- Как открыть файл в терминале Linux
- Команды cat и tac
- Команды head и tail
- Команды more и less
- Команда most
- Текстовый редактор Nano
- Просмотр содержимого файлов в командной строке Linux
- Команда cat
- Команда nl
- Команда less
- Команда more
- Команда head
- Команда tail
- Заключение
- 5 команд для просмотра содержимого файла в командной строке Linux
- 5 команд для просмотра файлов в Linux
- 1. Cat
- 3. Less
- 4. Head
- 5. Tail
- Бонус: Strings
- Заключение
- Bash-скрипты, часть 4: ввод и вывод
- Стандартные дескрипторы файлов
- STDIN
- STDOUT
- STDERR
- ▍Перенаправление потока ошибок
- ▍Перенаправление потоков ошибок и вывода
- Перенаправление вывода в скриптах
- ▍Временное перенаправление вывода
- ▍Постоянное перенаправление вывода
- Перенаправление ввода в скриптах
- Создание собственного перенаправления вывода
- Создание дескрипторов файлов для ввода данных
- Закрытие дескрипторов файлов
- Получение сведений об открытых дескрипторах
- Подавление вывода
- Итоги
Как открыть файл в терминале Linux
В Linux все настройки программ и самой операционной системы хранятся в текстовых документах. Также в текстовых документах сохраняются логи и другие необходимые данные. Поэтому при работе с Linux постоянно приходится просматривать и редактировать подобные текстовые и конфигурационные файлы.
В данной инструкции мы расскажем о том, как открыть файл в терминале Linux и какие команды для этого можно использовать. Материал будет актуален для любого дистрибутива Linux, включая Ubuntu, Debian, Kali Linux, CentOS и т.д.
Команды cat и tac
Если вам нужно открыть файл в терминале Linux, то для этого предусмотрено множество простых и эффективных способов. Пожалуй, самая часто используемая команда такого рода – это команда « cat ».
Чтобы использовать ее просто введите « cat » и название файла. Например, если вам нужно просмотреть содержимое файла « file_name.txt », то команда должна выглядеть вот так:
После выполнение данной команды все содержимое указанного файла будет выведено в терминал Linux. Данный способ вывода удобен для быстрого просмотра небольших файлов.
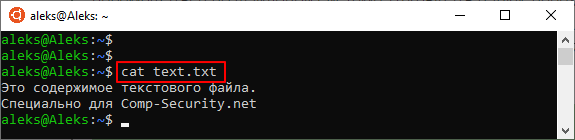
При использовании команды « cat » может понадобиться нумерация строк. В этом случае команду нужно вводить с параметром « -n ».
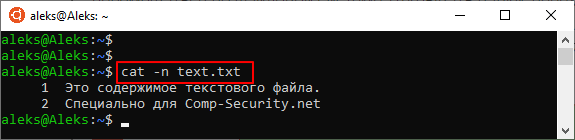
Также есть команда « tac », которая открывает файлы точно также как « cat », но выводит строки в обратном порядке (начиная с конца).
Обратите внимание , для того чтобы узнать больше о « cat » и « tac », а также других командах Linux, введите в терминал « man » (от англ. manual) и через пробел название интересующей вас команды, например, « man tac ». Это выведет подробную информацию о команде и список всех поддерживаемых параметров.
Команды head и tail
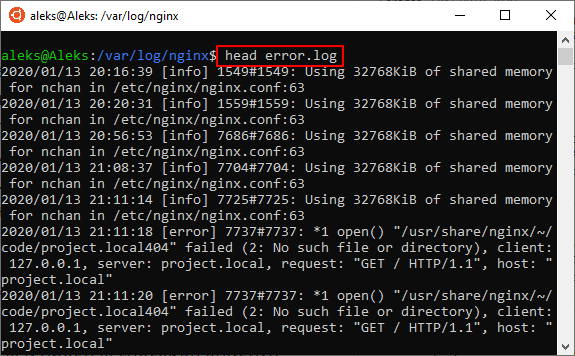
Если нужно открыть в терминале Linux большой файл, то вместо команды « cat » можно использовать « head » или « tail ». Данные команды выводят в терминал только часть файла. В случае « head » выводится только начало документа, а в случае « tail » только конец.
