- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Курс по сетям
- Redis – что это и для чего?
- Разбираемся с Jenkins. Что это?
- Настройка и использование Docker Compose
- Как стать веб разработчиком?
- LXC, LXD и LXCFS – в чем разница?
- Чем Docker отличается от виртуальной машины?
- Настройка и использование Docker Compose
- Установка Hadoop – надуваем слоника
- Почему Cloudera?
- Требования к железу
- Install cloudera hadoop on windows
- Установка Cloudera Hadoop
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Популярное и похожее
Курс по сетям

Redis – что это и для чего?
Разбираемся с Jenkins. Что это?
Настройка и использование Docker Compose
Как стать веб разработчиком?
LXC, LXD и LXCFS – в чем разница?
Чем Docker отличается от виртуальной машины?
Настройка и использование Docker Compose
Еженедельный дайджест
Установка Hadoop – надуваем слоника
Для чайников и кофейников
4 минуты чтения
В одной из статей мы рассказывали Вам, что такое Hadoop и с чем его едят. В этой статье мы подробно разберем, как развернуть кластер Hadoop с помощью сборки Cloudera.
Обучайся в Merion Academy
Пройди курс по сетевым технологиям
Начать

Почему Cloudera?
Почему мы выбрали именно этот дистрибутив? Дело в том, что на текущий момент он является самым популярным и широко распространенным набором инструментов для работы с большими объемами данных. Кроме того, данный дистрибутив имеет в составе такое решение как Cloudera Manager этот инструмент позволяет без лишних телодвижений развернуть новый кластер, а также осуществлять управление и наблюдение за его состоянием.
Стоит отметить, что распространение элементов данной сборки осуществляется в виде так называемых парселов пакетов информации в бинарной кодировке. Преимуществами такого решения являются упрощенная загрузка, взаимная согласованность компонентов, возможность единовременной активации всех необходимых установленных элементов, текущие (не кардинальные) обновления без прерывания рабочего процесса, а также простота восстановления после возникновения неполадок.
Также важно представлять, для каких целей Вы будете использовать кластеры Hadoop. Это связано с тем, что для выполнения различных задач Вам потребуются разные варианты по аппаратной мощности. Как правило, конфигурации, используемые для хранения данных, имеют повышенную мощность, а значит, и более высокую стоимость.
Требования к железу
Проработав вопросы с железом, нужно подготовить для развертки кластера программную часть. Для установки и работы потребуется любая система на основе Ubuntu, а также популярными вариантами являются различные версии CentOS, RHEL и Debian. Эти сборки находятся в открытом доступе на сайте разработчика, поэтому с подготовкой сложностей возникнуть не должно.
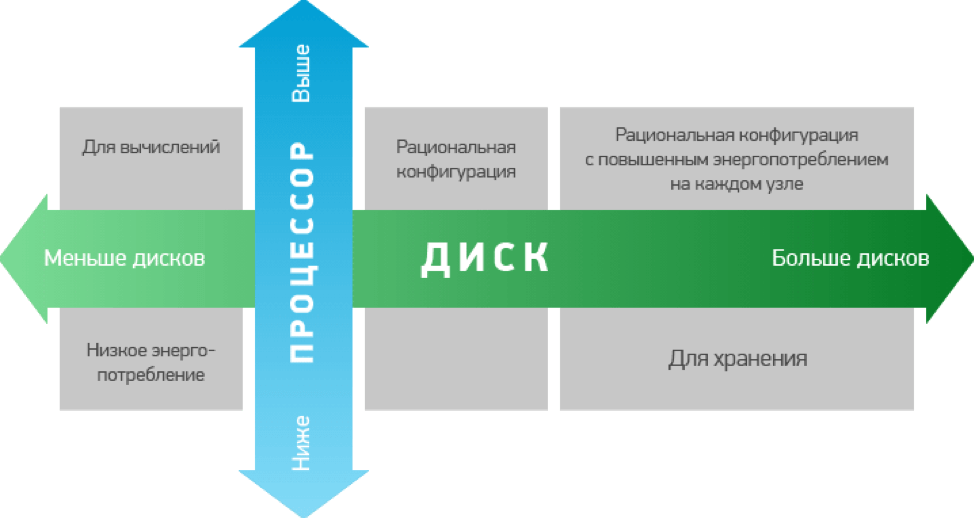
При установке на серверах будущего кластера при разбивке дисков стоит выделять около 70Гб под программную часть, около 1Гб для внутреннего участка памяти для выгрузки данных из кэша, остальную емкость можно оставить непосредственно для хранения данных.
