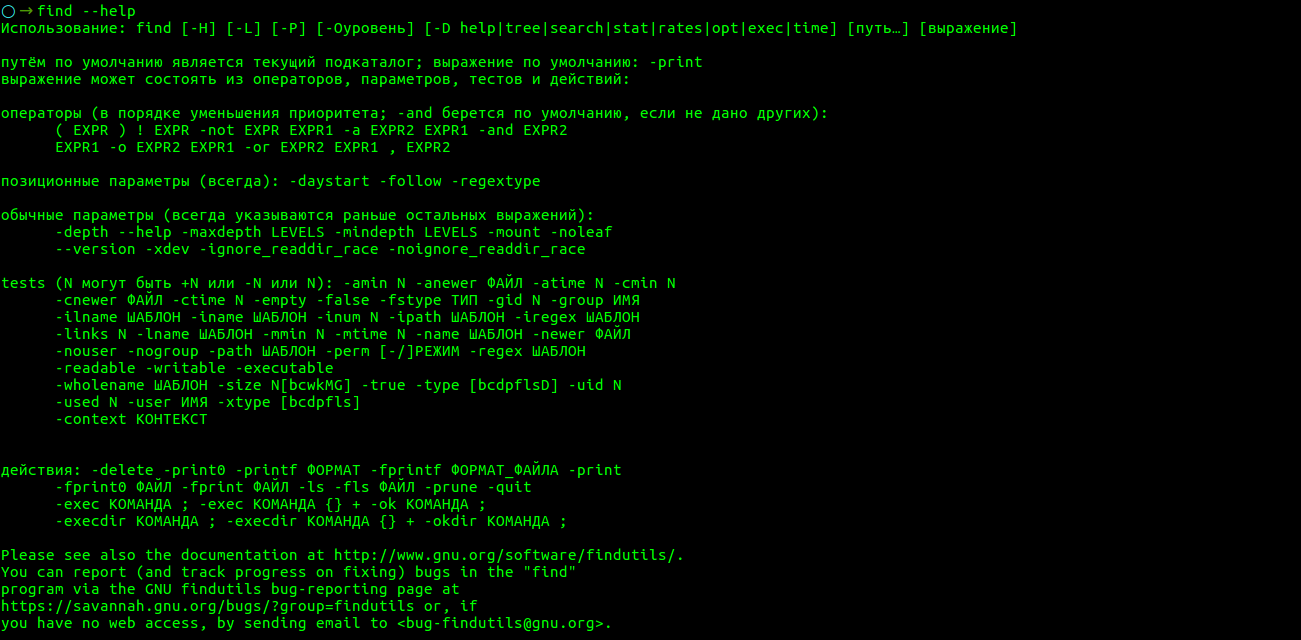
- Поиск в Linux с помощью команды find
- Общий синтаксис
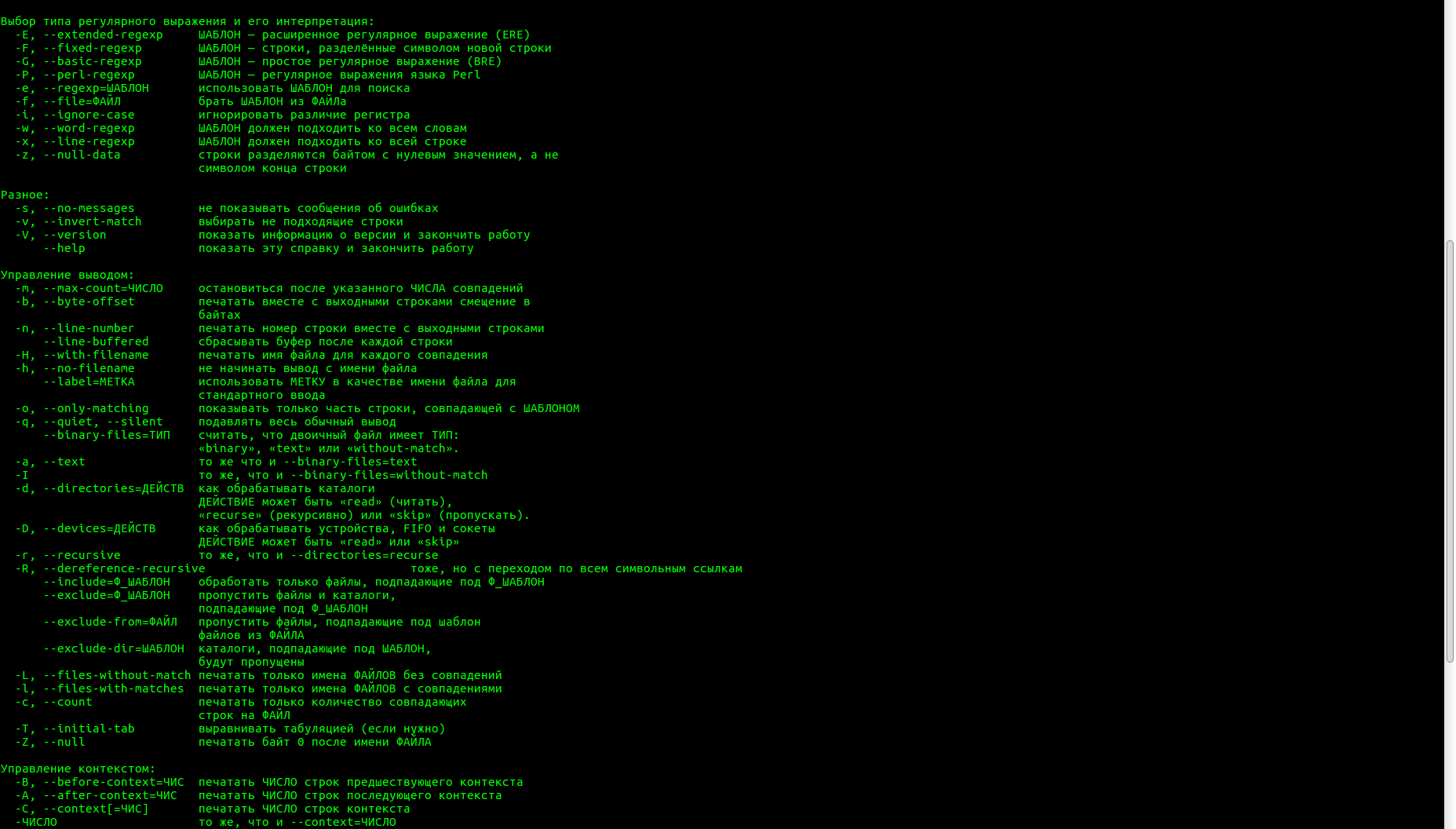
- Описание опций
- Примеры использования find
- Поиск файла по имени
- Поиск по дате
- По типу
- Поиск по правам доступа
- Поиск файла по содержимому
- С сортировкой по дате модификации
- Лимит на количество выводимых результатов
- Поиск с действием (exec)
- Чистка по расписанию
- 🧟♀️ Как найти определенное слово в файле в Linux
- Использование grep для поиска определенного слова в файле
- Использование find для поиска определенного слова в файле
- Использование ack для поиска определенного слова в файле
- Заключение
- Как найти все файлы, содержащие определённый текст (на Linux)
Поиск в Linux с помощью команды find
Утилита find представляет универсальный и функциональный способ для поиска в Linux. Данная статья является шпаргалкой с описанием и примерами ее использования.
Общий синтаксис
— путь к корневому каталогу, откуда начинать поиск. Например, find /home/user — искать в соответствующем каталоге. Для текущего каталога нужно использовать точку «.».
— набор правил, по которым выполнять поиск.
* по умолчанию, поиск рекурсивный. Для поиска в конкретном каталоге можно использовать опцию maxdepth.
