и тому же серверу Apache с двух разных IP-адресов.
2. Временный виртуальный сетевой интерфейс
Процесс создания виртуального сетевого интерфейса в Linux не занимает много времени. Он включает один запуск команды ifconfig.
Приведенная выше команда создает виртуальный сетевой интерфейс, базирующийся на оригинальном физическом сетевом интерфейсе eth0. Самое важное условие для создания виртуального сетевого интерфейса — должен существовать физический сетевой интерфейс, в нашем случае eth0. Ниже приведен полный пример:
Теперь мы можем настроить новый виртуальный интерфейс на базе eth0. После выполнения команды ifconfig новый виртуальный интерфейс готов к немедленному использованию.
2.1. Отключение виртуального сетевого интерфейса
Для отключения нашего, созданного ранее, временного сетевого интерфейса мы можем также использовать команду ifconfig с флагом down.
3. Присвоение виртуальному интерфейсу постоянного адреса
Описанные выше настройки не сохраняются после перезагрузки. Если вы хотите, чтобы виртуальный сетевой интерфейс работал постоянно, необходимо модифицировать конфигурационные файлы в соответствии с требованиями вашего дистрибутива Linux. Ниже описан этот процесс для самых распространенных дистрибутивов:
3.1. Debian / Ubuntu
3.1.1. Статический адрес
В Debian или Ubuntu вам необходимо отредактировать файл /etc/network/interfaces, добавив в него следующие строки:
3.1.2. Dhcp
Возможно также использовать витруальный сетевой интерфейс с DHCP. В этом случае вам необходимо добавить в /etc/network/interfaces следующую строку:
Для того, чтобы изменения вступили в силу, необходимо перезапустить сеть:
3.2. Redhat / Fedora / CentOS
3.2.1. Статический адрес
В Redhat, Fedora или CentOS Linux директория, отвечающая за присвоение постоянных IP-адресов — это /etc/sysconfig/network-scripts. В этой директории необходимо создать файл, соответствующий вашему новому виртуальному интерфейсу. В нашем случае этот файл будет называться ifcfg-eth0:0. Создайте этот новый файл и вставьте в него приведенные ниже строки. После перезагрузки адрес будет присвоен виртуальному интерфейсу на постоянной основе.
3.2.2. Dhcp
Когда закончите, перезапустите ваши интерфейсы:
4. Заключение
Раньше один физический сервер обслуживал один веб-сайт. Сегодня такой способ хостинга уже не является жизнеспособным, поэтому способность операционной системы создавать виртуальные сетевые интерфейсы действительно необходима.
Источник
Виртуальный сетевой интерфейс в linux. TAP vs TUN
Читатели, не нуждающиеся в теоретическом изложении концепции виртуальных сетевый интерфейсов Linux, могут сразу перейти к настройке по ссылкам:
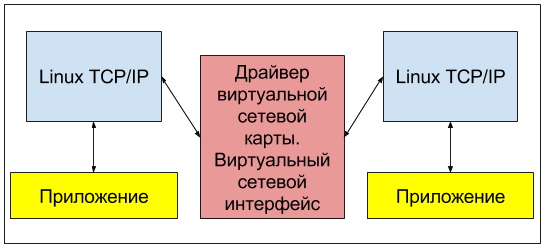
Создавать сетевые интерфейсы в linux нам позволяют различные модули ядра. Но там, где для реальных железных сетевых карт эти модули ядра, или как их еще называют — драйверы, обеспечивают прием данных от стека TCP/IP и их формирование уже в виде электрического сигнала на сетевой карте, драйверы виртуальных сетевых интерфейсов (loopback) могут лишь, приняв эти данные, отдать их какому-нибудь приложению для дальнейшей обработки. Такая функциональность может быть востребована, если на вашем сервере установлены программы, использующие стек TCP/IP для обмена данными и, понятно, не нуждающиеся в выводе этих данных в реальную сеть. Пример: веб-сайт на drupal связывается с базой данных, установленной на этом же сервере:
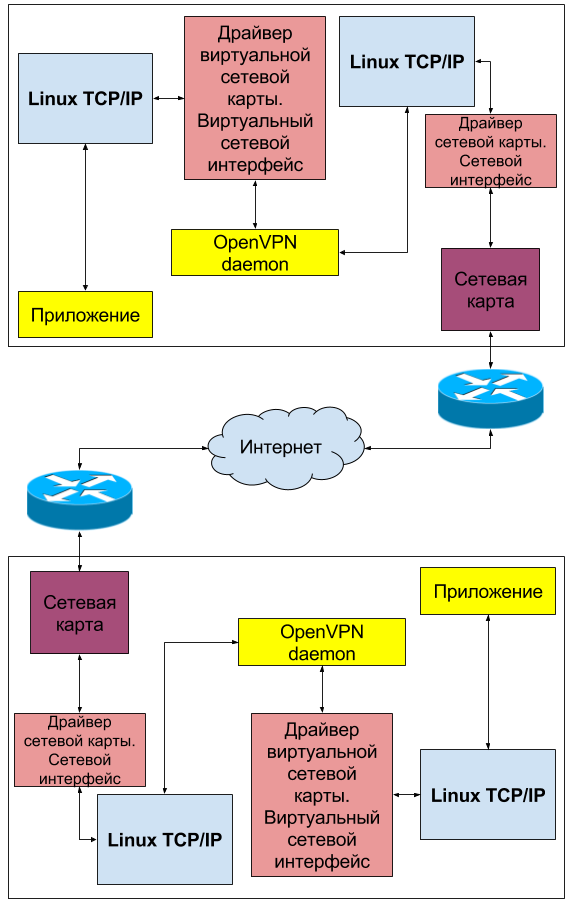
Другим распростаренным примером использования виртуальных сетевых интерфейсов (loopback) в linux может быть их использование для целей построения виртуальных частных сетей — VPN. Вы наверняка слышали о таких технологиях как OpenVPN, GRE, WireGuard и т.д. Каждый из этих демонов создает виртуальный сетевой интерфейс который служит для прозрачной маршрутизации данных между узлами, находящимися на удалении друг от друга и не имеющих возможности прямого взаимодействия. Рассмотрим общую сетевую топологию на примере OpenVPN:
От используемого драйвера зависит тип интерфейса, его скорость, допустимый размер MTU и т. д. Совсем даже не обязательно, что загружать драйвер в ядро вам придется самостоятельно. Скорее всего, создавая интерфейс нужного типа, система сама подберет и загрузит требуемый драйвер. Вам лишь останется сконфигурировать уже работающий loopback интерфейс. В данной статье мы рассмотрим 3 возможных на конец 2016 года типа виртуальных интерфейсов в linux: tun, tap и dummy. Отличие интерфейсов tun и tap заключается в том, что tap старается больше походить на реальный сетевой интерфейс, а именно он позволяет себе принимать и отправлять ARP запросы, обладает MAC адресом и может являться одним из интерфейсов сетевого моста, так как он обладает полной поддержкой ethernet — протокола канального уровня (уровень 2). Интерфейс tun этой поддержки лишен, поэтому он может принимать и отправлять только IP пакеты и никак не ethernet кадры. Он не обладает MAC-адресом и не может быть добавлен в бридж. Зато он более легкий и быстрый за счет отсутствия дополнительной инкапсуляции и прекрасно подходит для тестирования сетевого стека или построения виртуальных частных сетей (VPN). Виртуальный интерфейс типа dummy очень похож на tap, разница лишь в том, что он реализуется другим модулем ядра.
Создаем виртуальный интерфейс в linux вручную
Создавать и удалять интерфейсы, назначать IP и MAC адреса, изменять MTU и многое другое нам помогает утилита ip. Пользоваться ip удобно и легко, но помните, что произведенные изменения будут потеряны после перезагрузки компьютера. Используйте ip в целях тестирования.
Создаем интерфейс типа tun
ip tuntap add dev tun0 mode tun
ip address add 192.168.99.1/30 dev tun0
ip address show tun0
2: tun0:
mtu 1500 qdisc noop state DOWN group default qlen 500
link/none
inet 192.168.99.1/30 scope global tun0
valid_lft forever preferred_lft forever
Как видим у нас теперь есть виртуальный интерфейс с именем «tun0», у него есть IP-адрес, и ни слова о MAC-адресе — всё, как мы и рассчитывали. Его уже можно пинговать, и на нем уже можно запускать слушающие сервисы. Но что будет, если мы попытаемся добавить этот интерфейс в бридж?
ip link set dev tun0 master br0
RTNETLINK answers: Invalid argument
Команда ip логичным образом выдала ошибку — нет никакого смысла добавлять в бридж интерфейс, не обладающий поддержкой ethernet.
