- Encoding
- Change the encoding used to view a file
- Configure file encoding settings
- Select console output encoding
- Ошибка с кодировкой windows 1251 в IDEA
- Java. Ошибка с символами русского алфавита в Intellij Idea! Поможете?
- Use the UTF-8, Luke! File Encodings in IntelliJ IDEA
- What is the problem with file encodings?
- How does the IDE determine encoding for the file?
- What happens when I try to change the file encoding?
- What else IntelliJ IDEA can do for me?
- What is the ultimate advice you have regarding file encodings?
- Intellij idea windows 1251
Encoding
To display and edit files correctly, IntelliJ IDEA needs to know which encoding to use. In general, source code files are mostly in UTF-8. This is the recommended encoding unless you have some other requirements.
To determine the encoding of a file, IntelliJ IDEA uses the following steps:
If the byte order mark (BOM) is present, IntelliJ IDEA will use the corresponding Unicode encoding regardless of all other settings. For more information, see Byte order mark.
If the file declares the encoding explicitly, IntelliJ IDEA will use the specified encoding. For example, this can apply to XML, HTML, and JSP files. The explicit declaration also overrides all other settings, but you can change it in the editor.
If there is no BOM and no explicit encoding declaration in the file, IntelliJ IDEA will use the encoding configured for the file or directory in the file encoding settings. If encoding is not configured for the file or directory, IntelliJ IDEA will use the encoding of the parent directory. If the parent directory encoding is also not configured, IntelliJ IDEA will fall back to the Project Encoding , and if there is no project, to Global Encoding .
Change the encoding used to view a file
If IntelliJ IDEA displays characters in a file incorrectly, it probably couldn’t detect the file encoding. In this case, you need to specify the correct encoding to use for viewing and editing this file.
With the file open in the editor, either select File | File Properties | File Encoding from the main menu or click the File Encoding widget on the status bar, and select the correct encoding of the file.
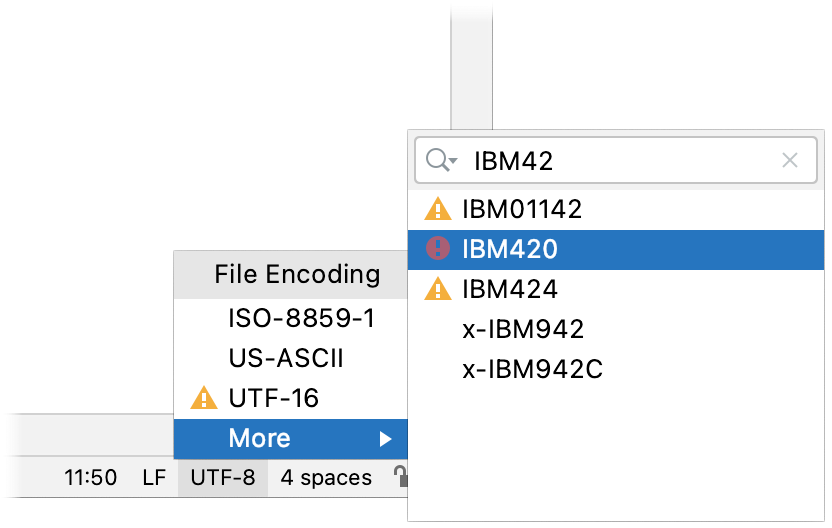
The list of encodings is rather large. You can use speed search to quickly find the correct encoding: start typing when the popup is open.
Encodings marked with or might change the file contents. In this case, IntelliJ IDEA opens a dialog where you can choose what to do with the file:
Reload : load the file in the editor from disk and apply encoding changes to the editor only. You will see the content changes related to the chosen encoding, but the actual file will not change.
Convert : overwrite the file with the chosen encoding.
This will add an association for the file to the file encoding settings. IntelliJ IDEA will use the specified encoding to view and edit this file.
Configure file encoding settings
In the Settings/Preferences dialog Ctrl+Alt+S , select Editor | File Encodings .
IntelliJ IDEA uses these settings to view and edit files for which it was not able to detect the encoding and also uses the specified encodings for new files.
