- Как найти несколько строк и шаблонов с помощью Grep
- Grep несколько шаблонов
- Grep несколько строк
- Выводы
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- 16 полезных примеров grep
- Синтаксис grep
- 1. Поиск среди нескольких файлов
- 2. Регистронезависимый поиск
- 3. Поиск слова
- 4. Вывод количества совпадений
- 5. Поиск в поддиректориях
- 6. Инверсивный поиск
- 7. Вывод нумерации строк
- 8. Ограничение вывода
- 9. Вывод дополнительных строк
- 10. Вывод списка файлов
- 11. Вывод абсолютных совпадений
- 12. Поиск совпадения в начале строки
- 13. Поиск совпадения в конце строки
- 14. Использования файла шаблонов
- 15. Поиск по нескольким шаблонам
- 16. Указание расширенных регулярных выражений
- Заключение
- Поиск текста в файлах Linux
- Что такое grep?
- Синтаксис grep
- Опции
- Примеры использования
- Поиск текста в файлах
- Вывести несколько строк
- Регулярные выражения в grep
- Рекурсивное использование grep
- Поиск слов в grep
- Поиск двух слов
- Количество вхождений строки
- Инвертированный поиск в grep
- Вывод имени файла
- Цветной вывод в grep
- Выводы
Как найти несколько строк и шаблонов с помощью Grep
grep — это мощный инструмент командной строки, который позволяет вам искать в одном или нескольких входных файлах строки, соответствующие регулярному выражению, и записывать каждую совпадающую строку в стандартный вывод.
В этой статье мы покажем вам, как использовать GNU grep для поиска нескольких строк или шаблонов.
Grep несколько шаблонов
GNU grep поддерживает три синтаксиса регулярных выражений: базовый, расширенный и Perl-совместимый. Если тип регулярного выражения не указан, grep интерпретирует шаблоны поиска как базовые регулярные выражения.
Для поиска нескольких шаблонов используйте оператор OR (чередование).
Оператор чередования | (pipe) позволяет вам указать различные возможные совпадения, которые могут быть буквальными строками или наборами выражений. Этот оператор имеет самый низкий приоритет среди всех операторов регулярных выражений.
Синтаксис поиска нескольких шаблонов с использованием базовых регулярных выражений grep следующий:
Всегда заключайте регулярное выражение в одинарные кавычки, чтобы избежать интерпретации и расширения метасимволов оболочкой.
При использовании основных регулярных выражений метасимволы интерпретируются как буквальные символы. Чтобы сохранить особые значения метасимволов, они должны быть экранированы обратной косой чертой ( ). Вот почему мы избегаем оператора ИЛИ ( | ) косой чертой.
Чтобы интерпретировать шаблон как расширенное регулярное выражение, вызовите grep с параметром -E (или —extended-regexp ). При использовании расширенного регулярного выражения не избегайте символа | оператор:
Для получения дополнительной информации о том, как создавать регулярные выражения, ознакомьтесь с нашей статьей Grep regex .
Grep несколько строк
Буквальные строки — это самые простые шаблоны.
В следующем примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
Если искомая строка содержит пробелы, заключите ее в двойные кавычки.
Вот тот же пример с использованием расширенного регулярного выражения, которое избавляет от необходимости экранировать оператор |
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep with параметром -i (или —ignore-case ):
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера. Поэтому, если вы искали «error», grep также напечатает строки, где «error» встроено в слова большего размера, например, «errorless» или «antiterrorists».
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или —word-regexp ):
Символы слова включают буквенно-цифровые символы (az, AZ и 0–9) и символы подчеркивания (_). Все остальные символы считаются несловесными символами.
Чтобы узнать больше о параметрах grep , посетите нашу статью Команда Grep .
Выводы
Мы показали вам, как использовать grep для поиска нескольких шаблонов, строк и слов.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
16 полезных примеров grep
Полезно про grep
Изначально разработанный для Unix-систем grep, является одной из наиболее широко используемых утилит командной строки в среде Linux.
grep расшифровывается как «глобальный поиск строк, соответствующих регулярному выражению и их вывод» (globally search for a regular expression and print matching lines). grep в основном ищет на основе указанного посредством стандартного ввода или файла шаблона, или регулярного выражения и печатает строки, соответствующие заданным критериям. Часто используется для фильтрации ненужных деталей при печати только необходимой информации из больших файлов журнала.
Это возможно благодаря совместной работе регулярных выражений и поддерживаемых grep параметров.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Здесь мы рассмотрим некоторые из часто используемых сисадминами или разработчиками команд grep в различных сценариях.
Синтаксис grep
Команда grep принимает шаблон и необязательные аргументы вместе со перечислять файлов, если используется без трубопровода.
1. Поиск среди нескольких файлов
grep позволяет выполнять поиск заданного шаблона не только в одном, но и среди нескольких файлах. Для этого можно использовать подстановочный символ * .
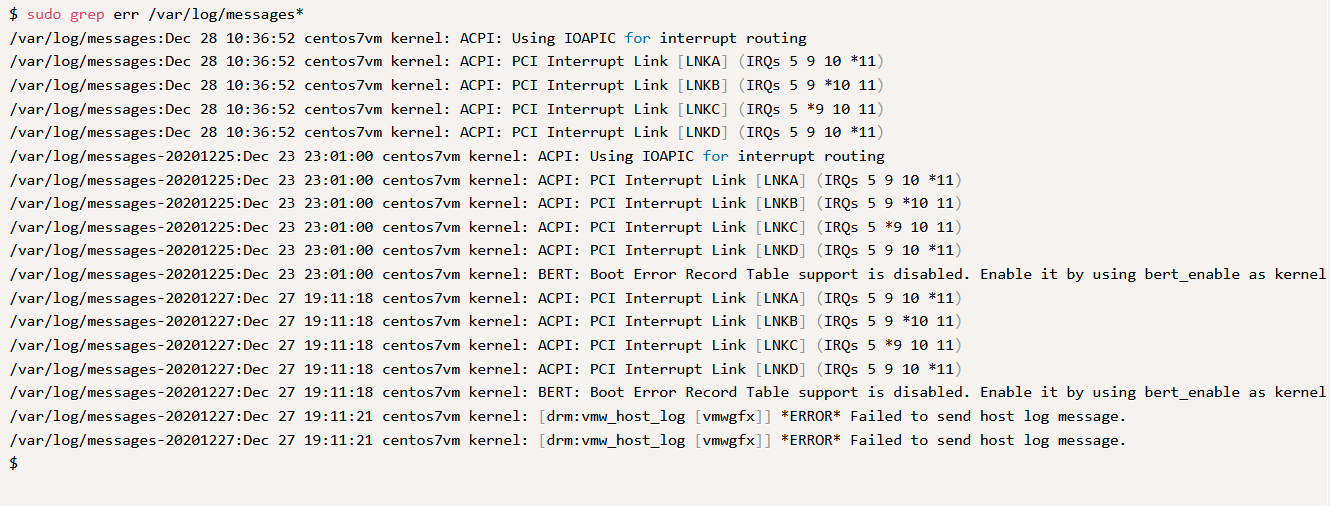
Как видно из вывода, утилита перед результатом искомого шаблона выводит также название файла, что позволяет определить где именно было найдено совпадение.
2. Регистронезависимый поиск
grep позволяет искать шаблон без учета регистра. Чтобы указать grep игнорировать регистр используется флаг –i .

