- Узнаём данные S.M.A.R.T. в Linux. Контроль состояния HDD или SSD
- S.M.A.R.T.
- Contents
- Smartmontools
- smartctl
- Run a test
- View test results
- Generate table with attributes of all disks
- smartd
- daemon management
- Define the devices to monitor
- Notifying potential problems
- Power management
- Schedule self-tests
- Alert on temperature changes
- Complete smartd.conf example
- Console applications
- Оценка технического состояния жестких дисков с использованием технологии S.M.A.R.T
- Общие сведения о технологии S.M.A.R.T
- smartctl — программное средство для управления S.M.A.R.T
- Примеры использования smartctrl.
- Расшифровка атрибутов S.M.A.R.T
- Оценка технического состояния жесткого диска по данным S.M.A.R.T
- Выполнение встроенных тестов S.M.A.R.T
- Список команд ATA для работы с S.M.A.R.T
Узнаём данные S.M.A.R.T. в Linux. Контроль состояния HDD или SSD
Дата добавления: 07 июля 2012

S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology) — это технология, предоставляющая пользователю различные данные о текущем состоянии жесткого диска или твердотельного накопителя. Анализируя данные S.M.A.R.T., пользователь может оценить состояние своих накопителей и решить, требуют ли они замены или ещё смогут работать долго и без сбоев.
Консольный способ: smartmontools
Узнать данные S.M.A.R.T. в чистом виде нам поможет утилита под названием smartmontools .
Приведем пример установки для дистрибутивов на основе Debian:
Количество атрибутов может отличаться в зависимости от модели диска.
В этой таблице нам нужно смотреть на значение поля RAW_VALUE для нужного атрибута. Именно оно показывает текущее значение атрибута.
Наиболее важные показатели:
Raw_Read_Error_Rate — количество ошибок чтения. Ненулевое значение должно сильно насторожить, а большие значение и вовсе говорят о скором выходе диска из строя. Известно, что на дисках Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5? большое значение в этом поле является нормальным. Для остальных же дисков в идеале значение должно быть равно нулю;
Spin_Up_Time — время раскрутки диска. Измеряется в миллисекундах т.е. в моём случае это 1.3 секунды. Чем меньше — тем лучше. Большие значения говорят о низкой отзывчивости;
Start_Stop_Count — количество циклом запуска/остановки шпинделя;
Reallocated_Sector_Ct — количество перераспределённых секторов. Большое значение говорит о большом количестве ошибок диска;
Seek_Error_Rate — количество ошибок позиционирования. Большое значение говорит о плохом состоянии диска;
Power_On_Hours — количество наработанных часов во включённом состоянии. По нему можно узнать сколько проработал диск во включённом состоянии. Довольно полезно, например, если покупать ноутбук с витрины и хочется узнать долго ли он там стоял;
Power_Cycle_Count — количество включений/выключений диска;
Spin_Retry_Count — количество попыток повторной раскрутки. Большое значение говорит о плохом состоянии диска;
Temperature_Celsius — температура диска в градусах Цельсия. При слишком высокой температуре диски могут быстрее выйти из строя;
Reallocated_Event_Count — количество операций перераспределения секторов;
Offline_Uncorrectable — количество неисправных секторов. Большое значение говорит о повреждённой поверхности.
Более наглядный графический способ: gnome-disk-utility
В графическом варианте и с описанием атрибутов, данные SMART представляет программа gnome-disk-utility . В русской локализации в меню она называется как «дисковая утилита». В английской локализации известна как «Disks».
