- Creating threads in linux
- RETURN VALUES
- ERRORS
- EXAMPLES
- ATTRIBUTES
- SEE ALSO
- NOTES
- Используем потоки в Linux C++
- Linux Kernel Process Management
- This chapter is from the book
- This chapter is from the book
- This chapter is from the book
- Process Descriptor and the Task Structure
- Allocating the Process Descriptor
- Storing the Process Descriptor
- Process State
- Manipulating the Current Process State
- Process Context
- The Process Family Tree
Creating threads in linux
The pthread_create() function is used to create a new thread, with attributes specified by attr , within a process. If attr is NULL, the default attributes are used. (See pthread_attr_init (3C)). If the attributes specified by attr are modified later, the thread’s attributes are not affected. Upon successful completion, pthread_create() stores the ID of the created thread in the location referenced by thread .
The thread is created executing start_routine with arg as its sole argument. If the start_routine returns, the effect is as if there was an implicit call to pthread_exit() using the return value of start_routine as the exit status. Note that the thread in which main() was originally invoked differs from this. When it returns from main() , the effect is as if there was an implicit call to exit() using the return value of main() as the exit status.
The signal state of the new thread is initialised as follows: o The signal mask is inherited from the creating thread. o The set of signals pending for the new thread is empty.
Default thread creation:
This would have the same effect as:
User-defined thread creation: To create a thread that is scheduled on a system-wide basis, use:
To customize the attributes for POSIX threads, see pthread_attr_init (3C).
A new thread created with pthread_create() uses the stack specified by the stackaddr attribute, and the stack continues for the number of bytes specified by the stacksize attribute. By default, the stack size is 1 megabyte for 32-bit processes and 2 megabyte for 64-bit processes (see pthread_attr_setstacksize (3C)). If the default is used for both the stackaddr and stacksize attributes, pthread_create() creates a stack for the new thread with at least 1 megabyte for 32-bit processes and 2 megabyte for 64-bit processes. (For customizing stack sizes, see NOTES ).
If pthread_create() fails, no new thread is created and the contents of the location referenced by thread are undefined.
RETURN VALUES
If successful, the pthread_create() function returns 0 . Otherwise, an error number is returned to indicate the error.
ERRORS
The pthread_create() function will fail if:
EAGAIN The system lacked the necessary resources to create another thread, or the system-imposed limit on the total number of threads in a process PTHREAD_THREADS_MAX would be exceeded.
EINVAL The value specified by attr is invalid.
EPERM The caller does not have appropriate permission to set the required scheduling parameters or scheduling policy.
EXAMPLES
Example 1 Example of concurrency with multithreading
The following is an example of concurrency with multithreading. Since POSIX threads and Solaris threads are fully compatible even within the same process, this example uses pthread_create() if you execute a.out 0 , or thr_create() if you execute a.out 1 .
Five threads are created that simultaneously perform a time-consuming function, sleep( 10 ) . If the execution of this process is timed, the results will show that all five individual calls to sleep for ten-seconds completed in about ten seconds, even on a uniprocessor. If a single-threaded process calls sleep( 10 ) five times, the execution time will be about 50-seconds.
The command-line to time this process is:
POSIX threading /usr/bin/time a.out 0
Solaris threading /usr/bin/time a.out 1
If main() had not waited for the completion of the other threads (using pthread_join (3C) or thr_join (3C)), it would have continued to process concurrently until it reached the end of its routine and the entire process would have exited prematurely. See exit (2).
ATTRIBUTES
See attributes (5) for descriptions of the following attributes:
|
SEE ALSO
NOTES
Multithreaded application threads execute independently of each other, so their relative behavior is unpredictable. Therefore, it is possible for the thread executing main() to finish before all other user application threads. The pthread_join (3C)function, on the other hand, must specify the terminating thread (IDs) for which it will wait.
A user-specified stack size must be greater than the value PTHREAD_STACK_MIN . A minimum stack size may not accommodate the stack frame for the user thread function start_func . If a stack size is specified, it must accommodate start_func requirements and the functions that it may call in turn, in addition to the minimum requirement.
