- Как ускорить работу виртуальных машин VMware Workstation
- 1. Аппаратная часть
- 2. Файлы ВМ на разных HDD
- 3. Фиксированные виртуальные диски
- 4. Дефрагментация HDD
- 5. Тормоза после приостановки ВМ
- 6. Обрезка страничной памяти
- 7. Плеер VMware
- 8. ПО EFI
- 9. Оптимизация гостевых ОС
- 10. Правильный антивирус для хост-системы
- OSX 10.10 Yosemite работает медленно на VMware
- 5 ответов 5
- Оптимизация работы виртуальной инфраструктуры на базе VMWare vSphere
Как ускорить работу виртуальных машин VMware Workstation
10 способов, как можно ускорить работу с виртуальными машинами в среде гипервизора VMware Workstation.
VMware Workstation – один из лучших гипервизоров для Windows. Это не самая производительная, но самая стабильная программа, с помощью которой можно виртуально исследовать различные операционные системы (ОС). VMware не конфликтует с другими гипервизорами (как Microsoft Hyper-V), в ней всегда работают дополнения гостевых ОС и прочие функции (в отличие от нестабильной VirtualBox), она функциональная и настраиваемая. Ну а что касается производительности, то здесь можно кое-что предпринять. Как ускорить работу виртуальных машин (ВМ) VMware?
1. Аппаратная часть
При использовании любого гипервизора, как и в случае с физическим компьютером, аппаратная оптимизация первична, программная – вторична. Для работы с VMware не принципиально, но желательно иметь на борту физического компьютера четырёхъядерный процессор, чтобы двое ядер оставались хост-системе (основной ОС), а двое могли бы быть задействованы ВМ.
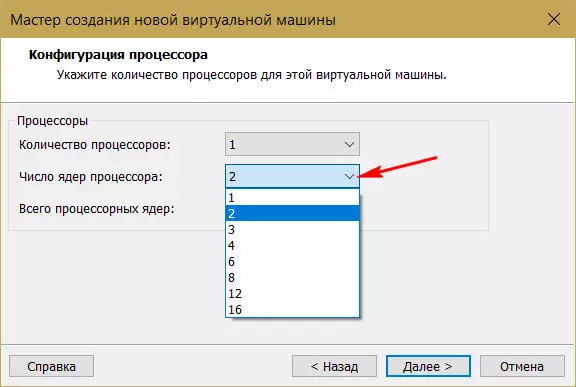
Для базовых целей типа исследования ОС и тестирования несложного софта будет достаточно 2 Гб оперативной памяти. Разве что гостевым Windows 8.1 и 10 можно выделить 3 Гб, если у физического компьютера имеется 6 или 8 Гб. Выделять больший объём без конкретных целей использования памяти нет надобности.
ВМ, размещённая на одном и том же HDD, где установлена хост-система, будет тормозить даже при мощном процессоре и отсутствии недостатка оперативной памяти. HDD – слабое звено в конфигурации и физических, и виртуальных компьютеров из-за медленной скорости чтения и записи данных. Если в наличии нет SSD, для размещения ВМ желательно выделить отдельный HDD – жёсткий диск, к которому не будет обращаться хост-система. Ну или пойти путём универсального аппаратного апгрейда – реализовать RAID 0 (как минимум). Без последнего задействовать два HDD в работе ВМ можно, если разбросать её файлы по разным дискам.
2. Файлы ВМ на разных HDD
- файлов виртуального жёсткого диска (обычно это тип VMDK, но VMware также может работать с типом VHD);
- файлов конфигурации самой ВМ;
- файлов снапшотов;
- кэша (данных, участвующих в сообщении хост- и гостевой ОС).
При использовании ВМ и по завершении работы с ней происходит запись данных во все эти файлы. За исключением снапшотов, если они не задействуются. Чтобы распределить нагрузку, можно файл виртуального диска VMDK (или VHD) хранить на одном HDD, а файлы конфигурации ВМ – на другом HDD, в частности, на том же, где размещается хост-система. Для всех ВМ указываем расположение по умолчанию – каталог на одном HDD.
