- Драйверы устройств в Linux
- Часть 2: Пишем в классе наш первый драйвер для Linux
- Динамическая загрузка драйверов
- Наш первый драйвер для Linux
- Сборка нашего первого драйвера
- Подведем итог
- Как написать свой первый Linux device driver. Часть 3
- Сборка модуля ядра
- Как написать свой первый Linux device driver. Часть 2
- Функция scull_open
- Функция scull_read
- Функция scull_write
- Опрос
Драйверы устройств в Linux
Часть 2: Пишем в классе наш первый драйвер для Linux
Оригинал: «Device Drivers, Part 2: Writing Your First Linux Driver in the Classroom»
Автор: Anil Kumar Pugalia
Дата публикации: December 1, 2010
Перевод: Н.Ромоданов
Дата перевода: июнь 2012 г.
В этой статье, которая является частью серии статей о драйверах устройств в Linux, речь идет о концепции динамической загрузки драйверов — сначала мы перед тем, как собирать драйвер, напишем драйвер для Linux, а затем, после сборки, загрузим его.
Светлана и Пагс добрались в свой класс с опозданием и увидели, что их профессор уже начал читать лекцию. Светлана робко попросила разрешения войти. Раздраженный профессор Гопи ответил: «Входите! Вы, друзья, опять сегодня опоздали, и по какой причине»?
Пагс поспешно ответил, что они обсуждали именно ту тему, которую сегодня изучают в классе — драйверы устройств в Linux. Пагс был более, чем счастлив, когда профессор сказал: «Хорошо! Тогда что-нибудь скажите о динамической загрузке в Linux. Если вы справитесь, то я прощу вас обоих!». Пагс знал, что один из способов сделать профессора счастливым, это — покритиковать Windows.
Он объяснил: «Как известно, при обычной установке драйверов в Windows для того, чтобы их активировать, необходимо перезагрузить систему. А если это, предположим, действительно неприемлемо в случае, если это нужно делать на сервере? Вот где выигрывает Linux. В Linux можно загружать и выгружать драйверы на лету, и это активно используется сразу после загрузки системы. Кроме того, драйвер мгновенно отключается после его выгрузки. Это называется динамической загрузкой и выгрузкой драйверов в Linux «.
Это впечатлило профессора. «Хорошо! Идите на свои места, но больше не опаздывайте». Профессор продолжил лекцию: «Теперь, когда вы уже знаете, что такое динамическая загрузка и выгрузка драйверов, я, прежде, чем мы перейдем к написанию нашего первого драйверов, покажу вам, как загружать и выгружать драйвера».
Динамическая загрузка драйверов
Эти динамически загружаемые драйвера чаще всего называют модулями, которые собираются в виде отдельных модулей с расширением .ko (объект ядра). В каждой системе Linux в корне файловой системы (/) есть стандартное место для всех предварительно собранных модулей. Они организованы аналогично древовидной структуре исходных кодов ядра и находятся в директории /lib/modules/ /kernel , где результат вывода системной команды uname -r (см.рис.1).
