- 16 команд мониторинга Linux-сервера, которые вам действительно нужно знать
- iostat
- meminfo и free
- mpstat
- netstat
- ps и pstree
- strace
- tcpdump
- uptime
- vmstat
- Wireshark
- Как узнать загрузку процессора и памяти в Linux — команда vmstat
- Как нужно оценивать производительность?
- Синтаксис команды vmstat
- Опции vmstat
- Примеры использования vmstat
- Заключение
16 команд мониторинга Linux-сервера, которые вам действительно нужно знать
Хотите знать, что самом деле происходит на с вашим сервером? Тогда вы должны знать эти основные команды. Как только вы их освоите, вы станете администратором-экспертом в системах Linux.
В зависимости от дистрибутива Linux, вы можете с помощью программы с графическим интерфейсом получить больше информации, чем могут дать эти команды, запускаемые из командной оболочки. В SUSE Linux, например, есть отличное графическое инструментальное средство YaST , предназначенное для конфигурирования и управления системой; также в KDE есть отличное инструментальное средство KDE System Guard .
Однако, основное правило администратора Linux состоит в том, что вы должны работать с графическим интерфейсом на сервере только в случае, когда это вам абсолютно необходимо. Это обусловлено тем, что графические программы на Linux занимают системные ресурсы, которые было бы лучше использовать в другом месте. Поэтому хотя программа с графическим интерфейсом и может отлично подходить для базовой проверки состояния сервера, если вы хотите знать, что происходит на самом деле, отключите графический интерфейс и воспользуйтесь инструментальными средствами, работающими из командной строки Linux.
Это также означает, что вы должны запускать графический интерфейс на сервере только тогда, когда это действительно необходимо; не оставляйте его работать. Чтобы достичь оптимальной производительности, сервер Linux должен работать на уровне runlevel 3 , на котором, когда компьютер загружается, полностью поддерживается работа в сети и многопользовательский режим, но графический интерфейс не запускается. Если вам действительно нужно графический рабочий стол, вы всегда можете его открыть с помощью команды startx , выполненной из командной строки.
Если ваш сервер при загрузке запускается в графическом режиме, то вам это нужно изменить. Для этого откройте терминальное окно, с помощью команды su перейдите в режим пользователя root и с помощью вашего любимого текстового редактора откройте файл /etc/inittab .
Как только вы это сделаете, найдите строку initdefault и измените ее с id:5:initdefault: на id:3:initdefault:
Если файла inittab нет, то создайте его и добавьте строку id:3 . Сохраните файл и выйдите из редактора. В следующий раз при загрузке ваш сервер будет загружаться на уровне запуска 3. Если вы после этого изменения не захотите перезагружать сервер, вы также можете с помощью команды init 3 непосредственно задать уровень запуска вашего сервера.
Как только ваш сервер станет работать на уровне запуска init 3, вы для того, чтобы увидеть, что происходит внутри вашего сервера, можете начать пользоваться следующими программами командной оболочки.
iostat
Команда iostat подробно показывает, что к чему в вашей подсистеме хранения данных. Как правило, вы должны использовать команду iostat для того, чтобы следить, что ваша подсистема хранения работают в целом хорошо и прежде, чем ваши клиенты заметят, что сервер работает медленно, выявлять те места, из-за медленного ввода/вывода которых возникают проблемы. Поверьте мне, вам следует обнаруживать эти проблемы раньше, чем это сделают ваши пользователи!
meminfo и free
Команда meminfo предоставит вам подробный список того, что происходит в памяти. Как правило, доступ к данным meminfo можно получить с помощью другой программы, например, cat или grep . Так, например, с помощью команды
вы в любой момент будете знать все, что происходит в памяти вашего сервера.
