Отладка дампов Linux
Эта статья относится к: ✔️ пакету SDK для .NET Core 3.0 и более поздних версий
Сбор дампов в Linux
Два рекомендуемых способа сбора дампов в Linux:
- Средство CLI dotnet-dump
- Переменные среды для сборки дампов при аварийном завершении
Управляемые дампы с помощью dotnet-dump
Средство dotnet-dump просто в использовании и не зависит от каких-либо отладчиков машинного кода. dotnet-dump работает на различных платформах Linux (например, Alpine или ARM32/ARM64), где традиционные средства отладки могут быть недоступны. Однако dotnet-dump фиксирует только управляемое состояние, поэтому его нельзя использовать для отладки в машинном коде. Дампы, собранные dotnet-dump , анализируются в среде с той же ОС и архитектурой, в которой был создан дамп. Средство dotnet-gcdump можно использовать в качестве альтернативного варианта, которое фиксирует только сведения о куче GC, но создает дампы, которые можно проанализировать в Windows.
Дампы ядра с помощью createdump
Вместо dotnet-dump , создающего только управляемые дампы, createdump рекомендуется для создания основных дампов в Linux, содержащих как собственные, так и управляемые данные. Другие средства, такие как gdb или gcore, можно также использовать для создания основных дампов, однако они могут не учитывать состояние, необходимое для управляемой отладки, что приводит к неизвестному типу или именам функций во время анализа.
Средство createdump устанавливается вместе со средой выполнения .NET Core. Его можно найти рядом с libcoreclr.so (обычно в папке /usr/share/dotnet/shared/Microsoft.NETCore.App/[версия]). Средство использует идентификатор процесса для получения дампа в качестве основного аргумента, а также может принимать необязательные параметры, указывающие, какой тип дампа следует сохранять (по умолчанию используется малый дамп с кучей). Возможны следующие значения.
Исходный файл трассировки для преобразования. По умолчанию используется значение trace.nettrace.
Параметры
-f|—name
Файл, в который записывается дамп. Значение по умолчанию — «/tmp/coredump.%p», где % p — это идентификатор целевого процесса.
-n|—normal
-h|—withheap
Создание минидампа с кучей (по умолчанию).
-t|—triage
Создание минидампа для рассмотрения.
-u|—full
Создайте полного дампа ядра.
-d|—diag
Включение диагностических сообщений.
Для сбора дампов ядра требуется либо возможность SYS_PTRACE , либо createdump необходимо запустить с помощью sudo или su.
Анализ дампов в Linux
Как управляемые дампы, собранные с помощью dotnet-dump , так и дампы ядра, собранные с помощью createdump , можно проанализировать с помощью средства dotnet-dump , используя команду dotnet-dump analyze . dotnet dump требует, чтобы среда, в которой анализируется дамп, использовала ту же ОС и архитектуру, что и среда, в которой был записан дамп.
Кроме того, LLDB можно использовать для анализа основных дампов в Linux, что позволяет выполнять анализ как управляемых, так и собственных кадров. LLDB использует расширение SOS для отладки управляемого кода. Средство dotnet-sos CLI можно использовать для установки SOS, в котором содержится много полезных команд для отладки управляемого кода. Чтобы проанализировать дампы .NET Core, для LLDB и SOS требуются следующие двоичные файлы .NET Core из среды, в которой был создан дамп.
- libmscordaccore.so
- libcoreclr.so
- dotnet (узел, используемый для запуска приложения)
В большинстве случаев эти двоичные файлы можно скачать с помощью средства dotnet-symbol . Если необходимые двоичные файлы невозможно загрузить с помощью dotnet-symbol (например, если используется частная версия .NET Core, построенная на основе источника), может потребоваться скопировать перечисленные выше файлы из среды, в которой был создан дамп. Если файлы не расположены вместе с файлом дампа, можно использовать команду LLDB/SOS setclrpath
, чтобы задать путь, из которого они должны быть загружены, и setsymbolserver -directory
, чтобы задать путь для поиска файлов символов.
После того как необходимые файлы будут доступны, можно загрузить дамп в LLDB, указав узел dotnet в качестве исполняемого файла для отладки:
В приведенной выше командной строке — это путь к дампу для анализа, а — это собственная программа, запускающая приложение .NET Core. Обычно это двоичный файл dotnet , если приложение не является автономным. В этом случае это имя приложения без расширения DLL.