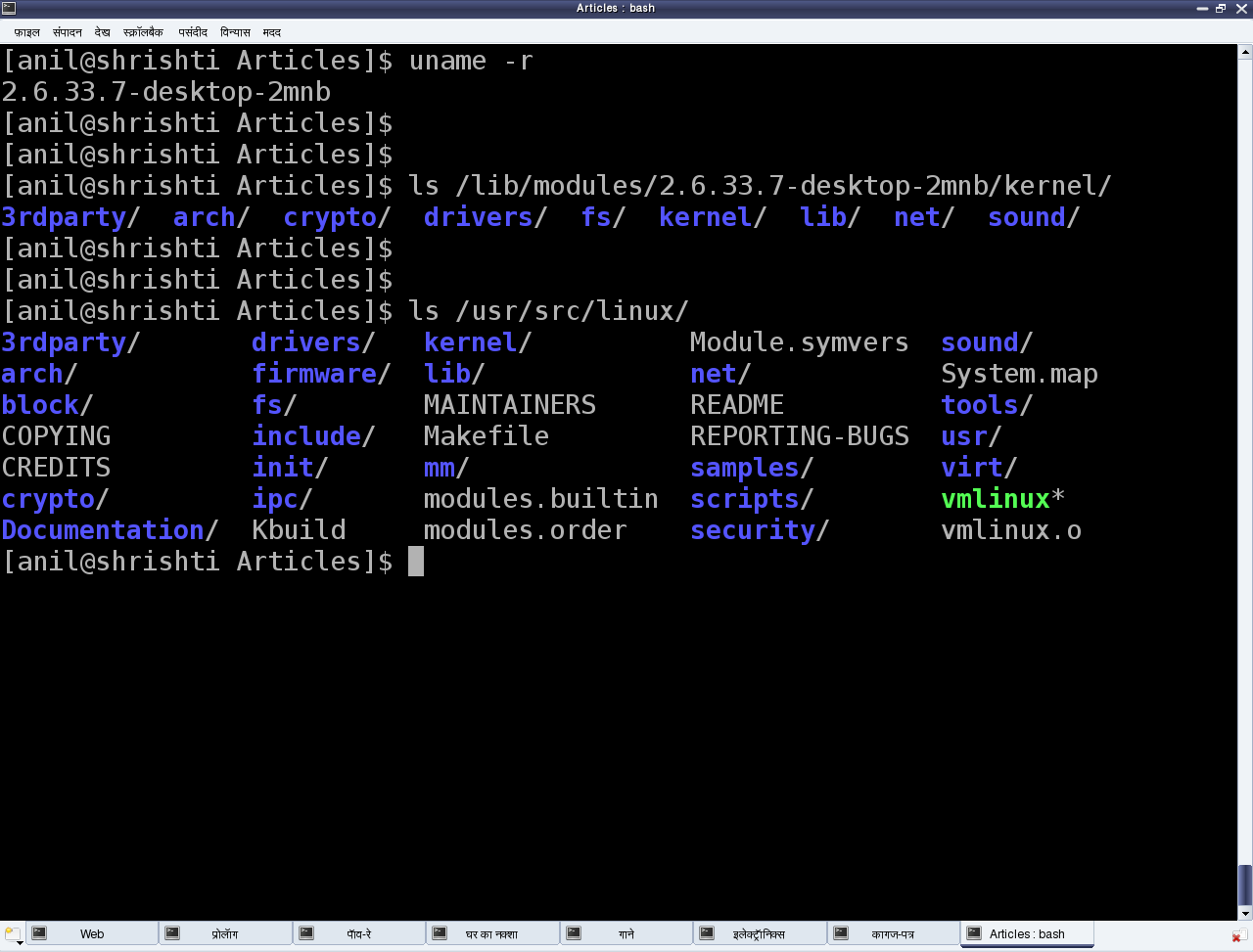
Рис.1: Предварительно собранные модули Linux
Чтобы динамически загружать и выгружать драйверы, воспользуйтесь следующими командами, которые находятся в директории /sbin и должны выполняться с привилегиями пользователя root:
- lsmod — список модулей, загруженных в текущий момент
- insmod — добавление / загрузка указанного файла модуля
- modprobe — добавление / загрузка модуля вместе со всеми его зависимостями
- rmmod — удаление / выгрузка модуля
Давайте в качестве примера рассмотрим соответствующие драйвера файловой системы FAT. На рис.2 показан весь процесс нашего эксперимента. Файлы с модулями будут fat.ko , vfat.ko и т.д., находящиеся в директории fat (в vfat для старых версий ядра) в /lib/modules/`uname -r`/kernel/fs . Если они представлены в сжатом формате .gz , вам нужно будет распаковать их с помощью команды gunzip , прежде чем вы сможете выполнить операцию insmod .
