- Оптимизация Linux под нагрузку. Кэширование операций записи на диск.
- Кэширование в Linux
- Настройка pdflush
- Итого: Когда pdflush начинает запись?
- Процесс записи страниц
- Рекомендации по оптимизации Linux для операций, требующий частой записи
- Инструкция по настройке параметров
- How to Clear Cache on Linux
- How Linux File System Cache Works
- Using Free command to view Cache Usage
- Proc Sys VM Drop Caches Command
- Experimental Verification that Drop Caches Works
- Conclusion
- About the author
- Linux Wolfman
- 10 лучших инструментов кэширования с открытым исходным кодом для Linux
- Что такое кеширование или кеширование контента?
- Зачем использовать кеширование?
- 1. Redis
- 2. Memcached
- 3. Apache Ignite
- 4. Сервер Couchbase
- 5. Hazelcast IMDG
- 6. Mcrouter
- 7. Varnish Cache
- 8. Прокси-сервер для кеширования Squid
- 9. NGINX
- 10. Apache Traffic Server
- Заключительные замечания
Оптимизация Linux под нагрузку. Кэширование операций записи на диск.
Недавно на одном из виртуальных серверов столкнулся с проблемой долгой записи на диск. И под эту тему нашел интересную статью, в которой подробно рассмотрен вопрос функционирования кэширования операций записи на диск в Linux. Сегодня будет перевод этой статьи.
Кэширование в Linux
При записи данных на диск (любой программой) Linux кэширует эту информацию в области памяти, называемой Page Cache (страничный кэш). Информацию об этой области памяти можно посмотреть с помощью команд free, vmstat или top. Полную информацию об этой области памяти можно посмотреть в файле /proc/meminfo. Ниже приведен пример этой файла на сервере с 4-мя GB RAM:
Размер Page Cache показан в параметре «Cached», в данном примере он составляет 2,9 GB. При записи страниц в память размер параметра «Dirty» увеличивается. При начале непосредственно записи на диск будет увеличиваться параметр «Writeback» до тех пор, пока запись не закончится. Достаточно сложно увидеть параметр «Writeback» высоким, так как его значение увеличивается только во время опроса, когда операции ввода/вывода (I/O) поставлены в очередь, но еще не записаны на диск.
Linux обычно записывает данные из кэша на диск с помощью процесса pdflush. В любой момент в системе запущено от 2 до 8 потоков pdflush. В файле /proc/sys/vm/nr_pdflush_threads можно посмотреть сколько в данный момент активных потоков. Каждый раз все существующие потоки pdflush заняты по крайней мере 1 секунду. Новые потоки пытаются записать данные в свободные очереди устройств, таким образом, чтобы на каждое активное устройство был 1 поток сбрасывающий данные из кэша. Каждый раз по прошествии секунды без какой либо активности со стороны pdflush убирается 1 поток. В Linux можно настроить минимальное и максимальное количество pdflush потоков.
Настройка pdflush
Каждый поток pdflush контролируется несколькими параметрами в /proc/sys/vm:
- /proc/sys/vm/dirty_writeback_centisecs (default 500): в сотых долях секунд. Этот параметр означает как часто pdflush возобновляет работу для записи данных на диск. По умолчанию возобновляет работу 2 потока каждые 5 секунд.
Возможно недокументированное поведение, которое пресекает попытки уменьшения dirty_writeback_centisecs для более агрессивного кэширования данных процессом pdflush. Например, в ранних версиях ядра 2.6 Linux в файле mm/page-writeback.c код включал логику, которая описывалась «если запись на диск длится дольше, чем параметр dirty_writeback_centisecs, тогда нужно поставить интервал в 1 секунду». Эта логика описана только в коде ядра, и ее функционирование зависит от версии ядра Linux. Так как это не очень хорошо, поэтому вы будете защищены от уменьшения этого параметра. - /proc/sys/vm/dirty_expire_centiseconds (default 3000): в сотых долях секунд. Этот параметр указывает как долго данные могут находится в кэше, после чего должны быть записаны на диск. Значение по умолчанию очень долгое: 30 секунд. Это означает, что при нормальной работе до тех пор пока в кэш не запишется достаточно данных для вызова другого метода pdflush, Linux не будет записывать данные на диск, находящиеся в кэше менее 30 секунд.
