- How to create 100% CPU load in Linux
- About Sergey Tkachenko
- 2 thoughts on “ How to create 100% CPU load in Linux ”
- CPU Load: когда начинать волноваться?
- Аналогия транспортного потока
- Так Вы говорите, 1.00 — идеальное значание load average?
- Что насчет многопроцессорных систем? Мой сервер показывает загрузку 3.00 и все ОК!
- Многоядерность vs. многопроцессорность
- Сведем все вместе
- Примечания переводчика
- Understand Linux Load Averages and Monitor Performance of Linux
- How to Monitor Linux System Load Average
- Top Command
- Glances Tool
- Understanding System Average Load in Relation Number of CPUs
- Multi-processor Vs Multi-core
- If You Appreciate What We Do Here On TecMint, You Should Consider:
How to create 100% CPU load in Linux
Sometimes it is useful to stress out your CPU. For example, if you have replaced your CPU fan or changed something in the cooling system, it is a good idea to test it under heavy load. Here is a trick you can use to overload your CPU in Linux.
One of great options of the Linux operating system is the amount of useful tools available out of the box even in the base system. Thanks to the «everything-is-a-filesystem» concept used when designing Linux, you don’t need extra tools to stress out your CPU.
How to create a 100% CPU load in Linux
To create a 100% CPU load on your Linux PC, do the following.
- Open your favorite terminal app. Mine is xfce4-terminal.
- Identify how many cores and threads your CPU has. You can get detailed CPU info with the following command:
It prints out information about all CPUs, including physical and virtual.
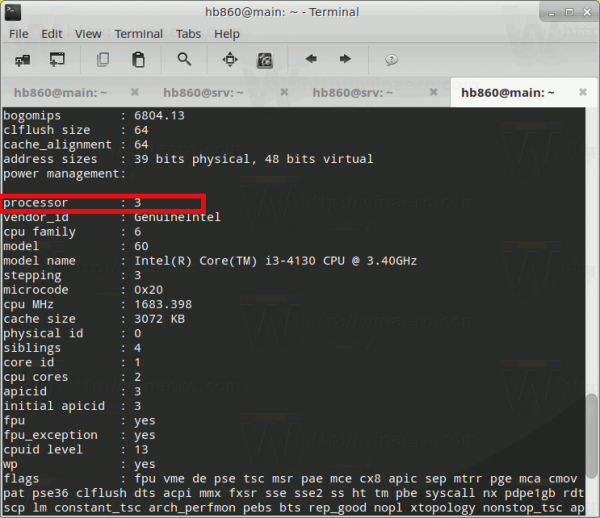
Notice the «Processor» line for every information section. It has a value starting from 0 and ending at the number of cores/threads. In my case, it shows 4 CPUs, which matches my dual core i3 with 2 threads per core.
Alternatively, you can use something like the htop utility, it shows the same information using bars: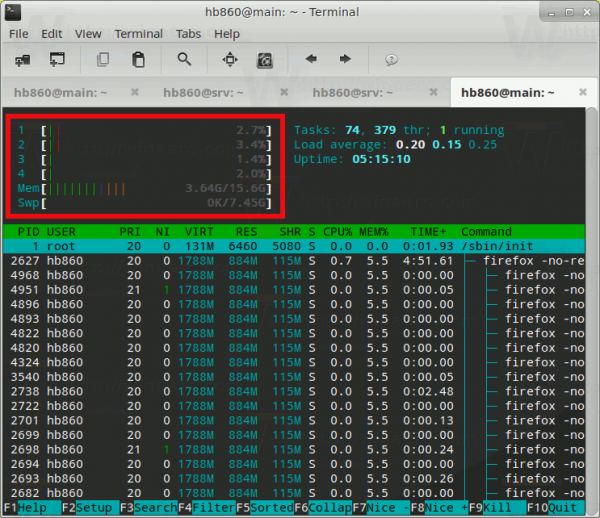
Next, execute the following command as root:
Repeat the command N times, where N is the number of CPUs. In my case, I have to execute it four times.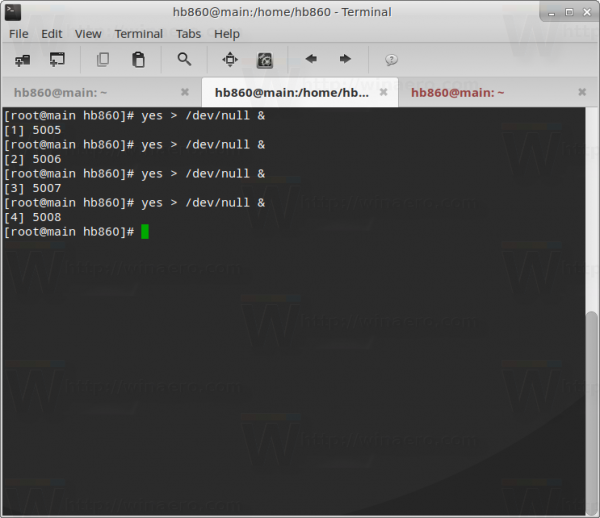
