- Windows Research Kernel
- Содержание
- Что такое Windows Research Kernel?
- Windows Academic Program
- Структура Windows Research Kernel
- HTML документация по WRK
- Насколько сложный программный код у Windows?
- Кен Грегг (Ken Gregg), разработчик в составе группы Windows NT
- Насколько сложна Windows в программном коде?
- Кен Грегг (Ken Gregg)
- Как менялся программный код Windows?
- Как база кода Windows NT развивалась с 1993 года
- Кен Грегг (Ken Gregg)
- Несколько слов про ядро Windows NT
- Давай напишем ядро! Создаем простейшее рабочее ядро операционной системы
- Содержание статьи
- Как загружаются x86-машины
- Что нам понадобится
- Входная точка на ассемблере
- Ядро на C
- Компоновка
- GRUB и мультизагрузка
- Собираем ядро
- WARNING
- Настраиваем GRUB и запускаем ядро
- GRUB 2
- Пишем ядро с поддержкой клавиатуры и экрана
- Работа с портами: чтение и вывод
- Прерывания
- Задаем IDT
- Функция — обработчик прерывания клавиатуры
Windows Research Kernel
Содержание
Что такое Windows Research Kernel?
Windows Research Kernel (WRK) — исходный код ядра ОС Windows (Windows XP x64 и Windows Server 2003 SP1), распространяемый для некоммерческих, исследовательских целей в рамках «Windows Academic Program» под НЕ СВОБОДНОЙ лицензией (где пруфлинк?). Как следствие, этот код не может быть использован в процессе разработки ReactOS (т.е. разработчики никогда не смотрели этот код и не планируют этого делать, пока не изменятся условия лицензирования WRK)
WRK предназначен для факультетов и преподавателей, работающих в области операционных систем, для разработчиков курсов, авторов учебников и т.д., желающих включить информацию о ядре Windows, основанную на действующем исходном коде. WRK содержит среду для сборки/тестирования и бинарные файлы для исключённых компонентов исходного кода, которые могут быть использованы, чтобы собрать полнофункциональные NTOS ядра для последующей установки на Windows Server 2003 для x86/x64 и Windows XP x64.
Ниже информация из лекции «Исследовательское ядро Windows» курса «Введение во внутреннее устройство Windows» от Intuit.ru.
Windows Academic Program
В 2006 году корпорация Microsoft в рамках академической программы Windows (Windows Academic Program) сделала доступной для академических организаций исходный код исследовательского ядра Windows (Windows Research Kernel, WRK). WRK основано на коде операционных систем Windows Server 2003 SP1 и Windows XP x64.
Кроме WRK в академическую программу Microsoft входят следующие компоненты:
- учебные материалы по курсу операционных систем на основе Windows XP – Windows Internals Curriculum Resource Kit (CRK). Составлены в соответствии с рекомендациями ACM/IEEE по преподаванию курса «Операционные системы» (Operating systems, OS). Материалы включают презентации лекций, указания к лабораторным работам (в том числе лабораторные работы для Windows 7), задания, тесты, а также материалы для преподавателей (Instructor Supplement);
- среда ProjectOZ для экспериментального исследования ядра Windows;
- описание опыта университетов (Faculty Experiences) по преподаванию в рамках академической программы Microsoft.
Все компоненты Windows Academic Program, кроме WRK и материалов для преподавателей (Instructor Supplement), доступны любому желающему. WRK и Instructor Supplement можно получить, подтвердив свой статус преподавателя или по подписке Microsoft Developer Network Academic Alliance (MSDN AA).
Microsoft, предоставляя академическому сообществу исходные коды ядра Windows, преследовало следующие цели:
- облегчить студентам и преподавателям сравнение Windows с другими операционными системами;
- предоставить студентам возможность для изучения исходных кодов ядра и создания собственных проектов на их основе;
- поддержать исследования и публикации по внутреннему устройству Windows;
- содействовать разработке учебников по операционным системам на основе ядра Windows;
- упростить лицензирование.
Исследовательское ядро Windows включает более 800 000 строк исходного кода, в основном на языке программирования C, но есть файлы и на ассемблере. В процессе подготовки к опубликованию исходный код в некоторых местах был упрощен, а комментарии улучшены.
На следующем рисунке представлена схема, отражающая покрытие исходным кодом WRK компонентов ядра.
