- Linux для человеков!
- Обзоры
- Фотогалереи
- Помощь при использовании сайта
- Новое из блога
- Перекодировка текстовых файлов из cp1251 в UTF-8 с помощью iconv
- Средства Linux для перекодирования файлов
- Проблема новой строки
- Откуда пошли названия символов CR и LF
- Проблема кодировки
- Заключение
- Конвертирование файлов в кодировку UTF-8 в Linux
- Конвертирование файлов из UTF-8 в ASCII
- Конвертирование нескольких файлов в кодировку UTF-8
- Перекодировка из cp1251 в UTF8
Linux для человеков!
Обзоры
Фотогалереи
Помощь при использовании сайта
Новое из блога
Перекодировка текстовых файлов из cp1251 в UTF-8 с помощью iconv
В Windows по умочанию используется кодировка символов CP1251, чем иногда доставляет проблем пользователям других, нормальных ОС, которые давно перешли на юникод и забыли о проблемах с кодировками как страшный сон. Но пользователи Windows как американцы, не знают, что существуют другие страны ОС и сохраняют субтитры в CP1251 что делает их нечитабельными для других.
Для решения этой проблемы есть iconv который как раз и служит для перекодировки текстовых файлов из одной кодировки в другую. Во всех почти дистрибутивах данный пакет устанавливается по умолчанию, но если его вдруг не оказалось — установите его с помощью вашего пакетного менеджера.
Для перекодировки достаточно ввести всего одну команду в терминале, а именно:
Поясню: ключ «f» задает исходную кодировку в которой файл находится сейчас, ключ «t» указывает целевую кодировку, ключ «o» задает путь для сохранения перекодированного файла.
Вот, все очень просто. Так же вы можете таким образом кодировать любые текстовые файлы. Часто и тексты песен попадаются с такой неприятной особенностью.
Недавно узнал более простой и понятный способ перекодировки текстовых файлов — с помощью enconv.
Не буду приводить полного синтаксиса и описания всех ключей. Для перекодировки достаточно одного, например:
С помощью данной команды мы перегнали текст в UTF-8. Да, именно, просто перегнали без необходимости указания исходной кодировки. Все просто, указываем лишь ту которую хотим получить. Желательно сделать резервную копию файла, так как насколько я понял enconv’у нельзя задать выходной файл и изменяться кодировка будет прямо в исходном файле.
Если у кого то есть еще какие то методы перекодировки текстовых файлов — прошу в каменты.
Источник
Средства Linux для перекодирования файлов
Оригинал: Linux tools to convert file formats
Автор: Federico Kereki
Дата: 22 июля 2008
Перевод: Александр Тарасов aka oioki
Дата перевода: 14 августа 2008
Было бы намного проще, если бы мы жили в мире, в котором существует один лишь Linux, и если бы приложениям не требовались данные из других источников. Однако все еще существует необходимость в получении данных из систем Windows, MS DOS и Macintosh. Импортирование таких документов требует соответствующего перекодирования; иначе было бы невозможно обмениваться данными, или содержимое файлов интерпретировалось бы некорректно. Вообще самый простой способ передавать данные между системами — это с помощью обычных текстовых файлов или в таких форматах как CSV-файлы (значения, разделенные пробелами). Однако преобразование файлов из форматов Windows и Mac OS приводит к различиям в символах новой строки и кодировке символов . В этой статье рассказано, отчего возникают такие проблемы и как их устранить.
Проблема новой строки
Каждая операционная система использует определенный символ (или последовательность символов) для обозначения конца текстовой строки. Нельзя использовать обычные символы для указания новой строки, ведь они могут идти лишь в обычном тексте. Поэтому используется специальный непечатный символ — и у каждой ОС он свой:
- Linux и Mac OS X унаследовали Unix-стиль и используют LF (управляющий ASCII -символ line feed) в качестве символа конца строки.
- Старые Macintosh-системы использовали CR (carriage return, другой управляющий ASCII-символ).
