- Отслеживание состояния сети в Linux – команда netstat
- Синтаксис и опции netstat
- Контроль сетевых соединений
- Посмотреть сетевые соединения
- Идентификация сетевых процессов
- Получение статистики для различных сетевых протоколов
- Мониторинг сетевого стека linux
- Netlink
- Считаем соединения
- Разбивка по IP
- Детализация рулит
- TCP backlog
- Счетчики и ошибки протоколов
- TCP ретрансмиты
- Conntrack
- Вместо заключения
Отслеживание состояния сети в Linux – команда netstat
Для получения сведений об активности и статистике сетевых соединений (интерфейсов) существует масса удобных мониторинговых приложений с графическим пользовательским интерфейсом, всевозможных виджетов и т. д. Однако, все эти решения построены на основе стандартных утилит, входящих в состав практически любой Linux- или UNIX-ориентированной системы. Для администрирования серверов на базе системы Linux такие стандартные утилиты являются достаточно исчерпывающим инструментом для получения информации о работе сети. Одной из таких является команда netstat. С помощью неё можно получить вывод с информацией о состоянии сетевого программного обеспечения, статистику сети, сведения о маршрутизации и т.д.
Синтаксис и опции netstat
| -a | Показывать состояние всех сокетов; |
| -o | Показывать таймен |
| -i | Показывает состояние сетевых интерфейсов |
| -n | Показывать ip адрес, а не сетевое имя |
| -r | Показать таблицы маршрутизации. При использовании с опцией -s показывает статистику маршрутизации. |
| -s | Показать статистическую информацию по протоколам. При использовании с опцией -r показывает статистику маршрутизации. |
| -f семейство_адресов | Ограничить показ статистики или адресов управляющих блоков только указанным семейством_адресов, в качестве которого можно указывать:inet Для семейства адресов AF_INET, или unix Для семейства адресов AF_UNIX. |
| -I интерфейс | Показывать информацию о конкретном интерфейсе. |
| -p | Отобразить идентификатор/название процесса, создавшего сокет (-p, —programs display PID/Program name for sockets) |
Ключи можно комбинировать. Самая распространенная команда использования netstat это:
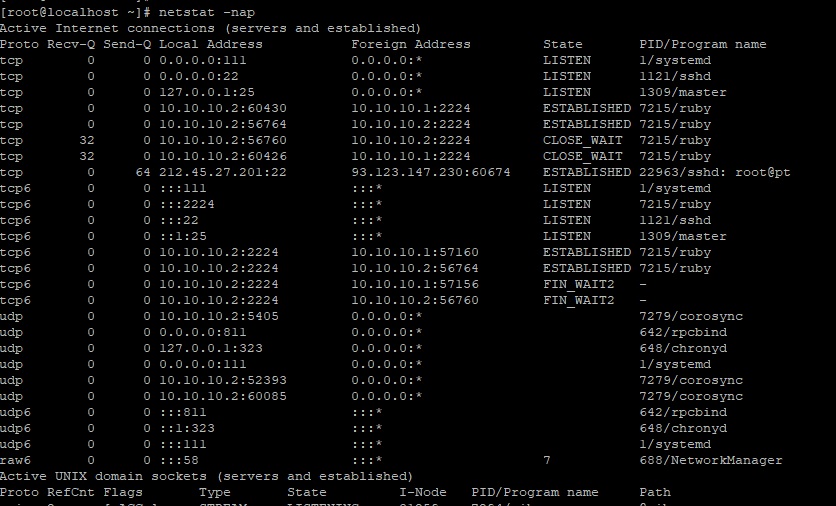
Эта команда выводит довольно большой список. Поэтому для получения нужной информации используйте grep. Например для получения всех портов которые слушаются в системе.

Контроль сетевых соединений
Используя опцию -i можно получить данные о состоянии сетевых интерфейсов системы, а также основных счётчиков трафика. Вывод предоставляется в виде наглядной таблицы с соответствующими столбцами. Формат самой таблицы зависит от используемой системы. К примеру, в Ubuntu, да и вообще в Debian-ориентированных системах он будет примерно таким:
В данном выводе видно, как ведёт себя интерфейс eno1, через который осуществляется соединение в сеть, а также что происходит с интерфейсом обратной связи lo. В столбцах RX/TX приводится статистика по трафику с указанием количества пакетов, в том числе и пакетов с ошибками. В частности, показатель RX свидетельствует о количестве пакетов, полученных интерфейсом, TX – о количестве пропущенных через этот интерфейс пакетов с момента загрузки системы или первичной активации (задействования) интерфейса.
Количество ошибок (RX-ERR, TX-ERR) как правило, не должно быть больше 1% (в некоторых случаях 5%) от общего числа пакетов. Если ошибок больше, то следует проанализировать этот параметр на других компьютерах. Большое количество ошибок в сети (на других компьютерах) свидетельствует о неполадках в окружении сети. На отдельном компьютере излишнее их (ошибок) количество говорит о неполадках с сетевым интерфейсом (сетевая карта) или с самим соединением (кабели, совместимость оборудования).