Voila, you have loaded your CPU at 100%. See the following screenshot: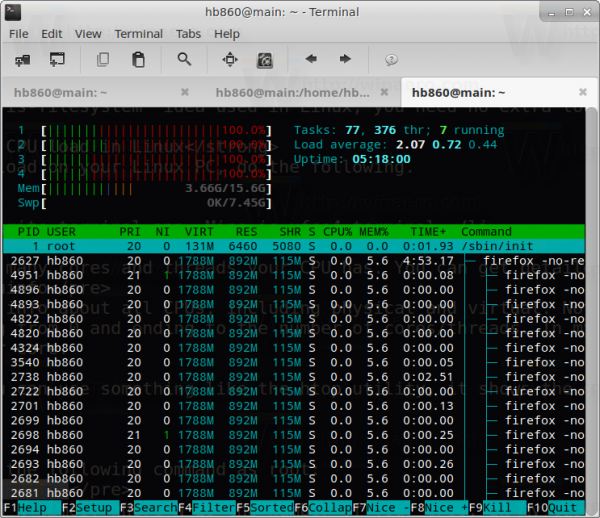
To stop it, execute the command killall yes as root.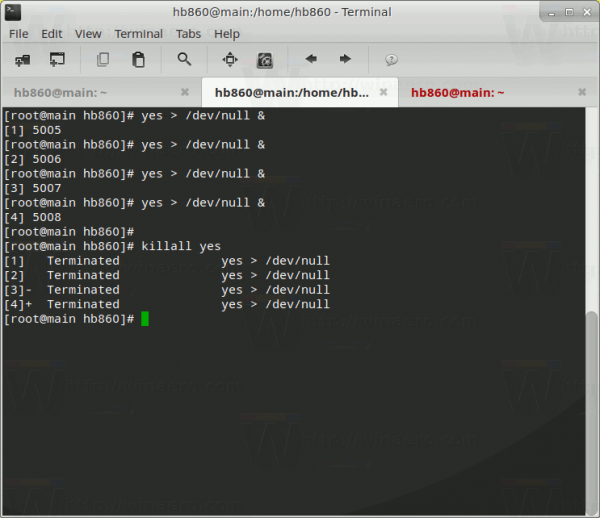
Winaero greatly relies on your support. You can help the site keep bringing you interesting and useful content and software by using these options:
Share this post
About Sergey Tkachenko
Sergey Tkachenko is a software developer from Russia who started Winaero back in 2011. On this blog, Sergey is writing about everything connected to Microsoft, Windows and popular software. Follow him on Telegram, Twitter, and YouTube.
2 thoughts on “ How to create 100% CPU load in Linux ”
That’s brilliant. Thank you. I have been using stress-ng but that package is not supported on Photon OS. This is perfect.
Thanks man. Exactly what I was looking for. No need to install additional softwares, simple and works like a charm.
Источник
CPU Load: когда начинать волноваться?
Данная заметка является переводом статьи из блога компании Scout. В статье дается простое и наглядное объяснение такого понятия, как load average . Статья ориентирована на начинающих Linux-администраторов, но, возможно, будет полезна и более опытным админам. Заинтересовавшимся добро пожаловать под кат.
Вероятно, Вы уже знакомы с понятием load average . Load average — это три числа, отображаемые при выполнении команд top и uptime . Выглядят они примерно так:
Большинство интуитивно понимают, что эти три числа обозначают средние значения загрузки процессора на прогрессивно увеличивающихся временных промежутках (одна, пять и пятнадцать минут) и чем меньше их значения — тем лучше. Большие числа свидетельствуют о слишком большой нагрузке на сервер. Но какие значения считать предельными? Какие значения являются «плохими», а какие — «хорошими»? Когда Вам следует просто волноваться о занчениях средней загрузки, а когда следует бросать другие дела и решать проблему так быстро, как это возможно?
Для начала, давайте разберемся, что же означает load average . Рассмотрим простейший случай: предположим, что у нас в наличии один сервер с одноядерным процессором.
