Файлы символьных устройств
Имеются два главных пути для общения модуля разговаривать с процессами. Первый идет через файлы устройства (подобно файлам в каталоге /dev ), другой должен использовать файловую систему proc. Поскольку одной из главных причин написания модуля ядра, является поддержка некоего аппаратного устройства, мы начнем с файлов устройства.
Первоначальная цель файлов устройства состоит в том, чтобы позволить процессам связываться с драйверами устройства в ядре, и через них с физическими устройствами (модемы, терминалы, и т.д.).
Каждый драйвер устройства, который является ответственным за некоторый тип аппаратных средств, имеет собственный главный номер. Список драйверов и их главных номеров доступен в /proc/devices . Каждое физическое устройство, управляемое драйвером устройства имеет малый номер. Каталог /dev включает специальный файл, названный файлом устройства, для каждого из тех устройств, которые реально установлены в системе.
Например, если Вы даете команду ls -l /dev/hd[ab]* , вы увидите все IDE разделы жесткого диска, которые могли бы быть связаны с машиной. Обратите внимание, что все из них используют тот же самый главный номер, 3, но малые номера у каждого свои! Оговорка: Считается, что вы используете архитектуру PC. Я не знаю ничего относительно файлов устройств Linux на других архитектурах .
Когда система была установлена, все файлы устройств были созданы командой mknod . Не имеется никакой технической причины, по которой они должны быть в каталоге /dev , это только полезное соглашение. При создании файла устройства для целей тестирования, как с упражнением здесь, вероятно имело бы смысл поместить его в каталог, где Вы компилируете модуль.
Устройства разделены на два типа: символьные и блочные. Различие в том, что блочные имеют буфер для запросов, так что они могут выбирать в каком порядке им отвечать. Это важно в случае устройств памяти, где скорее понадобится читать или писать сектора, которые ближе друг к другу, чем те, которые находятся далеко. Другое различие: блочные устройства могут принимать ввод и возвращать вывод только в блоках (чей размер может измениться согласно устройству), в то время как символьные устройства могут использовать столько байтов, сколько нужно. Большинство устройств в мире символьно, потому что они не нуждаются в этом типе буферизации и не работают с фиксированным размером блока. Вы можете узнать, является ли устройство блочным или символьным, рассматривая первый символ в выводе ls -l . Если это «b», значит устройство блочное, а если «c», то символьное.
Этот модуль разделен на две отдельных части: часть модуля, которая регистрирует устройство и часть драйвера устройства. init_module вызывает module_register_chrdev , чтобы добавить драйвер устройства к символьной таблице драйверов устройств ядра. Этот вызов также возвращает главный номер, который нужно использовать для драйвера. Функция cleanup_module вычеркивает из списка устройство.
Это (регистрация и отмена регистрации) основные функциональные возможности этих двух функций. Действия в ядре не выполняются по собственной инициативе, подобно процессам, а вызываются процессами через системные вызовы или аппаратными устройствами через прерывания или другими частями ядра (просто вызывая специфические функции). В результате, когда Вы добавляете код к ядру, вы регистрируете его как драйвер для некоторого типа события, и когда Вы удаляете его, вы отменяете регистрацию.
Драйвер устройства выполняет четыре действия (функции), которые вызываются, когда кто-то пробует делать что-либо с файлом устройства, который имеет наш главный номер. Ядро знает, что вызвать их надо через структуру file_operations , Fops , который был дан, когда устройство было зарегистрировано, включает указатели на те четыре функции, которые данное устройство выполняет.
Еще мы должны помнить, что мы не можем позволять модулю выгружаться командой rmmod всякий раз, когда root захочет его выгрузить. Причина в том что, если файл устройства открыт процессом, и мы удаляем модуль, то использование файла вызвало бы обращение к точке памяти где располагалась соответствующая функция. Если мы удачливы, никакой другой код не был загружен туда, и мы получим уродливое сообщение об ошибках. Если мы неудачливы (обычно так и бывает), другой модуль был загружен в то же самое место, что означает переход в середину другой функции внутри ядра. Результаты этого невозможно предсказывать, но они не могут быть положительны.