После запуска LLDB может потребоваться использовать команду setsymbolserver , чтобы указать правильное расположение символов ( setsymbolserver -ms , чтобы использовать сервер символов корпорации Майкрософт, или setsymbolserver -directory
для указания локального пути). Собственные символы можно загрузить, запустив loadsymbols . На этом этапе для анализа дампа можно использовать команды SOS.
Источник
Получение и анализ содержимого памяти в ОС Linux
В данной статей мы рассмотрим метод удаленного получения образа памяти при помощи LiME в системе на базе CentOS 6.5 x64.

Автор: Дэн Кэбен (Dan Caban)
Раньше образ памяти в системах на базе ОС Linux можно было получить напрямую (при помощи утилиты dd) из файлов псевдоустройств, таких как /dev/mem и /dev/kmem. В последних версиях ядра доступ к этим устройствам стал ограничен и/или полностью исключен. Чтобы исследователи и системные администраторы могли получить неограниченный доступ, были разработаны загружаемые модули, которые, к примеру, доступны в проектах fmem и LiME (Linux Memory Extractor).
В данной статей мы рассмотрим метод удаленного получения образа памяти при помощи LiME в системе на базе CentOS 6.5 x64.
LiME – загружаемый модуль ядра (Loadable Kernel Module, LKM). Загружаемые модули обычно разрабатываются с целью расширения функционала ядра. Модуль можно добавить, используя учетную запись с привилегиями суперпользователя. При установке модуля следует быть осторожным, поскольку некорректная его установка несет потенциальные риски для целевой системы. С другой стороны, LiME обладает рядом несомненных преимуществ:
- Скомпилированный модуль довольно небольшого размера.
- Процедура установки не требует перезагрузки.
- Модуль легко добавляется или удаляется.
- Полученный дамп памяти можно скачать удаленно без записи на локальный диск целевой системы.
- Дамп памяти совместим с фреймворком Volatility.
Подготовка к работе
Поскольку LiME распространяется в виде исходных текстов, для начала необходимо его скомпилировать. Всю доступную информацию можно легко найти в интернете, но перед этим рекомендую вам поискать скомпилированные версии модуля или скомпилировать и протестировать его на виртуальной машине.
В любом случае для начала необходимо узнать версию ядра на целевой машине.
]$ uname -a
Linux localhost.localdomain 2.6.32-431.5.1.el6.x86_64 #1 SMP
Wed Feb 12 00:41:43 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
Скомпилированные версии LiME-модулей можно взять в Linux Forensics Tools Repository at Cert.org (этот ресурс заслуживает доверия). Там хранятся RPM-репозитарии аналитических утилит для Red Hat Enterprise Linux, CentOS и Fedora.
Чтобы найти скомпилированный модуль для определенной версии ядра и операционной системы зайдите на Cert и найдите «repoview» для целевой операционной системы

Рисунок 1: Раздел с репозитариями для CentOS
Далее зайдите в раздел «applications/forensics tools» и откройте документацию для «lime-kernel-objects».
На момент написания статьи в репозитарии были скомпилированные версии для следующих версий ядер (под ОС CentOS 6 / RHEL 6):
2.6.32-71
2.6.32-71.14.1
2.6.32-71.18.1
2.6.32-71.24.1
2.6.32-71.29.1
2.6.32-71.7.1
2.6.32-131.0.15
2.6.32-220
2.6.32-279
2.6.32-358.0.1
2.6.32-358.11.1
2.6.32-358.14.1
2.6.32-358.18.1
2.6.32-358.2.1
2.6.32-358.23.2
2.6.32-358.6.1
2.6.32-431
2.6.32-431.1.2.0.1
2.6.32-431.3.1
Оказалось, что под мою версию ядра еще не существует скомпилированных модулей. Придется сделать чуть больше телодвижений.
Я установил на виртуальной машине CentOS 6.5 x64 с последней версией ядра (2.6.32-431.5.1.el6.x86_64).
]$ yum update
[root@vmtest
После обновления ядра перезагружаем виртуальную машину.
Теперь нам нужны соответствующие заголовки и исходники ядра, а также утилиты для компиляции.
]$ yum install gcc gcc-c++ kernel-headers kernel-source
Теперь мы готовы к загрузке и компиляции модуля LiME!