Вы можете воспользоваться командой free для быстрого «фактографического» взгляда на память. Если кратко, то с помощью команды free вы получите обзор состояния памяти, а с помощью команды meminfo вы узнаете все подробности.
mpstat
Команда mpstat сообщает о действиях каждого из доступных процессоров в многопроцессорных серверах. В настоящее время почти во всех серверах используются многоядерные процессоры. Команда mpstat также сообщает об усредненной загрузке всех процессоров сервера. Это позволяет отображать общую статистику по процессорам во всей системе или для каждого процессора отдельно. Эти значения могут предупредить вас о возможных проблемах с приложением прежде, чем они станут раздражать пользователей.
netstat
Команда netstat , точно также, как и ps , является инструментальным средством Linux, которым администраторы пользуются каждый день. Она отображает большое количество информации о состоянии сети, например, об использовании сокетов, маршрутизации, интерфейсах, протоколах, показывает сетевую статистику и многое другое. Некоторые из наиболее часто используемых параметров:
-a — Показывает информацию о всех сокетах
-r — Показывает информацию, касающуюся маршрутизации
-i — Показывает статистику, касающуюся сетевых интерфейсов
-s — Показывает статистику, касающуюся сетевых протоколов
Команда nmon , сокращение от Nigel’s Monitor, является популярным инструментальным средством с открытым исходным кодом, которое предназначено для мониторинга производительности систем Linux. Команда nmon следит за информацией о производительности нескольких подсистем, таких как использование процессоров, использование памяти, выдает информацию о работе очередей, статистику дисковых операций ввода/вывода, статистику сетевых операций, активности системы подкачки и метрические характеристики процессов. Затем вы через «графический» интерфейс команды curses можете в режиме реального времени просматривать информацию, собираемую командой nmon.
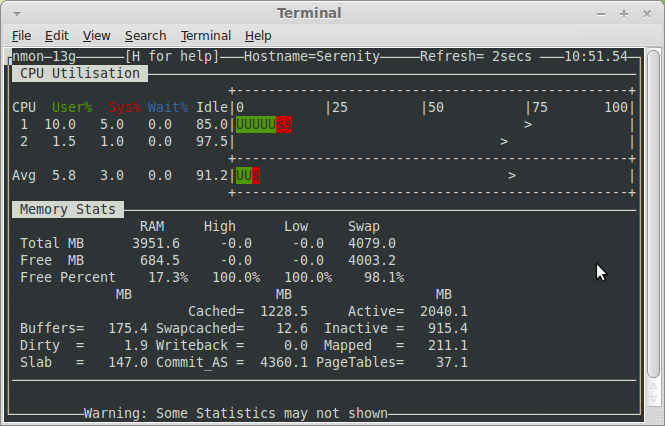
Чтобы команда nmon работала, вы должны ее запустить из командной строки. После этого вы можете с помощью нажатий на отдельные клавиши выбирать подсистемы, за работой которых вы хотите проследить. Например, чтобы получить статистику по процессору, памяти и дискам, наберите c , m и d . Вы также можете использовать команду nmon с флагом -f для того, чтобы сохранить статистику в файле CSV для последующего анализа.
Я считаю, что для повседневного мониторинга серверов команда nmon является одной из самых полезных программ в моем инструментальном наборе, предназначенном для систем Linux.
Команда pmap сообщает об объеме памяти, которые используются процессами на вашем сервере. Вы можете использовать этот инструмент для того, чтобы определить, для каких процессов на сервере выделяется память и как эти процессы ее используют.
ps и pstree
Команды ps и pstree являются двумя самыми лучшими командами администратора Linux. Они обе выдают список всех запущенных процессов. Команда ps показывает, сколько памяти и процессорного времени используют программы, работающие на сервере. Команда pstree выдает меньше информации, но указывает, какие процессы являются потомками других процессов. Имея эту информацию, вы можете обнаружить неуправляемые процессы и уничтожить их с помощью команды kill , предназначенной для «безусловного уничтожения» процессов в Linux.
Программа sar является инструментальным средством мониторинга, столь же универсальным как швейцарский армейский нож. Команда sar , на самом деле, состоит из трех программ: sar , которая отображает данные, и sa1 и sa2 , которые собирают и запоминают данные. После того, как программа sar установлена, она создает подробный отчет об использовании процессора, памяти подкачки, о статистике сетевого ввода/вывода и пересылке данных, создании процессов и работе устройств хранения данных. Основное отличие между sar и nmon в том, что первая команда лучше при долгосрочном мониторинге системы, в то время, как я считаю, nmon лучше для того, чтобы мгновенно получить информацию о состоянии моего сервера.
strace
Команду strace часто рассматривают, как отладочное средство программиста, но, на самом деле, ее можно использовать не только для отладки. Команда перехватывает и записывает системные вызовы, которые происходят в процессе. Т.е. она полезна в диагностических, учебных и отладочных целях. Например, вы можете использовать команду strace для того, чтобы выяснить, какой на самом деле при запуске программы используется конфигурационный файл.
tcpdump
Tcpdump является простой и надежной утилитой мониторинга сети. Ее базовые возможности анализа протокола позволяют получить общее представление о том, что происходит в вашей сети. Однако, чтобы по-настоящему разобраться в том, что происходит в вашей сети, вам следует воспользоваться программой Wireshark (см. ниже).