Установка
Подготовив почву для установки, можно приступать непосредственно к процессу. Проверив соединение с серверами, их доступность и синхронизацию, а так же имеют одинаковые пароли root, а так же убедившись, что все сервера имеют доступ к сайту разработчика для обновления программной части, можно устанавливать непосредственно Cloudera Manager. Далее наше участие в процессе установки будет минимальным программа сама установит все необходимые компоненты. По ее завершению, можно запускать стандартную базу данных, и собственно саму программу.
Далее приступим к, собственно, развертыванию кластера. Это удобнее делать через веб-интерфейс. В строку браузера вводим адрес сервера, затем войдем в систему по умолчанию логин и пароль admin и admin разумеется, первым делом меняем пароли.
Далее выбираем версию дистрибутива. Есть бесплатный вариант с ограниченным функционалом, 60-дневная пробная версия и платная лицензия, предоставляющая наиболее полный набор функций, включая поддержку от производителя. При выборе базовой бесплатной версии можно будет в будущем активировать любую из оставшихся. Это актуально в случае, если программа Вам понравится, и вы приобретете базовые навыки работы с кластером.
В процессе установки Cloudera Manager устанавливает соединение с серверами, входящими в кластер. По умолчанию используется root и одинаковое имя пользователя, поэтому важно чтобы пароли root на всех серверах были одинаковы.
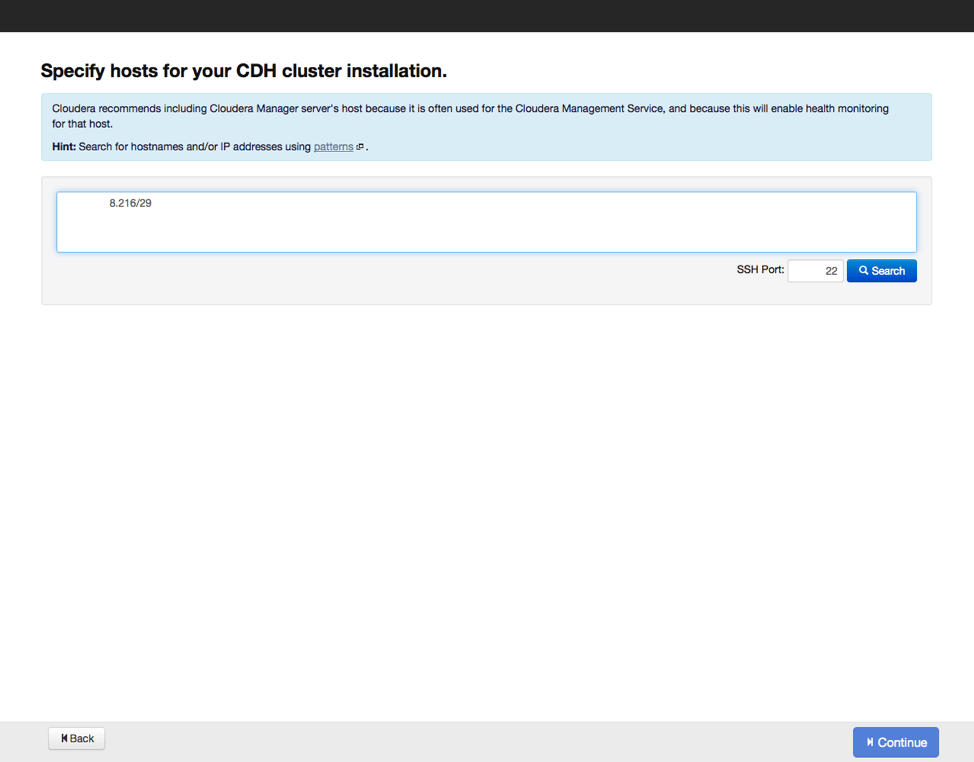
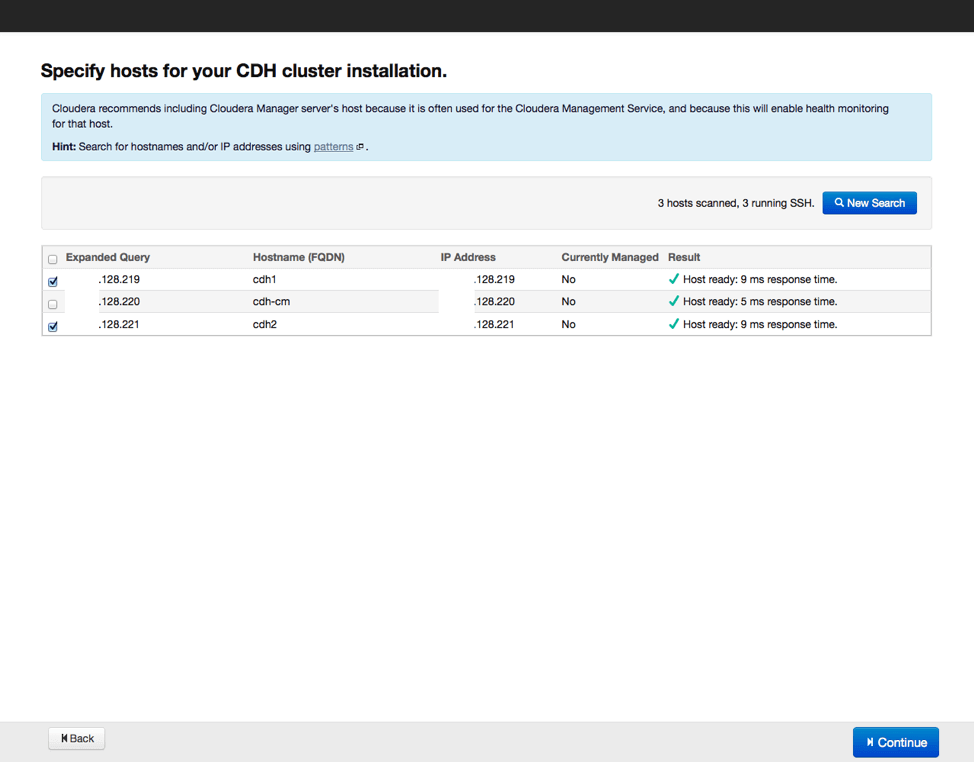
Следующим шагом станет указание хостов, куда будут устанавливаться рабочие элементы Hadoop, а также проверим, все ли сделано верно, и нет ли потерь. Затем выберем репозиторий, из которого будут скачиваться данные для установки, а также выберем вариант с использованием парселов, как и рекомендуется. Можно еще выбрать установку дополнительных инструментов актуальных версий поисковика SOLR и базы данных на основе Impala. Вводим параметры доступа по SSH и запускаем процесс установки.