Создаем интерфейс типа tap
ip tuntap add dev tap0 mode tap
ip address add 192.168.99.5/30 dev tap0
ip address show tap0
3: tap0:
mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether d6:1c:67:cd:6f:80 brd ff:ff:ff:ff:ff:ff
inet 192.168.99.5/30 scope global tap0
valid_lft forever preferred_lft forever
У нас теперь появился новый виртуальный интерфейс с именем «tap0», у него есть как IP-адрес, так и MAC-адреса. Его также можно пинговать, и на нем также можно запускать слушающие сервисы. Команда, добавляющая интерфейс в бридж уже не выдаст ошибку, потому что это интерфейс, обладающий поддержкой ethernet:
ip link set dev tap0 master br0
Создаем интерфейс типа dummy
ip link add dev dum0 type dummy
ip address add 192.168.99.9/30 dev dum0
ip address show dum0
4: dum0:
mtu 1500 qdisc noop master br0 state DOWN group default qlen 1000
link/ether 1a:37:3b:0f:da:be brd ff:ff:ff:ff:ff:ff
inet 192.168.99.9/30 scope global dum0
valid_lft forever preferred_lft forever
Вы наверняка заметили, что команда для добавления интерфейса изменилась. Ничего необычного. Так написана утилита «ip». Ну и конечно, виртуальный интерфейс типа dummy можно легко добавить в бридж:
ip link set dev dum0 master br0
Создаем виртуальный интерфейс в linux с помощью systemd-networkd
В systemd-networkd за создание интерфейсов отвечают одни конфигурационные файлы, имеющие суффикс «.netdev», а за их настройку другие, имеющие суффикс «.network». Соответственно нам понадобиться в /etc/systemd/network создать по паре конфигурационных файлов для каждого из исследуемых типов интерфейсов
Создаем интерфейс типа tun
Создадим соответственно файлы tun0.netdev с содержимым:
[NetDev]
Name=tun0
Kind=tun
Создаем интерфейс типа tap
Создадим соответственно файлы tap0.netdev с содержимым:
[NetDev]
Name=tap0
Kind=tap
Создаем интерфейс типа dummy
Создадим соответственно файлы dum0.netdev с содержимым:
[NetDev]
Name=dum0
Kind=dummy
Стоит отметить, что если вы планируете маршрутизировать траффик через виртуальные интерфейсы ( а, используя их для цели создания виртуальных частных сетей (VPN), вы точно этого хотите), то в конфигурационный файл в секии «Network» следует добавить диррективу «IPForward=yes».
Источник
Introduction to Linux interfaces for virtual networking

Linux has rich virtual networking capabilities that are used as basis for hosting VMs and containers, as well as cloud environments. In this post, I will give a brief introduction to all commonly used virtual network interface types. There is no code analysis, only a brief introduction to the interfaces and their usage on Linux. Anyone with a network background might be interested in this blog post. A list of interfaces can be obtained using the command ip link help .
This post covers the following frequently used interfaces and some interfaces that can be easily confused with one another:
After reading this article, you will know what these interfaces are, what’s the difference between them, when to use them, and how to create them.
For other interfaces like tunnel, please see An introduction to Linux virtual interfaces: Tunnels
Bridge
A Linux bridge behaves like a network switch. It forwards packets between interfaces that are connected to it. It’s usually used for forwarding packets on routers, on gateways, or between VMs and network namespaces on a host. It also supports STP, VLAN filter, and multicast snooping.
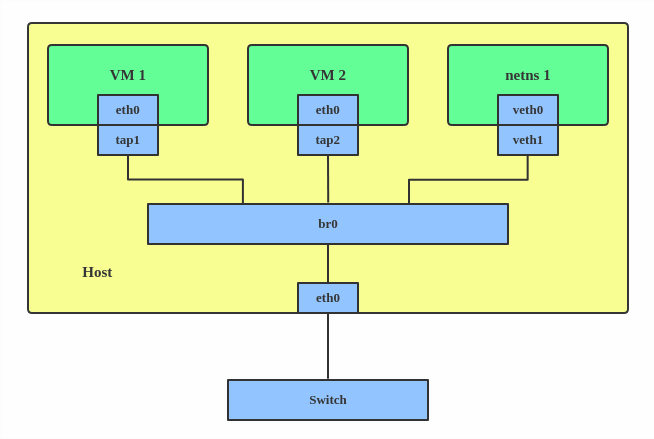
Use a bridge when you want to establish communication channels between VMs, containers, and your hosts.
Here’s how to create a bridge:
This creates a bridge device named br0 and sets two TAP devices ( tap1 , tap2 ), a VETH device ( veth1 ), and a physical device ( eth0 ) as its slaves, as shown in the diagram above.
