Настройка резервного копирования Linux-сервера за 5 минут
Передо мной возникла необходимость настроить резервное копирование на новом Linux-сервере, задачка эта оочень важная, но уж больно скучная: нужно написать и отладить скрипты, которые будут архивировать нужные папки (причем желательно делать инкрементальные архивы), базы данных, хранилища subversion, а затем переносить эти архивы на удаленный сервер. По этому я попробовал нагуглить готовое решение для этой задачки и в результате наткнулся на backup-manager — замечательный опенсорсный набор bash-скриптов, позволяющих:
- архивировать любые папки, в том числе и создавать инкрементальные архивы. В конфиге просто указывается список директорий, которые должны быть скопированы, а также «черный список» файлов, которые копироваться не будут.
- делать резервное копирование баз данных MySQL. В конфиге указываются логин и пароль mysql-юзера, имеющего доступ к базам, а всю остальную работу backup-manager делает сам.
- делать резервное копирование svn-репозиториев, причем бэкап делается не копированием папки с хранилищем, а с помощью команды svnadmin dump.
- шифровать архивы.
- копировать созданные архивы на удаленные сервера по FTP, SSH или (это самая важная для меня фича) в хранилище Amazon S3, а также записывать их на DVD.
Таким образом, один этот этот набор скриптов решил абсолютно все мои задачи, связанные с резервным копированием. Настраивается все это хозяйство не более чем за пять минут, так как в конфигурационном файле каждый параметр имеет подробные комментарии, так что проблем с настройкой возникнуть ни у кого не должно.
Скачать можно отсюда: www.backup-manager.org/downloads, либо просто можно установить пакет backup-manager (пример для Debian):
aptitude install backup-manager
Кроме того, нужно учесть, что для копирования данных в хранилище Amazon S3 в системе должны быть установлены пакеты libnet-amazon-s3-perl и libfile-slurp-perl:
aptitude install libnet-amazon-s3-perl libfile-slurp-perl
Теперь остается только настроить запуск backup-manager по крону и можно спать спокойно.
Upd.
Все настройки хранятся в файле /etc/backup-manager.conf, вот основные его параметры:
# Папка, в которой архивы будут складываться локально
export BM_REPOSITORY_ROOT=»/var/archives»
# Используемые методы резервного копирования
export BM_ARCHIVE_METHOD=»tarball-incremental mysql svn»
# Далее для каждого из выбранных выше методов резервного копирования задаем настройки
# Список папок, содержимое которых будем бэкапить
BM_TARBALL_TARGETS[0]=»/etc»
BM_TARBALL_TARGETS[1]=»/boot»
BM_TARBALL_TARGETS[2]=»/var/www»
export BM_TARBALL_TARGETS
# Список исключений, то есть файлов в перечисленных выше папках, которые бэкапить не нужно
export BM_TARBALL_BLACKLIST=»/dev /sys /proc /tmp *imagecache*»
# Теперь указываем как часто делать мастер-бэкап и инкрементный бэкап
export BM_TARBALLINC_MASTERDATETYPE=»weekly»
export BM_TARBALLINC_MASTERDATEVALUE=»1″
# Для бэкапа MySQL баз данных указываем какие базы бэкапить и параметры mysql-юзера
export BM_MYSQL_DATABASES=»__ALL__»
export BM_MYSQL_ADMINLOGIN=»user»
export BM_MYSQL_ADMINPASS=»1234″
# Для бэкапа subversion-репозитория указываем путь к хранилищу
export BM_SVN_REPOSITORIES=»/var/repositories»
# Выбираем метод аплоада созданного бэкапа а удаленный сервер
# (еще есть варианты ftp, ssh, ssh-gpg, rsync)
export BM_UPLOAD_METHOD=»s3″
# Для копирования копий на Amazon S3 задаем имя корзины, access key и secret key
export BM_UPLOAD_S3_DESTINATION=»basket-name»
export BM_UPLOAD_S3_ACCESS_KEY=»ABC123″
export BM_UPLOAD_S3_SECRET_KEY=»DEF456″
Это самые основные настройки, в самом конфиге есть еще пара десятков параметров, все они подробно прокомментированы.
Источник
Бэкап Linux и восстановление его на другом железе
Я работаю в организации с маленьким штатом, деятельность тесно связана с IT и у нас возникают задачи по системному администрированию. Мне это интересно и частенько я беру на себя решение некоторых.
На прошлой неделе мы настраивали FreePBX под debian 7.8, нанимали фрилансера. В процессе настройки оказалось, что сервер (да, я так называю обычный PC) не хочет грузится с HDD при подключенных USB 3G модемах, которые мы используем для звонков на мобильные, колупание BIOSа не помогло. Непорядок. Решил, что нужно перенести его на другую железяку. Так появилось сразу две связанные задачи:
- сделать бэкап сервера;
- восстановить бэкап на другом железе.
Гугление не дало внятных ответов, как это сделать, пришлось собирать информацию кусками и пробовать. Всякие acronis’ы отбросил сразу, ибо не интересно.
Опыт общения с linux-системами у меня небольшой: настройка VPN сервера на open-vpn, ftp-сервера и еще пара мелочей. Сам себя я характеризую как человека умеющего читать маны и править конфиги 🙂
Ниже я описываю свой частный случай и почему я поступил именно так. Надеюсь, новичкам будет полезно, а бородатые админы улыбнутся вспомнив молодость.
Начинаем копать теорию:
Второй способ требует наличия внешнего жесткого диска объемом не меньше раздела, который архивируем. Да и что с ним потом делать, непонятно, хранить на полочке? Остановился на tar, чуть сложнее в реализации, нужно будет создать MBR, но время создания/восстановления архива существенно меньше, хранить бэкап проще, полтора гига можно закинуть в облако и скачать, когда будет нужно. Записывать его можно на ту же live-флэшку, с которой буду грузиться.
Итак, план действия:
1. Создание бэкапа
Грузимся с live-флэшки, у меня это debian-live-7.8.0-amd64-standard.
Переключаемся на root:
Монтируем раздел, который будем архивировать, у меня это sda1, чтобы случайно не наломать дров, монтируем только для чтения. Посмотреть все свои разделы можно при помощи команд ls /dev | grep sd или df -l
Наша флэшка уже примонтирована, но в режиме только чтения, нужно перемонтировать для чтения-записи, чтобы писать туда бэкап.
Все готово для создания архива
Здесь у нас параметры: c — создать архив, v — выводить информацию о процессе, z — использовать сжатие gzip, p — сохраняем данные о владельцах и правах доступа, f — пишем архив в файл, путь к файлу, —exclude — исключаем из архива каталог (я исключил каталоги с записями разговоров и каталог с бэкапами FreePBX), /mnt/ — каталог, который архивируем.
Ждем… у меня вся подготовка и создание архива заняли 10 минут. Будь флэшка быстрее, уложился бы в 7-8 минут.
Складываем архив в надежное место за пределами офиса.
Восстановление бэкапа на другом железе
2. Размечаем диск, создаем файловую систему
Грузимся с live-флэшки, у меня все та же debian-live-7.8.0.
Переключаемся на root:
Размечаем диск. Мне понравилась утилита с псевдографическим интерфейсом cfdisk. Там все просто и понятно.
Удаляем все имеющиеся разделы. Я создал два новых раздела, один на 490 Gb под / (sda1) и 10 Gb под swap (sda2) в конце диска, т.к. он практически не будет задействован. Проверим типы разделов. Который под систему должен иметь тип 83 Linux, второй — 82 Linux swap / Solaris. Помечаем системный раздел загрузочным (bootable), сохраняем изменения и выходим.
Cоздаем файловую систему на первом разделе.
3. Распаковываем архив.
