- Как узнать кодировку файловой системы?
- Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- Re: Как узнать кодировку файла или просто набора символов?
- linux узнать кодировку файла
- iconv и большие файлы
- Как узнать кодировку файла в Ubuntu Linux: 5 комментариев
- Программы для определения кодировки в Linux
- Команда file -i показывает неверную кодировку
- Программа enca для определения кодировки файла
- Как определить кодировку строки
- Изменение кодировки в Linux
- Использование команды iconv
- Конвертирование файлов из windows-1251 в UTF-8 кодировку
- Изменение кодировки программой enca
- Конвертация строки в правильную кодировку
Как узнать кодировку файловой системы?
Как узнать кодовые таблицы, используемые для именования файлов
файловой подсистемой Linux и Windows, из программы на Си (gcc, MinGW32)?
Например, файловых систем Ext3, XFS, NTFS, FAT32?


В Linux у файловых систем нет кодировки, имена пишутся напрямую, без какого-либо преобразования. Считайте что кодировка имён файлов совпадает с текущей локалью.

Что ж тогда модули ядерные делают с таблицами кодировок?

>В Linux у файловых систем нет кодировки, имена пишутся напрямую, без какого-либо преобразования
Ага. Особенно когда под линуксом где-то примонтирована файловая система NTFS, в которой Unicode вшит по определению.
Преобразования делаются по-любому и при монтировании кодировки указываются. Если честно, точно не знаю где и как это делается, но думаю для каждой примонтированой fs есть отдельная настройка какое преобразовании надо осуществлять из текущей локали в кодировку fs и обратно.

Вообще-то,  Eshkin_kot правильно сказал: мало ли какая ФС у вас примонтирована, все равно в опциях монтирования указывается текущая локаль. Так что париться на этот счет не надо. А уж узнать кодировку имен файлов «родной» линуксовой системы без enca невозможно: у меня, например, USB-HDD, локаль — koi8-r; если я подключу этот винт человеку с юникодом, ясное дело, вместо русских имен файлов у него будет черт те что, и узнать, какая же кодировка там на самом деле, можно только так: ls . | enca.
Eshkin_kot правильно сказал: мало ли какая ФС у вас примонтирована, все равно в опциях монтирования указывается текущая локаль. Так что париться на этот счет не надо. А уж узнать кодировку имен файлов «родной» линуксовой системы без enca невозможно: у меня, например, USB-HDD, локаль — koi8-r; если я подключу этот винт человеку с юникодом, ясное дело, вместо русских имен файлов у него будет черт те что, и узнать, какая же кодировка там на самом деле, можно только так: ls . | enca.
Признаю. Был не прав. Похоже ext2/ext3 не делает преобразований. Это делается в fat/ntfs.
> Признаю. Был не прав. Похоже ext2/ext3 не делает преобразований. Это делается в fat/ntfs.
Ещё в cifs/smbfs, iso9660, jfs, . Причём это преобразование не зависит от локали пользовательского процесса, а задаётся жёстко, одно на всех, при монтировании 🙁
На этот случай в mc есть новая очень полезная штука — преобразование кодировки в панели. При копировании тоже можно сделать преобразование. Правда, с юникодом пока не работает — приходится после копирования таких файлов переименовывать их в КОИ-8 скриптиком.
есть ещё convmv, fuse-convmvfs только это всё костыли, из-за того что в Linux у файловых систем нет кодировки. 🙁
в Linux у файловых систем нет кодировки
А зачем файловой системе кодировка? ФС наплевать, как вы обзовете файл. Этим уже ядро и пользовательские процессы занимаются. А узнать кодировку труда не составляет.

Именно. Для файловой системы имя файла — набор байт. Интерпретация этих последовательностей байтов возлагается на пользовательские программы. Можно иметь одновременно файлы в одной директории с именами во множестве кодировок.

А зачем файловой системе кодировка? ФС наплевать, как вы обзовете файл. Этим уже ядро и пользовательские процессы занимаются.
Кстати, очень ценное замечание, жаль что такое понимание приходит с опытом, а не прописывается в манах изначально.
Действительно, в опциях монтирования кодировка не указывается явно.
Хотя вот для ntfs есть опции
Но это, видимо, для решения проблемы состыковки кодировок разной битности , а не состыковки разных кодировок одинаковой битности.
И для стыковки кодировок одинаковой битности. Как по-вашему, я могу прочитать русские имена файлов/директорий на флешке в fat32 или на диске, записанном в мастдае (без рокриджа), когда у меня кодировка КОИ-8? Той же опцией iocharset=koi8-r 🙂
Вот это и странно, ведь согласно идее http://www.linux.org.ru/jump-message.jsp?msgid=4509712&cid=4511106 программе монтирования должно быть пофиг на кодировку.
Это дело файлового менеджера или другой программы, с помощью которой проводится чтение/запись.
Тогда лучше считать, что опция монтирования iocharset= излишне умничает и пытается влезть не в свой «домен». Ведь, действительно, в общем случае на ФС могут быть файлы в разных кодировках, e.g. диски со школьным линуксом 😉
А ей и так пофиг. Это просто опция, облегчающая жизнь пользователю.
>Это дело файлового менеджера или другой программы, с помощью которой проводится чтение/запись
имхо, преобразование имен файлов из кодировки, в которой они были первоначально туда записаны какой-либо не очень продвинутой осью, в локальную кодировку всей системы лежит как раз на плечах драйвера ФС.
в случае, если они совпадают — никаких действий производить не надо.
в принципе это и есть действие по умолчанию. т.е. если специально не указано драйвер считает, что кодировка на ФС совпадает с текущей кодировкой локали.
а если указать, что на фс файлы в utf8, а локаль при этом koi8-r — надо конвертить.
> в локальную кодировку всей системы
В Linux нет локальной кодировки всей системы, каждая программа может иметь свою локаль и кодировку.
в принципе это и есть действие по умолчанию. т.е. если специально не указано драйвер считает, что кодировка на ФС совпадает с текущей кодировкой локали.
вообщето нет 🙂 если почитать man mount то можно увидеть что например для iso9660: «The default is iso8859-1», для fat: «By default, codepage 437 is used.» (это кодировка на диске) + «iocharset . The default is iso8859-1» (это кодировка локали).
>iso9660: «The default is iso8859-1»,
это, можно считать, не попадает под мои слова «если специально не указано»)
В Linux нет локальной кодировки всей системы, каждая программа может иметь свою локаль и кодировку.
да, немного перепутал. имел в виду кодировку и локаль текущего приложения.
При компиляции ядра можно указать правильную кодировку для vfat и локаль системы. Так что эти умолчания работают только для дефолтных ядер.
Источник
Как узнать кодировку файла или просто набора символов?
Пришла в GAIM кракозяка — пробовал разные варианты с iconv — все без толку. Правильно я понимаю — человеческий текст не восстановить, т.к. она запорчен? НА будущее: как узнать в какой кодировке кракозяквы?


Re: Как узнать кодировку файла или просто набора символов?
Перебором и проверкой результата по словарю. Рекомендую еще посмотреть на этот баг: http://developer.pidgin.im/ticket/1645 — там упоминается такой перл, как «I confirm that converting that from UTF-16 to Windows-1251 results in that valid UTF-8 string».

Re: Как узнать кодировку файла или просто набора символов?
Re: Как узнать кодировку файла или просто набора символов?
pidgin ненужен. licq — наше всьо
Re: Как узнать кодировку файла или просто набора символов?
>echo «message» | iconv -f utf-8 -t cp1251 уже пробовали?
iconv: illegal input sequence at position 0
Да хрен с ним с Пиджин то. Интересно вообще: есть набор символов псевдограифики и ощущение того, что за ними скрывается осмысленный текст. Как за разумное время его прочитать?

Re: Как узнать кодировку файла или просто набора символов?
>pidgin ненужен. licq — наше всьо
licq может irc, jabber?
Re: Как узнать кодировку файла или просто набора символов?
Re: Как узнать кодировку файла или просто набора символов?
for e in `iconv -l`; do echo $e; iconv -f $e /dev/null | less
Если в образце лежит осмысленный текст, то обычно за него легко зацепиться глазом при просмотре выхлопа этой команды. Конечно, это не поможет в случае дважды закодированного текста.
Re: Как узнать кодировку файла или просто набора символов?

Re: Как узнать кодировку файла или просто набора символов?

Re: Как узнать кодировку файла или просто набора символов?
Есть такая хорошая штука, konwert.
Re: Как узнать кодировку файла или просто набора символов?
>Есть такая хорошая штука, konwert.
Любопытная вещь. Спасибо — не знал. Она определила кодировку, оказалось непонятно как cp866. Вот только результат работы команды
]iconv —verbose erunda.txt —from-code cp866 —to-code utf-8 -o erundautf
более чем странный. Вот например кусок (не знаю как будет в браузере читаться конечно)
Re: Как узнать кодировку файла или просто набора символов?
Декодер этот Артемия Лебедева вообще ужас показывает.
Источник
linux узнать кодировку файла
Давно в категории «Ubuntu» у меня не было материалов. Сегодня я исправлюсь и выпущу сразу две статьи. Итак, начнём. вам приходилось менять кодировку текстовых файлов в linux’e? А что если объем такого файла больше 10 Gb?!
Что бы изменить кодировку файла нужно использовать замечательную утилиту iconv. В параметрах необходимо указывать исходную кодировку, а в этом нам поможет команда:
Ну а далее вот такие действия:
iconv -f WINDOWS-1251 -t UTF-8 -o output_file.txt original_file.txt
- -f WINDOWS-1251 — исходная кодировка,
- -t UTF-8 — конечная
- -o output_file.txt — куда выводить результат
- original_file.txt — исходный файл
Остальные ключики как обычно в man iconv.
iconv и большие файлы
Для быстрого выполнения процесса кодировки, iconv загружает файл в оперативную память и в swap. Но это работает только для небольших файлов. Если файл уж совсем большой, а ОЗУ не особо, то вы прост получите ошибку, мол «слишком большой файл», звиняйте хлопцы. Где взять такой файл? К примеру это может быть выборка из БД ( игры для ipad, PC, PSP или другие данные)
Вот здесь предлагают различные решения данного вопроса: и скриптами, и разбивка на части, вывод в потоки, а потом обратно сборка в файл. Лично мне понравилось весьма простое решение: команда split — она позволяет разбить текстовый файл на более мелкие, а дальше с ними работать как угодно можно.
В простом варианте чтобы разбить файл на куски объёмом по 1Gb выполнить:
Это самые просты решения, эти команды можно использовать в различных скриптах и получить от этого много кайфов. Надеюсь эта заметка вам чем-то помогла.
К сожалению ни в gEdit, ни в Leafpad я не нашёл функции, которая бы могла сказать в какой кодировке находится файл. Но на выручку, как всегда приходить консоль:
file -i file.txt
Как узнать кодировку файла в Ubuntu Linux: 5 комментариев
�� Тоже недавно наткнулся на этот совет.. Обязательно поможет кому нибудь…
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
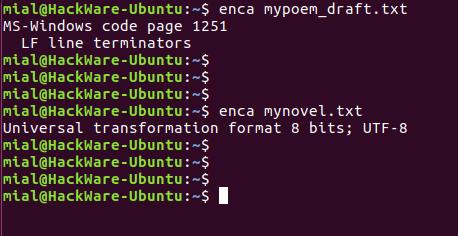
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
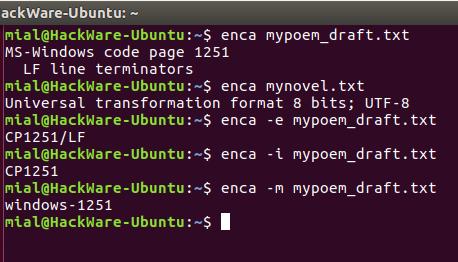
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
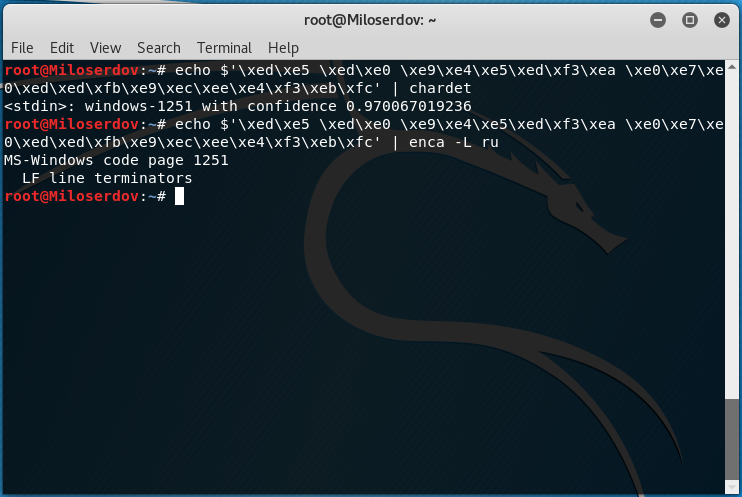
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
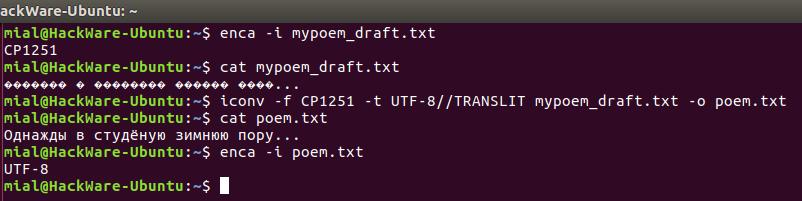
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
Источник