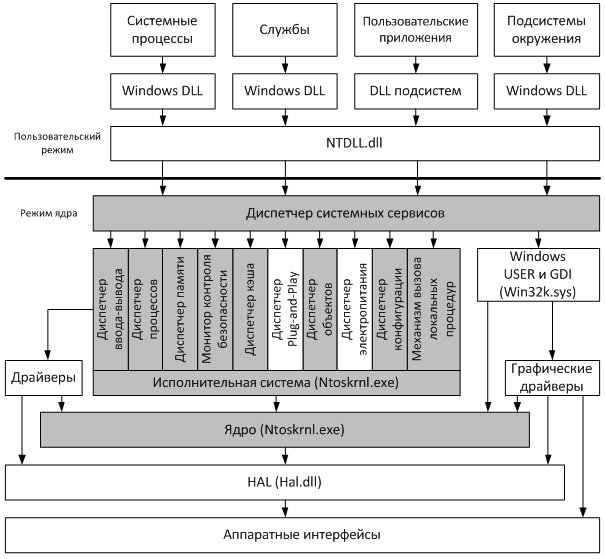
Рис.1. Покрытие исходным кодом WRK компонентов ядра (выделено серым цветом)
Как видно из рисунка, исходные коды практически всех компонентов исполнительной системы (кроме диспетчера Plug-and-Play и диспетчера электропитания) и ядра представлены в WRK.
Структура Windows Research Kernel
В состав WRK, кроме собственно исходных кодов ядра Windows, входят руководство по ядру Windows NT (NT OS/2 Design Workbook) и решение (solution) Visual Studio 2008 (WRK.sln) (которое можно преобразовать для более новых версий Visual Studio).
Руководство по ядру Windows NT было составлено в конце 1980 х – начале 1990 х гг., когда в Microsoft велась разработка новой операционной системы Windows NT с рабочим названием «NT OS/2» сначала совместно с IBM, затем самостоятельно. Руководство содержит ценную информацию по структуре и функциям ядра Windows, а также раскрывает соображения, которые привели разработчиков к тем или иным архитектурным решениям.
Главные компоненты WRK находятся в папке WRK-v1.2\base\ntos и включают, в основном описания и определения функций и структур данных. В ядре Windows при именовании функций используются определенные соглашения [5; 2]. Название функции обычно строится по следующей схеме:
где обозначает модуль, которому принадлежит функция, – действие, совершаемое над .
Например, рассмотрим функцию KeStartThread:
- Ke (префикс) – функция входит в состав ядра;
- Start (операция) – функция начинает выполнение объекта;
- Thread (объект) – объектом является поток.
| Компонент WRK | Префикс функций | Название компонента на англ. языке | Название компонента на русском языке |
|---|---|---|---|
| cache | Cc | Cache manager | диспетчер кэша |
| config | Cm | Configuration manager | диспетчер конфигурации |
| dbgk | Dbgk | Debugging Framework | подсистема отладки |
| ex | Ex | Executive support routines | функции поддержки исполнительной системы – синхронизация, таймеры, структуры данных исполнительной системы, системная информация |
| fsrtl | FsRtl | File system driver run-time library | библиотека функций поддержки файловой системы времени выполнения |
| io | Io | Input/Output manager | диспетчер ввода-вывода |
| ke | Ke | Kernel | ядро |
| lpc | Lpc | Local Procedure Call | механизм вызова локальных процедур |
| mm | Mm | Memory manager | диспетчер памяти |
| ob | Ob | Object manager | диспетчер объектов |
| perf | Perf | Performance | функции для сбора информации о производительности системы |
| ps | Ps | Process manager | диспетчер процессов |
| raw | Raw | Raw File System | функции для Raw File System |
| rtl | Rtl | Run-Time Library | библиотека функций времени выполнения |
| se | Se | Security manager | диспетчер безопасности |
| wmi | Wmi | Windows Management Instrumentation | поддержка WMI – инструментальные средства управления Windows |
Компоненты WRK и префиксы функций
Кроме перечисленных в таблице, в WRK есть ещё два важных компонента:
- inc – общедоступные заголовочные файлы;
- init – функции инициализации системы.
Приведем ещё один префикс часто встречающихся в WRK функций – Nt. Функции ядра с этим префиксом входят в Native API, они экспортируются Ntdll.dll, их можно вызывать из пользовательского режима. Часто функции с префиксом Nt соответствует WinAPI функция, и, например, при вызове WinAPI функции CreateProcess происходит вызов функции NtCreateProcess.