It is usually very difficult to determine the runtime stack requirements for a thread. PTHREAD_STACK_MIN specifies how much stack storage is required to execute a NULL start_func . The total runtime requirements for stack storage are dependent on the storage required to do runtime linking, the amount of storage required by library runtimes (as printf() ) that your thread calls. Since these storage parameters are not known before the program runs, it is best to use default stacks. If you know your runtime requirements or decide to use stacks that are larger than the default, then it makes sense to specify your own stacks.
Источник
Используем потоки в Linux C++

Каждый разработчик рано или поздно сталкивается с необходимостью создания потока. Ведь нельзя решить практически ни одну сложную задачу выполняя только одну задачу за раз.
В Linux имеется собственная реализация потоков. Для создания потока существует функция pthread_create:
- pthread_t *thread — указатель на поток
- const pthread_attr_t *attr — атрибуты потока (если NULL — стандартные)
- void *(*start_routine)(void*) — имя функции выполняемой в потоке
- void *arg — параметр передаваемый функции.
Возвращает данная функция 0 если всё успешно и номер ошибки если нет.
После создания потока можно приступать к ожиданию его завершения — pthread_join:
Первый параметр — указатель на поток, второй — практически всегда NULL.
Кроме того поток можно завершить досрочно:
Теперь давайте создадим небольшую программу для наглядности.
Создадим приложение с двумя потоками.
Библиотеки:
Определим функцию для потока:
В функции main зададим основные переменные:
Зададим идентификатор потока. Не путайте с системным идентификатором! Это всего лишь переменная для нашей программы!
Создадим потока и проверим ошибки:
Тоже повторим для второго потока:
Отделим момент для наглядности примера:
Ждём завершения первого и второго потока:
Выводим сообщение о конце и выходим из программы:
Вывод программы такой:
Обратите ваше внимание на то, что чтобы откомпилировать программу придётся задать флаг -D_REENTERANT и библиотеки:
Хотя я создавал проект в Qt Creator и qmake разобрался сам 😉
Источник
Linux Kernel Process Management
This chapter is from the book
This chapter is from the book
This chapter is from the book
The process is one of the fundamental abstractions in Unix operating systems 1 . A process is a program (object code stored on some media) in execution. Processes are, however, more than just the executing program code (often called the text section in Unix). They also include a set of resources such as open files and pending signals, internal kernel data, processor state, an address space, one or more threads of execution, and a data section containing global variables. Processes, in effect, are the living result of running program code.
Threads of execution, often shortened to threads, are the objects of activity within the process. Each thread includes a unique program counter, process stack, and set of processor registers. The kernel schedules individual threads, not processes. In traditional Unix systems, each process consists of one thread. In modern systems, however, multithreaded programs—those that consist of more than one thread—are common. As you will see later, Linux has a unique implementation of threads: It does not differentiate between threads and processes. To Linux, a thread is just a special kind of process.
On modern operating systems, processes provide two virtualizations: a virtualized processor and virtual memory. The virtual processor gives the process the illusion that it alone monopolizes the system, despite possibly sharing the processor among dozens of other processes. Chapter 4, «Process Scheduling,» discusses this virtualization. Virtual memory lets the process allocate and manage memory as if it alone owned all the memory in the system. Virtual memory is covered in Chapter 11, «Memory Management.» Interestingly, note that threads share the virtual memory abstraction while each receives its own virtualized processor.
A program itself is not a process; a process is an active program and related resources. Indeed, two or more processes can exist that are executing the same program. In fact, two or more processes can exist that share various resources, such as open files or an address space.
A process begins its life when, not surprisingly, it is created. In Linux, this occurs by means of the fork() system call, which creates a new process by duplicating an existing one. The process that calls fork() is the parent, whereas the new process is the child. The parent resumes execution and the child starts execution at the same place, where the call returns. The fork() system call returns from the kernel twice: once in the parent process and again in the newborn child.