- В Windows используется два символа — CR и затем LF.
Чтобы узнать, какой символ используется в текстовом файле для новой строки, запустите hexdump . С его помощью можно исследовать содержимое файла побайтово. Я подготовил два трехстроковых файла — один на Linux-системе, другой на Windows — и вывел их содержимое побайтово. Файл выводится порциями по 16 байт, отображаются собственно символы и их представления в восьмеричной системе счисления. Обратите внимание, что Linux-файл содержит управляющий символ \n, а Windows — \r и затем \n. На старых Macintosh-системах вы бы увидели одиночный символ \r.
Для преобразования файлов из Windows в Linux можно воспользоваться командой с говорящим названием dos2unix . Самый простой способ преобразовать файл test.windows в формат Linux — запустить
Однако можно воспользоваться и потоковым вариантом:
Все ключи команды можно узнать, посмотрев справку dos2unix -h или man dos2unix .
Для преобразования текстового файла со старой Macintosh-системы необходимо заменить символы CR на LF, это можно сделать с помощью программы tr (translate): который просто меняет каждый символ CR (восьмеричное 015) на LF (восьмеричное 012). tr также может произвести удаление символа CR для преобразования из Windows-системы, нужно воспользоваться ключом -d. Действие, аналогичное действию ранее упомянутой dos2unix, достигается следующим образом:
Проблема кодировки
Помимо обычных 26 символов в английском языке (да и во многих других) используются и специальные типографические символы. Смотрели ли вы фильм Æon Flux и посылали ли curriculum vitæ? В немецком тексте рассыпано множество гласных с умляутами и буквы наподобие ß. В испанском есть разнообразные ň и острые акценты, во французском языке — грависы и циркумфлексы («pie à la mode»). Если вам нужно набирать такие символы на обычной клавиатуре, обратитесь к этой статье .
Unicode не нужен для обычного английского текста: вполне хватит ASCII-символов, включающих обычные неакцентированные буквы от A до Z, цифры от 0 до 9 и знаки пунктуации. Если вы работаете только с латинским алфавитом, использующимся в странах Западной Европы, то можете сохранять текст в кодировке ISO 8859-1 (неформально ее называют Latin-1), в которой каждый символ занимает один байт, однако в ней невозможно представить символы других языков. Однако в других языках требуется более широкий набор символов и без Unicode не обойтись. Unicode поддерживает более 100 тысяч символов из нескольких десятков языков. Unicode (также известый как стандарт ISO 10646) является расширением ASCII. В то время как ASCII отводит под каждый символ ровно 1 байт, для Unicode-символа требуется больше. Для обеспечения совместимости между ASCII и Unicode обычно используют кодировку UTF-8 . В ней для ASCII-символов используется как обычно 1 байт (поэтому ASCII-файл также считается корректным файлом в кодировке UTF-8), а для символов других языков и служебных символов — больше.
Хотя UTF-8 и Latin-1 одинаково кодируют ASCII-символы, однако акцентированные и т.п. символы представляются иначе; поэтому чтобы корректно обработать файл, необходимо знать его формат, иначе все символы, не принадлежащие ASCII-таблице, будут искажены.
Давайте посмотрим, как одна строчка на испанском языке («¡Que la Fuerza te acompañe!», что означает «Да пребудет с тобой Сила!») представляется в обоих форматах:
Обратите внимание на символы не из ASCII-таблицы (знак обращенного восклицания в начале и ñ ближе к концу), можно видеть, что в UTF-8 для их кодирования используется два байта, в то время как в Latin-1 всего один. Также видно, что в обоих форматах обычные ASCII-символы кодируются одним байтом.