Обычно, когда Вы не хотите выполнять что-либо, Вы возвращаете код ошибки (отрицательное число) из функции, которая делает данное действие. С cleanup_module такой фокус не пройдет: если cleanup_module вызван, модуль завершился. Однако, имеется счетчик использований, который считает, сколько других модулей используют этот модуль, названный номером ссылки (последний номер строки в /proc/modules ). Если это число не нулевое, rmmod будет терпеть неудачу. Счетчик модульных ссылок доступен в переменной mod_use_count_ . Так как имеются макрокоманды, определенные для обработки этой переменной ( MOD_INC_USE_COUNT и MOD_DEC_USE_COUNT ), мы предпочитаем использовать их, а не mod_use_count_ непосредственно, так что мы будем в безопасности, если реализация изменится в будущем.
Источник
Драйверы устройств в Linux
Часть 5: Файлы символьных устройств – создание файлов и операции с ними
Эта статья является продолжением серии статей о драйверах устройств в Linux. В ней обсуждаются вопросы, касающиеся символьных драйверов и их реализации.
В моей предыдущей статье я упоминал, что даже при регистрации диапазона устройств , файлы устройств в директории /dev не создаются — Светлана должна была создать их вручную с помощью команды mknod . Но при дальнейшем изучении Светлана выяснила, что файлы устройств можно создавать автоматически с помощью демона udev . Она также узнала о втором шаге подключения файла устройства к драйверу устройства — связывание операций над файлом устройства с функциями драйвера устройства. Вот что она узнала.
Автоматическое создание файлов устройств
Ранее, в ядре 2.4, автоматическое создание файлов устройств выполнялось самим ядром в devfs с помощью вызова соответствующего API. Однако, по мере того, как ядро развивалось, разработчики ядра поняли, что файлы устройств больше связаны с пользовательским пространством и, следовательно, они должны быть именно там, а не в ядре. Исходя из этого принципа, теперь для рассматриваемого устройства в ядре в /sys только заполняется соответствующая информация о классе устройства и об устройстве. Затем в пользовательском пространстве эту информацию необходимо проинтерпретировать и выполнить соответствующее действие. В большинстве настольных систем Linux эту информацию собирает демон udev, и создает, соответственно, файлы устройств.
Демон udev можно с помощью его конфигурационных файлов настроить дополнительно и точно указать имена файлов устройств, права доступа к ним, их типы и т. д. Так что касается драйвера, требуется с помощью API моделей устройств Linux, объявленных в
, заполнить в /sys соответствующие записи. Все остальное делается с помощью udev . Класс устройства создается следующим образом:
Затем в этот класс информация об устройстве ( ) заносится следующим образом:
Здесь, в качестве first указывается dev_t . Соответственно, дополняющими или обратными вызовами, которые должны вызыватся в хронологически обратном порядке, являются:
Посмотрите на рис.1 на записи /sys , созданные с помощью chardrv — запись ( ) и с помощью mynull — запись ( ). Здесь также показан файл устройства, созданный с помощью udev по записи : , находящейся в файле dev .