Команда top показывает, что происходит с вашими активными процессами. По умолчанию она отображает самые ресурсоемкие задачи, запущенные на сервере, и обновляет список каждые пять секунд. Вы можете отсортировать процессы по PID (идентификатор процесса), времени работы, можете сначала указывать новые процессы, затраты по времени, по суммарному затраченному времени, а также по используемой памяти и по общему времени использования процессора с момента запуска процесса. Я считаю, что это быстрый и простой способ увидеть, что некоторый процесс начинает выходить из-под контроля и из-за этого все движется к проблеме.
uptime
Используйте команду uptime для того, чтобы узнать, как долго работает сервер и сколько пользователей было зарегистрировано в системе. Эта команда также покажет вам среднюю загрузку сервера. Оптимальное значение равно 1 или меньше, что означает, что каждый процесс немедленно получает доступ к процессору и потери циклов процессора отсутствуют.
vmstat
Вы можете использовать команду vmstat , в основном, для контроля того, что происходит с виртуальной памятью. Для того, чтобы получить наилучшую производительность системы хранения данных, Linux постоянно обращается к виртуальной памяти.
Если ваши приложения занимают слишком много памяти, вы получите чрезмерное значение затрат страниц памяти (page-outs) — программы перемещаются из оперативной памяти в пространство подкачки вашей системы, которое находится на жестком диске. Ваш сервер может оказаться в таком состоянии, когда он тратит больше времени на управление памятью подкачки, а не на работу ваших приложений; это состояние называемое пробуксовкой (thrashing). Когда компьютер находится в состоянии пробуксовки, его производительность падает очень сильно. Команда vmstat , которая может отображать либо усредненные данные, либо фактические значения, может помочь вам определить программы, которые занимают много памяти, прежде, чем из-за них ваш процессор перестанет шевелиться.
Wireshark
Программа wireshark , ранее известная как ethereal (и до сих пор часто называют именно так), является «старшим братом» команды tcpdump , хотя она более сложная и с более расширенными возможностями анализа и отчетности по используемым протоколам. У wireshark есть как графический интерфейс, так и интерфейс командной оболочки. Если вам требуется серьезное администрирование сетей, вам следует использовать программу ethereal. И, если вы используете wireshark/ethereal, я настоятельно рекомендую воспользоваться книгой Practical Packet Analysis Криса Сандера (Chris Sander), рассказывающей о том, как с помощью практического анализа пакетов можно получить максимальную отдачу от этой полезной программы.
Это обзор всего лишь нескольких наиболее значимых систем мониторинга из многих, имеющихся для Linux. Тем не менее, если вы сможете освоить эти программы, они помогут вам на пути к вершинам системного администрирования Linux.
Источник
Как узнать загрузку процессора и памяти в Linux — команда vmstat
Производительность (или непроизводительность) систем очень сложно оценивать «на глаз» или даже с секундомером. Ведь даже если это и получится, то из виду будут упущены ключевые детали, предоставляющие информацию о том, почему производительность может быть именно такой, а не больше (или меньше). Для выяснения причин стоит углубиться в анализ этой самой производительности более основательно. И для этих целей существуют специализированные утилиты, одной из которых является vmstat – довольно популярный инструмент (после команды top разве что), которым пользуются многие системные администраторы Linux.
Как нужно оценивать производительность?
Вообще, производительность и/или быстродействие — величины постоянные только для конкретного (и довольно короткого) промежутка времени для конкретной системы. Для более объективной оценки необходимо проводить многочисленные «замеры» в разное время в течении довольно длительного (месяц и более) периода.
Немаловажно и то, что анализ следует проводить без использования всевозможных «синтетических» тестов — т. е. только в условиях реальной и пиковой нагрузки, возникающей во время реальный задач, предусмотренных техпроцессом, регламентом в рамках реальной «производственной» необходимости. Очень часто именно в таких условиях можно выявить ошибки в конфигурации системы, приводящие к ограничениям в использовании программно-аппаратных ресурсов.
