- Использование smartctl для проверки RAID контроллеров Adaptec под Linux
- Распознает ли Linux контроллер Adaptec RAID?
- Загрузка и установка Adaptec Storage Manager для Linux
- Проверяем состояния SATA диска
- Использование Adaptec Storage Manager
- Работа с mdadm в Linux для организации RAID
- Установка mdadm
- Сборка RAID
- Подготовка носителей
- Создание рейда
- Создание файла mdadm.conf
- Создание файловой системы и монтирование массива
- Информация о RAID
- Настройка мониторинга RAID LSI MegaRaid на Linux с помощью Zabbix
- Установка megacli
- CentOS
- Ubuntu
- Использование megacli
- Скрипты для получения состояния дисков
- UserParameter для агента Zabbix
- Настройка сервера Zabbix
- Создание шаблона
- Применение шаблона
Использование smartctl для проверки RAID контроллеров Adaptec под Linux
Команду «smartctl -d ata -a /dev/sdb» можно использовать для проверки жесткого диска и текущего состояния его соединения с системой. Но как с помощью команд smartctl проверить SAS или SCSI диски, спрятанные за RAID контроллером Adaptec в системах под управлением Linux ОС? Для этого необходимо использовать последовательные синтаксисы проверки SAS или SATA. Как правило — это логические диски для каждого массива физических накопителей в операционной системы. Команду /dev/sgX возможно использовать в качестве перехода через контроллеры ввода/вывода, которые обеспечиваюь прямой доступ к каждому физическому диску, подключенному к RAID контроллеру Adaptec.

