- Как удалить программу в операционной системе Linux?
- Установка Prometheus + Alertmanager + node_exporter на Linux
- Подготовка сервера
- Время
- Брандмауэр
- SELinux
- Prometheus
- Загрузка
- Установка (копирование файлов)
- Назначение прав
- Запуск и проверка
- Автозапуск
- Alertmanager
- Загрузка
- Установка
- Назначение прав
- Автозапуск
- node_exporter
- Загрузка
- Установка
- Назначение прав
- Автозапуск
- Отображение метрик с node_exporter в консоли prometheus
- Отображение тревог
- Отправка уведомлений
- Мониторинг служб Linux
- Сбор метрие с помощью node_exporter
- Отображение тревог
Как удалить программу в операционной системе Linux?

В операционной системе Linux, как и в Windows, все установленные приложения можно удалять или переустанавливать. Для этого можно установить специальное приложение или воспользоваться Терминалом (своего рода прототип командной строки). Как же это сделать?
Для того, чтобы удалить программу в Linuxстоит открыть Терминал. Для этого выполняем следующее:
- Нажимаем «Меню», «Приложения», «Стандартные» и выбираем «Терминал».

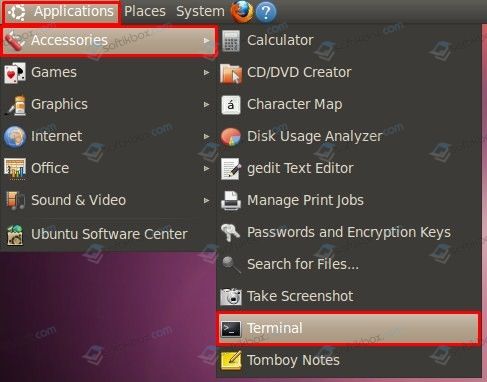
- Откроется окно инструмента. Теперь, чтобы посмотреть список всех установленных приложений вводим команду«dpkg–list» или «dpkg–l» (без кавычек).
- Появится список приложений. Находим то, что нужно удалить. Запоминаем правильное название (с пробелами и подчеркиваниями).
- Чтобы удалить программу, а также все её файлы и настройки вводим «sudoapt-get —purgeremoveимя_приложения».
- Если вы хотите переустановить программу, а поэтому настройки нужно сохранить, вводим «sudoapt-getremoveимя_приложения».
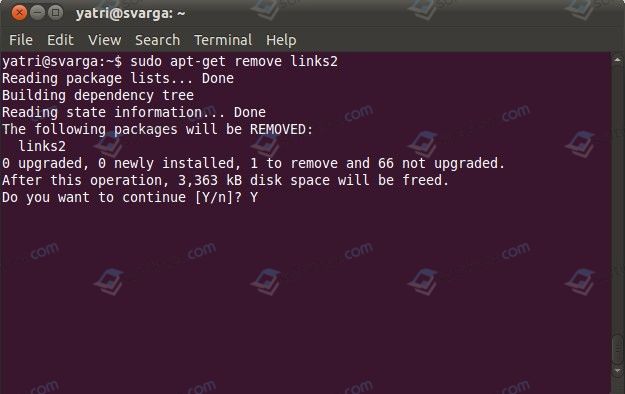
ВАЖНО! Если во время установки приложения произошла ошибка и программа не была доустановлена, то её удаление возможно выполнить следующей командой: «dpkg —remove —force-remove-reinstreqимя_приложения».
Источник
Установка Prometheus + Alertmanager + node_exporter на Linux
В двух словах, Prometheus — система мониторинга, обладающая возможностями тонкой настройки метрик. Она будет полезна для отслеживания состояния работы сервисов на низком уровне.
Данная инструкция позволит установить prometheus как на системы RPM (Red Hat, CentOS), так и deb (Debian, Ubuntu). Помимо Prometheus мы установим Alertmanager для возможности отправлять тревоги и node_exporter для мониторинга сервера Linux.
Подготовка сервера
Настроим некоторые параметры сервера, необходимые для правильно работы системы.
Время
Для отображения событий в правильное время, необходимо настроить его синхронизацию. Для этого установим chrony:
а) если на системе CentOS / Red Hat:
yum install chrony
systemctl enable chronyd
systemctl start chronyd
б) если на системе Ubuntu / Debian:
apt-get install chrony
systemctl enable chrony
systemctl start chrony
Брандмауэр
На фаерволе, при его использовании, необходимо открыть порты:
- TCP 9090 — http для сервера прометеус.
- TCP 9093 — http для алерт менеджера.
- TCP и UDP 9094 — для алерт менеджера.
- TCP 9100 — для node_exporter.
а) с помощью firewalld:
firewall-cmd —permanent —add-port=9090/tcp —add-port=9093/tcp —add-port=9094/
б) с помощью iptables:
iptables -I INPUT 1 -p tcp —match multiport —dports 9090,9093,9094,9100 -j ACCEPT
iptables -A INPUT -p udp —dport 9094 -j ACCEPT
в) с помощью ufw:
ufw allow 9090,9093,9094,9100/tcp
ufw allow 9094/udp
SELinux
По умолчанию, SELinux работает в операционный системах на базе Red Hat. Проверяем, работает ли она в нашей системе:
Если мы получаем в ответ:
. необходимо отключить его командами:
sed -i ‘s/^SELINUX=.*/SELINUX=disabled/g’ /etc/selinux/config
* если же мы получим ответ The program ‘getenforce’ is currently not installed, то SELinux не установлен в системе.
Prometheus
Prometheus не устанавливается из репозитория и имеет, относительно, сложный процесс установки. Необходимо скачать исходник, создать пользователя, вручную скопировать нужные файлы, назначить права и создать юнит для автозапуска.
Загрузка
Переходим на официальную страницу загрузки и копируем ссылку на пакет для Linux:

. и используем ее для загрузки пакета на Linux:
* если система вернет ошибку, необходимо установить пакет wget.
Установка (копирование файлов)
После того, как мы скачали архив prometheus, необходимо его распаковать и скопировать содержимое по разным каталогам.
Для начала создаем каталоги, в которые скопируем файлы для prometheus:
Распакуем наш архив:
tar zxvf prometheus-*.linux-amd64.tar.gz
. и перейдем в каталог с распакованными файлами:
Распределяем файлы по каталогам:
cp prometheus promtool /usr/local/bin/
cp -r console_libraries consoles prometheus.yml /etc/prometheus
Назначение прав
Создаем пользователя, от которого будем запускать систему мониторинга:
useradd —no-create-home —shell /bin/false prometheus
* мы создали пользователя prometheus без домашней директории и без возможности входа в консоль сервера.
Задаем владельца для каталогов, которые мы создали на предыдущем шаге:
chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus
Задаем владельца для скопированных файлов:
chown prometheus:prometheus /usr/local/bin/
Запуск и проверка
Запускаем prometheus командой:
/usr/local/bin/prometheus —config.file /etc/prometheus/prometheus.yml —storage.tsdb.path /var/lib/prometheus/ —web.console.templates=/etc/prometheus/consoles —web.console.libraries=/etc/prometheus/console_libraries
. мы увидим лог запуска — в конце «Server is ready to receive web requests»:
level=info ts=2019-08-07T07:39:06.849Z caller=main.go:621 msg=» Server is ready to receive web requests. «
Открываем веб-браузер и переходим по адресу http:// :9090 — загрузится консоль Prometheus:

Автозапуск
Мы установили наш сервер мониторинга, но его необходимо запускать вручную, что совсем не подходит для серверных задач. Для настройки автоматического старта Prometheus мы создадим новый юнит в systemd.
Возвращаемся к консоли сервера и прерываем работу Prometheus с помощью комбинации Ctrl + C. Создаем файл prometheus.service:
[Unit]
Description=Prometheus Service
After=network.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
—config.file /etc/prometheus/prometheus.yml \
—storage.tsdb.path /var/lib/prometheus/ \
—web.console.templates=/etc/prometheus/consoles \
—web.console.libraries=/etc/prometheus/console_libraries
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
Перечитываем конфигурацию systemd:
systemctl enable prometheus
После ручного запуска мониторинга, который мы делали для проверки, могли сбиться права на папку библиотек — снова зададим ей владельца:
chown -R prometheus:prometheus /var/lib/prometheus
systemctl start prometheus
. и проверяем, что она запустилась корректно:
systemctl status prometheus
Alertmanager
Alertmanager нужен для сортировки и группировки событий. Он устанавливается по такому же принципу, что и prometheus.
Загрузка
На той же официальной странице загрузки копируем ссылку на Alertmanager для Linux:

После предыдущей установки мы должны были остаться в каталоге прометеуса — выходим на уровень выше:
Теперь используем ссылку для загрузки alertmanager:
Установка
Создаем каталоги для alertmanager:
mkdir /etc/alertmanager /var/lib/prometheus/alertmanager
Распакуем наш архив:
tar zxvf alertmanager-*.linux-amd64.tar.gz
. и перейдем в каталог с распакованными файлами:
Распределяем файлы по каталогам:
cp alertmanager amtool /usr/local/bin/
cp alertmanager.yml /etc/alertmanager
Назначение прав
Создаем пользователя, от которого будем запускать alertmanager:
useradd —no-create-home —shell /bin/false alertmanager
* мы создали пользователя alertmanager без домашней директории и без возможности входа в консоль сервера.
Задаем владельца для каталогов, которые мы создали на предыдущем шаге:
chown -R alertmanager:alertmanager /etc/alertmanager /var/lib/prometheus/alertmanager
Задаем владельца для скопированных файлов:
chown alertmanager:alertmanager /usr/local/bin/
Автозапуск
Создаем файл alertmanager.service в systemd:
[Unit]
Description=Alertmanager Service
After=network.target
[Service]
EnvironmentFile=-/etc/default/alertmanager
User=alertmanager
Group=alertmanager
Type=simple
ExecStart=/usr/local/bin/alertmanager \
—config.file=/etc/alertmanager/alertmanager.yml \
—storage.path=/var/lib/prometheus/alertmanager \
$ALERTMANAGER_OPTS
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
Перечитываем конфигурацию systemd:
systemctl enable alertmanager
systemctl start alertmanager
Открываем веб-браузер и переходим по адресу http:// :9093 — загрузится консоль alertmanager:

node_exporter
Для получения метрик от операционной системы, установим и настроим node_exporter на тот же сервер прометеуса (и на все клиентские компьютеры). Процесс установки такой же, как у Prometheus и Alertmanager.
Если мы устанавливаем node_exporter на клиента, необходимо проверить наличие брандмауэра и, при необходимости, открыть tcp-порт 9100.
Загрузка
Заходим на страницу загрузки и копируем ссылку на node_exporter:

* обратите внимание, что для некоторых приложений есть свои готовые экспортеры.
После предыдущей установки мы должны были остаться в каталоге алерт менеджера — выходим на уровень выше:
Теперь используем ссылку для загрузки node_exporter:
Установка
Распакуем скачанный архив:
tar zxvf node_exporter-*.linux-amd64.tar.gz
. и перейдем в каталог с распакованными файлами:
Копируем исполняемый файл в bin:
cp node_exporter /usr/local/bin/
Назначение прав
Создаем пользователя nodeusr:
useradd —no-create-home —shell /bin/false nodeusr
Задаем владельца для исполняемого файла:
chown -R nodeusr:nodeusr /usr/local/bin/node_exporter
Автозапуск
Создаем файл node_exporter.service в systemd:
[Unit]
Description=Node Exporter Service
After=network.target
[Service]
User=nodeusr
Group=nodeusr
Type=simple
ExecStart=/usr/local/bin/node_exporter
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
Перечитываем конфигурацию systemd:
systemctl enable node_exporter
systemctl start node_exporter
Открываем веб-браузер и переходим по адресу http:// :9100/metrics — мы увидим метрики, собранные node_exporter:

Отображение метрик с node_exporter в консоли prometheus
Открываем конфигурационный файл prometheus:
В разделе scrape_configs добавим:
scrape_configs:
.
— job_name: ‘node_exporter_clients’
scrape_interval: 5s
static_configs:
— targets: [‘192.168.0.14:9100′,’192.168.0.15:9100’]
* в данном примере мы добавили клиента с IP-адресом 192.168.0.14, рабочее название для группы клиентов node_exporter_clients. Для примера, мы также добавили клиента 192.168.0.15 — чтобы продемонстрировать, что несколько клиентов добавляется через запятую.
Чтобы настройка вступила в действие, перезагружаем наш сервис prometheus:
systemctl restart prometheus
Заходим в веб-консоль prometheus и переходим в раздел Status — Targets:

. в открывшемся окне мы должны увидеть нашу группу хостов и сам компьютер с установленной node_exporter:

* статус также должен быть UP.
Отображение тревог
Создадим простое правило, реагирующее на недоступность клиента.
Создаем файл с правилом:
groups:
— name: alert.rules
rules:
— alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
description: ‘<< $labels.instance >> of job << $labels.job >> has been down
for more than 1 minute.’
summary: Instance << $labels.instance >> down
Теперь подключим наше правило в конфигурационном файле prometheus:
.
rule_files:
# — «first_rules.yml»
# — «second_rules.yml»
— «alert.rules.yml»
.
* в данном примере мы добавили наш файл alert.rules.yml в секцию rule_files. Закомментированные файлы first_rules.yml и second_rules.yml уже были в файле в качестве примера.
systemctl restart prometheus
Открываем веб-консоль прометеуса и переходим в раздел Alerts. Если мы добавим клиента и попробуем его отключить для примера, мы увидим тревогу:

Отправка уведомлений
Теперь настроим связку с алерт менеджером для отправки уведомлений на почту.
В секцию global добавим:
global:
.
smtp_from: monitoring@dmosk.ru
* мы будем отправлять сообщения от email monitoring@dmosk.ru.
Приведем секцию route к виду:
route:
group_by: [‘alertname’, ‘instance’, ‘severity’]
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: ‘web.hook’
routes:
— receiver: send_email
match:
alertname: InstanceDown
* в данном примере нами был добавлен маршрут, который отлавливает событие InstanceDown и запускает ресивер send_email.
. далее добавим еще один ресивер:
receivers:
.
— name: send_email
email_configs:
— to: alert@dmosk.ru
smarthost: localhost:25
require_tls: false
* в данном примере мы отправляем сообщение на почтовый ящик alert@dmosk.ru с локального сервера. Обратите внимание, что для отправки почты наружу у нас должен быть корректно настроенный почтовый сервер (в противном случае, почта может попадать в СПАМ).
Перезапустим сервис для алерт менеджера:
systemctl restart alertmanager
Теперь настроим связку prometheus с alertmanager — открываем конфигурационный файл сервера мониторинга:
Приведем секцию alerting к виду:
alerting:
alertmanagers:
— static_configs:
— targets:
— 192.168.0.14:9093
* где 192.168.0.14 — IP-адрес сервера, на котором у нас стоит alertmanager.
systemctl restart prometheus
Немного ждем и заходим на веб интерфейс алерт менеджера — мы должны увидеть тревогу:

. а на почтовый ящик должно прийти письмо с тревогой.
Мониторинг служб Linux
Для мониторинга сервисов с помощью Prometheus мы настроим сбор метрик и отображение тревог.
Сбор метрие с помощью node_exporter
Открываем сервис, созданный для node_exporter:
. и добавим к ExecStart:
* данная опция указывает экспортеру мониторить состояние каждой службы.
При необходимости, мы можем либо мониторить отдельные службы, добавив опцию collector.systemd.unit-whitelist:
ExecStart=/usr/local/bin/node_exporter —collector.systemd —collector.systemd.unit-whitelist=»(chronyd|mariadb|nginx).service»
* в данном примере будут мониториться только сервисы chronyd, mariadb и nginx.
. либо наоборот — мониторить все службы, кроме отдельно взятых:
ExecStart=/usr/local/bin/node_exporter —collector.systemd —collector.systemd.unit-blacklist=»(auditd|dbus|kdump).service»
* при такой настройке мы запретим мониторинг сервисов auditd, dbus и kdump.
Чтобы применить настройки, перечитываем конфиг systemd:
systemctl restart node_exporter
Отображение тревог
Настроим мониторинг для службы NGINX.
Создаем файл с правилом:
groups:
— name: services.rules
rules:
— alert: nginx_service
expr: node_systemd_unit_state
for: 1s
annotations:
summary: «Instance << $labels.instance >> is down»
description: «<< $labels.instance >> of job << $labels.job >> is down.»
Подключим файл с описанием правил в конфигурационном файле prometheus:
.
rule_files:
# — «first_rules.yml»
# — «second_rules.yml»
— «alert.rules.yml»
— «services.rules.yml»
.
* в данном примере мы добавили наш файл services.rules.yml к уже ранее добавленному alert.rules.yml в секцию rule_files.
systemctl restart prometheus
Для проверки, остановим наш сервис:
systemctl stop nginx
В консоли Prometheus в разделе Alerts мы должны увидеть тревогу:
Источник