HTML документация по WRK
В Институте программной инженерии Хассо Платтнера Университета г. Потсдама (Hasso-Plattner-Institute for Software Engineering at University Potsdam) Александром Шмидтом (Alexander Schmidt) и Михаэлем Шёбелем (Michael Schobel) была создана HTML документация по WRK с использованием генератора документации Phoenix Cross Reference (PXR)2 . Данная документация доступна для преподавателей по следующей ссылке:
HTML документация по WRK включает 4 раздела: функции (functions), типы данных (types), синонимы (typedefs) и макросы (macros).
По информации, предоставляемой HTML документацией, WRK содержит 4167 функций и 1957 типов данных.
Насколько сложный программный код у Windows?

Чтобы разобраться вопросе, насколько может быть сложным программный код «Виндовс» мы обратились к одному из разработчиков команды Windows NT в компании Microsoft — Кену Греггу (Ken Gregg).
Кен Грегг (Ken Gregg), разработчик в составе группы Windows NT
«Могу сказать вам, что у меня был доступ к исходному коду, когда я был в команде Windows NT (NT является основой для всех настольных версий Windows начиная с XP), во время проектов разработки NT 3.1 и NT 3.5. Всё было в рамках стандартов кодирования NT Workbook — эдакой «библии» для всей проектной команды.
. Хотя я и не читал каждую строку кода, но то, с чем мне пришлось работать, было очень:
Нужно исходить из того, что именно понимается под сложностью кода. Это понимание сугубо субъективное, ведь так? Благо существует множество различных метрик, используемых и комбинируемых для измерения сложности программного обеспечения в тех или иных ситуациях (та же самая модульность, многоуровневость и обслуживаемость).

Насколько сложна Windows в программном коде?
Конечно, чтобы прочитать и понять код, вам нужно было бы иметь представление об общей архитектуре Windows NT.
Вероятно, лучшим источником информации о внутренностях Windows сегодня являются книги Windows Internals 6th Edition (в двух томах).
Некоторые люди просто приравнивают сложность кода к размеру. У этого сравнения тоже есть метрика — строки кода (LOC).
Измерение LOC зависит от используемых инструментов и критериев. Их выбирают для точного определения строк кода на каждом языке программирования.

Кен Грегг (Ken Gregg)
«Существует много споров о методах, используемых для подсчета строк кода (LOC). Если использовать одни и те же критерии от одного выпуска к следующему, то получится относительное изменение размера базы кода.
Сравнивать эти числа с цифрами другой ОС, которая использовала другой метод подсчета строк кода, всё равно что сравнивать яблоки с апельсинами. То есть это некорректный подход».

Как менялся программный код Windows?
Здесь приводятся некоторые лакомые кусочки, дающие представление о размерах современной кодовой базы Windows. Строки кода здесь являются приблизительными и неофициальными, но основаны на достаточно надёжных источниках, о которых говорит Кен Грегг .
Как база кода Windows NT развивалась с 1993 года
MLOC — это количество миллионов строк исходного кода. По ним можно определить относительную сложность операционной системы, если опираться на размеры кода (LOC-методика).
- Windows NT 3.1 (1993) — 5,6 MLOC
- Windows NT 3.5 (1994) — 8,4 MLOC
- Windows NT 3.51 (1995) — 10,2 MLOC
- Windows NT 4.0 (1996) — 16 MLOC
- Windows 2000 (2000) — 29 MLOC
- Windows XP (2001) — 35 MLOC
- Windows Vista (2007) — 45 MLOC
- Windows 7 (2009) — 42 MLOC
- Windows 8 (2012) — 50 MLOC
- Windows 10 (2015) — 55 MLOC
Исходный код Windows состоит в основном из C и C++, а также небольшого количества кода на ассемблере.
Некоторые из утилит пользовательского режима и другие подобные службы пишутся на Си Шарп, но это относительно небольшой процент от общей базы кода.
Кен Грегг (Ken Gregg)
«Я намеренно не включил в список 16-битные версии ОС, выпущенные с 1985 по 2000 годы. Windows NT была основой для всех современных 32-бит и 64-бит версий Windows. Количество строк кода в серверных версиях было таким же, как и в несерверных версиях, выпущенных в том же году (то есть они имели одинаковую базу исходного кода)».

Несколько слов про ядро Windows NT
По словам Кена, работа над ядром NT началась в 1988 году. Ядро было создано с нуля в качестве 32-разрядной упреждающей многозадачной ОС.
Ядро NT впервые загрузилось в июле 1989 года на процессоре Intel i860 RISC. С самого начала был сильный толчок к тому, чтобы новая ОС была совместимой с различными архитектурами центральных процессоров и не была привязана только к архитектуре Intel x86 (IA-32).