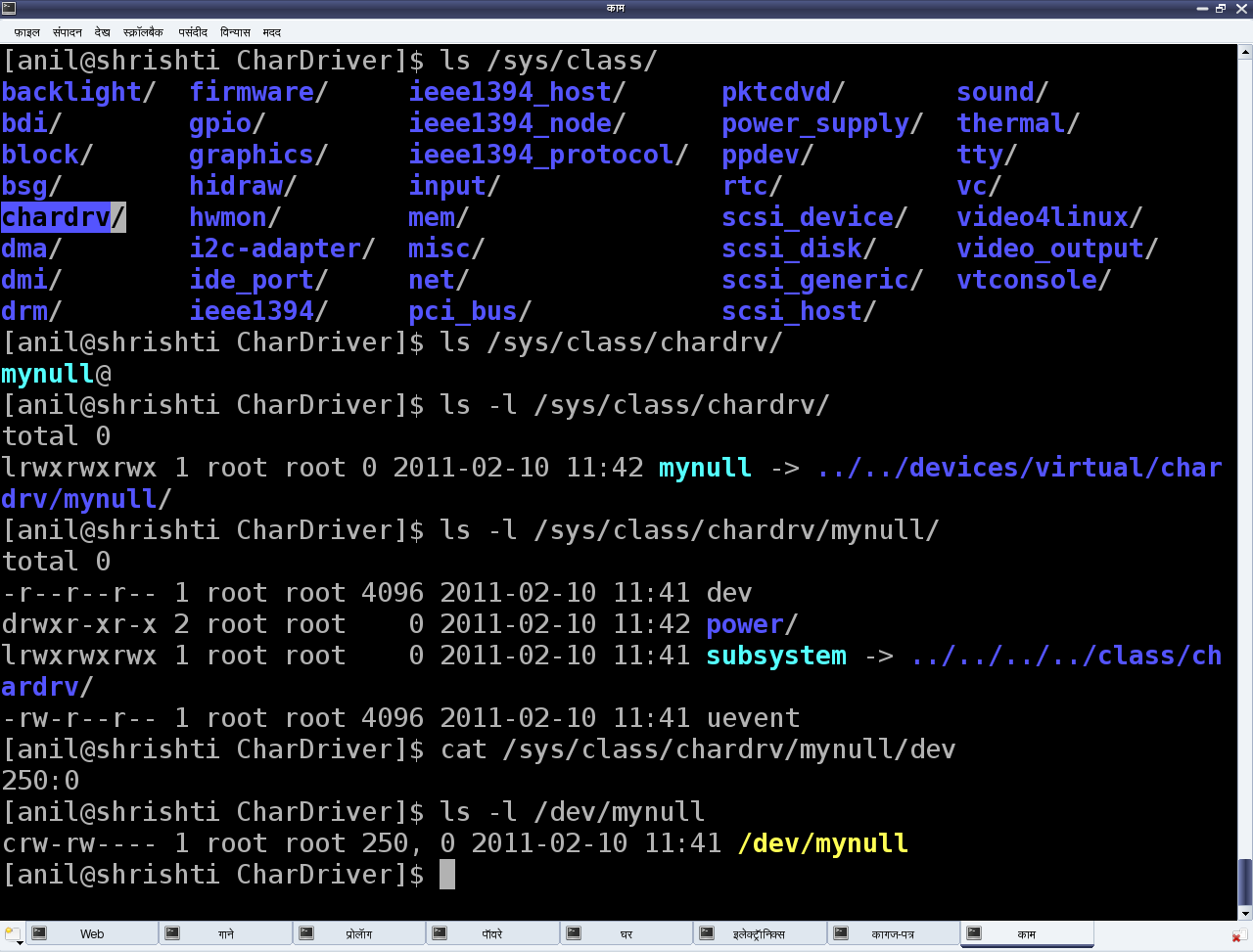
Рис.1: Автоматическое создание файла устройства
В случае, если указаны несколько младших номеров minor, API device_create() и device_destroy() могут вызываться в цикле и в этом случае окажется полезной строка ( ). Например, вызов функции device_create() в цикле с использованием индекса i будет иметь следующий вид:
Операции с файлами
Независимо от того, что системные вызовы (или, в общем случае, операции с файлами), о которых мы рассказываем, применяются к обычным файлам, их также можно использовать и с файлами устройств. Т.е. мы можем сказать: если смотреть из пользовательского пространства, то в Linux почти все является файлами. Различие — в пространстве ядра, где виртуальная файловая система (VFS) определяет тип файла и пересылает файловые операции в соответствующий канал, например, в случае обычного файла или директория — в модуль файловой системы, или в соответствующий драйвер устройства в случае использования файла устройства. Мы будем рассматривать второй случай.
Теперь, чтобы VFS передала операции над файлом устройства в драйвер, ее следует об этом проинформировать. И это то, что называется регистрацией драйвером в VFS файловых операций. Регистрация состоит из двух этапов. (Код, указываемый в скобках, взят из кода «null -драйвера», который приведен ниже).
Во-первых, давайте занесем нужные нам файловые операции ( my_open , my_close , my_read , my_write , …) в структуру, описывающую файловые операции ( struct file_operations pugs_fops ) и ею инициализируем структуру, описывающую символьное устройство ( struct cdev c_dev ); используем для этого обращение cdev_init() .
Затем передадим эту структуру в VFS с помощью вызова cdev_add() . Обе операции cdev_init() и cdev_add() объявлены в
. Естественно, что также надо закодировать фактические операции с файлами ( my_open , my_close , my_read , my_write ).
