- Кодировки UTF-8 и Windows 1251 — просто о сложном
- Немного теории
- Недостатки и достоинства
- Базы банных
- Htaccess
- java convert String windows-1251 to utf8
- 2 Answers 2
- Задать кодировку Windows-1251 для файла
- Решение
- How to find Encoding for 1251 codepage
- 3 Answers 3
- Not the answer you’re looking for? Browse other questions tagged c# .net encoding or ask your own question.
- Linked
- Related
- Hot Network Questions
- Subscribe to RSS
- Как из стоки windows-1251 получить строку UTF-8 на C#?
Кодировки UTF-8 и Windows 1251 — просто о сложном

Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
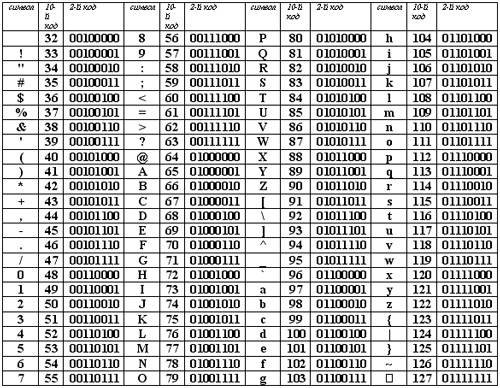
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
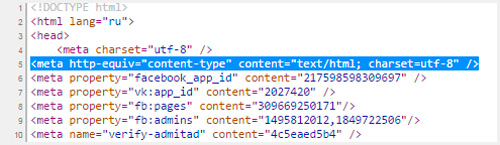
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
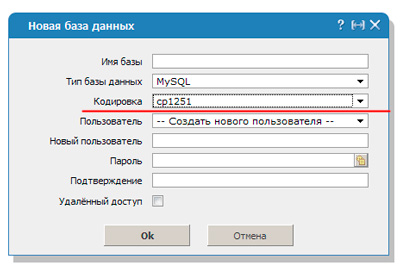
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.
java convert String windows-1251 to utf8
I’m trying change keyboard: input cyrylic keyboard, output latin. Example: qwerty +> йцукен
It doesn’t work, can anyone tell me what i’m doing wrong?
2 Answers 2
First java text, String/char/Reader/Writer is internally Unicode, so it can combine all scripts. This is a major difference with for instance C/C++ where there is no such standard.
Now System.in is an InputStream for historical reasons. That needs an indication of encoding used.
The above explicitly sets the conversion for System.in to Cyrillic. Without this optional parameter the default encoding is taken. If that was not changed by the software, it would be the platform encoding. So this might have been correct too.
Now text is correct, containing the Cyrillic from System.in as Unicode.
You would get the UTF-8 bytes as:
The old «recoding» of text was wrong; drop this line. in fact not all Windows-1251 bytes are valid UTF-8 multi-byte sequences.
System.out is a PrintStream, a rather rarely used historic class. It prints using the default platform encoding. More or less rely on it, that the default encoding is correct.
For printing to an UTF-8 encoded file:
Here I have added a Unicode BOM character in front, so Windows Notepad may recognize the encoding as UTF-8. In general one should evade using a BOM. It is a zero-width space (=invisible) and plays havoc with all kind of formats: CSV, XML, file concatenation, cut-copy-paste.
Задать кодировку Windows-1251 для файла
 Перевести фамилию в кодировку Windows 1251
Перевести фамилию в кодировку Windows 1251
Закодируйте и разместите в разрядную сетку свою фамилию, используя базовую таблицу кодировки.
Изменить кодировку строки UTF-8 to windows-1251
получаю из хмл текст, он весь в UTF-8. как изменить кодировку строки UTF-8 to windows-1251? если.
Можно ли использовать кодировку Windows-1251 в WP7
Добрый день! Решил посмотреть что представляет из себя Windows Phone 7 и написать тестовое.
Как задать кодировку для файла?
4
| Тематические курсы и обучение профессиям онлайн Профессия С#-разработчик (Skillbox) Архитектор ПО (Skillbox) Профессия Тестировщик (Skillbox) |
Решение
Iiisi, кодировку следует передавать конструкторам StreamReader и StreamWriter. Вызов file.Write(Str,Code) не менял кодировку. Ты вызывал вот эту перегрузку Write предназначенную для форматированного вывода.
Правильно будет так:
Заказываю контрольные, курсовые, дипломные и любые другие студенческие работы здесь или здесь.
Как изменить кодировку символов с Windows-1251 на UTF-8?
Здравствуйте. Не давно начал изучать HTML, XHTML, CSS. Столкнулся с небольшой проблемой. Изучаю.
Перекодировать строку из кодировки KOI в кодировку Windows-1251 и обратно
Кодировщик. Написать программу, перекодирующую строку в кодировке KOI в строку в кодировке.
Можно ли изменить кодировку Windows-1251 на Utf-8 при помощи Cmd.exe?
В бух.7.7 создал файл.txt, нужно сохранить его в utf-8. Средства 1с77 позволяют менять кодовую.
Как в iframe задать кодировку для текстового файла, на который он ссылается
Есть тег iframe, который ссылается на текстовый файл. В текстовом файле есть русский текст. Он.
How to find Encoding for 1251 codepage
I need to create System.Encoding for 1251 codepage.
On my russian Windows I use
I am afraid this will produce different results depending on Windows
3 Answers 3
Correct, you will get different results on different machines if you use Encoding.Default .
If you want a specific codepage, you can use Encoding.GetEncoding:
For .NET Core you also need to reference the System.Text.Encoding.CodePages package and then use Encoding.RegisterProvider:
The .NET Framework/.NET Core supports a large number of character encodings and code pages. To retrieve an encoding that is present in the .NET Framework/.NET Core pass the EncodingProvider object to the Encoding.RegisterProvider method to make the encodings supplied by the EncodingProvider object available to the common language runtime. Microsoft Document Reference

Not the answer you’re looking for? Browse other questions tagged c# .net encoding or ask your own question.
Linked
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
site design / logo © 2021 Stack Exchange Inc; user contributions licensed under cc by-sa. rev 2021.4.16.39093
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Как из стоки windows-1251 получить строку UTF-8 на C#?

может так попробовать?

как вариант можно попробовать сериализовать в json с помощью специально для этого реализованными инструментами, например: newtonsoft json.
еще у WebClient`а есть свойство Encoding. Можно попробовать разные варианты.

В платформе .NET все строки представлены как UTF-16.
Поэтому нет «строки windows-1251», а есть UTF-16 строка, которая была заполнена символами из источника, в котором символы были сохранены в windows-1251.
Из этого становится виден сценарий:
1. Считать файл байтов, где символы кодируются в windows-1251.
2. Преобразовать в UTF-16
3. Выполнить над строками различные необходимые действия.
4. Сохранить результат с преобразованием в набор байт, где символы представленны как UTF-8.
И пример кода:
1-2. Построчное чтение из файла с windows-1251
4. Помещаем в тело запроса набор байт, где символы в UTF-8