NT в конечном итоге работал на MIPS, DEC Alpha, PowerPC, Itanium и, конечно, Intel x86 и x64.
Некоторая сложность была добавлена в базу кода на уровне абстрагирования оборудования (HAL). Это было нужно для поддержки неинтеловских архитектур.
А как вы оцениваете перспективы Windows в плане кода? Узнайте, какие версии Windows актуальны сейчас и какие ОС можно рассмотреть в качестве альтернативы.
Есть проблемы при использовании Windows и непонятен программный код для внедрения новых бизнес-инструментов в ОС от Microsoft? Проконсультируйтесь с экспертами по ИТ-аутсорсингу и получите поддержку по любым техническим вопросам и задачам.
Давай напишем ядро! Создаем простейшее рабочее ядро операционной системы

Содержание статьи

Это перевод двух статей Арджуна Сридхарана:
Публикуется с разрешения автора. Перевел Андрей Письменный.
Давай напишем ядро, которое будет загружаться через GRUB на системах, совместимых с x86. Наше первое ядро будет показывать сообщение на экране и на этом останавливаться.
Как загружаются x86-машины
Прежде чем думать о том, как писать ядро, давай посмотрим, как компьютер загружается и передает управление ядру. Большинство регистров процессора x86 имеют определенные значения после загрузки. Регистр — указатель на инструкцию (EIP) содержит адрес инструкции, которая будет исполнена процессором. Его захардкоженное значение — это 0xFFFFFFF0. То есть x86-й процессор всегда будет начинать исполнение с физического адреса 0xFFFFFFF0. Это последние 16 байт 32-разрядного адресного пространства. Этот адрес называется «вектор сброса» (reset vector).
В карте памяти, которая содержится в чипсете, прописано, что адрес 0xFFFFFFF0 ссылается на определенную часть BIOS, а не на оперативную память. Однако BIOS копирует себя в оперативку для более быстрого доступа — этот процесс называется «шедоуинг» (shadowing), создание теневой копии. Так что адрес 0xFFFFFFF0 будет содержать только инструкцию перехода к тому месту в памяти, куда BIOS скопировала себя.
Итак, BIOS начинает исполняться. Сначала она ищет устройства, с которых можно загружаться в том порядке, который задан в настройках. Она проверяет носители на наличие «волшебного числа», которое отличает загрузочные диски от обычных: если байты 511 и 512 в первом секторе равны 0xAA55, значит, диск загрузочный.
Как только BIOS найдет загрузочное устройство, она скопирует содержимое первого сектора в оперативную память, начиная с адреса 0x7C00, а затем переведет исполнение на этот адрес и начнет исполнение того кода, который только что загрузила. Вот этот код и называется загрузчиком (bootloader).
Загрузчик загружает ядро по физическому адресу 0x100000. Именно он и используется большинством популярных ядер для x86.
Все процессоры, совместимые с x86, начинают свою работу в примитивном 16-разрядном режиме, которые называют «реальным режимом» (real mode). Загрузчик GRUB переключает процессор в 32-разрядный защищенный режим (protected mode), переводя нижний бит регистра CR0 в единицу. Поэтому ядро начинает загружаться уже в 32-битном защищенном режиме.
Заметь, что GRUB в случае с ядрами Linux выбирает соответствующий протокол загрузки и загружает ядро в реальном режиме. Ядра Linux сами переключаются в защищенный режим.
Что нам понадобится
- Компьютер, совместимый с x86 (очевидно),
- Linux,
- ассемблер NASM,
- GCC,
- ld (GNU Linker),
- GRUB.
Ты можешь найти исходный код того, что у нас должно получиться, в репозитории автора на GitHub.
Входная точка на ассемблере
Нам бы, конечно, хотелось написать все на C, но совсем избежать использования ассемблера не получится. Мы напишем на ассемблере x86 небольшой файл, который станет стартовой точкой для нашего ядра. Все, что будет делать ассемблерный код, — это вызывать внешнюю функцию, которую мы напишем на C, а потом останавливать выполнение программы.
Как сделать так, чтобы ассемблерный код стал стартовой точкой для нашего ядра? Мы используем скрипт для компоновщика (linker), который линкует объектные файлы и создает финальный исполняемый файл ядра (подробнее объясню чуть ниже). В этом скрипте мы напрямую укажем, что хотим, чтобы наш бинарный файл загружался по адресу 0x100000. Это адрес, как я уже писал, по которому загрузчик ожидает увидеть входную точку в ядро.