Bonded interface
The Linux bonding driver provides a method for aggregating multiple network interfaces into a single logical «bonded» interface. The behavior of the bonded interface depends on the mode; generally speaking, modes provide either hot standby or load balancing services.
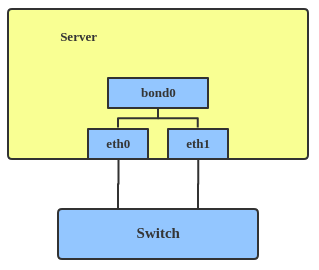
Use a bonded interface when you want to increase your link speed or do a failover on your server.
Here’s how to create a bonded interface:
This creates a bonded interface named bond1 with mode active-backup. For other modes, please see the kernel documentation.
Team device
Similar a bonded interface, the purpose of a team device is to provide a mechanism to group multiple NICs (ports) into one logical one (teamdev) at the L2 layer.

The main thing to realize is that a team device is not trying to replicate or mimic a bonded interface. What it does is to solve the same problem using a different approach, using, for example, a lockless (RCU) TX/RX path and modular design.
But there are also some functional differences between a bonded interface and a team. For example, a team supports LACP load-balancing, NS/NA (IPV6) link monitoring, D-Bus interface, etc., which are absent in bonding. For further details about the differences between bonding and team, see Bonding vs. Team features.
Use a team when you want to use some features that bonding doesn’t provide.
Here’s how to create a team:
This creates a team interface named team0 with mode active-backup , and it adds eth0 and eth1 as team0 ‘s sub-interfaces.
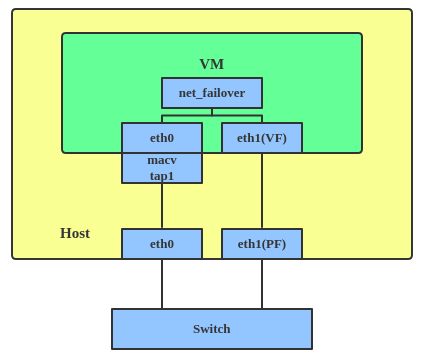
A new driver called net_failover has been added to Linux recently. It’s another failover master net device for virtualization and manages a primary (passthru/VF [Virtual Function] device) slave net device and a standby (the original paravirtual interface) slave net device.
A VLAN, aka virtual LAN, separates broadcast domains by adding tags to network packets. VLANs allow network administrators to group hosts under the same switch or between different switches.
The VLAN header looks like:
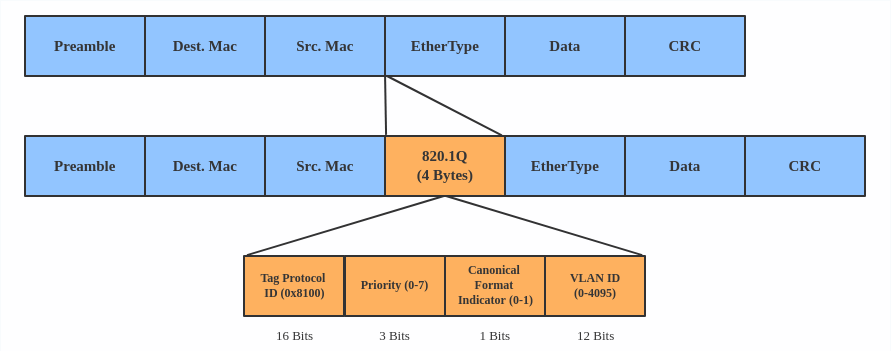
Use a VLAN when you want to separate subnet in VMs, namespaces, or hosts.
Here’s how to create a VLAN:
This adds VLAN 2 with name eth0.2 and VLAN 3 with name eth0.3 . The topology looks like this:
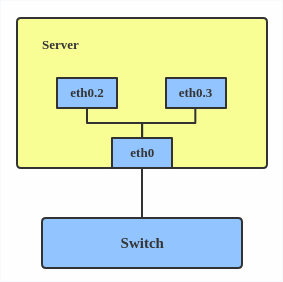
Note: When configuring a VLAN, you need to make sure the switch connected to the host is able to handle VLAN tags, for example, by setting the switch port to trunk mode.
VXLAN
VXLAN (Virtual eXtensible Local Area Network) is a tunneling protocol designed to solve the problem of limited VLAN IDs (4,096) in IEEE 802.1q. It is described by IETF RFC 7348.
