- Linux, Windows или macOS: что выбрать программисту — отвечают эксперты
- Linux, Windows или macOS: что выбрать программисту — отвечают эксперты
- старший backend-разработчик .defa
- инженер-программист компании ICL Services
- декан профессии «Программист С++» образовательного портала GeekBrains
- ведущий frontend-разработчик TalentTech
- разработчик в Kodix Auto
- Итак, кому какой системой стоит пользоваться?
- Где используется Java, пишут ли на ней под Windows?
- Java и Linux — особенности эксплуатации
- Память в Java
- Память в Linux
- Важные факты о JVM
- Когда заканчивается память
- Когда память заканчивается в JVM
- Выделяем память в Java
- Выделяем память в Linux
- Пару слов про Docker
- Потоки в Java
- Как найти java—потоки
- Итого о потоках
- IO и Networking
Linux, Windows или macOS: что выбрать программисту — отвечают эксперты
Linux, Windows или macOS: что выбрать программисту — отвечают эксперты
У каждой ОС есть свои плюсы, минусы и особенности, и как правило программисты выбирают ОС на основе своих предпочтений и представлений. Но что, если отбросить личные симпатии и попытаться взглянуть объективно: какая ОС даёт больше всего преимуществ программисту? Мы задали этот вопрос экспертам, и вот что они ответили.

старший backend-разработчик .defa
Выбор ОС в первую очередь зависит от того, в какой области разработчик работает, а ещё это дело привычки и субъективных представлений об удобстве. Я веб-разработчик и успел попробовать несколько операционных систем. Вот мой личный рейтинг удобства ОС именно для разработки веб-решений.
Первое место — macOS. Практически всё идеально, могут возникать проблемы с Docker, поскольку не всегда оптимально используются ресурсы (бывает >= 70 % CPU). Но это мелочи. macOS — это практически идеальный баланс между ОС для работы и для повседневных задач.
Ещё одно первое место — Ubuntu/Mint (и другие Linux-дистрибутивы). Именно для разработки я считаю это семейство ОС лучшей. Из плюсов перед macOS — близость к production-окружению, «нативная» работа Docker. Из минусов — всё-таки иногда всплывают ошибки, которые без консоли не поправить (пример, проблемы со звуком), ну и софта гораздо меньше.
Второе место отдам Windows. Здесь можно спокойно вести разработку. При наличии такого софта как Docker или Vagrant многие проблемы можно легко обойти. Чего мне действительно не хватает в Windows, так это нормального терминала (ConEmu, Git Bash и другие не в счёт). Зато софта под эту ОС гораздо больше, чем на Ubuntu или macOS.
В качестве заключения отмечу, что всё-таки выбирать стоит ту ОС, в которой разработчику привычнее и комфортнее работать. Если всё в операционной системе устраивает, то переход на что-то другое вызовет лишний стресс и трату времени на изучение возможностей новой ОС. В конце концов, в ту же Windows потихоньку внедряется WSL.

инженер-программист компании ICL Services
На вопрос, какую операционную систему выбрать для программирования, в большинстве случае нет чёткого ответа, т. к. это больше субъективный выбор каждого человека: как по удобству взаимодействия с самой системой, так и с используемыми инструментами для разработки. Большинство популярных языков и сред разработки в основном присутствуют на всех платформах.
Конечно, есть немало случаев, когда выбор ограничен. Например язык программирования плохо адаптирован под конкретную операционную систему или требуется конкретная платформа для выполнения, тут стоило бы или даже необходимо использовать то, что есть.
Если ограничений нет, то, я считаю, самый правильный выбор — попробовать каждую из систем, для того чтобы решить, что же конкретно тебе удобнее. У каждой системы есть как плюсы, так и минусы: где-то удобнее разворачивать среду и работать с ней, где-то есть более удобные инструменты разработки и т. д., поэтому говорить, что для веб-разработки нужна обязательно macOS или для разработки на .net core нужен Windows, я считаю, неправильно.
Также для нашей страны актуален вопрос цены рабочей машины. Например, для многих, а тем более для начинающих, продукты компании Apple могут показаться дорогими при прочих равных. У компьютеров на Windows или Linux ценник более доступный.
Если подытожить, то если нет ограничений на выбор системы, советую попробовать все системы и выбрать ту конфигурацию системы и инструментов, которую удобно использовать именно вам.

декан профессии «Программист С++» образовательного портала GeekBrains
В первую очередь нужно быть уверенным, что инструмент, с которым человек будет работать, удобен. А операционная система — это инструмент и ничто иное. Если говорить о выборе операционки, то неплохо было бы сразу знать, где ваше приложение будет в дальнейшем крутиться. Если человек предполагает разработку под операционную систему OS X (под MacBook, iOS, iPhone, iPad), то ему обязательно нужен опыт работы в macOS и собственно сама OS X, потому что все остальные операционки хоть и поддерживают языки Swift и Objective-C, но на довольно слабом уровне. Инструментарий разработки под OS X внутри OS X хорошо настроен и нативен.
Дальше у нас встает извечная борьба между Windows и Linux. Начинать холивар, я думаю, смысла нет. Если у пользователя есть привычка работать в Windows — то имеет смысл в этой операционной системе и оставаться, так как в принципе, 80 % задач разработки можно закрывать в Windows. Если хочется попробовать что-то другое — это, бесспорно, Linux. Желательно делать Linux на виртуальной машине, чтобы не потерять своё текущее окружение, но иметь возможность «пощупать». Очень много всякого софта для разработки написано под обе операционки, тут тоже стоит сразу оговориться, что если предполагается разработка на Android — то надо быть по крайней мере знакомым с операционной системой Linux. Необходимо представлять, что это за окружение, как оно работает, знать про открытые драйверы, системные настройки, потому что Android — это тоже Linux.
Есть специализированный стек разработки под Windows: это разработка под Active Directory, разработка разнообразных протоколов, разработка под Microsoft Office и прочие штуки. Понятное дело, что с Microsoft Office перейти на Linux будет нельзя, под него стопроцентно нужен Windows. Тут встает вопрос лицензирования. Если у человека всю жизнь был Linux, то ему не с руки покупать лицензию, которая условно стоит 8 000 рублей. Поэтому в большинстве случаев пользователи остаются на Linux.
Я, в свою очередь, несмотря на то, что веду свои уроки с макбука, активно пропагандирую Линуксы разного рода: это и всякие попсовые Debian и Ubuntu, разного рода Arch Linux, даже Red Hat и прочее, прочее. Соответственно, если у вас есть какие-то опасения, то стоит помнить, что инструментарий на Linux такой же, как на Windows, то есть все среды разработки (всё, что не касается Microsoft Visual Studio) портированы и работают кроссплатформенно. Для новичка будет несложно сориентироваться, главное, не надо сразу начинать лезть в консоль или жить в терминале и пугать себя.

ведущий frontend-разработчик TalentTech
Выбор операционной системы, как правило, происходит на усмотрение самого программиста. Это дело вкуса — кому-то нравится macOS, другие считают Linux топовой системой. Одно важное условие: если ваш продукт будет иметь дело с iOS, то поле выбора ограничено — тут не обойтись без macOS. Иначе ничего не получится, если только разработка не идёт на удалённых серверах. Также эта система считается более user-friendly. То есть все мобильные разработчики, чьи продукты будут запущены в AppStore, не имеют другого выбора, кроме Mac.
Веб-разработка менее требовательна к ОС. Лишь два браузера – Explorer и Safari являются специфическими: первый будет работать только на Windows, а второй – на Mac. Когда разработчику нужно тестировать то, что он разработал, — ему понадобится соответствующий браузер.
Linux считается немного более сложным вариантом — она также бывает простой в использовании, но есть и «хардкор-версия», она скорее для тех, кто «пишет» драйверы и в целом больше работает с «железом». Преимущество этой системы в том, что можно собрать её целиком «под себя» и иметь над ней полный контроль. Это сложнее, требуются мозги и навыки, но использование в таком случае будет немного производительнее.
Разработка игр, как правило, происходит на кроссплатформенных системах. А вот приложения backend-разработчиков чаще выпускаются на Linux, соответственно будет удобно держать именно эту систему на своей машине разработки — это может быть и локальная машина, и нет. Часть разработчиков работает на удалённых серверах, а их локальная машина — это по факту просто интерфейс доступа.
Также если вы привыкли работать на macOS, то будет довольно трудно «переключиться» на Windows, и наоборот. То, чего на Mac можно добиться простыми действиями, на «винде» делается сложно.

разработчик в Kodix Auto
На такой вопрос сложно дать однозначный ответ. Скорее, это больше зависит от предпочтений разработчика. Но очевидно следующее:
- Если пишете программы для какой-то определённой платформы, то её и нужно выбирать.
- Если это веб-разработка, то вероятность того, что сервер будет крутиться на Unix — 80 %, а значит, стоит выбирать Linux или Mac.
Прежде всего следует разобраться, в чём отличие Unix от Windows, и выбрать то, что нравится и больше подходит. Писать хороший код можно везде. В этом вопросе нет серебряной пули, и это самое главное, что нужно понимать начинающему разработчику.
Итак, кому какой системой стоит пользоваться?
Всё зависит от двух вещей: что вам удобно и чем вы занимаетесь. Например, если вы разрабатываете iOS-приложения, то вам придётся пользоваться macOS; если вы пишете бэкенд и сервер крутится на Linux, то, скорее всего, на нём вам и удобней будет работать. Если не принимать во внимание завязанные на конкретной платформе стеки разработки, то всё зависит от ваших предпочтений, ведь очень много софта работает на всех основных системах. Нравится работать в Windows/Linux/BolgenOS? Работайте дальше, если это не ограничивает ваши возможности. К тому же при необходимости в простых случаях можно воспользоваться виртуальной машиной. А переучиваться работать на другой системе просто «потому что» — пустая трата сил и времени.
Напоминаем, что вы можете задать свой вопрос экспертам, а мы соберём на него ответы, если он окажется интересным. Вопросы, которые уже задавались, можно найти в списке выпусков рубрики. Если вы хотите присоединиться к числу экспертов и прислать ответ от вашей компании или лично от вас, то пишите на experts@tproger.ru, мы расскажем, как это сделать.
Хинт для программистов: если зарегистрируетесь на соревнования Huawei Cup, то бесплатно получите доступ к онлайн-школе для участников. Можно прокачаться по разным навыкам и выиграть призы в самом соревновании.
Перейти к регистрации
Источник
Где используется Java, пишут ли на ней под Windows?
>Где используется Java
в основном ентерпрайз
андроид — часто
прикладное — часто
роботы — 50/50 (пруфов нет)
игры — редко
сайты — редко
системное/ОС — редко
>пишут ли на ней под Windows?
хоть на салярисе
>Или лучше под винду C#?
под виндоуз — с решетка
>Легко ли перенести проект Java Windows в Linux или OS X
гмак — не знаю
но в линуксе и виндоуз — отличается расположение компонентов в ГУИ (явафх — не знаю)
поэтому проблемы будут только с графическим приложением
под винду — конечно, C# лучше.
а что, не видно?
создайте на C# простое приложение Winforms и посчитайте, сколько там элементов на панели.
а потом посчитайте для Java. не говоря уж о том, что для Java еще и поипаться придется, чтобы увидеть этот самый WYSIWYG и эту самую панель:
https://netbeans.org/features/java/swing_ru.html
)))
> Легко ли перенести проект Java Windows в Linux или OS X
Вы хотели спросить: «Легко ли портировать кривое УГ, написанное на Java под Windows, — под Linux или OS X?»))
В Linux — легко (если это не Android — тогда никак без переделки))). Java компилируется в свой платформонезависимый исполняемый формат — *.jar. При наличии верно настроенной JVM достаточно просто скинуть его на комп с виндой или линухом и дважды щелкнуть мышкой.
. Если конечно в этом приложении не используется платформозависимый функционал на основе WinAPI или DirectX (без которого писать под винду — убого).
На OS X — тоже должно работать, но вообще-то приложения для маков в App Store выкладывать положено вроде. jar не примут.
Источник
Java и Linux — особенности эксплуатации
Java — очень распространённая платформа, на ней пишут очень разные вещи, начиная от Big Data, заканчивая микросервисами, монолитами, enterprise и прочим. И, как правило, всё это развёртывают на Linux серверах. При этом, соответственно, те люди, которые пишут на Java, зачастую делают это совсем на других операционных системах. Там они:
- пишут код;
- отлаживают, тестируют;
- после этого упаковывают в jar;
- отправляют на Linux, и оно работает.
В том, что оно работает, нет особой магии. Но это приводит к тому, что такие разработчики немножечко «засахариваются» в своём мире кроссплатформенности и не очень хотят разбираться, а как оно на самом деле работает в реальной операционной системе.