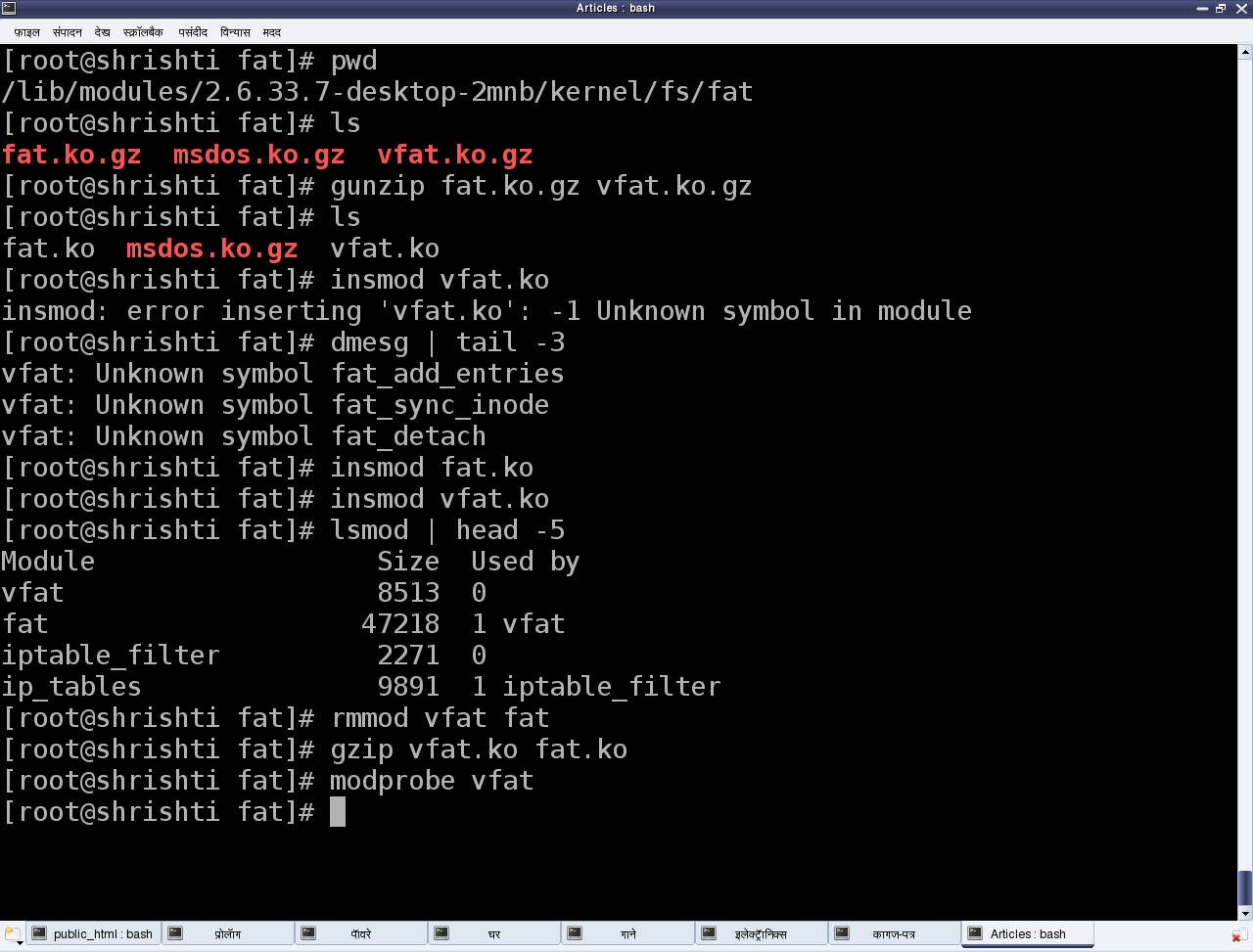
Рис.2: Операции с модулями Linux
Модуль vfat зависит от модуля fat , так что первым должен быть загружен модуль fat.ko . Чтобы автоматически выполнить распаковку и загрузку зависимостей, воспользуйтесь командой modprobe . Обратите внимание, что когда вы пользуетесь командой modprobe , вы не должны в имени модуля указывать расширение .ko . Команда rmmod используется для выгрузки модулей.