Требуемая кодировка зависит от используемого приложения. Большинство Linux-программ работают с кодировкой UTF-8, многие другие используют Latin-1, а некоторые обе кодировки сразу. Сначала нужно определить, текст в какой кодировке нужен программе, а затем преобразовывать, если это требуется. К счастью, это можно с легкостью сделать (причем в обоих направлениях), воспользовавшись программой recode .
recode предлагает множество опций (для более подробной справки наберите recode —help или info recode ), ей можно воспользоваться для преобразования текста в разнообразные кодировки (для получения полного списка поддерживаемых кодировок введите recode -l ). Однако для простых преобразований достаточно команд: (на выходе получится текст в кодировке Latin-1 и UTF-8 соответственно)
В зависимости от требуемого преобразования проблема новой строки может устраниться автоматически, однако в особых случаях нужно обращаться к документации (или попробуйте опытным путем, что получится).
Заключение
Преобразование текстовых файлов из других операционных систем — не прямой процесс, однако в Linux для этого есть все средства. Неважно какой формат файла, всегда можно автоматизировать требуемое преобразование и работать с разными несовместимыми форматами.
Источник
Конвертирование файлов в кодировку UTF-8 в Linux
Оригинал: How to Convert Files to UTF-8 Encoding in Linux
Автор: Aaron Kili
Дата публикации: 2 ноября 2016 года
Перевод: А. Кривошей
Дата перевода: ноябрь 2017 г.
В этом руководстве мы рассмотрим кодировки символов и разберем несколько примеров преобразования файлов из одной кодировки в другую с помощью утилиты командной строки. Затем мы покажем, как преобразовать файлы в Linux из любой кодировки (charset) в UTF-8.
Как вы, наверное, уже знаете, компьютер не понимает и не хранит информацию в виде букв, цифр или чего-либо еще. Он работает только с битами. Бит имеет только два возможных значения — 0 или 1, true или false, да или нет. Все остальное кодируется последовательностями битов.
Простыми словами, кодировка символов — это способ кодировки различных символов определенными последовательностями нулей и единиц. Когда мы вводим текст и сохраняем его в файл, слова и предложения, которые мы набираем, состоят из разных символов, а символы преобразуются в биты с помощью кодировки.
Существуют различные схемы кодирования, такие как ASCII, ANSI, Unicode и другие. Ниже приведен пример кодировки ASCII.
В Linux для преобразования текста из одной кодировки в другую используется утилита командной строки iconv.
Вы можете проверить кодировку файла с помощью команды file, используя флаг -i или -mime, который печатает строку типа mime, как в приведенных ниже примерах:

Синтаксис команды iconv следующий:
Где -f или —from-code задает входную кодировку, а -t или —to-encoding задает конечную кодировку.
Для того, чтобы вывести список всех доступных опций, введите:
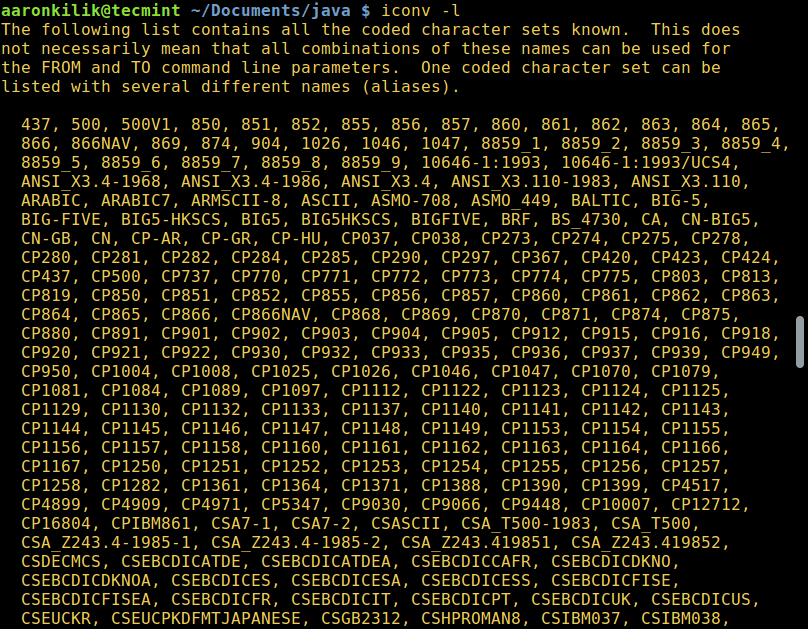
Конвертирование файлов из UTF-8 в ASCII
Далее мы научимся конвертировать текст из одной кодировки в другую. Приведенная ниже команда преобразует текст из ISO-8859-1 в кодировку UTF-8.
