- Отслеживание журналов входа в систему в Ubuntu
- Вступление
- Отслеживание входа в систему
- Использование команды «last»
- Использование команды «lastlog»
- Итоги
- Средства мониторинга Linux системы (часть 1?)
- Log-файлы (журналы)
- Правки в файлах
- Какова загрузка системы?(LoadAverage)
- Что происходит в системе (процессы)
- ps — process status
- В заключение…
Отслеживание журналов входа в систему в Ubuntu
Вступление
Конфигурирование и управление пользователями и группами – основная часть системного администрирования. Эта задача включает в себя мониторинг возможностей входа всех элементов системы.
В данном руководстве представлены основные понятия об управлении пользователями и ведении журнала аутентификации. Данные принципы работы изучаются на примере выделенного сервера Ubuntu 12.04, но любой современный дистрибутив Linux работает таким же образом.
В третьей части говорится о том, как отслеживать журнал регистрации доступа, чтобы убедиться в том, что система доступна только для авторизованных пользователей.
Отслеживание входа в систему
Основным компонентом управления аутентификацией является мониторинг системы после настройки пользователей.
К счастью, современные системы Linux регистрируют все попытки аутентификации в дискретном файле. Он расположен в «/var/log/auth.log».
sudo less /var/log/auth.log
May 3 18:20:45 localhost sshd[585]: Server listening on 0.0.0.0 port 22.
May 3 18:20:45 localhost sshd[585]: Server listening on :: port 22.
May 3 18:23:56 localhost login[673]: pam_unix(login:session): session opened fo
r user root by LOGIN(uid=0)
May 3 18:23:56 localhost login[714]: ROOT LOGIN on ‘/dev/tty1’
Sep 5 13:49:07 localhost sshd[358]: Received signal 15; terminating.
Sep 5 13:49:07 localhost sshd[565]: Server listening on 0.0.0.0 port 22.
Sep 5 13:49:07 localhost sshd[565]: Server listening on :: port 22.
. . .
Использование команды «last»
Как правило, нужно отследить только самые последние попытки входа. Это можно сделать при помощи инструмента «last»:
last
demoer pts/1 rrcs-72-43-115-1 Thu Sep 5 19:37 still logged in
root pts/1 rrcs-72-43-115-1 Thu Sep 5 19:37 — 19:37 (00:00)
root pts/0 rrcs-72-43-115-1 Thu Sep 5 19:15 still logged in
root pts/0 rrcs-72-43-115-1 Thu Sep 5 18:35 — 18:44 (00:08)
root pts/0 rrcs-72-43-115-1 Thu Sep 5 18:20 — 18:20 (00:00)
demoer pts/0 rrcs-72-43-115-1 Thu Sep 5 18:19 — 18:19 (00:00)
Это действие выводит отформатированную версию файла «/etc/log/wtmp».
Как можно видеть, в первой и третьей строках показано, что пользователь все еще находится в системе.
В противном случае, общее время сеанса пользователя задается набором значений, разделенных дефисом.
Использование команды «lastlog»
Чтобы получить подобную информацию в другом виде, можно просмотреть последний раз входа в систему каждого пользователя.
Это можно сделать, войдя в файл «/etc/log/lastlog». Данная информация сортируется в соответствии с записями в файле «/etc/passwd»:
lastlog
Username Port From Latest
root pts/1 rrcs-72-43-115-1 Thu Sep 5 19:37:02 +0000 2013
daemon **Never logged in**
bin **Never logged in**
sys **Never logged in**
sync **Never logged in**
games **Never logged in**
. . .
Здесь можно увидеть время последнего входа в систему каждого пользователя.
Обратите внимание, на данный момент многие пользователи системы никогда не входили, о чем говорит значение **Never logged in**.
Итоги
Авторизация пользователей в Linux является относительно гибкой областью управления системой, так как одну и ту же задачу можно выполнить разными способами при помощи простых инструментов.
Важно запомнить, где система хранит информацию о входе, чтобы отслеживать внесенные на сервер изменения
Источник
Средства мониторинга Linux системы (часть 1?)
Короче, продолжаем. Теперь я для вас подготовил некую уже не маленькую статью, на тему мониторинга Linux систем. В некотором роде эта статья мне будет служить в качестве мини-справочника по необходимым командам, для того, чтобы можно было понимать, все ли нормально с системой. Поговорим об основных командах типа top/htop/uptime/ps, о том где какие логи лежат и что они означают и так далее. Короче, начнем..