Описание опций
| Опция | Описание |
|---|---|
| -name | Поиск по имени. |
| -iname | Регистронезависимый поиск по имени. |
| -type | |
| -size | Размер объекта. Задается в блоках по 512 байт или просто в байтах (с символом «c»). |
| -mtime | Время изменения файла. Указывается в днях. |
| -mmin | Время изменения в минутах. |
| -atime | Время последнего обращения к объекту в днях. |
| -amin | Время последнего обращения в минутах. |
| -ctime | Последнее изменение владельца или прав на объект в днях. |
| -cmin | Последнее изменение владельца или прав в минутах. |
| -user | Поиск по владельцу. |
| -group | По группе. |
| -perm | С определенными правами доступа. |
| -depth | Поиск должен начаться не с корня, а с самого глубоко вложенного каталога. |
| -maxdepth | Максимальная глубина поиска по каталогам. -maxdepth 0 — поиск только в текущем каталоге. По умолчанию, поиск рекурсивный. |
| -prune | Исключение перечисленных каталогов. |
| -mount | Не переходить в другие файловые системы. |
| -regex | По имени с регулярным выражением. |
| -regextype | Тип регулярного выражения. |
| -L или -follow | Показывает содержимое символьных ссылок (симлинк). |
| -empty | Искать пустые каталоги. |
| -delete | Удалить найденное. |
| -ls | Вывод как ls -dgils |
| Показать найденное. | |
| -print0 | Путь к найденным объектам. |
| -exec <> \; | Выполнить команду над найденным. |
| -ok | Выдать запрос перед выполнением -exec. |
Также доступны логические операторы:
| Оператор | Описание |
|---|---|
| -a | Логическое И. Объединяем несколько критериев поиска. |
| -o | Логическое ИЛИ. Позволяем команде find выполнить поиск на основе одного из критериев поиска. |
| -not или ! | Логическое НЕ. Инвертирует критерий поиска. |
Полный набор актуальных опций можно получить командой man find.
Примеры использования find
Поиск файла по имени
1. Простой поиск по имени:
find / -name «file.txt»
* в данном примере будет выполнен поиск файла с именем file.txt по всей файловой системе, начинающейся с корня /.
2. Поиск файла по части имени:
* данной командой будет выполнен поиск всех папок или файлов в корневой директории /, заканчивающихся на .tmp
3. Несколько условий.
а) Логическое И. Например, файлы, которые начинаются на sess_ и заканчиваются на cd:
find . -name «sess_*» -a -name «*cd»
б) Логическое ИЛИ. Например, файлы, которые начинаются на sess_ или заканчиваются на cd:
find . -name «sess_*» -o -name «*cd»
в) Более компактный вид имеют регулярные выражения, например:
find . -regex ‘.*/\(sess_.*cd\)’
* где в первом поиске применяется выражение, аналогичное примеру а), а во втором — б).
4. Найти все файлы, кроме .log:
find . ! -name «*.log»
* в данном примере мы воспользовались логическим оператором !.
Поиск по дате
1. Поиск файлов, которые менялись определенное количество дней назад:
find . -type f -mtime +60
* данная команда найдет файлы, которые менялись более 60 дней назад.
2. Поиск файлов с помощью newer. Данная опция доступна с версии 4.3.3 (посмотреть можно командой find —version).
а) дате изменения:
find . -type f -newermt «2019-11-02 00:00»
* покажет все файлы, которые менялись, начиная с 02.11.2019 00:00.
find . -type f -newermt 2019-10-31 ! -newermt 2019-11-02
* найдет все файлы, которые менялись в промежутке между 31.10.2019 и 01.11.2019 (включительно).
б) дате обращения:
find . -type f -newerat 2019-10-08
* все файлы, к которым обращались с 08.10.2019.
find . -type f -newerat 2019-10-01 ! -newerat 2019-11-01
* все файлы, к которым обращались в октябре.
в) дате создания:
find . -type f -newerct 2019-09-07
* все файлы, созданные с 07 сентября 2019 года.
find . -type f -newerct 2019-09-07 ! -newerct «2019-09-09 07:50:00»
* файлы, созданные с 07.09.2019 00:00:00 по 09.09.2019 07:50
По типу
Искать в текущей директории и всех ее подпапках только файлы:
* f — искать только файлы.