Наш первый драйвер для Linux
Перед тем, как написать наш первый драйвер, давайте рассмотрим некоторые понятия. Драйвер никогда не работает сам по себе. Он похож на библиотеку, загружаемую из-за функций, которые будут вызваны из работающего приложения. Он написан на языке C, но в нем отсутствует функция main() . Кроме того, он будет загружаться / компоноваться с ядром, поэтому он должен компилироваться аналогично тому, как было откомпилировано ядро, и вы можете в качестве заголовочных файлов использовать только те, что есть в исходном коде ядра, а не из стандартного директория /usr/include .
Интересный факт, касающийся ядра, это то, что оно, как мы видим даже на примере нашего первого драйвера, представляет собой объектно-ориентированную реализацию на языке C. В любом драйвере есть конструктор и деструктор. Когда модуль успешно загружается в ядро, то вызывается конструктор модуля, а дескруктор модуля вызывается, когда команде rmmod удается успешно выгрузить модуль. Это в драйвере две обычные функции, разве что они называются init и exit, соответственно, и вызываются с помощью макросов module_init() и module_exit() , которые определены в заголовков ядра module.h .
С учетом вышесказанного это полный код нашего первого драйвера; назовем его ofd.c. Обратите внимание, что отсутствует заголовок stdio.h (заголовок пользовательского пространства), вместо него мы используем аналог kernel.h (заголовок пространства ядра). Функция printk() эквивалентна функции printf() . Кроме того, для обеспечения совместимости версии модуля с ядром, в которое будет загружен модуль, добавлен заголовок version.h . С помощью макроса MODULE_* заполняется информация, относящаяся к модулю, которая будет использована как «подпись» модуля.
Сборка нашего первого драйвера
Т.к. у нас есть код на языке C, настало время его скомпилировать и создать файл модуля ofd.ko . Для этого мы используем систему сборки ядра. В приведенном ниже файле Makefile происходит обращение к системе сборки ядра из исходных кодов, а файл Makefile ядра, в свою очередь, обращается к файлу Makefile нашего нового драйвера с тем, чтобы собрать драйвер.
Чтобы собрать драйвер для Linux, у вас в системе должен быть исходный код ядра (или, по крайней мере, заголовки ядра). Предполагается, что исходный код ядра будет находиться в директории /usr/src/linux . Если в вашей системе он находится в каком-нибудь другом месте, то укажите это место в переменной KERNEL_SOURCE в файле Makefile .
Когда есть код на языке C ( ofd.c ) и готов файл Makefile , то все, что нам нужно сделать для сборки нашего первого драйвера ( ofd.ko ), это вызвать команду make .
Подведем итог
Как только у нас будет файл ofd.ko , мы в роли пользователя root или с помощью команды sudo выполним обычные действия.
Команда lsmod должна вам сообщить о том, что драйвер ofd загружен.
Пока студенты экспериментировали со своим первым модулем, прозвенел звонок, сообщивший об окончании урока. Профессор Гопи подвел итог: «В настоящий момент мы не увидели ничего, кроме того, что модуль lsmod сообщил о загрузке драйвера. Куда выводит информацию команда printk ? Найдите это самостоятельно на лабораторных занятиях и познакомьте меня с своими выводами. Также учтите, что наш первый драйвер будет шаблоном для любого драйвера, который можно написать для Linux. Написание специализированных драйверов это всего лишь вопрос о том, чем будет заполнен конструктор и деструктор драйвера. Поэтому дальнейшее изучение будет представлять собой расширение данного драйвера с целью получить драйвер с конкретными функциональными возможностями».
