- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Руководство по команде grep в Linux
- Про Linux за 5 минут | Что это или как финский студент перевернул мир?
- Для чего мы пользуемся grep-ом?
- Поиск строк
- Поиск по нескольким параметрам
- Разница между grep, egrep fgrep, pgrep, zgrep
- Разница между find и grep
- Рекурсивный поиск
- Найти пробелы и табуляцию
- Использование регулярных выражений
- Команда Grep в Linux (поиск текста в файлах)
- Командный синтаксис grep
- Искать строку в файлах
- Инвертировать соответствие (исключить)
- Использование Grep для фильтрации вывода команды
- Рекурсивный поиск
- Показать только имя файла
- Поиск без учета регистра
- Искать полные слова
- Показать номера строк
- Подсчет совпадений
- Бесшумный режим
- Основное регулярное выражение
- Расширенные регулярные выражения
- Поиск нескольких строк (шаблонов)
- Строки печати перед матчем
- Печатать строки после матча
- Выводы
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Руководство по команде grep в Linux
Читать между строк
10 минут чтения
То, что система Linux предоставляет пользователю большое многообразие разного функционала уже не секрет. На одном из прошлых материалов мы рассмотрели, как и где можно использовать команду find. В этой же статье мы на примерах разберём команду grep, мощный инструмент системных администраторов.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена

Про Linux за 5 минут | Что это или как финский студент перевернул мир?

Для чего мы пользуемся grep-ом?
Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле. Также можно передать вывод любой команды в grep, что сильно упрощает работу во время поиска и траблшутинга.
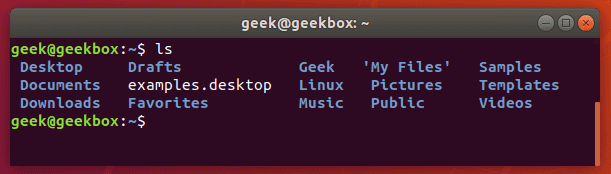
Возьмём команду ls. Сама по себе она выводит список всех файлов и папок.
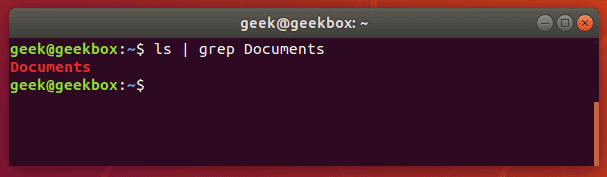
Но если нужно найти конкретную папку или один файл среди сотни других, то мы можем передать вывод команды ls в grep через вертикальную черту (|), а уже grep-у параметром передать нужное слово.
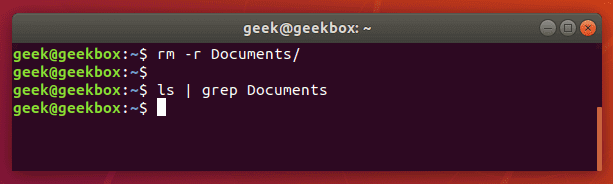
Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории.
Поиск строк
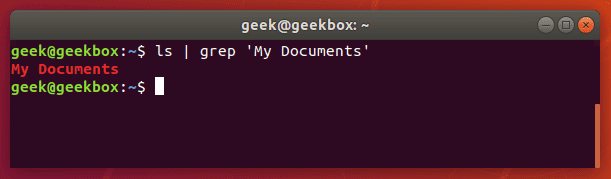
Если же нужно найти не одно слово, а словосочетание или целое предложение, то параметр команды grep должно быть выделено кавычками. Grep поддерживает как одинарные, так и двойные кавычки.
Несмотря на то, что команда grep чаще используется как своего рода фильтр для других команд, но её также можно использовать отдельно как на примере ниже.
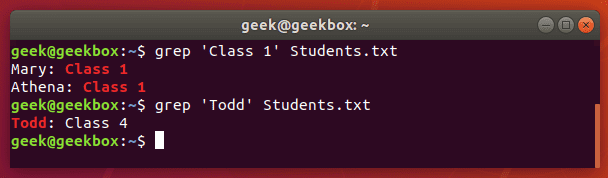
В этом примере мы вели поиск указанных в кавычках слов в файле Students.txt и команда grep успешно справилась со своей задачей.