With a 24-bit segment ID, aka VXLAN Network Identifier (VNI), VXLAN allows up to 2^24 (16,777,216) virtual LANs, which is 4,096 times the VLAN capacity.
VXLAN encapsulates Layer 2 frames with a VXLAN header into a UDP-IP packet, which looks like this:
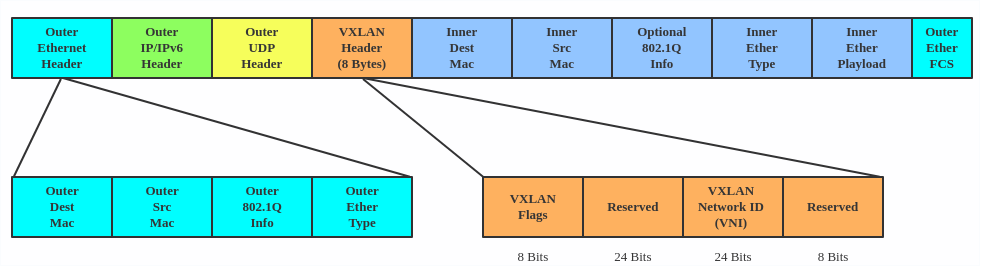
VXLAN is typically deployed in data centers on virtualized hosts, which may be spread across multiple racks.
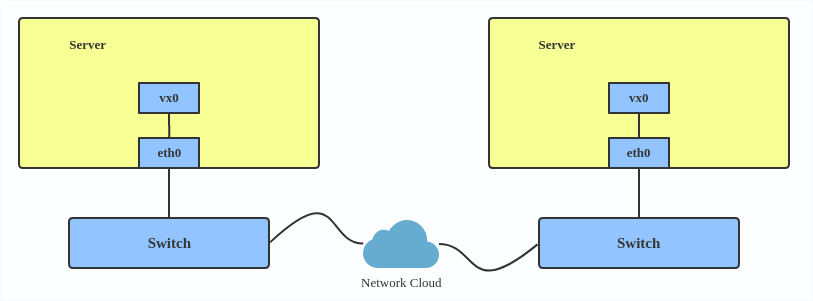
Here’s how to use VXLAN:
MACVLAN
With VLAN, you can create multiple interfaces on top of a single one and filter packages based on a VLAN tag. With MACVLAN, you can create multiple interfaces with different Layer 2 (that is, Ethernet MAC) addresses on top of a single one.
Before MACVLAN, if you wanted to connect to physical network from a VM or namespace, you would have needed to create TAP/VETH devices and attach one side to a bridge and attach a physical interface to the bridge on the host at the same time, as shown below.
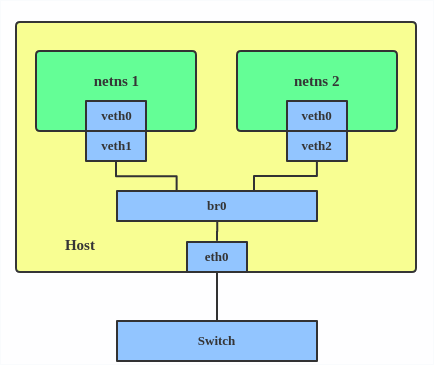
Now, with MACVLAN, you can bind a physical interface that is associated with a MACVLAN directly to namespaces, without the need for a bridge.
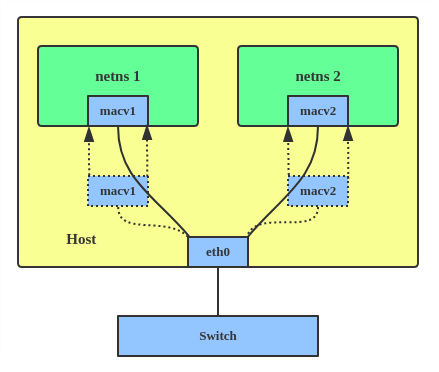
There are five MACVLAN types:
1. Private: doesn’t allow communication between MACVLAN instances on the same physical interface, even if the external switch supports hairpin mode.
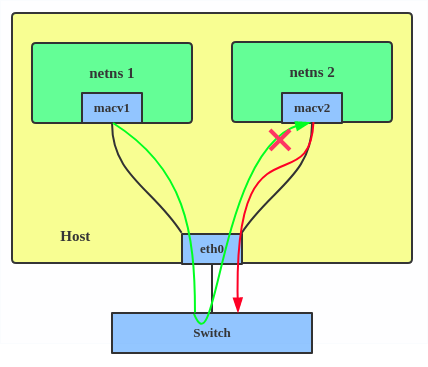
2. VEPA: data from one MACVLAN instance to the other on the same physical interface is transmitted over the physical interface. Either the attached switch needs to support hairpin mode or there must be a TCP/IP router forwarding the packets in order to allow communication.