Чтобы открыть файл с помощью данной команды просто введите « head » или « tail » и название файла:
По умолчанию команды « head » и « tail » выводят по 10 строк с начала или конца файла. Но, при необходимости это значение можно изменить при помощи параметра « -n ». Для этого вводим « -n » и число строк (не отделяя пробелом). Выглядит это примерно так:
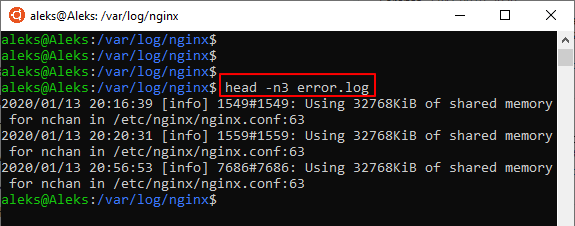
Кроме этого, вы можете ограничить количество информации, которую выводят команды « head » и « tail », указав значение в байтах. Для этого нужно использовать параметр « -c ». Например, чтобы вывести 100 байт нужно добавить параметр « -c » и указать значение 100 (не отделяя пробелом). Выглядит это примерно так:
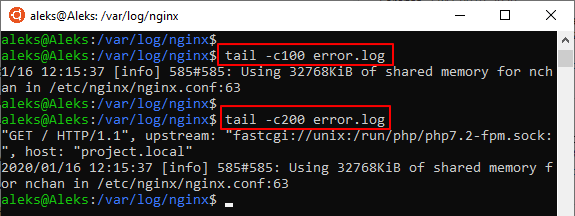
Команды « head » и « tail » имеют общий набор параметров, но у « tail » есть уникальный параметр « -f », которого нет у « head ». При вызове « tail -f file_name.txt » выводимая информация будет автоматически обновляться. Это может быть удобно для наблюдения за логами.
Команды more и less
Для открытия больших файлов в терминале Linux можно использовать команды « more » и « less ». Команда « more » открывает файл в терминале Linux и позволяет пролистывать его только вниз при помощи клавиш Enter (одна строка вниз) и Space (страница вниз). Пролистывания вверх нет, поэтому, если вы случайно проскочили нужное вам место в файле, то вернуться назад не получится.
Чтобы открыть файл в терминале Linux с помощью команды « more » и « less » нужно ввести следующее:
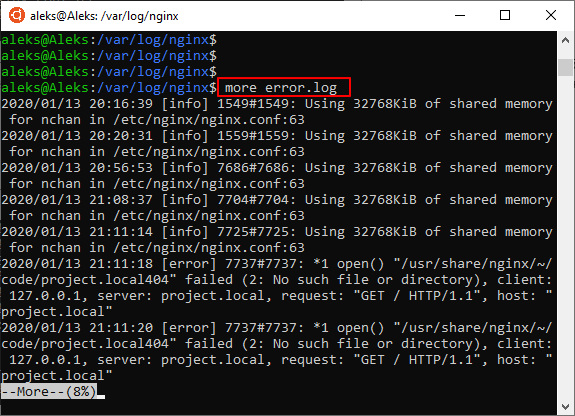
Команда « less » также позволяет открывать большие файлы в терминале Linux, но она уже предоставляет больше возможностей. С помощью « less » можно пролистывать содержимое документа как вниз ( Page Down ), так и вверх ( Page Up ), переходить в конец ( End ) и начало файла ( Home ), пролистывать текст по одной строке ( Enter ), а также выполнять поиск в обоих направлениях.
Для того чтобы выполнить поиск после выполнения « less » нужно ввести слеш ( / ) и любой кусок текста. Чтобы перейти к следующему найденному отрывку нужно нажать N , а Shift-N возвращает к предыдущему найденному отрывку. Для поиска в обратном направлении вместо знака слеш ( / ) нужно вводить знак вопроса ( ? ) и после этого любой текст.