- /proc/sys/vm/dirty_background_ratio (default 10): Максимальный процент оперативной памяти, который может быть заполнен страничным кэшем до записи данных на диск. Некоторые версии ядра Linux могут этот параметр устанавливать в 5%.
В большинстве документации этот параметр описывается как процент от общей оперативной памяти, но согласно исходным кодам ядра Linux это не так. Глядя на meminfo, параметр dirty_background_ratio расчитывается от величины MemFree + Cached — Mapped. Поэтому для нашей демонстрационной системы 10% составляет немного меньше, чем 250MB, но не 400MB.
Итого: Когда pdflush начинает запись?
В конфигурации по умолчанию, данные, записываемые на диск, находятся в памяти до тех пор пока:
- они дольше 30 секунд находятся в памяти;
- кэшированные страницы занимают более 10% рабочей памяти.
Если на сервере операции записи происходят часто, то однажды будет достигнут параметр dirty_background_ratio, и вы сможете увидеть, что вся запись на диск идет только через этот параметр не дожидаясь истечения параметра dirty_expire_centiseconds.
Процесс записи страниц
Параметр /proc/sys/vm/dirty_ratio (default 40): Максимальный процент общей оперативной памяти, который может быть выделен под страничный кэш, до того как pdflush будет писать данные на диск.
Примечание: Во время записи на диск все процессы блокируются на запись, не только тот который заполнил буфер на запись. Это может вызвать спровоцировать блокировку одним процессов всех операций вводы/вывода в системе. Провести этот
Рекомендации по оптимизации Linux для операций, требующий частой записи
Обычно люди при попытке увеличения производительности дисковой подсистемы сталкиваются с проблемой, что Linux буферизует слишком много информации сразу. Это особенно трудно для операций, требующий синхронизации файловой системы, использующих вызовы fsync. Если во время такого вызова в кэше много данных, то система может «подвиснуть» пока не закончится этот вызов.
Другая частая проблема происходит потому что слишком много требуется записать до того, как начнется запись на физический диск, операции ввода/вывода происходят чаще, чем при нормальной работе. Вы получите более долгие периоды, когда запись на диск не происходит, пока большой кэш не будет заполнен, после чего сработает один из триггеров pdflush и данные запишутся на максимальной скорости.
dirty_background_ratio: Основной инструмент настройки, обычно уменьшают этот параметр. Если ваша цель снизить количество данных, хранимое в кэше, так что данные будут писаться на диск постепенно, а не все сразу, то уменьшение этого параметра наиболее эффективный путь. Более приемлемо значение по умолчанию для систем имеющих много оперативной памяти и медленные диски.
dirty_ratio: Второй по значимости параметр для настройки. При значительном снижении этого параметра приложения, которые должны писать на диск, будут блокироваться все вместе.
dirty_expire_centisecs: Попробуйте уменьшить, но не сильно. Позволяет уменьшить время нахождения страниц в кэше до записи на диск, но это значительно снизит среднюю скорость записи на диск, т.к. это менее эффективно. Это особенно проявится на системах с медленными дисками.
Инструкция по настройке параметров
В файле /etc/sysctl.conf вносим, например:
После синхронизируем данные кэша и диска, очистим кэш и сохраним параметры.
Источник
How to Clear Cache on Linux
How Linux File System Cache Works
The kernel reserves a certain amount of system memory for caching the file system disk accesses in order to make overall performance faster. The cache in linux is called the Page Cache. The size of the page cache is configurable with generous defaults enabled to cache large amounts of disk blocks. The max size of the cache and the policies of when to evict data from the cache are adjustable with kernel parameters. The linux cache approach is called a write-back cache. This means if data is written to disk it is written to memory into the cache and marked as dirty in the cache until it is synchronized to disk. The kernel maintains internal data structures to optimize which data to evict from cache when more space is needed in the cache.
During Linux read system calls, the kernel will check if the data requested is stored in blocks of data in the cache, that would be a successful cache hit and the data will be returned from the cache without doing any IO to the disk system. For a cache miss the data will be fetched from IO system and the cache updated based on the caching policies as this same data is likely to be requested again.
When certain thresholds of memory usage are reached background tasks will start writing dirty data to disk to ensure it is clearing the memory cache. These can have an impact on performance of memory and CPU intensive applications and require tuning by administrators and or developers.