Поиск по правам доступа
1. Ищем все справами на чтение и запись:
find / -perm 0666
2. Находим файлы, доступ к которым имеет только владелец:
find / -perm 0600
Поиск файла по содержимому
find / -type f -exec grep -i -H «content» <> \;
* в данном примере выполнен рекурсивный поиск всех файлов в директории / и выведен список тех, в которых содержится строка content.
С сортировкой по дате модификации
find /data -type f -printf ‘%TY-%Tm-%Td %TT %p\n’ | sort -r
* команда найдет все файлы в каталоге /data, добавит к имени дату модификации и отсортирует данные по имени. В итоге получаем, что файлы будут идти в порядке их изменения.
Лимит на количество выводимых результатов
Самый распространенный пример — вывести один файл, который последний раз был модифицирован. Берем пример с сортировкой и добавляем следующее:
find /data -type f -printf ‘%TY-%Tm-%Td %TT %p\n’ | sort -r | head -n 1
Поиск с действием (exec)
1. Найти только файлы, которые начинаются на sess_ и удалить их:
find . -name «sess_*» -type f -print -exec rm <> \;
* -print использовать не обязательно, но он покажет все, что будет удаляться, поэтому данную опцию удобно использовать, когда команда выполняется вручную.
2. Переименовать найденные файлы:
find . -name «sess_*» -type f -exec mv <> new_name \;
find . -name «sess_*» -type f | xargs -I ‘<>‘ mv <> new_name
3. Вывести на экран количество найденных файлов и папок, которые заканчиваются на .tmp:
find . -name «*.tmp» | wc -l
4. Изменить права:
find /home/user/* -type d -exec chmod 2700 <> \;
* в данном примере мы ищем все каталоги (type d) в директории /home/user и ставим для них права 2700.
5. Передать найденные файлы конвееру (pipe):
find /etc -name ‘*.conf’ -follow -type f -exec cat <> \; | grep ‘test’
* в данном примере мы использовали find для поиска строки test в файлах, которые находятся в каталоге /etc, и название которых заканчивается на .conf. Для этого мы передали список найденных файлов команде grep, которая уже и выполнила поиск по содержимому данных файлов.
6. Произвести замену в файлах с помощью команды sed:
find /opt/project -type f -exec sed -i -e «s/test/production/g» <> \;
* находим все файлы в каталоге /opt/project и меняем их содержимое с test на production.
Чистка по расписанию
Команду find удобно использовать для автоматического удаления устаревших файлов.
Открываем на редактирование задания cron:
0 0 * * * /bin/find /tmp -mtime +14 -exec rm <> \;
* в данном примере мы удаляем все файлы и папки из каталога /tmp, которые старше 14 дней. Задание запускается каждый день в 00:00.
* полный путь к исполняемому файлу find смотрим командой which find — в разных UNIX системах он может располагаться в разных местах.
Источник
🧟♀️ Как найти определенное слово в файле в Linux

По умолчанию большинство инструментов поиска смотрят имена файлов, а не их содержимое.
Тем не менее, самая известная программа поиска GNU, grep, будет искать файлы с правильными флагами.
Здесь мы покажем вам, как вы можете найти конкретные слова в файле в Linux.
Использование grep для поиска определенного слова в файле
По умолчанию grep просматривает содержимое файлов, а также их имена.
Он включен в большинство систем Linux и в целом одинаков для всех дистрибутивов.
Тем не менее, небольшие или менее мощные Linux-боксы могут предпочесть выполнить другую команду, например, ack.
В зависимости от того, как файл закодирован, grep не всегда может заглянуть внутрь.
Но для большинства текстовых форматов grep может сканировать текст файла по указанному шаблону.
Флаг -R устанавливает grep в рекурсивный режим, перемещаясь по всем каталогам, содержащимся в указанном каталоге.
Флаг -w ищет совпадения всего слова.
Это означает, что «red» будет соответствовать только «red», окруженному пробельными символами, а не «redundant» или «tired».
Флаг -e предшествует шаблону для поиска.
Он поддерживает регулярные выражения по умолчанию.
Чтобы ускорить grep, вы можете использовать флаги –exclude и –include, чтобы ограничить поиск определенными типами файлов.
Например, –exclude = *. Csv не будет искать в файлах с расширением .csv. –include = *. txt, с другой стороны, будет выполнять поиск только в файлах с расширением .txt.
Флаг можно добавить сразу после команды grep, как показано ниже:
Вы также можете исключить указанные каталоги, следуя приведенному ниже формату:
Эта команда не будет выполнять поиск в каких-либо каталогах в текущем рабочем каталоге с именами dir1, dir2 или с шаблоном * _old, исключая их из процесса поиска.
Он выполнит указанный рекурсивный поиск по полному слову во всех других файлах в текущем рабочем каталоге.
Использование find для поиска определенного слова в файле
Хотя синтаксис команды find является более сложным, чем grep, некоторые предпочитают его.
Эта команда будет использовать флаг find -exec для передачи найденных файлов в grep для поиска.
Благодаря продуманному синтаксису вы можете использовать более быстрый поиск в файловой системе c find, чтобы найти конкретные типы файлов, в которых вы хотите искать, и затем направить их в grep для поиска внутри файлов.
Обратите внимание, что команда find ищет только имена файлов, а не их содержимое.
Вот почему grep требуется для поиска текста и содержимого файла.
Обычные флаги grep должны быть полностью работоспособны в пределах флага -exec.
Использование ack для поиска определенного слова в файле
Команда ack, вероятно, является самым быстрым инструментом поиска, но она не так популярна, как описанные выше опции.
Команда, показанные ниже будет искать в текущем каталоге.
Если вы хотите выполнить поиск в определенном файле или каталоге, вы можете добавить этот файл или полный путь к вашему поиску.
Заключение
Для большинства людей в большинстве ситуаций, grep – лучший широко доступный инструмент поиска.
Вы также можете посмотреть другие инструменты поиска, такие как RipGrep, для более быстрого поиска.
Источник
Как найти все файлы, содержащие определённый текст (на Linux)
Иногда бывают ситуации, когда нужно просканировать всю файловую систему Linux и найти все файлы, содержащие определённую строку текста. То есть нужно выполнить поиск не по имени файла, а по содержимому текстового файла.
Пример таких ситуаций из практики:
- конфигурация веб-сервера Apache разбита на множество файлов, и нужно найти файл, который устанавливает определённый HTTP заголовок (найти файл, содержащий текст заголовка)
- имеются большое количество отчётов и среди них нужно найти только те, которые содержат определённое слово или фразу
Пример — поиск заголовка Strict-Transport-Security в директории конфигурационных файлов веб-сервера:

Одним из лучших вариантов поиска всех файлов, содержащих заданный текст, является команда:
В этой команде используются следующие опции:
-r (также можно использовать -R) для рекурсивного поиска — то есть поиск будет выполнен в папке и подпапках. Опция -R делает так, что программа следует по символическим ссылкам, если натыкается на них, соответственно, с опцией -r этого не происходит. Но поиск является рекурсивным в обоих случаях
-n означает выводить номера строку (чтобы быстрее найти в них нужное место)
-w используется для поиска по полным словам. При использовании опции -w будут выбраны только строки, которые содержат совпадения целых слов. То есть для того, чтобы совпадение засчиталось, совпавшая подстрока быть либо вначале строки, либо перед ней должен идти несловесный составной символ. Аналогично она должна быть либо в конце строки, либо за ней должен следовать несловесный составной символ. Словесными составными символами являются буквы, цифры и подчёркивание. Соответственно, несловесными являются все остальные: пробелы, знаки препинания, дефисы и прочее.
