- Информация об оперативной памяти в Linux. Свободная, занятая и тип памяти
- Свободная и занятая оперативная память
- Команда free
- Команда vmstat
- Команда top
- Команда htop
- Файл /proc/meminfo
- Тип памяти и частота
- Заключение
- Нехватка оперативной памяти в Linux на рабочем ПК: оптимизация и действия при зависании
- zram и приоритеты свопов
- Быстро вырубить программу, перегружающую ОЗУ. Запас ОЗУ для SSH
- Как Linux работает с памятью. Семинар в Яндексе
- Термины
- Страницы памяти
- Memory Zones и NUMA
- Page Cache
- Память процесса
- Выделение памяти
- Работа с файлами и с памятью
- Readahead
- Источники пополнения Free List
Информация об оперативной памяти в Linux. Свободная, занятая и тип памяти

В этой статье мы рассмотрим, как получить информацию об оперативной памяти (RAM) в Linux.
Мы воспользуемся утилитами командной строки доступными для большинства Linux дистрибутивов.
Свободная и занятая оперативная память
Для получения информации о количестве свободной и занятой оперативной памяти в Linux можно использовать различные утилиты и команды. Рассмотрим несколько распространенных способов.
Команда free
Команда free очень простая, она выводит информацию о общем количестве оперативной памяти, о количестве занятой и свободной памяти, а также об использовании файла подкачки.
По умолчанию объем памяти выводится в килобайтах. Используя опции, можно выводить объем памяти в других форматах. Некоторые опции:
- -m — в мегабайтах
- -g — в гигабайтах
- -h — автоматически определить формат
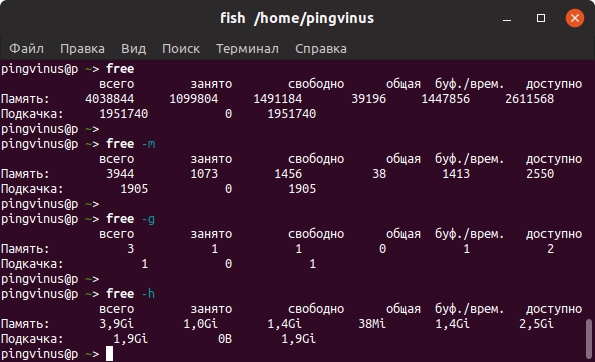
Команда vmstat
Команда vmstat выводит различную статистику по использованию памяти. Используя ключ -s можно вывести подробную статистику в табличном виде.
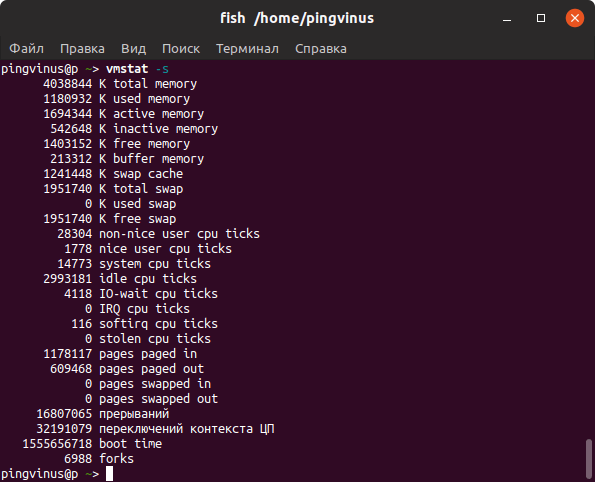
Команда top
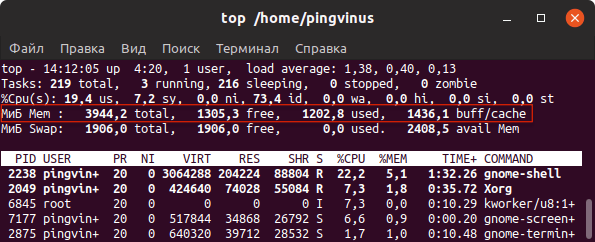
top — это утилита командной строки, которая используется для мониторинга процессов и используемых ресурсов компьютера.
