- Что такое каналы (pipe) в Linux? Как работает перенаправление каналов?
- Каналы в Linux: общая идея
- Имейте в виду: Pipe перенаправляет стандартный вывод на стандартный ввод, но не как аргумент команды
- Типы каналов в Linux
- Каналы без названия
- Именованные каналы
- Именованные каналы не занимают память на диске
- Сниженный ввод-вывод
- Связь между двумя очень разными процессами
- Понимание каналов более низкого уровня [для опытных пользователей и разработчиков]
- Linux Pipe Command with Examples
- Prerequisites
- Syntax
- Sort the list using pipes
- Display file data of a corresponding range
- Pipe and more command
- Count the number of files
- Process identification
- Get sub-directories using pipe
- Get files using pipe
- Use multiple pipes in a single command
- Fetch particular data with pipes
- Conclusion
- About the author
- Aqsa Yasin
Что такое каналы (pipe) в Linux? Как работает перенаправление каналов?
Главное меню » Linux » Что такое каналы (pipe) в Linux? Как работает перенаправление каналов?

Вы, вероятно, также знаете, что такое перенаправление канала, которое используется для перенаправления вывода одной команды в качестве ввода для следующей команды.
Но знаете ли вы, что под ним? Как на самом деле работает перенаправление каналов?
Не беспокойтесь, потому что сегодня мы демистифицируем каналы Unix, чтобы в следующий раз, когда вы пойдете на свидание с этими причудливыми вертикальными полосами, вы точно знали, что происходит.
Примечание. Мы использовали термин Unix в некоторых местах, потому что концепция каналов (как и многие другие вещи в Linux) происходит от Unix.
Каналы в Linux: общая идея
Вот что вы повсюду увидите относительно «что такое каналы в Unix?»:
- Каналы Unix – это механизм IPC (межпроцессное взаимодействие), который перенаправляет вывод одной программы на вход другой программы.
Это общее объяснение, которое дают все. Мы хотим проникнуть глубже. Давайте перефразируем предыдущую строку более техническим языком, убрав абстракции:
- Каналы Unix – это механизм IPC (межпроцессного взаимодействия), который принимает программу stdout и пересылает ее другой программе stdin через буфер.
Намного лучше. Удаление абстракции сделало его намного чище и точнее. Вы можете посмотреть на следующую схему, чтобы понять, как работает pipe.
Один из простейших примеров команды pipe – передать некоторый вывод команды команде grep для поиска определенной строки.
Имейте в виду: Pipe перенаправляет стандартный вывод на стандартный ввод, но не как аргумент команды
Очень важно понять, что конвейер передает команду stdout другой команде stdin, но не как аргумент команды. Мы объясним это на примере.
Если вы используете команду cat без аргументов, по умолчанию будет выполняться чтение из stdin. Вот пример:
Здесь мы использовали cat без передачи файлов, поэтому по умолчанию stdin. Затем мы написали строку, а затем использовал Ctrl + d, чтобы сообщить, что закончили писать (Ctrl + d подразумевает EOF или конец файла). Как только мы закончили писать, cat прочитал stdin и написал эту строку в stdout.
Теперь рассмотрим следующую команду:
Вторая команда НЕ эквивалентна cat hey. Здесь stdout”hey” переносится в буфер и передает stdin в cat. Поскольку аргументов командной строки не было, cat по умолчанию выбрал stdin для чтения, а что-то уже было в stdin, поэтому команда cat приняла это и напечатала stdout.
Фактически, мы создали файл с именем hey и поместили в него некоторый контент.
Типы каналов в Linux
В Linux есть два типа каналов:
- Безымянный канал, также называемый анонимным.
- Именованные каналы
Каналы без названия
Без названия каналы, как следует из названия, не имеют имени. Они создаются на лету вашей оболочкой Unix всякий раз, когда вы используете символ |.
Когда люди говорят о каналах в Linux, они обычно говорят об этом. Они полезны, потому что вам, как конечному пользователю, не нужно ничего отслеживать. Ваша оболочка справится со всем этим.
Именованные каналы
Этот немного отличается. Именованные каналы действительно присутствуют в файловой системе. Они существуют как обычный файл. Вы можете создать именованный файл, используя следующую команду:
Это создаст файл с именем «pipe». Выполните следующую команду:
Обратите внимание на «p» в начале, это означает, что файл является каналом. Теперь воспользуемся этим каналом.
Как мы говорили ранее, конвейер пересылает вывод одной команды на вход другой. Это как курьерская служба, вы даете посылку доставить с одного адреса, а они доставляют по другому. Итак, первый шаг – предоставить пакет, то есть предоставить каналу что-то.
Вы заметите, что echo еще не вернули нам терминал. Откройте новый терминал и попробуйте прочитать из этого файла.
Обе эти команды завершили свое выполнение одновременно.
Это одно из фундаментальных различий между обычным файлом и именованным каналом. В канал ничего не записывается, пока какой-либо другой процесс не прочитает его.
Зачем использовать именованные каналы? Вот список того, почему вы хотите использовать именованные каналы
Именованные каналы не занимают память на диске
Если вы выполните a du -s pipe, вы увидите, что он не занимает места. Это потому, что именованные каналы похожи на конечные точки для чтения и записи из буфера памяти и в него. Все, что записывается в именованный канал, фактически сохраняется во временном буфере памяти, который сбрасывается, когда операция чтения выполняется из другого процесса.
Сниженный ввод-вывод
Поскольку запись в именованный канал означает сохранение данных в буфере памяти, операции с большими файлами значительно сокращают дисковый ввод-вывод.
Связь между двумя очень разными процессами