Using Free command to view Cache Usage
We can use the free command from the command line in order to analyze the system memory and the amount of memory allocated to caching. See command below:
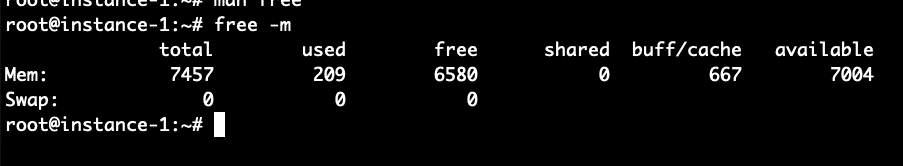
What we see from the free command above is that there is 7.5 GB of RAM on this system. Of this only 209 MB is used and 6.5 MB is free. 667 MB is used in the buffer cache. Now let’s try to increase that number by running a command to generate a file of 1 Gigabyte and reading the file. The command below will generate approximately 100MB of random data and then append 10 copies of the file together into one large_file.
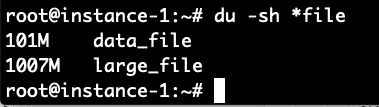
Now we will make sure to read this 1 Gig file and then check the free command again:

We can see the buffer cache usage has gone up from 667 to 1735 Megabytes a roughly 1 Gigabyte increase in the usage of the buffer cache.
Proc Sys VM Drop Caches Command
The linux kernel provides an interface to drop the cache let’s try out these commands and see the impact on the free setting.

We can see above that the majority of the buffer cache allocation was freed with this command.
Experimental Verification that Drop Caches Works
Can we do a performance validation of using the cache to read the file? Let’s read the file and write it back to /dev/null in order to test how long it takes to read the file from disk. We will time it with the time command. We do this command immediately after clearing the cache with the commands above.

It took 8.4 seconds to read the file. Let’s read it again now that the file should be in the filesystem cache and see how long it takes now.
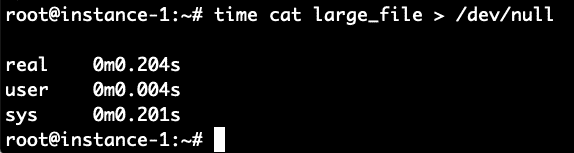
Boom! It took only .2 seconds compared to 8.4 seconds to read it when the file was not cached. To verify let’s repeat this again by first clearing the cache and then reading the file 2 times.
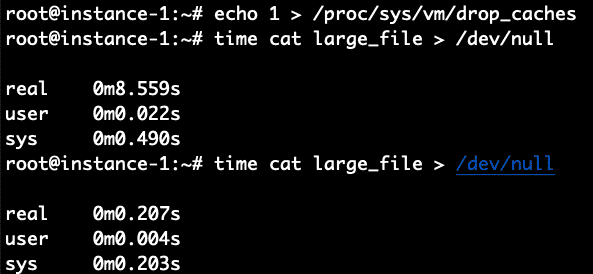
It worked perfectly as expected. 8.5 seconds for the non-cached read and .2 seconds for the cached read.
Conclusion
The page cache is automatically enabled on Linux systems and will transparently make IO faster by storing recently used data in the cache. If you want to manually clear the cache that can be done easily by sending an echo command to the /proc filesystem indicating to the kernel to drop the cache and free the memory used for the cache. The instructions for running the command were shown above in this article and the experimental validation of the cache behavior before and after flushing were also shown.
About the author

Linux Wolfman
Linux Wolfman is interested in Operating Systems, File Systems, Databases and Analytics and always watching for new technologies and trends. Reach me by tweeting to @linuxhint and ask for the Wolfman.
Источник
10 лучших инструментов кэширования с открытым исходным кодом для Linux
Надёжные распределенные вычислительные системы и приложения стали краеугольным камнем выдающихся бизнесов, особенно в области автоматизации и управления критически важными бизнес-процессами и предоставления услуг клиентам. Как разработчики и системные администраторы этих систем и приложений, вы должны предоставить все виды решений в области информационных технологий (ИТ), которые обеспечат вам самые эффективные из доступных систем.
