- Установка logstash для сбора логов Windows и syslog
- Installing logstash on windows
- Installing from Package Repositoriesedit
- APTedit
- YUMedit
- Installing Logstash on macOS with Homebrewedit
- Starting Logstash with Homebrewedit
- Dockeredit
- Guide On How to Install Logstash for Elasticsearch on Windows
- Introduction
- Prerequisites
- Configuring JDK in Windows
- Install Logstash
- Installing Logstash As a Service
- Conclusion:
- Pilot the ObjectRocket Platform Free!
- Изучаем ELK. Часть II — Установка Kibana и Logstash
- Вступительное слово
- План действий
- Скачиваем и устанавливаем Kibana
- Установка из Deb пакета
- Установка из RPM пакета
- Установка из архива tar.gz
- Настраиваем Kibana для работы с кластером Elasticsearch
- Настраиваем балансировку нагрузки между Kibana и Elasticsearch
- Установка и настройка Elasticsearch
- Настраиваем Kibana
- Настраиваем несколько экземпляров Kibana
- Скачиваем и устанавливаем Logstash
- Установка из Deb пакета
- Установка из RPM пакета
- Установка из архива
- Настраиваем Logstash для чтения данных из файла
- Смотрим полученные данные в Kibana
- Заключение
Установка logstash для сбора логов Windows и syslog
Устанавливаем Java 8
Устанавливаем elasticsearch
Редактируем конфиг /etc/elasticsearch/elasticsearch.yml:
Добавляем в автозагрузку:
Устанавливаем logstash
Создаём файл c patterns для разбора логов cisco:
Проверяем конфиг на ошибки, запускаем, и вносим в автозапуск:
Пример успешной работы:
Устанавливаем kibana
Редактируем конфиг /etc/kibana/kibana.yml:
Создаем файл шаблона индекса beats:
Создаем файл шаблона индекса syslog:
Загружаем шаблоны в elasticsearch:
Установка Windows агента отправки логов
Скачиваем https://download.elastic.co/beats/winlogbeat/winlogbeat-1.3.1-windows.zip. Распаковываем в C:\ и переименовываем в Winlogbeat. Запускаем PowerShell от админа и устанавливаем сервис:
Если мы видим сообщение о том что скрипты отключены в системе по умолчанию (а так оно и будет), то мы просто создаём политику для Winlogbeat:
Перед стартом сервиса правим в конфиге — C:\Winlogbeat\winlogbeat.yml.
В блоку event_logs перечислены основные журналы системы, которые нужно транспортировать на Logstash:
В event_logs можно добавить и другие журналы, список которых можно посмотреть так:
Если система выше Vista, то можно указать каналы:
Далее нам нужно загрузить на сервер индексы для winlogbeat как мы это делали для topbeat, filebeat, packetbeat. Это можно сделать удалённо:
Полезное
При длительной инициализации идекса Kibana можно удалить индексы с состоянием RED.
Удаление всех индексов (Внимание! Слетят все настройки Kibana):
Вместо * можно указать неугодный индекс, например:
Для удаление старых логов не обходимо установить «питоновский» модуль:
Installing logstash on windows
The Logstash binaries are available from https://www.elastic.co/downloads. Download the Logstash installation file for your host environment—TARG.GZ, DEB, ZIP, or RPM.
Unpack the file. Do not install Logstash into a directory path that contains colon (:) characters.
These packages are free to use under the Elastic license. They contain open source and free commercial features and access to paid commercial features. Start a 30-day trial to try out all of the paid commercial features. See the Subscriptions page for information about Elastic license levels.
Alternatively, you can download an oss package, which contains only features that are available under the Apache 2.0 license.
On supported Linux operating systems, you can use a package manager to install Logstash.
Installing from Package Repositoriesedit
We also have repositories available for APT and YUM based distributions. Note that we only provide binary packages, but no source packages, as the packages are created as part of the Logstash build.
We have split the Logstash package repositories by version into separate urls to avoid accidental upgrades across major versions. For all 7.x.y releases use 7.x as version number.
We use the PGP key D88E42B4, Elastic’s Signing Key, with fingerprint
to sign all our packages. It is available from https://pgp.mit.edu.
APTedit
Download and install the Public Signing Key:
You may need to install the apt-transport-https package on Debian before proceeding:
Save the repository definition to /etc/apt/sources.list.d/elastic-7.x.list :
Use the echo method described above to add the Logstash repository. Do not use add-apt-repository as it will add a deb-src entry as well, but we do not provide a source package. If you have added the deb-src entry, you will see an error like the following:
Just delete the deb-src entry from the /etc/apt/sources.list file and the installation should work as expected.
Run sudo apt-get update and the repository is ready for use. You can install it with:
See Running Logstash for details about managing Logstash as a system service.
YUMedit
Download and install the public signing key:
Add the following in your /etc/yum.repos.d/ directory in a file with a .repo suffix, for example logstash.repo
And your repository is ready for use. You can install it with:
The repositories do not work with older rpm based distributions that still use RPM v3, like CentOS5.
See the Running Logstash document for managing Logstash as a system service.
Installing Logstash on macOS with Homebrewedit
Elastic publishes Homebrew formulae so you can install Logstash with the Homebrew package manager.
To install with Homebrew, you first need to tap the Elastic Homebrew repository:
After you’ve tapped the Elastic Homebrew repo, you can use brew install to install the default distribution of Logstash:
This installs the most recently released default distribution of Logstash. To install the OSS distribution, specify elastic/tap/logstash-oss .
Starting Logstash with Homebrewedit
To have launchd start elastic/tap/logstash-full now and restart at login, run:
To run Logstash, in the foreground, run:
Dockeredit
Images are available for running Logstash as a Docker container. They are available from the Elastic Docker registry.
See Running Logstash on Docker for details on how to configure and run Logstash Docker containers.
Guide On How to Install Logstash for Elasticsearch on Windows
![]()
- Elasticsearch
- Logstash
- Windows
Introduction
Setting parameters for the Elasticsearch service is a simple process that yields tremendous control. As a user, it is important to be able to manage the kind of data that is being recovered. Logstash is made for configuring the filters that enable this potential. By using the easy instructions below, it is possible to install this tool to refine Elasticsearch queries. Then data can be analyzed without sifting through large portions of unwanted information by separating it at the source(s).
Prerequisites
- Elasticsearch is only set up to support 64-bit architecture. Many, if not all, of the Elastic products will have trouble working properly on a 32-bit environment. Elastic Discussion for 32-bit
- The windows system being installed onto should already have JDK 8 running. To verify whether JVM is installed, open the window for command prompt (Just type cmd into the search bar on the main menu) and type C:\ into the command prompt terminal.