Итак, для начала, давайте все это сделаем как можно проще — скажем, максимально просто в виде «null драйвера».
null — драйвер
Светлана повторила обычный процесс сборки, добавив при этом некоторые новые проверочные шаги, а именно:
- Собрала драйвер (файл .ko ) с помощью запуска команды make .
- Загрузила драйвер с помощью команды insmod .
- С помощью команды lsmod получила список всех загруженных модулей.
- С помощью команды cat /proc/devices . получила список используемых старших номеров major.
- Поэкспериментировала с «null драйвером» (подробности смотрите на рис.2).
- Выгрузила драйвер с помощью команды rmmod .
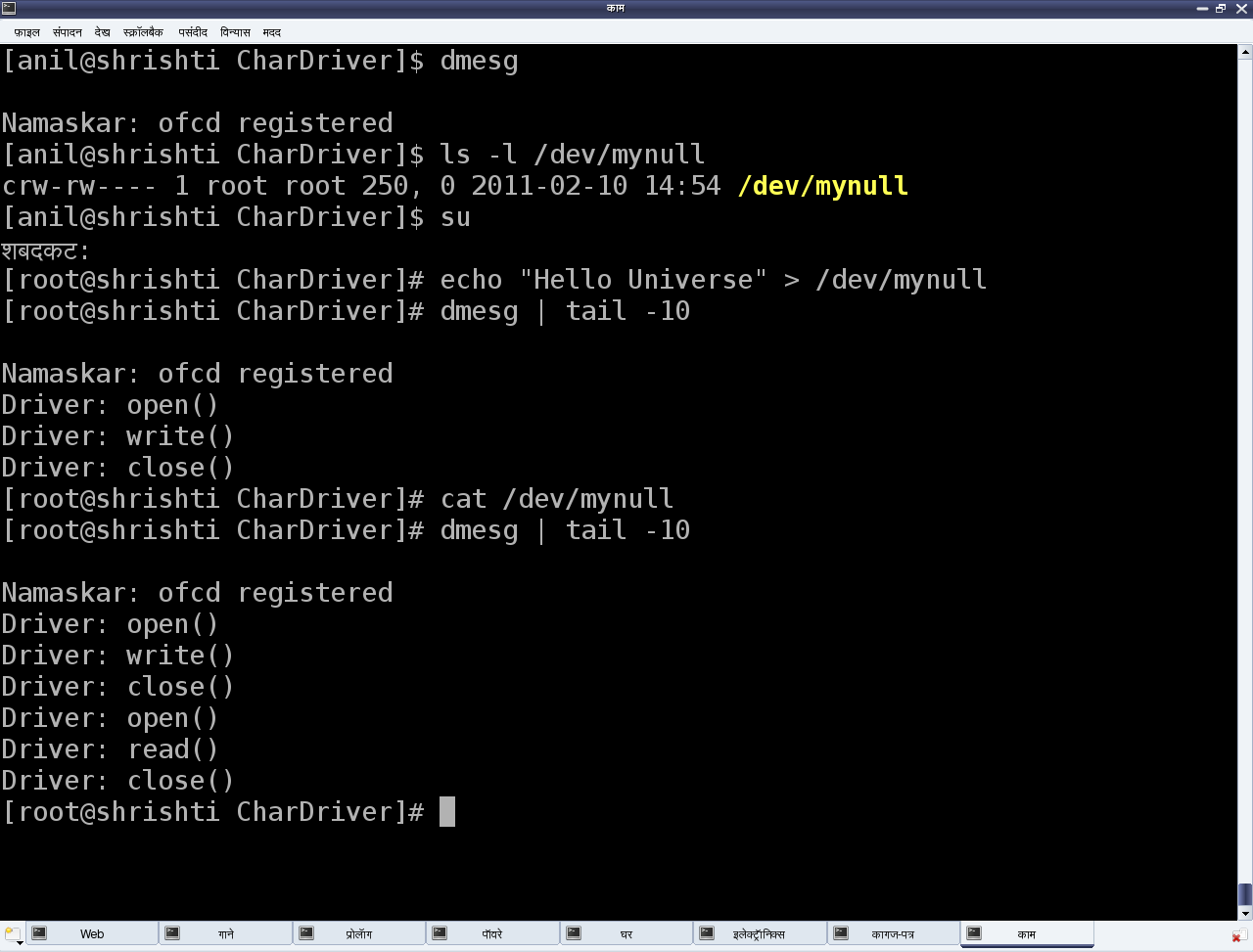
Рис.2: Эксперименты с «null драйвером»
Подведем итог
Светлана олпределенно была довольна; она сама написала символьный драйвер, который работает точно также, как и стандартный файл устройства /dev/null . Чтобы понять, что это значит, проверьте пару для файла /dev/null , а также выполните с ним команды echo и cat .