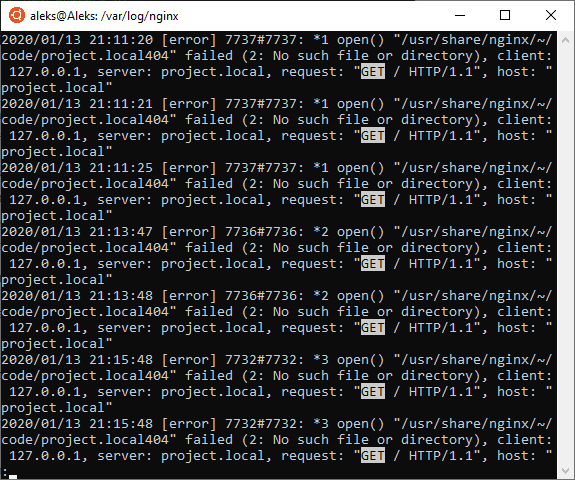
Учитывая большие возможности команды « less », для открытия файлов в терминале Linux в основном используют именно ее, а не команду « more ».
Команда most
Если возможностей « less » не хватает, то можно использовать команду « most ». Она предоставляет еще больше возможностей для открытия файлов в терминале Linux, но она может быть не установлена по умолчанию.
Если вы используете Ubuntu Linux , то для установки « most » нужно выполнить вот такую команду:
Команда « most » позволяет открывать сразу несколько файлов и переключаться между ними при необходимости. Также « most » позволяет редактировать текущий файл, переходить к нужной строке файла, разделять экран пополам, блокировать или пролистывать оба экрана одновременно и многое другое. По умолчанию, « most » не обертывает длинные строки, а использует горизонтальную прокрутку.
Для того чтобы открыть файл в терминале Linux с помощью « most » нужно выполнить вот такую команду:
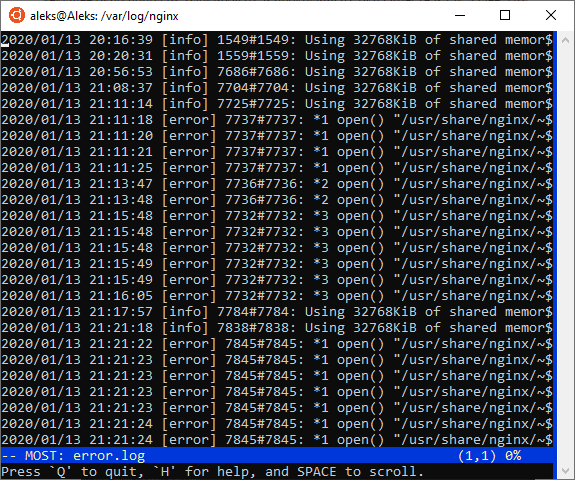
Для перемещения по открытому файлу в «most» можно использовать стрелки на клавиатуре, Tab (вправо), Enter (вниз), T (начало), B (конец), J и G (переход к n-й строке), SPACE и D (один экран вниз), DELETE и U (один экран вверх). Для поиска вперед S , f или слеш , для поиска назад знак вопроса (?).
Текстовый редактор Nano
Если вам нужно не просто открыть файл в терминале Linux, но и отредактировать его, то лучше всего использовать не « most », а какой-нибудь более продвинутый текстовый редактор для терминала. Например, это может быть редактор Nano .
В Ubuntu Linux текстовый редактор Nano установлен по умолчанию, но если его нет в вашей системе, то вы можете его установить следующими командами:
Для CentOS, Fedora :
Для Debian, Ubuntu :
Чтобы открыть файл в терминале Linux при помощи редактора Nano нужно выполнить следующую команду:
Интерфейс программы Nano включает в себе верхнюю строку с информацией о редакторе и открытом файле, область редактирование с содержимым открытого файла, нижнюю панель с информацией о комбинациях клавиш.