Сюда входят такие задачи, как проектирование, тестирование и реализация стратегий повышения производительности, надёжности, доступности и масштабируемости систем/приложений, чтобы предоставить конечным пользователям удовлетворительный уровень обслуживания. Кэширование — один из многих, очень простых, но эффективных методов доставки приложений, на который вы можете положиться. Прежде чем идти дальше, давайте кратко рассмотрим, что такое кеширование, где и/или как его можно применить, а также его преимущества?
Что такое кеширование или кеширование контента?
Кэширование (или кэширование содержимого) — это широко используемый метод хранения копий данных во временном хранилище (также известном как кеш), чтобы к данным можно было легко и быстро получить доступ, чем когда они извлекаются из исходного хранилища. Данные, хранящиеся в кеше, могут включать файлы или фрагменты файлов (например, файлы HTML, сценарии, изображения, документы и т. д.), Операции или записи базы данных, вызовы API, записи DNS и т. д. В зависимости от типа и цели кэширования.
Кэш может быть в виде аппаратного или программного обеспечения. Программный кэш (которому и посвящена данная статья) может быть реализован на разных уровнях стека приложений.
Кэширование может применяться на стороне клиента (или на уровне представления приложения), например, кеширование браузера или кеширование приложения (или автономный режим). Большинство, если не все современные браузеры поставляются с реализацией кеширования HTTP. Возможно, вы слышали популярную фразу «очистите кеш» при доступе к веб-приложению, чтобы вы могли видеть последние данные или контент на веб-сайте или в приложении, вместо того, чтобы браузер использовал старую копию контента, хранящуюся локально.
Другой пример кэширования на стороне клиента — кэширование DNS, которое происходит на уровне операционной системы (ОС). Это временное хранилище информации о предыдущих поисках DNS, выполненных ОС или веб-браузером.
Кэширование также может быть реализовано на сетевом уровне, в локальной или глобальной сети через прокси. Распространённый пример кэширования этого типа — сети доставки контента (CDN), которые представляют собой глобально распределенную сеть веб-прокси-серверов.
В-третьих, вы также можете реализовать кеширование на исходном или внутреннем сервере(ах). Существуют разные формы кеширования на уровне сервера, в их число входят:
- кэширование веб-сервера (для кеширования изображений, документов, скриптов и т. д.).
- кэширование приложений или запоминание приложений (используется при чтении файлов с диска, данных из других служб или процессов или при запросе данных из API и т. д.).
- кэширование базы данных (для обеспечения доступа в памяти к часто используемым данным, таким как запрошенные строки базы данных, результаты запросов и другие операции).
Обратите внимание, что данные кэша могут храниться в любой системе хранения, включая базу данных, файл, системную память и т. д. Но должны быть более быстрым носителем, чем первичный источник. В этом отношении кэширование в памяти является наиболее эффективной и часто используемой формой кэширования.
Зачем использовать кеширование?
Кэширование даёт множество преимуществ, включая следующие:
- На уровне базы данных оно увеличивает скорость чтения кэшированных данных до микросекунд. Вы также можете использовать кэш с обратной записью для повышения производительности записи, когда данные записываются в память, а затем записываются на диск или в основное хранилище с заданными интервалами. Но аспект целостности данных может иметь потенциально катастрофические последствия. Например, при сбое системы непосредственно перед сохранением данных в основном хранилище.
- На уровне приложения кэш может хранить часто считываемые данные внутри самого процесса приложения, тем самым сокращая время поиска данных с секунд до микросекунд, особенно по сети.
- Принимая во внимание общую производительность приложения и сервера, кэширование помогает снизить нагрузку на сервер, задержку и пропускную способность сети, поскольку кэшированные данные передаются клиентам, тем самым улучшая время отклика и скорость доставки клиентам.
- Кэширование также обеспечивает доступность контента, особенно через CDN, и многие другие преимущества.
В этой статье мы рассмотрим некоторые из лучших инструментов с открытым исходным кодом (кэширование приложений/баз данных и кэширующие прокси-сервера) для реализации кэширования на стороне сервера в Linux.
1. Redis
Redis (REmote DIctionary Server в полной мере) — это бесплатная, быстрая, высокопроизводительная и гибкая распределенная вычислительная система с открытым исходным кодом, которая может использоваться на большинстве, если не на всех языках программирования.