Аналогия транспортного потока
Одноядерный процессор похож на дорогу с одной полосой движения. Представьте себе, что Вы управяете движением машин по мосту. Иногда, Ваш мост загружен настолько сильно, что машинам приходится ждать в очереди чтобы проехать по нему. Вы хотите дать людям понять, как долго им придется ждать чтобы перебраться на другую сторону реки. Хорошим способом сделать это будет показать как много машин ждут в очереди в конкретный момент времени. Если машин в очереди нет, подъезжающие водители будут знать, что они сразу смогут проехать по мосту. В противном случае, они будут понимать, что придется ждать своей очереди.
Итак, Управляющий Мостом, какую систему обозначений Вы будете использовать? Как насчет такой:
- 0.00 означает, что на мосту нет ни одной машины. Фактически, значения от 0.00 до 1.00 означают отсутствие очереди. Подъезжающая машина может воспользоваться мостом без ожидания;
- 1.00 означает, что на мосту находится как раз столько автомобилей, сколько он может вместить. Все еще идет хорошо, но, в случае увеличения потока машин, возможны проблемы;
- Значения, превышающие 1.00 означают наличие очереди на въезде. Насколько большой? Например, значение 2.00 показывает, что в очереди стоит столько же автомобилей, сколько движется по мосту. 3.00 означает, что мост полностью занят и в очереди ожидает в два раза больше машин, чем он может вместить. И так далее.
 load average = 1.00 load average = 0.50 load average = 1.70
load average = 1.00 load average = 0.50 load average = 1.70
Вот базовое значение загрузки процессора. «Машины» обрабатываются с использованием промежутков процессорного времени («пересекают мост»), либо ставятся в очередь. В Unix это называется длина очереди выполнения: количество всех процессов, выполняемых в данный момент времени, плюс количество процессов, ожидающих в очереди.
Вам, как управляющему мостом, хотелось бы, чтобы машины-процессы никогда не ждали в очереди. Таким образом, предпочтительно, чтобы загрузки процессора была всегда ниже 1.00. Периодически возможны всплески трафика, когда загрузка будет превышать 1.00, но если она постоянно превышает данное значение — это повод начать волноваться.
Так Вы говорите, 1.00 — идеальное значание load average?
Что насчет многопроцессорных систем? Мой сервер показывает загрузку 3.00 и все ОК!
У Вас четырехпроцессорная система? Все в порядке, если load average равен 3.00.
В мультипроцессорных системах загрузка вычисляется относительно количества доступных процессорных ядер. 100% загрузка обозначается числом 1.00 для одноядерной машины, числом 2.00 для двуядерной, 4.00 для четырехъядерной и т.д.
Если вернуться к нашей аналогии с мостом, 1.00 означает «одну полностью загруженную полосу движения». Если на мосту всего одна полоса, 1.00 означает, что мост загружен на 100%, если же в наличии две полосы, он загружен всего на 50%.
То же самое с процессорами. 1.00 означает 100% загрузки одноядерного процессора. 2.00 — 100% загрузки двуядерного и т.д.
Многоядерность vs. многопроцессорность
Сведем все вместе
Давайте посмотрим на средние значения загрузки с помощью команды uptime :
Здесь представлены показатели для системы с четырехъядерным процессором и мы видим, что имеется большой запас по нагрузке. Я даже не буду задумываться о ней, пока load average не превысит 3.70.
Какое среднее значение мне следует контролировать? Для одной, пяти или 15 минут?
Количество ядер важно для правильно понимания load average. Как мне его узнать?
Команда cat /proc/cpuinfo выводит информацию обо всех процессорах в вашей системе. Чтобы узнать количество ядер, «скормите» ее вывод утилите grep :
Примечания переводчика
Выше представлен перевод самой статьи. Также много интересной информации можно почерпнуть из комментариев к ней. Так, один из комментаторов говорит о том, что не для каждой системы важно иметь запас по производтельности и не допускать значения загрузки выше 0.70 — иногда нам нужно чтобы сервер работал «на всю катушку» и в таких случаях load average = 1.00 — то, что доктор прописал.
Хабраюзер dukelion добавил в комментариях ценное замечание, что в некоторых сценариях, для достижения максимального КПД «железа», стоит держать значение load average несколько выше 1.00 в ущерб эффективности работы каждого отдельного процесса.
