- Иерархические информационные модели
- IT-блог о веб-технологиях, серверах, протоколах, базах данных, СУБД, SQL, компьютерных сетях, языках программирования и создание сайтов.
- Иерархическая база данных. Иерархическая модель данных
- Иерархическая модель данных
- Структура иерархической базы данных
- Преобразование концептуальной модели в иерархическую модель данных
- Управление иерархическими данными
- Иерархические информационные модели
Иерархические информационные модели
Нас окружает множество различных объектов, каждый из которых обладает определенными свойствами. Однако некоторые группы объектов имеют одинаковые общие свойства, которые отличают их от объектов других групп.
Группа объектов, обладающих одинаковыми общими свойствами, называется классом объектов. Внутри класса объектов могут быть выделены подклассы, объекты которых обладают некоторыми особенными свойствами, в свою очередь подклассы могут делиться на еще более мелкие группы и так далее. Такой процесс систематизации объектов называется процессом классификации.
В процессе классификации объектов часто строятся информационные модели, которые имеют иерархическую структуру. В биологии весь животный мир рассматривается как иерархическая система (тип, класс, отряд, семейство, род, вид), в информатике используется иерархическая файловая система и так далее. В иерархической информационной модели объекты распределены по уровням. Каждый элемент более высокого уровня может состоять из элементов нижнего уровня, а элемент нижнего уровня может входить в состав только одного элемента более высокого уровня. В иерархической структуре элементы распределяются по уровням, от первого (верхнего) уровня до нижнего (последнего) уровня. На первом уровне может располагаться только один элемент, который является «вершиной» иерархической структуры. Основное отношение между уровнями состоит в том, что элемент более высокого уровня может состоять из нескольких элементов нижнего уровня, при этом каждый элемент нижнего уровня может входить в состав только одного элемента верхнего уровня.
Изображение информационной модели в форме графа. Граф является удобным способом наглядного представления структуры информационных моделей. Вершины графа (овалы) отображают элементы системы.
Элементы верхнего уровня находятся в отношении «состоять из» к элементам более низкого уровня. Такая связь между элементами отображается в форме дуги графа (направленной линии в форме стрелки). Графы, в которых связи между объектами несимметричны (как в данном случае), называются ориентированными.
Статическая иерархическая модель. Рассмотрим процесс построения информационной модели, которая позволяет классифицировать современные компьютеры. Класс Компьютеры можно разделить на три подкласса: Суперкомпьютеры, Серверы и Персональные компьютеры.
Компьютеры, входящие в подкласс Суперкомпьютеры, отличаются сверхвысокой производительностью и надежностью и используются в крупных научно-технических центрах для управления процессами в реальном масштабе времени.
Компьютеры, входящие в подкласс Серверы, обладают высокой производительностью и надежностью и используются в качестве серверов в локальных и глобальных сетях.
Компьютеры, входящие в подкласс Персональные компьютеры, обладают средней производительностью и надежностью и используются в офисах и дома для работы с различными приложениями.
Подкласс Персональные компьютеры делится, в свою очередь, на Настольные, Портативные и Карманные компьютеры.
В рассмотренной иерархической модели, классифицирующей компьютеры, имеются три уровня. На первом, верхнем, уровне располагается элемент Компьютеры, в него входят три элемента второго уровня Суперкомпьютеры, Серверы и Персональные компьютеры. В состав последнего входят три элемента третьего, нижнего, уровня Настольные, Портативные и Карманные компьютеры.
Изобразим иерархическую модель, классифицирующую компьютеры, в виде графа (рис. 2.5).
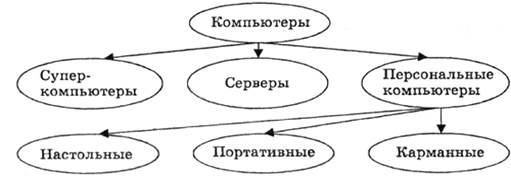 |
| Рис. 4.5.1. Классификация компьютеров |
Полученный граф напоминает дерево, которое растет сверху вниз, поэтому иерархические графы иногда называют деревьями.