Это хранилище структуры данных в памяти, которое работает как механизм кэширования, постоянная база данных на диске в памяти и брокер сообщений. Хотя он разработан и протестирован на Linux (рекомендуемая платформа для развёртывания) и OS X, Redis также работает в других системах POSIX, таких как *BSD, без каких-либо внешних зависимостей.
Redis поддерживает множество структур данных, таких как строки, хэши, списки, наборы, отсортированные наборы, растровые изображения, потоки и многое другое. Это позволяет программистам использовать определённую структуру данных для решения конкретной проблемы. Он поддерживает автоматические операции со своей структурой данных, такие как добавление к строке, добавление элементов в список, увеличение значения хэша, вычисление пересечения множеств и многое другое.
Его ключевые функции включают репликацию Redis master-slave (которая по умолчанию является асинхронной), высокую доступность и автоматическое переключение при отказе, предлагаемые с использованием Redis Sentinel, кластера Redis (вы можете масштабировать горизонтально, добавляя дополнительные узлы кластера) и разделение данных (распределение данных между несколькими экземплярами Redis). Он также поддерживает транзакции, сценарии Lua, ряд параметров сохраняемости и шифрование связи клиент-сервер.
Redis — это постоянная база данных в памяти, которая находится в памяти, поэтому обеспечивает наилучшую производительность, когда лучше всего работает с набором данных в памяти. Однако вы можете использовать его с базами данных на диске, такими как MySQL, PostgreSQL и многими другими. Например, вы можете взять в Redis небольшие данные с очень большим объёмом записи, а другие фрагменты данных оставить в базе данных на диске.
Redis поддерживает безопасность разными способами: во-первых за счёт использования функции «защищённого режима» для защиты экземпляров Redis от доступа из внешних сетей. Он также поддерживает аутентификацию клиент-сервер (где пароль настраивается на сервере и указывается в клиенте) и TLS на всех каналах связи, таких как клиентские соединения, ссылки репликации, протокол шины Redis Cluster и многое другое.
Redis имеет очень много вариантов использования, которые включают кеширование базы данных, кэширование всей страницы, управление данными сеанса пользователя, хранилище ответов API, систему обмена сообщениями публикации/подписки, очередь сообщений и многое другое. Их можно применять в играх, приложениях социальных сетей, RSS-каналах, анализе данных в реальном времени, рекомендациях пользователей и т. д.
2. Memcached
Memcached — это бесплатная, простая, но мощная система кэширования объектов распределенной памяти с открытым исходным кодом. Это хранилище ключей и значений в памяти для небольших фрагментов данных, таких как результаты вызовов базы данных, вызовов API или отрисовки страницы. Он работает в Unix-подобных операционных системах, включая Linux и OS X, а также в Microsoft Windows.
Будучи инструментом разработчика, он предназначен для увеличения скорости динамических веб-приложений путём кэширования контента (по умолчанию, кеш-память наименее использованного (LRU)), что снижает нагрузку на базу данных на диске — он действует как краткосрочная память для Приложения. Он предлагает API для самых популярных языков программирования.
Memcached поддерживает строки как единственный тип данных. Он имеет архитектуру клиент-сервер, где половина логики выполняется на стороне клиента, а другая половина — на стороне сервера. Важно отметить, что клиенты понимают, как выбрать сервер для записи или чтения для элемента. Кроме того, клиент очень хорошо знает, что делать, если он не может подключиться к серверу.
Несмотря на то, что это система распределенного кэширования, поддерживающая кластеризацию, серверы Memcached отключены друг от друга (т.е. они не знают друг друга). Это означает, что нет поддержки репликации, как в Redis. Они также понимают, как хранить и извлекать элементы, управлять тем, когда выселять или повторно использовать память. Вы можете увеличить доступную память, добавив больше серверов.
Он поддерживает аутентификацию и шифрование через TLS начиная с Memcached 1.5.13, но эта функция все ещё находится на экспериментальной стадии.
3. Apache Ignite
Apache Ignite, также бесплатное и с открытым исходным кодом, горизонтально масштабируемое распределенное хранилище ключей и значений в памяти, кэш и многомодельная система баз данных, которая предоставляет мощные API-интерфейсы обработки для вычислений с распределенными данными. Это также сетка данных в памяти, которую можно использовать либо в памяти, либо с собственной персистентностью Ignite. Он работает в UNIX-подобных системах, таких как Linux, а также Windows.