Поиск по нескольким параметрам
Команде grep можно передавать не один параметр, а несколько. Для этого перед каждым аргументом пишется ключ e. Эту команду система понимает, как «или-или» и выводит все вхождения указанных слов. Заметьте, что кавычками выделена только строка, которая содержит пробел.

Разница между grep, egrep fgrep, pgrep, zgrep
Исторически разные версии Linux-а включали разновидности команды grep. Хотя в современных версия систем базовая команда grep поддерживает все возможности, которыми обладают egrep fgrep, pgrep, zgrep, но все же их тоже стоит рассмотреть.
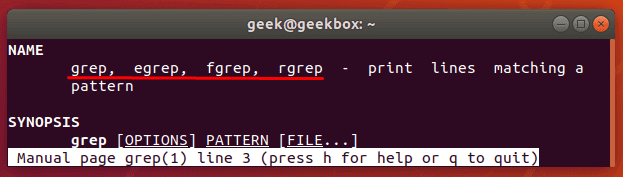
Как видно из вывода man grep (мануал по команде grep), все эти версии всего лишь разные названия основной команды. Например, egrep это тоже самое, что и grep E (помните, командная строка Linux регистрозависимая и команды grep e и grep E интерпретируются по разному). Этой команде в качестве шаблона передается расширенное регулярное выражение. Существует очень много разных ситуаций, где можно воспользоваться этой командой. Например, две команды ниже эквивалентны и выводят все строки, в которых есть две подряд идущих буквы «p».
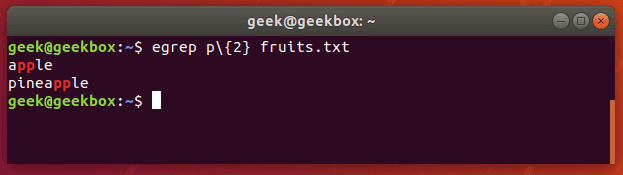
Fgrep это команда grep F, которая обрабатывает переданный шаблон как список фиксированных данных строкового типа. Эта команда полезна, когда в шаблоне используются зарезервированные для регулярных выражений символы, которые при обычно grep пришлось бы экранировать.
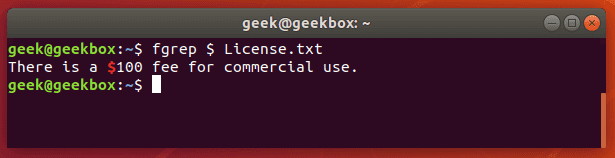
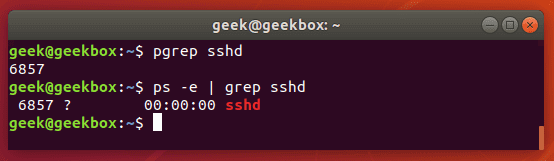
Команда pgrep используется для поиска конкретного процесса, запущенного в системе и возвращает идентификатор указанного процесса (PID). Команда ниже выводит PID процесса sshd. Почти такого же результата можно достичь если запустить команду ps e | grep sshd.
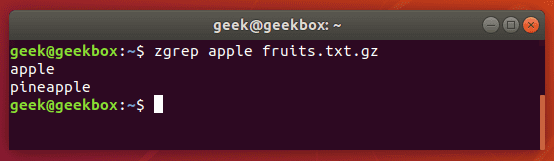
Команда zgrep используется для поиска указанного шаблона в заархивированных файлах, что очень удобно так как не приходится сначала разархивировать файл, а потом уже вести поиск.
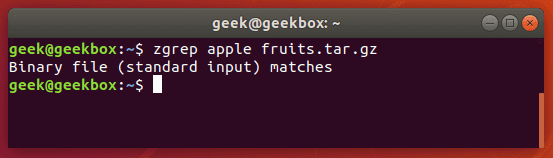
Zgrep также работает с tar архивами, но ограничивается лишь выводом информации о том, нашла ли она соответствие или нет. Это замечание мы сделали потому, что чаще всего gzip-ом архивируются tar файлы.
Разница между find и grep
Те, кто только начинает пользоваться командной строкой Linux должны понимать, что find и grep это две разные команды, которые имеют совсем разные функции, даже если оба используются для «поиска» чего-либо.
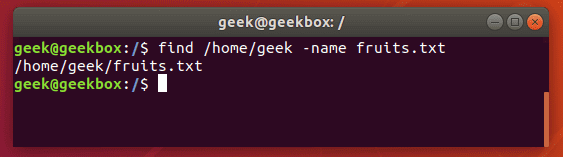
При поиске файлов grep-ом удобно пользоваться для фильтрации вывода команды find, как и было показано в начале материала. Но если нужно найти какой-то файл в системе по его названию или части названия (при этом используется маска *), то лучше всего обратиться к find. Она выведёт точно расположение искомого файла.
Рекурсивный поиск
Чтобы вести поиск по указанному шаблону среди всех файлов во всех папках и подпапках, команду grep нужно запустить с ключом r. Команда выведет все файлы, где найдено совпадение с указанным шаблоном, а также путь к ним. По умолчанию поиск ведется по текущей директории и поддиректориях.

Найти пробелы и табуляцию
Как и было отмечено ранее, если в шаблоне поиска содержится пробел, то мы должны выделять строку кавычками. Это мы можем использовать для поиска пробелов и знаков табуляции в файле. О том как вставить табуляцию чуть позже.

Есть несколько путей вставки табуляции, но некоторые дистрибутивы могут не поддерживать их. Как известно, в командной строке Linux клавиша TAB сама по себе дополняет введённую команду. Но если комбинировать клавиши ctrl+v, а затем нажать TAB, то система воспримет это как знак табуляции. $ grep » » sample.txt
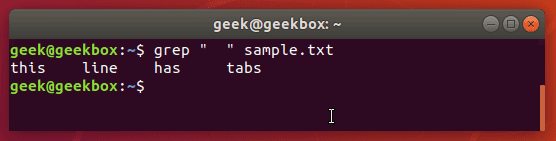
Эта фишка очень помогает при поиске среди конфигурационных файлов системы, так как значения от параметров отделяются табуляцией.
Использование регулярных выражений
Регулярные выражения сильно расширяют возможности команды grep, что позволяет нам вести более гибкий поиск. Далее мы рассмотрим несколько вариантов использования регулярных выражений.
[квадратные скобки] они используются чтобы проверить на соответствие одному из указанных символов.
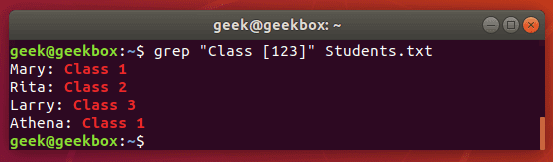
[-] знак дефиса означает диапазон значений. Это могут быть как буквы, так и цифры.
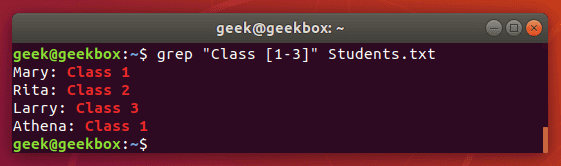
Вторая команда вывела то же, что и первая, но здесь мы обошлись знаком диапазона.
^ каретка используется для поиска строк, которые начинаются с указанного шаблона. Команда ниже выведет все строки, которые начинаются с буквы «А».
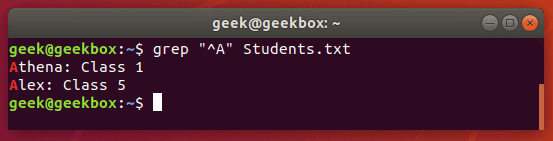
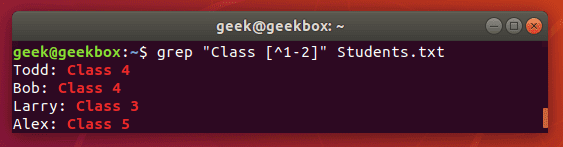
[^] но между квадратными скобками смысл каретки меняется. Здесь он исключает из поиска следующие за ней символы или диапазон символов.
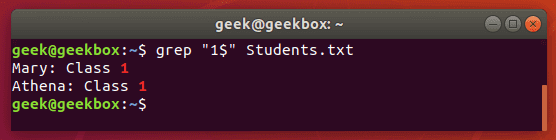
$ знак доллара означает конец строки. Команда выведет только те строки, в конце которых встречает указанный шаблон.