- If there’s an error, or if the Window’s command prompt doesn’t understand the command, it means JVM is not installed. Otherwise, if it is running, the terminal output will look like this:
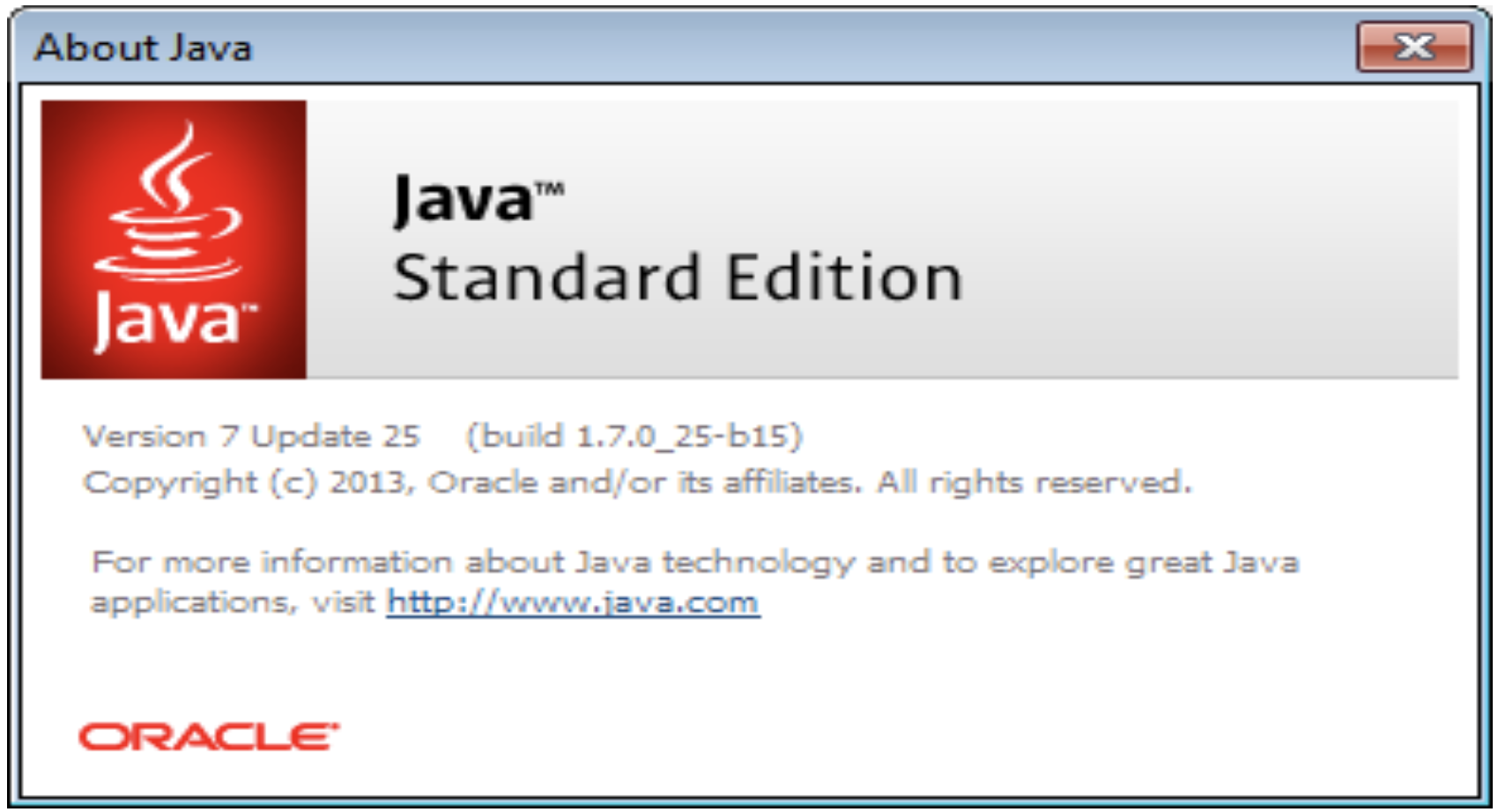
- It can also be checked by opening up the Java application listed in the programs menu and clicking on the «About» tab:

- It is recommended to have Java series 1.8, or later, installed when running Elasticsearch. For more information, or to check the version of Java installed, visit the Java Panel found in the Windows Start Menu.
- To specifically select a Java version to use, it can be directly configured using the JAVA_HOME environment variable. Just right click My Computer and select Properties . Once there, click on the Advanced tab, and select the Environment Variables to edit the JAVA_HOME variable to point the system to the JDK software location, for example: C:\Program Files\Java\jdk1.X.X (make sure to replace X with the proper version number for the installed JDK).
- For more information, consult Oracle’s Java Support Map.
- View supported Windows architecture and supported products in Elastic’s website – Support Matrix
Configuring JDK in Windows
- It is recommended to use a supported LTS (“Long Term Support”) version of Elasticsearch. For more information, consult Oracle’s Java Support Map.
- Download to install the Oracle JDK v8. Select all the defaults.
- Click on the Start button, do a search by typing “Environment Variables” and then open the system properties. The advanced tab under “System Properties” should be visible.
- Click the button for Environment Variables.
- On the System Variables tab click “New”.
- Go into the JDK install directory (type the variable name JAVA_HOME)and click OK. The screen will look just like this:
Install Logstash
- Download the Logstash zip package for Windows on the downloads page for Logstash.
- Extract the zip contents using the system’s unzip tool.
- Logstash must be configured before the application can be run.
- It is necessary to save a config file in the bin folder and give it a meaningful name. As an example using “ logstash.config “, the content is shown below.
input <
# Accept input from the console.
stdin<>
>
filter <
# Add filter here. This sample has a blank filter.
>
output <
# Output to the console.
stdout <
codec => «rubydebug»
>
>
- To initiate Logstash, use the batch file -f flag followed by the config file location typed in the command line.
- To stop Logstash, press CTRL+c and it will stop the current process.
Installing Logstash As a Service
Download the NSSM — Non-Sucking Service Manager from NSSM Homepage.
Extract the EXE to the BIN directory of the Logstash location created earlier.
Navigate to the bin directory, then execute the following from the shell.
- The NSSM dialog should now be visible.
- In the path application field, provide the location where the Logstash.bat file is located.
- In the startup directory field, provide the full path of the bin directory.