С другой стороны, есть те, кто занимается администрированием серверов, на их сервера устанавливают JVM, отправляют jar и war-файлы, а с точки зрения мира Linux все это:
- чужеродное;
- проприетарное;
- собирается не из исходников;
- поставляется какими-то jar-архивами;
- «отъедает» всю память на сервере;
- вообще, ведёт себя не по-человечески.
Цель доклада Алексея Рагозина на Highload++, расшифровка которого идет далее, была в том, чтобы рассказать особенности Java для «линуксоидов» и, соответственно, Linux — Java-разработчикам.
Доклад не будет разбором полётов, потому что проблем много, они все интересные, и снаряд дважды в одну воронку не попадает. Поэтому затыкать уже известные «дыры» — пораженческая позиция. Вместо этого поговорим про:
- особенности реализации JVM;
- особенности реализации Linux:
- как они могут не стыковаться.

В Java есть виртуальная машина, и Linux, как и любая другая современная операционная система, по сути, — это тоже виртуальная машина. И в Java и в Linux есть управление памятью, потоки, API.
Слова похожи, но на самом деле под ними очень часто скрываются совершенно разные вещи. Собственно, по этим пунктам мы и пройдёмся, наибольшее внимание уделив памяти.
Память в Java
Сразу замечу, что я буду говорить только про реализацию JVM HotSpot, это Open JDK и Oracle JDK. То есть, наверняка в IBM J9 есть какие-то свои особенности, но я, к сожалению, про них не знаю. Если же мы говорим про HotSpot JVM, то картина мира выглядит следующим образом. Прежде всего в Java есть область, где живут java-объекты — так называемый Heap или, по-русски, куча, где работает сборщик мусора. Эта область памяти, как правило, занимает большую часть пространства процесса. Куча в свою очередь разбита на молодое и старое пространство (Young Gen / Old Gen). Не вдаваясь в дербри сайзинга JVM, важно то, что у JVM есть параметр «-Xmх», определяющий максимальный размер, до которого может вырасти пространство кучи.
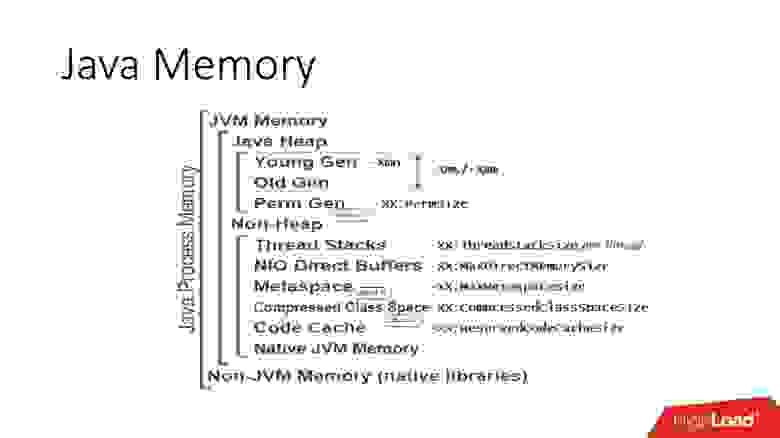
А дальше есть много вариантов:
- можно управлять отдельно размерами молодого пространства;
- можно сразу выставить максимальный размер кучи;
- либо дать возможность ему расти постепенно.
Деталей слишком много — важно, что есть лимит. И, в принципе, это общий подход ко всем областям, которые используют JVM. То есть практически все области, перечисленные на картинке выше, имеют определённый лимит. JVM сразу резервируетадресное пространство, исходя из лимита, а потом по мере необходимости запрашивает реальные ресурсы памяти в этом диапазоне. Это важно понимать.
Помимо кучи есть другие потребители памяти. Наиболее важными из них являются области памяти для стеков потоков. Потоки в Java — это обычные linux-потоки, у них есть стек, для которого резервируется определённый размер памяти. Чем больше у вас потоков, тем больше стеков выделено в памяти процесса. Поскольку число потоков в Java может измеряться сотнями и тысячими, иногда эта цифра может становиться достаточно существенной, особенно, если у вас какой-нибудь stateless microservice, в котором куча на 200 Мб, а ThreadPool на 50-100 потоков.
Кроме этого, есть ещё так называемые NIO Direct Buffers — это специальные объекты в Java, которые позволяют работать с памятью вне кучи. Они, как правило, используются для работы c I/O, потому что это память, к которой может напрямую обращаться как Си так и Java-код. Соответственно, эта область доступна через API, и у неё тоже есть максимальный лимит.
Остальное — это метаданные, какой-то сгенерированный код, память для них обычно не вырастает до больших величин, но она есть.
Помимо этих специальных областей не надо забывать, что JVM написана на C++, соответственно, там есть
- malloc и обычная аллокация памяти;
- библиотеки, которые подгружаются в JVM (статически или динамически слинкованные, которые тоже могут использовать память).
И эта память не классифицируется по нашей схеме, а просто является памятью, выделенной стандартными средствами C Runtime. C ней тоже иногда бывают проблемы, причём на достаточно ровном месте.
Например, вот у нас java код распространяется в jar виде. Jar — это zip-архив, для работы с ним используется библиотека zlib. Для того, чтобы что-то разархивировать zlib надо аллоцировать буфер, который будет использован для декомпрессии и, конечно, для него требуется память. Всё бы ничего, но сейчас есть мода на так называемые uber-jar, когда создается один здоровенный jar, и возникают нюансы.
При попытке старта из такого jar-файла открывается одновременно слишком много потоков zlib на распаковку. Причём с точки зрения Java всё хорошо: куча маленькая, все области маленькие, но потребление памяти процессом растёт. Это, конечно же «клинический» случай, но такие потребности JVM надо принимать ао внимание. Например, если вы установили -Xmx в 1 Гбайт, посадили Java в Docker-контейнер и поставили лимит памяти на контейнер тоже в 1 Гбайт, то JVM в него не поместится. Надо ещё чуть-чуть накинуть, а сколько точно — зависит от многих факторов, в том числе от количества потоков и от того, что именно ваш код делает.
Итак, это то, как JVM работает с памятью.
Теперь, так сказать, для другой части аудитории.
Память в Linux
В Linux нет никакого сборщика мусора. Его работа с точки зрения памяти совершенно другая. У него есть физическая память, которая разбита на страницы; есть процессы, у которых есть своё адресное пространство. Ему надо ресурсы этой памяти в виде страниц как-то разделить между процессами, чтобы они работали в своём виртуальном адресном пространстве и делали своё дело.

