- Проверка диска на битые секторы в Linux
- Проверка накопителя на битые секторы средствами badblocks.
- Проверка накопителя на битые секторы в Linux в smartmontools
- Выводы
- Проверка диска на битые секторы в Linux
- Проверка диска на битые секторы Linux
- Выводы
- Проверка жесткого диска в Linux
- Установка Smartmontools
- Проверка жесткого диска в smartctl
- Автоматическая диагностика в smartd
- Проверка диска на ошибки в GUI
- Выводы
- Оцените статью:
- Об авторе
- 9 комментариев
Проверка диска на битые секторы в Linux
Любой компьютер — сложное устройство, которые состоит из множества компонентов и никто не застрахован от сбоев любого из них. В этой статье мы рассмотрим как своевременно распознать одну из серьезных проблем с устройствами хранения информации, будь то жесткий диск или flash-накопитель, как выполняется проверка диска на битые секторы linux.
Любой накопитель состоит из множества маленьких блоков (секторов), которые хранят информацию в виде нулей или единиц (битов). Если, по какой-то причине, операционная система не может записать бит информации в определенный сектор, то можно считать его «битым».
Сектор может стать битым по разным причинам:
- Заводской брак
- Выключение питание компьютера во время записи информации.
- Физический износ накопителя.
Небольшое количество битых секторов находится практически на любом накопителе. Но стоит обратить внимание,если их количество со временем увеличивается. Это может говорить о скорой физической смерти накопителя и Вам пора задуматься о его замене.
Давайте рассмотрим, при помощи каких утилит в Linux мы можем проверить диск на битые секторы linux.
Проверка накопителя на битые секторы средствами badblocks.
Badblocks — стандартная утилита Linuх для проверки на битые секторы. Она устанавливается по-умолчанию практически в любой дистрибутив и с ее помощью можно проверить как жесткий диск, так и внешний накопитель.
Для начала давайте посмотрим, какие накопители подключены к нашей системе и какие на них имеются разделы. Для этого нам нужна еще одна стандартная утилита Linux — fdisk.
Естественно, что выполнять команды нужно с правами суперпользователя:
Параметром -l мы говорим утилите fdisk, что нам нужно показать список разделов и выйти.

Теперь, когда мы знаем, какие разделы у нас есть, мы можем проверить их на битые секторы. Для этого мы будем использовать утилиту badblocks следующим образом:
Для проверки мы указываем следующие параметры:
- -v — подробный вывод информации о результатах проверки.
- /dev/sda1 — раздел, который мы хотим проверить на битые секторы.
- > badsectors.txt — выводим результат выполнения команды в файл badsectors.txt.

Если же в результате были найдены битые секторы, то нам надо дать указание операционной системе не записывать в них информацию в будущем. Для этого нам понадобятся утилиты Linux для работы с файловыми системами:
- e2fsck. Если мы будем исправлять раздел с файловыми система Linux ( ext2,ext3,ext4).
- fsck. Если мы будем исправлять файловую систему, отличную от ext.
Вводим следующие команды:
Или, если у нас файловая система не ext:
Параметром -l мы говорим утилите использовать список битых секторов из файла badsectors.txt, который мы получили ранее при проверке с помощью утилиты badblocks.
Проверка накопителя на битые секторы в Linux в smartmontools
Теперь давайте рассмотрим более современный и надежный способ проверить диск на битые секторы linux. Современные накопители ATA/SATA ,SCSI/SAS,SSD имеют встроенную систему самоконтроля S.M.A.R.T (Self-Monitoring, Analysis and Reporting Technology, Технология самоконтроля, анализа и отчетности), которая производит мониторинг параметров накопителя и поможет определить ухудшение параметров работы накопителя на ранних стадиях. Для работы со S.M.A.R.T в Linux есть утилита smartmontools.
Давайте сначала ее установим. Если ваш дистрибутив основан на DebianUbuntu, то вводите:
Если же у Вас дистрибутив на основе RHELCentOS, то вводите:
Теперь, когда мы установили smartmontools мы можем посмотреть станицу помощи, с помощью команды:
Давайте перейдем к работе с утилитой. Вводим следующую команду с параметром -H,чтобы утилита показала нам информацию о состоянии накопителя:

Как видим, проверка диска на битые секторы linux завершена и утилита говорит нам, что с накопителем все в порядке!
Дополнительно, можно указать следующие параметры -a или —all, чтобы получить еще больше информации о накопителе, или -x и —xall, чтобы просмотреть информацию в том числе и об остальных параметрах накопителя.
Выводы
В этой статье мы рассмотрели способы проверки накопителей на наличие битых секторов под Linux для того,чтобы вовремя предусмотреть возможные сбои и не потерять данные.
Источник
Проверка диска на битые секторы в Linux
Одно из самых важных устройств компьютера — это жесткий диск, именно на нём хранится операционная система и вся ваша информация. Единица хранения информации на жестком диске — сектор или блок. Это одна ячейка в которую записывается определённое количество информации, обычно это 512 или 1024 байт.
Битые сектора, это повреждённые ячейки, которые больше не работают по каким либо причинам. Но файловая система всё ещё может пытаться записать в них данные. Прочитать данные из таких секторов очень сложно, поэтому вы можете их потерять. Новые диски SSD уже не подвержены этой проблеме, потому что там существует специальный контроллер, следящий за работоспособностью ячеек и перемещающий данные из нерабочих в рабочие. Однако традиционные жесткие диски используются всё ещё очень часто. В этой статье мы рассмотрим как проверить диск на битые секторы Linux.
Проверка диска на битые секторы Linux
Для поиска битых секторов можно использовать утилиту badblocks. Если вам надо проверить корневой или домашний раздел диска, то лучше загрузится в LiveCD, чтобы файловая система не была смонтирована. Все остальные разделы можно сканировать в вашей установленной системе. Вам может понадобиться посмотреть какие разделы есть на диске. Для этого можно воспользоваться командой fdisk:
sudo fdisk -l /dev/sda1
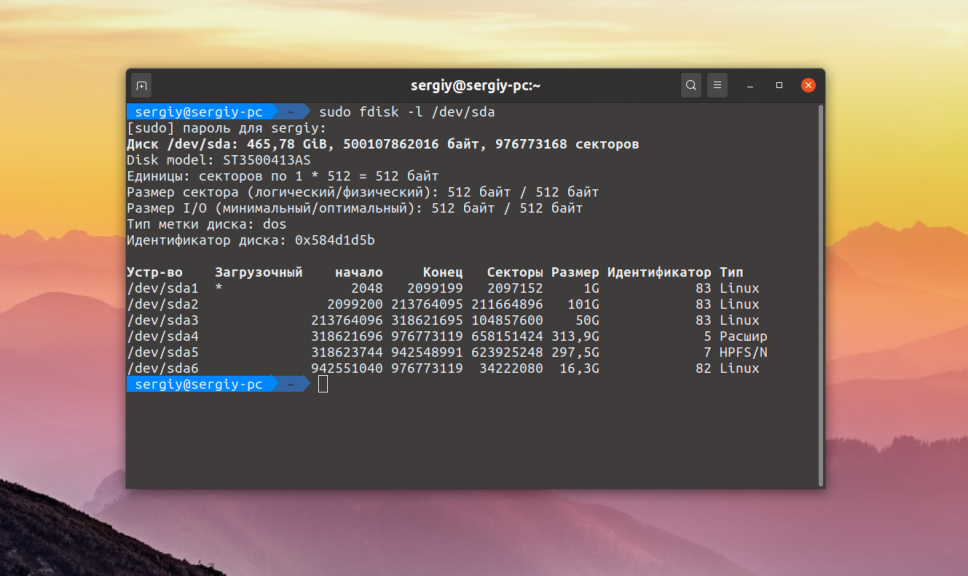
Или если вы предпочитаете использовать графический интерфейс, это можно сделать с помощью утилиты Gparted. Просто выберите нужный диск в выпадающем списке:
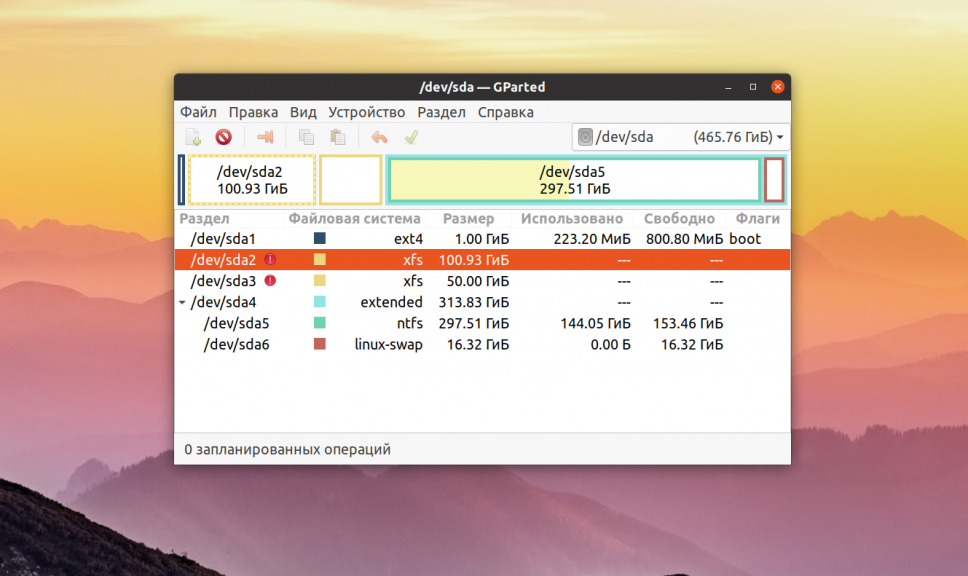
В этом примере я хочу проверить раздел /dev/sda2 с файловой системой XFS. Как я уже говорил, для этого используется команда badblocks. Синтаксис у неё довольно простой:
$ sudo badblocks опции /dev/имя_раздела_диска
Давайте рассмотрим опции программы, которые вам могут понадобится:
- -e — позволяет указать количество битых блоков, после достижения которого дальше продолжать тест не надо;
- -f — по умолчанию утилита пропускает тест с помощью чтения/записи если файловая система смонтирована чтобы её не повредить, эта опция позволяет всё таки выполнять эти тесты даже для смонтированных систем;
- -i — позволяет передать список ранее найденных битых секторов, чтобы не проверять их снова;
- -n — использовать безопасный тест чтения и записи, во время этого теста данные не стираются;
- -o — записать обнаруженные битые блоки в указанный файл;
- -p — количество проверок, по умолчанию только одна;
- -s — показывать прогресс сканирования раздела;
- -v — максимально подробный режим;
- -w — позволяет выполнить тест с помощью записи, на каждый блок записывается определённая последовательность байт, что стирает данные, которые хранились там раньше.
Таким образом, для обычной проверки используйте такую команду:
sudo badblocks -v /dev/sda2 -o
Это безопасно и её можно выполнять на файловой системе с данными, она ничего не повредит. В принципе, её даже можно выполнять на смонтированной файловой системе, хотя этого делать не рекомендуется. Если файловая система размонтирована, можно выполнить тест с записью с помощью опции -n:
sudo badblocks -vn /dev/sda2 -o
После завершения проверки, если были обнаружены битые блоки, надо сообщить о них файловой системе, чтобы она не пыталась писать туда данные. Для этого используйте утилиту fsck и опцию -l:
Если на разделе используется файловая система семейства Ext, например Ext4, то для поиска битых блоков и автоматической регистрации их в файловой системе можно использовать команду e2fsck. Например:
sudo e2fsck -cfpv /dev/sda1
Параметр -с позволяет искать битые блоки и добавлять их в список, -f — проверяет файловую систему, -p — восстанавливает повреждённые данные, а -v выводит всё максимально подробно.
Выводы
В этой статье мы рассмотрели как выполняется проверка диска на битые секторы Linux, чтобы вовремя предусмотреть возможные сбои и не потерять данные. Но на битых секторах проблемы с диском не заканчиваются. Там есть множество параметров стабильности работы, которые можно отслеживать с помощью таблицы SMART. Читайте об этом в статье Проверка диска в Linux.
Источник
Проверка жесткого диска в Linux
Если и есть то, с чем вы очень не хотите столкнуться в вашей операционной системе, то это неожиданный выход из строя жестких дисков. С помощью резервного копирования и технологии хранения RAID вы можете очень быстро вернуть все данные на место, но потеря аппаратного устройства может очень сильно сказаться на бюджете, особенно если вы такого не планировали.
Чтобы избежать таких проблем можно использовать пакет smartmontools. Это программный пакет для управления и мониторинга устройств хранения данных с помощью технологии Self-Monitoring Analysis and Reporting Technology или просто SMART.
Большинство современных ATA/SATA/SCSI/SAS накопителей информации предоставляют интерфейс SMART. Цель SMART — мониторинг надежности жесткого диска, для выявления различных ошибок и своевременного реагирования на их появление. Пакет smartmontools состоит из двух утилит — smartctl и smartd. Вместе они представляют мощную систему мониторинга и предупреждения о возможных поломках HDD в Linux. Дальше будет подробно рассмотрена проверка жесткого диска linux.
Установка Smartmontools
Пакет smartmontools есть в официальных репозиториях большинства дистрибутивов Linux, поэтому установка сводится к выполнению одной команды. В Debian и основанных на нем системах выполните:
sudo apt install smartmontools
sudo yum install smartmontools
Во время установки надо выбрать способ настройки почтового сервера. Можно его вовсе не настраивать, если вы не собираетесь отправлять уведомления о проблемах с диском на почту.

Отправлять почту получится только на веб-сервере, к которому привязан домен, на локальной машине можно выбрать пункт только для локального использования и тогда почта будет складываться в локальную папку и её можно будет посмотреть утилитой mail. Теперь можно переходить к диагностике жесткого диска Linux.
Проверка жесткого диска в smartctl
Сначала узнайте какие жесткие диски подключены к вашей системе:
ls -l /dev | grep -E ‘sd|hd’
В выводе будет что-то подобное:

Здесь sdX это имя устройства HDD подключенного к компьютеру.
Для отображения информации о конкретном жестком диске (модель устройства, S/N, версия прошивки, версия ATA, доступность интерфейса SMART) Запустите smartctl с опцией info и именем жесткого диска. Например, для /dev/sda:
smartctl —info /dev/sda

Хотя вы можете и не обратить внимания на версию SATA или ATA, это один из самых важных факторов при поиске замены устройству. Каждая новая версия ATA совместима с предыдущими. Например, старые устройства ATA-1 и ATA-2 прекрасно будут работать на ATA-6 и ATA-7 интерфейсах, но не наоборот. Когда версии ATA устройства и интерфейса не совпадают, возможности оборудования не будут полностью раскрыты. В данном случае для замены лучше всего выбрать жесткий диск SATA 3.2.
Запустить проверку жесткого диска ubuntu можно командой:
smartctl -s on -a /dev/sda

Здесь опция -s включает флаг SMART на указном устройстве. Вы можете его убрать если поддержка SMART уже включена. Информация о диске разделена на несколько разделов, В разделе READ SMART DATA находится общая информация о здоровье жесткого диска.
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment rest result: PASSED
Этот тест может быть пройден (PASSED) или нет (FAILED). В последнем случае сбой неизбежен, начинайте резервное копирование данных с этого диска.
Следующая вещь которую можно посмотреть, когда выполняется диагностика HDD в linux, это таблица SMART атрибутов.