Often, immediately after a fork it is desirable to execute a new, different, program. The exec*() family of function calls is used to create a new address space and load a new program into it. In modern Linux kernels, fork() is actually implemented via the clone() system call, which is discussed in a following section.
Finally, a program exits via the exit() system call. This function terminates the process and frees all its resources. A parent process can inquire about the status of a terminated child via the wait4() 2 system call, which enables a process to wait for the termination of a specific process. When a process exits, it is placed into a special zombie state that is used to represent terminated processes until the parent calls wait() or waitpid().
Another name for a process is a task. The Linux kernel internally refers to processes as tasks. In this book, I will use the terms interchangeably, although when I say task I am generally referring to a process from the kernel’s point of view.
Process Descriptor and the Task Structure
The kernel stores the list of processes in a circular doubly linked list called the task list 3 . Each element in the task list is a process descriptor of the type struct task_struct, which is defined in . The process descriptor contains all the information about a specific process.
The task_struct is a relatively large data structure, at around 1.7 kilobytes on a 32-bit machine. This size, however, is quite small considering that the structure contains all the information that the kernel has and needs about a process. The process descriptor contains the data that describes the executing program—open files, the process's address space, pending signals, the process's state, and much more (see Figure 3.1).
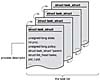
Figure 3.1 The process descriptor and task list.
Allocating the Process Descriptor
The task_struct structure is allocated via the slab allocator to provide object reuse and cache coloring (see Chapter 11, "Memory Management"). Prior to the 2.6 kernel series, struct task_struct was stored at the end of the kernel stack of each process. This allowed architectures with few registers, such as x86, to calculate the location of the process descriptor via the stack pointer without using an extra register to store the location. With the process descriptor now dynamically created via the slab allocator, a new structure, struct thread_info, was created that again lives at the bottom of the stack (for stacks that grow down) and at the top of the stack (for stacks that grow up) 4 . See Figure 3.2.
The new structure also makes it rather easy to calculate offsets of its values for use in assembly code.
The thread_info structure is defined on x86 in as
Each task's thread_info structure is allocated at the end of its stack. The task element of the structure is a pointer to the task's actual task_struct.

Figure 3.2 The process descriptor and kernel stack.
Storing the Process Descriptor
The system identifies processes by a unique process identification value or PID. The PID is a numerical value that is represented by the opaque type 5 pid_t, which is typically an int. Because of backward compatibility with earlier Unix and Linux versions, however, the default maximum value is only 32,768 (that of a short int), although the value can optionally be increased to the full range afforded the type. The kernel stores this value as pid inside each process descriptor.
This maximum value is important because it is essentially the maximum number of processes that may exist concurrently on the system. Although 32,768 might be sufficient for a desktop system, large servers may require many more processes. The lower the value, the sooner the values will wrap around, destroying the useful notion that higher values indicate later run processes than lower values. If the system is willing to break compatibility with old applications, the administrator may increase the maximum value via /proc/sys/kernel/pid_max.
Inside the kernel, tasks are typically referenced directly by a pointer to their task_struct structure. In fact, most kernel code that deals with processes works directly with struct task_struct. Consequently, it is very useful to be able to quickly look up the process descriptor of the currently executing task, which is done via the current macro. This macro must be separately implemented by each architecture. Some architectures save a pointer to the task_struct structure of the currently running process in a register, allowing for efficient access. Other architectures, such as x86 (which has few registers to waste), make use of the fact that struct thread_info is stored on the kernel stack to calculate the location of thread_info and subsequently the task_struct.
On x86, current is calculated by masking out the 13 least significant bits of the stack pointer to obtain the thread_info structure. This is done by the current_thread_info() function. The assembly is shown here:
This assumes that the stack size is 8KB. When 4KB stacks are enabled, 4096 is used in lieu of 8192.
Finally, current dereferences the task member of thread_info to return the task_struct:
Contrast this approach with that taken by PowerPC (IBM's modern RISC-based microprocessor), which stores the current task_struct in a register. Thus, current on PPC merely returns the value stored in the register r2. PPC can take this approach because, unlike x86, it has plenty of registers. Because accessing the process descriptor is a common and important job, the PPC kernel developers deem using a register worthy for the task.