Но Светлану стала беспокоить одна особенность. В своем драйвере она использовала свои собственные вызовы ( my_open , my_close , my_read , my_write ), но, к удивлению, они, в отличие от любых других вызовов файловой системы, работают таким необычным образом. Что же тут необычного? Необычно, по крайней мере с точки зрения обычных файловых операций, то, что чтобы Светлана не записывала, при чтении она ничего не могла получить. Как она сможет решить эту проблему? Читайте следующую статью.
Источник
Файлы устройств linux это
В Linux существуют две директории — /dev и /proc, которые не имеют Windows-аналогов, и их назначение начинающим пользователям обычно непонятно. Но именно они являются мощными инструментами для понимания и более эффективного использования Linux.
Эта статья — обзор файловых систем Device (/dev) и Process (/proc). Здесь обьясняется, что это такое, как они работают, и как они используются на практике.
/dev: Файловая система устройств.
Устройства: В Linux устройство — это любая вещь (или программа, эмулирующая эту вещь), которая предоставляет методы для осуществления ввода/вывода. Например, клавиатура — это устройство ввода. В Linux большинство устройств представлены, как файлы в этой файловой системе (сетевые карты — исключение). Эти специальные файлы хранятся в /dev, и легко доступны для всех процессов, работающих с устройствами.
Обычно устройства разделяются на 2 категории — символьные устройства и блокирующие устройства. Символьные устройства производят операции ввода-вывода на базе символов. Самый очевидный пример — это клавиатура, где каждое нажатие кнопки посылает один символ.
Блокирующие устройства читают данные большими обьемами. Обычно это — устройства хранения данных, такие, как жесткие диски IDE (/dev/hd), SCSI (/dev/sd) и CD-ROMы (/dev/cdrom). В операциях ввода-вывода учавствуют большие массивы данных, что обеспечивает более эффективную работу.
Наименования устройств: Устройства часто называются сокращенными названиями вещей, которые они представляют. Например, /dev/fb представляет Frame Buffer для графики, а /dev/hd — жесткие диски IDE. Иногда более удобны бывают символьные ссылки, например — /dev/mouse может ссылаться на USB, PS2, и т.д.
Иногда может быть несколько одинаковых устройств. Если на компьютере 2 CD-ROMа, то первый будет называться /dev/cdrom0, а второй — /dev/cdrom1.
В случае с жесткими дисками наименование становится сложнее. Имя устройства состоит из типа, позиции и номера раздела. Например, первый жесткий диск может быть назван /dev/hda, где «hd» обозначает «диск IDE», а «a» — что это первый HDD. /dev/hdb будет указыать на второй жесткий диск. Первый раздел на первом диске будет называться /dev/hda1, где число 1 — номер раздела. Заметьте, что у некоторых устройств нумерация может начинаться и с нуля (/dev/cdrom0). Список всех разделов может выглядеть примерно так:
/dev/hda
/dev/hda1
/dev/hda2
/dev/hda3
/dev/hda4
/dev/hdb
/dev/hdb1
/dev/hdb2
/dev/hdb3
Жесткие диски SCSI используют /dev/sd вместо /dev/hd, но их правила наименования ничем не отличаются.
Специальные устройства: Существует несколько специальных устройств, которые иногда могут быть полезны — /dev/null, /dev/zero, / dev/full, and /dev/random.