Выходные данные события можно мгновенно и очень эффективно получить из другого процесса с помощью именованных каналов. Поскольку чтение и запись происходят одновременно, время ожидания практически равно нулю.
Понимание каналов более низкого уровня [для опытных пользователей и разработчиков]
В следующем разделе речь идет о каналах на более глубоком уровне с фактическими реализациями. Этот раздел требует от вас базового понимания:
- Как работает программа на C
- Что такое системные вызовы
- Что такое процессы
- Что такое файловые дескрипторы
Мы не будем вдаваться в подробности примеров. Речь идет только о «каналах». Для большинства пользователей Linux этот раздел не нужен.
В конце мы предоставили для компиляции образец файла – Makefile. Имейте в виду, что эти программы предназначены только для иллюстративных целей, поэтому, если вы видите, что ошибки обрабатываются некорректно.
Рассмотрим следующий пример программы:
В строке 16 мы создали безымянный канал, используя функцию pipe(). Первое, что следует заметить, это то, что мы передали массив целых чисел со знаком длиной 2.
Это потому, что канал – это не что иное, как массив из двух целых чисел без знака, представляющих два файловых дескриптора. Один для письма, один для чтения. И оба они указывают на расположение буфера в памяти, которое обычно составляет 1 МБ.
Здесь мы назвали переменную fd. fd [0] – дескриптор входного файла, fd [1] – дескриптор выходного файла. В этой программе один процесс записывает строку в файловый дескриптор fd [1], а другой процесс читает из файлового дескриптора fd [0].
Именованный канал ничем не отличается. С именованным каналом вместо двух файловых дескрипторов вы получаете имя файла, которое можно открыть из любого процесса и работать с ним, как с любым другим файлом, учитывая при этом характеристики канала.
Вот пример программы, которая делает то же самое, что и предыдущая программа, но вместо анонимного канала создает именованный канал.
Здесь мы использовали системный вызов mknod для создания именованного канала. Как вы можете видеть, хотя мы удалили канал по завершении, вы вполне можете оставить его и легко использовать для связи между различными программами, просто открыв и записав в файл с именем «npipe» в моем случае.
Вам также не придется создавать два разных канала для двусторонней связи, как в случае с анонимными каналами.
Вот образец Makefile, как и было обещано. Поместите его в тот же каталог, что и предыдущие программы, с именами «pipe.c» и «fifo.c» соответственно.
Вот так. Это действительно все, что есть в каналах Unix.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Linux Pipe Command with Examples
Prerequisites
To apply pipe commands on Linux, you need to have a Linux environment in your system. This can be done by downloading a virtual box and configuring an Ubuntu file on it. Users must have privileges to access the applications required.
Syntax
Command 1 | command 2 | command 3 | ……
Sort the list using pipes
The pipe has much functionality used to filter, sort, and display the text in the list. One of the common examples is described here. Suppose we have a file named file1.txt having the names of the students. We have used the cat command to fetch the record of that file.
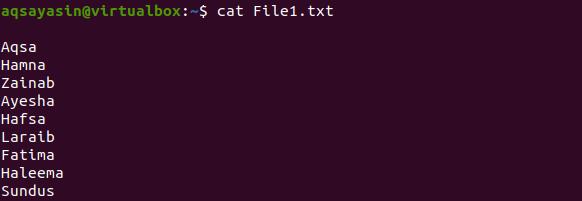
The data present in this file is unordered. So, to sort the data, we need to follow a piece of code here.
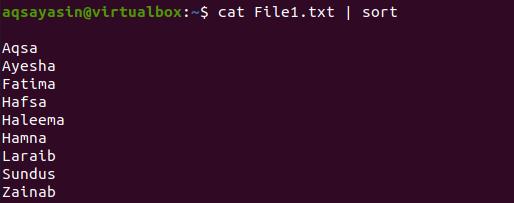
Through the respective output, you can see that students’ names are arranged alphabetically in a sequence from a to z.
Beside this. Suppose we want to get an output in sorted form plus removing redundancy. We will use the same command and a “uniq” keyword in addition to the default command. Let’s consider a file named file2.txt having the names of subjects in it. The same command is used for fetching data.
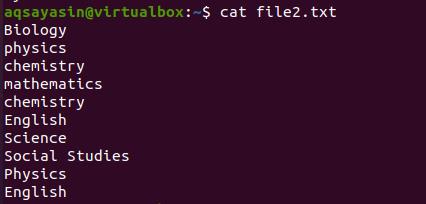
Now we will use the command to remove all the words that are duplicated in the file.
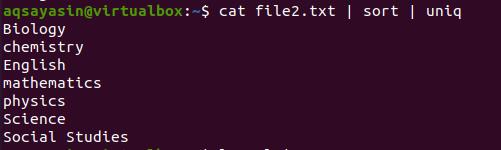
The output shows that the elements are organized and arranged alphabetically. At the same time, all the words that were duplicated are removed. The above command will only display the output, but we will use the below-cited command to save them.
The output will be saved in another file with the same extension.
Display file data of a corresponding range
It is very annoying when you want to get some data only from the start, but the command gives you all the matching items in your system. You can use the ‘head’ keyword. It helps to limit your output with concerning some range. i.e., in this example, we have declared the range up to 4. So the data will be from the first 4 lines of the file. Consider the same file file2.txt as we have taken an example above.
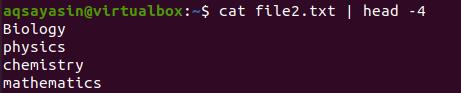
Similar to head, we can also use the tail option. This will limit the output to the last lines according to the range given.
Pipe and more command
By using more command, all the output is displayed at a time on the screen. The pipe act as a container and displays all the output data as an input of ls-l. Because the output is a long list of files.
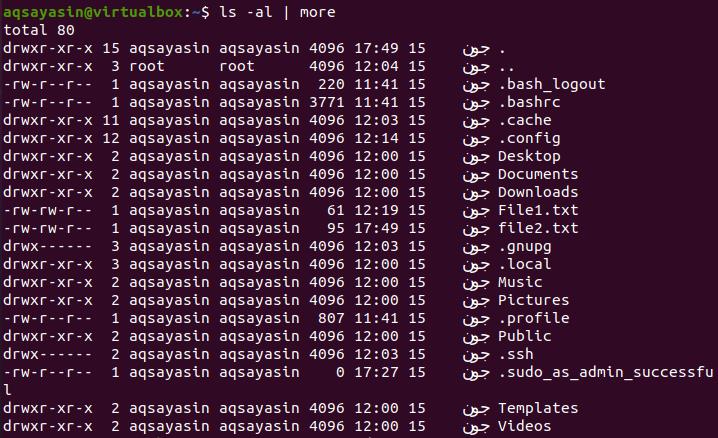
Ls is used to display all possible data of the respective command. It firstly displays the total number of data related to the corresponding query.
Count the number of files
It is a common need to know the number of files currently present. And it is not necessary to use the grep or cat command to fetch data of all the types. We can use pipe in this case either. The command used is written as:

Whereas wc is “word count” used to count the files present.
Process identification
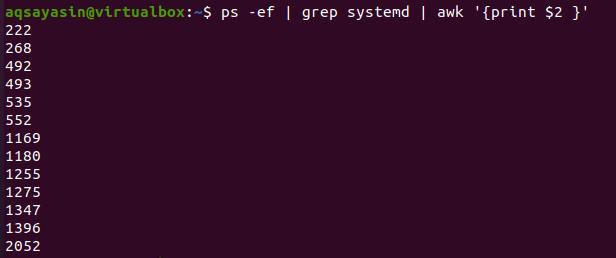
Many complicated tasks are also performed by using the pipe in our commands. The command we are discussing now is used to display the process ids of the systemd processes.
The awk command’s $2 displays the data of $2 that is the second column.
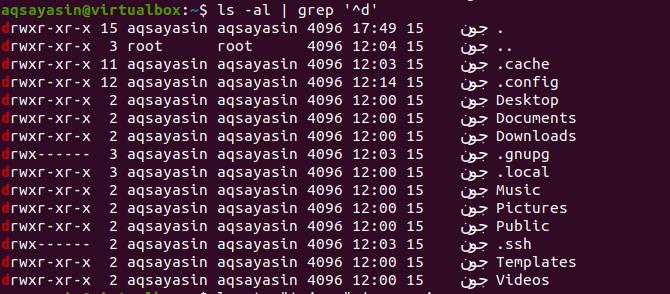
Get sub-directories using pipe
One of the pipeline commands we have used to get all the present subdirectories in the current directory is one of the pipe queries in the pipeline commands we have used. We have used the grep command here. Grep only functions to show the data starting from the ‘d’. The pipe will help in retrieving the respective data of all the directories. ‘^d’ is used here.
Get files using pipe
To get the files from the system of respective extensions, we can get this by using the pipe in our commands. The first example is finding the java files in the system. ‘locate’ and ‘grep’ help get the files of respective extensions.