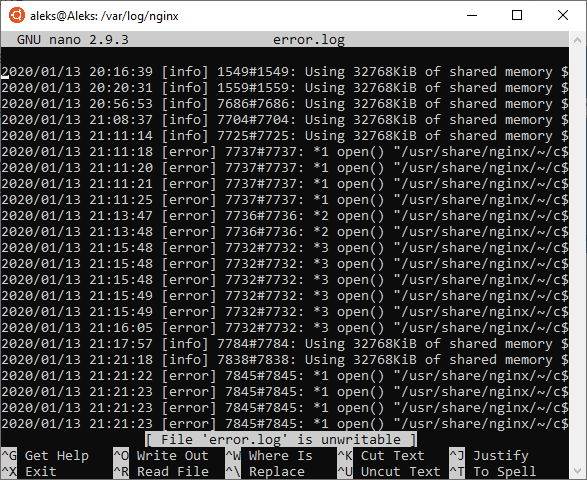
Для управления текстовым редактором Nano используются следующие комбинации клавиш:
- Ctrl-G или F1 – просмотр справки;
- Ctrl-X или F2 – выход из программы;
- Ctrl-O или F3 – сохранение открытого файла;
- Ctrl-J или F4 – выровнять текущий абзац;
- Ctrl-R или F5 – загрузить содержимое другого файла в текущий;
- Ctrl-W или F6 – выполнить поиск;
- Ctrl-Y или F7 – пролистать страницу вперед;
- Ctrl-V или F8 – пролистать страницу назад;
- Ctrl-K или F9 – вырезать строку и запомнить;
- Ctrl-U или F10 – вставить;
- Ctrl-C или F11 – положение курсора;
- Ctrl-T или F12 – проверить орфографию;
Источник
Просмотр содержимого файлов в командной строке Linux

Рассмотрим несколько команд, которые используются для просмотра содержимого текстовых файлов в командной строке Linux.
Команда cat
Команда cat выводит содержимое файла, который передается ей в качестве аргумента.
Это самый простой и наиболее часто используемый способ для вывода содержимого текстовых файлов. Но выводить большие файлы через cat не всегда удобно.
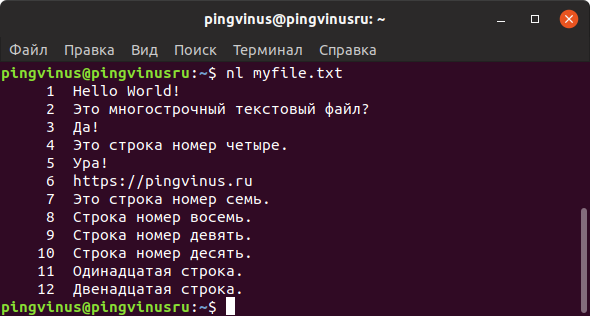
Команда nl
Команда nl действует аналогично команде cat , но выводит еще и номера строк в столбце слева.
Команду nl удобно применять для просмотра программного кода или поиска строк в файлах конфигурации.
Команда less
Утилита less выводит содержимое файла, но отображает его только в рамках текущего окна в режиме просмотра.
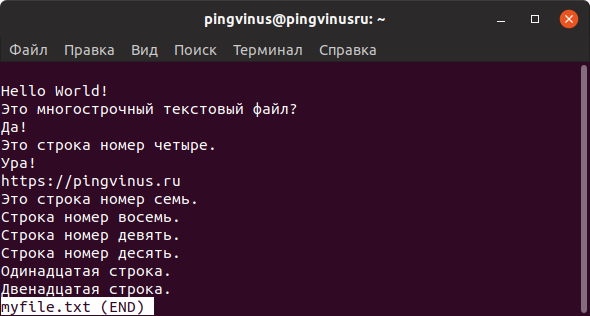
Вы можете прокручивать текст файла клавишами стрелок или перелистывать страницы клавишами w и z .
Для поиска текста внутри файла нажмите / .
Для просмотра списка доступных горячих клавиш нажмите h
Чтобы выйти из режима просмотра используется клавиша q .
Очень удобно, что после выхода окно терминала остается чистым и не содержит текст файла.
Команда more
Команда more очень похожа на команду less . Она также выводит файл в терминале в режиме просмотра, но имеет некоторые отличия от команды less.
Например, less в конце файла выводит сообщение (END) (или EOF — End Of File) и ожидает нажатия клавиши q чтобы закрыть режим просмотра, а more по достижении конца файла сразу возвращает управление в терминал.
Также more после своей работы оставляет текст файла в терминале, а less работает «чисто» и не сохраняет текст в терминале.
Команда head
Команда head выводит на экран только первые 10 строк файла.
Используя опцию -n можно задать количество строк, которое нужно вывести. Например, чтобы вывести 15 строк используется команда:
Вместо -n можно просто использовать знак минус — , за которым сразу указывается количество строк.
