- How to Create Human Readable Output with Linux Commands
- 1. Choosing to Display on Certain Columns
- 2. Preserving Color Information for ls
- 3. Showing the Variable Width Columns in a Table
- Human readable format
- How to Display File Size in Human Readable Format (KB, MB, GB) in Linux Terminal
- human readable format
- Ubuntu Check RAM Memory Chip Speed and Specification From Within a Linux System
- du Command Output In Human Readable Format ( GB / MB / TB )
- Linux Date Command: Convert Named Stats Dump Date
- Shell Scripting: Check File Size ( Find File Size )
- Find the file permission without using ls -l command
- Display stat for /etc/passwd file
- Finding the Biggest Files and Folders in Linux Command Line
- How to find the biggest folders in Linux?
- Adding Options
- Human-Readable Output
- Corrected Human-Readble Output
- Where are the largest files?
How to Create Human Readable Output with Linux Commands

The command line interface is a lot more “information dense” compared to the equivalent GUIs on Windows. With a single instruction, you can get a screen full of data, with columns, calculations, and colors. Most commands have additional options that allow you to modify their output so that you get the exact information you’re looking for.
Unfortunately, this power comes with a loss of usability. Many useful commands like netstat for example, generate their output in a series of columns with no fixed width, making it hard to parse by human readability standards. Even simple commands like listing the contents of a directory can contain additional information to confuse you.
In this article, I’ll show you how to do three things:
- Choose to display only certain columns of output
- Retain the color options for certain commands
- Make the columns neat and tidy when the output is all scrambled
Table of Contents
1. Choosing to Display on Certain Columns
A simple command like “ls” has options to display a lot more data than just the filename and directory. For example, this command:
The “-l” option lists a bunch of columns for each entry like the permissions, who owns it, time of creation etc as shown here:
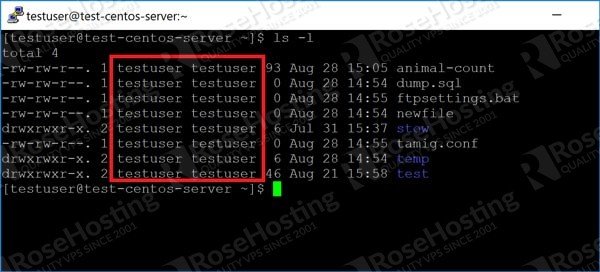
Useful as this data is, it might be a bit too much. Luckily, Linux has a system of “piping” the output of commands to others and using this, we can pick and choose which columns to display using the “awk” command.
Let’s say that in the screenshot here, we want to only display the last column – the one with the file or folder name. We do it like this:
This generates the following output:
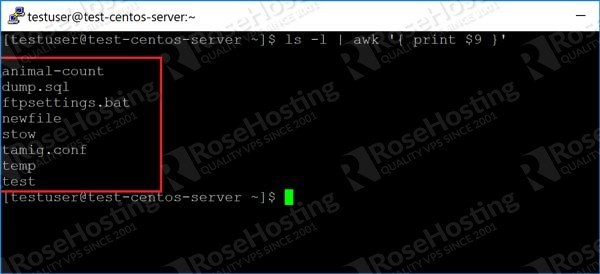
The key here is the part of the command that says:
Which displays only column number 9. We take the output from “ls -l” and “pipe” it to awk. If we want, we can display columns 1 and 9 like this:
You might be thinking that it’s too much effort to type out all the above each and every time you want to print a couple of columns. You might not even remember it! And you’d be right. Which is why you can just create a custom command of your own to run it automatically with a keyword of your choice!
2. Preserving Color Information for ls
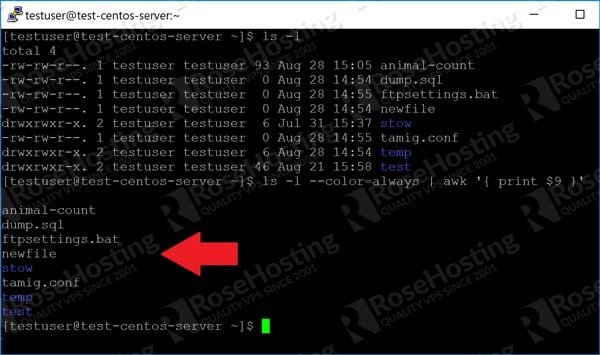
Since ls is such a common command, you’ll probably be using it with awk a lot. You might have noticed in the previous examples, that piping the output to awk destroys the color information of ls. This is unfortunate, because a lot of us rely on color coding to quickly differentiate between folders, directories, and zipped files.