‘*’ is used to fetch all the files in the system. Currently, we have a single file present in our system. The second example is to get the files with the extension of the text. The entire command is the same only the file extension is changed.

Use multiple pipes in a single command
In this example, unlike the earlier ones, we have used more than one pipe in a single command to elaborate its functionality. Consider a file named file3.txt.
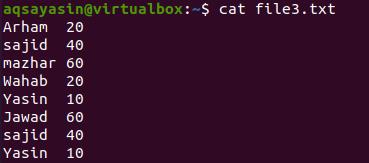
Now we want to get the record of the word that matched with the name we have provided in the command. Here cat command is used to fetch the data from a particular file. Grep is used to select that specific word from the file. ‘tee’ is used to save the result in another file. And wc is to count the resultant data. So the result is shown below.

The word is matched with the 2 contents. We can display the data from the new sample file to display the whole result, where the result is being stored.
Fetch particular data with pipes
In this example, we want to get the data from the file having ‘h’ in its content.

The result shows that the fetched data is according to the search by the ‘h’ command. Moving towards the following example. Here we want to fetch the items of the file having ‘s’ in it, but we have applied a condition of case sensitivity. Both upper and lower case alphabets will be fetched.
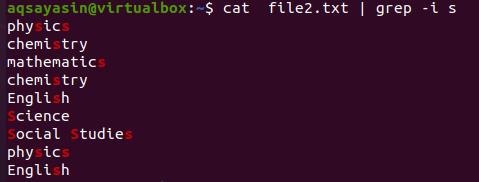
The result is shown in the image. Next, we will display the students’ names having alphabets ‘a’ and ‘t’ combined in the word. The result is in the below-cited image.
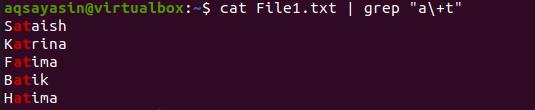
Conclusion
The article depicts the versatility of pipe in Linux commands. However, it is quite simple but works in a manner to resolve many complex queries. This command-line utility is easily implementable and compatible with UNIX and Linux operating systems.
About the author

Aqsa Yasin
I am a self-motivated information technology professional with a passion for writing. I am a technical writer and love to write for all Linux flavors and Windows.
Источник