Пример установки для дистрибутивов на основе Debian:
Запускаем программу. 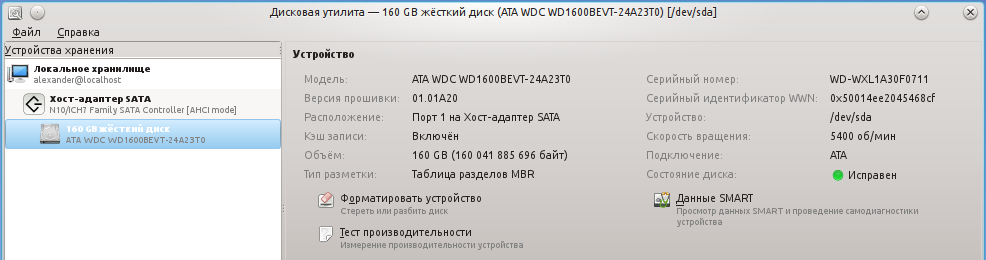
В поле «состояние диска» уже можно увидеть оценку состояния диска на основе данных S.M.A.R.T. Чтобы увидеть значение конкретных атрибутов нажимаем на кнопку «Данные SMART»: 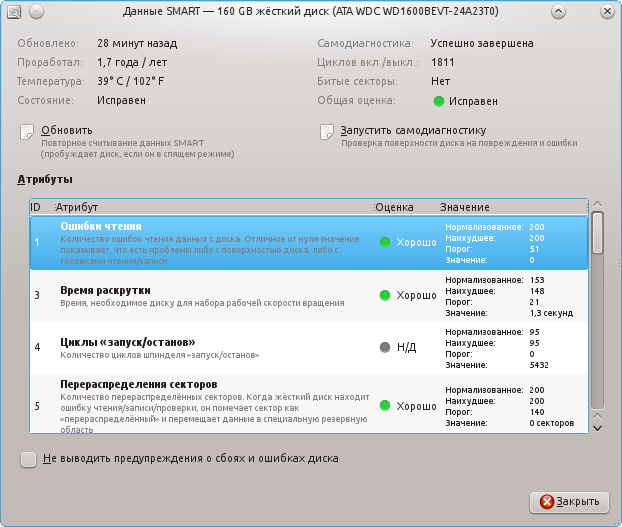
Пример данных о SSD (Твёрдотельном накопителе): 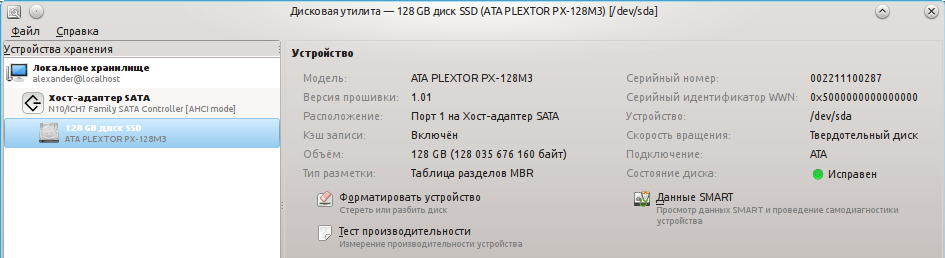
S.M.A.R.T.: 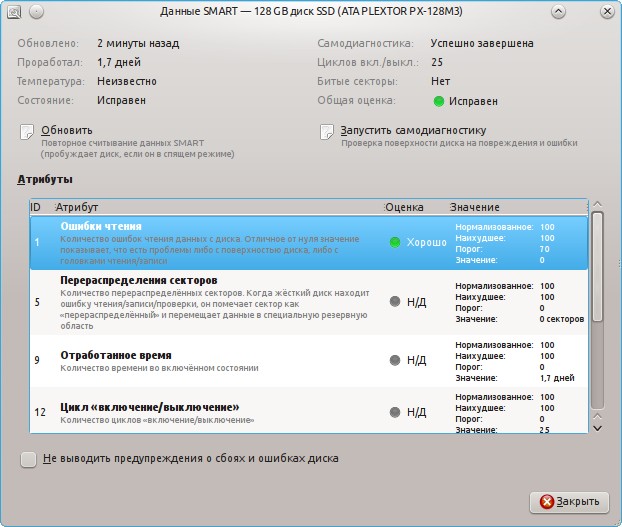
Здесь всё понятно и наглядно. Также присутствует описание атрибутов и оценка их показаний. Проблемные значения будут выделены красным цветом.
Источник
S.M.A.R.T.
S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) is a supplementary component built into many modern storage devices through which devices monitor, store, and analyze the health of their operation. Statistics are collected (temperature, number of reallocated sectors, seek errors. ) which software can use to measure the health of a device, predict possible device failure, and provide notifications on unsafe values.