Монтируем отформатированный раздел
Распаковываем архив прямо с флэшки
Параметр —same-owner — сохраняет владельцев у распаковываемых файлов, x — извлекаем из архива, v — выводить информацию о процессе, p — сохраняем права доступа, f — указываем файл, который распаковываем, C — распаковываем в категорию.
4. Создаем MBR на новом диске.
Чтобы корректно создать загрузочную запись, монтируем рабочие каталоги к нашему будущему root-каталогу, у меня это /mnt. Каталоги /dev и /proc сейчас используются live-системой, используем параметр bind, чтобы они были доступны сразу в двух местах:
Переключаемся на новую систему используя chroot:
Делаем swap-раздел для новой системы:
Подключаем его же:
Чтобы grub работал, нужно указать ему правильные UUID разделов в fstab, сейчас там прописаны разделы предыдущей системы:
Открываем второй терминал (Alt+F2) под root:
И видим текущие UUID разделов.
Вручную переписываем их в fstab переключаясь между Alt+F1 и Alt+F2. Да, муторно, но попытки копировать занимали у меня больше времени, чем переписывание. Сохраняем fstab.
Устанавливаем grub2. У меня один физический диск, поэтому ставим его на sda:
На чистый диск должно встать без ошибок. Обновляем информацию из fstab:
Возвращаемся в Live-систему:
Размонтируем все каталоги:
Если вылазят процессы, которые используют эти каталоги, убиваем их используя fuser.
Все, поехали. Грузимся с жесткого диска:
Здесь статья должна была закончиться, но у меня возникли проблемы с подключением к интернету. Сервер видит сеть, видит компьютеры в ней, но в интернет не ходит… а это как бы важно для телефонии.
5. Тестирование и устранение неполадок.
Показывет интерфейсы eth1 и lo, гугление сказало, что gateway можно прописать только подключению eth0, остальные рассчитаны только на работу внутри сети.