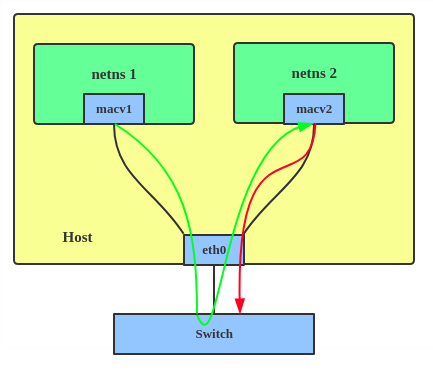
3. Bridge: all endpoints are directly connected to each other with a simple bridge via the physical interface.
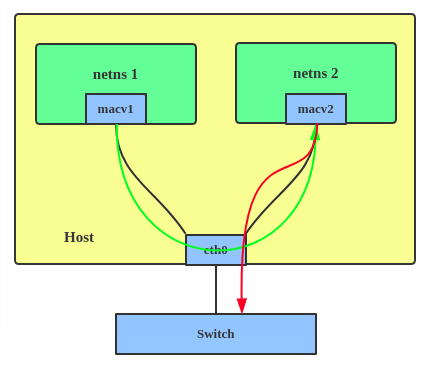
4. Passthru: allows a single VM to be connected directly to the physical interface.
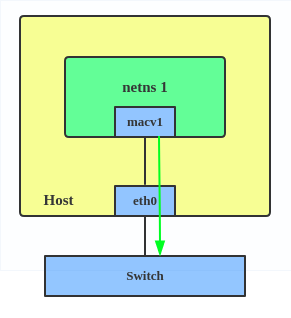
5. Source: the source mode is used to filter traffic based on a list of allowed source MAC addresses to create MAC-based VLAN associations. Please see the commit message.
The type is chosen according to different needs. Bridge mode is the most commonly used.
Use a MACVLAN when you want to connect directly to a physical network from containers.
Here’s how to set up a MACVLAN:
This creates two new MACVLAN devices in bridge mode and assigns these two devices to two different namespaces.
IPVLAN
IPVLAN is similar to MACVLAN with the difference being that the endpoints have the same MAC address.
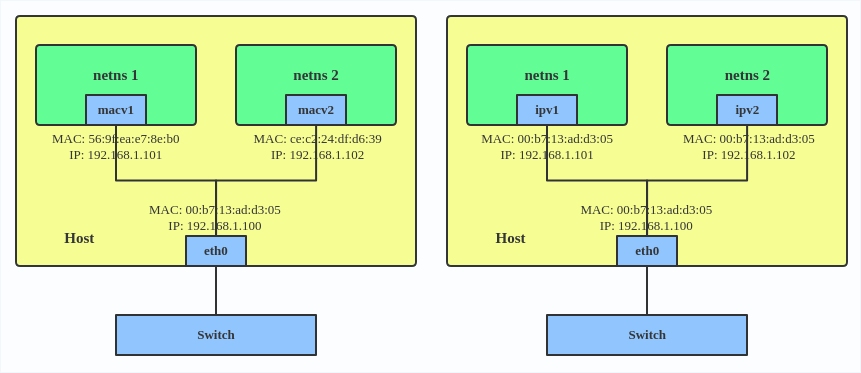
IPVLAN supports L2 and L3 mode. IPVLAN L2 mode acts like a MACVLAN in bridge mode. The parent interface looks like a bridge or switch.
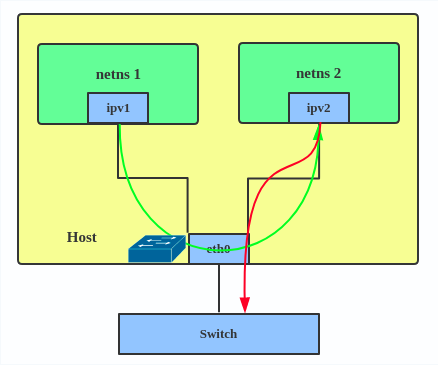
In IPVLAN L3 mode, the parent interface acts like a router and packets are routed between endpoints, which gives better scalability.