Contents
Smartmontools
The smartmontools package contains two utility programs for analyzing and monitoring storage devices: smartctl and smartd . Install the smartmontools package to use these tools.
SMART support must be available and enabled on each storage device to effectively use these tools. You can use #smartctl to check for and enable SMART support. That done, you can manually #Run a test and #View test results, or you can use #smartd to automatically run tests and email notifications.
smartctl
smartctl is a command-line tool that «controls the Self-Monitoring, Analysis and Reporting Technology (SMART) system built into most ATA/SATA and SCSI/SAS hard drives and solid-state drives.»
The -i / —info option prints a variety of information about a device, including whether SMART is available and enabled:
If SMART is available but not enabled, you can enable it:
You may need to specify a device type. For example, specifying —device=ata tells smartctl that the device type is ATA, and this prevents smartctl from issuing SCSI commands to that device.
Run a test
There are three types of self-tests that a device can execute (all are safe to user data):
- Short: runs tests that have a high probability of detecting device problems,
- Extended or Long: the test is the same as the short check but with no time limit and with complete disk surface examination,
- Conveyance: identifies if damage incurred during transportation of the device.
The -c / —capabilities flag prints which tests a device supports and the approximate execution time of each test. For example:
Use -t / —test= flag to run a test:
View test results
You can view a device’s overall health with the -H flag. «If the device reports failing health status, this means either that the device has already failed, or that it is predicting its own failure within the next 24 hours. If this happens […] get your data off the disk and to someplace safe as soon as you can.»
You can also view a list of recent test results and detailed information about a device:
Generate table with attributes of all disks
![]() This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.
This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.![]()
smartd
The smartd daemon monitors SMART statuses and emits notifications when something goes wrong. It can be managed with systemd and configured using the /etc/smartd.conf configuration file. The configuration file syntax is esoteric, and this wiki page provides only a quick reference. For more complete information, read the examples and comments within the configuration file, or read smartd.conf(5) .
daemon management
To start the daemon, check its status, make it auto-start on system boot and read recent log file entries, simply start/enable the smartd.service systemd unit.
smartd respects all the usual systemctl and journalctl commands.
Define the devices to monitor
To monitor for all possible SMART errors on all disks, the following setting must be added in the configuration file.
Note this is the default smartd configuration and the -a parameter, which is the default parameter, may be omitted.
To monitor for all possible SMART errors on /dev/sda and /dev/sdb , and ignore all other devices:
To monitor for all possible SMART errors on externally connected disks (USB-backup disks spring to mind) it is prudent to tell smartd the UUID of the device since the /dev/sdX of the drive might change during a reboot.
First, you will have to get the UUID of the disk to monitor: ls -lah /dev/disk/by-uuid/ now look for the disk you want to Monitor
I know that my USB disk attached to /dev/sde during boot. Now to tell smartd to monitor that disk simply use the /dev/disk/by-uuid/ path.
Note that you may additionally need -d removable for smartd to work.
Now your USB disk will be monitored even if the /dev/sdX path changes during reboot.
Notifying potential problems
To have an email sent when a failure or new error occurs, use the -m option:
To be able to send the email externally (i.e. not to the root mail account) a MTA (Mail Transport Agent) or a MUA (Mail User Agent) will need to be installed and configured. Common MUAs are msmtp and Postfix, but perhaps the easiest dma will suffice. Common MTAs are sendmail and Postfix. It is enough to simply configure S-nail if you do not want anything else, but you will need to follow these instructions.
The -M test option causes a test email to be sent each time the smartd daemon starts:
Emails can take quite a while to be delivered. To make sure you are warned immediately if your hard drive fails, you may also define a script to be executed in addition to the email sending:
To send an email and a system notification, put something like this into /usr/local/bin/smartdnotify :
If you are running a desktop environment, you might also prefer having a popup to appear on your desktop. In this case, you can use this script (replace X_user and X_userid with the user and userid running X respectively) :
This requires libnotify and a compatible desktop environment. See Desktop notifications for more details.