Вот код на ассемблере.
kernel.asm
Первая инструкция bits 32 — это не ассемблер x86, а директива NASM, сообщающая, что нужно генерировать код для процессора, который будет работать в 32-разрядном режиме. Для нашего примера это не обязательно, но указывать это явно — хорошая практика.
Вторая строка начинает текстовую секцию, также известную как секция кода. Сюда пойдет весь наш код.
global — это еще одна директива NASM, она объявляет символы из нашего кода глобальными. Это позволит компоновщику найти символ start , который и служит нашей точкой входа.
kmain — это функция, которая будет определена в нашем файле kernel.c . extern объявляет, что функция декларирована где-то еще.
Далее идет функция start , которая вызывает kmain и останавливает процессор инструкцией hlt . Прерывания могут будить процессор после hlt , так что сначала мы отключаем прерывания инструкцией cli (clear interrupts).
В идеале мы должны выделить какое-то количество памяти под стек и направить на нее указатель стека (esp). GRUB, кажется, это и так делает за нас, и на этот момент указатель стека уже задан. Однако на всякий случай выделим немного памяти в секции BSS и направим указатель стека на ее начало. Мы используем инструкцию resb — она резервирует память, заданную в байтах. Затем оставляется метка, указывающая на край зарезервированного куска памяти. Прямо перед вызовом kmain указатель стека (esp) направляется на эту область инструкцией mov .
Ядро на C
В файле kernel.asm мы вызвали функцию kmain() . Так что в коде на C исполнение начнется с нее.
kernel.c
Все, что будет делать наше ядро, — очищать экран и выводить строку my first kernel.
Первым делом мы создаем указатель vidptr, который указывает на адрес 0xb8000. В защищенном режиме это начало видеопамяти. Текстовая экранная память — это просто часть адресного пространства. Под экранный ввод-вывод выделен участок памяти, который начинается с адреса 0xb8000, — в него помещается 25 строк по 80 символов ASCII.
Каждый символ в текстовой памяти представлен 16 битами (2 байта), а не 8 битами (1 байтом), к которым мы привыкли. Первый байт — это код символа в ASCII, а второй байт — это attribute-byte . Это определение формата символа, в том числе — его цвет.
Чтобы вывести символ s зеленым по черному, нам нужно поместить s в первый байт видеопамяти, а значение 0x02 — во второй байт. 0 здесь означает черный фон, а 2 — зеленый цвет. Мы будем использовать светло-серый цвет, его код — 0x07.
В первом цикле while программа заполняет пустыми символами с атрибутом 0x07 все 25 строк по 80 символов. Это очистит экран.
Во втором цикле while символы строки my first kernel, оканчивающейся нулевым символом, записываются в видеопамять и каждый символ получает attribute-byte, равный 0x07. Это должно привести к выводу строки.
Компоновка
Теперь мы должны собрать kernel.asm в объектный файл с помощью NASM, а затем при помощи GCC скомпилировать kernel.c в другой объектный файл. Наша задача — слинковать эти объекты в исполняемое ядро, пригодное к загрузке. Для этого потребуется написать для компоновщика (ld) скрипт, который мы будем передавать в качестве аргумента.
link.ld
Здесь мы сначала задаем формат ( OUTPUT_FORMAT ) нашего исполняемого файла как 32-битный ELF (Executable and Linkable Format), стандартный бинарный формат для Unix-образных систем для архитектуры x86.
ENTRY принимает один аргумент. Он задает название символа, который будет служить входной точкой исполняемого файла.
SECTIONS — это самая важная для нас часть. Здесь мы определяем раскладку нашего исполняемого файла. Мы можем определить, как разные секции будут объединены и куда каждая из них будет помещена.
В фигурных скобках, которые идут за выражением SECTIONS , точка означает счетчик позиции (location counter). Он автоматически инициализируется значением 0x0 в начале блока SECTIONS , но его можно менять, назначая новое значение.
Ранее я уже писал, что код ядра должен начинаться по адресу 0x100000. Именно поэтому мы и присваиваем счетчику позиции значение 0x100000.
Взгляни на строку .text : < *(.text) >. Звездочкой здесь задается маска, под которую подходит любое название файла. Соответственно, выражение *(.text) означает все входные секции .text во всех входных файлах.
В результате компоновщик сольет все текстовые секции всех объектных файлов в текстовую секцию исполняемого файла и разместит по адресу, указанному в счетчике позиции. Секция кода нашего исполняемого файла будет начинаться по адресу 0x100000.
После того как компоновщик выдаст текстовую секцию, значение счетчика позиции будет 0x100000 плюс размер текстовой секции. Точно так же секции data и bss будут слиты и помещены по адресу, который задан счетчиком позиции.
GRUB и мультизагрузка
Теперь все наши файлы готовы к сборке ядра. Но поскольку мы будем загружать ядро при помощи GRUB, остается еще один шаг.
Существует стандарт для загрузки разных ядер x86 с помощью бутлоадера. Это называется «спецификация мультибута». GRUB будет загружать только те ядра, которые ей соответствуют.
В соответствии с этой спецификацией ядро может содержать заголовок (Multiboot header) в первых 8 килобайтах. В этом заголовке должно быть прописано три поля:
- magic — содержит «волшебное» число 0x1BADB002, по которому идентифицируется заголовок;
- flags — это поле для нас не важно, можно оставить ноль;
- checksum — контрольная сумма, должна дать ноль, если прибавить ее к полям magic и flags .
Наш файл kernel.asm теперь будет выглядеть следующим образом.
kernel.asm
Инструкция dd задает двойное слово размером 4 байта.
Собираем ядро
Итак, все готово для того, чтобы создать объектный файл из kernel.asm и kernel.c и слинковать их с применением нашего скрипта. Пишем в консоли:
По этой команде ассемблер создаст файл kasm.o в формате ELF-32 bit. Теперь настал черед GCC:
Параметр -c указывает на то, что файл после компиляции не нужно линковать. Мы это сделаем сами:
Эта команда запустит компоновщик с нашим скриптом и сгенерирует исполняемый файл под названием kernel .
WARNING
Хакингом ядра лучше всего заниматься в виртуалке. Чтобы запустить ядро в QEMU вместо GRUB, используй команду qemu-system-i386 -kernel kernel .
Настраиваем GRUB и запускаем ядро
GRUB требует, чтобы название файла с ядром следовало конвенции kernel- . Так что переименовываем файл — я назову свой kernel-701 .
Теперь кладем ядро в каталог /boot . На это понадобятся привилегии суперпользователя.
В конфигурационный файл GRUB grub.cfg нужно будет добавить что-то в таком роде:
Не забудь убрать директиву hiddenmenu, если она прописана.
GRUB 2
Чтобы запустить созданное нами ядро в GRUB 2, который по умолчанию поставляется в новых дистрибутивах, твой конфиг должен выглядеть следующим образом:
Благодарю Рубена Лагуану за это дополнение.
Перезагружай компьютер, и ты должен будешь увидеть свое ядро в списке! А выбрав его, ты увидишь ту самую строку.

Это и есть твое ядро!
Пишем ядро с поддержкой клавиатуры и экрана
Мы закончили работу над минимальным ядром, которое загружается через GRUB, работает в защищенном режиме и выводит на экран одну строку. Настала пора расширить его и добавить драйвер клавиатуры, который будет читать символы с клавиатуры и выводить их на экран.
Полный исходный код ты можешь найти в репозитории автора на GitHub.
Мы будем общаться с устройствами ввода-вывода через порты ввода-вывода. По сути, они просто адреса на шине ввода-вывода. Для операций чтения и записи в них существуют специальные процессорные инструкции.
Работа с портами: чтение и вывод
Доступ к портам ввода-вывода осуществляется при помощи инструкций in и out , входящих в набор x86.
В read_port номер порта передается в качестве аргумента. Когда компилятор вызывает функцию, он кладет все аргументы в стек. Аргумент копируется в регистр edx при помощи указателя на стек. Регистр dx — это нижние 16 бит регистра edx . Инструкция in здесь читает порт, номер которого задан в dx , и кладет результат в al . Регистр al — это нижние 8 бит регистра eax . Возможно, ты помнишь из институтского курса, что значения, возвращаемые функциями, передаются через регистр eax . Таким образом, read_port позволяет нам читать из портов ввода-вывода.
Функция write_port работает схожим образом. Мы принимаем два аргумента: номер порта и данные, которые будут записаны. Инструкция out пишет данные в порт.
Прерывания
Теперь, прежде чем мы вернемся к написанию драйвера, нам нужно понять, как процессор узнает, что какое-то из устройств выполнило операцию.