По окончании установки получаем отчет о всех установленных элементах и их актуальных версиях, после его изучения переходим к следующему этапу выбору вариантов установки дополнительных компонентов Hadoop. Начинающим специалистам рекомендуется выбирать полную установку со временем конфигурацию программных инструментов можно будет менять, удаляя неиспользуемые компоненты и добавляя необходимые. Также программа установки предложит выбрать, какие элементы будут установлены на серверах. Если все сделано правильно вариант «по умолчанию» будет наилучшим выбором.
Далее нас ждет этап настройки базы данных. Настраиваем базу по умолчанию, либо выбираем альтернативный вариант, а также обязательно проверяем, как она работает. После этого настраиваем отдельные элементы в составе нашего кластера и запускаем процесс настройки по выбранным параметрам. По завершению настройки можно переходить к экрану мониторинга кластера, куда выводятся все данные по входящим в кластер серверам.
Install cloudera hadoop on windows
Установка Cloudera Hadoop
Создано 09.03.2017 11:16
Опубликовано 09.03.2017 11:16
Основные компоненты Cloudera Hadoop
Map Reduce (YARN) — модель распределеных вычислений, предназначенная для параллельных вычислений над большими объемами данных. MapReduce работа состоит из двух фаз: map — выполняется параллельно и (по возможности) локально над каждым блоком данных. Вместо того, чтобы доставлять терабайты данных к программе, небольшая, определённая пользователем программа копируется на сервера с данными и делает с ними всё, что не требует перемешивания и перемещения данных (shuffle); reduce — дополняет map агрегирующими операциями.