Log-файлы (журналы)
Все логи по умолчанию хоронятся в директории /var/log/ (ну так принято по стандарту иерархии файловой системы) и эти файлы — сведения о происходящих процессах в системе. Кстати, если вы поддерживайте систему, которая может быть интересна взломщикам, то настоятельно рекомендуется обзавестись системой дублирования логов, например, на туже почту. Взломщик будет думать, что все «зачистил» за собой, но доказательства его пребывания в системе останутся. Но речь не об этом..
Рассмотрим пример стандартных файлов в директории /var/log/, на примере ОС Debian Linux 7:
- /var/log/syslog — syslog является основным системным журналом и в нем сохраняются сообщения демонов и других программ, работающих в системе, например, dhclient, cron, init, xscreensaver, а также некоторые сообщения ядра. Этот журнал — первое место, откуда надо начинать просмотр при попытке отследить типичные системные ошибки
- /var/log/auth.log — содержит информацию системы авторизации, в том числе логины и механизм проверки подлинности, которые были использованы
- /var/log/daemon.log — содержит информацию о различных демонах/сервисах запущенных в системе. С помощью него можно находить проблемы во время падения системы
- /var/log/dmesg — в файле содержаться все сообщения ядра, начиная с этапа загрузки системы, а просмотреть содержимое этого файла можно используя команду dmesg
- /var/log/kern.log — файл журнала ядра, предоставляет подробный лог сообщений от ядра Linux, которые могут быть полезны при анализе и устранении неисправностей
- /var/log/messages — файл содержит глобальные настройки, в том числе сообщения, которые регистрируются при запуске системы
- /var/log/debug — журнал отладки, предоставляющий подробную отладочную информацию системы и приложений, которые используют syslogd для отладки
- /var/log/user.log — содержит информацию о всех журналах на уровне пользователя
- /var/log/btmp — файл содержит записи обо всех неудавшихся попытках регистрации пользователей в системе. Посмотреть неудачные попытки входа в систему можно с помощью команды lastb
- /var/log/faillog — в этом файле хранится число неудачных попыток входа в систему и их предельное число для каждой учётной записи. А если в консоли ввести команду faillog, то можно увидеть содержимое этого файла
- /var/log/mail.log, /var/log/mail.err, /var/log/mail.info, /var/log/mail.warn — файлы журналирующие почтовые события
- /var/log/lastlog — файл содержащий записи о предыдущих входах в систему
- var/log/apt — директория содержит информацию, которая пишется при установки/удалении пакета с помощью программы apt
- /var/log/alternatives.log — файл программы update-alternatives, которая является механизмом выбора предпочтительного ПО среди нескольких вариантов в таких дистрибутивах Linux, как Debian и Ubuntu
- /var/log/aptitude — файл программы aptitude содержащий информацию об установке/удалении пакетов
- /var/log/dbconfig-common — в случае использования утилиты dbconfig все действия будут журналироваться в файлах, в этой лиректории
- /var/log/dpkg.log — файл содержит информацию, которая пишется при установки/удалении пакета с помощью программы dpkg
- /var/log/fsck — если в вашей системе запускалась проверка файловой системы то она будет журналироваться в файлы находящиеся в этой директории
- /var/log/wtmp — файл содержит двоичные данные о времени регистрации и продолжительность работы всех пользователей системы. Он пользуется командой last для вывода списка регистрировавшихся пользователей
- /var/log/apache2 — если в вашей системе установлен apache, то в данной директории будут находиться журналы access_log и error_log
- /var/log/mysql.err и /var/log/mail.info — если у вас установлена СУБД MySQL, то в этих файлах будут журналироваться сведения о работе и об ошибках СУБД
Теперь приведем пример, что когда нам понадобится..
- Если у нас не запускается какая то служба, то имеет смысл посмотреть файл /var/log/syslog, хотя скажу сразу, туда логируется почти все, даже bind9, если таковой стоит, поэтому лучше смотреть этот файл при помощи «tail -f»:
- Если есть какие-то проблемы с системой, то можно воспользоваться такими командами, как dmesg, messages, debug
- Все что касается почтовой службы, мы можем просматривать в файлах var/log/mail.log, /var/log/mail.err, /var/log/mail.info, /var/log/mail.warn, но если у вас установлен exim или postfix, то у них уже будут свои log-файлы в своих директориях
- Чтобы понять, кто и когда заходил в систему, можно ввести команду last, все неудачные попытки входа в систему можно увидеть при помощи команды lastb
- Если мы хотим проверить, нормально ли установилось то или иное приложение, то стоит заглянуть в файлы dpkg.log, apt или aptitude (ну все зависит от того, как вы ставили то или иное приложение)
На этом про логи, я думаю, достаточно..