Похоже, отсутствие eth0 вызвано способом переноса системы. Находим файл, который отвечает за нумерацию интерфейсов, смотрим туда:
Действительно, там два активных интерфейса, определенных MAC’ами. Комментируем первый, второму прописываем eth0.
Перезапуск /etс/init.d/networking не помог, поэтому перезагружаемся:
Подключаем донглы, проверяем, все работает.
Спасибо за внимание.
Источник
System Center 2012 R2 Data Protection Manager — Особенности резервного копирования баз данных SQL
 Всех приветствую! И вновь речь пойдет о продукте компании Microsoft – System Center 2012 R2 Data Protection Manager (DPM) . В каждом программном продукте есть свои нюансы и DPM в этом плане не исключение. В данной статье рассмотрю особенности, которые необходимо учесть при планировании резервного копирования баз данных Microsoft SQL.
Всех приветствую! И вновь речь пойдет о продукте компании Microsoft – System Center 2012 R2 Data Protection Manager (DPM) . В каждом программном продукте есть свои нюансы и DPM в этом плане не исключение. В данной статье рассмотрю особенности, которые необходимо учесть при планировании резервного копирования баз данных Microsoft SQL.
Будьте в курсе актуальных новостей в мире ИТ: https://t.me/ITKBnews. Также будем рады видеть Вас участниками групп https://vk.com/blogitkb и https://www.fb.com/blog.it.kb
Начнем с того, что для начала нужно
1. Установить агента на сервер SQL (примере будет использоваться server2). Проверить его доступность. 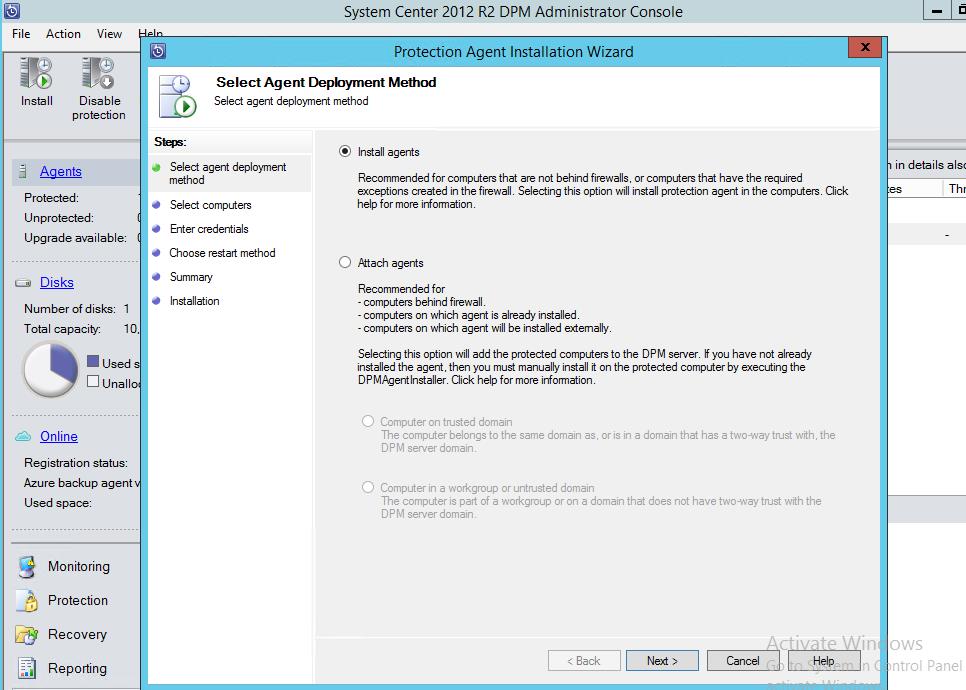
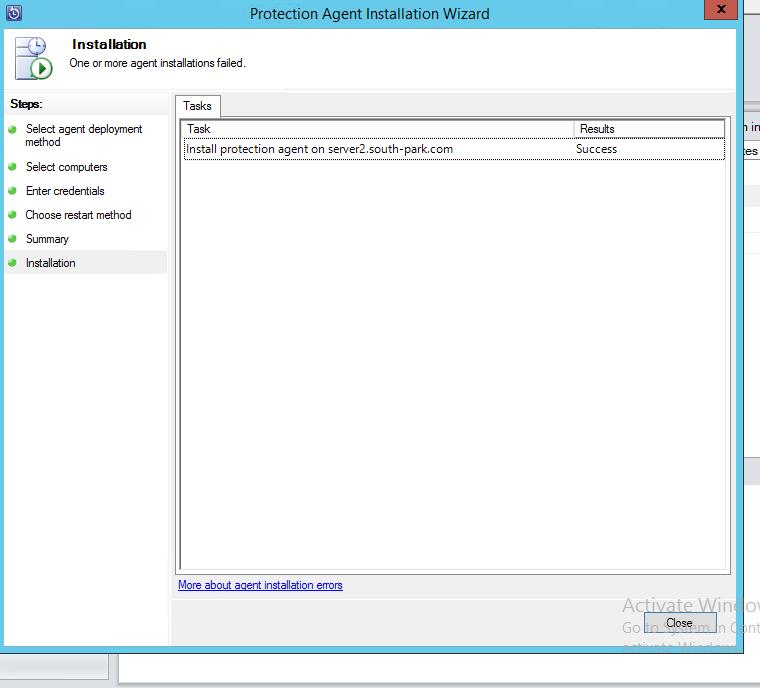 2. После установки придется перезагрузить защищаемый сервер (в нашем случае server2 — SQL)