В SMART таблице записаны параметры, определенные для конкретного диска разработчиком, а также порог отказа для этих параметров. Таблица заполняется автоматически и обновляется на основе прошивки диска.
- ID # — идентификатор атрибута, как правило, десятичное число между 1 и 255;
- ATTRIBUTE_NAME — название атрибута;
- FLAG — флаг обработки атрибута;
- VALUE — это поле представляет нормальное значение для состояния данного атрибута в диапазоне от 1 до 253, 253 — лучшее состояние, 1 — худшее. В зависимости от свойств, начальное значение может быть от 100 до 200;
- WORST — худшее значение value за все время;
- THRESH — самое низкое значение value, после перехода за которое нужно сообщить что диск непригоден для эксплуатации;
- TYPE — тип атрибута, может быть Pre-fail или Old_age. Все атрибуты по умолчанию считаются критическими, то-есть если диск не прошел проверку по одному из атрибутов, то он уже считается не пригодным (FAILED) но атрибуты old_age не критичны;
- UPDATED — показывает частоту обновления атрибута;
- WHEN_FAILED — будет установлено в FAILING_NOW если значение атрибута меньше или равно THRESH, или в «—» если выше. В случае FAILING_NOW, лучше как можно скорее выполнить резервное копирование, особенно если тип атрибута pre-fail.
- RAW_VALUE — значение, определенное производителем.
Сейчас вы думаете, да smartctl хороший инструмент, но у меня нет возможности запускать его каждый раз вручную, было бы неплохо автоматизировать все это дело чтобы программа запускалась периодически и сообщала мне о результатах проверки. И это возможно, с помощью smartd.
Автоматическая диагностика в smartd
Автоматическая диагностика HDD в Linux настраивается очень просто. Сначала отредактируйте файл конфигурации smartd — /etc/smartd.conf. Добавьте следующую строку:
/dev/sda -m myemail@mydomain.com -M test
- -m — адрес электронной почты для отправки результатов проверки. Это может быть адрес локального пользователя, суперпользователя или внешний адрес, если настроен сервер для отправки электронной почты;
- -M — частота отправки писем. once — отправлять только одно сообщение о проблемах с диском. daily — отправлять сообщения каждый день если была обнаружена проблема. diminishing — отправлять сообщения через день если была обнаружена проблема. test — отправлять тестовое сообщение при запуске smartd. exec — выполняет указанную программу в место отправки почты.
Сохраните изменения и перезапустите smartd:
sudo systemctl restart smartd
Вы должны получить на электронную почту письмо о том, что программа была запущена успешно. Это будет работать только если на компьютере настроен почтовый сервер.

Также можно запланировать тесты по своему графику, для этого используйте опцию -s и регулярное выражение типа T/MM/ДД/ДН/ЧЧ, где:
Здесь T — тип теста:
- L — длинный тест;
- S — короткий тест;
- C — тест перемещения (ATA);
- O — оффлайн тест.
Остальные символы определяют дату и время теста:
- ММ — месяц в году;
- ДД — день месяца;
- ЧЧ — час дня;
- ДН — день недели (от 1 — понедельник 7 — воскресенье;
- MM, ДД и ЧЧ — указываются с двух десятичных цифр.
Точка означает все возможные значения, выражение в скобках (A|B|C) — означает один из трех вариантов, выражение в квадратных скобках 4 означает диапазон (от 1 до 5).
Например, чтобы выполнять полную проверку жесткого диска linux каждый рабочий день в час дня добавьте опцию -s в строчку конфигурации вашего устройства:
/dev/sda -m myemail@mydomain.com -M once -s (L /../../1/13)
Если вы хотите чтобы утилита сканировала и проверяла все устройства, которые есть в системе используйте вместо имени устройства директиву DEVICESCAN:
DEVICESCAN -m myemail@mydomain.com -M once -s (L /../../4/13)
Проверка диска на ошибки в GUI
В графическом интерфейсе тоже можно посмотреть информацию из SMART. Для этого можно воспользоваться приложением Gnome Диски, откройте его из главного меню, выберите нужный диск, а затем кликните по пункту Данные самодиагностики и SMART в контекстном меню:

В открывшемся окне вы увидите те же данные диагностики SMART, а также все атрибуты SMART и их состояние:

Выводы
Если вы хотите быстро проверить механическую работу жесткого диска, посмотреть его физическое состояние или выполнить более-менее полное сканирование поверхности диска используйте smartmontools. Не забывайте выполнять регулярное сканирование, потом будете себя благодарить. Вы уже делали это раньше? Будете делать? Или используете другие методы? Напишите в комментариях!