With ls, we can preserve this information by using the ” –color=always” option. So our awk command above becomes:
And this produces the following:
3. Showing the Variable Width Columns in a Table
The “ls” command is very obliging. Its output is neat, and each column has a specific width. But what if you have a file where the columns don’t line up nicely? For example, take this file:
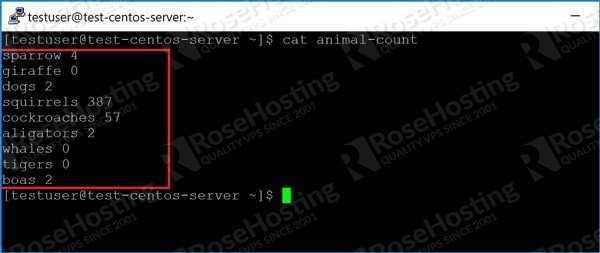
Since each animal name has a different width, the next column starts at a different place each time. In a long list, the output can become unreadable. Commands like netstat are impossible to decipher.
As before, we have a command called “column” into which we can pipe the output to make it display the data in a table. Here it is:
The “-t” parameter specifies a table.
We get the following output:
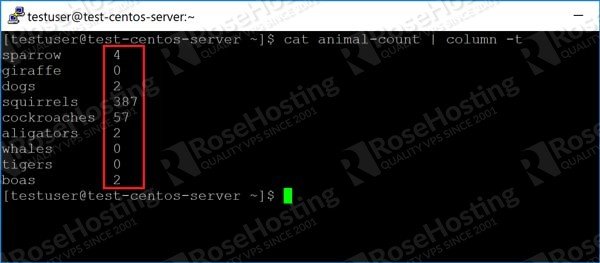 That’s much easier to read. We use “column” frequently while parsing the output of commands with a lot of data and variable width columns. It’s particularly useful for log files – sometimes containing thousands of lines of code.
That’s much easier to read. We use “column” frequently while parsing the output of commands with a lot of data and variable width columns. It’s particularly useful for log files – sometimes containing thousands of lines of code.
We hope these tips and tricks make your Linux admin tasks a little easier with human readable output! If you use one of our managed Linux hosting plans, you can always as our system administrator to help you any aspect of managing your Linux server. They are available 24/7 and will take care of your request immediately.
If you liked this post please share it with your friends via social media networks, or if you have any question regarding this blog post, please feel free to leave a comment below and one of our system administrators will reply as soon as possible. Thanks!
Источник
Human readable format
Всем доброе утро!
Такой вопрос — что такое этот Human readable format и где про него что-то почитать? Перерыла весь гугл — куча упоминаний и ничего, блин, конкретного нет. Что это такое, какие критерии и тд.
Буду благодарна за разъяснение. 
Fasm section ‘.data’ readable writeable executable и readable executable
Если section ‘.data’ readable executable, то наш exe файл не сможет записывать в область даты.
#define PRINT(format,x) printf(«x = %format\n»,x)
#include #include
#define PRINT(format,x) printf(«x = %format\n»,x) int.
 Class Human
Class Human
Здравствуйте, начал изучать ООП. Столкнулся с такой проблемой. Не могу вызвать в Main «SeyHello».
Класс Human
создать класс human состоящий из полей -имя -фамилия -дата рождения -пол -национальность.
Pavel_Srgv, спасибо, Ваш пример и правда показал разницу! Наглядно, даже для меня 
А как тогда это применить к самим файлам? Что значит human-readable file?
Вот как раз нашла эту команду, всё получилось. Только Вы не могли бы рассказать что здесь что?
find . -type f — это понятно. А вот дальше. Исполняемые файлы -exec, а что значит «file <> +» ?
или же просто ‘text/’
Human readable format – неточное определение в данном контексте. например xml можно читать человеком, но это не считается Human readable, в отличие от csv или yaml, поэтому что именно грепать, ясно лишь примерно.
Помощь в написании контрольных, курсовых и дипломных работ здесь.
Разработать класс Human
Разработать класс Human. Добавить в класс 3 поля: пол (использовать перечисление), возраст.
Создать класс Human
Помогите пожалуйста с заданием Создать класс Human, который содержит такие: закрытые — имя.
Найти ошибку в Class Human
Найдите ошибку: Class Human < int Age; string Name; public: Human() <>>
Структура Human (хранение, сортировка)
Привет! Сам текст задания звучит так: Реализовать структуру Human, которая должна содержать.
Источник
How to Display File Size in Human Readable Format (KB, MB, GB) in Linux Terminal
You probably already know that you can use ls command with long listing option -l to show file size in Linux.
But unfortunately, the long listing shows the file size in blocks and that’s not of much use to us humans.