You can also put your custom scripts into /usr/share/smartmontools/smartd_warning.d/ :
This scripts notifies every logged in users on the system via libnotify.
This script requires libnotify and procps-ng and a compatible desktop environment.
You can execute your custom scripts with
Power management
If you use a computer under control of power management, you should instruct smartd how to handle disks in low power mode. Usually, in response to SMART commands issued by smartd, the disk platters are spun up. So if this option is not used, then a disk which is in a low-power mode may be spun up and put into a higher-power mode when it is periodically polled by smartd.
On some devices the -n does not work. You get the following error message in syslog:
As an alternative, you can use the -i option of smartd. It controls how often smartd spins the disks up to check their status. Default is 30 minutes. To change it create and edit /etc/default/smartmontools .
For more info see smartd(8) .
Schedule self-tests
smartd can tell disks to perform self-tests on a schedule. The following /etc/smartd.conf configuration will start a short self-test every day between 2-3am, and an extended self test weekly on Saturdays between 3-4am:
Alert on temperature changes
smartd can track disk temperatures and alert if they rise too quickly or hit a high limit. The following will log changes of 4 degrees or more, log when temp reaches 35 degrees, and log/email a warning when temp reaches 40:
Complete smartd.conf example
Putting together all of the above gives the following example configuration:
- DEVICESCAN smartd scans for disks and monitors all it finds
- -a monitor all attributes
- -o on enable automatic offline data collection
- -S on enable automatic attribute autosave
- -n standby,q do not check if disk is in standby, and suppress log message to that effect so as not to cause a write to disk
- -s . schedule short and long self-tests
- -W . monitor temperature
- -m . mail alerts
Console applications
- skdump — utility to monitor and manage SMART devices to monitor and report hard disk drive health.
http://0pointer.de/blog/projects/being-smart.html || libatasmart
iostat -x (from sysstat ) also provides some disk health metrics: in particular, high values in the f_await column mean that the disk does not respond quickly to requests, and might be failing.
Источник
Оценка технического состояния жестких дисков с использованием технологии S.M.A.R.T
Общие сведения о технологии S.M.A.R.T
Современные жесткие диски довольно “умные” устройства и, кроме основных присущих им как устройствам хранения и обработки данных свойств, поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. ( S elf- M onitoring A nalysis a nd R eporting T echnology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков (HDD). В последующие годы стандарты S.M.A.R.T дорабатывались в соответствии с изменениями технологий и оборудования ( SMART II и SMART III) и продолжают совершенствоваться в настоящее время.
Жесткий диск, начиная с момента его изготовления, постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках — атрибутах (Attribute), сохраняющихся в постоянном запоминающем устройстве , как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя — служебной зоне . Данные атрибутов могут быть считаны, в соответствии со спецификацией ATA ( AT Attachment ) по командам поддержки SMART (SMART READ DATA и еще более десятка команд), которые передаются в накопитель специальным программным обеспечением, как например, утилитами от производителей оборудования или универсальными программами тестирования и мониторинга состояния HDD (udisks, smartctl, GSmartControl, gnome-disks и т.п.). Современные стандарты ATA включают в себя поддержку протокола SCT (SMART Command Transport), обеспечивающего считывание журналов статистики устройства. Журнал статистики устройства — это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG.
Атрибут представляет собой характеристику определенного состояния жесткого диска, которая изменяется в процессе эксплуатации, принимая числовое значение от максимального, установленного в момент изготовления данного устройства, до минимального, при достижении которого, работоспособность накопителя не гарантируется. Все атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется жесткими дисками разных моделей. Некоторые из них могут использоваться только конкретным производителем оборудования, и поддерживаться отдельными моделями накопителей. Так, например, атрибут с идентификатором 7 , характеризующий количество ошибок установки головок на требуемую дорожку поверхности диска Seek_Error_Rate не имеет смысла для твердотельных дисков ( SSD ) и, соответственно, не поддерживается ими, а атрибут с идентификатором 9 ,характеризующий суммарное время работы накопителя за весь срок эксплуатации и обозначаемый как Power_On_Hours ,поддерживается как SSD, так и традиционными HDD.