Устройство /dev/null физически не существует, но данные, помещенные туда, просто исчезают и их уже невозможно вернуть обратно. Во многих случаях программы выводят много лишней информации. В shell-скриптах /dev/null часто используется, чтобы не беспокоить пользователя различными ненужными вещами. В примере, приведенном ниже, в ядро помещается модуль и вывод перенаправляется в /dev/null.
$ modprobe cipher-twofish > /dev/null
/dev/zero выполняет почти те же функции, что и /dev/null. Это устройство так же используется, чтобы убрать ненужные данные, но чтение из /dev/zero постоянно дает символы \0. (Чтение из /dev/null дает символы End of file). Поэтому /dev/zero часто используется для создания пустых файлов:
dd if=/dev/zero of=/my-file bs=1k count=100
Эта команда создает файл размером 100 Kb, состоящий только из нулевых символов.
/dev/full изображает полное устройство. Запись в /dev/full возвращает ошибку. Это устройство полезно при тестировании, как программа поведет себя при доступе к устройству, не имеющему свободного места.
$ cp test-file /dev/full
cp: writing /dev/full»: No space left on device
$ df -k /dev/full
file system 1k-blocks Used Available Use% Mounted on
/dev/full 0 0 0 —
Устройства /dev/random и /dev/urandom генерируют «случайную» информацию. Хотя вывод из обоих этих устройств может показаться совершенно случайным, но /dev/random на самом деле более случайно, чем /dev/urandom. /dev/random генерирует случайные символы на основе «шума окружающей среды», который имеет ограниченное количество, поэтому /dev/random работает медленно, и может иногда останавливаться и ждать поступления новых данных. /dev/urandom использует те же данные, что и /dev/random, но если случайные данные заканчиваются, начинается генерация псевдослучайных чисел. Это делает /dev/urandom более быстрым, но менее безопасным.
Старая файловая система /dev: В прошлом /dev была частью нормальной файловой системы и состояла из специальных файлов, созданных при установке системы и хранящихся на жестком диске.
Обычно /dev занимала очень много места, чтобы поддерживать множество жестких дисков, консолей, и т.д. Например, в старой файловой системе размещались сразу же 11 записей для жестких дисков — с /dev/hdb1 по /dev/hdb11. И чтобы выяснить, какой из этих файлов действительно соответствует устройству, нужна была команда:
$ file -s /dev/hdb?
/dev/hdb1: Linux/i386 ext2 file system
/dev/hdb2: Linux/i386 ext2 file system
/dev/hdb3: Linux/i386 ext2 file system
/dev/hdb4: empty
/dev/hdb5: empty
/dev/hdb6: empty
/dev/hdb7: empty
/dev/hdb8: empty
/dev/hdb9: empty
Если файл для устройства не присутствовал, есго нужно было создавать специальной программой mknod или MAKEDEV. Хотя старая модель работала, но она была сложной и неудобной.
DevFS: В ядрах версии 2.4 появилась альтернатива под названием DevFS. Принцип — файловая система /dev создается ядром при каждой загрузке и хранится в оперативной памяти. Если добавляются новые устройства, ядро просто добавляет запись, соответствующую им, в /dev. Если устройство требует специальной конфигурации для корректной работы с DevFS, то существует конфигурационный файл (обычно /etc/devfsd.conf).
/proc: Файловая система для процессов.