Размер страницы — обычно 4 килобайта. На самом деле это не так, в архитектуре x86 уже очень давно существует поддержка больших страниц. В Linux она появилась относительно недавно, и с ней пока немножко непонятная ситуация. Когда поддержка больших страниц (Transparent Huge Tables) появилась в Linux, очень многие люди наступили на грабли, связанные с performance degradation из-за некоторых нюансов обслуживания больших страниц в Linux. И вскоре интернет заполнился рекомендациями выключать их от греха подальше. После этого какие-то баги, связанные с работой больших страниц в Linux, починили, но осадок остался.
Но на текущий момент нет чёткого понимания, например, с какой версии поддержку больших страниц можно включить по умолчанию и не беспокоиться.
Поэтому будьте осторожны. Если вдруг на вашем Linux сервер внезапно на ровном месте вырастет потребление ресурсов ядром, то проблема может быть как раз в том, что у вас включены большие страницы, а сейчас они включены по умолчанию в большинстве дистрибутивов.
Итак, с точки зрения ядра у Linux есть множество страниц, которыми надо управлять. С точки зрения процесса — есть адресное пространство, в котором он резервирует диапазоны адресов. Зарезервированное адресное пространство — это ничто, не ресурс, в нём ничего нет. Если обратитесь по этому адресу, вы получите segfault, потому что там ничего нет.
Для того, чтобы в адресном пространстве появилась страница, нужен немножко другой syscall, и тогда процесс говорит операционной системе: «Мне, пожалуйста, в этих адресах нужен 1 Гбайт памяти». Но даже в этом случае память там появляется тоже не сразу и со своими хитростями.
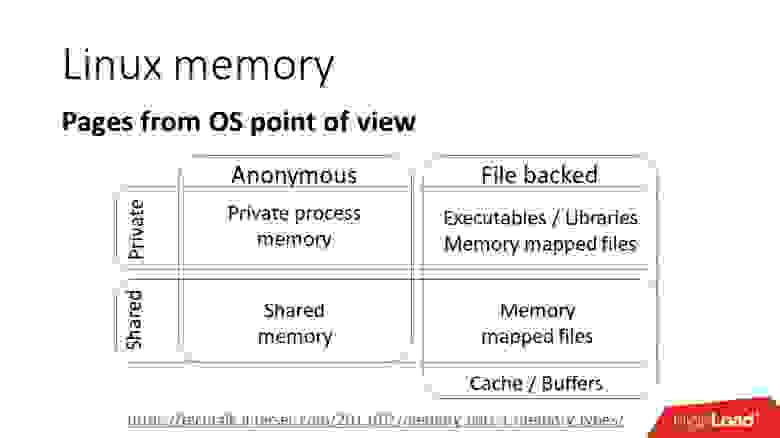
С точки зрения ядра классификация страниц выглядит следующим образом, есть страницы:
a) приватные, то есть это значит, что они принадлежат одному процессу и доступны в адресном пространстве только одного процесса;
b) анонимные — это обычная память, не связанная в файлами;
c) memory mapped files — отображение файлов в память;
d) используемые совместно, которые могут быть либо:
- Copy-On-Write, то есть, при ветвлении процесса, память становится доступна обоим процессам до тех пор, пока не будет записана и страницы не превратятся в приватные;
- через Shared файл, т.е., если несколько процессов отображают в память один и тот же файл, то страницы могут использоваться совместно.
В общем, с точки зрения ядра операционной системы всё достаточно просто.