Оцените статью:
Об авторе
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.
9 комментариев
Вы слишком замудрили в данной статье. Легче написать smartctl —scan и всё сразу видно.
И ещё у меня такую ошибку выдало Error 4324 occurred at disk power-on lifetime: 15035 hours (626 days + 11 hours)
А куда обращатся непонятно.
Подскажите пожалуйста, можно ли получить карту диска, наподобие таковой в виктории, программой под линукс?
Не знаю такой, как вариант после проверки диска командой:
ddrescue -n -f /dev/sdX /dev/null file.log
или после клонирования на другое устройство можно посмотреть графическую карту с помощью:
ddrescueview file.log
Консольный вариант: ddrescuelog -t file.log
whdd наверное хорошо, только deb пакетов нет, а из исходников не собирается.
hard disk sentinel через ./ запустил и окей
Здравствуйте!
У меня получается непонятка.
По smart характеристикам диск хороший,
но после запуска самотестирования выдает ошибки чтения в одних и тех же секторах
Что это значит?
счас приведу выхлоп
sudo smartctl —all /dev/sda
.
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 100 050 Pre-fail Always — 0
2 Throughput_Performance 0x0005 100 100 050 Pre-fail Offline — 0
3 Spin_Up_Time 0x0027 100 100 001 Pre-fail Always — 1795
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always — 3920
5 Reallocated_Sector_Ct 0x0033 100 100 050 Pre-fail Always — 0
7 Seek_Error_Rate 0x000b 100 100 050 Pre-fail Always — 0
8 Seek_Time_Performance 0x0005 100 100 050 Pre-fail Offline — 0
9 Power_On_Hours 0x0032 074 074 000 Old_age Always — 10664
10 Spin_Retry_Count 0x0033 178 100 030 Pre-fail Always — 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always — 3627
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always — 372
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always — 67
193 Load_Cycle_Count 0x0032 096 096 000 Old_age Always — 49523
194 Temperature_Celsius 0x0022 100 100 000 Old_age Always — 36 (Min/Max 7/47)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always — 0
197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always — 272
198 Offline_Uncorrectable 0x0030 100 100 000 Old_age Offline — 7
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always — 0
220 Disk_Shift 0x0002 100 100 000 Old_age Always — 0
222 Loaded_Hours 0x0032 076 076 000 Old_age Always — 9681
223 Load_Retry_Count 0x0032 100 100 000 Old_age Always — 0
224 Load_Friction 0x0022 100 100 000 Old_age Always — 0
226 Load-in_Time 0x0026 100 100 000 Old_age Always — 266
240 Head_Flying_Hours 0x0001 100 100 001 Pre-fail Offline — 0
в то же время внутренний лог говорит о фиксации 79 ошибок:
SMART Error Log Version: 1
ATA Error Count: 79 (device log contains only the most recent five errors)
а вот результаты самотестирования, которые я запускал:
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Selective offline Completed: read failure 00% 10662 516606384
# 2 Selective offline Completed: read failure 00% 10662 516606376
# 3 Selective offline Completed: read failure 00% 10662 516606376
# 4 Selective offline Completed: read failure 00% 10662 516606368
# 5 Selective offline Completed: read failure 00% 10662 516606368
# 6 Selective offline Completed: read failure 00% 10661 164354232
# 7 Selective offline Completed without error 00% 10661 —
# 8 Selective offline Completed: read failure 00% 10661 102832
# 9 Selective offline Completed: read failure 00% 10660 100296
#10 Short offline Completed: read failure 00% 10660 100296
#11 Selective offline Completed without error 00% 10660 —
#12 Short offline Completed: read failure 00% 10659 100296
#13 Extended offline Completed: read failure 00% 10371 100296
#14 Extended offline Aborted by host 90% 10367 —
#15 Short offline Completed: read failure 00% 10367 100296
#16 Short offline Completed: read failure 00% 10367 100296
#17 Short offline Completed: read failure 00% 10363 100296
#18 Short offline Completed: read failure 00% 10363 100296
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 516606384 1953525160 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
из них видно куча bad секторов, а смарт атрибуты(выше) говорят что все ок.
Что это означает, не подскажете?
Источник