Хабраюзер enemo в комментариях добавил замечание о том, что высокий показатель load average может быть вызван большим количеством процессов, выполняющих в данный момент операции чтения/записи. То есть, load average > 1.00 на одноядерной машине не всегда говорит о том, что в Вашей системе отсутствует запас по загрузке процессора. Требуется более внимательное изучение причин такого показателя. Кстати, это хорошая тема для нового поста на Хабре 🙂
Источник
Understand Linux Load Averages and Monitor Performance of Linux
In this article, we will explain one of the critical Linux system administration tasks – performance monitoring in regards to system/CPU load and load averages.
Before we move any further, let’s understand these two important phrases in all Unix-like systems:
- System load/CPU Load – is a measurement of CPU over or under-utilization in a Linux system; the number of processes which are being executed by the CPU or in waiting state.
- Load average – is the average system load calculated over a given period of time of 1, 5 and 15 minutes.
In Linux, the load-average is technically believed to be a running average of processes in it’s (kernel) execution queue tagged as running or uninterruptible.
Note that:
- All if not most systems powered by Linux or other Unix-like systems will possibly show the load average values somewhere for a user.
- A downright idle Linux system may have a load average of zero, excluding the idle process.
- Nearly all Unix-like systems count only processes in the running or waiting states. But this is not the case with Linux, it includes processes in uninterruptible sleep states; those waiting for other system resources like disk I/O etc.
How to Monitor Linux System Load Average
There are numerous ways of monitoring system load average including uptime which shows how long the system has been running, number of users together with load averages:
The numbers are read from left to right, and the output above means that:
- load average over the last 1 minute is 1.98
- load average over the last 5 minutes is 2.15
- load average over the last 15 minutes is 2.21
High load averages imply that a system is overloaded; many processes are waiting for CPU time.
We will uncover this in the next section in relation to number of CPU cores. Additionally, we can as well use other well known tools such as top and glances which display a real-time state of a running Linux system, plus many other tools:
Top Command
Glances Tool
The load averages shown by these tools is read /proc/loadavg file, which you can view using the cat command as below:
On desktop machines, there are graphical user interface tools that we can use to view system load averages.
Understanding System Average Load in Relation Number of CPUs
We can’t possibly explain system load or system performance without shedding light on the impact of the number of CPU cores on performance.
Multi-processor Vs Multi-core
- Multi-processor – is where two or more physical CPU’s are integrated into a single computer system.
- Multi-core processor – is a single physical CPU which has at least two or more separate cores (or what we can also refer to as processing units) that work in parallel. Meaning a dual-core has 2 two processing units, a quad-core has 4 processing units and so on.
Furthermore, there is also a processor technology which was first introduced by Intel to improve parallel computing, referred to as hyper threading.
Under hyper threading, a single physical CPU core appears as two logical CPUs core to an operating system (but in reality, there is one physical hardware component).
Note that a single CPU core can only carry out one task at a time, thus technologies such as multiple CPUs/processors, multi-core CPUs and hyper-threading were brought to life.
With more than one CPU, several programs can be executed simultaneously. Present-day Intel CPUs use a combination of both multiple cores and hyper-threading technology.
To find the number of processing units available on a system, we may use the nproc or lscpu commands as follows:
Another way to find the number of processing units using grep command as shown.
Now, to further understand system load, we will take a few assumptions. Let’s say we have load averages below:
On a single core system this would mean:
- The CPU was fully (100%) utilized on average; 1 processes was running on the CPU (1.00) over the last 1 minute.
- The CPU was idle by 60% on average; no processes were waiting for CPU time (0.40) over the last 5 minutes.
- The CPU was overloaded by 235% on average; 2.35 processes were waiting for CPU time (3.35) over the last 15 minutes.
On a dual-core system this would mean:
- The one CPU was 100% idle on average, one CPU was being used; no processes were waiting for CPU time(1.00) over the last 1 minute.
- The CPUs were idle by 160% on average; no processes were waiting for CPU time. (0.40) over the last 5 minutes.
- The CPUs were overloaded by 135% on average; 1.35 processes were waiting for CPU time. (3.35) over the last 15 minutes.
You might also like:
In conclusion, if you are a system administrator then high load averages are real to worry about. When they are high, above the number of CPU cores, it signifies high demand for the CPUs, and low load averages below the number of CPU cores tells us that CPUs are underutilized.
If You Appreciate What We Do Here On TecMint, You Should Consider:
TecMint is the fastest growing and most trusted community site for any kind of Linux Articles, Guides and Books on the web. Millions of people visit TecMint! to search or browse the thousands of published articles available FREELY to all.
If you like what you are reading, please consider buying us a coffee ( or 2 ) as a token of appreciation.

We are thankful for your never ending support.
Источник