Распознает ли Linux контроллер Adaptec RAID?
Для проверки Вы можете использовать следующую команду:
В результате выполнения команды получите следующее:
Загрузка и установка Adaptec Storage Manager для Linux
Необходимо установить Adaptec Storage Manager в соответсвии собранному дисковому массиву.
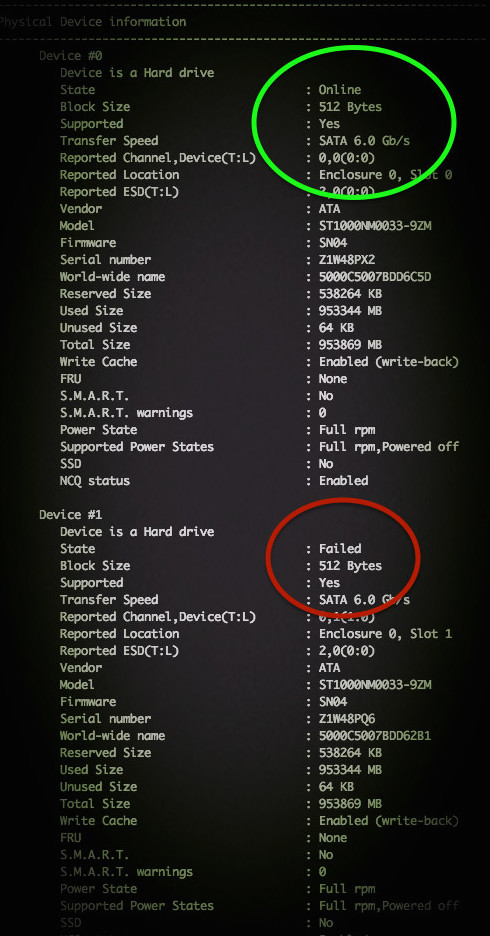
Проверяем состояния SATA диска
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg <1,2,3,4>. Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
В результате получим что то похожее на:
А вот команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Проверить жесткий диск можно с помощью следующих команд:
Использование Adaptec Storage Manager
Другие простые команды для проверки базового состояния выглядят следующим образом:
Обратите внимание на то, что более новая версия arcconf расположена в архиве /usr/Adaptec_Event_Monitor. Таким образом, весь путь должен выглядеть так:
Вы можете самостоятельно проверить состояние массива Adaptec RAID на Linux с помощью ввода простой команды:
# /usr/Adaptec_Event_Monitor/arcconf getconfig 1
Или (более поздняя версия):
Примерный результат на фото:
По традиции, немного рекламы в подвале, где она никому не помешает. Напоминаем, что в связи с тем, что общая емкость сети нидерландского дата-центра, в котором мы предоставляем услуги, достигла значения 5 Тбит / с (58 точек присутствия, включения в 36 точек обмена, более, чем в 20 странах и 4213 пиринговых включений), мы предлагаем выделенные серверы в аренду по невероятно низким ценам, только неделю!.
Источник
Работа с mdadm в Linux для организации RAID
mdadm — утилита для работы с программными RAID-массивами различных уровней. В данной инструкции рассмотрим примеры ее использования.
Установка mdadm
Утилита mdadm может быть установлена одной командой.
Если используем CentOS / Red Hat:
yum install mdadm
Если используем Ubuntu / Debian:
apt-get install mdadm
Сборка RAID
Перед сборкой, стоит подготовить наши носители. Затем можно приступать к созданию рейд-массива.
Подготовка носителей
Сначала необходимо занулить суперблоки на дисках, которые мы будем использовать для построения RAID (если диски ранее использовались, их суперблоки могут содержать служебную информацию о других RAID):
mdadm —zero-superblock —force /dev/sd
* в данном примере мы зануляем суперблоки для дисков sdb и sdc.
Если мы получили ответ:
mdadm: Unrecognised md component device — /dev/sdb
mdadm: Unrecognised md component device — /dev/sdc
. то значит, что диски не использовались ранее для RAID. Просто продолжаем настройку.
Далее нужно удалить старые метаданные и подпись на дисках:
wipefs —all —force /dev/sd
Создание рейда
Для сборки избыточного массива применяем следующую команду:
mdadm —create —verbose /dev/md0 -l 1 -n 2 /dev/sd
- /dev/md0 — устройство RAID, которое появится после сборки;
- -l 1 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd — сборка выполняется из дисков sdb и sdc.
Мы должны увидеть что-то на подобие:
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store ‘/boot’ on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
—metadata=0.90
mdadm: size set to 1046528K
Также система задаст контрольный вопрос, хотим ли мы продолжить и создать RAID — нужно ответить y:
Continue creating array? y
Мы увидим что-то на подобие:
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
. и находим информацию о том, что у наших дисков sdb и sdc появился раздел md0, например:
.
sdb 8:16 0 2G 0 disk
??md0 9:0 0 2G 0 raid1
sdc 8:32 0 2G 0 disk
??md0 9:0 0 2G 0 raid1
.
* в примере мы видим собранный raid1 из дисков sdb и sdc.
Создание файла mdadm.conf
В файле mdadm.conf находится информация о RAID-массивах и компонентах, которые в них входят. Для его создания выполняем следующие команды:
echo «DEVICE partitions» > /etc/mdadm/mdadm.conf
mdadm —detail —scan —verbose | awk ‘/ARRAY/
DEVICE partitions
ARRAY /dev/md0 level=raid1 num-devices=2 metadata=1.2 name=proxy.dmosk.local:0 UUID=411f9848:0fae25f9:85736344:ff18e41d
* в данном примере хранится информация о массиве /dev/md0 — его уровень 1, он собирается из 2-х дисков.