2. После установки придется перезагрузить защищаемый сервер (в нашем случае server2 — SQL) 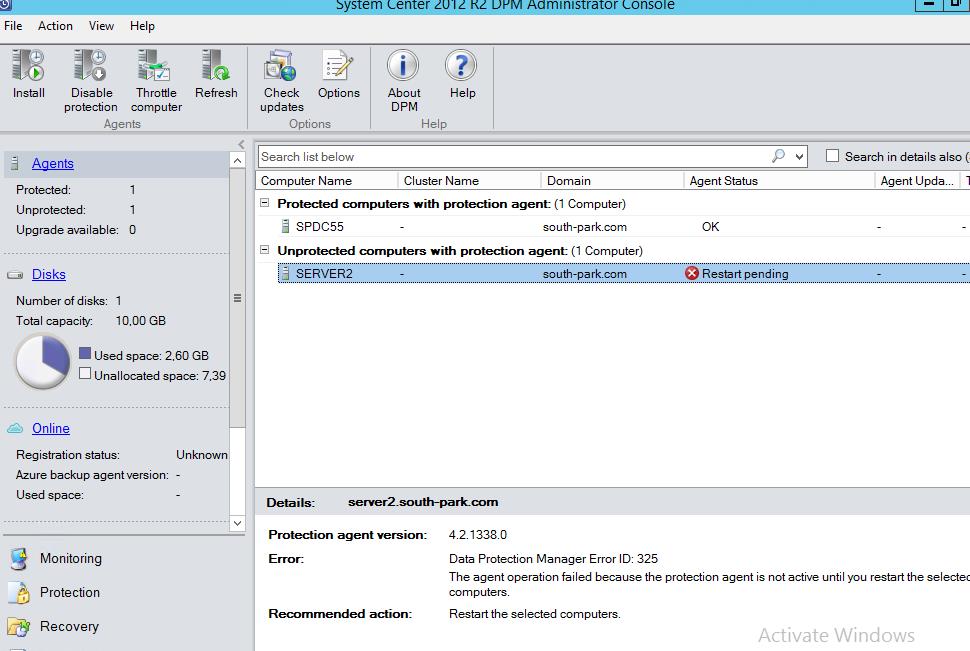 После перезагрузки состояние подключение к агенту должно быть — OK
После перезагрузки состояние подключение к агенту должно быть — OK 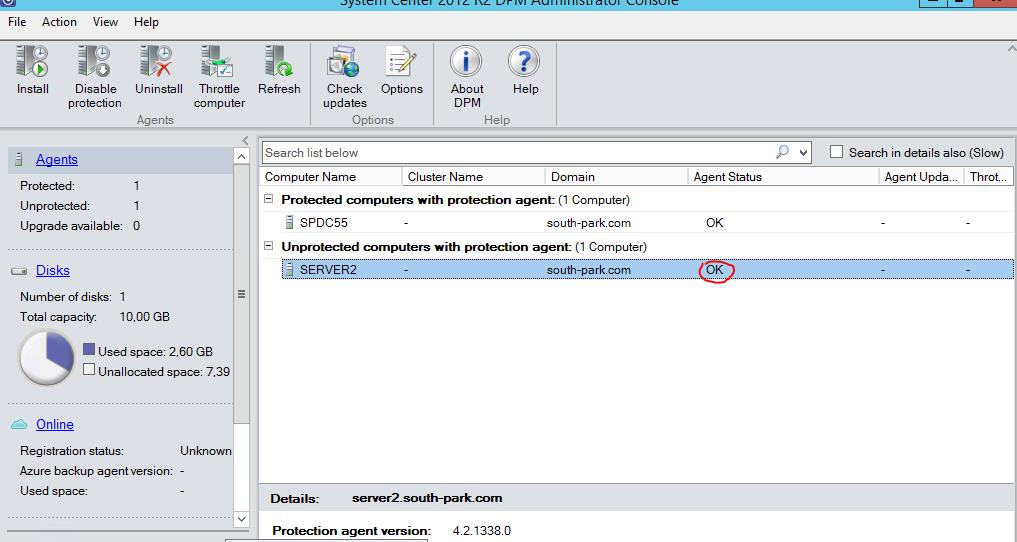 3. Создать группу защиты (Protection Group)
3. Создать группу защиты (Protection Group) 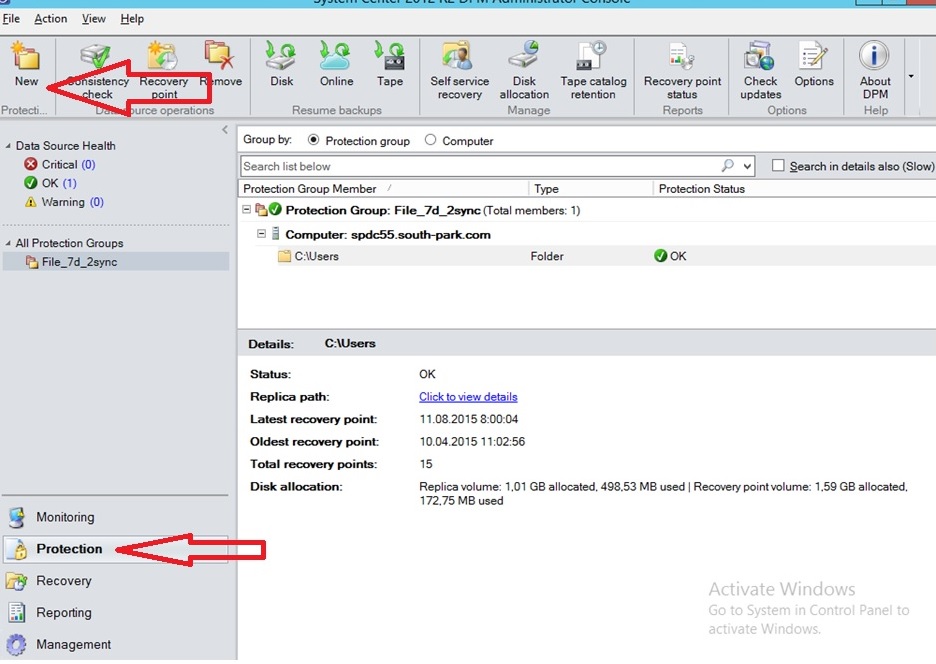
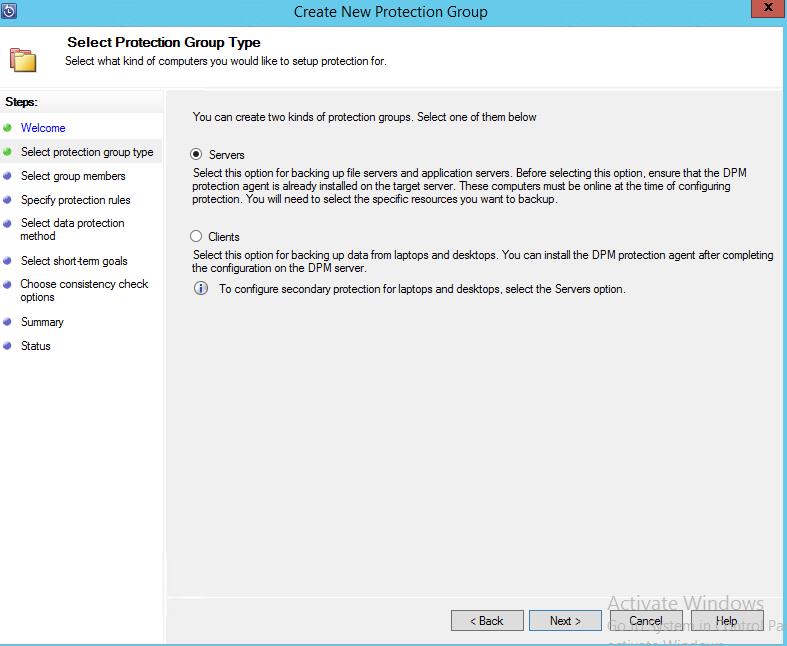 4. Выбрать базы для защиты
4. Выбрать базы для защиты 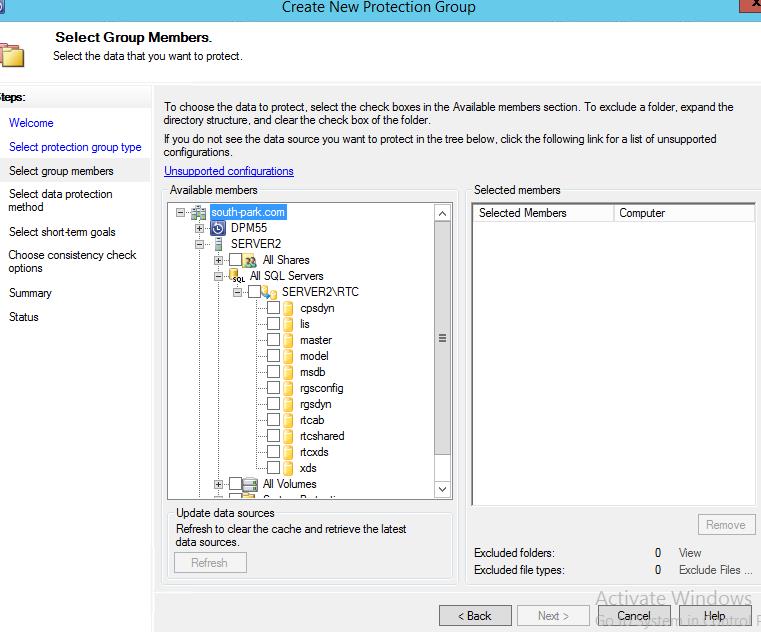 Есть два варианта: Автоматический – выбираются все базы
Есть два варианта: Автоматический – выбираются все базы 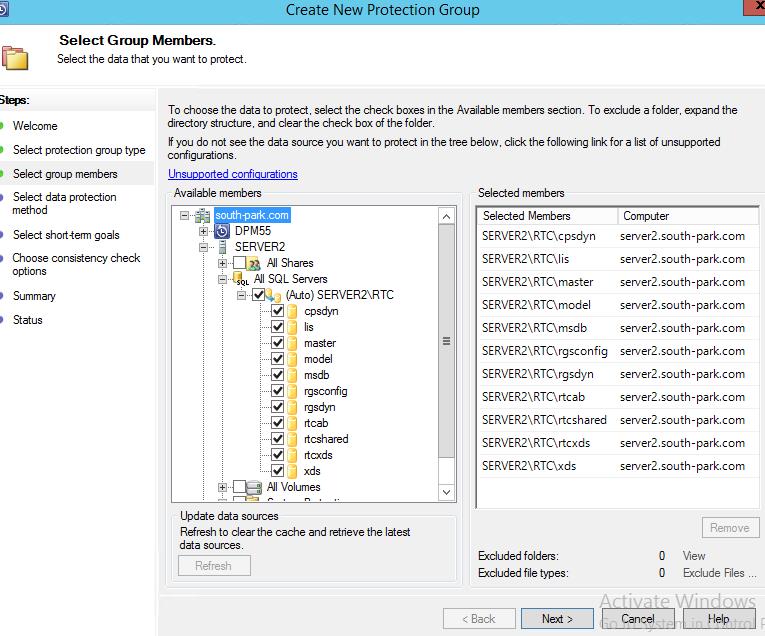 И второй вариант — выбор в ручном режиме
И второй вариант — выбор в ручном режиме 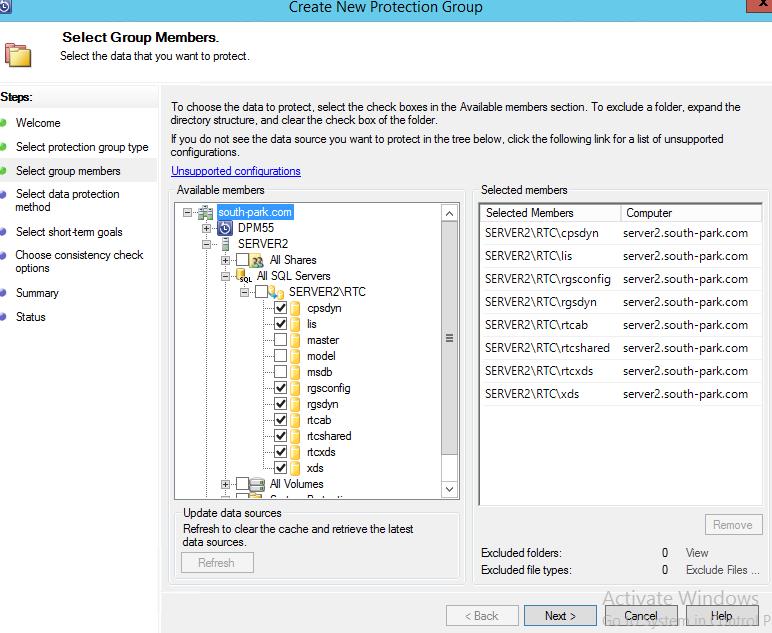
Если не появляется, то
Вариант 1 (в примере для SQL Server 2008 R2):
Зайти на SQL сервер
В командной строке выполнить
В результате должно быть вот такое сообщение:
Выполнить в командной строке на SQL сервере
Убедиться, что SqlServerWriter присутствует без ошибок
Если нет, то проверить корректность именования баз данных, т.е. в имени баз не должны быть пробелы. Если таковые базы есть, то исправить их имя – убрать пробелы.
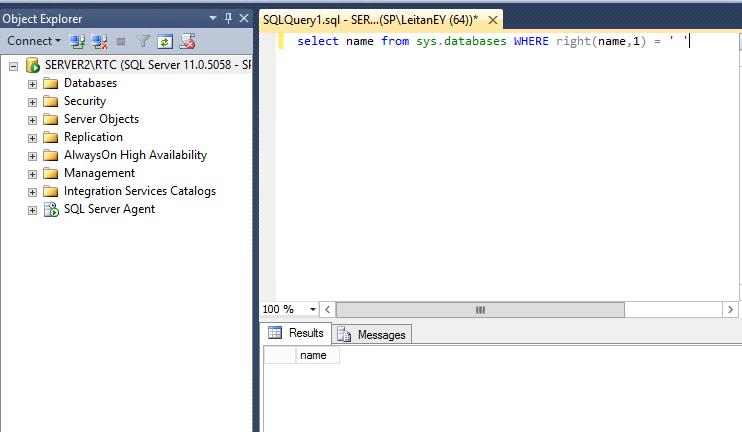
В SQL Management Studio выполнить запрос вида:
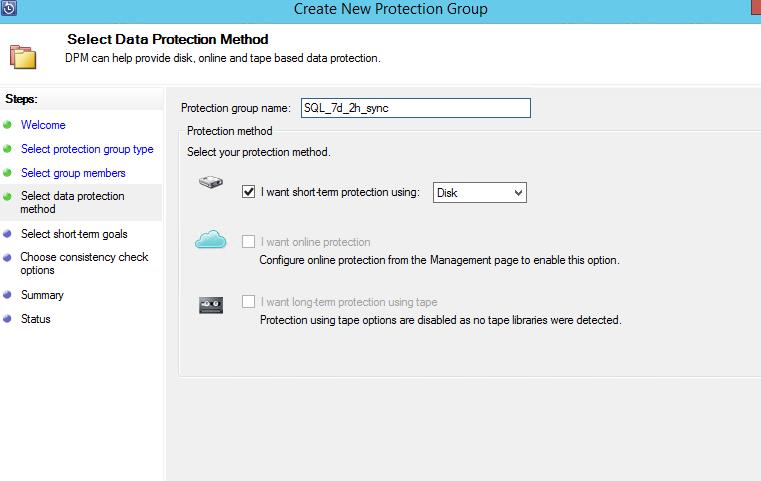
5. После выбора баз назвываем группу. В примере,
SQL – тип защищаемого ресурса
7d – срок хранения данных 7 дней
2h – период синхронизации каждые 2 часа
Sync – выполнение инкрементального резервного копирования
 6. Определить модель базы данных (Full, Simple)
6. Определить модель базы данных (Full, Simple)
. Важный момент.