]# mkdir lime; cd lime
[root@vmtest lime]# wget https://lime-forensics.googlecode.com/files/lime-forensics-1.1-r17.tar.gz
[root@vmtest lime]# tar -xzvf lime-forensics-1.1-r17.tar.gz
[root@vmtest lime]# cd src
[root@vmtest src]# make
….
make -C /lib/modules/2.6.32-431.5.1.el6.x86_64/build M=/root/lime/src modules
…
[root@vmtest src]# ls lime*.ko
lime-2.6.32-431.5.1.el6.x86_64.ko
После компиляции модуля загрузим его на виртуальной машине и выгрузим память в локальный файл. Настройки модуля выглядят следующим образом:
]# insmod lime-2.6.32-431.5.1.el6.x86_64.ko «path=/root/mem.img format=lime»
Образ памяти будет выгружен в файл /root/mem.img, а формат «lime» совместим с фреймворком volatility.
Я проверил параметры созданного образа (на соответствие размера и объема памяти, выделенного под виртуальную машину, а также на корректность содержимого образа).
]# ls -lah /root/mem.img
-r—r—r—. 1 root root 1.0G Mar 9 08:11 /root/mem.img
[root@vmtest
]# strings /root/mem.img | head -n 3
EMiL
root (hd0,0)
kernel /vmlinuz-2.6.32-431.5.1.el6.x86_64 ro root=/dev/mapper/vg_livecd-lv_root rd_NO_LUKS
Удаляем модуль ядра при помощи простой команды:
Получение образа через интернет
После успешных тестов вернемся к нашей первоначальной задаче: захвату памяти на сервере с ОС CentOS и загрузке полученного образа через интернет. Я загрузил модуль на подконтрольный мне сервер, а затем скачал его через протокол HTTP:
LiME позволяет не только записывать образы на локальный диск. Вместо этого мы можем создать TCP-сервис при помощи аргумента path=tcp:4444.
]# insmod lime-2.6.32-431.5.1.el6.x86_64.ko «path=tcp:4444 format=lime»
Если, к примеру, мы находимся внутри клиентской сети или порт 4444 доступен через интернет, при помощи netcat я могу соединиться с сервером и скачать образ памяти на свой компьютер.
]# nc target.server.com 4444 > /home/dan/evidence/evidence.lime.img
Поскольку целевой сервер находится в интернете, на котором установлен фаервол, к процессу получения образа следует подходить более творчески.
Помните, как я загружал модуль на целевой сервер через HTTP (80-й порт)? Это означает, что файервол разрешает исходящие TCP-соединения через этот порт.
Я могу установить сервер netcat, который будет доступен через интернет при помощи конфигурирования файервола так, чтобы трафик с этого порта передавался на мой локальный LAN-адрес. Вы можете сделать то же самое при помощи большинства роутеров и функции проброса портов (port forwarding).
Шаг 1: настраиваем netcat сервер на нашей машине, чтобы он прослушивал 80-й порт.
]# nc –l 80 > /home/dan/evidence/evidence.lime.img
Шаг 2: Запускаем модуль LiME и конфигурируем его на ожидание TCP-соединений на 4444 порту.
]# insmod lime-2.6.32-431.5.1.el6.x86_64.ko «path=tcp:4444 format=lime»
Сейчас на целевом сервере я могу использовать локальное соединение netcat, связанное с удаленным соединением к моему компьютеру через 80-й порт (где 60.70.80.90 – условный адрес моей машины).
Шаг 3: Создаем цепочку для передачи образа памяти на мою машину.
]# nc localhost 4444 | nc 60.70.80.90 80
Теперь, когда образ оказался на моей машине, можно начать его анализ.
Ниже показана наглядная схема процесса передачи образа:
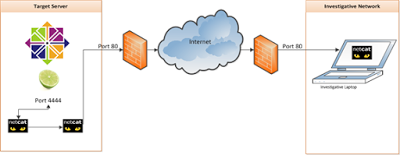
Рисунок 2: Схема передачи образа памяти на удаленный хост
Анализ памяти при помощи Volatility
В Volatility есть множество профилей для парсинга дампов памяти, но эти конфигурации в основном полезны при анализе образов взятых в ОС Windows. Чтобы выполнить анализ дампа взятого из Линукса, мы должны создать новый профиль, в точности соответствующий операционной системе, версии ядра и архитектуре. Вернемся в виртуальной машине для того, чтобы собрать всю необходимую информацию для создания профиля. Нам потребуется:
- отладочные символы (System.map*)
- Необходим доступ к тестовой виртуальной машине с той же самой архитектурой, версией ядра и операционной системой.
- информация о структурах данных ядра (vtypes)
- Необходимы исходники volatility и утилиты для компиляции файлов ядра на той же самой архитектуре, версии ядра и операционной системе.
Для начала создадим папку, в которую будем складировать все необходимые файлы.
mkdir -p volatility-profile/boot/
mkdir -p volatility-profile/volatility/tools/linux/
Теперь скопируем отладочные символы, находящиеся в CentOS в директории /boot/. Необходимо найти файл System.map*, соответствующий версии ядра, которая была запущена во время получения дампа памяти (2.6.32-431.5.1.el6.x86_64).
]# cd /boot/
[root@vmtest boot]# ls -lah System.map*
-rw-r—r—. 1 root root 2.5M Feb 11 20:07 System.map-2.6.32-431.5.1.el6.x86_64
-rw-r—r—. 1 root root 2.5M Nov 21 22:40 System.map-2.6.32-431.el6.x86_64
Копируем соответствующий файл System.map в ранее созданную папку.
[root@vmtest boot]# cp System.map-2.6.32-431.5.1.el6.x86_64
/volatility-profile/boot/ Одно из требований при компиляции файлов ядра (vtypes) – наличие библиотеки libdwarf. В других операционных системах ее можно получить при помощи apt-get или yum. В CentOS 6.5 необходимо скомпилировать исходники, взятые из Fedora Project. Остальные пакеты, необходимые для компиляции, должны быть установлены во время компиляции LiME (см. Раздел «Подготовка к работе»).
[root@vmtest boot]# cd
]# mkdir libdwarf
[root@vmtest libdwarf]# cd libdwarf/
[root@vmtest libdwarf]# wget http://pkgs.fedoraproject.org/repo/pkgs/libdwarf/libdwarf-20140208.tar.gz
/4dc74e08a82fa1d3cab6ca6b9610761e/libdwarf-20140208.tar.gz
[root@vmtest libdwarf]# tar -xzvf libdwarf-20140208.tar.gz
[root@vmtest dwarf-20140208]# cd dwarf-20140208/
[root@vmtest dwarf-20140208]#./configure
[root@vmtest dwarf-20140208]# make
[root@vmtest dwarfdump]# cd dwarfdump
[root@vmtest dwarfdump]# make install
Копируем исходники Volatility и скомпилировать структуры ядра.
[root@vmtest dwarfdump]# cd
]# mkdir volatility
[root@vmtest
]# cd volatility
[root@vmtest volatility]# cd volatility
[root@vmtest volatility]# wget https://volatility.googlecode.com/files/volatility-2.3.1.tar.gz
[root@vmtest volatility]# tar -xzvf volatility-2.3.1.tar.gz
[root@vmtest volatility]# cd volatility-2.3.1/tools/linux/
[root@vmtest linux]# make
После успешной компиляции скопируем получившийся файл (module.dwarf) в папку профиля.
[root@vmtest linux]# cp module.dwarf
Запаковываем оба файла в ZIP-архив (согласно требованиям Volatility).
[root@vmtest linux]# cd
/volatility-profile/
[root@vmtest volatility-profile]# zip CentOS-6.5-2.6.32-431.5.1.el6.x86_64.zip
boot/System.map-2.6.32-431.5.1.el6.x86_64 volatility/tools/linux/module.dwarf
adding: boot/System.map-2.6.32-431.5.1.el6.x86_64 (deflated 80%)
adding: volatility/tools/linux/module.dwarf (deflated 90%)
Полученный архив на своей машине можно было бы скопировать в стандартную папку, предназначенную для хранения профилей, однако чтобы избежать их потери во время обновлений, я создал отдельную директорию и сослался на нее во время запуска volatility.
Далее видим, что Volatility распознал новую директорию для плагинов.
dan@investigativelaptop evidence]# vol.py —plugins=/home/dan/.volatility/profiles/ —info | grep -i profile | grep -i linux
Volatility Foundation Volatility Framework 2.3.1
LinuxCentOS-6_5-2_6_32-431_5_1_el6_x86_64x64 — A Profile for Linux CentOS-6.5-2.6.32-431.5.1.el6.x86_64 x64
Запускаем плагины с префиксом linux, которые идут в составе Volatility, для выполнения анализа памяти.
Источник