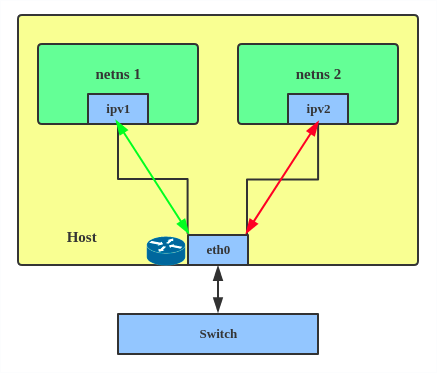
Regarding when to use an IPVLAN, the IPVLAN kernel documentation says that MACVLAN and IPVLAN «are very similar in many regards and the specific use case could very well define which device to choose. if one of the following situations defines your use case then you can choose to use ipvlan —
(a) The Linux host that is connected to the external switch / router has policy configured that allows only one mac per port.
(b) No of virtual devices created on a master exceed the mac capacity and puts the NIC in promiscuous mode and degraded performance is a concern.
(c) If the slave device is to be put into the hostile / untrusted network namespace where L2 on the slave could be changed / misused.»
Here’s how to set up an IPVLAN instance:
This creates an IPVLAN device named ipvl0 with mode L2, assigned to namespace ns0 .
MACVTAP/IPVTAP
MACVTAP/IPVTAP is a new device driver meant to simplify virtualized bridged networking. When a MACVTAP/IPVTAP instance is created on top of a physical interface, the kernel also creates a character device/dev/tapX to be used just like a TUN/TAP device, which can be directly used by KVM/QEMU.
With MACVTAP/IPVTAP, you can replace the combination of TUN/TAP and bridge drivers with a single module:
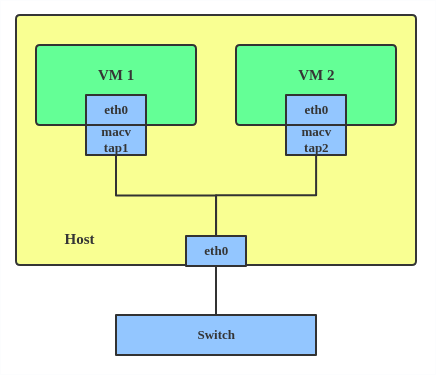
Typically, MACVLAN/IPVLAN is used to make both the guest and the host show up directly on the switch to which the host is connected. The difference between MACVTAP and IPVTAP is same as with MACVLAN/IPVLAN.
Here’s how to create a MACVTAP instance:
MACsec
MACsec (Media Access Control Security) is an IEEE standard for security in wired Ethernet LANs. Similar to IPsec, as a layer 2 specification, MACsec can protect not only IP traffic but also ARP, neighbor discovery, and DHCP. The MACsec headers look like this:
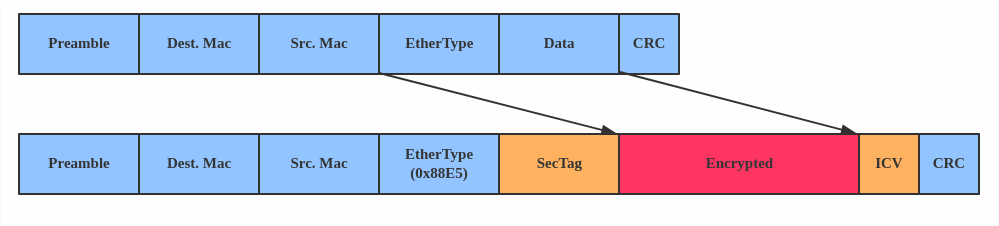
The main use case for MACsec is to secure all messages on a standard LAN including ARP, NS, and DHCP messages.
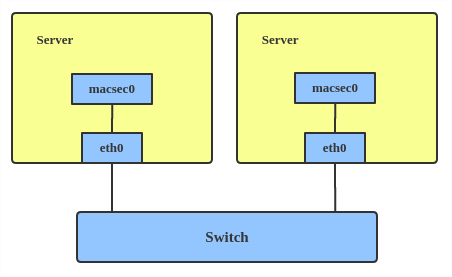
Here’s how to set up a MACsec configuration:
Note: This only adds a MACsec device called macsec0 on interface eth1 . For more detailed configurations, please see the «Configuration example» section in this MACsec introduction by Sabrina Dubroca.
The VETH (virtual Ethernet) device is a local Ethernet tunnel. Devices are created in pairs, as shown in the diagram below.
Packets transmitted on one device in the pair are immediately received on the other device. When either device is down, the link state of the pair is down.