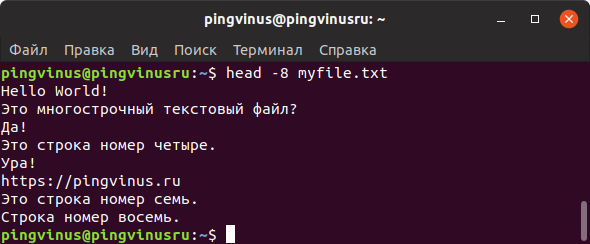
Команда tail
Команда tail аналогична команде head , но выводит последние 10 строк файла.
Заключение
Команды, которые мы рассмотрели, имеют дополнительные возможности и области применения. Для получения справки по каждой команде можно воспользоваться Man-страницами.
Источник
5 команд для просмотра содержимого файла в командной строке Linux
Главное меню » Операционная система Linux » 5 команд для просмотра содержимого файла в командной строке Linux

Чтение файла в терминале Linux – это не то же самое, что открытие файла в блокноте. Поскольку вы находитесь в режиме командной строки, вы должны использовать команды для чтения файлов в Linux.
Не беспокойтесь, это совсем не сложно для отображения файла в Linux. Также легко научиться читать файлы в строке.
Вот пять команд, которые позволяют вам просматривать содержимое файла в терминале Linux.
5 команд для просмотра файлов в Linux
Перед тем, как просмотреть файл в Unix-подобных системах, позвольте нам пояснить это, когда мы имеем в виду текстовые файлы здесь. Существуют различные инструменты и команды, если вы хотите читать двоичные файлы.
1. Cat
Это самая простая и, пожалуй, самая популярная команда для просмотра файла в Linux.
Cat просто печатает содержимое файла на стандартном экране, т.е. на экране. Это не может быть проще, чем это, не так ли?
Cat становится мощной командой, когда используется с ее параметрами. Мы рекомендуем прочитать это подробное руководство по использованию команды cat.
Проблема с командой cat в том, что она отображает текст на экране. Представьте, что вы используете команду cat с файлом, содержащим 2000 строк. Весь ваш экран будет заполнен 200 строками, и это не идеальная ситуация.
Итак, что вы делаете в таком случае? Используйте команду less в Linux (объяснено позже).
Команда nl почти как команда cat. Разница лишь в том, что она добавляет номера строк при отображении текста в терминале.
Есть несколько вариантов с командой nl, которая позволяет вам контролировать нумерацию.
3. Less
Команда Less просматривает файл по одной странице за раз. Лучше всего, чтобы вы выходили меньше (нажимая q), на экране не отображаются строки. Ваш терминал остается чистым и нетронутым.
Мы настоятельно рекомендуем изучить несколько параметров команды Less, чтобы вы могли использовать ее более эффективно.
4. Head
Команда Head – это еще один способ просмотра текстового файла, но с небольшой разницей. Команда head отображает первые 10 строк текстового файла по умолчанию.
Вы можете изменить это поведение, используя опции с командой head, но основной принцип остается тем же: команда head начинает работать с заголовка (начала) файла.
5. Tail
Команда Tail в Linux аналогична и все же противоположна команде head. В то время как команда head отображает файл с начала, команда tail отображает файл с конца.
По умолчанию команда tail отображает последние 10 строк файла.
Команды Head и Tail могут быть объединены для отображения выбранных строк из файла. Вы также можете использовать команду tail для просмотра изменений, внесенных в файл в режиме реального времени.
Бонус: Strings
Хорошо! Мы обещали показывать только команды для просмотра текстового файла. И этот имеет дело как с текстовыми, так и с двоичными файлами.
Команда Strings отображает читаемый текст из двоичного файла.
Нет, он не конвертирует двоичные файлы в текстовые файлы. Если бинарный файл состоит из реально читаемого текста, команда strings отображает этот текст на вашем экране.
Заключение
Некоторые пользователи Linux используют Vim для просмотра текстового файла, но мы думаем, что это излишне. Наша любимая команда открыть файл в Linux – это команда less. Она оставляет экран чистым и имеет несколько параметров, которые значительно упрощают просмотр текстового файла.
Какую команду вы предпочитаете?