Правки в файлах
Иногда бывает полезно выявлять факты изменения файлов в такой директории, как /etc, особенно, если администрированием сервера занимайтесь не только вы. Сделать это все можно при помощи команды find с параметром -mtime. Например, следующая команда покажет файлы, которые были изменение в течении последних двух суток:
Более подробно поиск по различным временам описан тут.
Какова загрузка системы?(LoadAverage)
Вы наверное часто обращали внимание на такую строчку, как LoadAverage, которая показывает числа. Собственно эти числа отображают число блокирующих процессов на исполнение в определенный интервал времени, а именно 1 минута, 5 минут и 15 минут. Под блокирующим процессом подразумевается процесс, который ждет ресурсы для того, чтобы продолжить свою работу, а под ресурсами подразумевается ЦП, дисковая подсистема ввода вывода и сетевая подсистема ввода/вывода.
Не обязательно быть специалистом, чтобы понимать, что высокие показатели LA говорят о том, что система не справляется, например эти цифры могут говорить об аппаратных проблемах.
Чтобы посмотреть эти показания, достаточно воспользоваться командой top или uptime (о top мы поговорим несколько позднее)
Большинство (как и я ) будут думать, что чем меньше эти числа, тем лучше, но нужно понимать, когда бить тревогу, если значения этих цифр начнет расти.
Отличная аналогия «на машинках» о том, что эти цифры обозначают приведена в статье на хабре, поэтому приведу краткую выдержку от туда: представим, что одноядерный процессор это однополосный мост, а мы управляем движением на этом мосту. Если мост перегружен, то машины ждут (ну или стоят в пробке). Собственно количество машин в очереди это и есть то число, которое вы видите. Пример можно увидеть на этих картинках из этой прекрасной статьи:
 load average = 0.50
load average = 0.50  load average = 1.00
load average = 1.00  load average = 1.70
load average = 1.70
Исходя из того, что мы видим, можно понять, что Load Average равный 1,00 — идеальное значение, но это не так. Идеальным значением для меня можно считать 0,50 ну или на худой конец 0,70, так как должен сохраняться какой-то запас на случай внезапной нагрузки или нештатного поведения той или иной программы.
И имейте в виду, пример выше это пример для одноядерного процессора. Если у вас четырехядерный процессор или два двухядерных процессора, то идеальным LA для вас будет 2,00 или 2,80.
Теперь подытожим эту тему,
- Какое значение лучше смотреть? За минуту, 5 минут или 15 минут?
Если на одноядерном процессоре LA за 5 или 15 минут, то следует на это обратить внимание - Как понять сколько процессоров в системе?
ну тут все просто, нужно отфильтровать grep-ом вывод cpuinfo:
Что происходит в системе (процессы)
Собственно. чтобы увидеть эти показатели, понять, где у нас есть проблемы, и вообще получить информацию о процессах воспользуемся утилитой top:
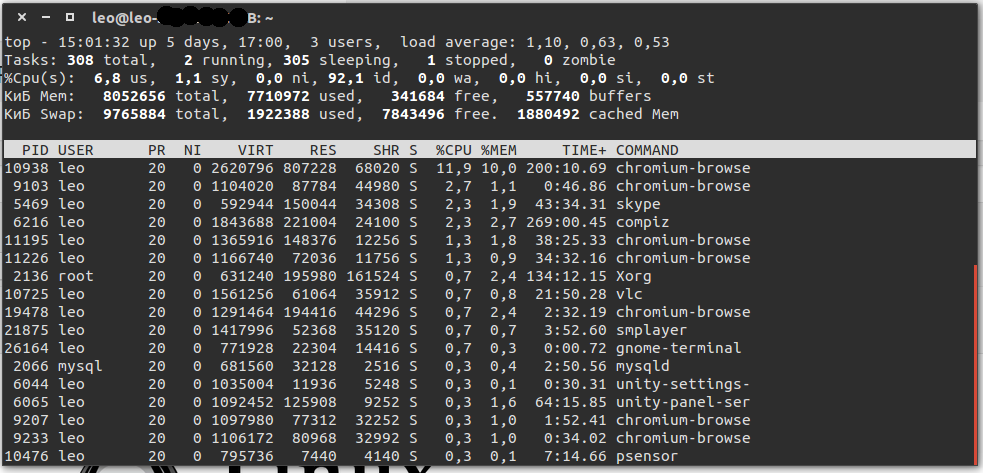
Рассмотрим по порядку, что есть что:
- Общая информация:
- текущем времени
- uptime времени (сколько система работает)
- количество пользовательских сессий (3 users)
- LoadAverage (ну о нем написан целый раздел)
- Статистика процессов:
- общее количество процессов в системе
- количество работающих в данный момент процессов
- количество спящих процессов (они работающие, просто «ждут» события)
- количество остановленных событий (я их останавливаю с помощью команды ctrl+z)
- количество процессов, ожидающих родительский процесс для передачи статуса завершения (0 zombie)