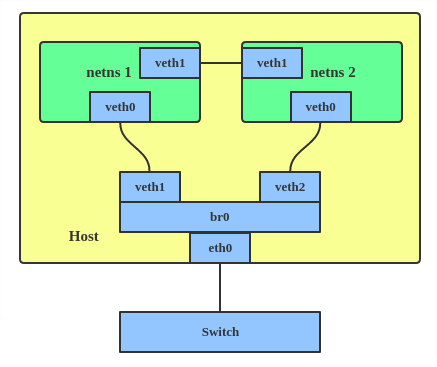
Use a VETH configuration when namespaces need to communicate to the main host namespace or between each other.
Here’s how to set up a VETH configuration:
This creates two namespaces, net1 and net2 , and a pair of VETH devices, and it assigns veth1 to namespace net1 and veth2 to namespace net2 . These two namespaces are connected with this VETH pair. Assign a pair of IP addresses, and you can ping and communicate between the two namespaces.
Similar to the network loopback devices, the VCAN (virtual CAN) driver offers a virtual local CAN (Controller Area Network) interface, so users can send/receive CAN messages via a VCAN interface. CAN is mostly used in the automotive field nowadays.
For more CAN protocol information, please refer to the kernel CAN documentation.
Use a VCAN when you want to test a CAN protocol implementation on the local host.
Here’s how to create a VCAN:
VXCAN
Similar to the VETH driver, a VXCAN (Virtual CAN tunnel) implements a local CAN traffic tunnel between two VCAN network devices. When you create a VXCAN instance, two VXCAN devices are created as a pair. When one end receives the packet, the packet appears on the device’s pair and vice versa. VXCAN can be used for cross-namespace communication.
Use a VXCAN configuration when you want to send CAN message across namespaces.
Here’s how to set up a VXCAN instance:
Note: VXCAN is not yet supported in Red Hat Enterprise Linux.
IPOIB
An IPOIB device supports the IP-over-InfiniBand protocol. This transports IP packets over InfiniBand (IB) so you can use your IB device as a fast NIC.
The IPoIB driver supports two modes of operation: datagram and connected. In datagram mode, the IB UD (Unreliable Datagram) transport is used. In connected mode, the IB RC (Reliable Connected) transport is used. The connected mode takes advantage of the connected nature of the IB transport and allows an MTU up to the maximal IP packet size of 64K.
For more details, please see the IPOIB kernel documentation.
Use an IPOIB device when you have an IB device and want to communicate with a remote host via IP.
Here’s how to create an IPOIB device:
NLMON
NLMON is a Netlink monitor device.
Use an NLMON device when you want to monitor system Netlink messages.
Here’s how to create an NLMON device:
This creates an NLMON device named nlmon0 and sets it up. Use a packet sniffer (for example, tcpdump ) to capture Netlink messages. Recent versions of Wireshark feature decoding of Netlink messages.
Dummy interface
A dummy interface is entirely virtual like, for example, the loopback interface. The purpose of a dummy interface is to provide a device to route packets through without actually transmitting them.
Use a dummy interface to make an inactive SLIP (Serial Line Internet Protocol) address look like a real address for local programs. Nowadays, a dummy interface is mostly used for testing and debugging.
Here’s how to create a dummy interface:
The IFB (Intermediate Functional Block) driver supplies a device that allows the concentration of traffic from several sources and the shaping incoming traffic instead of dropping it.
Use an IFB interface when you want to queue and shape incoming traffic.
Here’s how to create an IFB interface:
This creates an IFB device named ifb0 and replaces the root qdisc scheduler with SFQ (Stochastic Fairness Queueing), which is a classless queueing scheduler. Then it adds an ingress qdisc scheduler on eth0 and redirects all ingress traffic to ifb0 .
For more IFB qdisc use cases, please refer to this Linux Foundation wiki on IFB.
Additional resources
- Virtual networking articles on the Red Hat Developer blog
- Dynamic IP Address Management in Open Virtual Network (OVN)
- Non-root Open vSwitch in Red Hat Enterprise Linux
- Open vSwitch articles on the Red hat Developer Blog
netdevsim interface
netdevsim is a simulated networking device which is used for testing various networking APIs. At this time it is particularly focused on testing hardware
offloading, tc/XDP BPF and SR-IOV.
A netdevsim device can be created as follows
To enable tc offload:
To load XDP BPF or tc BPF programs:
To add VFs for SR-IOV testing:
To change the vf numbers, you need to disable them completely first:
Note : netdevsim is not compiled in RHEL by default
Источник