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Bash-скрипты, часть 4: ввод и вывод
В прошлый раз, в третьей части этой серии материалов по bash-скриптам, мы говорили о параметрах командной строки и ключах. Наша сегодняшняя тема — ввод, вывод, и всё, что с этим связано.

Вы уже знакомы с двумя методами работы с тем, что выводят сценарии командной строки:
- Отображение выводимых данных на экране.
- Перенаправление вывода в файл.
Иногда что-то надо показать на экране, а что-то — записать в файл, поэтому нужно разобраться с тем, как в Linux обрабатывается ввод и вывод, а значит — научиться отправлять результаты работы сценариев туда, куда нужно. Начнём с разговора о стандартных дескрипторах файлов.
Стандартные дескрипторы файлов
Всё в Linux — это файлы, в том числе — ввод и вывод. Операционная система идентифицирует файлы с использованием дескрипторов.
Каждому процессу позволено иметь до девяти открытых дескрипторов файлов. Оболочка bash резервирует первые три дескриптора с идентификаторами 0, 1 и 2. Вот что они означают.
- 0 , STDIN — стандартный поток ввода.
- 1 , STDOUT — стандартный поток вывода.
- 2 , STDERR — стандартный поток ошибок.
Эти три специальных дескриптора обрабатывают ввод и вывод данных в сценарии.
Вам нужно как следует разобраться в стандартных потоках. Их можно сравнить с фундаментом, на котором строится взаимодействие скриптов с внешним миром. Рассмотрим подробности о них.
STDIN
STDIN — это стандартный поток ввода оболочки. Для терминала стандартный ввод — это клавиатура. Когда в сценариях используют символ перенаправления ввода — , Linux заменяет дескриптор файла стандартного ввода на тот, который указан в команде. Система читает файл и обрабатывает данные так, будто они введены с клавиатуры.
Многие команды bash принимают ввод из STDIN , если в командной строке не указан файл, из которого надо брать данные. Например, это справедливо для команды cat .
Когда вы вводите команду cat в командной строке, не задавая параметров, она принимает ввод из STDIN . После того, как вы вводите очередную строку, cat просто выводит её на экран.
STDOUT
STDOUT — стандартный поток вывода оболочки. По умолчанию это — экран. Большинство bash-команд выводят данные в STDOUT , что приводит к их появлению в консоли. Данные можно перенаправить в файл, присоединяя их к его содержимому, для этого служит команда >> .
Итак, у нас есть некий файл с данными, к которому мы можем добавить другие данные с помощью этой команды:
То, что выведет pwd , будет добавлено к файлу myfile , при этом уже имеющиеся в нём данные никуда не денутся.
Перенаправление вывода команды в файл
Пока всё хорошо, но что если попытаться выполнить что-то вроде показанного ниже, обратившись к несуществующему файлу xfile , задумывая всё это для того, чтобы в файл myfile попало сообщение об ошибке.
После выполнения этой команды мы увидим сообщения об ошибках на экране.
Попытка обращения к несуществующему файлу
При попытке обращения к несуществующему файлу генерируется ошибка, но оболочка не перенаправила сообщения об ошибках в файл, выведя их на экран. Но мы-то хотели, чтобы сообщения об ошибках попали в файл. Что делать? Ответ прост — воспользоваться третьим стандартным дескриптором.
STDERR
STDERR представляет собой стандартный поток ошибок оболочки. По умолчанию этот дескриптор указывает на то же самое, на что указывает STDOUT , именно поэтому при возникновении ошибки мы видим сообщение на экране.
Итак, предположим, что надо перенаправить сообщения об ошибках, скажем, в лог-файл, или куда-нибудь ещё, вместо того, чтобы выводить их на экран.
▍Перенаправление потока ошибок
Как вы уже знаете, дескриптор файла STDERR — 2. Мы можем перенаправить ошибки, разместив этот дескриптор перед командой перенаправления:
Сообщение об ошибке теперь попадёт в файл myfile .