Атрибуты состоят из нескольких полей, ( наиболее часто обозначаемых как Val, Worst, Tresh, RAW ), каждое из которых является определенным показателем, характеризующим техническое состояние накопителя на данный момент времени. Программы считывания S.M.A.R.T. выводят содержимое атрибутов, как правило, в виде нескольких колонок :
ID# — числовой идентификатор атрибута
Attribute — название атрибута
Flags — флаги атрибутов, задаваемые производителем HDD. Характеризуют тип атрибута ( большинство программ интерпретируют флаги в виде символов k,c,r,s,o,p или аббревиатур, например, EC – Event Count, счетчик событий ).
Pre-Failure (PF, 01h) — при достижении порогового значения данного типа атрибутов диск требует замены. Иногда данный бит флагов обозначают как Life Critical (CR) или Pre-Failure warranty (PW)
O nline test (OC, 02h)– атрибут обновляет значение при выполнении off-line/on-line встроенных тестов SMART;
P erfomance R elated (PE или PR , 04h)– атрибут характеризует производительность ;
E rror R ate (ER , 08h )– атрибут отражает счетчики ошибок оборудования;
E vent C ounts (EC, 10h ) – атрибут представляет собой счетчик событий;
S elf P reserving (SP, 20h ) – самосохраняющися атрибут;
Некоторые из программ могут интерпретировать флаги в виде текстовых описаний, близких по смыслу к рассмотренным выше. Один атрибут может иметь несколько установленных в единицу значений флагов, например, атрибут с идентификатором 05 отражающий количество переназначенных из-за сбоев секторов из резервной области, имеет установленные флаги SP+EC+OC – самосохраняющийся, счетчик событий, обновляется при автономном и интерактивном режиме накопителя.
Value — текущее значение атрибута
Threshold — минимальное пороговое значения атрибута
Worst — самое худшее значение атрибута за все время работы накопителя
Raw — абсолютное значение атрибута
Type — некоторые из программ в данном необязательном поле отображают информацию из флажков атрибутов или признаки их критичности ( Critical или Pre-Fail , отражающих ухудшение характеристик оборудования, и Old-age для атрибутов, отражающих выработку ресурса);
Для анализа состояния накопителя, пожалуй самым важным значением атрибута является Value — условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров. Для каждого атрибута существует пороговое значение, при достижения которого, производитель не гарантирует его работоспособность — поле Threshold . Если значение Value приближается или становится меньше значения Threshold , — накопитель пора менять.
Перечень атрибутов и их значения жестко не стандартизированы и некоторые из них могут определяться изготовителем накопителя, но основная часть интерпретируются одинаково. Например, атрибут с идентификатором 05 ( Reallocated sector count ) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, как для устройств производства компании Seagate Technology, так и для устройств производства Western Digital . Набор поддерживаемых атрибутов зависит от модели накопителя и может значительно отличаться по составу для разных моделей.
smartctl — программное средство для управления S.M.A.R.T
Наиболее распространенным программным средством для получения данных S.M.A.R.T в среде Linux, является утилита smartctl из комплекта smartmontools , как правило, входящего в состав устанавливаемого по умолчанию программного обеспечения любого дистрибутива. При необходимости, обновить версию, а также скачать документацию на английском языке можно на сайте проекта smartmontools.org.
Для работы с утилитой smartctl требуются права суперпользователя root .
Формат командной строки smartctl :
smartctl параметры устройство
Примеры использования smartctl
smartctl –help или smartctl —usage — отобразить подсказку об использовании команды.
-V, —version, —copyright, —license — отобразить версию, информацию копирайта и лицензии.
-i, —info — отобразить идентификационную информацию для устройства.
-g NAME, —get=NAME — отобразить параметры настроек диска ( all, aam, apm, lookahead, security, wcache, rcache, wcreorder)
-a, —all — отобразить все данные SMART указанного диска.
-x, —xall — отобразить все технические данные для указанного диска.
—scan — выполнить поиск дисковых устройств.