Запуск утилиты top :
В заголовке выводится информация об использованной оперативной памяти.
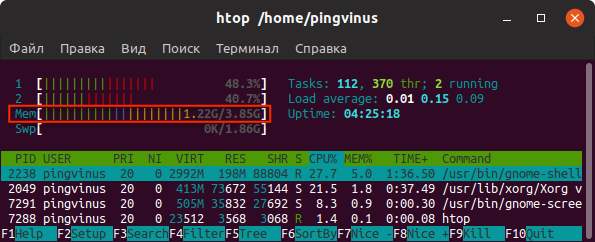
Команда htop
Утилита htop, также как и top, используется для мониторинга ресурсов и процессов.
Для установки утилиты htop в Ubuntu Linux (Linux Mint и других Ubuntu/Debian-дистрибутивах) выполните команду:
Запуск утилиты htop :
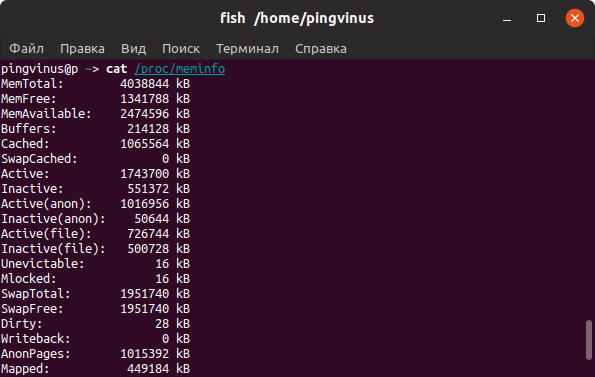
Файл /proc/meminfo
Описанные выше команды, в качестве источника информации используют системные файлы из файлов, хранящихся в виртуальной файловой системе /proc . В файле /proc/meminfo содержится информация об использовании памяти. Выведем содержимое файла /proc/meminfo :
Тип памяти и частота
Рассмотрим, как получить информацию об установленных в компьютер модулях оперативной памяти. Воспользуемся командной dmidecode
Используем следующую команду:
В выводе команды будет информация о слотах оперативной памяти. Для каждого слота отображается установленный модуль оперативной памяти, его тип (поле Type ), размер (поле Size ), скорость/частота (поле Speed ) и другая информация.
В зависимости от системы и оборудования не всегда удается получить все данные, поэтому некоторые поля могут быть пустыми или иметь надписи Not provided/Unknown.
Заключение
Мы рассмотрели различные способы для просмотра информации о доступной и занятой оперативной памяти, а также показали, как вывести информацию об установленных модулях оперативной памяти.
Для отслеживания использования ресурсов компьютера существует множество графических программ. Найти их можно в нашем каталоге программ для Linux в разделе Система/Мониторинг.
Источник
Нехватка оперативной памяти в Linux на рабочем ПК: оптимизация и действия при зависании
На любой операционной системе часто не хватает оперативной памяти. Рассмотрим, как и сэкономить на увеличении аппаратных ресурсов машины с Linux, и продолжить более-менее комфортно пользоваться компьютером с Linux в условиях нехватки памяти.
Типична такая ситуация: есть своп (swap, раздел подкачки), который начинает использоваться при нехватке оперативной памяти, и размещен он на HDD, то есть жестком диске с низкой скоростью чтения информации. В таких ситуациях операционная система начинает тормозить, подвисает курсор мыши, сложно переключиться в соседнюю tty и т.д. Почему? Потому что планировщик ядра Linux не может выполнить запрос на какое-то действие в запущенной программе, пока не получит доступ к ее оперативной памяти, выполнить следующее действие тоже не может, образовывается очередь из запросов на чтение с диска, и система «подвисает» именно потому, что обработка очереди происходит гораздо медленнее, чем этого хочет пользователь.
Если в такой момент запустить htop или uptime , то показатель Load Average (LA) будет очень высоким, несмотря на низкую загруженность ядер процессора. Сочетание высокого Load Average и низкой загрузки процессора говорят о забитой очереди процессора.