Он имеет многоуровневое хранилище, полную поддержку SQL и транзакции ACID (атомарность, согласованность, изоляция, долговечность) (поддерживается только на уровне API ключ-значение) на нескольких узлах кластера, совместную обработку и машинное обучение. Он поддерживает автоматическую интеграцию с любыми сторонними базами данных, включая любые СУБД (например, MySQL, PostgreSQL, Oracle Database и т. д.) или хранилища NoSQL.
Важно отметить, что, хотя Ignite работает как хранилище данных SQL, это не полностью база данных SQL. Он чётко обрабатывает ограничения и индексы по сравнению с традиционными базами данных; он поддерживает первичные и вторичные индексы, но только первичные индексы используются для обеспечения уникальности. Кроме того, он не поддерживает ограничения внешнего ключа.
Ignite также поддерживает безопасность, позволяя вам включить аутентификацию на сервере и предоставить учётные данные пользователя на клиентах. Также существует поддержка связи через сокеты SSL для обеспечения безопасного соединения между всеми узлами Ignite.
Ignite имеет множество вариантов использования, включая систему кеширования, ускорение системной рабочей нагрузки, обработку данных в реальном времени и аналитику. Его также можно использовать как платформу, ориентированную на графы.
4. Сервер Couchbase
Couchbase Server также является распределенной базой данных взаимодействия, ориентированной на документы NoSQL, с открытым исходным кодом, в которой данные хранятся в виде элементов в формате «ключ-значение». Он работает в Linux и других операционных системах, таких как Windows и Mac OS X. Он использует многофункциональный документно-ориентированный язык запросов под названием N1QL, который предоставляет мощные службы запросов и индексирования для поддержки субмиллисекундных операций с данными.
Его примечательными особенностями являются быстрое хранилище ключей и значений с управляемым кешем, специализированные индексаторы, мощный механизм запросов, горизонтально масштабируемая архитектура (многомерное масштабирование), большие данные и интеграция SQL, безопасность полного стека и высокая доступность.
Couchbase Server имеет встроенную поддержку кластера с несколькими экземплярами, где инструмент управления кластером координирует все действия узла и предоставляет клиентам простой интерфейс в масштабе кластера. Важно отметить, что вы можете добавлять, удалять или заменять узлы по мере необходимости, без простоев. Он также поддерживает репликацию данных между узлами кластера, выборочную репликацию данных между центрами обработки данных.
Он реализует безопасность через TLS, используя выделенные серверные порты Couchbase, различные механизмы аутентификации (с использованием учётных данных или сертификатов), контроль доступа на основе ролей (для проверки каждого аутентифицированного пользователя на предмет определённых системой ролей, которые им назначены), аудита, журналов и сеансов.
Его варианты использования включают унифицированный программный интерфейс, полнотекстовый поиск, параллельную обработку запросов, управление документами, индексацию и многое другое. Он специально разработан для обеспечения управления данными с малой задержкой для крупномасштабных интерактивных веб-приложений, мобильных приложений и приложений Интернета вещей.
5. Hazelcast IMDG
Hazelcast IMDG (In-Memory Data Grid) — это лёгкое, быстрое и расширяемое промежуточное ПО с открытым исходным кодом для сетки данных в памяти, которое обеспечивает эластично масштабируемые распределенные вычисления в памяти. Hazelcast IMDG также работает в Linux, Windows, Mac OS X и любой другой платформе с установленной Java. Он поддерживает широкий спектр гибких и языковых структур данных, таких как Map, Set, List, MultiMap, RingBuffer и HyperLogLog.
Hazelcast является одноранговым и поддерживает простую масштабируемость, настройку кластера (с возможностью сбора статистики, мониторинга по протоколу JMX и управления кластером с помощью полезных утилит), распределенные структуры данных и события, разделение данных и транзакции. Он также является избыточным, поскольку сохраняет резервную копию каждой записи данных на нескольких элементах. Чтобы масштабировать кластер, просто запустите другой экземпляр, данные и резервные копии автоматически и равномерно сбалансируются.