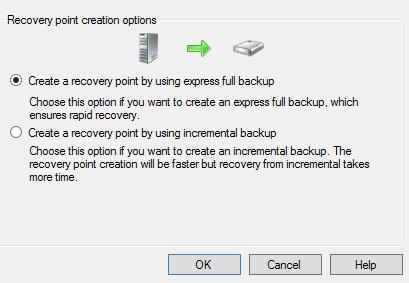
Если база SQL находится в Full режиме, то можно выполнять полное резервное копирование (Express Full Backup) и инкрементальное (Syncronization). При инкрементальном (Syncronization) резервном копировании лог файлы базы (*.ldf) будут усекаться (truncate), НО НЕ сжиматься (shrinking).
Если база SQL находится в Simple режиме, то доступно только полное резервное копирование (Express Full backup) , п.ч. в таком режиме у базы нет лог файла (*.ldf).
Вариант определения режима базы:
1) Выполнить SQL запрос
2) Выполнить PowerShell скрипт
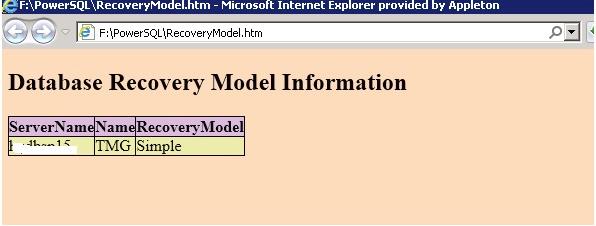
Get-RecoveryModel -InputFile F:\PowerSQL\Server.txt -RecoveryModel «SIMPLE» -DatabaseFlag $FALSE 2.PS:\>Get-RecoveryModel -InputFile F:\PowerSQL\Server.txt -RecoveryModel «FULL» -DatabaseFlag $TRUE .NOTES Author : Powershellsql@gmail.com .LINK http://sqlpowershell.wordpress.com/ #>
Пример вывода результата в HTML
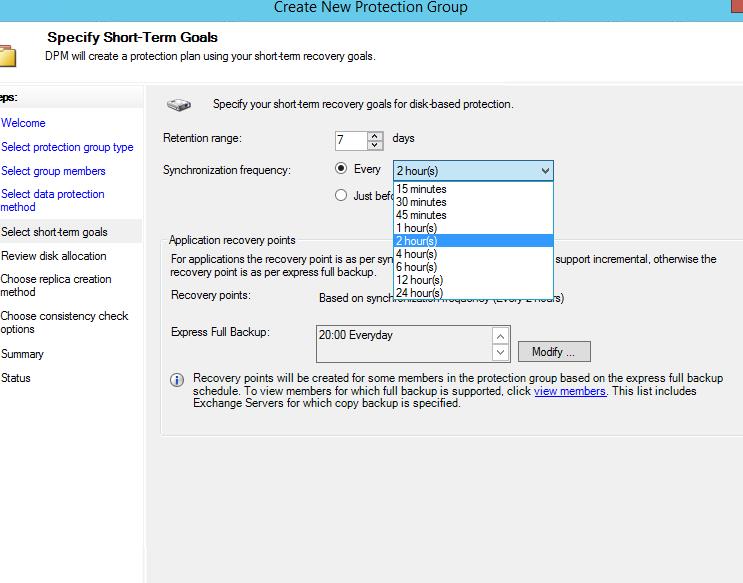
7. Определить периодичность инкрементальной копии (synchronization) и полной копии (Express Full Backup).
 8. Определить как данные будут располагаться в пуле дисков. Для большого количества ресурсов рекомендуется совместить (co-locate data), т.е. в одном динамическом диске будет размещаться несколько защищаемых ресурсов. Также можно выключить автоматическое расширение разделов (volume) в случае не хватки места.
8. Определить как данные будут располагаться в пуле дисков. Для большого количества ресурсов рекомендуется совместить (co-locate data), т.е. в одном динамическом диске будет размещаться несколько защищаемых ресурсов. Также можно выключить автоматическое расширение разделов (volume) в случае не хватки места.