Spark — инструмент, предназначенный для обработки данных. Он позволяет выполнять различные операции над распределенными коллекциями данных, но не обеспечивает их распределенного хранения. Spark работает быстрее, поскольку данные обрабатываются здесь по-другому. Если MapReduce осуществляет обработку в пошаговом режиме, то Spark оперирует всем набором данных как единым целым. MapReduce действует следующим образом: данные считываются из кластера, выполняется требуемая операция, результаты записываются в кластер, обновленные данные считываются из кластера, выполняется следующая операция, ее результаты записываются в кластер и т.д. А Spark выполняет все аналитические операции в памяти практически в реальном времени: данные считываются из кластера, выполняются необходимые операции, затем полученные результаты записываются в кластер, после чего процесс завершен. Производительности MapReduce, как правило, вполне достаточно, если вы оперируете статическими данными и можете подождать завершения обработки. Но если нужно анализировать потоковые данные тогда имеет смысл обратиться к Spark.
HDFS — распределенная файловая система, работающая на больших кластерах машин. Обычная ФС, по большому счёту, состоит из таблицы файловых дескрипторов и области данных. В HDFS вместо таблицы используется специальный сервер — сервер имён NameNode, а данные разбросаны по серверам данных DataNode. В остальном отличий не так много: данные разбиты на блоки, обычно по 64Мб или 128Мб, для каждого файла сервер имён хранит его путь, список блоков и их реплик.
Pig — язык управления потоком данных и исполнительная среда для анализа больших объемов данных.
Hive — распределенное хранилище данных; оно управляет данными, хранимыми в HDFS, и предоставляет язык запросов на базе SQL для работы с этими данными. Hive может быть использован теми, кто знает язык SQL. Hive создает задания MapReduce, которые исполняются на кластере Hadoop.
Impala — продукт компании Cloudera и основной конкурент Hive. В отличие от последнего, Impala никогда не использовала классический MapReduce, а изначально исполняла запросы на своём собственном движке (написанном, кстати, на нестандартном для Hadoop-а C++). Кроме того, в последнее время Impala активно использует кеширование часто используемых блоков данных и колоночные форматы хранения, что очень хорошо сказывается на производительности аналитических запросов. Так же, как и для Hive, Cloudera предлагает к своему детищу вполне эффективный ODBC-драйвер.
HBase — нереляционная распределенная база данных.
ZooKeeper — распределенный координационный сервис; предоставляет примитивы для построения распределенных приложений.
Sqoop — инструмент для пересылки данных между структурированными хранилищами и HDFS.
Oozie — сервис для записи и планировки заданий Hadoop.
ZooKeeper — главный инструмент координации для всех элементов инфраструктуры Hadoop. Чаще всего используется как сервис конфигурации, хотя его возможности гораздо шире.
Cloudera Hadoop состоит из:
Cloudera Hadoop (CDH) — собственно дистрибутив Hadoop;
Cloudera Manager — инструмент для развертывания, мониторинга и управления кластером Hadoop.
Компоненты Cloudera Hadoop распространяются в виде бинарных пакетов, называемых парселами. По сравнению со стандартными пакетами и пакетными менеджерами парселы имеют следующие преимущества:
простота загрузки: каждый парсел представляет собой один файл, в котором объединены все нужные компоненты;
внутренняя согласованность: все компоненты внутри парсела тщательно протестированы, отлажены и согласованы между собой, поэтому вероятность возникновения проблем с несовместимостью компонентов очень мала;
разграничение распространения и активации: можно сначала установить парселы на все управляемые узлы, а затем активировать их одним действием; благодаря этому обновление системы осуществляется быстро и с минимальным простоем;
обновления “на ходу”: при обновлении минорной версии все новые процессы (задачи) будут автоматически запускаться под этой версией, уже запущенные задачи продолжат исполняться в старом окружении до своего завершения. Однако обновление до более новой мажорной версии возможно только посредством полного перезапуска всех сервисов кластера, и соответственно всех текущих задач;
простой откат изменений: при возникновении каких-либо проблем в работе с новой версией CDH ее можно легко откатить до предыдущей.