-q TYPE, —quietmode=TYPE установить режим детализации вывода для smartctl ( errorsonly, silent, noserial)
-d TYPE, —device=TYPE — установить тип устройства (ata, scsi, sat[,auto][,N][+TYPE], usbcypress[,X], usbjmicron[,p][,x][,N], usbsunplus, marvell, areca,N/E, 3ware,N, hpt,L/M/N, megaraid,N, cciss,N, auto, test) Обычно установка типа устройства требуется в тех случаях, когда утилита smartctl не может определить его автоматически.
-b TYPE, —badsum=TYPE — задать реакцию на обнаружение ошибок контрольных сумм ( warn, exit, ignore)
-r TYPE, —report=TYPE — опция предназначена для разработчиков smartmontools и позволяет получить детализированную информацию при выполнении транзакций функции управления устройствами ввода/вывода ioctl ( ioctl, ataioctl, scsiioctl и уровень отладки). Подробности — man smartctl
-n MODE, —nocheck=MODE — режим запрета на выполнение тестов для режимов энергосбережения ( never, sleep, standby, idle ). Обычно используется для предотвращения запуска шпиндельного двигателя по команде smartctl.
-s VALUE, —smart=VALUE — отключение или включение SMART (on/off)
-o VALUE, —offlineauto=VALUE — запрет или разрешение автоматического выполнения тестов в неинтерактивном режиме ( в режиме простоя накопителя), принимаемые значения — on/off
-S VALUE, —saveauto=VALUE автосохранение атрибутов (on/off)
-s NAME[,VALUE], —set=NAME[,VALUE] — запрет/разрешение параметров оборудования накопителя ( aam,[N|off], apm,[N|off], lookahead,[on|off], security-freeze, standby,[N|off|now], wcache,[on|off], rcache,[on|off], wcreorder,[on|off])
-H, —health — отобразить состояние накопителя ( SMART health status)
-c, —capabilities — отобразить информацию о поддерживаемых возможностях SMART указанного жесткого диска.
-A, —attributes — отобразить атрибуты SMART
-f FORMAT, —format=FORMAT — задать формат отображаемых атрибутов SMART ( old, brief, hex[,id|val]). В основном, влияет на формат отображаемых значений идентификаторов атрибутов и формат отображения их флагов:
old — идентификаторы атрибутов выводятся в десятичной системе счисления, значения флагов отображаются в шестнадцатеричной и интерпретируются в виде текста.
hex — то же, что и в предыдущем случае, но идентификаторы атрибутов отображаются в шестнадцатеричной системе счисления.
brief — компактный вывод, идентификаторы отображаются в десятичной системе счисления, флаги отображаются в виде символов с расшифровкой в нижней части таблицы:
-l TYPE, —log=TYPE — отобразить указанный журнал устройства ( selftest, selective, directory[,g|s], xerror[,N][,error], xselftest[,N][,selftest],background, sasphy[,reset], sataphy[,reset], scttemp[sts,hist], scttempint,N[,p], scterc[,N,M], devstat[,N], ssd, gplog,N[,RANGE], smartlog,N[,RANGE]
-v N,OPTION , —vendorattribute=N,OPTION — установить параметр для определенного производителем атрибута с идентификатором N
-F TYPE, —firmwarebug=TYPE — адаптация программы для учета ошибок в аппаратной прошивке накопителя ( none, nologdir, samsung, samsung2, samsung3, xerrorlba, swapid)
-P TYPE, —presets=TYPE — предустановки параметров диска. По умолчанию, обнаружив информацию о накопителе в своей базе, утилита smartctl , использует набор параметров, доступный для данной модели. Опция use — использовать предустановки для данного накопителя, ignore — не использовать, show — отобразить предустановки для данного диска, showall — отобразить предустановки для указанной модели. Примеры:
smartctl –P ignore /dev/hdb — игнорировать предустановки для диска /dev/hdb;
smartctl –P show /dev/sdb — отобразить предустановки для указанного диска;
smartctl –P showall ‘ST9250315AS’ — — отобразить предустановки для указанной модели диска — ST9250315AS;
smartctl –P showall ‘ST3750515AS’ ‘SD15’ — отобразить предустановки для указанной модели диска ST3750515AS с прошивкой SD15;
-B [+]FILE, —drivedb=[+]FILE — прочитать и изменить базу данных моделей дисков из файла FILE. Знак “+” перед именем файла, означает добавление новых записей в базу, перед уже существующими.