Просто, да не совсем.
Когда мы хотим понять, что происходит на сервере с точки зрения памяти, мы идём в top и видим там какие-то цифры. В частности, там есть использованная память и свободная память. Есть разные мнения насчет того, сколько должно быть свободной памяти на сервере. Кто-то думает, что это 5%, но, на самом деле, и 0% от физической памяти — также норма, потому что то, что мы видим в качестве счётчика свободной памяти, — это в действительности не вся свободная память. Её на самом деле намного больше, просто она, как правило, скрыта в кэше страниц.
С точки зрения процесса top показывает три интересные колонки:
- virtual memory;
- resident memory;
- shared memory.
Последняя память в списке — просто те страницы, которые являются совместно используемыми. А вот с resident memory всё немножко хитрее. Остановимся более подробно на этих метриках.

Как я уже сказал, используемая и свободная память, достаточно бесполезные метрики. У сервера ещё остается память, которая никогда не была использована, потому что у операционной системы есть файловый кэш, и все современные ОС всю свободную память используют под него, так как из файлового кэша страницу памяти всегда можно очистить и использовать для более важных задач. Поэтому вся свободная память постепенно уходит в кэш и не возвращается обратно.
Метрика виртуальной памяти —это вообще не ресурс с точки зрения операционной системы. Вы запросто можете аллоцировать 100 терабайт адресного пространства, и всё. Сделали это и можете гордиться, что с адреса X по адрес Y пространство зарезервировано, но не более. Поэтому смотреть на неё как на ресурс и, например, ставить алерт, что виртуальный размер процесса превысил какой-то порог, довольно бессмысленно.
Вернёмся к Java, она все свои специальные области резервирует заранее, потому что код JVM ожидает, что эти области будут непрерывными с точки зрения адресного пространства. А значит адреса надо застолбить заранее. В связи с этим, запуская процесс с кучей на 256 Мбайт, вы можете внезапно увидеть, что виртуальный размер у него больше двух гигабайт. Не потому, что эти гигабайты нужны и что JVM способна их когда-либо утилизировать, а просто дефолт такой. От него ни холодно, ни жарко, по крайне мере, так думали те, кто писал JVM. Это, правда, не всегда соответствует мнению тех, кто потом занимается поддержкой серверов.
Residence size — наиболее близкая к реальности метрика — это количество страниц памяти, которые используются процессом, находящимся в памяти, не в свопе. Но она тоже немножечко своеобразная.

Возвращаюсь к кэшу. Как я уже сказал, кэш — это, в принципе, свободная память, но иногда бывают исключения. Потому что страницы в кэше бывают чистые и грязные (содержащие не сохранённые изменения). Если страница в кэше модифицирована, то прежде, чем она может быть использована для другой цели, её сначала надо записать на диск. А это уже совсем другая история. Пример, JVM пишет большой-большой Heap Dump. Делает она это неспешно, процесс происходи так:
- JVM быстренько пишет в память;
- операционная система выдаёт ей всю свободную память, которая у неё есть, под write behind cache, вся эта память оказывается «грязной»;
- идет медленная запись на диск.
Если размер этого дампа сопоставим с размером физической памяти сервера, может возникнуть ситуация, что для всех остальных процессов свободной памяти просто не будет.
То есть у нас, например, открывается новая ssh-сессия — чтобы запустить shell-процесс, надо выделить память. Процесс идёт за памятью, а ядро говорит ему: «Подожди, пожалуйста, сейчас я что-нибудь найду». Находит, но прежде, чем оно успевает отдать эту страницу SSHD, Java успевает «запачкать» ещё несколько страниц, потому что она тоже «висит» в Page Fault и, как только появляется свободная страница, она быстренько успевает выхватить эту память раньше, чем какие-то другие процессы. На практике такая ситуация приводила, например, к тому, что система мониторинга просто решала, что этот сервер «не живой» раз зайти на него через ssh не получается. Но это, конечно, крайний случай.
Еще процесс в Linux помимо virtual size и resident size имеет committedsize — это та память, которую процесс реально собирается использовать, то есть это адресное пространство, при обращении к которому вы не получите segfault, при обращении к которому ядро обязано предоставить вам физическую страницу памяти.
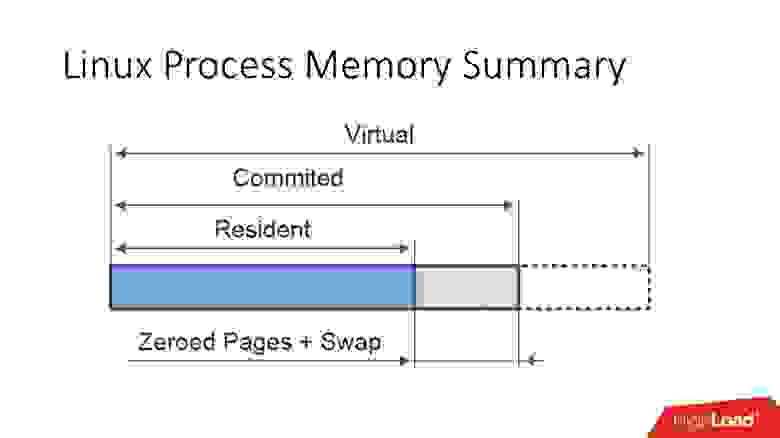
В идеальной ситуации committed и re sident должны были быть одним и тем же. Но, во-первых, страницы могут «свопиться».
Во-вторых, память в Linux выделяется всегда лениво.
- Вы говорите ему: «Дай мне, пожалуйста, 10 Гбайт». Он говорит: «Бери пожалуйста».
- Другой процесс: «Дай мне тоже 10 Гбайт» — «Бери пожалуйста».
- Третий процесс: «Дай мне тоже 10 Гбайт» — «Бери пожалуйста».
Потом оказывается, что физической памяти всего 16, а он всем раздал по 10. И начинается «кто первый взял, того и тапочки, а кому не повезло, за тем придёт OMKiller». Это особенности управления памятью Linux.
Важные факты о JVM
Первое, JVM очень не любит swapping. Если мне жалуются, что java-приложение почему-то тормозит, то первое, что я делаю, это смотрю, нет ли на сервере своппинга. Потому что есть два фактора, делающих Java очень нетолерантной к свопингу:
- Сборка мусора в Java постоянно бегает по страничкам, и если она «промахивается» мимо резидентных страниц, то вызывает перекладывание страниц с диска в память и обратно.
- Если в JVM хотя бы один поток «наступил» на страницу, которой в памяти нет, то это может привести к заморозке всех потоков этой JVM.
Есть механизм safe-point, который используется в JVM для всякой чёрной магии вроде перекомпиляции кода на лету, сборки мусора и так далее. Если один поток попал на Page Fault и ждёт, то JVM не может нормально войти в состояние safe-point, потому что не получает подтверждение от потока, который ждёт «приезда» страницы памяти. А все остальные потоки уже остановились и тоже ждут. Все стоят, ждут один этот несчастный поток. Поэтому, как только у вас начинается пейджинг, может начаться очень существенная деградация производительности.
Второе, Java никогда не отдаёт память операционной системе. Она будет использовать столько, сколько вы разрешили, даже если ей сейчас не очень нужны эти ресурсы, она их обратно не отдаст. Есть сборщики мусора, которые технически умеют это делать, но не надо рассчитывать, что они будут это делать.
У сборщика мусора такая логика работы: он либо использует больше
CPU, либо больше памяти. Если вы ему разрешили использовать 10 Гбайт, значит он разумно предполагает, что можно экономить ресурсы CPU, а эти 10 гигабайт с мусором подождут, а CPU пока пусть лучше делает делает что-то полезное, вместо чистки памяти, которая ещё не выходит за лимит.
В связи с этим важно правильно и обоснованно выставлять размер JVM. А если у вас несколько процессов в рамках одного контейнера, разумно распределять ресурсы памяти между ними.
Иначе пострадают все, что находится в этом контейнере.
Когда заканчивается память
Это еще одна из тех ситуаций, которыеочень по-разному воспринимаются «джавистами» и «линуксоидами».