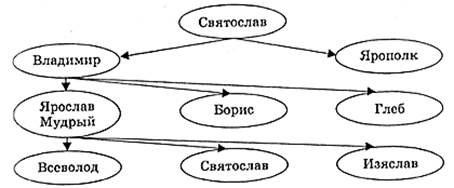
Динамическая иерархическая модель. Для описания исторического процесса смены поколений семьи используются динамические информационные модели в форме генеалогического дерева. В качестве примера можно рассмотреть фрагмент (X-XI века) генеалогического дерева династии Рюриковичей (рис. 2.6).
IT-блог о веб-технологиях, серверах, протоколах, базах данных, СУБД, SQL, компьютерных сетях, языках программирования и создание сайтов.
Иерархическая база данных. Иерархическая модель данных
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой уже были публикации: Нормальные формы и транзитивная зависимость, избыточность данных в базе данных, типы и виды баз данных, настройка MySQL сервера и файл my.ini, MySQL сервер, установка и настройка, Архитектура СУБД и архитектура баз данных, Сетевая база данных, сетевая модель данных. Я продолжаю рассматривать различные модели данных, и сегодня мы поговорим про иерархическую модель данных или иначе – иерархическую базу данных.
Стоит сказать, что иерархическая база данных является частным случаем сетевой модели данных, о которой мы говорили в предыдущей публикации. Но дело все в том, что и иерархическая модель данных, и сетевые базы данных являются мало эффективными, и постепенно от их использования отказываются. Иерархические и сетевые СУБД остались только в некоторых крупных фирмах, которые наполняли такие базы годами. И сейчас основной проблемой для таких фирм является проблема совместимости иерархических и сетевых баз данных с реляционными базами данных. Ну а сегодня мы просто поговорим про иерархическую базу данных.
Иерархическая модель данных
Иерархическая модель данных является частным случаем сетевой модели данных, структура иерархической базы данных немного проще сетевой и, соответственно, иерархические базы данных даже менее эффективны, чем сетевые. Иерархическая модель данных, как и сетевые БД опирается на теорию графов.
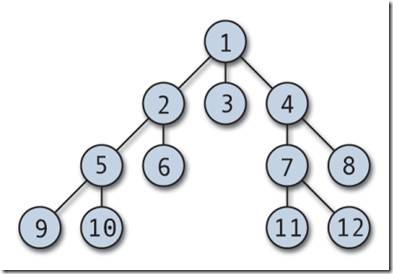
Иерархическая база данных. Иерархическая модель данных.
В основе иерархической модели данных лежит один главный элемент (главный узел), с которого все и начинается, такой элемент называет корневым элементом, в теории графов это называется корнем дерева. Вообще, по сути, что сетевая база данных, что иерархическая база данных имеет древовидную структуру. Все элементы или узлы, которые находятся ниже корневого узла иерархической модели, являются потомками корня. Стоит сказать, что и иерархическая база данных, и сетевая база данных оптимизированы на чтение информации из БД, но не на запись информации в базу данных, эта особенность обусловлена самой моделью данных.
Узлы дерева, которые находятся на одном уровне, обычно называются братьями. Узлы, которые находятся ниже какого-то определенного уровня, являются дочерними узлами по отношению к нему. Иерархическую модель данных можно сравнить с файловой системой компьютера. Компьютер умеет очень быстро работать с отдельными файлами: удалять конкретный файл, редактировать файл, копировать или перемещать файл. Но операция проверки компьютера антивирусом может происходить достаточно длительное время.
Точно такие же особенности присуще иерархической СУБД, то есть базы данных, имеющие иерархическую структуру, умеют очень быстро находить и выбирать информацию и отдавать ее пользователю. Но структура иерархической модели данных не позволяет столь же быстро перебирать информацию. Ну, это видно из рисунка, представленного выше. Допустим, что нам необходимо найти все записи, содержащие слово «сотрудник». Как будет поступать иерархическая СУБД в этом случае? А поступать она будет следующим образом: свой поиск она начнет с корневого элемента иерархической модели данных, проверив его, она начнет проверять его связи, если связей будет несколько, то она пойдет проверять в крайний левый дочерний элемент, расположенный на уровень ниже.
Затем иерархическая СУБД проверит содержимое этого элемента и его связи, если связей опять будет несколько, то она отправится опять-таки в крайний левый дочерний элемент, чтобы проверить его содержимое, проверив его содержимое она увидит, что у этого узла нет дочерних элементов и вернется в родительский узел этого узла, чтобы проверить, есть ли у него еще дочерние элементы. И так постепенно, узел за узлом, спуская и поднимаясь по иерархии узлов СУБД переберет все узлы и выдаст нам все записи, в которых есть слово «сотрудник». Ну, думаю, что с иерархической моделью данных мы более-менее разобрались (если не разобрались, то пишите в комментарии), можно приступить к рассмотрению структуры иерархической базы данных.
Структура иерархической базы данных
Самые первые в мире СУБД использовали иерархическую модель данных, иерархические базы данных появились даже раньше, чем сетевая модель хранения данных. Поэтому структура иерархической базы данных немного проще, чем структура сетевой БД. И так, основными информационными единицами иерархической модели данных являются сегмент и поле. Поле данных является наименьшей неделимой информационной единицей иерархической базы данных, доступной пользователю. У сегмента данных можно определить его тип и экземпляр сегмента.
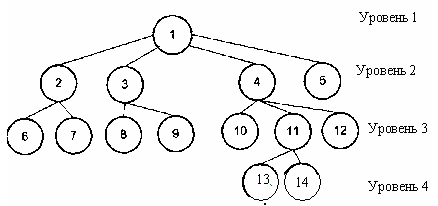
Иерархическая база данных. Иерархическая модель данных.
Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента – это именованная совокупность всех типов полей данных, входящих в данный сегмент. Если ориентироваться по рисунку выше, то тип сегмента – это родительский элемент и все его дочерние элементы. Как я уже говорил: иерархическая модель данных базируется на теории графов, но если структура сетевой БД описывается ориентированным графом (графом со стрелочками), то структура иерархической базы данных описывается неориентированным графом. Характерной особенностью структуры иерархической модели данных является то, что у любого потомка или дочернего элемента может быть только один предок или родительский элемент.
Каждый узел иерархического дерева или каждый элемент иерархической базы данных является сегментом данных. Линии, соединяющие сегменты – это связи между информационными объектами иерархической базы данных. Рисунок должен внести дополнительную ясность:
На концептуальном уровне иерархическая база данных является частным случаем сетевой модели данных.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую модель данных происходит аналогично преобразованию в сетевую модель данных, но существую некоторые тонкости, о которых мы и поговорим. Эти тонкости связаны с тем, что структура иерархической базы данных должна быть представлена в виде дерева, то есть данные иерархической модели должны быть организованы в виде дерева.
Как вы помните: дуги, соединяющие узлы между собой, – это связи. Связи бывают один к одному и один ко многим. Преобразование связей один ко многим происходит автоматически в том случае, если потомок иерархического дерева имеет только одного предка. Происходит это следующим образом: Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком. Согласитесь, что преобразование в иерархическую модель данных похоже на преобразование в сетевую модель.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Управление иерархическими данными
У иерархической модели данных существует два средства управления данными: языковые средства описания данных (ЯОД) и языковые средства манипулирования данными (ЯМД). Физическая структура иерархической базы данных описывает: логическую структуру иерархической модели данных и саму структуру хранения базы данных.
При этом способ доступа устанавливает способ организации взаимосвязи физических записей. Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо того, что обязательно должно быть задано имя иерархической базы данных и способа доступа к каждому элементу иерархической модели данных, описание иерархической БД должно содержать определение типов каждого сегмента данных, входящих в базу данных, в соответствие с выстроенной иерархией. Описание типов сегмента следует начинать с корня иерархической модели. Особенностью иерархических баз данных является то, что каждая физическая база данных может содержать только один корень, но в одной иерархической системе может находиться несколько физических баз данных.
Среди операторов манипулирования данными для иерархической базы данных можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической модели данных не так уж обширен, но этого набора вполне достаточно для управления и поддержания иерархических баз данных. Примеры типичных операторов поиска данных:
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
Иерархические информационные модели




![]()
Группа объектов, обладающих одинаковыми общими свойствами, называется классом объектов. Внутри класса объектов могут быть выделены подклассы, объекты которых обладают некоторыми особенными свойствами, в свою очередь подклассы могут делиться на еще более мелкие группы и так далее. Такой процесс систематизации объектов называется процессом классификации.
В процессе классификации объектов часто строятся ИМ, которые имеют иерархическую структуру. В биологии весь животный мир рассматривается как иерархическая система (тип, класс, отряд, семейство, род, вид), в информатике используется иерархическая файловая система и так далее.
Статическая иерархическая модель.
В иерархической структуре элементы распределяются по уровням, от первого (верхнего) уровня до нижнего (последнего) уровня. На первом уровне может располагаться только один элемент, который является «вершиной» иерархической структуры. Основное отношение между уровнями состоит в том, что элемент более высокого уровня может состоять из нескольких элементов нижнего уровня, при этом каждый элемент нижнего уровня может входить в состав только одного элемента верхнего уровня.
Изобразим иерархическую модель, классифицирующую компьютеры, в виде графа (рис. 1).
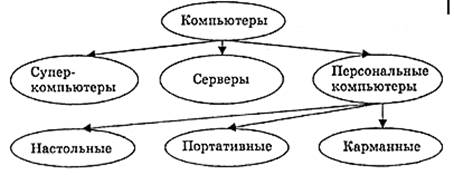
Полученный граф напоминает дерево, которое растет сверху вниз, поэтому иерархические графы иногда называют деревьями.
Динамическая иерархическая модель. Для описания исторического процесса смены поколений семьи используются динамические ИМ в форме генеалогического дерева. В качестве примера можно рассмотреть фрагмент (X-XI века) генеалогического дерева династии Рюриковичей (рис. 2).
ВОПРОС 19 Матричная логико-информационная модель
Матричная информационная модель (МИМ)составляется в виде шахматной таблицы. По строкам и колонкам таблицы записываются шифры документов и показателей, а на пересечение строк и колонок условными знаками изображаются их взаимосвязи.
МИМ представляет собой таблицу, отражающую соответствующие взаимосвязи всех подразделений предприятия и его окружения ( через движение документов и показателей), а также формирование новых данных в процессе функционирования системы управления.
МИМ отражает во взаимоувязанной форме характеристику любого подразделения (отдела), выполняющего определенные функции управления, и всего аппарата управления в целом и содержит сведения о документах, процессах движения и обработки, деятельности управленческого персонала.
МИМ отражает соответствующие взаимосвязи между всеми подразделениями предприятия и его окружением (через движение документов и его показателей), а также формирование новых данных в процессе функционирования системы управления. Она состоит из четырех квадрантов и вспомогательных разделов, каждый из которых имеет свое специфическое содержание и назначение.
МИМ состоит из двух квадрантов и двух вспомогательных разделов. Наиболее важное значение в МИМ имеет II квадрант, в котором представлены документы и показатели, используемые в системе.
МИМ представляет собой таблицу, отражающую соответствующие взаимосвязи между всеми подразделениями предприятия и его окружением (через движение документов и показателей), а также формирование новых данных в процессе функционирования системы управления.
МИМ представляет собой таблицу, отражающую информационные связи между подразделением организации и ее окружением, движение документов и показателей, формирование новых данных в процессе функционирования системы управления.
МИМ документооборота строится для каждого подразделения. В ней концентрируются практически все сведения, необходимые для последующего проектирования более совершенной информационной системы, в том числе и автоматизированной.
Для построения МИМ используются следующие исходные данные, получаемые в результате обследования, заполнения специальных анкет и предварительной обработки материалов обследования: перечень наименований документов, поступающих в подразделение; перечень наименований документов, разрабатываемых данным подразделением; перечень наименований всех выходящих документов с указанием их адреса; наименование показателей, содержащихся в каждом конкретном документе, поступающем в подразделение.

Основной недостаток МИМ состоит в том, что они не позволяют отразить технологию обработки документов, алгоритмы формирования показателей. Поэтому анализ информационной системы с помощью матричных информационных моделей не может быть достаточно полным и необходимы дополнительные методы и средства анализа.
ВОПРОС 20 Математические модели анализа информационных потоков
Одним из важнейших моментов при проектировании автоматизированных ИС (АИС) является рассмотрение информационных потоков, циркулирующих на предприятии. Эти потоки являются отражением любой хозяйственно-производственной деятельности и имеют центральное значение. Для проведения анализа потоков возникает задача создания математической модели информационных потоков, циркулирующих на предприятии. Целью построения модели является проведение анализа существующего положения на объекте автоматизации. В таком случае информационная модель (ИМ) может служить основой для проведения различных исследований:
— количественного анализа документооборота и организационной структуры, на основе которого в дальнейшем можно проводить оптимизацию и реорганизацию потоков информации, а также на основе количественных характеристик документооборота возможно проведение обоснованного расчета характеристик информационной сети предприятия;
— построения визуальной ИМ, например, построенные с помощью инструментальных CASE-средств.
Исходными данными для построения ИМ предприятия являются результаты, полученные в результате проведения обследования предприятия. Результатом обследования является хорошо упорядоченная и систематизированная БД, которая содержит н себе полную информацию о документообороте решаемых на предприятии задачах.
Для проведения информационного анализа необходима модель, которая наиболее полно отражает количественные характеристики информационных потоков. Учитывая большой размер современных предприятий и соответственно объемы документооборота, нужно ориентироваться на автоматизированную работу с моделью: ее построение и анализ. Для математического описания информационных потоков на предприятии хорошо подходят матричные модели, которые позволяют исследовать потоки данных между различными структурными элементами (отделы, службы, рабочие места) в различных разрезах. Модель в таком виде описывается с помощью набора матриц определенного вида, а преобразования модели производятся с помощью стандартных матричных операций.
За счет такого представления можно значительно сократить количество промежуточных операций при анализе и упростить алгоритмы обработки модели.
Основными компонентами математической модели, в отличие от используемых для обобщенного описания предприятия являются:
X = <х,. х2, …, хm> – совокупность сведений, подлежащих сбору, переработке и хранению в системе;
D =
Исходными данными для построения информационной модели предприятия являются результаты, полученные в результате проведения обследования предприятия. Будем считать, что обследование проводилось по «объединенной» методике. В таком случае результатом обследования является хорошо упорядоченная и систематизированная база данных, которая содержит в себе полную информацию о документообороте решаемых на предприятии задачах.
Основные элементы математической модели (матрицы):
| Название матрицы | Множества | Размерность | Характеристика |
| А1 | D x P | (m, q) | Документы по структурным элементам |
| А2 | Р х Р | (q, q) | Взаимосвязь структурных элементов |
| А3 | D x X | (m, r) | Информационное содержание документов |
| А4 | D x Z | (m. p) | Документов по задачам |
| А5 | Z x P | (p, q) | Задач по структурным элементам |
Также параметры информационных потоков характеризует вектор-столбец V, отражающий средний объем документов.
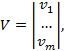 где Vi – средний объем документа. Данный вектор используется для получения среднего объема информационных потоков.
где Vi – средний объем документа. Данный вектор используется для получения среднего объема информационных потоков.
Под построением математической модели, будем подразумевать процесс перехода от данных представленных в виде информационной базы (полученной на этапе обследования) к математической модели в виде набора матриц определенного вида. В процессе построения производится преобразование количественных и временных характеристик документооборота в значения интенсивностей. Данный процесс может быть формализован и представлен в виде алгоритма. На основе алгоритма возможно создание инструментальных средств, предназначенных для автоматизированного перехода от реляционного представления собранных данных к матричной модели информационных потоков на предприятии.
На основе полученной модели производится анализ – получение различных значений (числовых и качественных), которые характеризуют информационные процессы на предприятии. Примером таких величин могут являться: а) степень информационной загруженности структурных элементов; б) соотношение входящей/внутренней/исходящей информации для каждого элемента, для выявления основных генераторов и потребителей информации: в) дублирование информационных потоков; г) степень информационного взаимодействия структурных элементов; и др.
По данным характеристикам могут быть выработаны рекомендации по оптимизации информационных потоков: необходимость структурной реорганизации, целесообразность автоматизации элемента и т.п.
Существуют ограничения на состояния системы, управление и наблюдаемость переменных, которые можно разделить на два рода:
— ограничения первого рода, обусловленные действием законов и закономерностей природы;
— ограничения второго рода, обусловленные конечной величиной ресурсов, а также различных величин, которые не могут или не должны превосходить определенных пределов.