По умолчанию, база данных хранится в файле /usr/share/smartmontools/drivedb.h
===== DEVICE SELF-TEST OPTIONS =====
-t TEST, —test=TEST — запустить выполнение теста TEST Run test. TEST: offline, short, long, conveyance, force, vendor,N, select,M-N, pending,N, afterselect,[on|off]
-C, —captive — выполнение тестов в режиме захвата накопителя. Используется совместно с параметром -t для тестов не в режиме offline . Использование данного параметра может вызвать занятость устройства на все время выполнения теста и привести к нарушению работы системы и потере данных. Не стоит использовать опцию -c для выполнения тестов накопителей с монтированными разделами. Для SCSI устройств данная опция означает выполнение встроенных тестов в режиме «Foreground mode» .
-X, —abort — принудительно завершить тест, выполняющийся без ключа —captive .
Примеры использования smartctrl.
smartctl —info /dev/sdb — отобразить идентификационную информацию для устройства /dev/sdb. Пример вывода команды:
smartctl —all /dev/hdа — отобразить все данные SMART для устройства /dev/hda
Пример отображаемых данных:
smartctl -A -v 9,minutes /dev/hda — отобразить все данные атрибутов SMART для устройства /dev/hda и атрибут с идентификатором 9 ( время нахождения во включенном состоянии) интерпретировать как внутреннее значение, задаваемое в минутах, а не в часах.
smartctl —smart=on —offlineauto=on —saveauto=on /dev/hda — включить SMART для диска /dev/hda, разрешить автоматическое выполнение оффлайн-тестов и самосохранение атрибутов. Команду можно выполнять на работающей системе. Фактически, это установка стандартных параметров эксплуатации для обычного дискового накопителя.
smartctl —test=long /dev/hda — выполнить расширенные встроенные тесты для диска /dev/hda.Команду можно использовать на работающей системе. Для просмотра результатов выполнения тестов используется команда вывода внутреннего журнала после завершения теста
smartctl -l selftest /dev/hda
smartctl —attributes —log=selftest —quietmode=errorsonly /dev/had — отобразить данные внутреннего журнала самотестирования и атрибуты ошибок.
smartctl -s on -t offline /dev/hdc — включить SMART и выполнить оффлайн-тест для диска /dev/hdc. Если при тестировании будет обнаружена ошибка, то информация по ней будет записана во внутренний журнал, просмотреть который можно с использованием параметра -l error .
smartctl -q silent -a /dev/had — проверить данные SMART без вывода полученной информации.Обычно используется в скриптах. После выполнения команды проверяется код возврата (переменная $? командной оболочки)для определения факта выхода значения какого – либо атрибута за предельную величину или наличия записи об ошибках в журналах устройства.
smartctl -q errorsonly -H -l selftest /dev/had — выводить информацию только при наличии ошибочного состояния SMART или если какой-либо из внутренних тестов завершился с ошибкой.
smartctl -t select,10-100 -t select,30-300 -t afterselect,on -t pending,45 /dev/hda — выполнить внутренний тест в заданной области блоков LBA и после его завершения сканировать оставшуюся часть диска. Если при сканировании будет выполнено выключение питания, то продолжить его через 45 минут после включения.
smartctl —all —device=3ware,0 /dev/sda — получить данные SMART для первого ATA-диска, подключенного к RAID контроллеру 3ware.
smartctl -a -d 3ware,0 /dev/twe0 — получить данные SMART для первого ATA-диска, подключенного к RAID контроллеру 3ware RAID 6000/7000/8000.
smartctl -a -d 3ware,0 /dev/twa0 — получить данные SMART для первого ATA-диска, подключенного к RAID контроллеру 3ware RAID 9000
smartctl -t short -d 3ware,3 /dev/sdb — запустить выполнение коротких внутренних тестов для 4-го диска, второго дискового SCSI устройства /dev/sdb
smartctl -a -d hpt,1/3 /dev/sda — получить данные SMART диска, подключенного к 3-му каналу первого контроллера HighPoint RocketRAID
Расшифровка атрибутов S.M.A.R.T
Идентификаторы атрибутов указаны в десятичной системе счисления, а в скобках они же – в шестнадцатеричной.