- Lastly in the arguments Enter the following sample arguments
- Other options are available, but for this purpose, those will all be left on their defaults
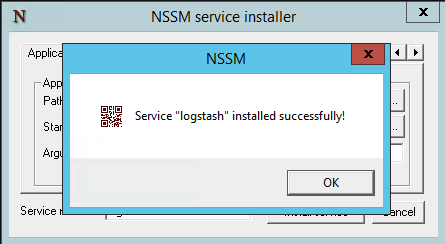
- Click the install service button and confirm the display of a success message. In the powershell, the following message should be seen:
- Open the Task Manager. From the “Services” tab, the program can be started.
Conclusion:
Logstash is a useful tool when monitoring data being generated by any number of sources. It equips the user with a powerful engine that can be configured to refine input/output to only deliver what is pragmatic. It grants the Elasticsearch service the ability to narrow fields of data into relevant collections. It also makes it easy by allowing automation of this process. All that must be done is to enter the correct values as detailed in the tutorial on configuring Logstash when finished installing it following the directions above.
Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Изучаем ELK. Часть II — Установка Kibana и Logstash

Вступительное слово
В предыдущей статье была описана процедура установки Elasticsearch и настройка кластера. В этой статье будет рассмотрена процедура установки Kibana и Logstash, а также их настройка для работы с кластером Elasticsearch.
План действий
Скачиваем и устанавливаем Kibana
Установка из Deb пакета
Импортируем PGP ключ:
Устанавливаем apt-transport-https пакет:
Перед установкой пакета необходимо добавить репозиторий Elastic:
Настраиваем Kibana для автоматического запуска при старте системы:
Так же возможен вариант установки из скаченного Deb пакет с помощью dpkg
Установка из RPM пакета
Импортируем PGP ключ
В директории /etc/yum.repos.d/ создаем файл репозитория kibana.repo для CentOS или Red Hat. Для дистрибутива OpenSUSE в директории /etc/zypp/repos.d/ :
Устанавливаем Kibana c помощью пакетного менеджера в зависимости от операционной системы, yum или dnf для CentOS, Red Hat, Fedora или zypper для OpenSUSE:
Настраиваем Kibana для автоматического запуска при старте системы:
Так же возможен вариант установки из скаченного RPM пакет с помощью rpm
Установка из архива tar.gz
Скачиваем архив c Kibana:
Извлекаем данные и переходим в директорию с Kibana:
Текущий каталог считается как $KIBANA_HOME .
Конфигурационные файлы находятся в каталоге $KIBANA_HOME/config/ .
Для запуска Kibana можно создать отдельного пользователя предоставив все необходимые права к каталогу с Kibana.
Настраиваем Kibana для работы с кластером Elasticsearch
Для настройки Kibana используется YAML файл, который лежит по следующему пути /etc/kibana/kibana.yml при установке из Deb и RPM пакетов или $KIBANA_HOME/config/kibana.yml при установке из архива.
Определяем адрес и порт, на которых будет работать Kibana (по умолчанию localhost:5601 ):
Указываем узлы кластера Elasticsearch:
В случае недоступности узла, с которым Kibana установила соединение, произойдет переключение на другой узел кластера, указанный в конфигурационном файле.
Указываем, где Kibana будет хранить свои логи (по умолчанию stdout ):
Необходимо предоставить доступ на запись к данному каталогу, чтобы Kibana писала логи. В случае установки из пакетов Dep или RPM доступ предоставляется пользователю или группе kibana , а для установки из архива — пользователю, который осуществляет запуск Kibana.
Настраиваем частоту опроса Elasticsearch для получения обновлённого списка узлов кластера:
Определяем, запрашивать ли обновленный список узлов кластера Elasticsearch в случае сбоя соединения с кластером:
В работе опции elasticsearch.sniffInterval обнаружился «баг», при работе с Elasticsearch. После запроса обновления может возникать ошибка:
«statusCode»:401,»error»:»Unauthorized»,»message»:»missing authentication credentials for REST request: security_exception.
Ссылка на BugFix. Исправление будет в версии 7.11.2
На выходе получаем конфигурационный файл:
По умолчанию Kibana имеет ограничение на использование памяти в размере 1,4 Гб. Для изменения этого значения необходимо в файле node.options указать новые значения для параметра —max-old-space-size . Значения указываются в мегабайтах.
Данный файл находится в каталоге /etc/kibana/ при установке из Deb и RPM пакетов или $KIBANA_HOME/config/ — при установке из архива
Запускаем службу kibana :
Для установки из архива используем:
Для выключения службы запущенной из архива используйте Ctrl-C .
В браузере набираем IP адрес и порт (в примере выше это http://10.0.3.1:5601 ), который указывали в конфигурации Kibana. В результате должна открыться приветственная страница.
 Приветственная страница Kibana
Приветственная страница Kibana
Настраиваем балансировку нагрузки между Kibana и Elasticsearch
Для организации балансировки между Kibana и узлами Elastcisearch в Elastcisearch имеется встроенный механизм. На хост c установленной Kibana, ставится Elasticsearch с ролью Coordinating only . Узел Elasticsearch с данной ролью обрабатывает HTTP запросы и распределяет их между узлами кластера.
Установка и настройка Elasticsearch
Устанавливаем Elasticseach на узел с Kibana. Как это сделать описано в предыдущей статье.
Настраиваем новому узлу роль Coordinating only . Для этого для ролей master , data и ingest указываем параметр false :
ingest роль позволяет построить конвейер дополнительной обработки данных до их индексирования. Выделения отдельных узлов с этой ролью снижает нагрузку на другие узлы. Узел с ролью master и/или data не имеют эту роль по умолчанию.
Указываем имя Elasticsearch кластера:
Указываем адреса узлов текущего кластера. Для этого создадим файл unicast_hosts.txt с перечнем узлов в директории с конфигурационными файлами Elasticsearch. Для установки из Deb и RPM пакетов это /etc/elasticsearch/ или $ES_HOME/config / при установке из архива:
Указываем, что адреса узлов кластера нужно брать из файла:
Данный метод имеет преимущество над методом из предыдущей статьи ( discovery.seed_hosts ). Elasticsearch следит за изменением файла и применяет настройки автоматически без перезагрузки узла.
Настраиваем IP адрес и порт для приема запросов от Kibana ( network.host и http.port ) и для коммуникации с другими узлами кластера Elasticsearch (transport.host и transport.tcp.port ). По умолчанию параметр transport.host равен network.host :
Итоговый конфигурационный файл:
Запускаем Elasticsearch и проверяем, что узел присоединился к кластеру:
Теперь в кластере 4 узла, из них 3 с ролью data .
Настраиваем Kibana
В конфигурации Kibana указываем адрес Coordinating only узла:
Перезапускаем Kibana и проверяем, что служба запустилась, а UI Kibana открывается в браузере.