Process State
The state field of the process descriptor describes the current condition of the process (see Figure 3.3). Each process on the system is in exactly one of five different states. This value is represented by one of five flags:
TASK_RUNNING—The process is runnable; it is either currently running or on a runqueue waiting to run (runqueues are discussed in Chapter 4, "Scheduling"). This is the only possible state for a process executing in user-space; it can also apply to a process in kernel-space that is actively running.
TASK_INTERRUPTIBLE—The process is sleeping (that is, it is blocked), waiting for some condition to exist. When this condition exists, the kernel sets the process's state to TASK_RUNNING. The process also awakes prematurely and becomes runnable if it receives a signal.
TASK_UNINTERRUPTIBLE—This state is identical to TASK_INTERRUPTIBLE except that it does not wake up and become runnable if it receives a signal. This is used in situations where the process must wait without interruption or when the event is expected to occur quite quickly. Because the task does not respond to signals in this state, TASK_UNINTERRUPTIBLE is less often used than TASK_INTERRUPTIBLE 6 .
TASK_ZOMBIE—The task has terminated, but its parent has not yet issued a wait4() system call. The task's process descriptor must remain in case the parent wants to access it. If the parent calls wait4(), the process descriptor is deallocated.
TASK_STOPPED—Process execution has stopped; the task is not running nor is it eligible to run. This occurs if the task receives the SIGSTOP, SIGTSTP, SIGTTIN, or SIGTTOU signal or if it receives any signal while it is being debugged.
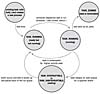
Figure 3.3 Flow chart of process states.
Manipulating the Current Process State
Kernel code often needs to change a process's state. The preferred mechanism is using
This function sets the given task to the given state. If applicable, it also provides a memory barrier to force ordering on other processors (this is only needed on SMP systems). Otherwise, it is equivalent to
The method set_current_state(state) is synonymous to set_task_state(current, state).
Process Context
One of the most important parts of a process is the executing program code. This code is read in from an executable file and executed within the program's address space. Normal program execution occurs in user-space. When a program executes a system call (see Chapter 5, "System Calls") or triggers an exception, it enters kernel-space. At this point, the kernel is said to be "executing on behalf of the process" and is in process context. When in process context, the current macro is valid 7 . Upon exiting the kernel, the process resumes execution in user-space, unless a higher-priority process has become runnable in the interim, in which case the scheduler is invoked to select the higher priority process.
System calls and exception handlers are well-defined interfaces into the kernel. A process can begin executing in kernel-space only through one of these interfaces—all access to the kernel is through these interfaces.
The Process Family Tree
A distinct hierarchy exists between processes in Unix systems, and Linux is no exception. All processes are descendents of the init process, whose PID is one. The kernel starts init in the last step of the boot process. The init process, in turn, reads the system initscripts and executes more programs, eventually completing the boot process.
Every process on the system has exactly one parent. Likewise, every process has zero or more children. Processes that are all direct children of the same parent are called siblings. The relationship between processes is stored in the process descriptor. Each task_struct has a pointer to the parent's task_struct, named parent, and a list of children, named children. Consequently, given the current process, it is possible to obtain the process descriptor of its parent with the following code:
Similarly, it is possible to iterate over a process's children with
The init task's process descriptor is statically allocated as init_task. A good example of the relationship between all processes is the fact that this code will always succeed:
In fact, you can follow the process hierarchy from any one process in the system to any other. Oftentimes, however, it is desirable simply to iterate over all processes in the system. This is easy because the task list is a circular doubly linked list. To obtain the next task in the list, given any valid task, use:
Obtaining the previous works the same way:
These two routines are provided by the macros next_task(task) and prev_task(task), respectively. Finally, the macro for_each_process(task) is provided, which iterates over the entire task list. On each iteration, task points to the next task in the list:
Note: It can be expensive to iterate over every task in a system with many processes; code should have good reason (and no alternative) before doing so.
Источник