В Java это происходит так: есть оператор new, который выделяет объект (на слайде это большой массив), если в куче недостаточно места, чтобы выделить память под этот большой массив, мы получаем Out of Memory error.

В Linux всё по-другому. Как мы помним, Linux легко может пообещать больше памяти, чем есть на самом деле, и вы начинаете с ней работать (выше условный код). И в отличии от JVM вы получите не ошибку, а аварийное завершение процесса выбранного OMKiller или смерть всего конейнера, если речь идёт о превышении квоты cgroups.
Когда память заканчивается в JVM
Теперь, разберемся чуть подробнее. В Java у нас есть так называемая область молодых объектов и область старых. Когда мы вызываем оператор new, объект выделяется в пространстве молодых объектов. Если же место в пространстве молодых объектов закончилось, происходит либо молодая, либо полная сборка мусора, если молодой сборки недостаточно. Суть в том, что, во-первых, если у нас не хватает памяти, происходит сборка мусора. И прежде, чем произойдёт Out of Memory error пройдет по крайне мере одна полная сборка, т.е. такая неспешная через всю нашу десятигигабайтную кучу. В некоторых случаях она будет ещё и в один поток, потому что full GC — особый случай.

При этом сборщик мусора наверняка чего-нибудь да наскребёт. Но если этого чего-нибудь меньше, чем 5% от размера кучи, всё равно будет выброшена ошибка, потому что это уже «не жизнь, а сплошное мучение». Но если этот Out of Memory error произойдёт в потоке, автор кода которого решил, что его поток должен работать, не взирая на любые ошибки, он может эту агонию продлевать путём перехвата исключений.
Вообще, после того, как стрельнула Out of Memory error, JVM уже нельзя считать живой. Внутренне состояние уже может быть разрушено, и есть такая опция ( -XX:OnOutOfMemoryError=»kill -9 %p» ), которая позволяет сразу убить этот процесс. Опять же есть нюансы. Если у вас размер JVM сопоставим с размером физической памяти бокса, то в момент вызова этой команды у вас произойдёт форк, который. приведёт к тому, что образ JVM будет продублирован. Соответственно, с точки зрения Linux память для JVM может немножечко превысить предел максимальной памяти, которую он готов выделить и эта команда не сработает. Такая проблема типична для Hadoop-серверов, например, когда большущий узел пытается запустить Python через shell. Естественно, этому дочернему процессу столько памяти не нужно, просто форк делает копию всего, а уже потом освобождает ненужную память. Только «потом» не всегда наступает.
Может быть другая ситуация, возможно, что куча ещё не максимального размера (меньше -Xmx), но сборка мусора не собрала достаточно памяти, и JVM решила, что надо увеличить кучу. Пошла к операционной системе, говорит: «дай мне больше памяти», а ОС говорит: «нет». Правда, как я уже сказал, Linux так не говорит, но другие системы говорят. Любая ошибка выделения памяти операционной системы с точки зрения JVM — это crash, без вопросов, никаких эксепшенов, никаких логов, только стандартный crash dump, и немедленное завершение процесса.
Есть ещё второй тип Out of Memory, который связан с так называемыми direct memory buffers. Это специальные объекты в Java, которые ссылаются на память вне кучи. Соответственно, они же её и аллоцируют, управляют жизненным циклом этой памяти, то есть определённая сборка мусора там всё равно есть. Чтобы такими буферами нельзя было занять бесконечно большое количество памяти, на них есть лимит, который JVM сама себе выставляет. Иногда возникает необходимость его подкорректировать, на что, естественно, есть магическая -XX опция, например, -XX:MaxDirectMemorySize=16g . В отличие от нормального Out of Memory этот Out of Memory — recoverable, потому что он возникает в определённом месте и его возможно отличить от другого типа ошибок.
Выделяем память в Java
Как я уже говорил, JVM на старте важно знать, сколько вы ей позволите использовать памяти, потому что исходя из этого строятся все эвристики сборщика мусора.
Сколько выделять памяти «в граммах» — это вопрос сложный, но вот основные тезисы:
- Вы должны понимать, сколько полезных объектов должны находиться в памяти постоянно (Liveset). Это правильнее всего измерять эмпирически, то есть надо:
- производить тесты;
- делать Heap Dump;
- смотреть, из чего состоит куча и как она будет расти при увеличении числа запросов или количества данных.
- размерамолодого поколения;
- размера live set;
- резерва.
Помимо кучи есть ещё direct buffers, какой-то резервJVM, который тоже надо определять эмпирически.
Таким образом footprint процесса в целом всегда будет больше, чем -Xmx, причем это не просто какой-то процент, а сочетание различных факторов вроде количества потоков.
Выделяем память в Linux
Двигаемся дальше, в Linux есть такая штука как ulimit — это такая странная конструкция, на мой взгляд джависта. Для процесса есть набор квот, который задает операционная система. Квоты есть разные, на количество открытых файлов, что логично, и ещё на какие-то другие вещи.