Оценка технического состояния жесткого диска по данным S.M.A.R.T
Набор атрибутов поддерживаемых конкретной моделью жесткого диска, даже если он минимален, позволяет с высокой достоверностью определить техническое состояние и перспективы эксплуатации устройства. Можно определить время нахождения во включенном состоянии по значению атрибута 9 , а в совокупности со значением атрибута 12 — количество включений /выключений электропитания, и следовательно, – круглосуточный или периодический режим эксплуатации. Интенсивность использования, температурный режим, негативные внешние воздействия – все эти факты легко отслеживаются по абсолютным значениям соответствующих атрибутов. Подобным же образом, можно оценить и уровень износа оборудования, качество поверхности и тракта записи/чтения.
Минимально информативный контроль состояния дисков может выполняться даже на уровне BIOS. В случае достижения критического значения любого атрибута, характеризующего работоспособность, при включенном мониторинге состояния S.M.A.R.T в настройках BIOS, загрузка операционной системы приостанавливается и на экран выводится сообщение:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Press F1 to Resume
Таким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить факт критического состояния накопителя средствами Базовой Системы Ввода-Вывода (BIOS) при включении компьютера.
Техническое состояние жесткого диска, не достигшее критического порога, характеризуется абсолютным значением атрибутов, отражающих счетчики сбоев, обнаруженных и исправленных оборудованием накопителя.
Изменение абсолютных значений атрибутов нужно рассматривать в динамике, и в логической взаимосвязи друг с другом.
Выполнение встроенных тестов S.M.A.R.T
Набор встроенных тестов S.M.A.R.T определяется производителем и может значительно отличаться для разных моделей жестких дисков. В основном, встроенные тесты SMART представлены короткими тестами ( short self-test ) и длинными ( extended sels-test ). Короткие тесты выполняют сканирование небольшой части дисковой поверхности, определенной производителем, и выполняются, в среднем, около 1 минуты. Длинные тесты выполняют сканирование всей рабочей поверхности диска и могут выполняться, в зависимости от быстродействия и объема диска, даже несколько часов. Также, для современных дисков, можно выполнять селективные тесты ( selective self-test), параметры которых задаются пользователем и тесты после транспортировки устройства ( conveyance self-test). Выполнение тестов можно прервать, если не задан режим захвата накопителя ( captive ) и накопитель поддерживает команду отмены теста. Что касается режима захвата накопителя при выполнении тестов captive , то пользоваться им нужно осторожно, если диск используется системой.
smartctl —test=short /dev/sdb — запустить короткий тест. В ответ на команду, будет выведена информация:
Что означает, что диску отправлена команда на выполнение короткого теста, диск ее воспринял успешно, тест будет продолжаться 1 минуту, и для принудительного его прекращения можно воспользоваться командой smartctl –X.
Результат выполнения теста можно проверить, просмотрев журнал тестов командой smartctl –l selftest . В ответ будет получена информация журнала selftest :
Колонки журнала: Num — номер записи.
Test_Description — описание теста.
Status — статус завершения ( выполнен без ошибок)
Remaining — процент оставшегося времени до завершения теста, если он еще не завершен ( 00% )
LifeTime(hours) — время работы накопителя с начала эксплуатации.
LBA_of_first_error — номер логического блока LBA где обнаружена первая ошибка при выполнении теста. В данном примере, ошибок нет.
Для запуска длинного теста используется команда:
smartctl —test=long /dev/sdb
В ответ на команду выводится информация о начале теста:
Как видно, длинный тест для данной модели накопителя будет выполняться 70 минут.
Результат выполнения можно проверить командой smartctl –l selftest /dev/sda
Список команд ATA для работы с S.M.A.R.T
Дополнительно по теме оборудования в Linux:
Если вы желаете помочь развитию проекта, можете воспользоваться кнопкой «Поделиться» для своей социальной сети
Источник