Select the encoding to use when other encoding options don’t apply.
For example, IntelliJ IDEA will use this encoding for files that are not part of any project or when you check out sources from a version control system.
Select the encoding to use for the specified files and directories.
If this selector is disabled, the file probably has a BOM or declares the encoding explicitly. In this case, you can’t configure the encoding to use for this file.
The encoding selected for a directory applies to all files and subdirectories within it.
Select the encoding for properties files in your project.
The standard Java API is designed to use the ISO 8859-1 encoding for properties files. You can use escape sequences for characters that are not defined by this encoding. Alternatively, you can define the default encoding for properties files on the project level and use a different API that can read properties files in the encoding you have defined.
Show national characters (those not defined in ISO 8859-1) in place of the corresponding escape sequences.
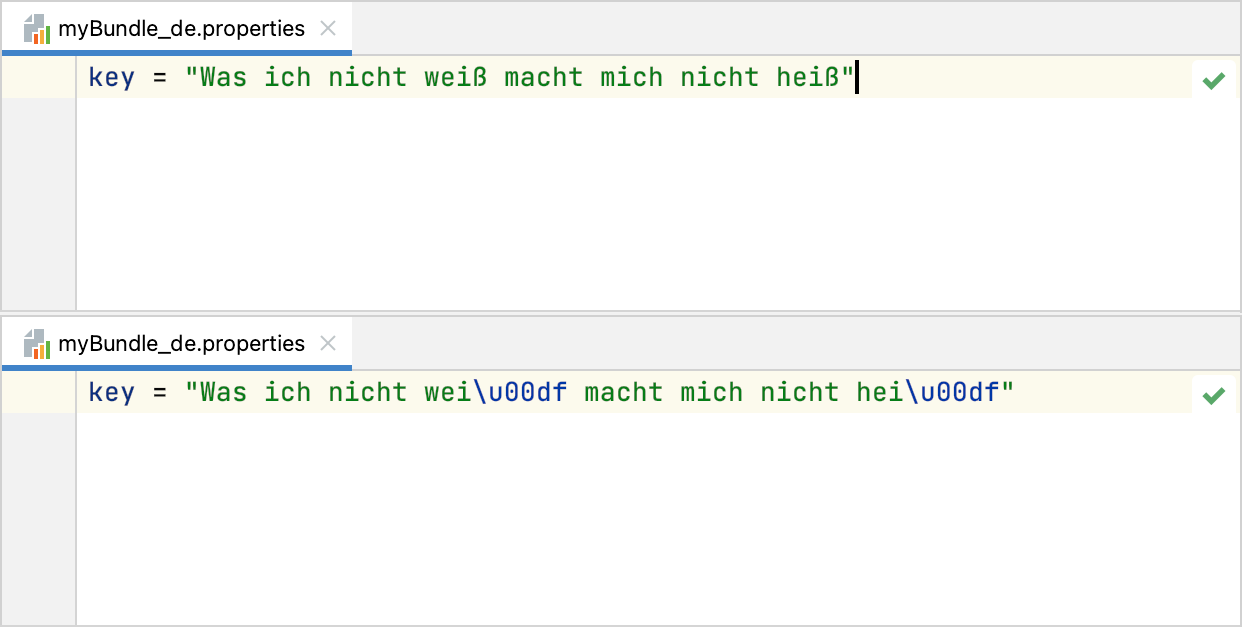
Select how IntelliJ IDEA should create UTF-8 files:
with BOM on Window and without BOM otherwise
By default, IntelliJ IDEA creates UTF-8 files without the BOM because some software is not compatible with the BOM, and it may be a problem when interpreting scripts. However, in some cases, you may want to have the BOM in your UTF-8 files.
To add or remove the BOM from all UTF-8 files in your project, right-click the name of your project in the Project tool window and select either Add BOM or Remove BOM .
Select console output encoding
By default, IntelliJ IDEA uses the system encoding to view console output.
In the Settings/Preferences dialog Ctrl+Alt+S , select Editor | General | Console .