Именно для управления ресурсами ulimits работают не очень — для того, чтобы ограничивать ресурс контейнера, используется другой инструмент. В ulimits есть максимальный размер памяти, который на Linux не работает, но там же есть ещё максимальный размер виртуальной памяти. Это такая интересная штука, потому что, как я уже говорил, виртуальная память — не ресурс. В принципе, от того, что я зарезервирую 100 Тбайт адресного пространства, операционной системе ни холодно ни жарко. Но ОС скорее всего не даст мне этого сделать, пока я для своего процесса не становлю соответствующий ulimit.
По умолчанию этот лимит есть и может помешать запускаться вашей JVM, особенно опять же если размер JVM сопоставим с физической памятью, потому что значение по умолчанию часто считается как раз от размера физической памяти. Это вызывает некоторое недоумение, когда, допустим, у меня на сервере 500 Гбайт, я пытаюсь запустить JVM на 400 Гбайт, а она просто падает на старте с какими-то непонятными ошибками. Потом выясняется, что JVM на старте выделяет себе все эти адресные пространства, и в какой-то момент ОС ей говорит: «Нет, что-то много ты брешь адресного пространства, мне жалко». И, как я уже сказал, в этом случае JVM просто «умирает». Поэтому иногда этот параметрам нужно не забыть настроить.
Бывают другие клинические ситуации, когда люди почему-то решают, что если у них для JVM на сервере выделено 20 Гбайт, то надо ей размер виртуального адресного пространства тоже выставить в 20 Гбайт. Это проблема, потому что некоторые участки памяти, которые JVM резервирует, никогда не будут использованы, и их достаточно много. Таким образом вы намного сильнее ограничиваете ресурсы памяти этого процесса, чем можете подумать.
Поэтому обращаюсь к линуксоидам, пожалуйста, не делайте так, пожалейте своих джавистов.
Пару слов про Docker
То есть не про сам Docker, а про управление ресурсами в контейнере. В Docker управление ресурсами для контейнеров работает через механизм cgroups. Это механизм ядра, который позволяет для дерева процессов ограничить всевозможные ресурсы, например CPU и память. В том числе для памяти можно ограничить размер резидентной памяти, занимаемой всем контейнером, количество swap, количество страниц и др. Эти лимиты, в отличие от ulimits, нормальные ограничения на весь контейнер; если процесс форкает какие-то дочерние процессы, то они попадают в ту же группу ограничения ресурсов.
- Если вы запускаете Java в docker-контейнер, она смотрит, сколько на хосте физической памяти, и исходя из того, сколько физической памяти реально на хосте, а не в контейнере считает ограничения по умолчанию. И очень быстро умирает, потому что ей столько не дают. Поэтому -Xmx обязательно — без этого не взлетит.
- Всегда под контейнер надо давать немножко больше памяти, чем подJVM. Допустим, вы делаете контейнер на 2 Гбайта, запускаете JVM с параметром -Xmx2048m , оно как-то начинает работать, потому что память аллоцируется лениво. Но потихонечку все эти страницы так или иначе начинают использоваться, и сначала ваш контейнер начинает уходить в локальный своп, а потом просто умирает. Причём умирает он в лучших традициях — просто исчезает.
Если оно просто стартовало, это ещё ничего не значит, потому что ресурсы выделяются реально лениво.
Потоки в Java
Про потоки в Java важно знать, что они — нормальные потоки операционной системы. Когда-то в первых JVM были реализованы так называемые green threads — зелёные потоки, когда на самом деле стек java-потока как-то жил своей жизнью, и один поток операционной системы выполнял то один java-поток, то другой. Это всё развивалось до тех пор, пока в операционных системах не появилась нормальная многопоточность. После этого все забыли «зелёные» потоки как страшный сон, потому что с нативными потоками код работает лучше.
Это значит, что stack trace на пол тысячи фреймов реально лежит в том пространстве стека, который выделила операционная система. Если вы вызываете какой-то нативный код из Java это код будет использовать тоже самый стек, что и java-код. Это означает возможность использования диагностического инструментария, который есть в Linux, для работы так же и с java-потоками.
Как найти java—потоки

Если мы воспользуемся командой ps для JVM, мы увидим такую непонятную картину, потому что все потоки называются одинаково. Но на практике там в порядке очереди идут:
- потоки сборщика мусора;
- так называемый operational thread JVM;
- application потоки,
но это наугад.