Он предоставляет набор полезных API-интерфейсов для доступа к процессорам в вашем кластере для максимальной скорости обработки. Он также предлагает распределенные реализации большого количества удобных для разработчиков интерфейсов Java, таких как Map, Queue, ExecutorService, Lock и JCache.
Функции безопасности включают в себя элементы кластера и проверку подлинности клиента и контроль доступа к клиентским операциям с помощью функций безопасности на основе JAAS. Он также позволяет перехватывать соединения сокетов и удалённые операции, выполняемые клиентами, шифрование связи на уровне сокетов между членами кластера и включение связи через сокеты SSL/TLS. Но согласно официальной документации, большинство этих функций безопасности предлагается в версии Enterprise.
Самый популярный вариант использования — распределенное кэширование в памяти и хранилище данных. Но его также можно развернуть для кластеризации веб-сеансов, замены NoSQL, параллельной обработки, простого обмена сообщениями и многого другого.
6. Mcrouter
Mcrouter — это бесплатный маршрутизатор протокола Memcached с открытым исходным кодом для масштабирования развёртываний Memcached, разработанный и поддерживаемый Facebook. Он включает в себя протокол Memcached ASCII, гибкую маршрутизацию, поддержку нескольких кластеров, многоуровневые кеши, пул соединений, несколько схем хеширования, маршрутизацию по префиксу, реплицированные пулы, теневое копирование производственного трафика, интерактивную реконфигурацию и мониторинг работоспособности/автоматическое переключение при отказе.
Кроме того, он поддерживает разогрев холодного кеша, расширенные команды статистики и отладки, надёжное качество обслуживания потока удаления, большие значения, широковещательные операции и поставляется с поддержкой IPv6 и SSL.
Он используется в Facebook и Instagram в качестве основного компонента инфраструктуры кеширования для обработки почти 5 миллиардов запросов в секунду на пике.
7. Varnish Cache
Varnish Cache — это гибкий, современный и многоцелевой ускоритель веб-приложений с открытым исходным кодом, который находится между веб-клиентами и исходным сервером. Он работает на всех современных платформах Linux, FreeBSD и Solaris (только x86). Это отличный механизм кэширования и ускоритель контента, который вы можете развернуть перед веб-сервером, таким как NGINX, Apache и многими другими, для прослушивания порта HTTP по умолчанию для получения и пересылки клиентских запросов на веб-сервер и доставки ответов сервера к клиенту.
Выступая в качестве посредника между клиентами и исходными серверами, Varnish Cache предлагает несколько преимуществ, в том числе кэширование веб-содержимого в памяти для уменьшения нагрузки на веб-сервер и повышения скорости доставки клиентам.
После получения HTTP-запроса от клиента он перенаправляет его на внутренний веб-сервер. Как только веб-сервер отвечает, Varnish кэширует содержимое в памяти и доставляет ответ клиенту. Когда клиент запрашивает тот же контент, Varnish будет обслуживать его отправив ответ из кэша, что значительно ускоряет ответ приложения. Если он не может обслуживать контент из кеша, запрос перенаправляется на серверную часть, а ответ кэшируется и доставляется клиенту.
Varnish включает VCL (язык конфигурации Varnish — гибкий предметно-ориентированный язык), используемый для настройки обработки запросов, и многое другое, модули Varnish (VMODS), которые являются расширениями для Varnish Cache.
С точки зрения безопасности Varnish Cache поддерживает ведение журнала, проверку запросов и регулирование, аутентификацию и авторизацию через VMODS, но в нём отсутствует встроенная поддержка SSL/TLS. Вы можете включить HTTPS для Varnish Cache, используя прокси SSL/TLS, например Hitch или NGINX.
Вы также можете использовать Varnish Cache в качестве брандмауэра веб-приложений, защитника от DDoS-атак, защитника хотлинкинга, балансировщика нагрузки, точки интеграции, шлюза единого входа, механизма политики аутентификации и авторизации, быстрого исправления нестабильных бэкендов и маршрутизатора HTTP-запросов.
8. Прокси-сервер для кеширования Squid
Ещё одно бесплатное, выдающееся и широко используемое решение для прокси и кеширования с открытым исходным кодом для Linux — это Squid. Это многофункциональное программное обеспечение для кэширования веб-прокси, которое предоставляет услуги прокси и кеширования для популярных сетевых протоколов, включая HTTP, HTTPS и FTP. Он также работает на других платформах UNIX и Windows.