Select the default encoding from the Default Encoding list.
Ошибка с кодировкой windows 1251 в IDEA
Когда компилируешь код, выходит ошибка deleted link . Сам код работает.сначала были кракозябры, потому что код написал на windows-1251, а потом я конвертировал в utf-8, из за этого видимо и ошибка. Как убрать?
| Комментарий модератора | ||
| ||

Как сделать кодировкой проекта Windows-1251
по умолчанию при создании проекта модуль главной формы находится в кодировке UTF8 как сделать.
 [UWP] Как прочитать файл с кодировкой windows-1251?
[UWP] Как прочитать файл с кодировкой windows-1251?
Здравствуйте, всем доброго времени суток. Подскажите, пожалуйста, как корректно прочитать.
Проблема с кодировкой. response.setContentType(‘text/html;windows-1251’)
Есть ASP-страница, общающаяся с БД на MSSQL-2000. Данные в большинстве полей — русско-язычные.
Setconsolecp 1251, setconsoleoutputcp 1251 (Windows.h), сбиваются шрифты на других ПК
Пишу консольную прогу с помощью vs 2017 (v141), на windows 10, с версией sdk 10.0.17134.0, MFC — в.
Заказываю контрольные, курсовые, дипломные и любые другие студенческие работы здесь или здесь.
проблема с кодировкой CP-1251
такая ещё проблема имеется. очень часто, когда мне пишут в пиджин у меня текст не распознаётся.
Win-1251 -> unf-8 с кодировкой
В БД установлено uft8_general_ci Согласно этой статье (.
Запись в dbf с кодировкой 1251
Добрый день. Для добавления файлов я копирую базу и в неё дописываю то, что мне нужно, но есть 1.
Создать файл с кодировкой 1251 в cmd
Привет! Пишу прогу которая работает с cmd. Мне нужно создавать файл, записывать в него лог и.
Парсинг html страниц с кодировкой 1251
Доброго дня! Помогите пожалуйста победить страницу с кодировкой windows-1251. Вместо кириллицы.
Файл с кодировкой 1251 открывается с кракозябрами
доброго времени. открываю файл так: List1.LoadFromFile(filename); все ок. открываю так .
Java. Ошибка с символами русского алфавита в Intellij Idea! Поможете?
Я создаю свой проект на Java в Intellij Idea, но из-за того, что не очень разбираюсь в Intellij Idea, иногда тыкаю не туда, куда надо (._. )
Дело вот в чем. Недавно я начал добавлять в свой проект сериализацию, чтобы прогресс сохранялся на компьюторе в виде фалов формата .ser. В Intellij Idea эти файлы отображались в дереве классов и папок и в них можно было заходить. Но когда я в них заходил, я видел в этих файлах непонятные знаки и числа, а сверху надпись на английском языке про какое-то форматирование символов что-ли. Ну и короче я нажал на одну из таких и теперь при заходе на файлы .ser эти кнопки больше не появляются, а большинство странных символов отображаются в виде нормальных. Но дело в том, что именно после того, как я это сделал, мой проект перестал поддерживать латиницу и вообще большинство русских символов 🙁
Например, когда я проверяю на соответствие какую либо строку, какому либо знаку русского алфавита, вылетает такая ошибка:
Error:(447, 22) java: unclosed character literal
Вот код, если необходимо:
И даже если все строки в программе с буквами русского алфавита закомментировать или убрать, то программа запуститься, но все русские надписи на кнопках и других объектах отображаются в виде непонятных знаков и чисел.
Короче, проект в принципе перестал воспринимать русский алфавит 🙁
Не знаю, возможно это не из-за этого, но пожааалуйста, кто-нибудь из знатоков Intellij Idea, выскажите своё мнение, почему так могло произойти, потому что не очень хочется забросить проект из-за какой-то кнопки.
Заранее спасибо!
Use the UTF-8, Luke! File Encodings in IntelliJ IDEA
Today we would like to answer the most frequent questions about file encodings in the IDE and show you a few tricks, which may help you to avoid potential pitfalls.
What is the problem with file encodings?
To be able to display the text correctly, IntelliJ IDEA needs to know which file encoding to use. Unfortunately, it is not always possible to tell the file encoding without additional information. Especially when single-byte encodings are used, there are multiple mappings possible.
However, things look better for UTF-family encodings. The UTF family consists of:
- Several multi-byte encodings like UTF-16 or UTF-32, which are easily detectable by the BOM (Byte Order Mark) word in the beginning of the file.
- The UTF-8 variable-bytes-per-character encoding which also can be auto-detected either by optional BOM or some specific byte combinations.
In particular, for an English character subset, the UTF-8 encoded file looks exactly like old plain ASCII text. That’s why UTF-8 is so popular and that’s why it’s the most preferred encoding.
How does the IDE determine encoding for the file?
IntelliJ IDEA uses multi-stage educated guessing, from most obvious to far-stretched.
First, if the BOM present, use the corresponding UTF-family encoding. Check if the file type declares the encoding itself and use that. For example, JSP files can specify the encoding right in the text:
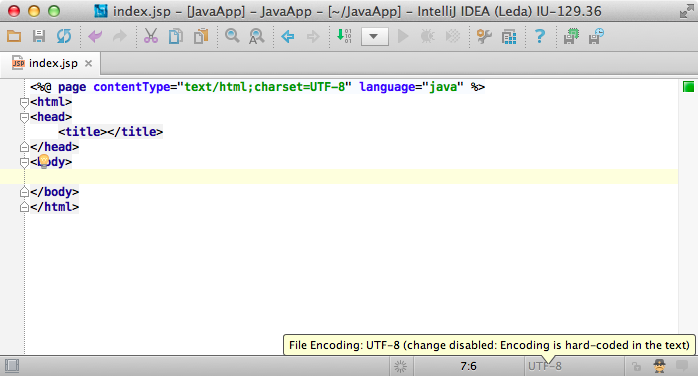
Check if you have specified the encoding explicitly and use that. You can specify the desired encoding for the file or for the containing directory or for the whole project or for the IDE. IntelliJ IDEA will use the most specific encoding:
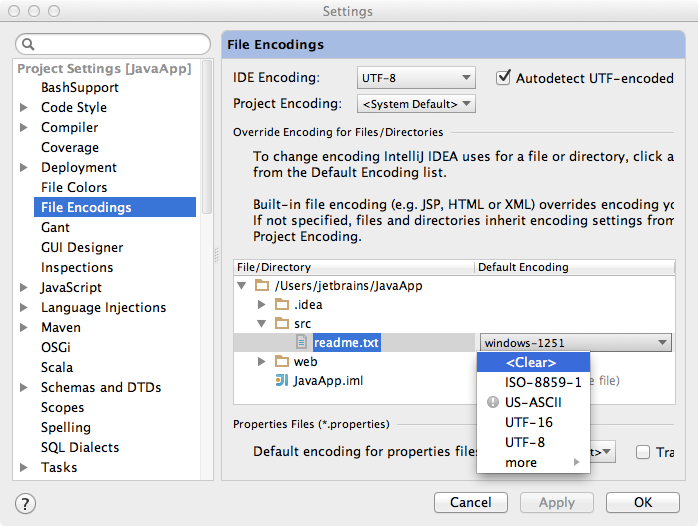
Try to figure out the encoding using some hints or heuristics. For example, when Auto-detect UTF-8 is selected, the IDE will analyze the file looking for some byte combinations which are UTF-8-specific.