Часто в интернете советуют изменить параметр ядра Linux vm.swappiness . Узнать его текущее значение на вашей системе можно так:
Ответ будет 60 почти наверняка. Это значит, что ядро Linux начинает свопить редко используемые страницы оперативной памяти, когда использование свободной оперативной памяти достигает 100%-60%=40%. Часто встречаются рекомендации поставить, например, vm.swappiness=10, чтобы своп не начинал использоваться, пока загрузка ОЗу не достигнет 90%. На самом деле не нужно трогать vm.swappiness, вы не умнее разработчиков ядра Linux, которые не просто так поставили 60 по умолчанию. Почему?
Представьте, что у вас всего 4 ГБ оперативной памяти, из них прямо сейчас занято 3 ГБ, vm.swappiness=10, своп на жестком диске (HDD) занят на 0%, и вы открываете тяжелый сайт в браузере, для чего требуется больше, чем имеющийся свободный 1 ГБ, например, 2 ГБ. Операционная система начинает в экстренном порядке отправлять в своп как минимум 0.5 ГБ (а по факту больше), чтобы можно было выделить браузеру необходимое количество оперативной памяти. Эта процедура становится самой приоритетной задачей, и придется пожертвовать даже движениями курсора мыши, чтобы ее выполнить как можно быстрее. Вы ждете. Проходит 5 минут, и система развисает, потому что окончила процедуру 100% загрузки очереди доступа к медленному жесткому диску, на котором размещена оперативная память (своп). При дефолтном vm.swappiness=60 редко используемые страницы памяти сбрасываются в своп заблаговременно, и резкого зависания на 5-10 минут не происходит.
UPD. В комментарии подсказывают, что это не точное описание работы vm.swappiness.
zram и приоритеты свопов
Рекомендую включить zram — прозрачное сжатие содержимого оперативной памяти. В Ubuntu это автоматизировано, достаточно установить пакет:
sudo apt install zram-config
Здесь и далее для дистрибутивов Rosa, Fedora все то же самое, но вместо zram-config —
Сервис systemd zram-config на Ubuntu будет автоматически добавлен в автозагрузку при установке пакета и запущен при перезагрузке системы. Для запуска вручную:
sudo systemctl start zram-config
sudo systemctl stop zram-config
Удаления из автозапуска:
sudo systemctl disable zram-config
Добавление в автозапуск:
sudo systemctl enable zram-config
При запуске zram-config берет число, равное 50% всего объема оперативной памяти, далее делает по одному виртуальному устройству /dev/zramN, где N начинается с 0, для каждого ядра процессора, а объем каждого /dev/zramN равен 50% всей оперативной памяти, деленному на количество ядер процессора. Так делалается для распараллеливания сжатия содержимого оперативной памяти по ядрам процессора; насколько я знаю, на современных ядрах Linux достаточно одного устройства /dev/zramN, а распараллелится оно само, но меня полностью устраивает искоробочная работа zram-config, и предпочитаю не лезть в нее руками.
Команда swapon -s выведет список всех задействованных свопов с указанием их приоритета. Первым используется тот своп, у которого приоритет выше. Если у вас уже есть дисковый своп и включен zram, то в случае с описанным выше пакетом-автокофигуратором приоритеты из коробки будут правильными. Например, у дискового свопа будет -1, а все /dev/zramN — 5. Таким образом, сначала используется zram, и только потом — диск.
Кстати, zram часто применяется на смартфонах, какую-либо на глаз заметную нагрузку на процессор при дефолтном методе сжатия lz4 он не создает.
Также приоритет свопа можно указать в /etc/fstab . Покажу на примере, как это сделано на моем рабочем компьютере с 6 ГБ ОЗУ.
Опцией монтирования pri=X заданы приоритеты свопов. Если еще включить zram, то картинка будет такой:
В первую очередь будет свопиться в zram, то есть сжиматься внутри оперативной памяти без использования внешнего устройства для свопа, во вторую — использовать небольшой своп на SSD. Почти никогда не будет использоваться 6 ГБ свопа на HDD, однако они понадобятся, если я захочу отправить компьютер в спящий режим в условиях большой загрузки оперативной памяти. (На самом деле у меня отключен zram).
На офисных ПК с 4 ГБ ОЗУ (Xubuntu 16.04, 17.10) всегда ставлю пакет zram-config . Chromium, по наблюдениям, на глаз, очень хорошо сжимается в оперативной памяти, в результате чего zram позволяет сделать работу намного более комфортной без модернизации железа.
Быстро вырубить программу, перегружающую ОЗУ. Запас ОЗУ для SSH
Бывает такое, что даже при vm.swappiness=60 какому-то черту, как правило, браузеру, требуется очень много оперативной памяти, и система подвисает. Решается очень просто: сочетание клавиш Alt+SysRq(PrintScreen)+F заставляет oom_killer принудительно включиться и вырубить процесс, который на момент вызова занимает больше всего памяти. Строго 1 процесс на 1 вызов, и строго обязательно что-то будет убито. Если много раз подряд нажмете, то, скорее всего, перезапустится графическая сессия. Событие убиения процесса отражается в dmesg красным цветом.
Однако эта штука, называющаяся Magic SysRq, из коробки отключена в большинстве дистрибутивов, потому что непривилегированный пользователь может убить абсолютно любой процесс. За это отчечает параметр ядра kernel.sysrq , узнать его текущее значение можно так:
Для работы Alt+SysRq+F нужно kernel.sysrq=1. Для этого отредатируем параметры ядра, расположенные в файлах /etc/sysctl.conf (обычно симлинк на /etc/sysctl.d/99-sysctl.conf) и /etc/sysctl.d/*.conf. Лучше всего создать отдельный файл:
sudo nano /etc/sysctl.d/99-dumalogiya.conf
Нажмем Ctrl+O, Enter для сохранения.
В случае с браузером Chromium Alt+SysRq(PrintScreen)+F будет вырубать по одной вкладке, не закрывая сам браузер, что очень удобно.

Сочетания клавиш Magic SysRq перехватываются напрямую ядром Linux, поэтому работают даже когда из-за очереди процессора подвисает X-сервер.
Источник
Как Linux работает с памятью. Семинар в Яндексе
Привет. Меня зовут Вячеслав Бирюков. В Яндексе я руковожу группой эксплуатации поиска. Недавно для студентов Курсов информационных технологий Яндекса я прочитал лекцию о работе с памятью в Linux. Почему именно память? Главный ответ: работа с памятью мне нравится. Кроме того, информации о ней довольно мало, а та, что есть, как правило, нерелевантна, потому что эта часть ядра Linux меняется достаточно быстро и не успевает попасть в книги. Рассказывать я буду про архитектуру x86_64 и про Linux-ядро версии 2.6.32. Местами будет версия ядра 3.х.
Эта лекция будет полезна не только системным администраторам, но и разработчикам программ высоконагруженных систем. Она поможет им понять, как именно происходит взаимодействие с ядром операционной системы.
Термины
Резидентная память – это тот объем памяти, который сейчас находится в оперативной памяти сервера, компьютера, ноутбука.
Анонимная память – это память без учёта файлового кеша и памяти, которая имеет файловый бэкенд на диске.
Page fault – ловушка обращения памяти. Штатный механизм при работе с виртуальной памятью.
Страницы памяти
Работа с памятью организована через страницы. Объём памяти, как правило, большой, присутствует адресация, но операционной системе и железу не очень удобно работать с каждым из адресов отдельно, поэтому вся память и разбита на страницы. Размер страницы – 4 KБ. Также существуют страницы другого размера: так называемые Huge Pages размером 2 MБ и страницы размером 1 ГБ (о них мы говорить сегодня не будем).
Виртуальная память – это адресное пространство процесса. Процесс работает не с физической памятью напрямую, а с виртуальной. Такая абстракция позволяет проще писать код приложений, не думать о том, что можно случайно обратиться не на те адреса памяти или адреса другого процесса. Это упрощает разработку приложений, а также позволяет превышать размер основной оперативной памяти за счёт описанных ниже механизмов. Виртуальная память состоит из основной памяти и swap-устройства. То есть объём виртуальной памяти может быть в принципе неограниченного размера.