Перенаправление сообщения об ошибке в файл
▍Перенаправление потоков ошибок и вывода
При написании сценариев командной строки может возникнуть ситуация, когда нужно организовать и перенаправление сообщений об ошибках, и перенаправление стандартного вывода. Для того, чтобы этого добиться, нужно использовать команды перенаправления для соответствующих дескрипторов с указанием файлов, куда должны попадать ошибки и стандартный вывод:
Перенаправление ошибок и стандартного вывода
Оболочка перенаправит то, что команда ls обычно отправляет в STDOUT , в файл correctcontent благодаря конструкции 1> . Сообщения об ошибках, которые попали бы в STDERR , оказываются в файле errorcontent из-за команды перенаправления 2> .
Если надо, и STDERR , и STDOUT можно перенаправить в один и тот же файл, воспользовавшись командой &> :
Перенаправление STDERR и STDOUT в один и тот же файл
После выполнения команды то, что предназначено для STDERR и STDOUT , оказывается в файле content .
Перенаправление вывода в скриптах
Существует два метода перенаправления вывода в сценариях командной строки:
- Временное перенаправление, или перенаправление вывода одной строки.
- Постоянное перенаправление, или перенаправление всего вывода в скрипте либо в какой-то его части.
▍Временное перенаправление вывода
В скрипте можно перенаправить вывод отдельной строки в STDERR . Для того, чтобы это сделать, достаточно использовать команду перенаправления, указав дескриптор STDERR , при этом перед номером дескриптора надо поставить символ амперсанда ( & ):
Если запустить скрипт, обе строки попадут на экран, так как, как вы уже знаете, по умолчанию ошибки выводятся туда же, куда и обычные данные.
Запустим скрипт так, чтобы вывод STDERR попадал в файл.
Как видно, теперь обычный вывод делается в консоль, а сообщения об ошибках попадают в файл.
Сообщения об ошибках записываются в файл
▍Постоянное перенаправление вывода
Если в скрипте нужно перенаправлять много выводимых на экран данных, добавлять соответствующую команду к каждому вызову echo неудобно. Вместо этого можно задать перенаправление вывода в определённый дескриптор на время выполнения скрипта, воспользовавшись командой exec :
Перенаправление всего вывода в файл
Если просмотреть файл, указанный в команде перенаправления вывода, окажется, что всё, что выводилось командами echo , попало в этот файл.
Команду exec можно использовать не только в начале скрипта, но и в других местах:
Вот что получится после запуска скрипта и просмотра файлов, в которые мы перенаправляли вывод.
Перенаправление вывода в разные файлы
Сначала команда exec задаёт перенаправление вывода из STDERR в файл myerror . Затем вывод нескольких команд echo отправляется в STDOUT и выводится на экран. После этого команда exec задаёт отправку того, что попадает в STDOUT , в файл myfile , и, наконец, мы пользуемся командой перенаправления в STDERR в команде echo , что приводит к записи соответствующей строки в файл myerror.
Освоив это, вы сможете перенаправлять вывод туда, куда нужно. Теперь поговорим о перенаправлении ввода.
Перенаправление ввода в скриптах
Для перенаправления ввода можно воспользоваться той же методикой, которую мы применяли для перенаправления вывода. Например, команда exec позволяет сделать источником данных для STDIN какой-нибудь файл:
Эта команда указывает оболочке на то, что источником вводимых данных должен стать файл myfile , а не обычный STDIN . Посмотрим на перенаправление ввода в действии:
Вот что появится на экране после запуска скрипта.
В одном из предыдущих материалов вы узнали о том, как использовать команду read для чтения данных, вводимых пользователем с клавиатуры. Если перенаправить ввод, сделав источником данных файл, то команда read , при попытке прочитать данные из STDIN , будет читать их из файла, а не с клавиатуры.
Некоторые администраторы Linux используют этот подход для чтения и последующей обработки лог-файлов.
Создание собственного перенаправления вывода
Перенаправляя ввод и вывод в сценариях, вы не ограничены тремя стандартными дескрипторами файлов. Как уже говорилось, можно иметь до девяти открытых дескрипторов. Остальные шесть, с номерами от 3 до 8, можно использовать для перенаправления ввода или вывода. Любой из них можно назначить файлу и использовать в коде скрипта.
Назначить дескриптор для вывода данных можно, используя команду exec :
После запуска скрипта часть вывода попадёт на экран, часть — в файл с дескриптором 3 .
Перенаправление вывода, используя собственный дескриптор
Создание дескрипторов файлов для ввода данных
Перенаправить ввод в скрипте можно точно так же, как и вывод. Сохраните STDIN в другом дескрипторе, прежде чем перенаправлять ввод данных.