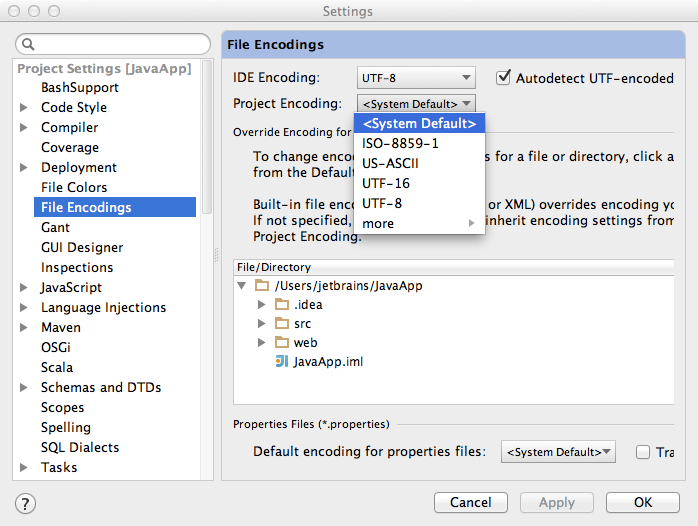
Finally, use the project-level or, if the project is unavailable, the application-level encoding.
See Settings → File Encoding → Project Encoding → IDE Encoding.
What happens when I try to change the file encoding?
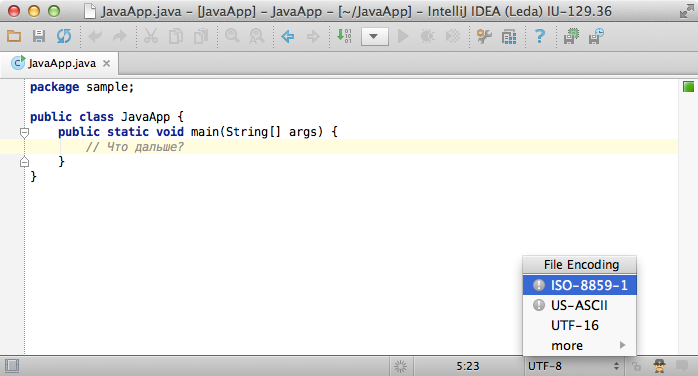
If the file encodings are completely compatible for this text, e.g. when changing English characters text from US_ASCII to UTF-8, IntelliJ IDEA just silently re-assigns encoding.
However, if the encodings are sufficiently different, the IDE have to ask you:
- Whether you want to reload the file from disk in the other encoding.
In this case IDEA will replace editor with text from the file decoded with the new encoding. - Or you would like to convert the text on the editor to the file using the other encoding.
Here, IDEA will encode the text in the editor window using the new encoding and overwrite the file.

Please note these little gray exclamation marks, meaning that that particular conversion/reload can cause information loss.
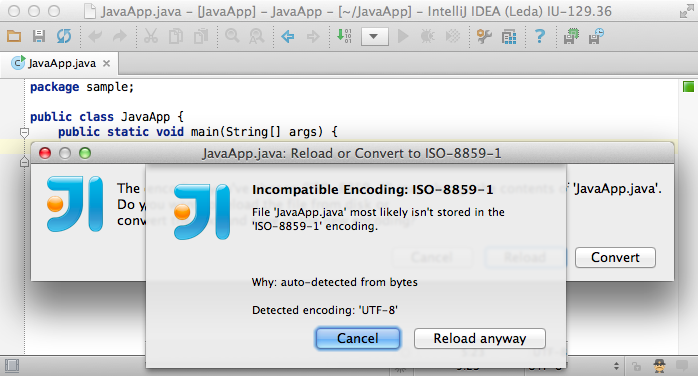
For example when you try to reload UTF-8 encoded file with the US-ASCII encoding, losing the non-english characters in the process.
Or when you try to save the German umlauts to the plain text ISO-8859-1 file.
What else IntelliJ IDEA can do for me?
IntelliJ IDEA will warn you when you try to swear in German in an ASCII-only document:
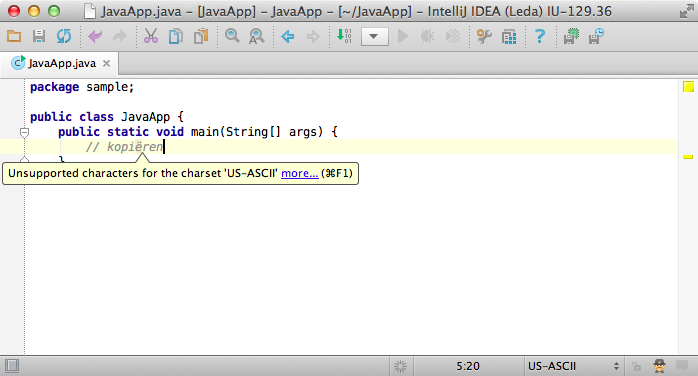
To enable this inspection, go to Settings → Inspections → Lossy Encoding.