Для управления виртуальной памятью в системе присутствует параметр overcommit . Он следит за тем, чтобы мы не переиспользовали размер памяти. Управляется через sysctl и может быть в следующих трех значениях:
- 0 – значение по умолчанию. В этом случае используется эвристика, которая следит за тем, чтобы мы не смогли выделить виртуальной памяти в процессе намного больше, чем есть в системе;
- 1 – говорит о том, что мы никак не следим за объёмом выделяемой памяти. Это полезно, например, в программах для вычислений, которые выделяют большие массивы данных и работают с ними особым способом;
- 2 – параметр, который позволяет строго ограничивать объем виртуальной памяти процесса.
Посмотреть, сколько у нас закоммичено памяти, сколько используется и сколько мы можем ещё выделить, можно в строках CommitLimit и Commited_AS из файла /proc/meminfo .
Memory Zones и NUMA
В современных системах вся виртуальная память делится на NUMA-ноды. Когда-то у нас были компьютеры с одним процессором и одним банком памяти (memory bank). Называлась такая архитектура UMA (SMP). Всё было предельно понятно: одна системная шина для общения всех компонентов. В последствии это стало неудобно, начало ограничивать развитие архитектуры, и, как следствие, была придумана NUMA.
Как видно из слайда, у нас есть два процессора, которые общаются между собой по какому-то каналу, и у каждого из них есть свои шины, через которые они общаются со своими банками памяти. Если мы посмотрим на картинку, то задержка от CPU 1 к RAM 1 в NUMA-ноде будет в два раза меньше, чем от CPU 1 на RAM 2. Получить эти данные и прочую информацию мы можем, используя команду numactl hardware .
Мы видим, что сервер имеет две ноды и информацию по ним (сколько в каждой ноде свободной физической памяти). Память выделяется на каждой ноде отдельно. Поэтому можно потребить всю свободную память на одной ноде, а другую — недогрузить. Чтобы такого не было (это свойственно базам данных), можно запускать процесс с командой numactl interleave=all. Это позволяет распределять выделение памяти между двумя нодам равномерно. В противном случае ядро выбирает ноду, на которой был запланирован запуск этого процесса (CPU scheduling) и всегда пытается выделить память на ней.
Также память в системе поделена на Memory Zones. Каждая NUMA-нода делится на какое-то количество таких зон. Они служат для поддержки специального железа, которое не может общаться по всему диапазону адресов. К примеру, ZONE_DMA – это 16 MБ первых адресов, ZONE_DMA32 – это 4 ГБ. Смотрим на зоны памяти и их состояние через файл /proc/zoneinfo .
Page Cache
Через Page Cache в Linux по умолчанию идут все операции чтения и записи. Он динамического размера, то есть именно он съест всю вашу память, если она свободна. Как гласит старая шутка, если вам нужна свободная память в сервере, просто вытащите ее из сервера. Page Cache делит все файлы, которые мы читаем, на страницы (страница, как мы сказали, – 4 KБ). Посмотреть, есть ли в Page Cache какие-то страницы какого-то конкретного файла, можно с помощью системного вызова mincore() . Или с помощью утилиты vmtouch, которая написана с использованием этого системного вызова.
Как же происходит запись? Любая запись происходит на диск не сразу, а в Page Cache, и делается это практически моментально. Тут можно увидеть интересную «аномалию»: запись на диск идет намного быстрее, чем чтение. Дело в том, что при чтении (если данной странички файла в Page Cache нет) мы пойдем в диск и будем синхронно ждать ответа, а запись в свою очередь пройдет моментально в кеш.
Минусом такого поведения является то, что на самом деле данные никуда не записались, — они просто находятся в памяти, и когда-то их нужно будет сбросить на диск. У каждой странички при записи проставляется флажок (он называется dirty). Такая «грязная» страничка появляется в Page Cache. Если накапливается много таких страничек, система понимает, что пора их сбросить на диск, а то можно их потерять (если внезапно пропадет питание, наши данные тоже пропадут).