Посмотреть сетевые соединения
Если дать команду netstat без параметров, то будет выведен список процессов (демонов), для которых установлены сетевые соединения. Если нужно также получить информацию о процессах, которые активных соединений не имеют, но слушают порты, нужно использовать ключ -a:
Данный вывод включает в себя также и информацию о системных сокетах UNIX и UDP. Как видно, в представленном отчёте зафиксировано входящее SSH-соединение, два входящих соединения IMAPS, одно входящее HTTP-соединение, а также несколько портов, которые «слушают» (LISTEN) другие соединения. Адреса в данном выводе представлены в формате имя_хоста:служба, где в качестве службы может выступать порт. В колонках Recv-Q и Send-Q отображается количество запросов в очередях на приём и отправку на данном узле/компьютере. Следует также отметить, что факт установки соединения проверяется только для протокола TCP. Кроме описанных состояний соединений имеются также и некоторые другие:
- TIME_WAIT – ожидание на завершение соединения;
- SYN_SENT – попытка некоторого процесса установить соединение с недоступным ресурсом или сервером;
- SYN_WAIT – состояние, при котором данный узел не может обработать все поступающие запросы. Зачастую это может свидетельствовать об ограничении возможностей системного ядра, либо о попытках намеренно вызвать перегрузку на сервере.
Идентификация сетевых процессов
Для того, чтобы однозначно иметь представление о конкретных процессах или демонах, слушающих соединения (порты) в системе, следует воспользоваться ключами -l и -p. Первый позволяет выводить, собственно, только слушающие порты, второй — для идентификации процесса/демона, например:
Как можно видеть, в данном выводе веб-сервер (один из его процессов) прослушивает по протоколу tcp6 все HTTP-соединения. Демон MySQL прослушивает локальный порт mysql по протоколу tcp. Для того, чтобы иметь возможность видеть номера самих портов, а также IP-адреса хостов, следует к команде netstat -lp добавить ключ n. Стоит также отметить, что для получения полной информации о слушающих процессах нужно запускать команду netstat от имени суперпользователя. Если не используется опция -n и не работает служба DNS, то netstat будет выполняться очень медленно.
Получение статистики для различных сетевых протоколов
Команда netstat позволяет видеть статистические данные по использованию всех доступных в системе протоколов. Для этого нужно использовать ключ -s:
Как видно, выводимая статистика отображается с разбивкой по разделам для каждого протокола. Здесь содержатся очень полезные сведения для анализа и поиска неполадок в работе сети.
Также для команды netstat есть ещё один полезный ключ, позволяющий выводить обновлённые данные с интервалом в одну секунду. Этот ключ работает не в каждой связке с другими опциями. Однако, отслеживание интерфейсов в режиме реального времени с этим ключом очень удобно, например команда netstat -i -a -c будет выводить статистику по использованию всех интерфейсов в системе, в том числе и отключенных (ключ -a) автоматически каждую секунду — ключ -c.
Информацию о таблице маршрутизации позволяет получить ключ -r:
Все рассмотренные ключи предоставляют исчерпывающие возможности для получения информации об использовании сети в подавляющем большинстве случаев. Однако, команда netstat располагает кроме рассмотренных, куда более внушительным арсеналом опций, ознакомиться с которыми можно с помощью команды man netstat.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Мониторинг сетевого стека linux
 Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели OSI!
Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели OSI!
С одной стороны большинство проблем с сетью возникают как раз на физическом и канальном уровнях, но с другой стороны приложения, работающие с сетью оперируют на уровне TCP сессий и не видят, что происходит на более низких уровнях.
Я расскажу, как достаточно простые метрики TCP/IP стека могут помочь разобраться с различными проблемами в распределенных системах.
Netlink
Почти все знают утилиту netstat в linux, она может показать все текущие TCP соединения и дополнительную информацию по ним. Но при большом количестве соединений netstat может работать достаточно долго и существенно нагрузить систему.
Есть более дешевый способ получить информацию о соединениях — утилита ss из проекта iproute2.
Ускорение достигается за счет использования протола netlink для запросов информации о соединениях у ядра. Наш агент использует netlink напрямую.
Считаем соединения
Disclaimer: для иллюстрации работы с метриками в разных срезах я буду показывать наш интерфейс (dsl) работы с метриками, но это можно сделать и на opensource хранилищах.
В первую очередь мы разделяем все соединения на входящие (inbound) и исходящие (outbound) по отношению к серверу.
Каждое TCP соединения в определенный момент времени находится в одном из состояний, разбивку по которым мы тоже сохраняем (это иногда может оказаться полезным):

По этому графику можно оценить общее количество входящих соединений, распределение соединений по состояниям.