3. Поиск слова
Иногда появляется необходимость поиска не части, а целого слова. В таких случаях утилита запускается с флагом -w .

4. Вывод количества совпадений
Не всегда нужно выводить результат совпадения. Иногда достаточно только количества совпадений с заданным шаблоном. Эту информацию мы можем получить с помощью параметра -c .

5. Поиск в поддиректориях
Часто необходимо искать файлы не только в текущей директории, но и в подкаталогах. grep позволяет легко сделать это с флагом -r .

6. Инверсивный поиск
Если вы хотите найти что-то, что не соответствует заданному шаблону, grep позволяет сделать только это с флагом -v .

Можно сравнить выходные резултаты grep для одного и того же шаблона и файла с флагом -v и без него. С параметром -v выводятся любые строки, которые не соответствуют образцу.
7. Вывод нумерации строк
grep позволяет нумеровать совпавшие строки, что позволяет легко определить, где строка находится в файле. Чтобы получить номера строк в выходных данных. используйте параметр –n :

8. Ограничение вывода
Результат вывода grep для файлов вроде журналов событий и т.д. может быть длинным, и вам может просто понадобиться фиксированное количество строк. Мы можем использовать -m [num] , чтобы ограничить выводимые строки.
Обратите внимание, как использование флага -m влияет на вывод grep для одного и того же набора условий в примере ниже:

9. Вывод дополнительных строк
Часто нам нужны не только строки, которые совпали с шаблоном, но некоторые строки выше или ниже их для понимания контекста.
С помощью флагов -A , -B или -C со значением num можно выводить строки выше или ниже (или и то, и другое) совпавшей строки. Здесь число обозначает количество дополнительных печатаемых строк, которое находится чуть выше или ниже соответствующей строки. Это применимо ко всем совпадениям, найденным grep в указанном файле или списке файлов.
Ниже показан обычный вывод grep, а также вывод с флагом -A , -B и -C один за другим. Обратите внимание, как grep интерпретирует флаги и их значения, а также изменения в соответствующих выходных данных. С флагом -A1 grep печатает 1 строку, которая следует сразу после соответствующей строки.
Аналогично, с флагом -B1 он печатает 1 строку непосредственно перед соответствующей строкой. С флагом -C1 он печатает 1 строку, которая находится до и после соответствующей строки.