Создание файловой системы и монтирование массива
Создание файловой системы для массива выполняется также, как для раздела:
* данной командой мы создаем на md0 файловую систему ext4.
Примонтировать раздел можно командой:
mount /dev/md0 /mnt
* в данном случае мы примонтировали наш массив в каталог /mnt.
Чтобы данный раздел также монтировался при загрузке системы, добавляем в fstab следующее:
/dev/md0 /mnt ext4 defaults 1 2
Для проверки правильности fstab, вводим:
Мы должны увидеть примонтированный раздел md, например:
/dev/md0 990M 2,6M 921M 1% /mnt
Информация о RAID
Посмотреть состояние всех RAID можно командой:
В ответ мы получим что-то на подобие:
md0 : active raid1 sdc[1] sdb[0]
1046528 blocks super 1.2 [2/2] [UU]
* где md0 — имя RAID устройства; raid1 sdc[1] sdb[0] — уровень избыточности и из каких дисков собран; 1046528 blocks — размер массива; [2/2] [UU] — количество юнитов, которые на данный момент используются.
** мы можем увидеть строку md0 : active(auto-read-only) — это означает, что после монтирования массива, он не использовался для записи.
Подробную информацию о конкретном массиве можно посмотреть командой:
* где /dev/md0 — имя RAID устройства.
Version : 1.2
Creation Time : Wed Mar 6 09:41:06 2019
Raid Level : raid1
Array Size : 1046528 (1022.00 MiB 1071.64 MB)
Used Dev Size : 1046528 (1022.00 MiB 1071.64 MB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Wed Mar 6 09:41:26 2019
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : proxy.dmosk.local:0 (local to host proxy.dmosk.local)
UUID : 304ad447:a04cda4a:90457d04:d9a4e884
Events : 17
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
- Version — версия метаданных.
- Creation Time — дата в время создания массива.
- Raid Level — уровень RAID.
- Array Size — объем дискового пространства для RAID.
- Used Dev Size — используемый объем для устройств. Для каждого уровня будет индивидуальный расчет: RAID1 — равен половине общего размера дисков, RAID5 — равен размеру, используемому для контроля четности.
- Raid Devices — количество используемых устройств для RAID.
- Total Devices — количество добавленных в RAID устройств.
- Update Time — дата и время последнего изменения массива.
- State — текущее состояние. clean — все в порядке.
- Active Devices — количество работающих в массиве устройств.
- Working Devices — количество добавленных в массив устройств в рабочем состоянии.
- Failed Devices — количество сбойных устройств.
- Spare Devices — количество запасных устройств.
- Consistency Policy — политика согласованности активного массива (при неожиданном сбое). По умолчанию используется resync — полная ресинхронизация после восстановления. Также могут быть bitmap, journal, ppl.
- Name — имя компьютера.
- UUID — идентификатор для массива.
- Events — количество событий обновления.
- Chunk Size (для RAID5) — размер блока в килобайтах, который пишется на разные диски.
Подробнее про каждый параметр можно прочитать в мануале для mdadm:
Также, информацию о разделах и дисковом пространстве массива можно посмотреть командой fdisk:
Источник
Настройка мониторинга RAID LSI MegaRaid на Linux с помощью Zabbix
Разберем ситуацию, при которой нам нужно узнать состояние дискового RAID-массива, затем настроить мониторинг данного состояния сервером Zabbix. В качестве операционной системы, под управлением которой работает компьютер с LSI MegaRaid будем использовать Linux.
Установка megacli
Смотреть состояние массива RAID будем с помощью фирменной утилиты megacli.
Для начала, проверим, что на сервере используется контроллер LSI MegaRaid:
lspci -nn | grep -i lsi
02:00.0 RAID bus controller [0104]: LSI Logic / Symbios Logic MegaRAID SAS 2108 [Liberator] [1000:0079] (rev 05)
Разберем процесс установка утилиты на Linux CentOS и Ubuntu.
CentOS
Устанавливаем пакеты для распаковки архивов и загрузки файлов:
yum install unzip wget
Переходим по ссылке download.hetzner.de/tools/LSI/tools/MegaCLI — логин hetzner и пароль download. В открывшемся окне копируем ссылку на нужную версию утилиты, например:

С помощью ссылки скачиваем утилиту на компьютер, на котором будет мониторить состояние контроллера:
wget —user hetzner —password download https://download.hetzner.de/tools/LSI/tools/MegaCLI/8.07.10_MegaCLI_Linux.zip
* в данном примере мы загружаем MegaCLI версии 8.07.10 для Linux. Для прохождения авторизации используем логин и пароль hetzner/download.
* если система вернет ошибку при выполнении команды, устанавливаем wget командой yum install wget.
Распаковываем скачанный архив:
rpm -i 8.07.10_MegaCLI_Linux/Linux\ MegaCLI\ 8.07.10/MegaCli-8.07.10-1.noarch.rpm
* напомню, в данном примере устанавливаем версию 8.07.10.
Создаем ссылку на бинарник:
ln -s /opt/MegaRAID/MegaCli/MegaCli64 /usr/bin/megacli
Проверяем, что утилита работает:
Мы должны получить версию установленного пакета.
Ubuntu
Открываем настройки репозитория:
В самый низ добавляем:
deb http://hwraid.le-vert.net/ubuntu xenial main
* где xenial — выпуск Ubuntu (можно посмотреть командой lsb_release -a).
Обновляем список пакетов:
И устанавливаем megacli:
apt-get install megacli
Проверяем, что утилита работает:
Мы должны получить версию установленного пакета.
Использование megacli
Для работы нам могут быть полезны следующие команды.
1. Посмотреть модели контролера и версию прошивки:
megacli -AdpAllInfo -aAll | grep -E ‘Product Name|Serial No|FW Package Build’
Product Name : RAID Ctrl SAS 6G 5/6 512MB (D2616)
Serial No :
FW Package Build : 12.12.0-0174
2. Состояние дисков:
megacli -PDList -Aall
Enclosure Device ID: 252
Slot Number: 0
Drive’s position: DiskGroup: 2, Span: 0, Arm: 0
Enclosure position: N/A
Device Id: 2
WWN: 50014ee2662dd189
Sequence Number: 2
Media Error Count: 0
Other Error Count: 0
Predictive Failure Count: 0
Last Predictive Failure Event Seq Number: 0
PD Type: SATA
Raw Size: 931.512 GB [0x74706db0 Sectors]
Non Coerced Size: 931.012 GB [0x74606db0 Sectors]
Coerced Size: 931.0 GB [0x74600000 Sectors]
Sector Size: 0
Logical Sector Size: 0
Physical Sector Size: 0
Firmware state: Online, Spun Up
Device Firmware Level: 1A02
Shield Counter: 0
Successful diagnostics completion on : N/A
SAS Address(0): 0x4433221103000000
Connected Port Number: 1(path0)
Inquiry Data: WD-WCC6Y1NURJ0VWDC WD10EZEX-08WN4A0 02.01A 02
FDE Capable: Not Capable
FDE Enable: Disable
Secured: Unsecured
Locked: Unlocked
Needs EKM Attention: No
Foreign State: None
Device Speed: 6.0Gb/s
Link Speed: 6.0Gb/s
Media Type: Hard Disk Device
Drive: Not Certified
Drive Temperature :30C (86.00 F)
PI Eligibility: No
Drive is formatted for PI information: No
PI: No PI
Port-0 :
Port status: Active
Port’s Linkspeed: 6.0Gb/s
Drive has flagged a S.M.A.R.T alert : No
* в данном примере отображено состояние для одного диска. Нам могут быть полезны параметры Firmware state — показывает состояние диска; Drive has flagged a S.M.A.R.T alert — состояние SMART.
Скрипты для получения состояния дисков
В нашем примере мы напишем очень простой скрипт, который будет находить неправильное состояние диска. Если хотя бы один из носителей имеет тревоги по SMART или ошибки в состоянии, скрипт будет возвращать 1. Если проблем нет — 0. Сам скрипт будет написан на bash.
У меня не получилось сделать так, чтобы команда megacli нормально отрабатывала при запуске от zabbix агента, поэтому сам скрипт будет выполняться по крону и результат записывать в отдельный файл, который и будет читать агент заббикса.
Создаем каталог, в который поместим скрипт:
Создаем файл скрипта:
count_errors=`megacli -PDList -Aall | grep -e «S.M.A.R.T alert : Yes» -e «Firmware state: Fail» | wc -l`
if [ $count_errors -gt 0 ]
then
echo 1 > /scripts/scan_result
else
echo 0 > /scripts/scan_result
fi
* это простой скрипт, который получает состояние всех дисков и проверяет, нет ли среди этих состояний тревог от SMART и состояния Failed — результат записывается в переменную count_errors в виде количества найденных проблем. Если значение данной переменной больше 0 (то есть, есть хотя бы одно состояние сбоя), скрипт записывает в файл /scripts/scan_result «1», иначе — «0».
Разрешаем запуск скрипта на выполнение:
chmod +x /scripts/raid_mon_cron.sh
Создадим задание в cron:
* в данном примере мы будем запускать наш скрипт по проверке состояние дисков каждые 5 минут.
Теперь создадим скрипт, который будет запускать zabbix-agent:
* обратите внимание, что скрипт создается в каталоге zabbix-агента. Если в нашей системе его нет, необходима установка — примеры установки для CentOS и Ubuntu.
* все, что делает скрипт — выводит содержимое файла /scripts/scan_result, в котором должно быть либо 0, либо 1.
Разрешаем запуск скрипта на выполнение и зададим владельца zabbix:
chmod 770 /etc/zabbix/zabbix_agentd.d/raid_mon.sh
chown zabbix:zabbix /etc/zabbix/zabbix_agentd.d/raid_mon.sh
Пробуем выполнить скрипты:
В зависимости от ситуации они вернут 0 или 1.
UserParameter для агента Zabbix
Запуск скрипта и передача результата его работы серверу мониторинга выполняется с помощью Zabbix-агента. Для этого необходимо настроить UserParameter.
Открываем настройки агента:
В самый низ добавляем строку:
* в данном случае, мы создаем в zabbix агенте пользовательский параметр с именем raid_mon — при его вызове будет запускаться скрипт /etc/zabbix/zabbix_agentd.d/raid_mon.sh, который мы ранее создали.
systemctl restart zabbix-agent
Если используется SELinux, отключаем его:
sed -i ‘s/^SELINUX=.*/SELINUX=disabled/g’ /etc/selinux/config
Проверяем работу параметра. Для этого с сервера zabbix выполняем команду:
zabbix_get -s 192.168.0.15 -k raid_mon
* в данном примере мы обращаемся к серверу 192.168.0.15 и запускаем пользовательский параметр raid_mon.
В итоге, мы должны получить такой же ответ, который получили, запустив скрипт локально с компьютера, на котором его создали.
Настройка сервера Zabbix
На сервере zabbix необходимо создать шаблон для сканирования дисков с триггером для получения данных от агента на сервере и в случае 1 выводить тревогу. После необходимо добавить данный шаблон для всех узлов, на которых необходим мониторинг дисков.
Создание шаблона
Открываем веб-панель управления Zabbix. Выполним ряд шагов для достижения цели.
1. Переходим в Настройка — Шаблоны:

Справа сверху кликаем по Создать шаблон:

В открывшемся окне называем шаблон, например, Template Scan RAID — добавляем его в группы, например Linux Servers и Windows Servers (нам никто не мешает также сканировать диски на серверах Windows):

Кликаем по Добавить. Будет создан шаблон.
2. В списке шаблонов находим свой и кликаем для его настройки:

Переходим в Группы элементов данных:

Кликаем по Создать группу элементов данных:

Даем название для группы, например, RAID:

. и кликаем по Добавить. Группа элементов создана.
3. Переходим на вкладку Элементы данных и кликаем по Создать элементы данных:

В открывшемся окне даем название для элемента, например, RAID: Status Monitoring — прописываем ключ raid_mon (тот, что задали в UserParameter) — ставим интервал обновления в 5 минут (так как в кроне мы сканируем состояние каждые 5 минут, проверять чаще нет смысла) — выбираем созданную ранее группу элементов данных (RAID):

. и кликаем по Добавить. Элемент данных добавлен.
4. Создаем триггер — для этого переходим на вкладку Триггеры — кликаем по Создать триггер:

Даем название для триггера, например, RAID: Status Error — меняем значение для важности, например, на Высокая — задаем выражение =1 (триггер должен реагировать на значение равное 1):

Нажимаем Добавить.
Шаблон готов и настроен.
Применение шаблона
Теперь можно применить наш шаблон к узлу. Переходим в Настройка — Узлы сети — выбираем узел, на котором создан скрипт для мониторинга дисков — переходим на вкладку Шаблоны и добавляем созданный нами шаблон:

Нажимаем Обновить.
Мониторинг состояния дисков настроен. При возникновении критического состояния мы увидим проблему «RAID: Status Error».
Источник