Настраиваем несколько экземпляров Kibana
Чтобы организовать работу нескольких экземпляров Kibana, размещаем их за балансировщиком нагрузки. Для каждого экземпляра Kibana необходимо:
Настроить уникальное имя:
server.name уникальное имя экземпляра. По умолчанию имя узла.
В документации к Kibana указана необходимость настройки server.uuid , однако, в списке параметров конфигурации данный параметр отсутствует. На практике uuid генерируется автоматически и хранится в директории, в которой Kibana хранит свои данные. Данная директория определяется параметром path.data . По умолчанию для установки из Deb и RPM пакетов это /var/lib/kibana/ или $KIBANA_HOME/data/ для установки из архива.
Для каждого экземпляра в рамках одного узла необходимо указать уникальные настройки:
logging.dest директория для хранения логов;
path.data директория для хранения данных;
pid.file файл для записи ID процесса;
server.port порт, который будет использовать данный экземпляр Kibana ;
Указать следующие параметры одинаковыми для каждого экземпляра:
xpack.security.encryptionKey произвольный ключ для шифрования сессии. Длина не менее 32 символов.
xpack.reporting.encryptionKey произвольный ключ для шифрования отчетов. Длина не менее 32 символов.
xpack.encryptedSavedObjects.encryptionKey ключ для шифрования данных до отправки их в Elasticsearch. Длина не менее 32 символов.
xpack.encryptedSavedObjects.keyRotation.decryptionOnlyKeys список ранее использованных ключей. Позволит расшифровать ранее сохраненные данные.
Настройки безопасности( xpack ) ELK будут рассмотрены в отдельной статье.
Чтобы запустить несколько экземпляров Kibana на одном узле, необходимо указать путь к файлу конфигурации каждого из них. Для этого используется ключ -c :
Скачиваем и устанавливаем Logstash
Установка из Deb пакета
Импортируем GPG ключ:
Устанавливаем apt-transport-https пакет:
Добавляем репозиторий Elastic:
Настраиваем Logstash для автоматического запуска при старте системы:
Установка из RPM пакета
Импортируем PGP ключ
В директории /etc/yum.repos.d/ создаем файл репозитория logstash.repo для CentOS или Red Hat. Для дистрибутива OpenSUSE — в директории /etc/zypp/repos.d/
Устанавливаем Logstash c помощью пакетного менеджера в зависимости от операционной системы, yum или dnf для CentOS , Red Hat , Fedora или zypper для OpenSUSE :
Настраиваем Logstash для автоматического запуска при старте системы:
Установка из архива
Скачиваем архив с Logstash:
Извлекаем данные и переходим в директорию с Logstash:
Текущий каталог считается как $LOGSTASH_HOME .
Конфигурационные файлы находятся в каталоге $LOGSTASH_HOME/config/ .
Помимо архива сайта можно скачать Deb или RPM пакет и установить с помощью dpkg или rpm .
Настраиваем Logstash для чтения данных из файла
В качестве примера настроим считывание собственных логов Logstash из директории /var/log/logstash/ . Для этого необходимо настроить конвейер ( pipeline ).
Logstash имеет два типа файлов конфигурации. Первый тип описывает запуск и работу Logstash ( settings files ).
Второй тип отвечает за конфигурацию конвейера ( pipeline ) обработки данных. Этот файл состоит из трех секций: input , filter и output .
Чтобы описать конвейер создаем файл logstash.conf в директории /etc/logstash/conf.d/ , если установка была из Deb и RPM , или в директории $LOGSTASH_HOME/conf.d/ для установки из архива, предварительно создав эту директорию.
Для установки из архива необходимо в конфигурационном файле $LOGSTASH_HOME/config/pipelines.yml указать путь до директории с настройками конвейера:
Для установки из архива также требуется указать, где хранить логи в файле конфигурации $LOGSTASH_HOME/config/logstash.yml :
Не забудьте предоставить доступ на запись к данному каталогу пользователю, который осуществляет запуск Logstash.
В файле logstash.conf настроим плагин file в секции input для чтения файлов. Указываем путь к файлам через параметр path , а через параметр start_position указываем, что файл необходимо читать с начала:
Каждое событие журнала логов будет представлять собой JSON документ и будет записано целиком в поле с ключом message . Чтобы из каждого события извлечь дату, время, источник и другую информацию, необходимо использовать секцию filter .
В секции filter с помощью плагина grok и встроенных шаблонов извлекаем из каждой записи ( message ) журнала логов необходимую информацию:
Шаблон имеет формат %
SEMANTIC — это ключ поля с данными, которые извлекаются с помощью шаблона, и под этим ключом будут храниться в JSON документе.
С помощью параметра match указываем, из какого поля ( message ) извлекаем данные по описанным шаблонам. Параметр overwrite сообщает, что оригинальное поле message необходимо перезаписать в соответствии с теми данными, которые мы получили с помощью шаблона %
Для сохранения данных в Elasticsearch настраиваем плагин elasticsearch в секции output . Указываем адреса узлов кластера Elasticseach и имя индекса.
Индекс ( index ) — оптимизированный набор JSON документов, где каждый документ представляет собой набор полей ключ — значение. Каждый индекс сопоставляется с одним или более главным шардом ( primary shard ) и может иметь реплики главного шарда ( replica shard ).
Что такое индекс, шард и репликация шардов рассмотрю в отдельной статье.
К названию индекса добавлен шаблон % <+YYYY.MM>, описывающий год и месяц. Данный шаблон позволит создавать новый индекс каждый месяц.
Для установки из архива:
Смотрим полученные данные в Kibana
Открываем Kibana, в верхнем левом углу нажимаем меню и в секции Management выбираем Stack Management . Далее слева выбираем Index patterns и нажимаем кнопку Create Index Patern . В поле Index pattern name описываем шаблон logstash* , в который попадут все индексы, начинающиеся с logstash.
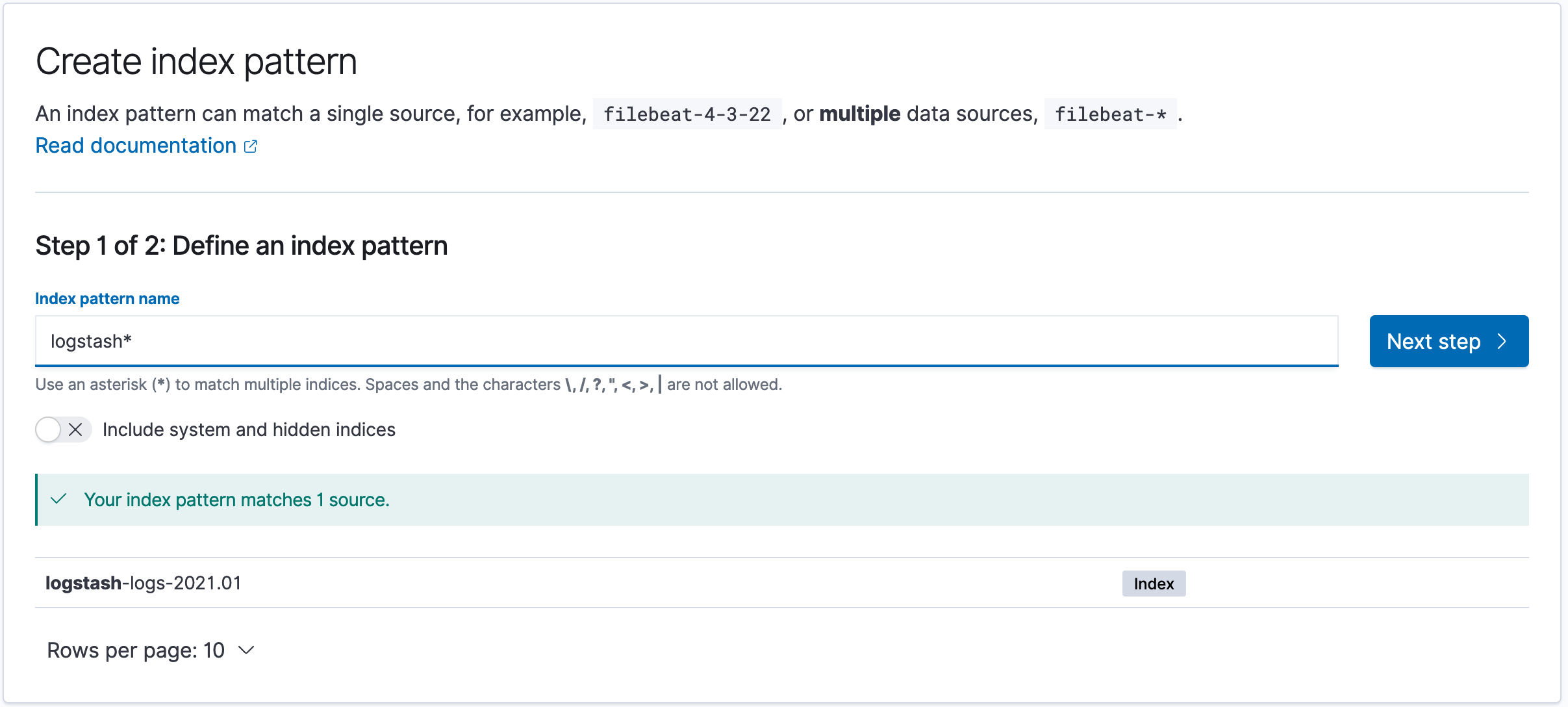 Создание шаблона индекса
Создание шаблона индекса
Жмем Next step и выбираем Time field поле timestamp , чтобы иметь возможность фильтровать данные по дате и времени. После жмем Create index pattern :
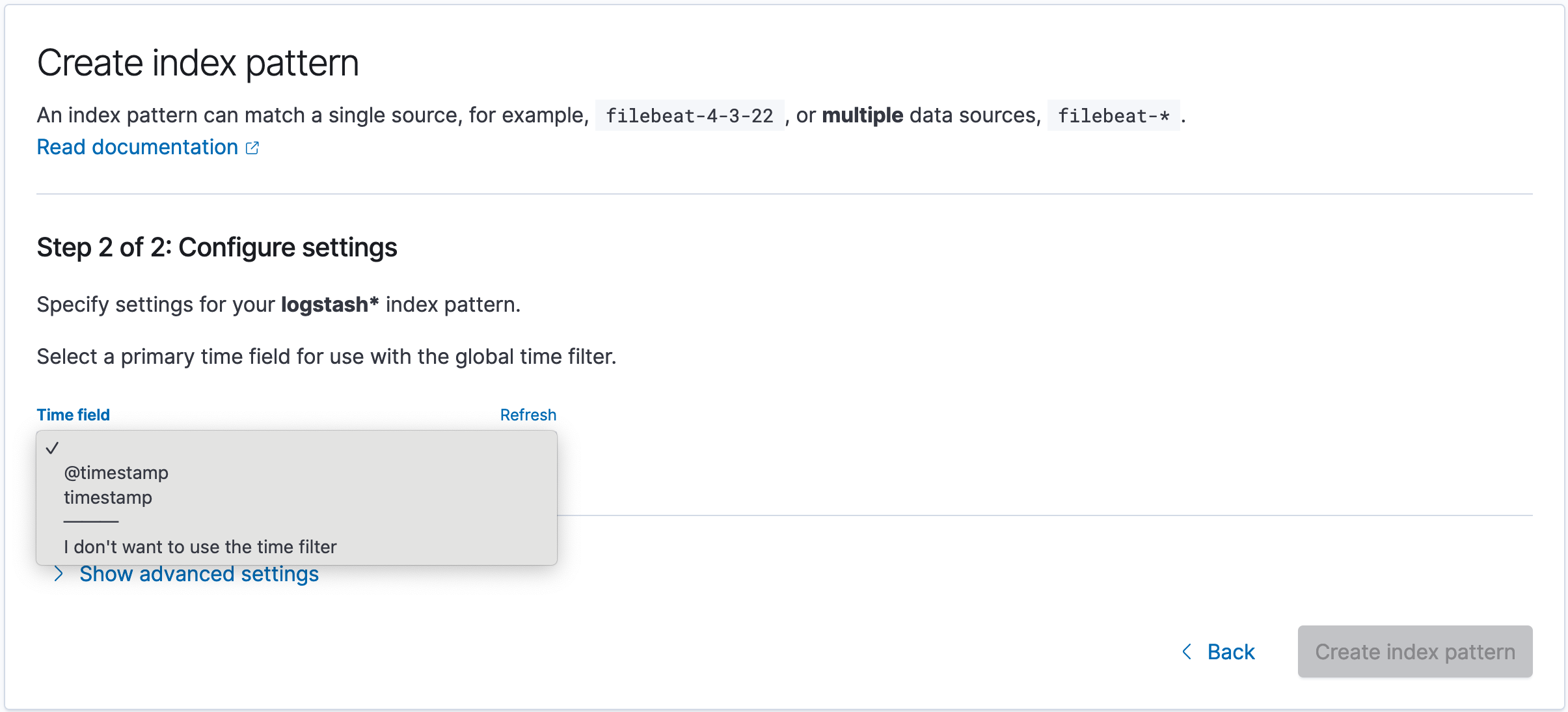 Выбор Time field
Выбор Time field
Logstash при анализе событий добавил поле @timestamp , в результате получилось 2 поля с датой и временем. Это поле содержит дату и время обработки события, следовательно, эти даты могут различаться. Например, если анализируемый файл имеет старые записи, то поле timestamp будет содержать данные из записей, а @timestamp текущее время, когда каждое событие были обработано.
После создания шаблона индексов Kibana покажет информацию об имеющихся полях, типе данных и возможности делать агрегацию по этим полям.
Чтобы посмотреть полученные данные на основе созданного шаблона нажимаем меню и в секции Kiban выбираем Discover .
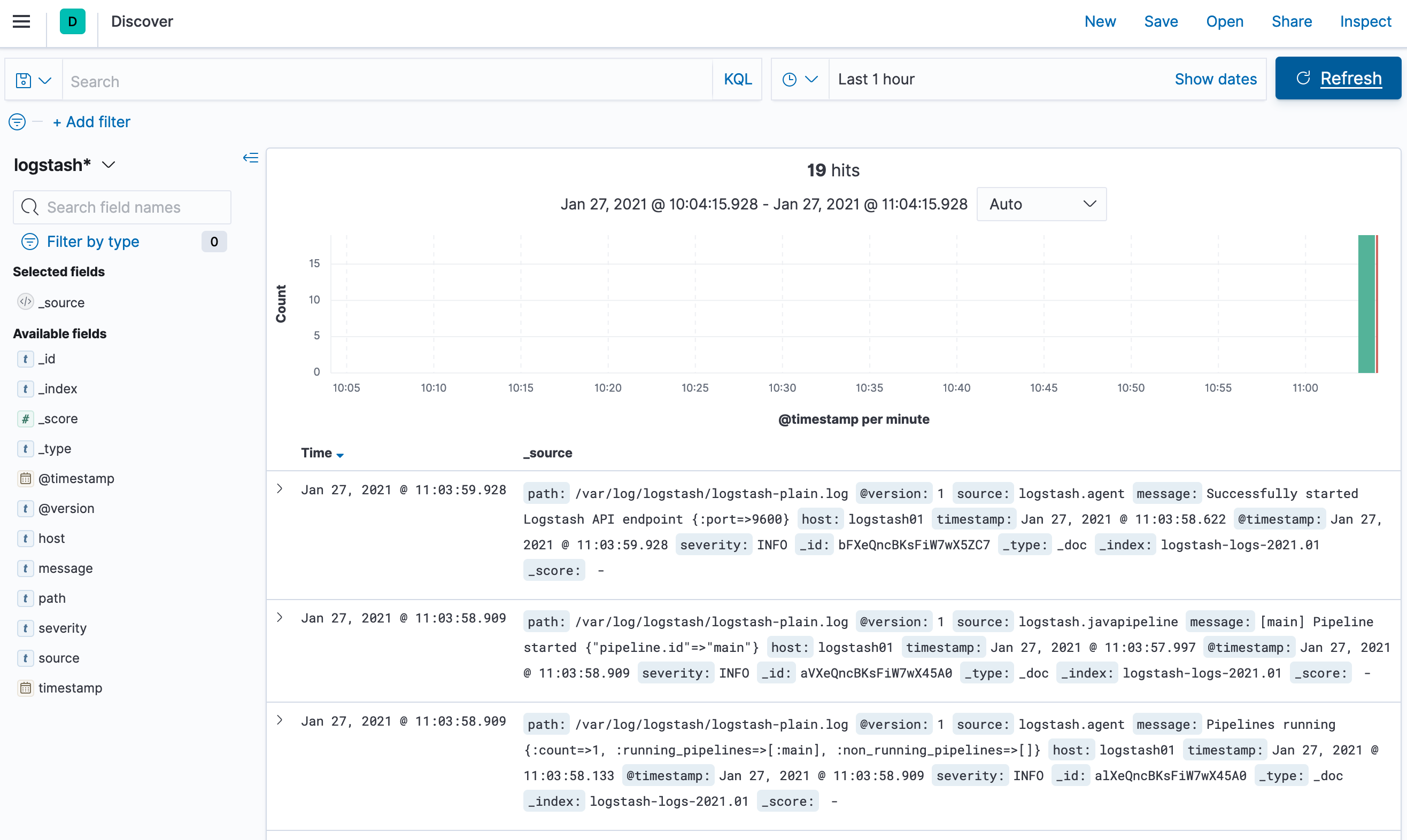 Kibana Discover
Kibana Discover
В правой части экрана можно выбрать интервал в рамках которого отображать данные.
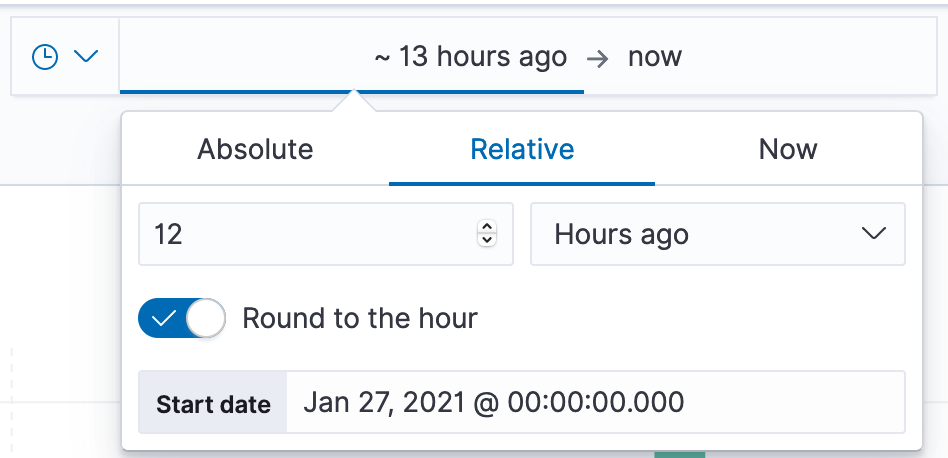 Выбор временного интервала
Выбор временного интервала
В левой часте экрана можно выбрать шаблон индекса или поля для отображения из списка Available fields . При нажатии на доступные поля можно получить топ-5 значений.
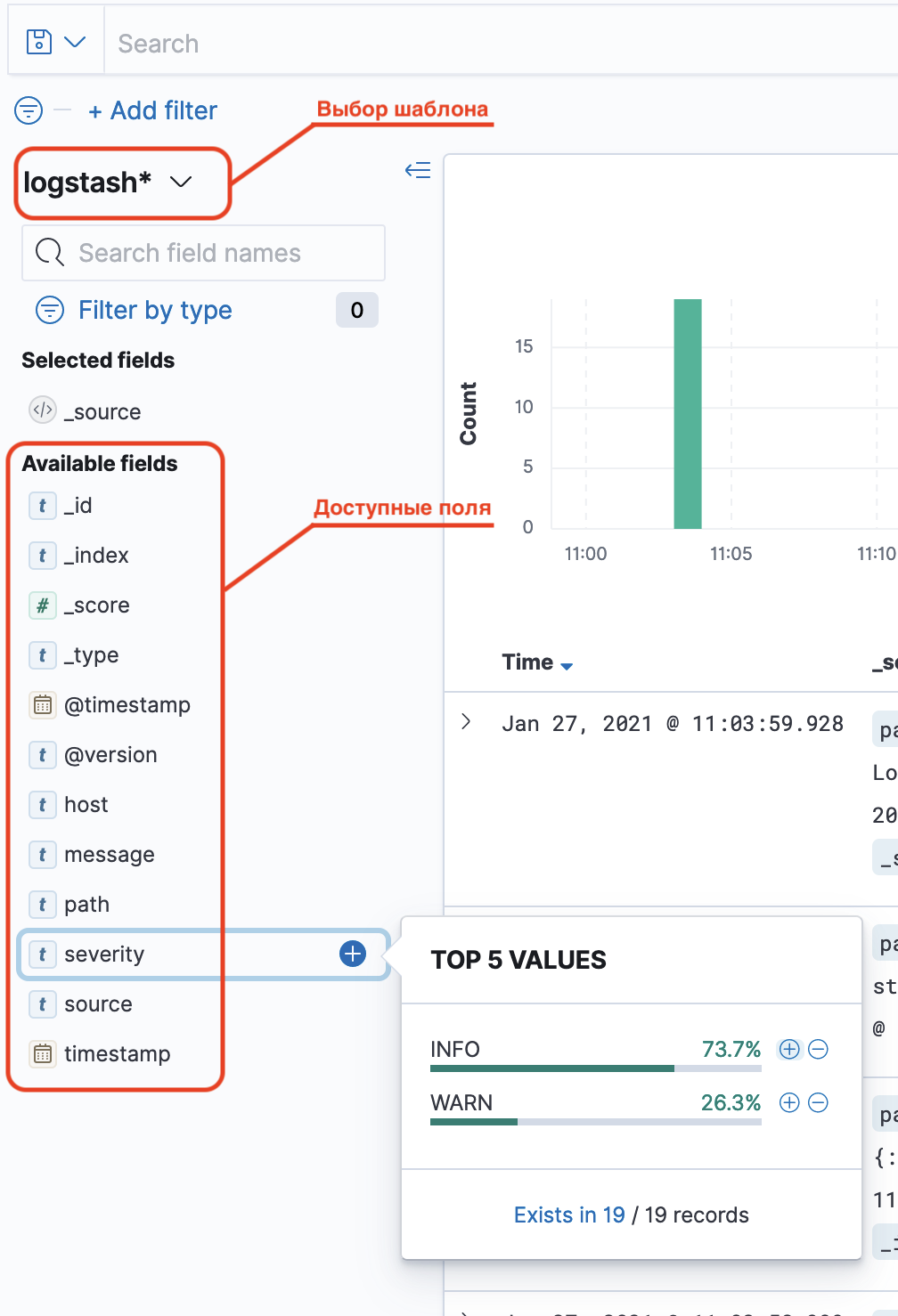 Шаблон индекса и доступные поля
Шаблон индекса и доступные поля
Для фильтрации данных можно использовать Kibana Query Language (KQL) . Запрос пишется в поле Search . Запросы можно сохранять, чтобы использовать их в будущем.
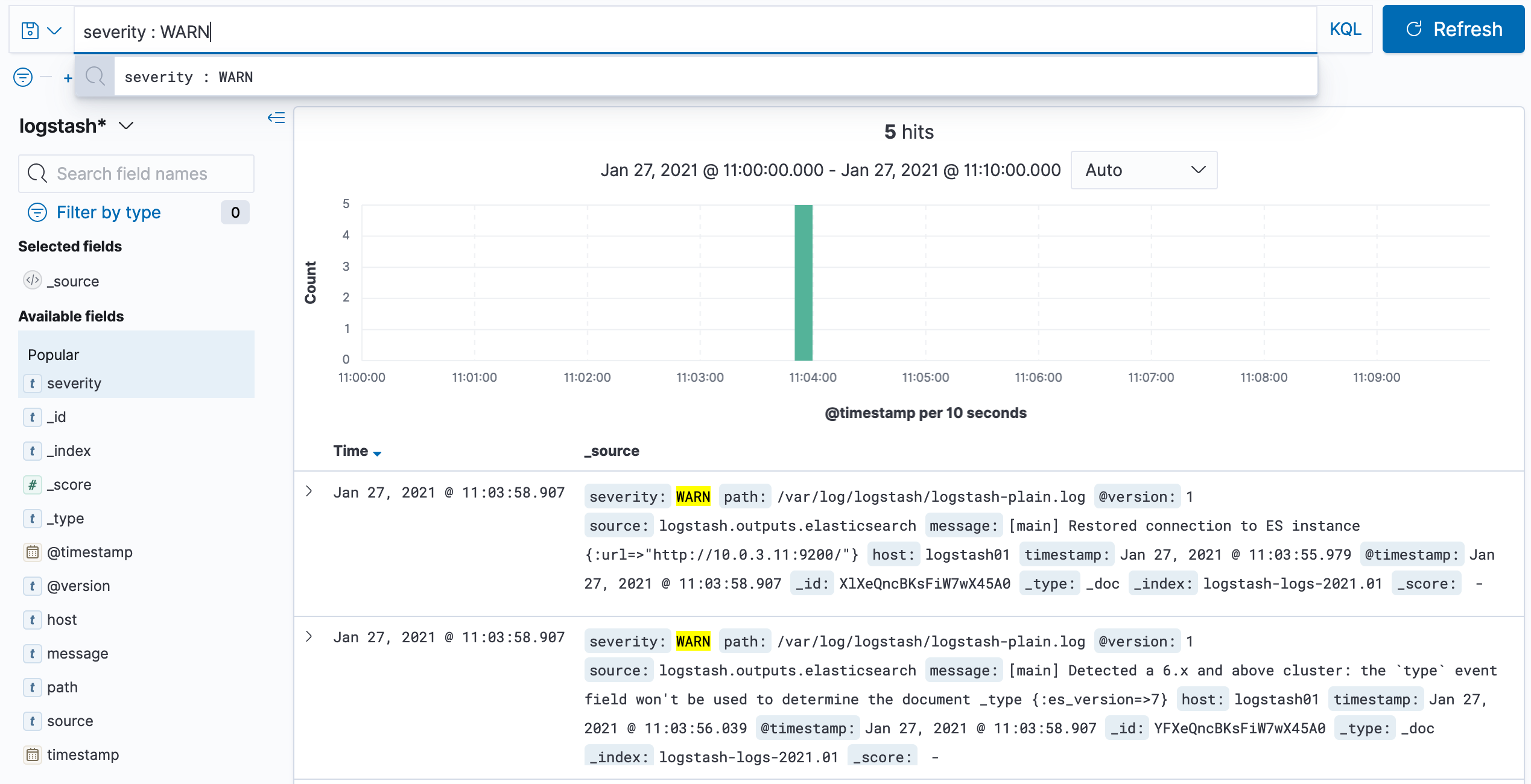 Фильтрация данных с помощью KQL
Фильтрация данных с помощью KQL
Для визуализации полученных данных нажимаем меню и в секции Kiban выбираем Visualize . Нажав Create new visualization , откроется окно с перечнем доступных типов визуализации.