10. Вывод списка файлов
Чтобы напечатать только имя файлов, в которых найден образец, а не сами совпадающие строки, используйте флаг -l .

11. Вывод абсолютных совпадений
Иногда нам нужно печатать строки, которые точно соответствуют заданному образцу, а не какой-то его части. Флаг -x grep позволяет делать именно это.
В приведенном ниже примере файл file.txt содержит строку только с одним словом «support», что соответствует требованию grep с флагом –x . При этом игнорируются строки, которые могут содержать слова «support» с сопутствующим текстом.

12. Поиск совпадения в начале строки
С помощью регулярных выражений можно найти последовательность в начале строки. Вот как это сделать.

Обратите внимание, как с помощью символ каретки ^ изменяет выходные данные. Символ каретки указывает grep выводить результат, только если искомое слово находится в начале строки. Если в шаблоне есть пробелы, то можно заключить весь образец в кавычки.
13. Поиск совпадения в конце строки
Другим распространенным регулярным выражением является поиск шаблона в конце строки.

В данном примере мы искали точку в конце строки. Поскольку точка . является значимым символом, нужно её экранировать, чтобы среда интерпретировала точку как команду. Обратите внимание, как изменяется вывод, когда мы просто ищем совпадения . и когда мы используем $ для указания grep искать только те строки, которые заканчиваются на . (не те, которые могут содержать его где-либо между ними).
14. Использования файла шаблонов
Могут возникнуть ситуации, когда у вас есть сложный список шаблонов, которые вы часто используете. Вместо записи его каждый раз можно указать список этих образцов в файле и использовать с флагом -f . Файл должен содержать по одному образцу на каждой строке.
В нашем примере мы создали файла шаблона с названием pattern.txt со следующим содержимым:

Для его использования используйте флаг -f .

15. Поиск по нескольким шаблонам
grep позволяет задать несколько шаблонов с помощью флага -e .

