- Устанавливаем ZFS в Linux — часть 2. ZVols, LZ4, ARC, и ZILs
- ZFS Volumes или ZVols
- LZ4 compression
- L2ARC
- Монтируем XML как dataset
- lz4 (1) — Linux Man Pages
- lz4: lz4, unlz4, lz4cat — Compress or decompress .lz4 files
- SYNOPSIS
- DESCRIPTION
- Difference between lz4 and gzip
- Concatenation of .lz4 files
- OPTIONS
- Short commands concatenation
- Multiple commands
- Operation mode
- Operation modifiers
- Как распаковать файлы jsonlz4 (резервные копии закладок Firefox) с помощью командной строки?
- Как я писал LZ4 плагин компрессии для Reiser4
Устанавливаем ZFS в Linux — часть 2. ZVols, LZ4, ARC, и ZILs
В прошлой статье мы коснулись конфигурации и основ использования ZFS в Linux. Мы выяснили как устанавливать ZFS в различные дистрибутивы,как создавать снэпшоты, клоны, и [simple_tooltip content=’Набор данных. Общее название следующих объектов ZFS: клонов, файловых систем, снимков или томов. Каждый набор данных идентифицируется по уникальному имени в пространстве имен ZFS.’] датасеты(dataset)[/simple_tooltip]. ZFS включает в себя множество дополнительных функций, таких как ZVols и ARC. В этой статье я попытаюсь объяснить их полезность.
Если не читали первую статью, то рекомендую ознакомиться сначала с ней Устанавливаем ZFS в Linux. Установка и настройка
ZFS Volumes или ZVols
По сути ZVols или «Z том» — набор данных, используемый для эмулирования физического устройства. ZVols могут использоваться в качестве устройств хранения блоков другими системами.
Для создания ZVol выполните в терминале:
Выполнив ls вы увидите примерно следующее:
В моём примере ZVol располагается в /dev/zvol/testpool/zvoltest1.
Вы можете использовать его иначе, например, /dev/sda3 или /dev/sdd5. Чтобы пробросить его в виртуальной машине, вы можете использовать Z Volume вместо файла .img, как в примере на изображении ниже:
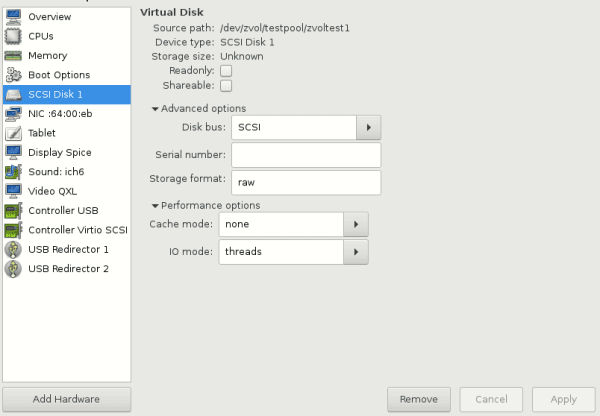
Обратите внимание на режим кэша (Cache Mode) и режим ввода-вывода(I/O mode). Эти настройки, могут предотвратить подвисания ввода-вывода и увеличить отзывчивость.
Помимо виртуализации, ZVols также широко примененим. Например его можно использовать по типу раздела подкачки (Swap). Как указано на ZoL Wiki, Swap тома могут быть созданы такими нехитрыми манипуляциями :
Конечно «4G» необходимо заменить на необходимый вам размер тома подкачки. После чего форматируем его и включаем:
Ну и последний пример использования ZVols, о котором я упомяну в этой статье, это возможность использование других файловых систем поверх Z Volume. Это удобно и применимо например в тех случаях, когда ваше приложение не поддерживает ZFS, то вы легко можете накатить поверх ZVol любую файловую систему, например ext4:
LZ4 compression
ZFS имеет нативную поддержку сжатия с удивительно низкой нагрузкой на процессор. LZ4, является наиболее подходящим для этого алгоритмом сжатия. Он может быть установлен, как для датасета так и для ZVol:
При использовании сжатия можно использовать значительно меньшее дисковое пространство для хранения того же объема данных. С ZFS в Linux, сжатие полностью прозрачно и происходит что называется «на лету» так что все приложения должны работать с ним.