Likewise, IntelliJ IDEA will try to detect the situation when you load rich-encoded text with incompatible encoding:
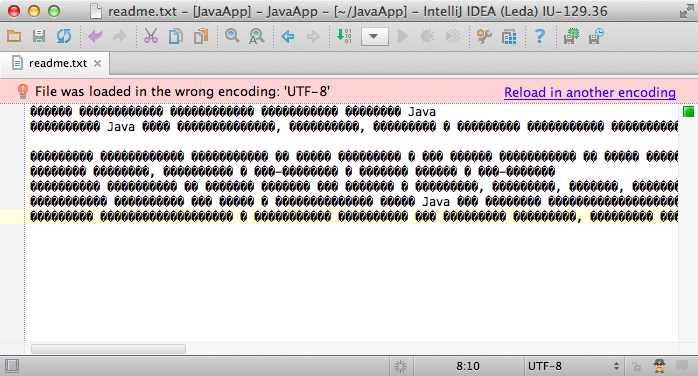
What is the ultimate advice you have regarding file encodings?
To avoid any problems with file encoding we strongly recommend to use UTF-8.
That’s all for today and we hope this article was useful for you!
Intellij idea windows 1251
Добрый день коллеги.
Кто-нибудь знает как в IntelliJ IDEA 9 сменить кодировку окна вывода (которое в качестве консоли у запускаемого приложения)? У меня IDEA выводит всё в кодировке windows-1251, а разрабатываемое приложение пишет в UTF-8. Собственно, вместо русского текста вижу одни закорючки.
Менять кодировку приложения не предлагать, так как это гораздо сложнее.
 | От: | Donz | http://donz-ru.livejournal.com |
| Дата: | 23.12.10 13:41 | ||
| Оценка: |
Здравствуйте, telek1024, Вы писали:
T>Менять кодировку приложения не предлагать, так как это гораздо сложнее.
Тогда предлагаю сделать рефакторинг кода, чтобы подобные настройки легко менялись одним движением руки 
 | От: | telek1024 |
| Дата: | 23.12.10 14:38 | |
| Оценка: |
Здравствуйте, Donz, Вы писали:
D>Здравствуйте, telek1024, Вы писали:
T>>Менять кодировку приложения не предлагать, так как это гораздо сложнее.
D>Тогда предлагаю сделать рефакторинг кода, чтобы подобные настройки легко менялись одним движением руки
Не. Код трогать вообще нельзя. Проще мириться с загогулинами в консоле, чем трогать код.
 | От: | Closer |
| Дата: | 23.12.10 17:34 | |
| Оценка: |
Здравствуйте, telek1024, Вы писали:
Что-то я у себя такого не наблюдаю. Без проблем вывел на консоль идеи текст System.out.print(«Привет!»);
Какая у вас OS? Региональные настройки? Приложение точно не меняет кодировку или перекодирует строки?
| | От: | telek1024 |
| Дата: | 24.12.10 08:34 | |
| Оценка: |
Здравствуйте, Closer, Вы писали:
C>Здравствуйте, telek1024, Вы писали:
C>[skipped]
C>Что-то я у себя такого не наблюдаю. Без проблем вывел на консоль идеи текст System.out.print(«Привет!»);
Ну так! По умолчанию приложение использует настройки ОС.
C>Какая у вас OS? Региональные настройки? Приложение точно не меняет кодировку или перекодирует строки?
У меня приложение стартует под виндой с JVM параметром -Dfile.encoding=UTF-8
И в этом параметре есть глубокий философский смысл.
Собственно я и спрашивал, как Идее объяснить, что в консоль ей валится не дефолтовая кодировка, а другая.



