- HTML кодировки
- Кодировка ISO
- Кодировки серии ISO 8859
- Для HTML4:
- Для HTML5:
- Кодировка Windows-1251 (CP1251)
- Кодировки стандарта UNICODE
- Таблицы кодировок ASCII, CP1251 (windows1251), ISO-8859-5
- Таблица ASCII
- Таблица CP1251 (windows-1251)
- Таблица IS0-8859-5
- Кодировка UTF-8 (Unicode Transformation Format)
- Файловый Архив
- [Обзор] Что предпочтительнее Windows-1251 или UTF-8?
HTML кодировки
Чтобы правильно отобразить html-документ, браузер должен знать какая кодировка символов использовалась при создании документа.
ASCII — одна из самых старых компьютерных кодировок, в которой каждому символу соответствует строго определенное число. Например, символу «a» соответствует число 97, а символу «A» — число 65.
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
ASCII — это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
Вы можете посмотреть на полный комплект Печатаемых символов ASCII.
Позже ASCII была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в кодировку ASCII символы национальных языков разных стран, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8 (Код Обмена Информацией, 8 бит) — это тоже расширенная кодировка ASCII. KOI8 включала в себя цифры, буквы латинского и русского алфавита, а также знаки пунктуации, спецсимволы и псевдографику.
Кодировка ISO
Организация Международных стандартов (International Standards Organization) создала диапазон кодировок для различных алфавитов/языков.
Кодировки серии ISO 8859
Для документов на английском и большинстве других западноевропейских языков, широко поддерживается кодирование ISO-8859-1.
В HTML ISO-8859-1 является кодировкой по умолчанию (в XHTML и в HTML5 кодировкой по умолчанию является UTF-8).
При использовании кодировки страницы, отличной от ISO-8859-1, вам необходимо указать это в теге .
Для HTML4:
Для HTML5:
Примером ANSI-кодировки является всем известная Windows-1251.
Windows-1251 выгодно отличается от других 8 битных кириллических кодировок (таких как CP866 и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только знак ударения). Она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Ниже приведены десятичные значения символов кодировки Windows-1251.
Для отображения символов таблицы в HTML-документе воспользуйтесь следующим синтаксисом:
Кодировка Windows-1251 (CP1251)
402
403
201A
453
201E
2026
2020
2021
20AC
2030
409
2039
40A
40C
40B
40F
452
2018
2019
201C
201D
2022
2013
2014
2122
459
203A
45A
45C
45B
45F
40E
45E
408
A4
490
A6
A7
401
A9
404
AB
AC
AD
AE
407
B0
B1
406
456
491
B5
B6
B7
451
2116
454
BB
458
405
455
457
410
411
412
413
414
415
416
417
418
419
41A
41B
41C
41D
41E
41F
420
421
422
423
424
425
426
427
428
429
42A
42B
42C
42D
42E
42F
430
431
432
433
434
435
436
437
438
439
43A
43B
43C
43D
43E
43F
440
441
442
443
444
445
446
447
448
449
44A
44B
44C
44D
44E
44F
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).
UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
Таблицы кодировок ASCII, CP1251 (windows1251), ISO-8859-5
Таблица ASCII
Таблица ASCII (American standard code for information interchange) является мировым стандартом для кодирования букв английского алфавита, популярных спец символов (! $ # % & и т.д.) и некоторых непечатных символов (например, возврат каретки 0x0D и перенос строки 0х0А).
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.