Синтаксис команды vmstat
Утилитой vmstat можно анализировать не только использование процессора, но также память — оперативную и/или дисковую. Синтаксис команды следующий:
Основными аргументами являются delay – время (в секундах), в течение которого следует производить замер, а также count – количество замеров или отчётов. Если дать команду vmstat без указания количества замеров, то она будет выводить отчёты, пока не будет прервано её выполнение сочетанием клавиш .
Вывод vmstat разбит на столбцы, которые объединены в следующие категории:
- procs – информация о процессах;
- memory – состояние оперативной памяти;
- swap – состояние виртуальной памяти (раздел или файл подкачки);
- io – активность устройств хранения (диски, флешки и т. д.);
- system – общая активность системы;
- cpu – использование центрального процессора.
Как уже было отмечено выше, эти категории объединяют колонки из вывода vmstat по соответствующему типу информации. Стоит рассмотреть их по отдельности. Для раздела procs:
- r – количество процессов в обрабатываемой процессором очереди;
- b – количество процессов, стоящих в очереди на выполнение операций ввода/вывода.
Для раздела memory:
- free – размер свободной памяти. То же значение, которое определяется командой free;
- swpd – количество блоков, которые были перемещены в Swap;
- buff – буферы памяти;
- cache – кеш памяти.
- si – общее количество блоков, считываемых системой из Swap;
- so – общее количество блоков, перемещаемых системой в Swap.
- bi – количество блоков в секунду, считываемых с диска;
- bo – количество блоков в секунду, записанных на диск.
- in – частота (количество в секунду) системных прерываний;
- cs – частота переключений между задачами.
- us – используемое (в процентах) время для выполнения «пользовательских» (т. е. не принадлежащих ядру) задач;
- sy — используемое (в процентах) время для выполнения задач ядра;
- id – время (в процентах) в простое;
- wa — время (в процентах), отведённое на ожидание операций ввода/вывода.
Опции vmstat
Доступные для vmstat опции приведены в следующей таблице:
| Опция | Назначение |
| -a, — active | Выводит активную и неактивную память. Доступно начиная с ядра версии 2.5.41 и выше. |
| -f, — forks | Выводит количество системных вызовов fork, vfork и rfork, а также страниц виртуальной памяти, используемых этими вызовами. |
| -m, — slabs | Количество используемой динамической памяти для ядра. |
| -n, —one-header | Отображает заголовок таблицы результатов только один раз, а не периодически. |
| -s, — stats | Переключение режима отображения вывода. |
| -d, — disk | Выводит статистику использования диска. |
| -w | Для больших объёмов данных увеличивает визуально ширину столбцов. |
| -p, — partition device | Выводит статистику использования раздела. Необходимо указывать раздел device. |
| -S, —unit character | Выводит статистику в указанных единицах [k, K, m, M] – в килобитах, килобайтах, мегабитах и мегабайтах соответственно. |
| — t, —timestamp | Добавлять к выводу время замеров. |
| — D, —disk-sum | Выводит общую статистику по использованию дисков. |
Примеры использования vmstat
Несмотря на то, что опции vmstat и позволяют получить ценные сведения, однако в большинстве случаев системные администраторы их практически не используют. Чаще всего использование vmstat сводится к следующему (что вполне достаточно):
Вообще, сервер общего назначения считается хорошо отбалансирован в плане нагрузки, если около 50% времени он тратит на обработку пользовательских задач и ещё столько же — на работу системных вызовов, взаимодействующих с ядром. Простои в системе должны быть — это потенциал для увеличения нагрузки, но в то же время они (простои) не должны быть слишком большими — это значит, что мощности сервера расходуются впустую.
Из приведённого примера следует, что центральный процессор практически постоянно переключается между высоконагруженными режимами и периодами почти полного простоя. Таким образом, можно сделать вывод, что необходима настройка используемого в работе сервера ПО и системной конфигурации для более равномерного распределения нагрузки.
Заключение
Как можно видеть, даже без использования графических приложений с графиками и диаграммами, обычная команда vmstat способна дать наглядную картину происходящего, касающегося использования ресурсов системы. Ну а самые объективные и достоверные результаты анализа производительности могут зависеть от применяемой для каждого конкретного случая методики.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник