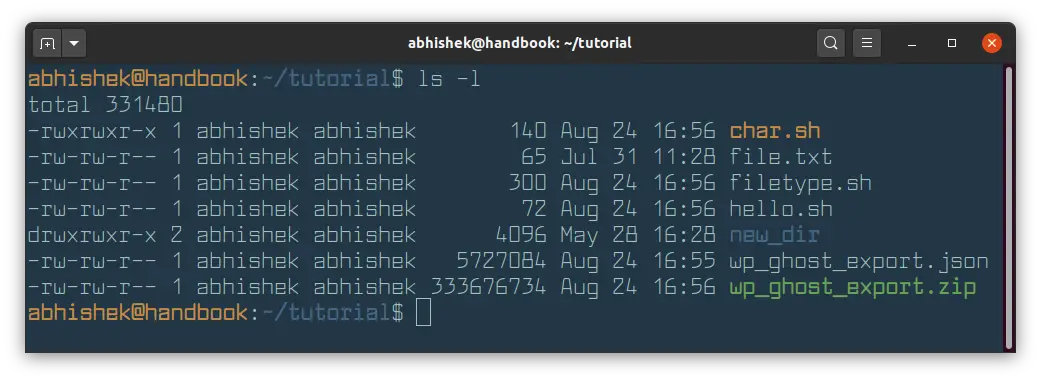
Good thing is that you can combine the option -l with -h to show the file size in human readable format.
As you can see, it is better to display file size in human-readable format.
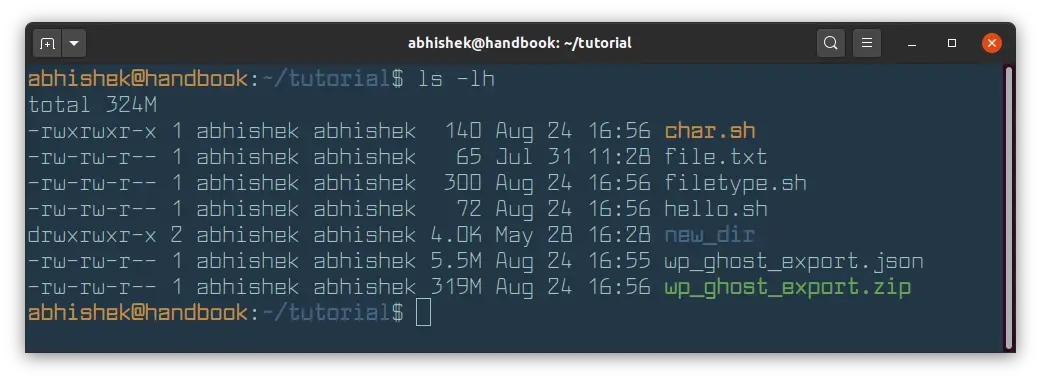
As you can see, file sizes are now displayed in K (for KB), M for (MB). If the file size is in Bytes, it is not displayed with any suffix. In the above example, char.sh is 140 Bytes in size.
Did you notice the size of new_dir directory? It is 4 KB. If you use ls -lh command on directories, it always shows the size of directory as 4.0 K.

By default, the block size in most Linux system is 4096 Bytes or 4 KB. A directory in Linux is simply a file with the information about the memory location of all the files in it.
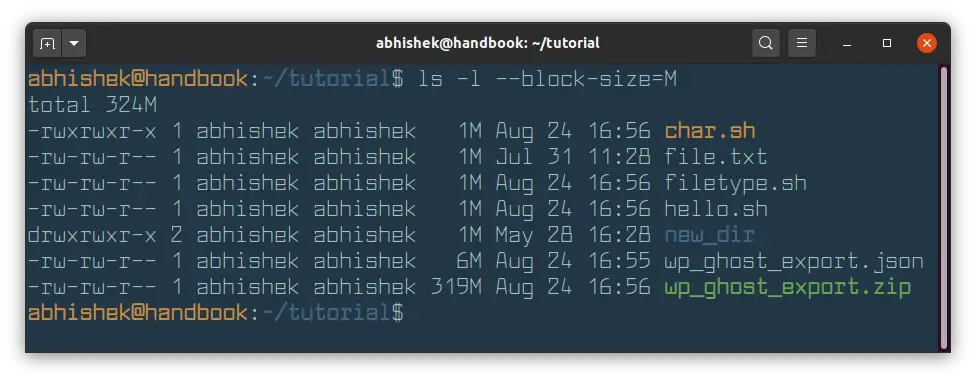
You can force ls command to display file size in MB with the —block-size flag.
The problem with this approach is that all the files with size less than 1 MB will also be displayed with file size 1 MB.
The ls command also has -s option to display size. You should combine with -h to show the file size in human readable form.
Here’s the output:

You can also use the stat command in Linux to check the file size.
I hope you find this quick tip helpful in seeing the file size in Linux.
Источник
human readable format
/Downloads/ directory. How do I sort and print sizes in human readable format using du -h command under Ubuntu Linux LTS version 12.04 or any other Linux distributions?
[continue reading…]
Ubuntu Check RAM Memory Chip Speed and Specification From Within a Linux System
I want to add more RAM to my server running Ubuntu Linux. How do I find out my current RAM chip information such as its speed, type and manufacturer name within a Linux system without opening the case?
[continue reading…]
du Command Output In Human Readable Format ( GB / MB / TB )
I need to get a list of sizes in human readable du output format. How do I get the output for du command in GB under Linux or UNIX operating systems?
[continue reading…]
Linux Date Command: Convert Named Stats Dump Date
T he rndc stats commands created /var/named/chroot/var/named/data/named_stats.txt file under RHEL 5.x or CentOS 5.x BIND 9 server. However, date is not is correct format. The date is in the following format:
grep ‘Dump’ /var/named/chroot/var/named/data/named_stats.txt
outputs:
+++ Statistics Dump +++ (1263408025)
— Statistics Dump — (1263408025)
+++ Statistics Dump +++ (1263408071)
— Statistics Dump — (1263408071)
+++ Statistics Dump +++ (1268304218)
— Statistics Dump — (1268304218)
+++ Statistics Dump +++ (1268304248)
— Statistics Dump — (1268304248)
How do I convert date (e.g., 1263408025) in a human readable format?
[continue reading…]
Shell Scripting: Check File Size ( Find File Size )
H ow do I find out file size under UNIX / Linux operating system and store the same to a variable called s?
[continue reading…]
Find the file permission without using ls -l command
Q. I need to find file permission and store the same to a shell variable. How do I find out the file permission without parsing ls -l output?
A. Use GNU stat command to display file or file system status. It has option to display output in specific format.
Display stat for /etc/passwd file
Type the following command:
$ stat /etc/passwd
Output:
Print access rights in octal format:
$ stat -c %a /etc/passwd
Output:
Print access rights in human readable format, enter:
$ stat -c %A /etc/passwd
Output:
Store access rights in octal format to a shell variable:
$ VAR=$(stat -c %a /etc/passwd)
$ echo $VAR
Источник
Finding the Biggest Files and Folders in Linux Command Line
This is a quick tutorial to show you how to find the biggest files on your Linux machine using a few commands that you may already be familiar with du, sort, and head.
Here’s a quick summary:
To find the 10 biggest folders in current directory:
To find the 10 biggest files and folders in current directory:
Read the rest of the article to get a detailed explanation of these commands.
How to find the biggest folders in Linux?
The du command is used for getting the disk usage. Sort command sorts the data as per your requirement. The head command displays the top lines of a text input source.
This is just one combination for getting the biggest files and directories in Linux command line. There can be several other ways to achieve the same result.

What happens if you run these three commands together without options? Your output probably won’t be very useful.
When you run these commands, unless specified with du, everything will run automatically using the current working directory as the source file.
Sort without options arranges items in numerical order, but this behavior is a little strange. 100 is considered less than 12 because 2 > 0. That’s definitely not what we want.
Head here defaults to displaying the first 10 items. Depending on the directory you want to analyze, you can tailor this to find large files quickly.
Adding Options
So let’s look at what might be more typical options.
Adding -n to sort command means that items will be sorted by numeric value. Adding -r means that the results will be reversed. This is what we want when searching for the largest number.
I’m also going to add -5 to limit our results further than the default for head. This value is something that you should decide based on what you know about the system.
You may want to expand the value to a number greater than 10, or omit it entirely if there are many large files you are trying to filter. Otherwise, you may run it, delete several files, but still have space issues.
Okay, let’s put it all together and see what happens.
That’s better, you can quickly see where the largest files are. You can do better, though. Let’s clean it up with some more options.

Human-Readable Output
The human options for certain commands help present numbers in a way that is familiar to us. Let’s try adding that to the du command.
Corrected Human-Readble Output
Wait a second… Those numbers don’t make any sense. No, they don’t because You have only changed the content to human-readable for the du command. Sort has its own built-in function for human-readable numeric sort with -h. Both must be used to get the desired output. You can run into these kinds of issues often in Linux.
It’s important to experiment and make sure that your results “make sense” before using a command a specific way.
Let’s try it again.
That’s more like it.
Where are the largest files?
You can tell from the output that the Documents folder contains some larger files, but if you switch to that folder and run our command again, you don’t get the largest file. You get this:
This is just telling us what you already know. The current directory, referred to as . , has 1.7G worth of files. That isn’t helpful if you’re trying to find single, unusually large files.
You need to add another flag to du for this task. Using option -a, you can get the output that we’re looking for. Let’s try it.
Conclusion
Did you enjoy this guide to finding large files in Linux? I hope all of these tips taught you something new.
If you like this guide, please share it on social media. If you have any comments or questions, leave them below.
Источник