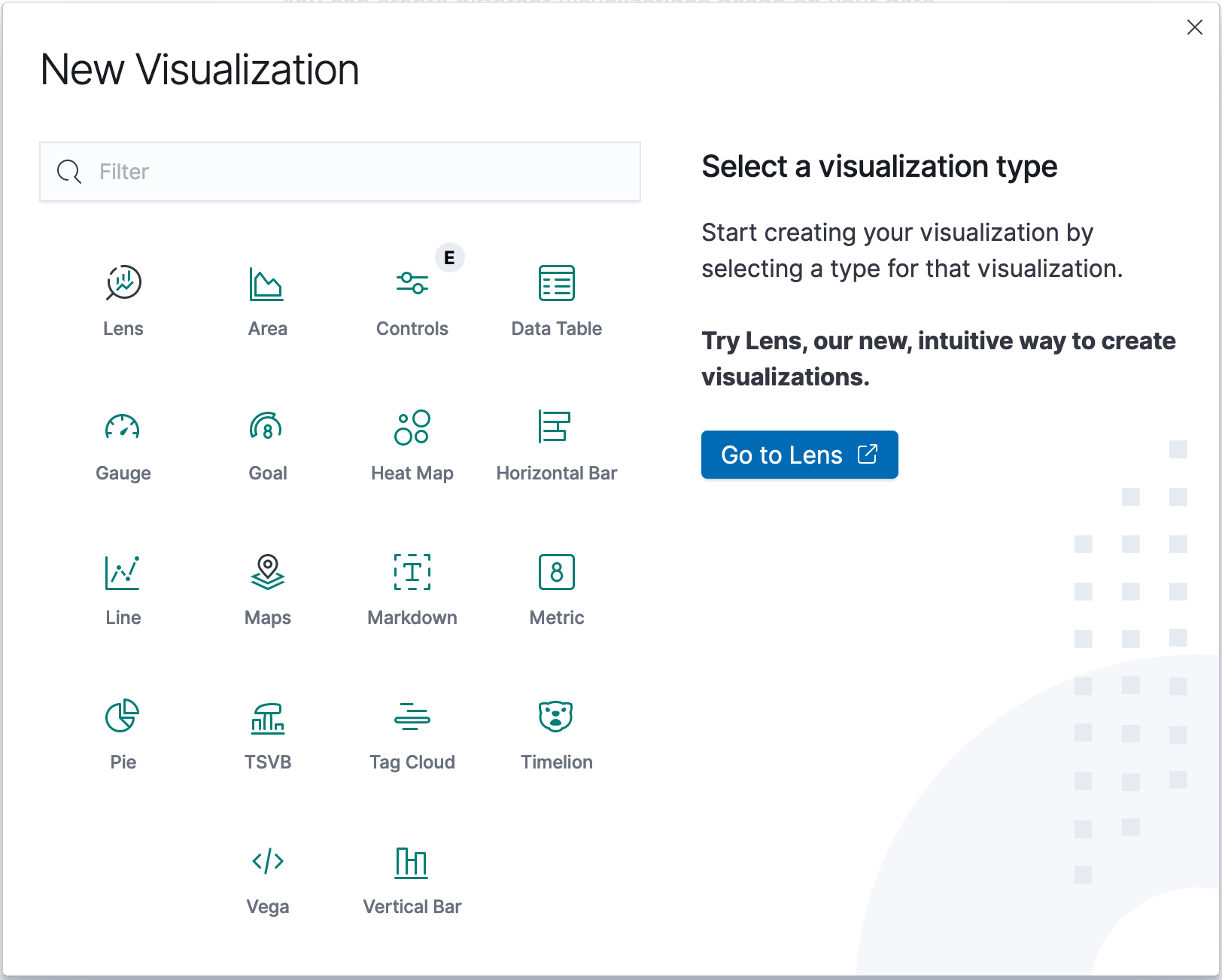 Типы визуализации Kibana
Типы визуализации Kibana
Для примера выбираем Pie , чтобы построить круговую диаграмму. В качестве источника данных выбираем шаблон индексов logstash* . В правой части в секции Buckets жмем Add , далее — Split slices . Тип агрегации выбираем Terms , поле severity.keyword . Жмем Update в правом нижнем углу и получаем готовую диаграмму. В секции Options можно добавить отображение данных или изменить вид диаграммы.
Если вместо графика отобразилась надпись No results found , проверьте выбранный интервал времени.
Чтобы посмотреть данные в Elasticsearch необходимо сделать GET запрос /имя_индекса/_search к любому узлу кластера. Добавление параметра pretty позволяет отобразить данные в читабельном виде. По умолчанию вывод состоит из 10 записей, чтобы увеличить это количество необходимо использовать параметр size :
Заключение
В рамках этой статьи была рассмотрена процедура установки и настройки Kibana и Logstash, настройка балансировки трафика между Kibana и Elasticsearch и работа нескольких экземпляров Kibana. Собрали первые данные с помощью Logstash, посмотрели на данные с помощью Kibana Discover и построили первую визуализацию.
Прежде чем углубляться в изучение плагинов Logstash, сбор данных с помощью Beats, визуализацию и анализ данных в Kibana, необходимо уделить внимание очень важному вопросу безопасности кластера. Об этом также постоянно намекает Kibana, выдавая сообщение Your data is not secure .
Теме безопасности будет посвящена следующая статья данного цикла.