После окончания чтения файла можно восстановить STDIN и пользоваться им как обычно:
В этом примере дескриптор файла 6 использовался для хранения ссылки на STDIN . Затем было сделано перенаправление ввода, источником данных для STDIN стал файл. После этого входные данные для команды read поступали из перенаправленного STDIN , то есть из файла.
После чтения файла мы возвращаем STDIN в исходное состояние, перенаправляя его в дескриптор 6 . Теперь, для того, чтобы проверить, что всё работает правильно, скрипт задаёт пользователю вопрос, ожидает ввода с клавиатуры и обрабатывает то, что введено.
Закрытие дескрипторов файлов
Оболочка автоматически закрывает дескрипторы файлов после завершения работы скрипта. Однако, в некоторых случаях нужно закрывать дескрипторы вручную, до того, как скрипт закончит работу. Для того, чтобы закрыть дескриптор, его нужно перенаправить в &- . Выглядит это так:
После исполнения скрипта мы получим сообщение об ошибке.
Попытка обращения к закрытому дескриптору файла
Всё дело в том, что мы попытались обратиться к несуществующему дескриптору.
Будьте внимательны, закрывая дескрипторы файлов в сценариях. Если вы отправляли данные в файл, потом закрыли дескриптор, потом — открыли снова, оболочка заменит существующий файл новым. То есть всё то, что было записано в этот файл ранее, будет утеряно.
Получение сведений об открытых дескрипторах
Для того, чтобы получить список всех открытых в Linux дескрипторов, можно воспользоваться командой lsof . Во многих дистрибутивах, вроде Fedora, утилита lsof находится в /usr/sbin . Эта команда весьма полезна, так как она выводит сведения о каждом дескрипторе, открытом в системе. Сюда входит и то, что открыли процессы, выполняемые в фоне, и то, что открыто пользователями, вошедшими в систему.
У этой команды есть множество ключей, рассмотрим самые важные.
- -p Позволяет указать ID процесса.
- -d Позволяет указать номер дескриптора, о котором надо получить сведения.
Для того, чтобы узнать PID текущего процесса, можно использовать специальную переменную окружения $$ , в которую оболочка записывает текущий PID .
Ключ -a используется для выполнения операции логического И над результатами, возвращёнными благодаря использованию двух других ключей:
Вывод сведений об открытых дескрипторах
Тип файлов, связанных с STDIN , STDOUT и STDERR — CHR (character mode, символьный режим). Так как все они указывают на терминал, имя файла соответствует имени устройства, назначенного терминалу. Все три стандартных файла доступны и для чтения, и для записи.
Посмотрим на вызов команды lsof из скрипта, в котором открыты, в дополнение к стандартным, другие дескрипторы:
Вот что получится, если этот скрипт запустить.
Просмотр дескрипторов файлов, открытых скриптом
Скрипт открыл два дескриптора для вывода ( 3 и 6 ) и один — для ввода ( 7 ). Тут же показаны и пути к файлам, использованных для настройки дескрипторов.
Подавление вывода
Иногда надо сделать так, чтобы команды в скрипте, который, например, может исполняться как фоновый процесс, ничего не выводили на экран. Для этого можно перенаправить вывод в /dev/null . Это — что-то вроде «чёрной дыры».
Вот, например, как подавить вывод сообщений об ошибках:
Тот же подход используется, если, например, надо очистить файл, не удаляя его:
Итоги
Сегодня вы узнали о том, как в сценариях командной строки работают ввод и вывод. Теперь вы умеете обращаться с дескрипторами файлов, создавать, просматривать и закрывать их, знаете о перенаправлении потоков ввода, вывода и ошибок. Всё это очень важно в деле разработки bash-скриптов.
В следующий раз поговорим о сигналах Linux, о том, как обрабатывать их в сценариях, о запуске заданий по расписанию и о фоновых задачах.
Уважаемые читатели! В этом материале даны основы работы с потоками ввода, вывода и ошибок. Уверены, среди вас есть профессионалы, которые могут рассказать обо всём этом то, что приходит лишь с опытом. Если так — передаём слово вам.
Источник