Процессы: В любое время Linux имеет много процессов, запущенных одновременно. Некоторые процессы доступны пользователю, а некоторые находятся на заднем плане и обрабатывают задачи, которые не требуют взаимодействия с пользователем. Запуск «ps -ef» в консоли выведет список всех процессов. Это выглядит примерно так:
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11:08 ? 00:00:04 init
root 2 1 0 11:08 ? 00:00:00 [keventd]
root 3 0 0 11:08 ? 00:00:00 [ksoftirqd_CPU0]
root 4 0 0 11:08 ? 00:00:00 [kswapd]
root 5 0 0 11:08 ? 00:00:00 [bdflush]
root 6 0 0 11:08 ? 00:00:00 [kupdated]
root 8 1 0 11:08 ? 00:00:00 [kjournald]
root 86 1 0 11:08 ? 00:00:00 /sbin/devfsd /dev
root 165 1 0 11:09 ? 00:00:00 [kjournald]
root 168 1 0 11:09 ? 00:00:00 [khubd]
root 294 1 0 11:09 ? 00:00:00 [kapmd]
root 515 1 0 11:09 ? 00:00:00 metalog [MASTER]
root 521 515 0 11:09 ? 00:00:00 metalog [KERNEL]
root 531 1 0 11:09 ? 00:00:00 /sbin/dhcpcd eth0
/etc/X11/fs/config -droppriv -user xfs
root 572 1 0 11:09 ? 00:00:00 /usr/kde/2/bin/kdm
root 593 572 2 11:09 ? 00:04:27 /usr/X11R6/bin/X -auth /var/lib/kdm/authfiles/A:0-25pIgI
root 644 1 0 11:09 vc/1 00:00:00 /sbin/agetty 38400 tty1 linux
root 1045 572 0 12:16 ? 00:00:00 -:0
mbutcher 1062 1045 0 12:16 ? 00:00:00 /bin/sh /etc/X11/Sessions/kde-2.2.2
mbutcher 1091 1062 0 12:16 ? 00:00:00 /bin/bash —login /usr/kde/2/bin/startkde
mbutcher 1132 1 0 12:16 ? 00:00:00 kdeinit: Running.
mbutcher 1157 1132 0 12:16 ? 00:00:01 kdeinit: kwin
mbutcher 1159 1 0 12:16 ? 00:00:07 kdeinit: kdesktop
mbutcher 1168 1 0 12:16 ? 00:00:00 kdeinit: kwrited
mbutcher 1171 1168 0 12:16 pty/s0 00:00:00 /bin/cat
mbutcher 1173 1 0 12:16 ? 00:00:00 alarmd
mbutcher 1207 1132 0 12:23 ? 00:00:08 kdeinit: konsole -icon konsole -miniicon konsole
mbutcher 1219 1207 0 12:23 pty/s2 00:00:00 /bin/bash
mbutcher 1309 1260 0 13:48 pty/s3 00:00:01 vi dev-and-proc.html
root 1314 1220 0 14:03 pty/s2 00:00:00 ps -ef
Многие из задач в списке, выведенном ps — это процессы, выполняемые на заднем плане. Процессы, заключенные в квадратные скобки — это процессы на уровне ядра. И только несколько задач, таких, как процессы KDE и записи в нижней части списка, взаимодействуют с пользователем.
Чтобы управлять системой, ядро должно следить за каждым запущенным процессом, включая себя. Так же информация о запущенных процессах должна быть доступна и для многих пользовательских приложений, таких, как «ps» и «top». В файловой системе /proc ядро хранит информацию о процессах.
Как DevFS, /proc хранится в памяти, а не на диске. Если посмотреть на файл /proc/mounts (который перечисляет все смонтированные файловые системы), то вы увидите строку:
proc /proc proc rw 0 0
/proc контролируется ядром и не имеет соответствующего устройства.
Информация о запущенных процессах: Чтобы следить за процессами, ядро назначает каждому из них номер PID (Process ID). Запуск команды «ps -ef», как мы уже делали ранее, напечатает список процессов, отсортированный по номеру PID (вторая колонка). В /proc хранится информация о каждом PID.
Многие директории в /proc — это числа, соответствующие номерам PID. Внутри директорий есть файлы, предоставляющие важные детали о процессе. Например, в выводе ps (выше) была строка:
mbutcher 1219 1207 0 12:23 pty/s2 00:00:00 /bin/bash
Этот процесс запускает bash, и имеет PID 1219. Директория /proc/1219 содержит информацию об этом процессе.
$ ls /proc/1219
cmdline cpu cwd environ exe fd maps mem root stat statm status
Файл «cmdline» содержит команду, данную для запуска этого процесса. Файл «environ» содержит переменные для процесса. «status» имеет статусную информацию, включая номер пользователя (UID) и номер группы (GID) пользователя, запустившего процесс, номер родительского процесса PPID (parent process ID), который запустил PID, и текущее состояние процесса, такое, как «Sleeping» или «Running».