Установка Cloudera Manager
Перед установкой нужно обязательно убедиться в том, что:
все входящие в кластер серверы доступны по ssh, и у них установлен один и тот же пароль root (или добавлен публичный ssh ключ);
на всех серверах установлен ntp и настроена синхронизация времени, в противном случае хосты будут теряться и моргать красным в мониторинге;
у всех узлов в составе кластера и сервера CM настроены DNS и PTR записи (либо все хосты должны быть прописаны в /etc/hosts всех серверов).
ВАЖНО! Cloudera не рекомендует использовать в рабочей инсталляции встроенную БД, поэтому лучше сразу настраивать внешнюю базу.
Установка и настройка БД postgresql:
# yum install postgresql-server
# systemctl start postgresql
# service postgresql initdb
Hint: the preferred way to do this is now «postgresql-setup initdb»
Initializing database . OK
Правим файл /var/lib/pgsql/data/pg_hba.conf:
local all all peer
host all all 0.0.0.0/0 md5
host all all 127.0.0.1/32 trust
и файл /var/lib/pgsql/data/postgresql.conf:
+ рекомендуемые параметры от клаудеры:
Cloudera в своей документации пишет:
Small to mid-sized clusters — Consider the following settings as starting points. If resources are limited, consider reducing the buffer sizes and checkpoint segments further. Ongoing tuning may be required based on each host’s resource utilization. For example, if the Cloudera Manager Server is running on the same host as other roles, the following values may be acceptable:
Large clusters — Can contain up to 1000 hosts. Consider the following settings as starting points.
max_connection — For large clusters, each database is typically hosted on a different host. In general, allow each database on a host 100 maximum connections and then add 50 extra connections. You may have to increase the system resources available to PostgreSQL, as described at Connection Settings.
shared_buffers — 1024 MB. This requires that the operating system can allocate sufficient shared memory. See PostgreSQL information on Managing Kernel Resources for more information on setting kernel resources.
wal_buffers — 16 MB. This value is derived from the shared_buffers value. Setting wal_buffers to be approximately 3% of shared_buffers up to a maximum of approximately 16 MB is sufficient in most cases.
checkpoint_segments — 128. The PostgreSQL Tuning Guide recommends values between 32 and 256 for write-intensive systems, such as this one.
checkpoint_completion_target — 0.9. This setting is only available in PostgreSQL versions 8.3 and higher, which are highly recommended.
# systemctl enable postgresql
Created symlink from /etc/systemd/system/multi-user.target.wants/postgresql.service to /usr/lib/systemd/system/postgresql.service.
# systemctl restart postgresql
4. Создание баз и ролей:
#sudo -u postgres psql
CREATE ROLE scm LOGIN PASSWORD ‘scm_Eiroo4d’;
CREATE DATABASE scm OWNER scm ENCODING ‘UTF8’;
create user hive with password ‘hive_Uav6aeW’;
CREATE DATABASE metastore OWNER hive ENCODING ‘UTF8’;
Теперь можно приступить к установке менеджера клаудеры.
Установка Cloudera Manager
1. Репозиторий клаудеры http://archive.cloudera.com/cm5/redhat/7/x86_64/cm/cloudera-manager.repo
Тащим его в /etc/yum.repos.d/
2. Установка Oracle JDK
# yum install oracle-j2sdk1.7
3. Установка Cloudera Manager Server Packages
# yum install cloudera-manager-daemons cloudera-manager-server
Правим конфиг сервера в файле /etc/cloudera-scm-server/db.properties:
Готовим ssh.
Все входящие в кластер серверы должны быть доступны по ssh, и у них должен быть установлен один и тот же пароль root или добавлен публичный ssh ключ. Пользователь ssh должен иметь права sudo.
Затем идем по урлу http://master1.hadoop.local:7180/ и несколько скринов разворачивания кластера:











Теперь нужно добавить сервис мониторинга. Для этого жмем Add cloudera management service в главном окне.



А теперь закидываем остальные хосты в кластер:



