- 4 полезных инструмента для поиска и удаления повторяющихся файлов в Linux
- 1. Rdfind — находит повторяющиеся файлы в Linux
- 2. Fdupes — сканирование дубликатов файлов в Linux
- 3. dupeGuru — поиск дубликатов файлов в Linux
- 4. FSlint — Поиск дубликатов файлов для Linux
- Дубликат файлы файлов linux
- 2 полезных инструмента для поиска и удаления повторяющихся файлов в Linux
- Rdfind – находит дубликаты файлов в Linux
- 4 Useful Tools to Find and Delete Duplicate Files in Linux
- 1. Rdfind – Finds Duplicate Files in Linux
- 2. Fdupes – Scan for Duplicate Files in Linux
- 3. dupeGuru – Find Duplicate Files in a Linux
- 4. FSlint – Duplicate File Finder for Linux
- If You Appreciate What We Do Here On TecMint, You Should Consider:
4 полезных инструмента для поиска и удаления повторяющихся файлов в Linux
Организация вашего домашнего каталога или даже системы может быть особенно сложной, если у вас есть привычка загружать всевозможные вещи из Интернета.
Часто вы можете обнаружить, что загрузили один и тот же файл mp3, pdf, epub (и все другие расширения файлов) и скопировали его в разные каталоги. Это может привести к тому, что ваши каталоги будут загромождены всевозможными бесполезными дублированными материалами.
В этом руководстве вы узнаете, как находить и удалять повторяющиеся файлы в Linux с помощью инструментов командной строки rdfind и fdupes, а также с помощью инструментов с графическим интерфейсом под названием DupeGuru и FSlint.
Предупреждение — всегда будьте осторожны при удалении в своей системе, так как это может привести к нежелательной потере данных. Если вы используете новый инструмент, сначала попробуйте его в тестовом каталоге, где удаление файлов не будет проблемой.
1. Rdfind — находит повторяющиеся файлы в Linux
Rdfind исходит из поиска избыточных данных. Это бесплатный инструмент, используемый для поиска дубликатов файлов в нескольких каталогах или внутри них. Он использует контрольную сумму и находит дубликаты на основе файлов, содержащих не только имена.
Rdfind использует алгоритм для классификации файлов и определяет, какой из дубликатов является исходным файлом, а остальные считает дубликатами. Правила ранжирования:
- Если A был найден при сканировании входного аргумента раньше, чем B, A имеет более высокий рейтинг.
- Если A был обнаружен на глубине ниже B, A имеет более высокий рейтинг.
- Если A был найден раньше, чем B, A имеет более высокий рейтинг.
Последнее правило используется, в частности, когда два файла находятся в одном каталоге.
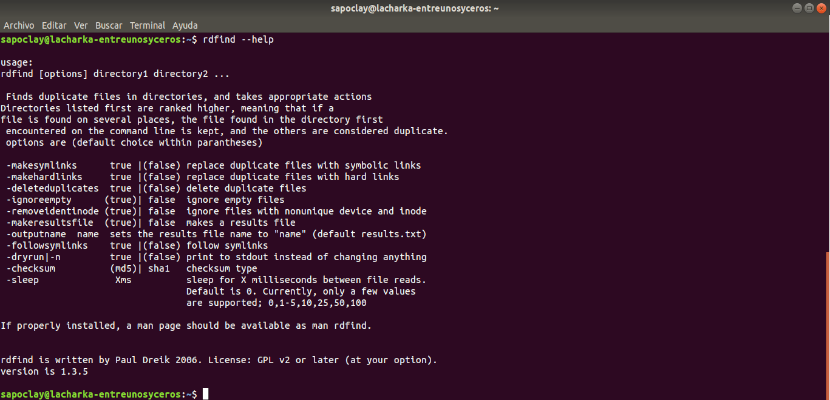
Чтобы установить rdfind в Linux, используйте следующую команду для вашего дистрибутива Linux.
Чтобы запустить rdfind в каталоге, просто введите rdfind и целевой каталог. Вот пример:

Как видите, rdfind сохранит результаты в файле с именем results.txt, расположенном в том же каталоге, в котором вы запустили программу. Файл содержит все дубликаты файлов, найденные rdfind. Вы можете просмотреть файл и удалить дубликаты файлов вручную, если хотите.
Еще вы можете использовать параметр -dryrun , который предоставит список дубликатов без каких-либо действий:
Когда вы найдете дубликаты, вы можете заменить их жесткими ссылками.
И если вы хотите удалить дубликаты, вы можете запустить.
Чтобы проверить другие полезные параметры rdfind, вы можете использовать руководство по rdfind с.
2. Fdupes — сканирование дубликатов файлов в Linux
Fdupes — еще одна программа, которая позволяет выявлять повторяющиеся файлы в вашей системе. Он бесплатный, имеет открытый исходный код и написан на C. Он использует следующие методы для определения повторяющихся файлов:
- Сравнение частичных подписей md5sum
- Сравнение полных подписей md5sum
- побайтовое сравнение проверки
Как и у rdfind, у него есть похожие параметры:
- Рекурсивный поиск
- Исключить пустые файлы
- Показывает размер повторяющихся файлов.
- Немедленно удалите дубликаты.
- Исключить файлы с другим владельцем
Чтобы установить fdupes в Linux, используйте следующую команду для вашего дистрибутива Linux.
Синтаксис Fdupes похож на rdfind. Просто введите команду, а затем каталог, который вы хотите просканировать.
Для рекурсивного поиска файлов вам необходимо указать -r такую u200bu200bопцию.
Вы также можете указать несколько каталогов и указать каталог для рекурсивного поиска.
Чтобы fdupes рассчитал размер повторяющихся файлов, используйте параметр -S .
Для сбора сводной информации о найденных файлах используйте параметр -m .

Наконец, если вы хотите удалить все дубликаты, используйте -d такую u200bu200bопцию.
Fdupes спросит, какой из найденных файлов удалить. Вам нужно будет ввести номер файла:

Решение, которое определенно не рекомендуется, — использовать параметр -N , который приведет к сохранению только первого файла.
Чтобы получить список доступных опций для использования с fdupes, просмотрите страницу справки, запустив.
3. dupeGuru — поиск дубликатов файлов в Linux
dupeGuru — это кроссплатформенный инструмент с открытым исходным кодом, который можно использовать для поиска дубликатов файлов в системе Linux. Инструмент может сканировать имена файлов или содержимое в одной или нескольких папках. Это также позволяет вам найти имя файла, похожее на файлы, которые вы ищете.
dupeGuru поставляется в разных версиях для платформ Windows, Mac и Linux. Его функция быстрого алгоритма нечеткого сопоставления поможет вам найти повторяющиеся файлы в течение минуты. Он настраивается, вы можете извлекать точные дубликаты файлов, которые хотите, и удалять ненужные файлы из системы.
Чтобы установить dupeGuru в Linux, используйте следующую команду для вашего дистрибутива Linux.

4. FSlint — Поиск дубликатов файлов для Linux
FSlint — это бесплатная утилита, которая используется для поиска и очистки различных форм линта в файловой системе. Он также сообщает о повторяющихся файлах, пустых каталогах, временных файлах, повторяющихся/конфликтующих (двоичных) именах, плохих символических ссылках и многом другом. Он имеет режимы командной строки и графического интерфейса.
Чтобы установить FSlint в Linux, используйте следующую команду для вашего дистрибутива Linux.

Это очень полезные инструменты для поиска дублированных файлов в вашей системе Linux, но вы должны быть очень осторожны при удалении таких файлов.
Если вы не уверены, нужен ли вам файл или нет, было бы лучше создать резервную копию этого файла и запомнить его каталог перед удалением. Если у вас есть какие-либо вопросы или комментарии, отправьте их в разделе комментариев ниже.
Источник
Дубликат файлы файлов linux
Для копирования файлов используйте команду cp («copy»). Она принимает два аргумента: исходный файл, который существует и должен быть скопирован, и целевой файл, который определяет имя файла-копии. cp создает идентичную копию файла, присваивая ей указанное имя целевого файла. Если файл с таким именем уже существует, cp перезаписывает его. Она не изменяет исходный файл.
Чтобы скопировать файл `my-copy’ в файл `neighbor-copy’, наберите:
$ cp my-copy neighbor-copy [Enter]
Эта команда создает новый файл с именем `neighbor-copy’, который является идентичным файлу `my-copy’ во всех отношениях, кроме имени файла, имени владельца, группы и времени модификации — новый файл имеет время модификации, указывающее момент его копирования. Файл `my-copy’ не изменяется.
Чтобы сохранить все атрибуты оригинального файла, включая его время модификации, имя владельца, группу и права доступа, используйте ключ `-p’ («preserve»)(сохранить).
Чтобы скопировать файл `my-copy’ в файл `neighbor-copy’, сохранив все атрибуты исходного файла в копии, наберите:
$ cp -p my-copy neighbor-copy [Enter]
Эта команда копирует файл `my-copy’ в новый файл `neighbor-copy’, полностью идентичный исходному по всем аспектам, кроме имени файла.
Чтобы скопировать каталог вместе со всеми подкаталогами и файлами, которые он содержит, используйте опцию -R — она создает рекурсивную копию указанного каталога и его содержимого.
Чтобы скопировать каталог `public_html’ вместе со всеми его файлами и подкаталогами, в новый каталог `private_html’, введите:
$ cp -R public_html private_html [Enter]
Опция `-R’ не копирует файлы, являющиеся символической ссылкой, и не сохраняет оригинальные права доступа к файлам. Чтобы скопировать каталог рекурсивно, включая все ссылки и учитывая все права доступа, используйте опцию `-a’ («archive»). Это полезно для резервного копирования больших по объему деревьев каталогов.
Чтобы сделать резервную копию дерева каталогов `public_html’ в каталог `private_html’, введите:
Источник
2 полезных инструмента для поиска и удаления повторяющихся файлов в Linux
Организация домашнего каталога или даже системы может быть особенно сложной, если у вас есть привычка скачивать всевозможные материалы из Интернета.
Часто вы можете обнаружить, что вы загрузили один и тот же mp3, pdf, epub (и все другие расширения файлов) и скопировали его в разные каталоги.
Это может привести к тому, что ваши каталоги будут загромождать всевозможные бесполезные дублированные файлы.
В этом учебном пособии вы узнаете, как находить и удалять дубликаты файлов в Linux, используя инструменты rdfind и fdupes командной строки.
Обратите внимание: всегда будьте осторожны с тем, что вы удаляете в своей системе, поскольку это может привести к нежелательной потере данных. Если вы используете новый инструмент, сначала попробуйте его в тестовом каталоге, где удаление файлов не будет проблемой.
Rdfind – находит дубликаты файлов в Linux
Это бесплатный инструмент, используемый для поиска дубликатов файлов через или в нескольких каталогах.
Он использует контрольную сумму и поиск дубликатов на основе файла содержит не только имена.
Rdfind использует алгоритм для классификации файлов и определяет, какой из дубликатов является исходным файлом, и рассматривает остальные как дубликаты.
- Если A было обнаружено при сканировании входного аргумента раньше B, A более ранжировано.
- Если A было найдено ниже B, то A более ранжировано.
- Если A было найдено раньше, чем B, то A более ранжировано.
Последнее правило используется, особенно в тех случаях, когда два файла находятся в одном каталоге.
Чтобы установить rdfind в Linux, используйте следующую команду в соответствии с вашим дистрибутивом Linux.
Чтобы запустить rdfind в каталоге, просто введите rdfind и целевой каталог. Вот пример:
Как вы можете видеть, rdfind сохранит результаты в файле с именем results.txt, который находится в том же каталоге, откуда вы запускали программу.
Файл содержит все повторяющиеся файлы, найденные rdfind.
Вы можете просмотреть файл и удалить дубликаты файлов вручную, если хотите.
Другое дело, что вы можете использовать опцию -dryrun, которая будет предоставлять список дубликатов без каких-либо действий:
Когда вы найдете дубликаты, вы можете заменить их c hardlinks.
И если вы хотите удалить дубликаты, вы можете запустить:
Чтобы проверить другие полезные параметры rdfind, вы можете использовать руководство rdfind.
Источник
4 Useful Tools to Find and Delete Duplicate Files in Linux
Organizing your home directory or even system can be particularly hard if you have the habit of downloading all kinds of stuff from the internet.
Often you may find you have downloaded the same mp3, pdf, epub (and all kind of other file extensions) and copied it to different directories. This may cause your directories to become cluttered with all kinds of useless duplicated stuff.
In this tutorial, you are going to learn how to find and delete duplicate files in Linux using rdfind and fdupes command-line tools, as well as using GUI tools called DupeGuru and FSlint.
A note of caution – always be careful what you delete on your system as this may lead to unwanted data loss. If you are using a new tool, first try it in a test directory where deleting files will not be a problem.
1. Rdfind – Finds Duplicate Files in Linux
Rdfind comes from redundant data find. It is a free tool used to find duplicate files across or within multiple directories. It uses checksum and finds duplicates based on file contains not only names.
Rdfind uses an algorithm to classify the files and detects which of the duplicates is the original file and considers the rest as duplicates. The rules of ranking are:
- If A was found while scanning an input argument earlier than B, A is higher ranked.
- If A was found at a depth lower than B, A is higher ranked.
- If A was found earlier than B, A is higher ranked.
The last rule is used particularly when two files are found in the same directory.
To install rdfind in Linux, use the following command as per your Linux distribution.
To run rdfind on a directory simply type rdfind and the target directory. Here is an example:
![]() Find Duplicate Files in Linux
Find Duplicate Files in Linux
As you can see rdfind will save the results in a file called results.txt located in the same directory from where you ran the program. The file contains all the duplicate files that rdfind has found. You can review the file and remove the duplicate files manually if you want to.
Another thing you can do is to use the -dryrun an option that will provide a list of duplicates without taking any actions:
When you find the duplicates, you can choose to replace them with hard links.
And if you wish to delete the duplicates you can run.
To check other useful options of rdfind you can use the rdfind manual with.
2. Fdupes – Scan for Duplicate Files in Linux
Fdupes is another program that allows you to identify duplicate files on your system. It is free and open-source and written in C. It uses the following methods to determine duplicate files:
- Comparing partial md5sum signatures
- Comparing full md5sum signatures
- byte-by-byte comparison verification
Just like rdfind it has similar options:
- Search recursively
- Exclude empty files
- Shows size of duplicate files
- Delete duplicates immediately
- Exclude files with a different owner
To install fdupes in Linux, use the following command as per your Linux distribution.
Fdupes syntax is similar to rdfind. Simply type the command followed by the directory you wish to scan.
To search files recursively, you will have to specify the -r an option like this.
You can also specify multiple directories and specify a dir to be searched recursively.
To have fdupes calculate the size of the duplicate files use the -S option.
To gather summarized information about the found files use the -m option.
![]() Scan Duplicate Files in Linux
Scan Duplicate Files in Linux
Finally, if you want to delete all duplicates use the -d an option like this.
Fdupes will ask which of the found files to delete. You will need to enter the file number:
![]() Delete Duplicate Files in Linux
Delete Duplicate Files in Linux
A solution that is definitely not recommended is to use the -N option which will result in preserving the first file only.
To get a list of available options to use with fdupes review the help page by running.
3. dupeGuru – Find Duplicate Files in a Linux
dupeGuru is an open-source and cross-platform tool that can be used to find duplicate files in a Linux system. The tool can either scan filenames or content in one or more folders. It also allows you to find the filename that is similar to the files you are searching for.
dupeGuru comes in different versions for Windows, Mac, and Linux platforms. Its quick fuzzy matching algorithm feature helps you to find duplicate files within a minute. It is customizable, you can pull the exact duplicate files you want to, and Wipeout unwanted files from the system.
To install dupeGuru in Linux, use the following command as per your Linux distribution.
![]() DupeGuru – Find Duplicate Files in Linux
DupeGuru – Find Duplicate Files in Linux
4. FSlint – Duplicate File Finder for Linux
FSlint is a free utility that is used to find and clean various forms of lint on a filesystem. It also reports duplicate files, empty directories, temporary files, duplicate/conflicting (binary) names, bad symbolic links and many more. It has both command-line and GUI modes.
To install FSlint in Linux, use the following command as per your Linux distribution.
![]() FSlint – Duplicate File Finder for -Linux
FSlint – Duplicate File Finder for -Linux
Conclusion
These are the very useful tools to find duplicated files on your Linux system, but you should be very careful when deleting such files.
If you are unsure if you need a file or not, it would be better to create a backup of that file and remember its directory prior to deleting it. If you have any questions or comments, please submit them in the comment section below.
If You Appreciate What We Do Here On TecMint, You Should Consider:
TecMint is the fastest growing and most trusted community site for any kind of Linux Articles, Guides and Books on the web. Millions of people visit TecMint! to search or browse the thousands of published articles available FREELY to all.
If you like what you are reading, please consider buying us a coffee ( or 2 ) as a token of appreciation.

We are thankful for your never ending support.
Источник