Рассмотрим файл input.file, который содержит следующие символы:
(Прим: вы увидите эти символы на снимке ниже)
Начнем с проверки кодировки файла, затем просмотрим его содержимое. Мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы затем проверяем содержимое выходного файла и новую кодировку, как показано ниже.
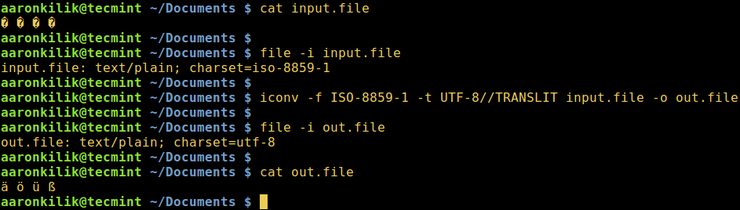
Примечание. Если в команду добавлена строка //IGNORE, то символы, которые не могут быть преобразованы, и ошибка выводятся после преобразования.
Далее, если добавлена строка //TRANSLIT, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы при необходимости и по возможности транслитерируются. Это означает, что если символ не может быть представлен в целевой кодировке, его можно аппроксимировать одним или несколькими похожими символами.
Далее, любой символ, который не может быть транслитерирован и которого нет в целевой кодировке, заменяется в выводе вопросительным знаком (?).
Конвертирование нескольких файлов в кодировку UTF-8
Возвращаясь к основной теме нашей статьи, мы можем написать небольшой скрипт для преобразования нескольких или всех файлов в каталоге в кодировку UTF-8, под названием encoding.sh:
Сохраните этот файл и сделайте скрипт исполняемым. Запускайте его из той директории, где расположены ваши файлы.
Важное замечание. Вы также можете также использовать этот скрипт для преобразования нескольких файлов из одной заданной кодировки в другую (любую), просто меняйте со значения переменных FROM_ENCODING и TO_ENCODING, не забывая об имени выходного файла «$
Для получения дополнительной информации почитайте руководство iconv:
Подводя итог этой статье, необходимо отметить, что понимание способов преобразования текста из одной кодировки в другую — это знания, необходимые каждому пользователю компьютера, а тем более программистам, когда дело касается работы с текстами.
Если вы хотите лучше понять проблему кодировок символов, прочитайте следующие статьи:
Источник
Перекодировка из cp1251 в UTF8
Как автоматически перекодировать все txt файлы с кодировкой cp1251 в UTF8 ?






> mv $FILE <,.orig>&& iconv -f CP1251 -t UTF-8 $FILE.orig -o $FILE
«man recode» и к тебе относится.
recode cp1251..utf8 *.txt

а man enconv относится к тебе.
если я знаю из какой кодировки в какую мне надо перевести, то эвристика enca мне не нужна. А для собственно перекодировки recode подходит лучше.
Txt книжки можно фаерфоксом открывать. Он автоматически распознаёт кодировки.
enconv -L russian *txt
recode cp1251..utf8 *.txt
во втором варианте символов больше 😀
в твоём варианте откуда он догадается что надо перекодировать В utf8? Из локали возьмёт? Ну тогда
recode cp1251 *.txt
и символов меньше.
из переменной, указанной в
Как запустить рекурсивную перекодировку всех txt файлов?
они не в одной директории, есть много под директорий..
find /path/to/dir -iname ‘*\.txt’ -exec recode cp1251..utf8 <> \;
Источник