Память процесса
Процесс состоит из следующих сегментов. У нас есть stack, который растет вниз; у него есть лимит дальше котрого он расти не может.
Затем идет регион mmap: там находятся все отображенные на память файлы процесса, которые мы открыли или создали через системный вызов mmap() . Далее идет большое пространство невыделенной виртуальной памяти, которую мы можем использовать. Снизу вверх растет heap – это область анонимной памяти. Внизу идут области бинарника, который мы запускаем.
Если мы говорим о памяти внутри процесса, то работать со страницами тоже неудобно: как правило, выделение памяти внутри процесса происходит блоками. Очень редко требуется выделить одну-две странички, обычно нужно выделить сразу какой-то промежуток страниц. Поэтому в Linux существует такое понятие, как область памяти (virtual memory area, VMA), которая описывает какое-то пространство адресов внутри виртуального адресного пространства этого процесса. На каждую такую VMA есть свои права (чтения, записи, исполнения) и области видимости: она может быть приватная или общая (которая «шарится (share)» с другими процессами в системе).
Выделение памяти
Выделение памяти можно поделить на четыре случая: есть выделение приватной памяти и памяти, которой можем с кем-то поделиться (share); двумя другими категорями являются разделение на анонимную память и ту, у которая связана с файлом на диске. Самые частые функции выделения памяти – это malloc и free. Если мы говорим о glibc malloc() , то он выделяет анонимную память таким интересным способом: использует heap для аллокации маленьких объемов (менее 128 KБ) и mmap() для больших объемов. Такое выделение необходимо для того, чтобы память расходовалась оптимальнее и её можно было запросто отдавать в систему. Если в heap не хватает памяти для выделения, вызывается системный вызов brk() , который расширяет границы heap. Системный вызов mmap() занимается тем, что отображает содержимое файла на адресное пространство. munmap() в свою очередь освобождает отображение. У mmap() есть флаги, которые регулируют видимость изменений и уровень доступа.
На самом деле, Linux не выделяет всю запрошенную память сразу. Процесс выделения памяти — Demand Paging — начинается с того, что мы запрашиваем у ядра системы страничку памяти, и она попадает в область Only Allocated. Ядро отвечает процессу: вот твоя страница памяти, ты можешь её использовать. И больше ничего происходит. Никакой физической аллокации не происходит. А произойдет она только в том случае, если мы попробуем в эту страницу произвести запись. В этот момент пойдёт обращение в Page Table – эта структура транслирует виртуальные адреса процесса в физические адреса оперативной памяти. При этом будут задействованы также два блока: MMU и TLB, как видно из рисунка. Они позволяют ускорять выделение и служат для трансляции виртуальных адресов в физические.
После того, как мы понимаем, что этой странице в Page Table ничего не соответствует, то есть нет связи с физической памятью, мы получаем Page Fault – в данном случае минорный (minor), так как отсутствует обращение в диск. После этого процесса система может производить запись в выделенную страницу памяти. Для процесса все это происходит прозрачно. А мы можем наблюдать увеличение счетчика минорных Page Fault для процесса на одну единицу. Также бывает мажорный Page Fault – в случае, когда происходит обращение в диск за содержимым страницы (в случае mmpa() ).
Один из трюков в работе с памятью в Linux – Copy On Write – позволяет делать очень быстрые порождения процессов (fork).
Работа с файлами и с памятью
Подсистема памяти и подсистема работы с файлами тесно связаны. Так как работа с диском напрямую очень медленна, ядро использует в качестве прослойки оперативную память.
malloc() использует больше памяти: происходит копирование в user space. Также потребляется больше CPU, и мы получаем больше переключений контекста, чем если бы мы работали с файлом через mmap() .