Теория управления организационными системами изучает не любые системы, а только определенный класс систем, в состав которых входят коллективы людей. Эти системы часто называют просто организациями. Наличие коллективов людей приводит к тому, что организационные системы как системы управления обладают следующими особенностями:
— сложной организацией, т. е. сложной структурой с большим количеством связей и сложной программой;
— сложным поведением в меняющейся среде;
— адаптивной устойчивостью поведения, т. е. одна и та же линия поведения системы может быть реализована при различном состоянии окружающей среды;
— наличием информационных процессов с обязательным включением стадий преобразования циркулирующей в системе информации.
ВОПРОС 21 Разработка обобщенного алгоритма работы АИС
Общность процессов управления в объектах разной природы проявляется в механизме обратной связи и информационной основе управления. Она обусловливает принципиальную возможность моделирования экономических процессов и использование ЭВМ для управления экономическими объектами. Статическая теория информации и аналогичные ей теории не получили распространения в управлении экономическими объектами. Это связано с тем, что их подход не учитывает специфику экономических данных, характер их использования в управлении. Не учитываются смысловые взаимосвязи, степень необходимости для управления, формы представления, уровень и частота использования, достоверность и другие важные характеристики.
Современные предприятия являются сложными открытыми экономическими системами. Их организационные структуры состоят из множества подсистем и характеризуются большим разнообразием внутренних и внешних связей. Сложность объекта экономики является существенным, а не второстепенным фактором при создании его ИС и в первую очередь ПО ЭИС. Поэтому попытки описать программные объекты ЭИС, абстрагируясь от их сложности, приводит к абстрагированию от их сущности.
Процесс управления в условиях функционирования ЭИС основывается на экономико-организационных моделях, адекватно отражающих характерные структурно-динамические свойства объекта. Адекватность модели означает, прежде всего, ее соответствие объекту в смысле идентичности поведения в условиях, имитирующих реальную ситуацию, поведения моделируемого объекта в части существенных для поставленной задачи характеристик и свойств. Безусловно, полного повторения объекта в модели быть не может, однако несущественными для анализа и принятия управленческого решений деталями можно пренебречь.
Модели представляют собой средства для визуализации, описания, проектирования и документирования архитектуры ЭИС. Модели строятся для того, чтобы понять и осмыслить структуру и поведение экономического объекта с целью облегчения процесса создания ЭИС, документации проектных решений, уменьшения риска получения неработоспособного ПО.
Системы обработки данных (СОД – EDP) предназначены учета и оперативного регулирования (счетов, платежных поручений и т.п.). Горизонт оперативного управления хозяйственными процессами составляет от одного до нескольких дней и реализует регистрацию и обработку событий, например, оформление и мониторинг выполнения заказов, приход и расход материальных ценностей, поступление и расходование денежных средств. Эти задачи имеют итеративный, регулярный характер, выполняются непосредственными исполнителями и регистраторами хозяйственных процессов (рабочими, бухгалтерами и т.д.) и связаны с оформлением и пересылкой документов в соответствии с четко определенными алгоритмами. Результаты хозяйственных операций через экранные формы вводятся в базу данных.
Информационные системы управления (ИСУ – MIS) ориентированы на тактический уровень управления: среднесрочное планирование, анализ и организацию работ в течение нескольких недель (месяцев), например, анализ и планирование поставок, сбыта, составление производственных программ. Для данного класса задач характерны регламентированность и периодическая повторяемость формирования результатных документов и четко определенный алгоритм решения задач. Решение подобных задач предназначено для руководителей различных служб предприятий (отделов материально-технического снабжения и сбыта, цехов). Задачи решаются на основе накопленной базы оперативных данных.
Системы поддержки принятия решений (СППР – DSS) используются в основном на верхнем уровне управления (руководство фирм, предприятий, организаций) для решения задач стратегического долгосрочного характера (1 год и более). К таким задачам относятся формирование стратегических целей фирмы, планирование привлечения ресурсов, источников финансирования, выбор места размещения предприятий и т.д. Для задач СППР свойственны недостаточность и противоречивость имеющейся информации, преобладание качественных оценок целей и ограничений, слабая формализация алгоритмов решения. В качестве инструментов обобщения чаще всего используются методы статистического анализа, экспертных оценок, математического и имитационного моделирования.