$ cat status
Name: bash
State: S (sleeping)
Tgid: 1219
Pid: 1219
PPid: 1207
TracerPid: 0
Uid: 501 501 501 501
Gid: 501 501 501 501
FDSize: 256
Groups: 501 10 18
VmSize: 2400 kB
VmLck: 0 kB
VmRSS: 1272 kB
VmData: 124 kB
VmStk: 20 kB
VmExe: 544 kB
VmLib: 1604 kB
SigPnd: 0000000000000000
SigBlk: 0000000080010000
SigIgn: 8000000000384004
SigCgt: 000000004b813efb
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
Каждая директория процесса также содержит несколько символических ссылок. «cwd» — ссылка на текущую рабочую директорию для этого процесса, «exe» — ссылка на саму программу, и «root» ссылается на директорию, которую программа считает корневой (обычно «/»). Директория «fd» содержит список символических ссылок на описания файлов, используемых процессом.
Так же в директории есть и другие файлы, предоставляющие информацию обо всем, начиная от использования процессора и памяти до количества времени, в течении которого этот процесс работал. Они описаны в исходниках ядра под «Documentation/file systems/proc.txt» и в man-странице «man proc».
Информация ядра: Кроме информации о процессах, /proc содержит много информации, генерируемой ядром для описания состояния системы.
Ядро и его модули могут генерировать файлы в /proc для предоставления информации об их состоянии. Например, /proc/fb предоставляет информацию о доступных устройствах frame buffer (чаще всего используются для демонстрации логотипа при загрузке).
$ cat fb
0 VESA VGA
Число 0 — это индекс устройства, соответствующего /dev/fb0. Если бы имелся второй frame buffer, то имелась бы еще одна запись, соответствующая /dev/fb1. Вообще, данные в /proc часто ссылаются на устройства в /dev или дают о них больше информации.
Много информации об устройствах хранится в /proc. Файл /proc/pci содержит информацию о почти каждом PCI-устройстве, обнаруженном в системе. Запуск команды «lspci» выводит похожий список, потому что в качестве источника информации используется именно /proc/pci. /proc/bus содержит директории для различных шинных архитектур (PCI, PCCard, USB), которые в свою очередь содержат информацию об устройствах, подключенных к этим шинам. Сетевая информация и статистика хранится в /proc/net. Информация о жестких дисках хранится в /proc/ide и /proc/scsi, в зависимости от типа жесткого диска. /proc/devices перечисляет все устройства, разделенные на категории «block» и «characters».
$ cat /proc/devices
Character devices:
1 mem
2 pty/m%d
3 pty/s%d
4 tts/%d
5 cua/%d
7 vcs
10 misc
14 sound
29 fb
116 alsa
162 raw
180 usb
226 drm
254 pcmcia
Block devices:
1 ramdisk
2 fd
3 ide0
22 ide1
А вообще — в /proc имеется намного больше файлов, чем описано здесь. Для каждого ядра формат /proc может быть разным, в зависимости от конфигурации и версии ядра, установленных устройств, и состояния компьютера. Формат информации может быть разным, но большинство из этих файлов документированы в Documentation/file systems/proc.txt.
Взаимодействие с процессами через /proc: Некоторые файлы из /proc предназначены не только для чтения. Запись в них может изменять параметры ядра. Чтение файлов из каталога /proc обычно безопасно, но записывать информацию в эти файлы, не зная их формата, опасно. Но все равно, иногда запись в /proc — это единственный способ взаимодействия с ядром.
Например, в последние версии ядра можно встроить высокопроизводительный Web-сервер, работающий на уровне ядра системы (khttp). Запуск Web-сервера по умолчанию может быть небезопасен, и поэтому khttp можно запустить через сообщение, посылаемое в /proc.
echo 1 > /proc/sys/net/khttpd/start
Когда ядро видит изменение содержимого /proc/sys/net/khttpd/start с нуля (значение по умолчанию) на единицу, оно запускает khttpd сервер.Так же в /proc имеется еще несколько десятков конфигурируемых параметров — некоторые для настройки оборудования, другие — для управления ядром. Почти все из них выполняются на низком уровне, и их неправильное использование может быть небезопасно для системы.
Заключение: /proc и /dev предоставляют в виде файлов интерфейсы для взаимодействия с Linux. Они помогают в определении конфигурации и состояния различных устройств и процессов системы. Так же они обеспечивают простое взаимодействие с операционной системой. Понимание и применение этих двух файловых систем — ключ к эффективной работе в Linux.
Источник