Источник
Как написать свой первый Linux device driver. Часть 3
Добрый вечер, хаброчитатели!
В предыдущих статьях (один, два) мы определили понятие символьного устройства и написали простейший пример символьного драйвера. Последняя часть посвещена проверки его работоспособности. На Хабре уже есть примеры как можно протестировать драйвер, например: тык.
Я попытаюсь рассмотреть данный вопрос чуть подробнее, надеюсь, вам понравится.

Пожалуйста, если у вас есть мысли, что можно добавить/исправить, то жду ваших комментариев или писем в ЛС, спасибо.
Сборка модуля ядра
Для того чтобы собрать наш модуль, нам понадобится написать маленький Makefile. Прочитать, что такое Makefile, можно тут: раз, два, три. Также я писал как-то пример Makefile для студентов, можно посомтреть тут: клик.
Если вкратце, то Makefile это набор инструкций для программы make, а make это утилита, автоматизирующая процесс преобразования файлов из одной формы в другую. После беглого знакомства с Makefile можно посмотреть на код:
Давайте взгялнем на команду:
Она начинается со смены каталога (в моем случае на: /lib/modules/4.4.0-93-generic/build), в этом каталоге находятся исходные тексты ядра, а также Makefile, который утилита make прочитает. Переменная M, позволяет указать где находится наш проект и вернуться назад, по указанному в нем пути. Т.е на самом деле мы используем другой Makefile, чтобы выполнить сборку нашего модуля.
Пишем в командной строке make и получаем вывод:
После сборки, на выходе получился скомпилированный модуль fake.ko. Его то мы и будем загружать с помощью команды insmod.
Далее нужно выполнить следующую последовательность действий:
- Загрузить модуль в ядро
Выполнить: sudo insmod fake.ko - Проверить, с помощью команды dmesg, ожидаемый вывод модуля
Пример: scull: register device major = 243 minor = 0 - Создать файл нашего устройства в файловой системе
Пример: sudo mknod /dev/scull c 243 0 - Изменить права доступа
Пример: sudo chmod 777 /dev/scull
Осталось дело за малым, пишем маленькую программу, которая позволит просто считывать/записывать данные.
- Компилируем: gcc test.c -o test
- Вызываем исполняемый файл: ./test
- Записываем в устройство: Hello world!
- Повторно вызываем исполняемый файл: ./test
- Считываем данные: scull: Hello world!
На этом тестирование простого символьного драйвера завершено, теперь вы можете придумать новый функционал, реализовать и выполнить проерку самостоятельно:)
В конце предыдущей статье я проводил опрос, хочу сказать спасибо всем, кто принял в нем участие! В скором времени начну писать о процессе портирования драйверов устройств с одной версии ядра на другую.
Источник
Как написать свой первый Linux device driver. Часть 2
В предыдущей части мы рассмотрели базовые структуры, а также написали инициализацию и удаление устройства.
В данной статье мы добавим в наш драйвер функции открытия scull_open, чтения/записи scull_read/scull_write и получим первый рабочий драйвер устройства.

Хочу выразить благодарность всем пользователям, которые прочитали, лайкнули и прокомментировали мою предыдущую статью. Отдельное спасибо за уточнения Kolyuchkin и dlinyj.
В прошлый раз поступило предложение не рассматривать подробно внутренности каждой функции, поэтому в данной статье я попытаюсь представить их в более широком смысле.
Сразу к делу!
В предыдущей статье мы не рассмотрели одну функцию, которая является частью scull_cleanup_module, а именно scull_trim. Как вы можете наблюдать в функции присутствует цикл, который просто проходится по связному списку и возвращает память ядру. Мы не будем заострять тут наше внимание. Главное впереди!
Перед рассмотрением функции sull_open, я хотел бы сделать маленькое отступление.
Многое в системе Linux может быть представлено в виде файла. Какие операции чаще совершаются с файлами — открытие, чтение, запись и закрытие. Также и с драйверами устройств, мы можем открыть, закрыть, прочитать и записать в устройство.