Самое простое решение — это опрашивать устройства — непрерывно по кругу проверять их статус. Это по очевидным причинам неэффективно и непрактично. Поэтому здесь в игру вступают прерывания. Прерывание — это сигнал, посылаемый процессору устройством или программой, который означает, что произошло событие. Используя прерывания, мы можем избежать необходимости опрашивать устройства и будем реагировать только на интересующие нас события.
За прерывания в архитектуре x86 отвечает чип под названием Programmable Interrupt Controller (PIC). Он обрабатывает хардверные прерывания и направляет и превращает их в соответствующие системные прерывания.
Когда пользователь что-то делает с устройством, чипу PIC отправляется импульс, называемый запросом на прерывание (Interrupt Request, IRQ). PIC переводит полученное прерывание в системное прерывание и отправляет процессору сообщение о том, что пора остановить то, что он делает. Дальнейшая обработка прерываний — это задача ядра.
Без PIC нам бы пришлось опрашивать все устройства, присутствующие в системе, чтобы посмотреть, не произошло ли событие с участием какого-то из них.
Давай разберем, как это работает в случае с клавиатурой. Клавиатура висит на портах 0x60 и 0x64. Порт 0x60 отдает данные (когда нажата какая-то кнопка), а порт 0x64 передает статус. Однако нам нужно знать, когда конкретно читать эти порты.
Прерывания здесь приходятся как нельзя более кстати. Когда кнопка нажата, клавиатура отправляет PIC сигнал по линии прерываний IRQ1. PIС хранит значение offset , сохраненное во время его инициализации. Он добавляет номер входной линии к этому отступу, чтобы сформировать вектор прерывания. Затем процессор ищет структуру данных, называемую «таблица векторов прерываний» (Interrupt Descriptor Table, IDT), чтобы дать функции — обработчику прерывания адрес, соответствующий его номеру.
Затем код по этому адресу исполняется и обрабатывает прерывание.
Задаем IDT
IDT — это массив, объединяющий структуры IDT_entry. Мы еще обсудим привязку клавиатурного прерывания к обработчику, а сейчас посмотрим, как работает PIC.
Современные системы x86 имеют два чипа PIC, у каждого восемь входных линий. Будем называть их PIC1 и PIC2. PIC1 получает от IRQ0 до IRQ7, а PIC2 — от IRQ8 до IRQ15. PIC1 использует порт 0x20 для команд и 0x21 для данных, а PIC2 — порт 0xA0 для команд и 0xA1 для данных.
Оба PIC инициализируются восьмибитными словами, которые называются «командные слова инициализации» (Initialization command words, ICW).
В защищенном режиме обоим PIC первым делом нужно отдать команду инициализации ICW1 (0x11). Она сообщает PIC, что нужно ждать еще трех инициализационных слов, которые придут на порт данных.
Эти команды передадут PIC:
- вектор отступа (ICW2),
- какие между PIC отношения master/slave (ICW3),
- дополнительную информацию об окружении (ICW4).
Вторая команда инициализации (ICW2) тоже шлется на вход каждого PIC. Она назначает offset , то есть значение, к которому мы добавляем номер линии, чтобы получить номер прерывания.
PIC разрешают каскадное перенаправление их выводов на вводы друг друга. Это делается при помощи ICW3, и каждый бит представляет каскадный статус для соответствующего IRQ. Сейчас мы не будем использовать каскадное перенаправление и выставим нули.
ICW4 задает дополнительные параметры окружения. Нам нужно определить только нижний бит, чтобы PIC знали, что мы работаем в режиме 80×86.
Та-дам! Теперь PIC проинициализированы.
У каждого PIC есть внутренний восьмибитный регистр, который называется «регистр масок прерываний» (Interrupt Mask Register, IMR). В нем хранится битовая карта линий IRQ, которые идут в PIC. Если бит задан, PIC игнорирует запрос. Это значит, что мы можем включить или выключить определенную линию IRQ, выставив соответствующее значение в 0 или 1.
Чтение из порта данных возвращает значение в регистре IMR, а запись — меняет регистр. В нашем коде после инициализации PIC мы выставляем все биты в единицу, чем деактивируем все линии IRQ. Позднее мы активируем линии, которые соответствуют клавиатурным прерываниям. Но для начала все же выключим!
Если линии IRQ работают, наши PIC могут получать сигналы по IRQ и преобразовывать их в номер прерывания, добавляя офсет. Нам же нужно заполнить IDT таким образом, чтобы номер прерывания, пришедшего с клавиатуры, соответствовал адресу функции-обработчика, которую мы напишем.
На какой номер прерывания нам нужно завязать в IDT обработчик клавиатуры?