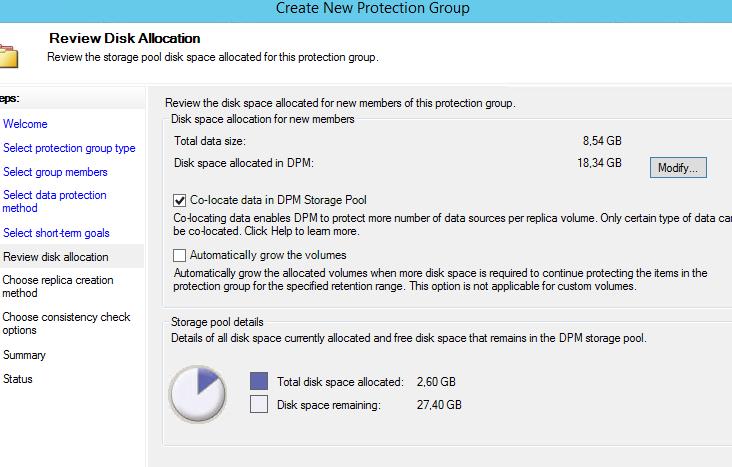
Примечание: После окончательной настройки группы защиты создадутся динамические диски, которые можно будет увидеть в диспетчере управления дисками (Disk Management)
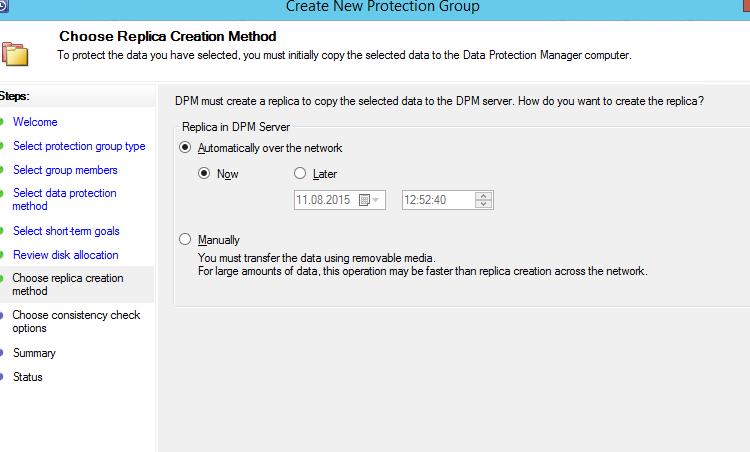
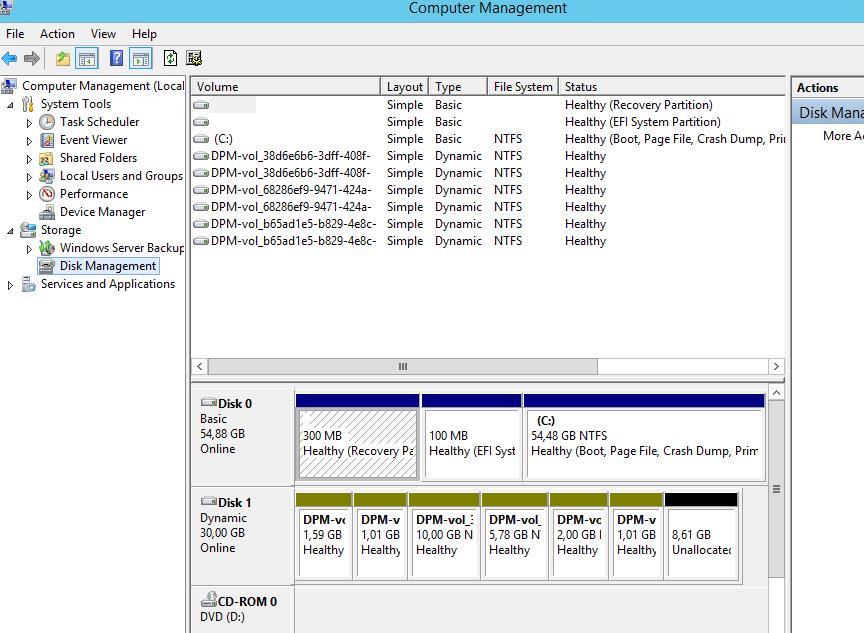 9. Первоначальную реплику можно создать
9. Первоначальную реплику можно создать
— в автоматическом режиме
— по расписанию (в наименее нагруженное время для сети и дисковой подсистемы DPM и SQL)
— в ручном режиме (после создания группы нужно будет нажать синхронизация из раздела защиты “Protection”)
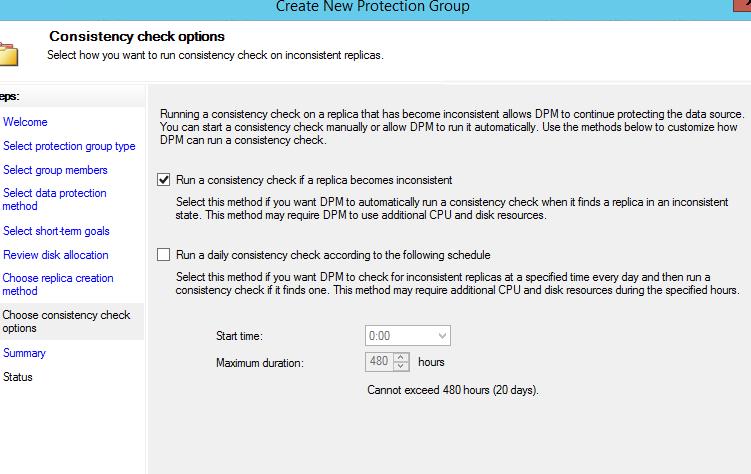
 10. Выбрать параметр проверки консистентности данных “consistency check ” (т.е. целостности) в случае возникновения ошибок.
10. Выбрать параметр проверки консистентности данных “consistency check ” (т.е. целостности) в случае возникновения ошибок.
При этом стоит помнить, что consistency check запускается через 15 минут после того как реплика стала не консистентной (т.е. данные между DPM хранилищем и защащаемыми данными разные на блочном уровне “ block-by-block verification ”).
Этот параметр можно изменить, также как и количество попыток
Рекомендуется устанавливать consistency check на время, когда меньше всего нагружены сеть, диски DPM и диски защищаемого сервера.
11. Для завершения создания группы защиты необходимо нажать “Create group”
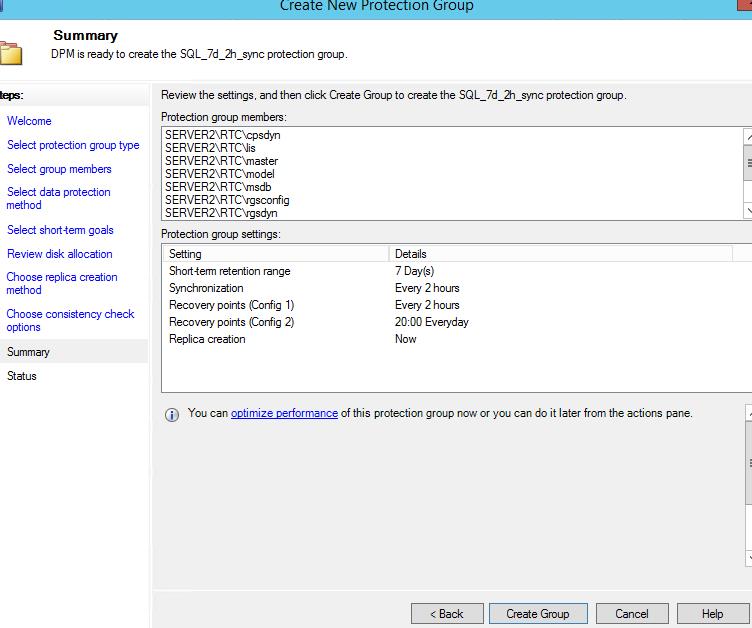
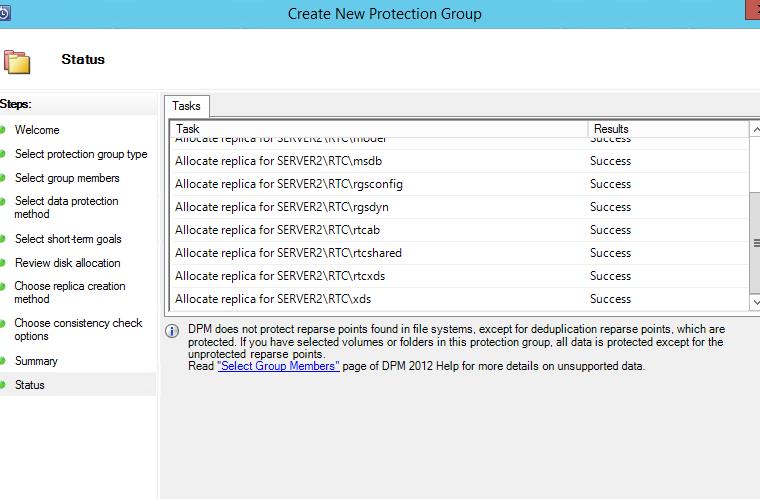
12. После успешного создания группы первая синхронизация может не пройти
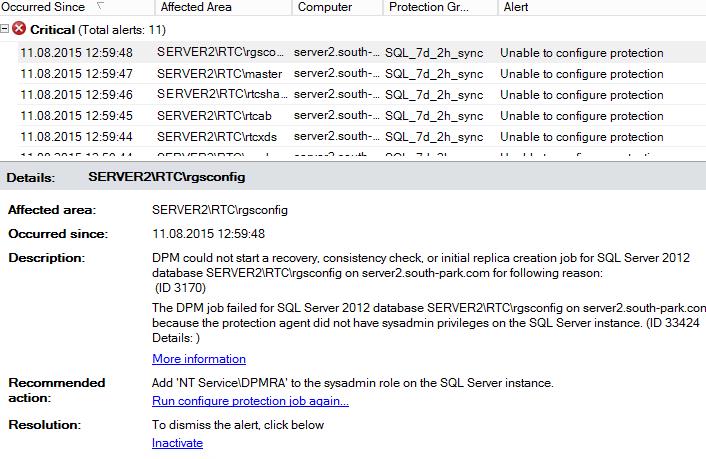
Решается это добавлением прав для DPM на SQL сервере.
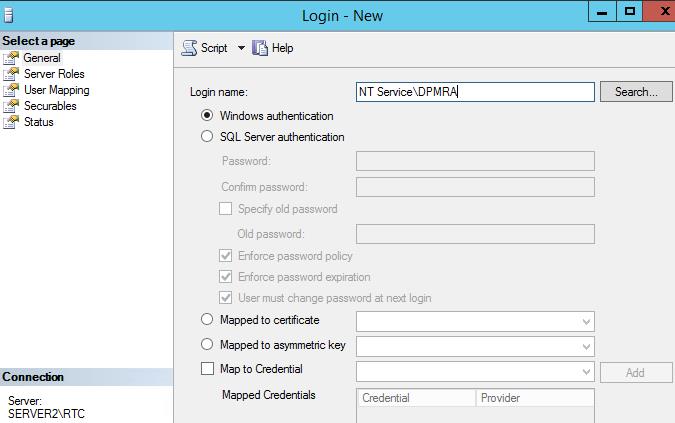
Идем на SQL сервер и делаем согласно рекомендациям.
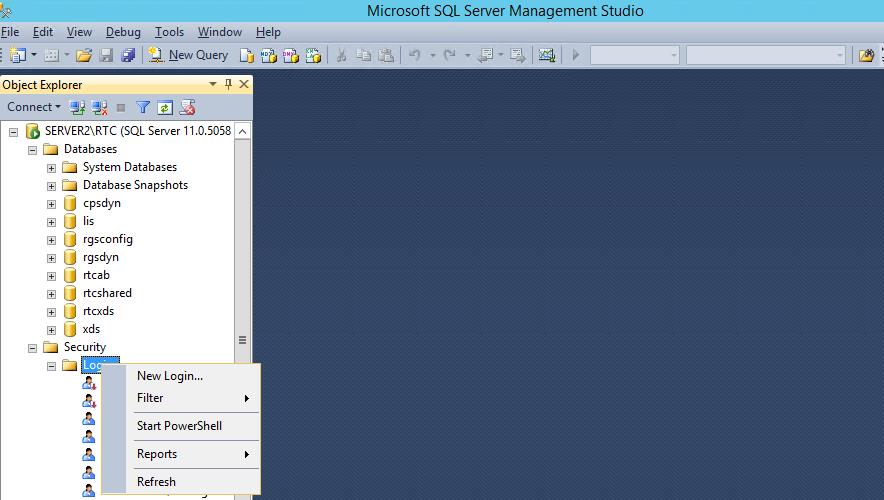
Добавляем NT Service\DPMRA
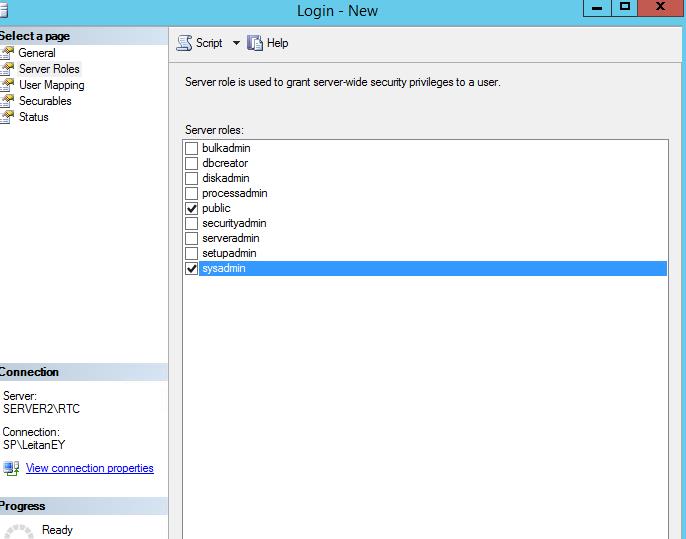
Запускаем проверку на консистентность, т.е. целостность данных реплики и SQL ресурса
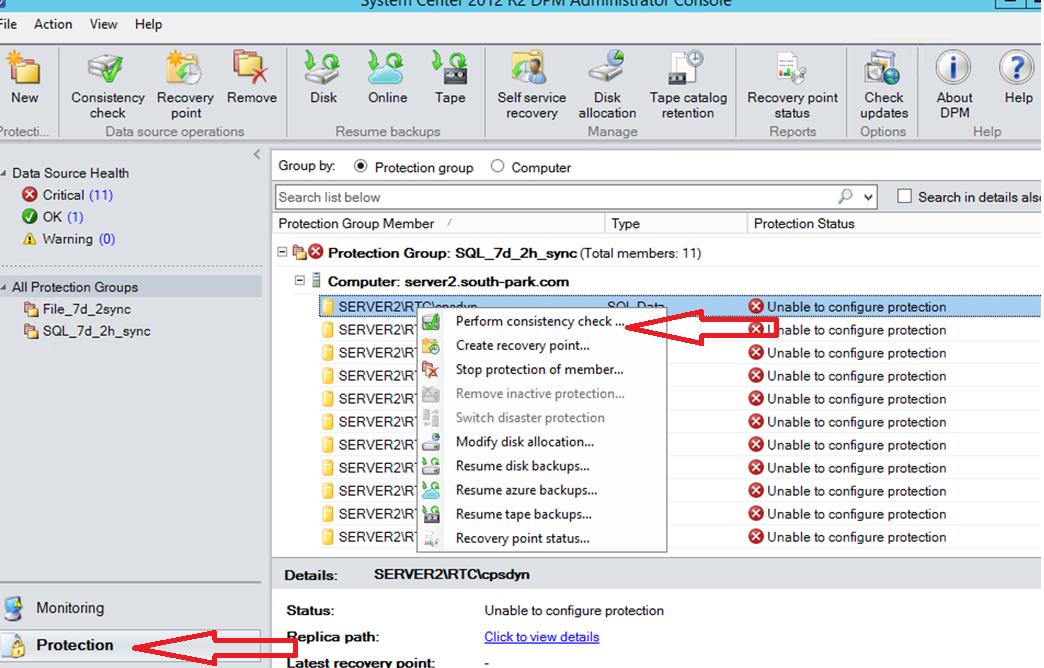
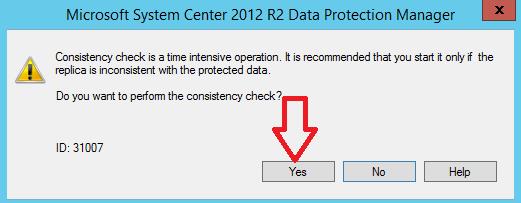
Наблюдаем за происходящим 🙂
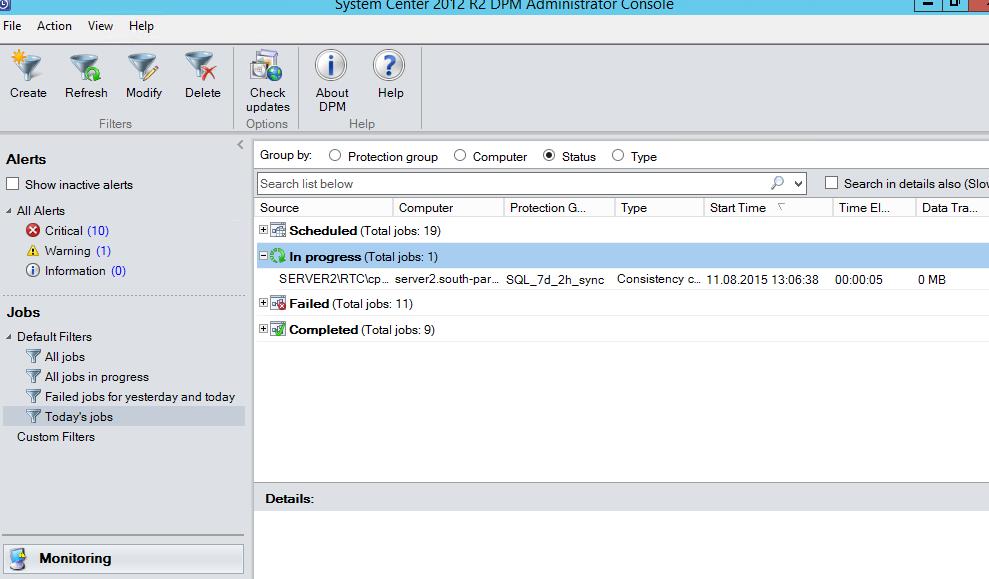
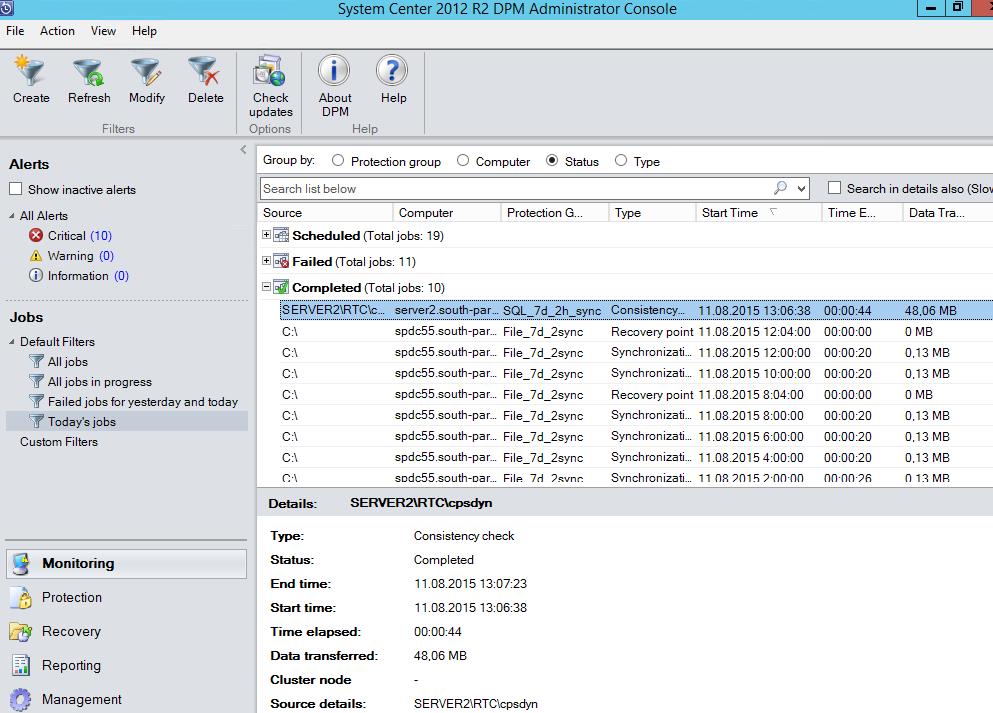
Для остальных ресурсов выполняет тоже самое
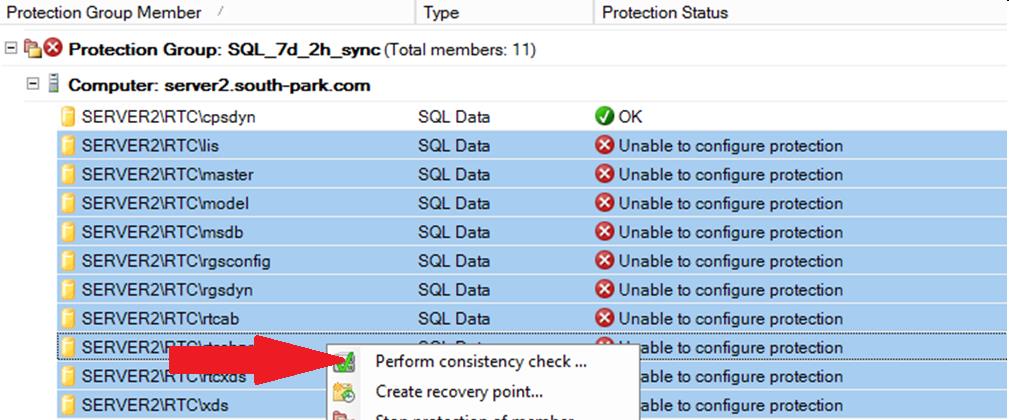
. Важный момент.
На сервере баз данных SQL должно быть свободное место (на том же логическом диске где и базы) для выполнения служебных заданий и хранения временных файлов.
В нашем случае оно будет равняться объему изменений баз данных за определённый период при выполнении инкрементальной копии (synchronization).
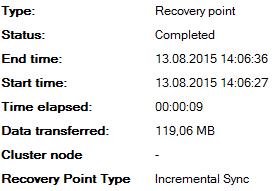
Рассмотрим на примере:
При выполнении инкрементальной копии было передано 119 МБ
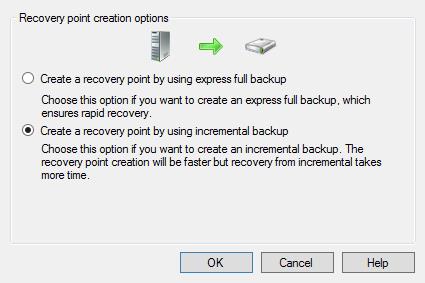
Временный файл, в который происходит запись, называется Current.log

Запись данных в файл

После создания снимка файл копируется на DPM сервер в реплику (replica volume).
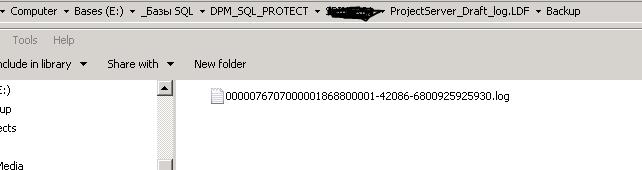
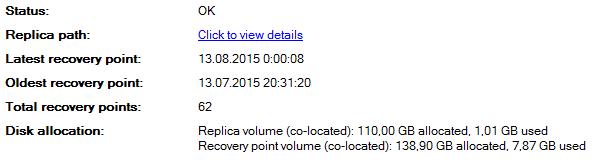
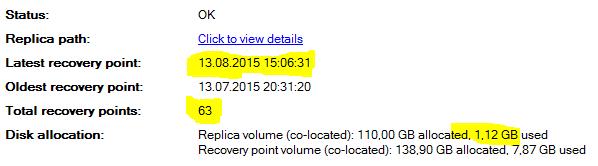
. Важный момент.
После успешного создания инкрементальной (одной или нескольких) выполняем на DPM для базы данных полное резервное копирование (Express Full Backup). При полном резервном копировании (Express Full Backup) все данные передаются напрямую на сервер DPM БЕЗ СОЗДАНИЯ ВРЕМЕННЫХ ФАЙЛОВ.
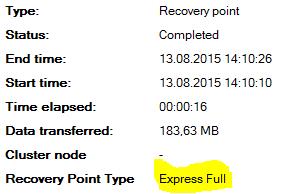
Получаем, что синхронизированные блоки перешли из реплики (replica volume) в точку восстановления (recovery point volume).
После этого временный файл из папки “ E:_Базы SQL\DPM_SQL_PROTECT\” удален и объем свободного места диска, на котором находятся базы, увеличился.
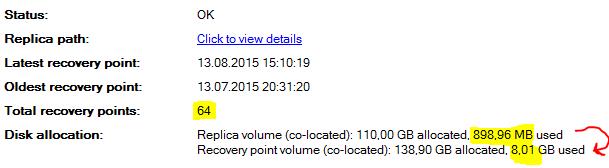
. Важный момент.
Как ранее уже обсуждалось, DPM не умеет сжимать (shrink) базу данных (уменьшать размер лог файла ldf). Поэтому для уменьшения объема лог файла необходимо выполнить команду в SQL Management Studio.
Источник



