- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Загрузка ЦПУ в Linux — насколько варит ваш котелок
- Методы проверки
- Проверяем загрузку процессора с помощью команды top
- Немного более модный способ: htop
- Прочие способы проверки степени загрузки ЦПУ
- Как настроить оповещения о слишком высокой нагрузке на процессор
- Заключение
- Полезно?
- Почему?
- 16 команд мониторинга Linux-сервера, которые вам действительно нужно знать
- iostat
- meminfo и free
- mpstat
- netstat
- ps и pstree
- strace
- tcpdump
- uptime
- vmstat
- Wireshark
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Загрузка ЦПУ в Linux — насколько варит ваш котелок
Понимать состояние ваших серверов с точки зрения их загрузки и производительности — крайне важная задача. В этой статье мы опишем несколько самых популярных методов для проверки и мониторинга загрузки ЦПУ на Linux хосте.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена


Методы проверки
Проверяем загрузку процессора с помощью команды top
Отличным способом проверки загрузки является команда top. Вывод этой команды выглядит достаточно сложным, зато если вы в нем разберетесь, то точно сможете понять какие процессы занимают большую часть ваших вычислительных мощностей.
Команда состоит всего из трех букв: top
У вас откроется окно в терминале, которое будет отображать запущенные сервисы в реальном времени, долю системных ресурсов, которую эти сервисы потребляют, общую сводку по загрузке CPU и т.д
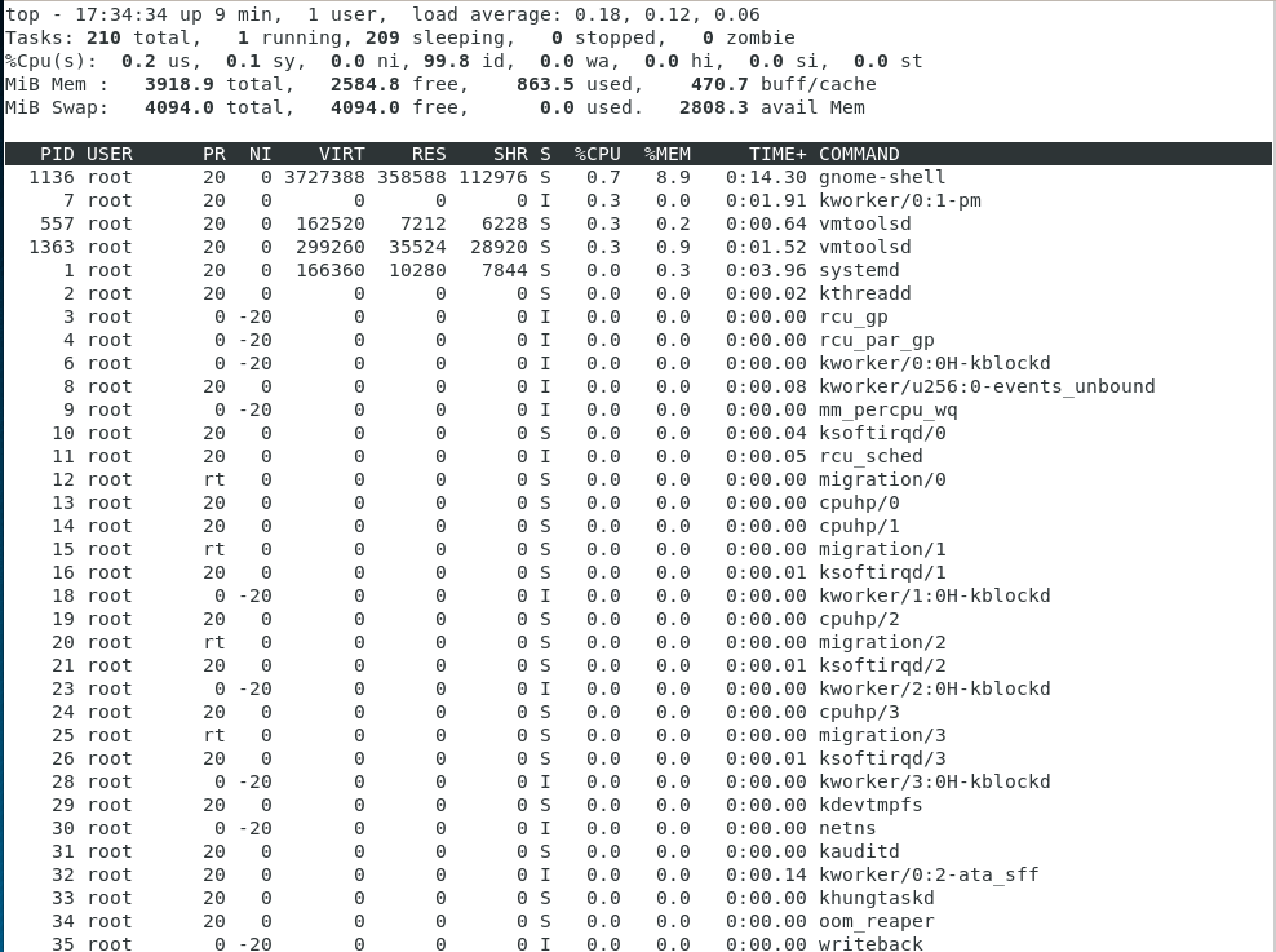
Будем идти по порядку: первая строчка отображает системное время, аптайм, количество активных пользовательских сессий и среднюю загруженность системы. Средняя загруженность для нас особенно важна, т.к дает понимание о среднем проценте утилизации ресурсов за некоторые промежутки времени.
Три числа показывают среднюю загрузку: за 1, 5 и 15 минут соответственно. Считайте, что эти числа — это процентная загрузка, т.е 0.2 означает 20%, а 1.00 — стопроцентную загрузку. Это звучит и выглядит достаточно логично, но иногда там могут проскакивать странные значения — вроде 2.50. Это происходит из-за того, что этот показатель не прямое значение загрузки процессора, а нечто вроде общего количества «работы», которое ваша система пытается выполнить. К примеру, значение 2.50 означает, что текущая загрузка равна 250% и ваша система на 150% перегружена.