На самом деле? если вы снимете thread dump с JVM с помощью командыjstack, то там будет шестнадцатеричное число «TID» — это идентификатор реального линуксового потока. То есть вы можете понять, какие java-потоки соответствуют каким потокам операционной системы и расшифровать ps.
Единственное, если вы уже видите, как напишете скрипт на perl, который будет это делать, не вызывайте jstack в цикле, лучше наоборот. Потому что каждый раз, когда вы вызываете jstack, вы вызываете глобальную паузу всех потоков JVM. В нормальных обстоятельствах это быстро, меньше, чем полмиллисекунды, но если делать такое 20 раз в секунду, то это уже может заметно отразится на производительности.
Можно, так же, вытащить эту информацию из самой JVM, в которой есть свой диагностический интерфейс. В частности, можете воспользоваться моим инструментом, который оттуда эту информацию вытягивает и просто для JVM печатает топ по потокам. Помимо CPU usage он ещё умеет печатать интенсивность аллокаций памяти кучи Java потоками.
Итого о потоках

Java-потоки — это обычные потоки операционной системы. В современных версиях JVM есть ключ PreserveFramePointer — это опция JIT-компилятора, позволяющая инструментам типа perf корректно парсить стек Java потоков.
Также есть на GitHub проект, который позволяет экспортировать «на лету» символы для скомпилированного java-кода, и с помощью того же perf получать вполне читабельный стек вызовов.
И небольшое напоминание, что у нас есть ещё потоки сборщика мусора.
Если у вас контейнер, на котором вы выделили два CPU, то надо количество параллельных потоков сборщика мусора тоже сделать два, потому что по умолчанию их будет больше, и они будут друг другу только мешать.
С другой стороны, в тот момент, когда работает сборщик мусора, все остальные потоки не делают ничего. Поэтому под сборщика мусора можно выделять 100% ресурсов контейнера, которые вы собираетесь выделить для Java.
IO и Networking
Сетевому стеку в Linux нужен тюнинг. Про это очень хорошо помнят те, кто занимается фронтенд-серверами, например, с Nginx, но то же самое неплохо бы делать на application и бэкенд-серверах — про это иногда забывают. И всё работает нормально до тех пор, пока у вас система становится геораспределенной и не начинается перегон данных через Атлантику. И упс, оказывается, надо было увеличить лимит на буферы.

Если вы используете UDP коммуникации, это тоже требует отдельной настройки на уровне операционной системы. Есть опции, которые код сам должен выставлять через API на сокетах, но они должны быть разрешены на уровне лимитов операционной системы. Иначе они просто не работают.
Второй интересный момент связан с особенностями работы с ресурсами в JVM.
У нас есть ограниченный ресурс — лимит на количество файлов, куда попадают сокеты и т.д., для процесса. Если у нас этот лимит превышен, то мы не можем:
- открывать соединение;
- открывать файлы;
- принимать соединения и т.д.
В Java на всех этих объектах есть методы для того, чтобы их явным образом закрывать и, соответственно, освобождать дескрипторы Linux.

Но если ленивый джавист этого не сделал, то сборщик мусора придёт и всё равно за него всё закроет. И всё бы хорошо, если бы этот сборщик мусора приходил по расписанию, но он приходит, когда посчитает нужным. Если у вас вся куча забита незакрытыми сокетами, то с точки зрения кучи это копейки, потому что там лежат только метаданные этого сокета и номер дескриптора из операционной системы. Поэтому если у вас есть вот такая комбинация внешних ресурсов, на которые ссылается java-код, то сборщик мусора иногда может вести себя не очень адекватно в этом плане.
Соединения и файлы всегда надо закрывать руками.
Даже если у вас произошла ошибка на сокете, всё равно, после того как вы словили exception, сокет надо закрыть. Потому что с точки зрения операционной системы то, что она вернула вам код ошибки, и вы в Java получили exception, ещё не значит, что сокет закрыт. С точки зрения операционной системы он будет продолжать считаться открытым, и операционная система честно будет готова вернуть код ошибки снова при проверке следующего обращения к нему. Соответственно, если мы что-то неправильно сконфигурировали, а сокеты должным образом не закрываются, через какое-то время лимит на файлы закончится, и приложению станет совсем плохо.
Есть пара ресурсов в JVM, которые нельзя освободить явным образом:
- memory map файлы;
- NIO direct buffers.
Поэтому с ними надо работать аккуратно, и желательно не выбрасывать, а переиспользовать. С точки зрения диагностики у нас есть heap dump, из которого всю эту информацию можно вытащить.
И, наконец, последние напутствия.

Выставляйте правильный размер JVM. Сама JVM не знает, сколько памяти ей нужно взять.
Учитесь пользоваться инструментами, в Linux есть инструменты, которые достаточно неплохо работают с Java, в JDK есть инструменты, которые позволяют получать много информации именно через командную строку. В Java есть JMX (Java Management Extensions) диагностический интерфейс, но для того, чтобы с ним работать, нужен другой java-процесс, что не всегда удобно.
В частности, не забывайте, про сочетание инструментов. Например, если у вас есть Linux core dump JVM, то вы можете с помощью инструментов JDK вытащить из него heap dump для Java и посмотреть его уже нормальным джавовским анализатором вместо того, чтобы делать этот heap dump непосредственно с живого процесса.
И уже совсем напоследок несколько ссылок на разные темы.
Java Memory Tuning and Diagnostic:
- https://blog.ragozin.info
- https://github.com/aragozin
Если у вас остались вопросы, то можно перескочить на соответствующую часть
доклада, может быть, кто-то это уже уточнил.
РИТ++ уже 28 и 29 мая, расписание здесь, а это прямая ссылка на покупку билетов.
До Highload++ Siberia времени чуть больше, она пройдет 25 и 26 июня. Но программа уже активно формируется, вы можете подписаться на рассылку и быть в курсе обновлений.
Источник