Здесь так же видно резкое падение общего количества соединений незадолго до 11 Jun, попробуем посмотреть на соединения в разрезе listen портов:
На этом графике видно, что самое значительное падение было на порту 8014, посмотрим только 8014 (у нас в интерфейсе можно просто нажать на нужном элементе легенды):
Попробуем посмотреть, изменилось ли количество входящий соединений по всем серверам?
Выбираем серверы по маске “srv10*”:
Теперь мы видим, что количество соединений на порт 8014 не изменилось, попробуем найти на какой сервер они мигрировали:
Мы ограничили выборку только портом 8014 и сделали группировку не по порту, а по серверам.
Теперь понятно, что соединения с сервера srv101 перешли на srv102.
Разбивка по IP
Часто бывает необходимо посмотреть, сколько было соединений с различных IP адресов. Наш агент снимает количество TCP соединений не только с разбивкой по listen портам и состояниям, но и по удаленному IP, если данный IP находится в том же сегменте сети (для всех остальный адресов метрики суммируются и вместо IP мы показываем “
Рассмотрим тот же период времени, что и в предыдущих случаях:
Здесь видно, что соединений с 192.168.100.1 стало сильно меньше и в это же время появились соединения с 192.168.100.2.
Детализация рулит
На самом деле мы работали с одной метрикой, просто она была сильно детализирована, индентификатор каждого экземпляра выглядит примерно так:
Например, у одно из клиентов на нагруженном сервере-фронтенде снимается
700 экземпляров этой метрики
TCP backlog
По метрикам TCP соединений можно не только диагностировать работу сети, но и определять проблемы в работе сервисов.
Например, если какой-то сервис, обслуживающий клиентов по сети, не справляется с нагрузкой и перестает обрабатывать новые соединения, они ставятся в очередь (backlog).
На самом деле очереди две:
- SYN queue — очередь неустановленных соединений (получен пакет SYN, SYN-ACK еще не отправлен), размер ограничен согласно sysctl net.ipv4.tcp_max_syn_backlog;
- Accept queue — очередь соединений, для которых получен пакет ACK (в рамках «тройного рукопожатия»), но не был выполнен accept приложением (очередь ограничивается приложением)
При достижении лимита accept queue ACK пакет удаленного хоста просто отбрасывается или отправляется RST (в зависимости от значения переменной sysctl net.ipv4.tcp_abort_on_overflow).
Наш агент снимает текущее и максимальное значение accept queue для всех listen сокетов на сервере.
Для этих метрик есть график и преднастроенный триггер, который уведомит, если backlog любого сервиса использован более чем на 90%:
Счетчики и ошибки протоколов
Однажды сайт одного из наших клиентов подвергся DDOS атаке, в мониторинге было видно только увеличение трафика на сетевом интерфейсе, но мы не показывали абсолютно никаких метрик по содержанию этого трафика.
В данный момент однозначного ответа на этот вопрос окметр дать по-прежнему не может, так как сниффинг мы только начали осваивать, но мы немного продвинулись в этом вопросе.
Попробуем что-то понять про эти выбросы входящего трафика:
Теперь мы видим, что это входящий UDP трафик, но здесь не видно первых из трех выбросов.
Дело в том, что счетчики пакетов по протоколам в linux увеличиваются только в случае успешной обработки пакета.
Попробуем посмотреть на ошибки:
А вот и наш первый пик — ошибки UDP:NoPorts (количество датаграмм, пришедших на UPD порты, которые никто не слушает)
Данный пример мы эмулировали с помощью iperf, и в первый заход не включили на сервер-приемщик пакетов на нужном порту.
TCP ретрансмиты
Отдельно мы показываем количество TCP ретрансмитов (повторных отправок TCP сегментов).
Само по себе наличие ретрансмитов не означает, что в вашей сети есть потери пакетов.
Повторная передача сегмента осуществляется, если передающий узел не получил от принимающего подтверждение (ACK) в течении определенного времени (RTO).
Данный таймаут расчитывается динамически на основе замеров времени передачи данных между конкретными хостами (RTT) для того, чтобы обеспечивать гарантированную передачу данных при сохранении минимальных задержек.
На практике количество ретрансмитов обычно коррелирует с нагрузкой на серверы и важно смотреть не на абсолютное значение, а на различные аномалии:
На данном графике мы видим 2 выброса ретрансмитов, в это же время процессы postgres утилизировали CPU данного сервера:
Cчетчики протоколов мы получаем из /proc/net/snmp.
Conntrack
Еще одна распространенная проблема — переполнение таблицы ip_conntrack в linux (используется iptables), в этом случае linux начинает просто отбрасывать пакеты.
Это видно по сообщению в dmesg:
Агент автоматически снимает текущий размер данной таблицы и лимит с серверов, использующих ip_conntrack.
В окметре так же есть автоматический триггер, который уведомит, если таблица ip_conntrack заполнена более чем на 90%:
На данном графике видно, что таблица переполнялась, лимит подняли и больше он не достигался.
Вместо заключения
Примеры наших стандартных графиков можно посмотреть в нашем демо-проекте.
Там же можно постмотреть графики Netstat.
Источник