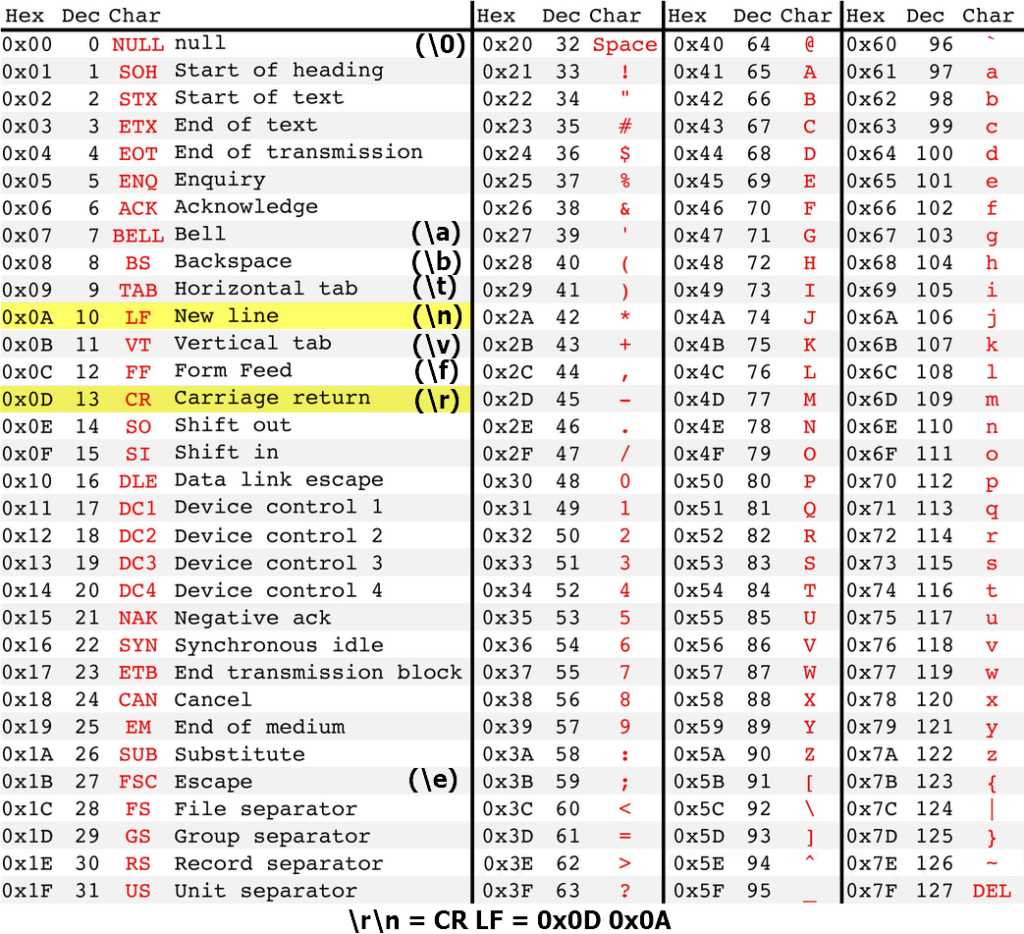
Таблица CP1251 (windows-1251)
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.
Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.

Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.
Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.
Файловый Архив
[Обзор] Что предпочтительнее Windows-1251 или UTF-8?
- Мемберка
- Администраторам
- Premoderation
- Новичкам!