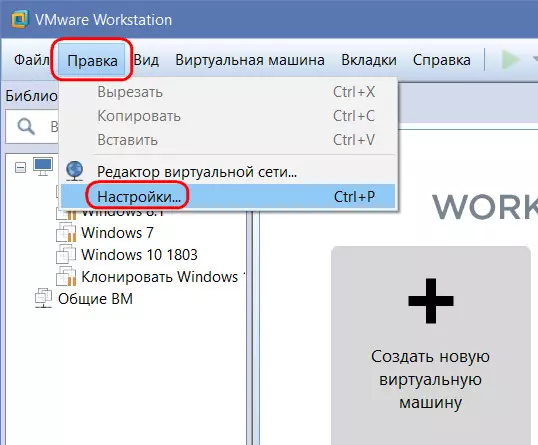
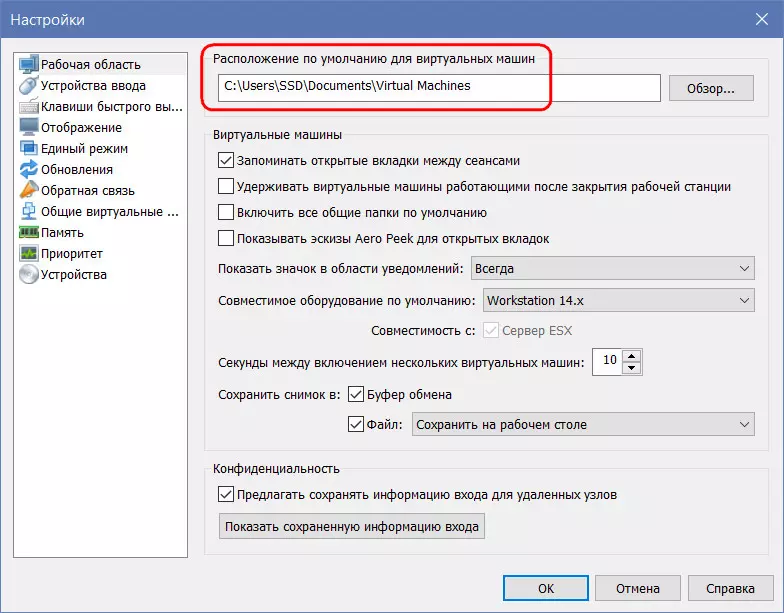
При создании же каждой отдельной ВМ используем выборочную настройку.
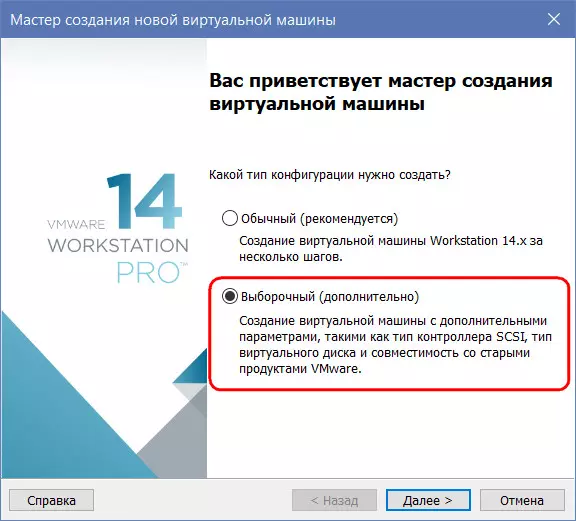
И на этапе задания параметров виртуального диска указываем его месторасположение на разделе другого HDD.
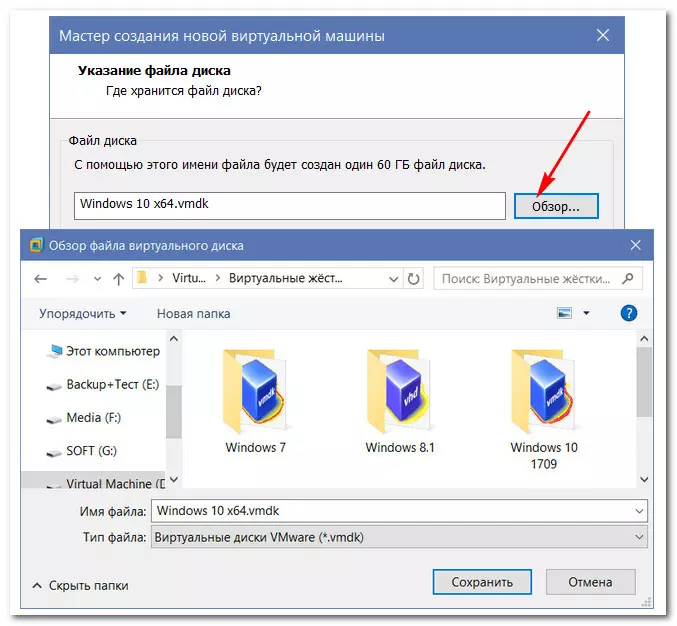
Применить такую схему к уже имеющихся ВМ можно путём удаления используемого виртуального диска в параметрах машины. А затем добавления этого же диска по-новому, когда его файл VMDK (или VHD) уже будет перемещён на другой HDD.