Клавиатура использует IRQ1. Это входная линия 1, ее обрабатывает PIC1. Мы проинициализировали PIC1 с офсетом 0x20 (см. ICW2). Чтобы получить номер прерывания, нужно сложить 1 и 0x20, получится 0x21. Значит, адрес обработчика клавиатуры будет завязан в IDT на прерывание 0x21.
Задача сводится к тому, чтобы заполнить IDT для прерывания 0x21. Мы замапим это прерывание на функцию keyboard_handler , которую напишем в ассемблерном файле.
Каждая запись в IDT состоит из 64 бит. В записи, соответствующей прерыванию, мы не сохраняем адрес функции-обработчика целиком. Вместо этого мы разбиваем его на две части по 16 бит. Нижние биты сохраняются в первых 16 битах записи в IDT, а старшие 16 бит — в последних 16 битах записи. Все это сделано для совместимости с 286-ми процессорами. Как видишь, Intel выделывает такие номера на регулярной основе и во многих-многих местах!
В записи IDT нам осталось прописать тип, обозначив таким образом, что все это делается, чтобы отловить прерывание. Еще нам нужно задать офсет сегмента кода ядра. GRUB задает GDT за нас. Каждая запись GDT имеет длину 8 байт, где дескриптор кода ядра — это второй сегмент, так что его офсет составит 0x08 (подробности не влезут в эту статью). Гейт прерывания представлен как 0x8e. Оставшиеся в середине 8 бит заполняем нулями. Таким образом, мы заполним запись IDT, которая соответствует клавиатурному прерыванию.
Когда с маппингом IDT будет покончено, нам надо будет сообщить процессору, где находится IDT. Для этого существует ассемблерная инструкция lidt, она принимает один операнд. Им служит указатель на дескриптор структуры, которая описывает IDT.
С дескриптором никаких сложностей. Он содержит размер IDT в байтах и его адрес. Я использовал массив, чтобы вышло компактнее. Точно так же можно заполнить дескриптор при помощи структуры.
В переменной idr_ptr у нас есть указатель, который мы передаем инструкции lidt в функции load_idt() .
Дополнительно функция load_idt() возвращает прерывание при использовании инструкции sti .
Заполнив и загрузив IDT, мы можем обратиться к IRQ клавиатуры, используя маску прерывания, о которой мы говорили ранее.
0xFD — это 11111101 — включаем только IRQ1 (клавиатуру).
Функция — обработчик прерывания клавиатуры
Итак, мы успешно привязали прерывания клавиатуры к функции keyboard_handler , создав запись IDT для прерывания 0x21. Эта функция будет вызываться каждый раз, когда ты нажимаешь на какую-нибудь кнопку.
Эта функция вызывает другую функцию, написанную на C, и возвращает управление при помощи инструкций класса iret. Мы могли бы тут написать весь наш обработчик, но на C кодить значительно легче, так что перекатываемся туда. Инструкции iret/iretd нужно использовать вместо ret , когда управление возвращается из функции, обрабатывающей прерывание, в программу, выполнение которой было им прервано. Этот класс инструкций поднимает флаговый регистр, который попадает в стек при вызове прерывания.
Здесь мы сначала даем сигнал EOI (End Of Interrupt, окончание обработки прерывания), записав его в командный порт PIC. Только после этого PIC разрешит дальнейшие запросы на прерывание. Нам нужно читать два порта: порт данных 0x60 и порт команд (он же status port) 0x64.
Первым делом читаем порт 0x64, чтобы получить статус. Если нижний бит статуса — это ноль, значит, буфер пуст и данных для чтения нет. В других случаях мы можем читать порт данных 0x60. Он будет выдавать нам код нажатой клавиши. Каждый код соответствует одной кнопке. Мы используем простой массив символов, заданный в файле keyboard_map.h , чтобы привязать коды к соответствующим символам. Затем символ выводится на экран при помощи той же техники, что мы применяли в первой версии ядра.
Чтобы не усложнять код, я здесь обрабатываю только строчные буквы от a до z и цифры от 0 до 9. Ты с легкостью можешь добавить спецсимволы, Alt, Shift и Caps Lock. Узнать, что клавиша была нажата или отпущена, можно из вывода командного порта и выполнять соответствующее действие. Точно так же можешь привязать любые сочетания клавиш к специальным функциям вроде выключения.
Теперь ты можешь собрать ядро, запустить его на реальной машине или на эмуляторе (QEMU) так же, как и в первой части.