- Изменения в правах
- Каталог Фрилансеров
- Если вы хотите купить какой то хак
На форуме введена премодерация ВСЕХ новых пользователей
Почта с временных сервисов, типа mailinator.com, gawab.com и/или прочих, которые предоставляют временный почтовый ящик без регистрации и/или почтовый ящик для рассылки спама, отслеживается и блокируется, а так же заносится в спам-блок форума, аккаунты удаляются
Внимание! Чтобы получить доступ к скачиванию вложений, необходимо не только брать с этого ресурса, но и вкладывать что-то своё в общую копилку знаний
Размещение публикации в разделе Кандидатский — простой способ поделиться наработками и получить повышение
Перед созданием темы ознакомьтесь с Правилами раздела
и отдельный раздел для платных заказов « Куплю/Закажу «
| Страница 1 из 2 | 1 | 2 | > |
| 30.06.2011, 13:38
Очень много иногда вижу вопросов, и не только на этом форуме, что все таки лучше Windows-1251 или UTF-8? Пришел к выводу, что надо бы для пользователей опубликовать одну статейку, которую читал уже давненько. Лично для меня, так все проекты давно на utf-8, но как говориться объясни разницу. для этого приведу в пример статейку:
Не так давно, в связи со сложившимися обстоятельствами, решил отказаться от кодировки Windows-1251, с которой работал очень давно, и целиком и полностью перейти на UTF-8. Все причины перехода раскрывать не буду, но основные из них: большинство современных веб-платформ по-умолчанию работают именно на ней; набор используемых в кодировки символов около 100000; Немного теории UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт. Основные отличия кодировок Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате. UTF-8 позволяет работать одновременно с несколькими языками, т.е. выдавать тексты, в которых используются символы разных алфавитов и даже иероглифы. С использованием кодировки 1251 это невозможно; Минусы UTF-8… А есть ли они у этой кодировки вообще? Я знаю только разных мифах и легендах на эту тему, вот некоторые из них: “У UTF-8 есть проблемы со старыми браузерами” – маловероятно… Во всяком случае, если под старыми не подразумевают Lynx и Mosaic _); |

Я не призываю всех поголовно переходить на utf-8. я просто хотел рассказать, что намного удобнее использовать именно эту кодировку. Расписать можно на эту тему еще кучу постов. но очевидно что utf-8 это международный стандарт, используемый всем миром))
UTF?8 — вовсе не «новомодная» или «молодая» кодировка, она успешно применяется более десяти лет. Если некий разработчик узнал о ней недавно или не знает до сих пор — это недостаток его квалификации, а не кодировки.
С UTF?8 возникают проблемы на веб?сервере?
«Я поместил на сервер страницу в UTF?8, а она отображается кракозябрами»,— так иногда жалуются начинающие разработчики. На самом деле, такая проблема случается с самыми разными кодировками и не связана ни с какими специфическими особенностями UTF?8. Здесь неприятность в том, что страница сделана в одной кодировке, а сервер в заголовках HTTP сообщает другую. Надо привести настройки сервера в соответствие с действительной кодировкой веб?страниц. Повторю, что это надо сделать при любой кодировке.
Файлы в UTF?8 занимают много места?
Говорят, что документы в UTF?8 становятся в два раза больше, чем в старых кодировках. Это миф из разряда «слышал звон, да не знаю, где он». На самом деле — раз на раз не приходится. Например, если документ состоит только из символов ASCII (латинские буквы, цифры, знаки препинания и т. д.) — то в кодировке UTF?8 он будет занимать ровно столько же байтов, сколько в любой другой. Если документ содержит только буквы русского алфавита и никаких других символов (что, согласитесь, бывает достаточно редко) — то в UTF?8 он действительно станет в два раза больше. А если в нём, например, поровну русских и арабских букв — в UTF?8 он будет в два раза меньше, чем, например, в Windows?1251 или Asmo?708.
Та самая страница, которую вы сейчас читаете, в кодировке UTF?8 занимает 35 килобайтов. А если перевести её, например, в Windows?1251, она будет занимать 26 килобайтов (убедитесь сами). Кстати, сравнивая страницы, посмотрите, насколько легче читается код в UTF?8.
Рассуждая о «весе» веб?страниц, следует отметить, что основную часть этого веса обычно составляет не код HTML, а изображения. (А также, возможно, другие объекты: ролики Flash, файлы JavaScript и т. д.) В результате даже в тех случаях, когда документ в UTF?8 увеличивается — это практически незаметно в общем объёме данных. По?моему, «разбухание» кода на несколько процентов — недорогая цена за главное преимущество UTF?8, с которого мы начали.
Тем, кто заботится о «весе», следовало бы в первую очередь выкинуть из кода устаревшие атрибуты HTML (вроде cellpadding или valign) и подстановки для тех символов, которым они не нужны (например, — для длинного тире или для неразрывного пробела). Действительно, иногда доходит до маразма — некто упирается: «Не буду делать страницы в UTF?8, потому что они от этого увеличиваются» — а сам при этом ваяет код с жуткими атрибутами и подстановками, который без них мог бы быть в пять раз короче.
Серверные языки программирования и базы данных плохо поддерживают UTF?8?
Кто?то скажет: «Всё это хорошо, пока мы имеем дело со статичными веб?страницами. Но если мы пользуемся PHP и MySQL, про UTF?8 лучше забыть». Это тоже неправда. В древности, действительно, некоторые языки программирования и системы управления базами данных не умели работать с UTF?8. Но сейчас все современные языки программирования и базы данных находятся в прекрасных отношениях с этой кодировкой. А несовременными языками и базами пользоваться не ст?ит: чем древнее ваши системы, тем проще их взломать.
Единственная трудность с серверными программами — в том, что многие из них по умолчанию настроены не на UTF?8, а на другие кодировки. Ну так перенастройте; мы же с вами не дети малые, чтобы везде и всюду использовать только настройки по умолчанию.
Поисковые системы плохо работают с UTF?8?
Ещё приходится слышать, будто поисковые системы «спотыкаются» об UTF?8. Эти сведения, опять же, устарели лет на восемь. Вот вам, например, поисковая система «Яндекс»:
Убедитесь, что она прекрасно находит всё, что угодно, на моём персональном сайте, где, между прочим, её работу «осложняет» не только UTF?8, но и переносы в словах.
Таким образом, не существует никаких противопоказаний к широкому применению UTF?8. Те, кто считает по?другому, просто отстали от жизни.
Когда UTF?8 не надо использовать
Конечно, бывают случаи, когда самую лучшую кодировку UTF?8 использовать всё?таки нежелательно. Хотя это вовсе не те ситуации, которыми пугают адепты вышеразвенчанных мифов.
Во?первых, иногда нам требуется не создавать новый документ, а внести изменения в уже существующий. Обычно в таких случаях нет смысла преобразовывать имеющийся документ в кодировку UTF?8, поэтому приходится редактировать его в той кодировке, в которой он представлен.
Во?вторых, иногда работу сайта обеспечивает программное ядро (так называемый «движок»), которое не умеет работать с UTF?8. В такой ситуации, конечно, следует задуматься, нет ли возможности подправить «движок» или заменить его на другой. Но это не всегда удаётся. Некоторые программные ядра обеспечивают функциональные достоинства, ради которых можно смириться с устаревшей кодировкой.
Как работать с UTF?8
В качестве «недостатков» UTF?8 упоминают и тот факт, что с ней сложно работать — мол, не все текстовые редакторы её поддерживают. Ну так пользуйтесь хорошим редактором, у которого нет проблем с современными кодировками. Кодировку UTF?8 понимают все нынешние редакторы — от стандартного «Блокнота» в Windows до Dreamweaver’а. (Сам я, кстати, пользуюсь EmEditor’ом, и этот сайт сделан именно его средствами.)
Надеюсь, что дальнейшие рекомендации будут вам полезны при работе с UTF?8.
При сохранении файла многие текстовые редакторы предлагают флажок «Include Unicode Signature (BOM)», «Add Byte Order Mark» или нечто подобное. Прежде всего убедитесь, что в вашем редакторе это есть. Если похожей настройки не обнаружено (как, например, в «Блокноте») — пользоваться таким редактором для серьёзных задач не ст?ит. Найдя этот флажок — отключите его.
Byte Order Mark (BOM) — это три служебных байта, которые автоматически записываются в начало документа и обозначают, что он сохранён в кодировке UTF. Подробности можно прочитать в справочнике, а практическая сторона заключается в том, что эти служебные байты в UTF?8 не являются необходимыми, зато, наоборот, могут ввести в заблуждение некоторые старые браузеры и другие программы.
Настройте простые сочетания клавиш для специальных символов
Если за каждой кавычкой, тире или неразрывным пробелом лезть в «Таблицу символов» — можно до старости провозиться с одним?единственным документом. Для наиболее распространённых специальных символов рекомендуется настроить сочетания клавиш, что обеспечит любой хороший редактор. Например, я наладил EmEditor так, что по нажатию Ctrl? -? ?? в документе появляется длинное тире, а по нажатию Ctrl? пробел? ?? — неразрывный пробел. Таких сочетаний клавиш у меня около 20, и они позволяют вводить наиболее полезные специальные символы так же просто, как обычные буквы и знаки препинания.
Конечно, когда мне требуется редко используемый символ — буква «юс», рожица или иероглиф,— я обращаюсь к «Таблице символов».
Указывайте кодировку везде, где требуется
Убедитесь, что веб?сервер сообщает правильную кодировку страниц. Если это не так — обратитесь к администратору сервера или прочтите справочные материалы о том, как настроить кодировку.
Встречаются службы размещения сайтов (хостинги), которые «намертво привязаны» к какой?либо одной кодировке и не позволяют хозяевам сайтов пользоваться другими кодировками. С такими хостингами связываться не ст?ит. В какой кодировке делать страницы — должен решать разработчик сайта, а не служба его размещения.
В коде HTML часто имеет смысл использовать элемент meta:
Существуют разные мнения про использование meta для указания кодировки. Когда?то я считал, что этот элемент скорее вреден, чем полезен. Однако ряд исследований и собственный опыт заставили меня пересмотреть свою точку зрения. Применять или не применять meta — следует решать отдельно для каждого конкретного сайта.
Не забывайте о шрифтах
Какой бы кодировкой вы ни пользовались, надо помнить, что браузеры отображают только те символы, которые есть в установленных на компьютере шрифтах. «Таблица символов» показывает именно их. Перечень стандартных шрифтов Windows размещён в разделе «Справочники».
В Unicode можно найти немало других символов — например, руны (, и пр.), буквы глаголицы (, и пр.), разнообразные значки и пиктограммы (, , и пр.). Но вставить их в документ не получится: у подавляющего большинства пользователей нет шрифтов, в которых присутствовали бы эти знаки. Тут даже UTF?8, при всех её достоинствах, помочь не в силах. Приходится размещать такие символы в виде растровых изображений (как сделано здесь) или искать другие обходные пути.
Многие другие «экзотические» символы обычно доступны на компьютерах пользователей, но браузеру приходится помогать найти нужный шрифт. Например, чтобы отобразить старославянские буквы (?, ? и пр.) или математические знаки (?, ? и пр.) — я указываю в CSS шрифт «Lucida Sans Unicode».
Один из редких мифов в пользу UTF?8 говорит, что эта кодировка заставляет компьютер отображать такие символы, которые недостижимы ни в одной старой кодировке. Однако чудес не бывает: если у вас на компьютере нет шрифта, в котором присутствует скрипичный ключ,— то вы не увидите этого символа в UTF?8 с таким же успехом, как в любой другой кодировке.
Главное преимущество UTF?8 — не в волшебном расширении набора символов, а в простом способе их включения в документ.
Смотрите в будущее
Если вы знакомы с Unicode, то, возможно, поинтересуетесь, почему я советую именно UTF?8, а не другие современные кодировки — скажем, UTF?16 или UTF?32. Отвечаю: они обеспечивают то же главное преимущество, что и UTF?8, но обладают и рядом недостатков. Во?первых, они, в отличие от UTF?8, действительно заметно увеличивают «вес» файлов. Во?вторых, с ними в некоторых используемых ныне браузерах ещё возникают проблемы.
Кстати, Консорциум W3C рекомендует использовать для веб-страниц именно UTF?8.