- Статистика использования CPU:
- 6,8 us — процент использования центрального процессора пользовательскими процессам
- 1.1 sy — процент использования центрального процессора системными процессами
- 0.0 ni — процент использования центрального процессора процессами с приоритетом, повышенным при помощи вызова nice
- 92.1 id (id это idle cpu time, т.е. время простоя CPU) — процент простоя процессора
- 0.0 wa — процент использования центрального процессора процессами, ожидающими завершения операций ввода-вывода (например чтение/запись на диск)
- 0.0 hi (hi это Hardware IRQ, т.е. аппаратные прерывания) — процент использования центрального процессора обработчиками аппаратных прерываний
- 0.0 si (si это Software Interrupts, т.е. программные прерывания) — процент использования центрального процессора обработчиками программных прерываний
- 0.0 st (st это Steal Time , т.е. заимствованное время) — количество ресурсов центрального процессора «заимствованных» у виртуальной машины гипервизором для других задач (таких, как запуск другой виртуальной машины); это значение будет равно нулю на не использующих виртуальные машины
- Статистика использования физической и swap памяти:
- общее количество памяти (total)
- количество используемой памяти (used)
- количество свободной памяти (free)
- количество памяти в кэше буферов (buffers)
- Список процессов, отсортированный по степени использования центрального процессора (по умолчанию), опишем столбцы:
- PID — идентификатор процесса
- USER — имя пользователя, который является владельцем процесса
- PR — приоритет процесса
- NI — значение «NICE», влияющие на приоритет процесса
- VIRT — объем виртуальной памяти, используемый процессом
- RES — объем физической памяти, используемый процессом
- SHR — объем разделяемой памяти процесса
- S — указывает на статус процесса: S=sleep (ожидает событий) R=running (работает) Z=zombie (ожидает родительский процесс)
- %CPU — процент использования центрального процессора данным процессом (0.3)
- %MEM — процент использования оперативной памяти данным процессом (0.7)
- TIME+ — общее время активности процесса (0:17.75)
- COMMAND — имя процесса (bb_monitor.pl)
Что нам тут интересно? Да интересно почти все :). Например, статистика CPU: высокие значения (более 80%) параметра wa говорят о простое из-за ввода вывода, что может говорить о проблемах с HDD. Кстати, если сложить все эти значения, то у вас получится 100%.
Что мы там можем делать в утилите top?
- Нажав на клавишу k мы можем убить процесс, достаточно будет ввести его PID
- нажав на клавишу u и введя имя пользователя мы можем увидеть все процессы определенного пользователя
- нажав на клавишу b или z и работающие процессы будут выделены цветом
Более подробнее о ключах top можно почитать в страницах man. Кстати, есть еще и отличный аналог утилиты top — htop:
ps — process status
Существует еще генератор снимков процессов ps. Подробнее о нем можно почитать его man, а ниже я приведу примеры использования этой команды:
- при помощи следующей команды мы можем выяснить, выполняется ли в данный момент программа apache:
- набрав в терминале следующую команду мы можем получить всю информацию о всех процессах всех пользователей в системе:
Этого я думаю достаточно. Есть еще масса интересных примеров на просторах интернета, например тут.
В заключение…
начиная писать эту статью, я не думал что все получится на столько громоздко, поэтому еще будет как минимум вторая или третья часть средств мониторинга linux систем.
Источник