Вторая строчка достаточна понятна и просто показывает количество задач, запущенных в системе и их текущий статус.
Третья строчка позволит вам отследить загрузку ЦПУ с подробной статистикой. Но здесь нужно сделать некоторые комментарии:
- us: процент времени, когда ЦПУ был загружен и которое было затрачено на user space (созданные/запущенные пользователем процессы)
- sy: процент времени, когда ЦПУ был загружен и которое было затрачено на на kernel (системные процессы)
- ni: процент времени, когда ЦПУ был загружен и которое было затрачено на приоритезированные пользовательские процессы (системные процессы)
- id: процент времени, когда ЦПУ не был загружен
- wa: процент времени, когда ЦПУ ожидал отклика от устройств ввода — вывода (к примеру, ожидание завершения записи информации на диск)
- hi: процент времени, когда ЦПУ получал аппаратные прерывания (например, от сетевого адаптера)
- si: процент времени, когда ЦПУ получал программные прерывания (например, от какого-то приложения адаптера)
- st: сколько процентов было «украдено» виртуальной машиной — в случае, если гипервизору понадобилось увеличить собственные ресурсы
Следующие две строчки показывают сколько занято/свободно оперативно памяти и файла подкачки, и не так релевантны относительно задачи проверки нагрузки на процессор. Под информацией о памяти вы увидите список процессов и процент ЦПУ, который они тратят.
Также вы можете нажимать на кнопку t, чтобы прокручивать между различными вариантами вывода информации и использовать кнопку q для выхода из top
Немного более модный способ: htop
Существует более удобная утилита под названием htop, которая предоставляет достаточно удобный интерфейс с красивым форматированием. Установка утилиты экстремально проста:
Для Ubuntu и Debian:
sudo apt-get install htop
Для CentOS и Red Hat:
yum install htop
dnf install htop
После установки просто введите команду ниже:

Как видно на скриншоте, htop гораздо лучше подходит для простой проверки степени загрузки процессора. Выход также осуществляется кнопкой q
Прочие способы проверки степени загрузки ЦПУ
Есть еще несколько полезных утилит, и одна из них (а точнее целый набор) называется sysstat.
Установка для Ubuntu и Debian:
sudo apt-get install sysstat
Установка для CentOS и Red Hat:
yum install sysstat
Как только вы установите systat, вы сможете выполнить команду mpstat — опять же, практически тот же вывод, что и у top, но в гораздо лаконичнее.

Следующая утилита в этом пакете это sar. Она наиболее полезна, если вы ее вводите вместе с каким-нибудь числом, например 6. Это определяет временной интервал, через который команда sar будет выводить информацию о загрузке ЦПУ.

К примеру, проверяем загрузку ЦПУ каждые 6 секунд:
Если же вы хотите остановить вывод после нескольких итераций, например 10, добавьте еще одно число:
Так вы также увидите средние значения за 10 выводов.
Как настроить оповещения о слишком высокой нагрузке на процессор
Одним из самых правильных способов является написание простого bash скрипта, который будет отправлять вам алерты о слишком высокой степени утилизации системных ресурсов.
Скрипт будет использовать обработчик sed и среднюю загрузку от команды sar. Как только нагрузка на сервер будет превышать 85%, администратор будет получать письмо на электронную почту. Соответственно, значения в скрипте можно изменить под ваши требования — к примеру поменять тайминги, выводить алерт в консоль, отправлять оповещения в лог и т.д.
Естественно, для выполнения этого скрипта нужно будет запустить его по крону:
Для ежеминутного запуска введите:
Заключение
Соответственно, лучшим способом будет комбинировать эти способы — например использовать htop при отладке и экспериментах, а для постоянного контроля держать запущенным скрипт.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Полезно?
Почему?
😪 Мы тщательно прорабатываем каждый фидбек и отвечаем по итогам анализа. Напишите, пожалуйста, как мы сможем улучшить эту статью.
😍 Полезные IT – статьи от экспертов раз в неделю у вас в почте. Укажите свою дату рождения и мы не забудем поздравить вас.
Источник
16 команд мониторинга Linux-сервера, которые вам действительно нужно знать
Хотите знать, что самом деле происходит на с вашим сервером? Тогда вы должны знать эти основные команды. Как только вы их освоите, вы станете администратором-экспертом в системах Linux.
В зависимости от дистрибутива Linux, вы можете с помощью программы с графическим интерфейсом получить больше информации, чем могут дать эти команды, запускаемые из командной оболочки. В SUSE Linux, например, есть отличное графическое инструментальное средство YaST , предназначенное для конфигурирования и управления системой; также в KDE есть отличное инструментальное средство KDE System Guard .
Однако, основное правило администратора Linux состоит в том, что вы должны работать с графическим интерфейсом на сервере только в случае, когда это вам абсолютно необходимо. Это обусловлено тем, что графические программы на Linux занимают системные ресурсы, которые было бы лучше использовать в другом месте. Поэтому хотя программа с графическим интерфейсом и может отлично подходить для базовой проверки состояния сервера, если вы хотите знать, что происходит на самом деле, отключите графический интерфейс и воспользуйтесь инструментальными средствами, работающими из командной строки Linux.
Это также означает, что вы должны запускать графический интерфейс на сервере только тогда, когда это действительно необходимо; не оставляйте его работать. Чтобы достичь оптимальной производительности, сервер Linux должен работать на уровне runlevel 3 , на котором, когда компьютер загружается, полностью поддерживается работа в сети и многопользовательский режим, но графический интерфейс не запускается. Если вам действительно нужно графический рабочий стол, вы всегда можете его открыть с помощью команды startx , выполненной из командной строки.
Если ваш сервер при загрузке запускается в графическом режиме, то вам это нужно изменить. Для этого откройте терминальное окно, с помощью команды su перейдите в режим пользователя root и с помощью вашего любимого текстового редактора откройте файл /etc/inittab .
Как только вы это сделаете, найдите строку initdefault и измените ее с id:5:initdefault: на id:3:initdefault:
Если файла inittab нет, то создайте его и добавьте строку id:3 . Сохраните файл и выйдите из редактора. В следующий раз при загрузке ваш сервер будет загружаться на уровне запуска 3. Если вы после этого изменения не захотите перезагружать сервер, вы также можете с помощью команды init 3 непосредственно задать уровень запуска вашего сервера.
Как только ваш сервер станет работать на уровне запуска init 3, вы для того, чтобы увидеть, что происходит внутри вашего сервера, можете начать пользоваться следующими программами командной оболочки.
iostat
Команда iostat подробно показывает, что к чему в вашей подсистеме хранения данных. Как правило, вы должны использовать команду iostat для того, чтобы следить, что ваша подсистема хранения работают в целом хорошо и прежде, чем ваши клиенты заметят, что сервер работает медленно, выявлять те места, из-за медленного ввода/вывода которых возникают проблемы. Поверьте мне, вам следует обнаруживать эти проблемы раньше, чем это сделают ваши пользователи!
meminfo и free
Команда meminfo предоставит вам подробный список того, что происходит в памяти. Как правило, доступ к данным meminfo можно получить с помощью другой программы, например, cat или grep . Так, например, с помощью команды
вы в любой момент будете знать все, что происходит в памяти вашего сервера.
Вы можете воспользоваться командой free для быстрого «фактографического» взгляда на память. Если кратко, то с помощью команды free вы получите обзор состояния памяти, а с помощью команды meminfo вы узнаете все подробности.
mpstat
Команда mpstat сообщает о действиях каждого из доступных процессоров в многопроцессорных серверах. В настоящее время почти во всех серверах используются многоядерные процессоры. Команда mpstat также сообщает об усредненной загрузке всех процессоров сервера. Это позволяет отображать общую статистику по процессорам во всей системе или для каждого процессора отдельно. Эти значения могут предупредить вас о возможных проблемах с приложением прежде, чем они станут раздражать пользователей.
netstat
Команда netstat , точно также, как и ps , является инструментальным средством Linux, которым администраторы пользуются каждый день. Она отображает большое количество информации о состоянии сети, например, об использовании сокетов, маршрутизации, интерфейсах, протоколах, показывает сетевую статистику и многое другое. Некоторые из наиболее часто используемых параметров:
-a — Показывает информацию о всех сокетах
-r — Показывает информацию, касающуюся маршрутизации
-i — Показывает статистику, касающуюся сетевых интерфейсов
-s — Показывает статистику, касающуюся сетевых протоколов
Команда nmon , сокращение от Nigel’s Monitor, является популярным инструментальным средством с открытым исходным кодом, которое предназначено для мониторинга производительности систем Linux. Команда nmon следит за информацией о производительности нескольких подсистем, таких как использование процессоров, использование памяти, выдает информацию о работе очередей, статистику дисковых операций ввода/вывода, статистику сетевых операций, активности системы подкачки и метрические характеристики процессов. Затем вы через «графический» интерфейс команды curses можете в режиме реального времени просматривать информацию, собираемую командой nmon.
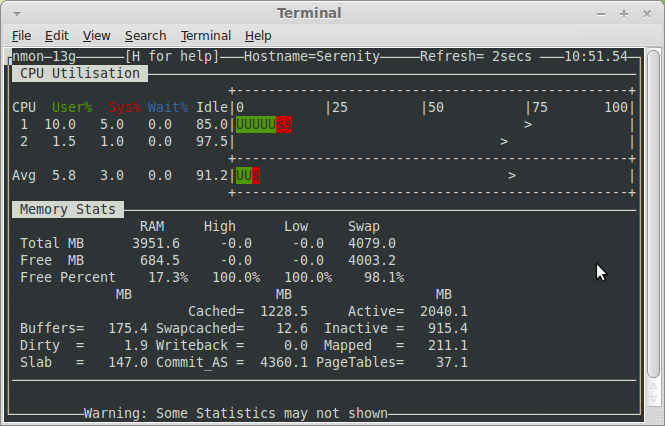
Чтобы команда nmon работала, вы должны ее запустить из командной строки. После этого вы можете с помощью нажатий на отдельные клавиши выбирать подсистемы, за работой которых вы хотите проследить. Например, чтобы получить статистику по процессору, памяти и дискам, наберите c , m и d . Вы также можете использовать команду nmon с флагом -f для того, чтобы сохранить статистику в файле CSV для последующего анализа.
Я считаю, что для повседневного мониторинга серверов команда nmon является одной из самых полезных программ в моем инструментальном наборе, предназначенном для систем Linux.
Команда pmap сообщает об объеме памяти, которые используются процессами на вашем сервере. Вы можете использовать этот инструмент для того, чтобы определить, для каких процессов на сервере выделяется память и как эти процессы ее используют.
ps и pstree
Команды ps и pstree являются двумя самыми лучшими командами администратора Linux. Они обе выдают список всех запущенных процессов. Команда ps показывает, сколько памяти и процессорного времени используют программы, работающие на сервере. Команда pstree выдает меньше информации, но указывает, какие процессы являются потомками других процессов. Имея эту информацию, вы можете обнаружить неуправляемые процессы и уничтожить их с помощью команды kill , предназначенной для «безусловного уничтожения» процессов в Linux.
Программа sar является инструментальным средством мониторинга, столь же универсальным как швейцарский армейский нож. Команда sar , на самом деле, состоит из трех программ: sar , которая отображает данные, и sa1 и sa2 , которые собирают и запоминают данные. После того, как программа sar установлена, она создает подробный отчет об использовании процессора, памяти подкачки, о статистике сетевого ввода/вывода и пересылке данных, создании процессов и работе устройств хранения данных. Основное отличие между sar и nmon в том, что первая команда лучше при долгосрочном мониторинге системы, в то время, как я считаю, nmon лучше для того, чтобы мгновенно получить информацию о состоянии моего сервера.
strace
Команду strace часто рассматривают, как отладочное средство программиста, но, на самом деле, ее можно использовать не только для отладки. Команда перехватывает и записывает системные вызовы, которые происходят в процессе. Т.е. она полезна в диагностических, учебных и отладочных целях. Например, вы можете использовать команду strace для того, чтобы выяснить, какой на самом деле при запуске программы используется конфигурационный файл.
tcpdump
Tcpdump является простой и надежной утилитой мониторинга сети. Ее базовые возможности анализа протокола позволяют получить общее представление о том, что происходит в вашей сети. Однако, чтобы по-настоящему разобраться в том, что происходит в вашей сети, вам следует воспользоваться программой Wireshark (см. ниже).
Команда top показывает, что происходит с вашими активными процессами. По умолчанию она отображает самые ресурсоемкие задачи, запущенные на сервере, и обновляет список каждые пять секунд. Вы можете отсортировать процессы по PID (идентификатор процесса), времени работы, можете сначала указывать новые процессы, затраты по времени, по суммарному затраченному времени, а также по используемой памяти и по общему времени использования процессора с момента запуска процесса. Я считаю, что это быстрый и простой способ увидеть, что некоторый процесс начинает выходить из-под контроля и из-за этого все движется к проблеме.
uptime
Используйте команду uptime для того, чтобы узнать, как долго работает сервер и сколько пользователей было зарегистрировано в системе. Эта команда также покажет вам среднюю загрузку сервера. Оптимальное значение равно 1 или меньше, что означает, что каждый процесс немедленно получает доступ к процессору и потери циклов процессора отсутствуют.
vmstat
Вы можете использовать команду vmstat , в основном, для контроля того, что происходит с виртуальной памятью. Для того, чтобы получить наилучшую производительность системы хранения данных, Linux постоянно обращается к виртуальной памяти.
Если ваши приложения занимают слишком много памяти, вы получите чрезмерное значение затрат страниц памяти (page-outs) — программы перемещаются из оперативной памяти в пространство подкачки вашей системы, которое находится на жестком диске. Ваш сервер может оказаться в таком состоянии, когда он тратит больше времени на управление памятью подкачки, а не на работу ваших приложений; это состояние называемое пробуксовкой (thrashing). Когда компьютер находится в состоянии пробуксовки, его производительность падает очень сильно. Команда vmstat , которая может отображать либо усредненные данные, либо фактические значения, может помочь вам определить программы, которые занимают много памяти, прежде, чем из-за них ваш процессор перестанет шевелиться.
Wireshark
Программа wireshark , ранее известная как ethereal (и до сих пор часто называют именно так), является «старшим братом» команды tcpdump , хотя она более сложная и с более расширенными возможностями анализа и отчетности по используемым протоколам. У wireshark есть как графический интерфейс, так и интерфейс командной оболочки. Если вам требуется серьезное администрирование сетей, вам следует использовать программу ethereal. И, если вы используете wireshark/ethereal, я настоятельно рекомендую воспользоваться книгой Practical Packet Analysis Криса Сандера (Chris Sander), рассказывающей о том, как с помощью практического анализа пакетов можно получить максимальную отдачу от этой полезной программы.
Это обзор всего лишь нескольких наиболее значимых систем мониторинга из многих, имеющихся для Linux. Тем не менее, если вы сможете освоить эти программы, они помогут вам на пути к вершинам системного администрирования Linux.
Источник