.точка обозначает один любой символ. Чтобы указать несколько любых символов, можно написать символ точку нужное количество раз.
Источник
Команда Grep в Linux (поиск текста в файлах)
Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
В этой статье мы покажем вам, как использовать команду grep на практических примерах и подробных объяснениях наиболее распространенных опций GNU grep .
Командный синтаксис grep
Синтаксис команды grep следующий:
Пункты в квадратных скобках необязательны.
- OPTIONS — Ноль или более вариантов. Grep включает ряд опций , управляющих его поведением.
- PATTERN — Шаблон поиска.
- FILE — Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из файла /etc/passwd , вы должны выполнить следующую команду:
Результат должен выглядеть примерно так:
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
Инвертировать соответствие (исключить)
Чтобы отобразить строки, не соответствующие шаблону, используйте параметр -v (или —invert-match ).
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
Вы также можете объединить несколько каналов по команде. Как вы можете видеть в выходных данных выше, также есть строка, содержащая процесс grep . Если вы не хотите, чтобы эта строка отображалась, передайте результат другому экземпляру grep как показано ниже.
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите grep с параметром -r (или —recursive ). Когда используется этот параметр, grep будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы следовать по всем символическим ссылкам , вместо -r используйте параметр -R (или —dereference-recursive ).
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете опцию -R , grep будет следовать по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается с -r потому что файлы внутри каталога с sites-enabled Nginx являются символическими ссылками на файлы конфигурации внутри каталога с sites-available .
Показать только имя файла
Чтобы подавить вывод grep по умолчанию и вывести только имена файлов, содержащих совпадающий шаблон, используйте параметр -l (или —files-with-matches ).
Приведенная ниже команда выполняет поиск по всем файлам, заканчивающимся на .conf в текущем рабочем каталоге и выводит только имена файлов, содержащих строку linuxize.com :
Результат будет выглядеть примерно так:
Параметр -l обычно используется в сочетании с рекурсивным параметром -R :
Поиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep с параметром -i (или —ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
Но если вы выполните поиск без учета регистра с использованием параметра -i , он будет соответствовать как заглавным, так и строчным буквам:
Указание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или —word-regexp ).
Если вы запустите ту же команду, что и выше, включая параметр -w , команда grep вернет только те строки, где gnu включен как отдельное слово.
Показать номера строк
Параметр -n (или —line-number ) указывает grep показывать номер строки, содержащей строку, соответствующую шаблону. Когда используется эта опция, grep выводит совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
Результат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Подсчет совпадений
Чтобы вывести количество совпадающих строк в стандартный вывод, используйте параметр -c (или —count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, в которых в качестве оболочки используется /usr/bin/zsh .
Бесшумный режим
-q (или —quiet ) указывает grep работать в тихом режиме, чтобы ничего не отображать на стандартном выводе. Если совпадение найдено, команда завершает работу со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (каретка) для сопоставления выражения в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Используйте символ $ (доллар), чтобы найти выражение в конце строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом конце строки.
Используйте расширение . (точка) символ, соответствующий любому одиночному символу. Например, чтобы сопоставить все, что начинается с kan затем имеет два символа и заканчивается строкой roo , вы можете использовать следующий шаблон:
Используйте [ ] (скобки) для соответствия любому одиночному символу, заключенному в квадратные скобки. Например, найдите строки, содержащие accept или « accent , вы можете использовать следующий шаблон:
Используйте [^ ] для соответствия любому одиночному символу, не заключенному в квадратные скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a , например coca , cobalt и т. Д., Но не будет соответствовать строкам, содержащим cola ,
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или —extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Вот несколько примеров:
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
Параметр -o используется для печати только соответствующей строки.
Поиск нескольких строк (шаблонов)
Два или более шаблонов поиска можно объединить с помощью оператора ИЛИ | .
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
Если вы используете опцию расширенного регулярного выражения -E , то оператор | не следует экранировать, как показано ниже:
Строки печати перед матчем
Чтобы напечатать определенное количество строк перед совпадающими строками, используйте параметр -B (или —before-context ).
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
Печатать строки после матча
Чтобы напечатать определенное количество строк после совпадающих строк, используйте параметр -A (или —after-context ).
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
Выводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Подробнее о Grep можно узнать на странице руководства пользователя Grep .
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Источник