Эти опции являются оптимальными, но, на самом деле, для поиска по всей директории вместе с вложенными поддиректориями, либо по всей файловой системе, достаточно использовать только опцию -r, а остальные можно пропустить.
Рассмотрим ещё несколько опций, которые могут оказаться весьма полезными:
-i для игнорирования регистра букв (по умолчанию ищутся буквы в точно таком же регистре, как и в шаблоне). Но обратите внимание, что эта опция очень сильно замедляет скорость поиска.
-l (маленькая L) подавляет нормальный вывод; вместо него выводится имя каждого файла, в котором найдено совпадение. То есть по умолчанию выводиться совпавшая строка, а с этой опцией будут выводиться только имена файлов, в которых найдена строка. Сканирование будет остановлено после первого совпадения.
—color[=КОГДА], —colour[=КОГДА] — используется для подсветки в терминале совпавшей подстроки, контекстных строк, имён файлов, номеров строк, байтового смещения и разделителей (для полей и групп контестных строк). КОГДА можно указывать или не указывать по жоеланию. В качестве КОГДА может быть never (никогда), always (всегда) или auto (автоматически).
-I — пропускать бинарные файлы. При рекурсивной обработке могут попадаться не текстовые файлы, натыкаясь на которые grep будет показывать предупреждения. Эта опция делает обработку бинарных файлов такой, как если бы они не содержали совпадающих данных.
В качестве шаблона grep используются регулярные выражения — они являются крайне мощным инструментом для поиска строк. Тем не менее, если вы не умеете пользоваться регулярными выражениями, то вы можете получить не те результаты, которых ожидаете, поскольку некоторые символы в регулярных выражениях имеют специальное значение. По этой причине рекомендуется ознакомиться с большой понятной инструкцией «Регулярные выражения и команда grep».
Ещё один вариант — использовать опцию -F. Она будет интерпретировать ШАБЛОНЫ как фиксированные строки, а не как регулярные выражения. С одной стороны, команда grep потеряет часть своей гибкости, но при этом вы получите более предсказуемый результат, если вы не понимаете регулярные выражения.
В зависимости от обстоятельств, можно использовать для повышения эффективности поиска следующие флаги:
—exclude=GLOB — означает пропустить файлы, с именем суффикса, которое совпадёт с шаблоном GLOB. Имя суффикса это как полное имя, так и любой суффикс, начинающийся после / и перед не-/ (то есть между слэшей в пути имени файла). При рекурсивном поиске, пропускаются все подфайлы, чьё базовое имя совпадает с GLOB. Базовое имя — это часть после последнего слэша (/). Шаблон GLOB поддерживает несколько подстановочных символов. Шаблон (GLOB) может использовать в качестве подстановочных символов * (означает последовательность нуля или более символов), ? (означает ровно один символ), и [СИМВОЛЫ] (означает любой один из СИМВОЛОВ), (означает любой из символов), а также \ для экранирования подстановочных символов или символа обратного слэша, чтобы они начали восприниматься буквально.
—include=GLOB — искать только файлы, чьё базовое имя совпадает с GLOB (можно использовать подстановочные символы, как описано чуть выше)
—exclude-dir=GLOB — пропустить директории с суффиксом имени, которые совпадает с шаблоном GLOB. При рекурсивном поиски, пропуск любых поддиректорий, чьё базовое имя совпадает с GLOB. Любые избыточные конечные слэши в GLOB игнорируются.
Чтобы было понятнее, рассмотрим примеры. Допустим мы хотим выполнить поиск только по файлам с расширениями .c или .h:
В этой команде * (звёздочка) означает любое имя файла. Но эта звёздочка экранирована, поскольку для терминала она также имеет особое значение. В этом имене должна идти точка и буква c или h.
Следующий поиск исключит из результатов все файлы, которые заканчиваются на расширение .o:
Для директорий возможно исключить конкретную директорию(ии) через параметр —exclude-dir. Например, следующая команда исключит dirs dir1/, dir2/ и все другие директории соответствующие *.dst/:
Источник