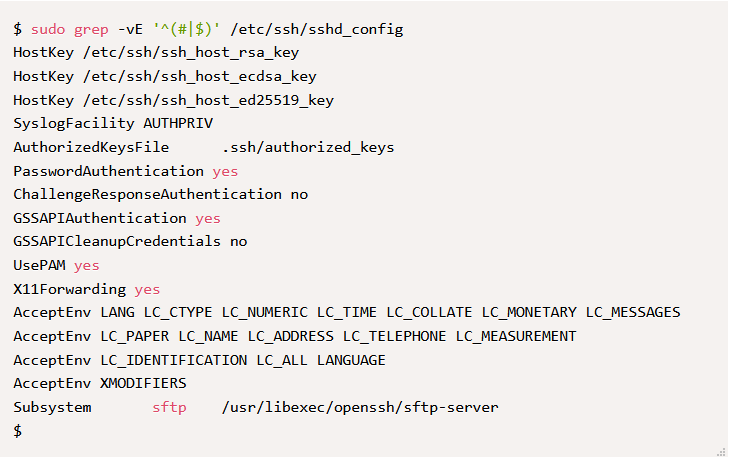
16. Указание расширенных регулярных выражений
grep также поддерживает расширенные регулярные выражения (Extended Regular Expressions – ERE) или с использованием флага -E . Это похоже на команду egrep в Linux.
Использование ERE имеет преимущество, когда вы хотите рассматривать метасимволы как есть и не хотите экранировать их. При этом использование -E с grep эквивалентно команде egrep .
Ниже приведён пример использование ERE, для вывода не пустых и не закомментированных строк. Это особенно полезно для поиска чего-то в больших конфигурационных файлах. Здесь дополнительно использован флаг –v , чтобы НЕ выводить строки, соответствующих шаблону ‘^ (# | $)’ .
Заключение
Приведенные выше примеры являются лишь верхушкой айсберга. grep поддерживает ряд вариантов и может быть очень полезным инструментом в руке человека, который знает, как его эффективно использовать. Мы можем не только использовать приведенные выше примеры, но и комбинировать их различными способами, чтобы получить то, что нам нужно. Для получения дополнительной информации можно воспользоваться встроенной системой справки Linux – man .
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник
Поиск текста в файлах Linux
Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux всё это делается с помощью одной очень простой, но в то же время мощной утилиты grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим, как выполняется поиск текста в файлах Linux, подробно разберём возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Команда grep (расшифровывается как global regular expression print) — одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. Секрет популярности — её мощь, она даёт возможность пользователям сортировать и фильтровать текст на основе сложных правил.
Утилита grep решает множество задач, в основном она используется для поиска строк, соответствующих строке в тексте или содержимому файлов. Также она может находить по шаблону или регулярным выражениям. Команда в считанные секунды найдёт файл с нужной строчкой, текст в файле или отфильтрует из вывода только пару нужных строк. А теперь давайте рассмотрим, как ей пользоваться.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [имя файла. ]
$ команда | grep [опции] шаблон
- Опции — это дополнительные параметры, с помощью которых указываются различные настройки поиска и вывода, например количество строк или режим инверсии.
- Шаблон — это любая строка или регулярное выражение, по которому будет вестись поиск
- Файл и команда — это то место, где будет вестись поиск. Как вы увидите дальше, grep позволяет искать в нескольких файлах и даже в каталоге, используя рекурсивный режим.
Возможность фильтровать стандартный вывод пригодится,например, когда нужно выбрать только ошибки из логов или найти PID процесса в многочисленном отчёте утилиты ps.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -b — показывать номер блока перед строкой;
- -c — подсчитать количество вхождений шаблона;
- -h — не выводить имя файла в результатах поиска внутри файлов Linux;
- -i — не учитывать регистр;
- — l — отобразить только имена файлов, в которых найден шаблон;
- -n — показывать номер строки в файле;
- -s — не показывать сообщения об ошибках;
- -v — инвертировать поиск, выдавать все строки кроме тех, что содержат шаблон;
- -w — искать шаблон как слово, окружённое пробелами;
- -e — использовать регулярные выражения при поиске;
- -An — показать вхождение и n строк до него;
- -Bn — показать вхождение и n строк после него;
- -Cn — показать n строк до и после вхождения;
Все самые основные опции рассмотрели и даже больше, теперь перейдём к примерам работы команды grep Linux.
Примеры использования
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
Поиск текста в файлах
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
grep User /etc/passwd
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
grep -i «user» /etc/passwd
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
grep -A4 «EE» /var/log/xorg.0.log
Выведет строку с вхождением и 4 строчки после неё:
grep -B4 «EE» /var/log/xorg.0.log
Выведет целевую строку и 4 строчки до неё:
grep -C2 «EE» /var/log/xorg.0.log
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
grep «^Nov 10» messages.1
Nov 10 01:12:55 gs123 ntpd[2241]: time reset +0.177479 s
Nov 10 01:17:17 gs123 ntpd[2241]: synchronized to LOCAL(0), stratum 10
Поиск в конце строки — спецсимвол «$»:
grep «terminating.$» messages
Jul 12 17:01:09 cloneme kernel: Kernel log daemon terminating.
Oct 28 06:29:54 cloneme kernel: Kernel log daemon terminating.
Найдём все строки, которые содержат цифры:
grep «2» /var/log/Xorg.0.log
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
Рекурсивное использование grep
Если вам нужно провести поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах, например в файлах конфигурации Apache — /etc/apache2/, используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займётся поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
grep -r «mydomain.com» /etc/apache2/
В выводе вы получите:
grep -r «zendsite» /etc/apache2/
/etc/apache2/vhosts.d/zendsite_vhost.conf: ServerName zendsite.localhost
/etc/apache2/vhosts.d/zendsite_vhost.conf: DocumentRoot /var/www/localhost/htdocs/zendsite
/etc/apache2/vhosts.d/zendsite_vhost.conf:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
grep -h -r «zendsite» /etc/apache2/
ServerName zendsite.localhost
DocumentRoot /var/www/localhost/htdocs/zendsite
Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
grep -w «abc» имя_файла
Поиск двух слов
Можно искать по содержимому файла не одно слово, а два сразу:
egrep -w ‘word1|word2’ /path/to/file
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
grep -c ‘word’ /path/to/file
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
grep -n ‘root’ /etc/passwd
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
grep -v пар /path/to/file
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
grep -l ‘primary’ *.c
Цветной вывод в grep
Также вы можете заставить программу выделять другим цветом вхождения в выводе:
grep —color root /etc/passwd

Выводы
Вот и всё. Мы рассмотрели использование команды grep для поиска и фильтрации вывода команд в операционной системе Linux. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Источник