Какие выводы можно сделать? Мы можем работать с файлами, как с памятью. У нас есть lazy lоading, то есть мы можем замапить очень-очень большой файл, и он будет подгружаться в память процесса через Page Cache только по мере надобности. Всё также происходит быстрее, потому что мы используем меньше системных вызовов и, в конце концов, это экономит память. Ещё стоит отметить, что при завершении программы память никуда не девается и остается в Page Cache.
В начале было сказано, что вся запись и чтение идут через Page Cache, но иногда по какой-то причине, есть необходимость в отходе от такого поведения. Некоторые программные продукты работают таким способом, например MySQL с InnoDB.
Подсказать ядру, что в ближайшее время мы не будем работать с этим файлом, и заставить выгрузить страницы файла из Page Cache можно с помощью специальных системных вызовов:
- posix_fadvide();
- madvise();
- mincore().
Утилита vmtouch также может вынести страницы файла из Page Cache – ключ “e”.
Readahead
Поговорим про Readahead. Если читать файлы с диска через Page Cache каждый раз постранично, то у нас будет достаточно много Page Fault и мы будем часто ходить на диск за данными. Поэтому мы можем управлять размером Readahead: если мы прочитали первую и вторую страничку, то ядро понимает, что, скорее всего, нам нужна и третья. И так как ходить на диск дорого, мы можем прочитать немного больше заранее, загрузив файл наперёд в Page Cache и отвечать в будущем из него. Таким образом происходит замена будущих тяжёлых мажорных (major) Page Faults на минорные (minor) page fault.
Итак мы выдали всем память, все процессы довольны, и внезапно память у нас закончилась. Теперь нам нужно ее как-то освобождать. Процесс поиска и выделения свободной памяти в ядре называется Page Reclaiming. В памяти могут находится страницы памяти, которые нельзя забирать, – залокированные страницы (locked). Помимо них есть ещё четыре категории страниц. Cтраницы ядра, которые выгружать не стоит, потому что это затормозит всю работу системы; cтраницы Swappable – это такие страницы анонимной памяти, которые никуда, кроме как в swap устройство выгрузить нельзя; Syncable Pages – те, которые могут быть синхронизированы с диском, а в случае открытого файла только на чтение – такие страницы можно с лёгкостью выбросить из памяти; и Discardable Pages – это те страницы, от которых можно просто отказаться.
Источники пополнения Free List
Если говорить упрощённо, то у ядра есть один большой Free List (на самом деле, это не так), в котором хранятся страницы памяти, которые можно выдавать процессам. Ядро пытается поддерживать размер этого списка в каком-то не нулевом состоянии, чтобы быстро выдавать память процессам. Пополняется этот список за счёт четырех источников: Page Cache, Swap, Kernel Memory и OOM Killer.
Мы должны различать участки памяти на горячую и холодную и как-то пополнять за счет них наши Free Lists. Page Cache устроен по принципу LRU/2 очереди. Есть активный список страниц (Active List) и инактивный список (Inactive List) страничек, между которыми есть какая-то связь. В Free List прилетают запросы на выделение памяти (allocation). Система отдаёт страницы из головы этого списка, а в хвост списка попадают страницы из хвоста инактивного (inactive) списка. Новые страницы, когда мы читаем файл через Page Cache, всегда попадают в голову и проходят до конца инактивного списка, если в эти страницы не было еще хотя бы одного обращения. Если такое обращение было в любом месте инактивного списка, то страницы попадают сразу в голову активного списка и начинают двигаться в сторону его хвоста. Если же в этот момент опять к ним происходит обращение, то страницы вновь пробиваются в верх списка. Таким образом система пытается сбалансировать списки: самые горячие данные всегда находятся в Page Cache в активном списке, и Free List никогда не пополняется за их счет.
Также тут стоит отметить интересное поведение: страницы, за счет которых пополняется Free List, которые в свою очередь прилетают из инактивного списка, но до сих пор не отданные для аллокации, могут быть возвращены обратно в инактивный списка (в данном случае в голову инактивного списка).
Итого у нас получается пять таких листов: Active Anon, Inactive Anon, Active File, Inactive File, Unevictable. Такие списки создаются для каждой NUMA ноды и для каждой Memory Zone.
Источник