Как и Varnish Cache, он получает запросы от клиентов и передаёт их указанным внутренним серверам. Когда внутренний сервер отвечает, он сохраняет копию содержимого в кеше и передаёт её клиенту. Будущие запросы того же контента будут обслуживаться из кеша, что приведёт к более быстрой доставке контента клиенту. Таким образом, он оптимизирует поток данных между клиентом и сервером для повышения производительности и кэширует часто используемый контент для уменьшения сетевого трафика и экономии полосы пропускания.
Squid поставляется с такими функциями, как распределение нагрузки по взаимосвязанным иерархиям прокси-серверов, создание данных, касающихся шаблонов использования Интернета (например, статистика о наиболее посещаемых сайтах), позволяет анализировать, захватывать, блокировать, заменять или изменять сообщения, передаваемые через прокси.
Он также поддерживает функции безопасности, такие как расширенный контроль доступа, авторизация и аутентификация, поддержка SSL/TLS и ведение журнала активности.
9. NGINX
NGINX (произносится как Engine-X) — это высокопроизводительное, полнофункциональное и очень популярное консолидированное решение с открытым исходным кодом для настройки веб-инфраструктуры. Это HTTP-сервер, обратный прокси-сервер, почтовый прокси-сервер и общий прокси-сервер TCP/UDP.
NGINX предлагает базовые возможности кэширования, когда кэшированный контент хранится в постоянном кэше на диске. Самое интересное в кэшировании контента в NGINX заключается в том, что его можно настроить для доставки устаревшего контента из своего кеша, когда он не может получить свежий контент с исходных серверов.
NGINX предлагает множество функций безопасности для защиты ваших веб-систем, включая завершение SSL, ограничение доступа с помощью базовой аутентификации HTTP, аутентификацию на основе результата подзапроса, аутентификацию JWT, ограничение доступа к проксируемым ресурсам HTTP, ограничение доступа по географическому положению, и многое другое.
Он обычно развёртывается как обратный прокси, балансировщик нагрузки, терминатор SSL/шлюз безопасности, ускоритель приложений/кеш контента и шлюз API в стеке приложений. Он также используется для потоковой передачи мультимедиа.
10. Apache Traffic Server
И последнее, но не менее важное: у нас есть Apache Traffic Server, быстрый, масштабируемый и расширяемый прокси-сервер с открытым исходным кодом, поддерживающий HTTP/1.1 и HTTP/2.0. Он разработан для повышения эффективности и производительности сети за счёт кэширования часто используемого контента на границе сети для предприятий, Интернет-провайдеров, магистральных провайдеров и т. д.
Он поддерживает как прямое, так и обратное проксирование трафика HTTP/HTTPS. Его также можно настроить для работы в одном или обоих режимах одновременно. Имеет постоянное кеширование, API плагины; поддержка ICP (Internet Cache Protocol), ESI (Edge Side Includes); Keep-ALive и многое другое.
С точки зрения безопасности Traffic Server поддерживает управление доступом клиентов, позволяя настраивать клиентов, которым разрешено использовать кеш прокси, завершение SSL для соединений между клиентами и самим собой, а также между ним и исходным сервером. Он также поддерживает аутентификацию и базовую авторизацию через плагин, ведение журнала (каждого полученного запроса и каждой обнаруженной ошибки) и мониторинг.
Apache Traffic Server может использоваться в качестве кеша веб-прокси, прямого прокси, обратного прокси, прозрачного прокси, балансировщика нагрузки или в иерархии кеша.
Заключительные замечания
Кэширование — одна из наиболее полезных и давно зарекомендовавших себя технологий доставки веб-контента, которая в первую очередь предназначена для увеличения скорости веб-сайтов или приложений. Это помогает снизить нагрузку на сервер, задержку и пропускную способность сети, поскольку клиентам отправляются кэшированные данные, что улучшает время отклика приложений и скорость доставки клиентам.
В этой статье мы рассмотрели лучшие инструменты кэширования с открытым исходным кодом для использования в системах Linux. Если вам известны другие инструменты кэширования с открытым исходным кодом, не перечисленные здесь, поделитесь с нами через форму обратной связи ниже. Вы также можете поделиться с нами своими мыслями об этой статье.
Источник