Поэтому в структуре file_operations, мы видим такие поля как: .read, .write, .open и .release — это базовые операции, которые может выполнять драйвер.
Функция scull_open
Функция принимает два аргумента:
- Указатель на структуру inode. Структура inode — это индексный дескриптор, который хранит информацию о файлах, каталогах и объектах файловой системы.
- Указатель на структуру file. Структура, которая создается ядром при каждом открытии файла, содержит информацию, необходимую верхним уровням ядра.
Главной функцией scull_open является инициализация устройства (если устройство открыто первый раз) и заполнение необходимых полей структур для его корректной работы.
Так как наше устройство ничего не делает, то нам и нечего инициализировать:)
Но чтобы создать видимость работы, мы выполним несколько действий:
В выше приведенном коде с помощью container_of мы получаем указатель на cdev типа struct scull_dev, используя inode->i_cdev. Полученный указатель записываем в поле private_data.
Далее, все еще проще, если файл открыт для записи — очистим его перед использованием и выведем сообщение о том, что устройство открыто.
Функция scull_read
Сейчас я постараюсь описать смысл использования функции read.
Так как наше устройство является символьным, то мы можем работать с ним как с потоком байтов. А что можно делать с потоком байтов? Правильно — читать. Значит, как понятно из названия функции, она будет читать из устройства байтики.
Когда вызывается функция чтения, ей передаются несколько аргументов, первый из них мы уже рассмотрели, теперь посмотрим на остальные.
buf — это указатель на строку, а __user говорит нам о том, что этот указатель находится в пространстве пользователя. Аргумент передает пользователь.
count — количество байтов, которые нужно прочитать. Аргумент передает пользователь.
f_pos — смещение. Аргумент передает ядро.
Т.е., когда пользователь хочет прочитать из устройства, он вызывает функцию read (не scull_read) при этом указывает буфер куда будет записана информация и количество читаемых байт.
Теперь немного подробнее рассмотрим код:
Первым делом идут проверки:
- Если смещение больше, чем размер файла, то, по понятным причинам, читать мы больше не можем. Выведем ошибку и выйдем из функции.
- Если сумма текущего смещения и размера данных для считывания больше размера кванта, то мы корректируем размер данных, подлежащих считыванию, и рапортуем сообщение наверх.
А вот и предмет разговора:
copy_to_user — копирует данные в buf (который находится в пространстве пользователя) из памяти, которую выделило ядро dptr->data[s_pos] размером count.
Если вам сейчас не понятны все эти переменные : s_pos, q_pos, item, rest — не беда, тут главное понять смысл функции read, а уже в 3 части статьи мы протестируем наш драйвер, и там уже будет понятно за что отвечает каждая из них. Но если вы хотите узнать об этом сейчас, вы всегда можете использовать printk (если вы понимаете, о чем я:)).
Функция scull_write
В виду того, что функция scull_write очень похожа на scull_read, и ее отличие от вышерассмотренной понятен из названия, я не буду расписывать эту функцию, а предлагаю вам осмыслить ее самостоятельно.
Все, мы написали полноценный бесполезный драйвер, внизу будет приведен полный код, а в следующей статье мы его протестируем.
После того как я прочитал статью, то понял, что получилось слишком много кода и лишних функций, поэтому ниже приведен максимально простой вариант реализации данного драйвера.
Опрос
Так сложились обстоятельства, что в данный момент у меня есть задачи по портированию драйверов устройств с одной версии ядра на другую. Интересно ли вам было бы прочитать как происходит этот процесс на конкретных примерах?
Если у вас уже есть такой опыт, вы можете поделиться им и написать мне, с какими вы столкнулись проблемами/ошибками при переносе драйверов устройств. А я в свою очередь постараюсь добавить ваш опыт в статью (обязательно укажу вас в ней).
Спасибо! 🙂
Источник