ARC, или «адаптивно заменяемый кэш» (adaptive replacement cache) это кэш ZFS встроенный в ОЗУ. Он более агрессивен, чем встроенное кэширование оперативной памяти Linux.
ARC или «адаптивный кеш замены» — это встроенный кеш ZFS в ОЗУ. Он намного более агрессивный, чем встроенное кэширование оперативной памяти Linux. По этой причине некоторые пользователи могут обнаружить, что кеш ARC использует слишком большую часть их оперативной памяти. Тогда как им следовало бы знать, что свободная оперативная память — это потерянная оперативная память. OpenZFS предлагает достаточно широкие настройки использования кеша ARC. Вы можете настроить его с помощью параметров ядра. Для GRUB найдите следующую строку в файле /etc/default/grub:
Добавьте строку “zfs.zfs_arc_max=(size)” указав размер в байтах:
После чего перезапишите конфигурационный файл GRUB с учётом изменений:
Для повышения производительности рекомендуется делать это значение настолько большим, насколько позволяет ваше ОЗУ.
L2ARC
Level 2 ARC — великолепное решение для тех, кто хочет получить высокую скорость от механических жестких дисков. С помощью него, вы можете использовать быстрый диск, например SSD, для кэширования данных. Чтобы добавить L2ARC, выполните следующие действия:
Где вместо ID_ВАШЕГО_УСТРОЙСТВА вам следует указать ID из /dev/disk/by-id/. Например:
Поскольку L2ARC улучшает производительность чтения, кэшируя его на более быстром диске, ZIL делает то же самое только для записи. Таким образом, он, вероятно, не нужен, если у вас нет рабочей нагрузки с интенсивной записью. Добавление ZIL почти идентично добавлению L2ARC:
Монтируем XML как dataset
Вы можете создать полностью раздельный набор данных для хранения XML-файлов libvirt. Libvirt хранит XML-файлы в /etc/libvirt/qemu. Для этого, вам следует временно переместить все файлы, создать датасет, смонтировать его и переместить файлы на него.
Это всё что требуется. теперь вы можете создавать снэпшоты poolname/xml датасета и откатываться к ним после неудачного изменения XML файлов.
Статья является переводом с английского статьи Ryan El Kochta: «ZFS Configuration Part 2: ZVols, LZ4, ARC, and ZILs Explained»
Источник
lz4 (1) — Linux Man Pages
lz4: lz4, unlz4, lz4cat — Compress or decompress .lz4 files
Command to display lz4 manual in Linux: $ man 1 lz4
lz4 — lz4, unlz4, lz4cat — Compress or decompress .lz4 files
SYNOPSIS
unlz4 is equivalent to lz4 -d
lz4cat is equivalent to lz4 -dcfm
When writing scripts that need to decompress files, it is recommended to always use the name lz4 with appropriate arguments ( lz4 -d or lz4 -dc ) instead of the names unlz4 and lz4cat .
DESCRIPTION
Difference between lz4 and gzip
Default behaviors can be modified by opt-in commands, detailed below. • lz4 -m makes it possible to provide multiple input filenames, which will be compressed into files using suffix .lz4 . Progress notifications become disabled by default (use -v to enable them). This mode has a behavior which more closely mimics gzip command line, with the main remaining difference being that source files are preserved by default. • Similarly, lz4 -m -d can decompress multiple *.lz4 files. • It’s possible to opt-in to erase source files on successful compression or decompression, using —rm command. • Consequently, lz4 -m —rm behaves the same as gzip .
Concatenation of .lz4 files
Then lz4cat foo.lz4 is equivalent to cat file1 file2 .
OPTIONS
Short commands concatenation
Multiple commands
Operation mode
Operation modifiers
0.5%), while decompression speed will be improved by 5-20%, depending on use cases. This option only works in combination with very high compression levels (>=10). -D dictionaryName Compress, decompress or benchmark using dictionary dictionaryName . Compression and decompression must use the same dictionary to be compatible. Using a different dictionary during decompression will either abort due to decompression error, or generate a checksum error. -f —[no-]force This option has several effects: If the target file already exists, overwrite it without prompting. When used with —decompress and lz4 cannot recognize the type of the source file, copy the source file as is to standard output. This allows lz4cat —force to be used like cat (1) for files that have not been compressed with lz4 . -c —stdout —to-stdout Force write to standard output, even if it is the console. -m —multiple Multiple input files. Compressed file names will be appended a .lz4 suffix. This mode also reduces notification level. Can also be used to list multiple files. lz4 -m has a behavior equivalent to gzip -k (it preserves source files by default). -r operate recursively on directories. This mode also sets -m (multiple input files). -B# Block size 5(default : 7)
-B4 = 64KB ; -B5 = 256KB ; -B6 = 1MB ; -B7 = 4MB -BI Produce independent blocks (default) -BD Blocks depend on predecessors (improves compression ratio, more noticeable on small blocks) —[no-]frame-crc Select frame checksum (default:enabled) —[no-]content-size Header includes original size (default:not present)
Note : this option can only be activated when the original size can be determined, hence for a file. It won’t work with unknown source size, such as stdin or pipe. —[no-]sparse Sparse mode support (default:enabled on file, disabled on stdout) -l Use Legacy format (typically for Linux Kernel compression)
Note : -l is not compatible with -m ( —multiple ) nor -r
Источник
Как распаковать файлы jsonlz4 (резервные копии закладок Firefox) с помощью командной строки?
Кажется, существуют разные способы распаковки JavaScript и браузера, но не существует ли способа преобразовать файлы jsonlz4 во что-то, что unlz4 будет читать?
Я смог распаковать jsonlz4 с помощью lz4json :
Сохраните этот скрипт в файле, например mozlz4 :
Фактически почти все файлы lz4 профиля Firefox являются файлами mozlz4 . Это означает, что они имеют одинаковый «заголовок формата файла». За исключением одного файла. Я говорю о файле webext.sc.lz4 . Он имеет mozJSSCLz40v001\0 заголовок файла и, возможно, некоторую sc упаковку для упаковки группы файлов в поток байтов.
Существует аддон Firefox для чтения или компресс .mozlz4 текстовые файлы mozlz4-редактировать
Достаточно настойчивый поиск в Google для этого приводит ко многим решениям, но большинство из них, кажется, либо (а) нарушено последующими изменениями в базовых библиотеках, либо (б) излишне сложным (по крайней мере, на мой личный вкус), что делает их неуклюжим заглянуть в существующий код.
Следующее, кажется, работает по крайней мере на Python 2.7 и 3.6 с использованием последней версии привязок Python LZ4 :
Конечно, это не пытается проверить входные данные (или выходные данные), не предназначено для обеспечения безопасности и т. Д., Но если кто-то просто хочет иметь возможность анализировать собственные данные FF, он выполняет основную работу.
Командная строка версии здесь , которые могут быть сохранены в соответствующем каталоге и вызывается из командной строки , как:
Источник
Как я писал LZ4 плагин компрессии для Reiser4

Объяснять что такое Reiser4 и с чем его едят я не буду, т. к. на этот счет достаточно информации [1, 2] и повторять её я не вижу смысла. Поэтому начну пожалуй с того, что Reiser4 я решил опробовать в 2010 году, но из-за проблем использования прозрачной компрессии совместно с упаковкой хвостов (как оказалось были проблемы в flush процедуре, которые на данный момент решены[3]) перешел обратно на ReiserFS. В 2013 году я узнал о том, что эта проблема решена [4] и я снова вернулся на Reiser4 (LZO1 на стационарной системе, на ноутбуке без сжатия). Через какое-то время я вспомнил про новости о «Чрезвычайно быстром алгоритме сжатия» LZ4, а так-же о том, что комьюнити Illumos добавило поддержку оного в ZFS. Тут меня посетила мысль: «А было-бы здорово будь в Reiser4 поддержка LZ4»! Вот я и начал «приделывать» его к Reiser4.
Сначала я просмотрел код плагина ccreg40 (как известно Reiser4 имеет плагиновую структуру). Все начинается с файла fs/reiser4/plugin/compress/compress.h в котором есть перечисление reiser4_compression_id:
В нем обозначаются идентификационные номера того или иного алгоритма сжатия (по умолчанию доступны LZO1 и GZIP1). Последним в списке идет LAST_COMPRESSION_ID, который нужен для определения размеров различных таблиц содержащих информацию о алгоритмах и сопутствующих им функций.
Продолжаем мы в файле fs/reiser4/plugin/compress/compress.c, в котором мы уже непосредственно описываем функции. Всего 7-мь основных функций:
- init() – Нужна, если алгоритм требует предварительной инициализации чего-либо. Ни GZIP1, ни LZO1, ни LZ4 этого не требуют, поэтому они просто возвращают 0.
- overrun() – Возвращает максимальный размер «хвоста», который может образоваться при сжатии. К примеру если не учитывать «хвост», то при несжимаемых входящих данных, произойдет выход за пределы выходного буфера. К примеру для GZIP1 это значение составляет 0, для LZO1 “src_len/64+19”, а для LZ4 “src_len/255+16”.
- alloc() – Выделяет память для нужд алгоритма.
- free() – Освобождает память, выделенную для нужд алгоритма.
- min_size_deflate () – Возвращает минимальный размер блока, который все еще имеет смысл сжимать.
- compress() – Сжимает данные.
- decompress() – Распаковывает данные.
Подробнее остановлюсь на функциях alloc()/free(). Один из аргументов которые они принимают, значится аргумент act типа tfm_action. tfm_action является перечислением описанным в заголовочном файле fs/reiser4/plugin/compress/compress.h (имеет такую-же структуру как и reiser4_compression_id), в котором два элемента TFMA_READ и TFMA_WRITE.
Таким образом можно определить момент, вызывания функции, при чтении или при записи. Некоторые алгоритмы требуют дополнительную память для декомпрессии, и таким образом мы правильно выделим нужное количество памяти. К примеру алгоритм GZIP1 требует дополнительной памяти и мы выделяем для него оную, а алгоритмы LZO1/LZ4 не требуют и мы не выделяем её.
Заканчивается все в том-же файле compress.c, описанием массива compression_plugins, в котором мы указываем тип плагина, его идентификационный номер, заголовок, функции и т. д.
Теперь о том, что я изменил в коде LZ4. Для начала я убрал весь код связанный с Microsoft Visual Studio (может когда-нибудь и соберут ядро Linux посредством компилятора MS VS, но явно это будет не в ближайшем будущем) и C++ (один extern “C”). Затем убрал код, связанный с оптимизацией для BigEndian систем, которая делала выходную информацию несовместимой с LittleEndian системами и код, позволяющий использовать стековую память вместо обычной (получится быстрее, но мы в ядре, нам такие вольности не пройдут даром). Напоследок убрал из кода функции malloc()/free(), добавив в список аргументов функций указатель на участок памяти, выделенной для нужд LZ4 (вспомните alloc()).
Ну а теперь самое главное, как все это работало… откровенно говоря, плохо. Плагин LZ4 работал медленнее и сжимал хуже плагина LZO1. Замеры проводились на живой системе, в однопользовательском режиме. В замер входила операция размонтирования раздела (чтоб сработали sync/flush процедуры и файлы полностью записались на диск). Производилось три теста: линейное запись/чтение на диск файла забитого нулями (из /dev/zero), линейное чтение/запись несжимаемого файла (предварительно взятого с /dev/urandom и записанного в память на tmpfs) и распаковка/сжатие исходных кодов ядра Linux версии 3.9.5. Из всех тестов, плагин с LZ4 показал преимущество только при записи/чтении файла с нулями. Во всех остальных тестах, LZO1 обошел LZ4 и по скорости сжатия/декомпрессии, и по конечному объему файлов.
В ходе дальнейших исследований (fullbench из состава LZ4 и lz4c vs lzop), было выяснено, что LZ4 теряет все свои свойства при блоках маленького размера, а проявляет заявленные свойства [5] только на больших блоках, к примеру в fullbench по умолчанию 4MiB, в lz4c 8MiB. Как выразился Эдуард Шишкин: «4MiB — это как-то многовато. LZO1 сжимает куски и много мельче..» [6]
Таким образом я выяснил, что для Reiser4 LZO1 является более предпочтительным вариантом, ежели LZ4. Кстати говоря, что-то мне подсказывает, что поддержка LZ4, которая была добавлена сообществом, в ZFS будет проявлять себя далеко не всегда (хотя по сравнению с LZJB всегда), и безуспешные попытки протолкнуть LZ4 в Linux [7] (в качестве возможности использования для сжатия ядра или initram) тому подтверждение. Что до LZ4 в btrfs… Эдуард Шишкин наглядно рассказал о том, что из себя представляет btrfs [8] и как ведется его разработка.
Источник