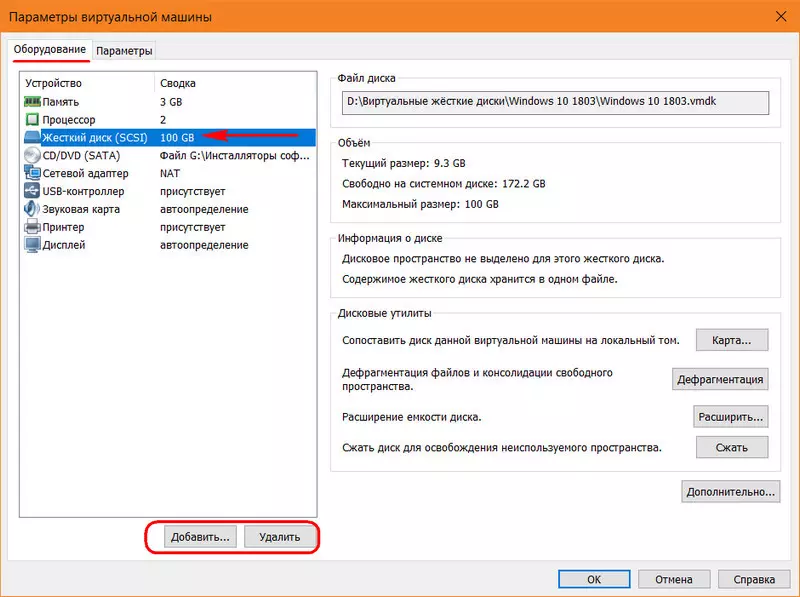
3. Фиксированные виртуальные диски
Немного ускорить работу ВМ на HDD можно путём работы с фиксированными, а не назначенными по умолчанию в VMware динамическими виртуальными дисками. Для этого при создании ВМ на этапе указания размера диска необходимо выбрать его сохранение в одном файле и установить галочку опции выделения всего места.
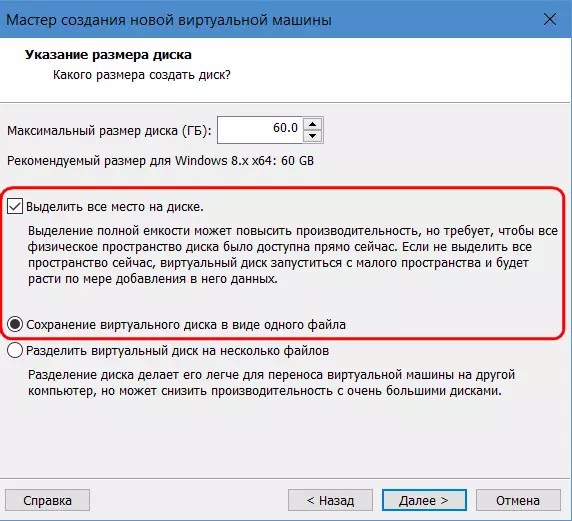
При таком раскладе будет создан виртуальный диск фиксированного типа. Его файл со старта займёт указанный объём, и ресурс HDD при непосредственной работе с ВМ не будет распыляться ещё и на операцию по выделению места на физическом диске.
4. Дефрагментация HDD
Ускорить работу ВМ на HDD можно традиционным методом оптимизации этого типа жёстких дисков – дефрагментацией. В среде хост-системы Windows желательно время от времени проводить эту процедуру с использованием эффективных сторонних программ.
5. Тормоза после приостановки ВМ
Работающие с VMware наверняка замечали, что в большинстве случаев после приостановки одной ВМ сразу же оперативно запустить другую нереально. Нужно немного подождать. Естественно, речь идёт о случаях расположения ВМ на HDD. Как только мы приостанавливаем ВМ, сразу же начинается активная запись данных на диск с его загрузкой вплоть до 100%. И так может длиться несколько минут. При приостановке ВМ содержимое оперативной памяти гостевой ОС каждый раз записывается в файл «.vmem». Он находится в числе прочих файлов конфигурации ВМ и планировано занимает столько места на диске, сколько машине выделено «оперативки». По факту же размер файла варьируется в зависимости от записанных в него в последний раз данных.
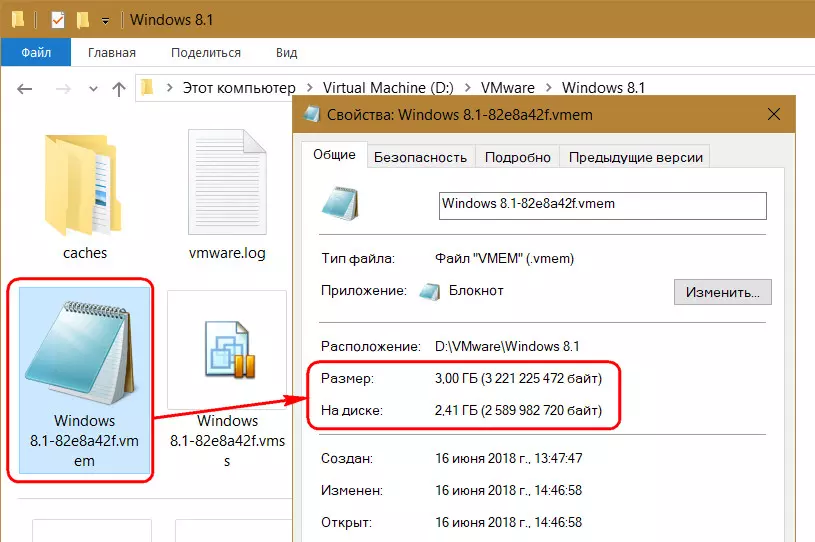
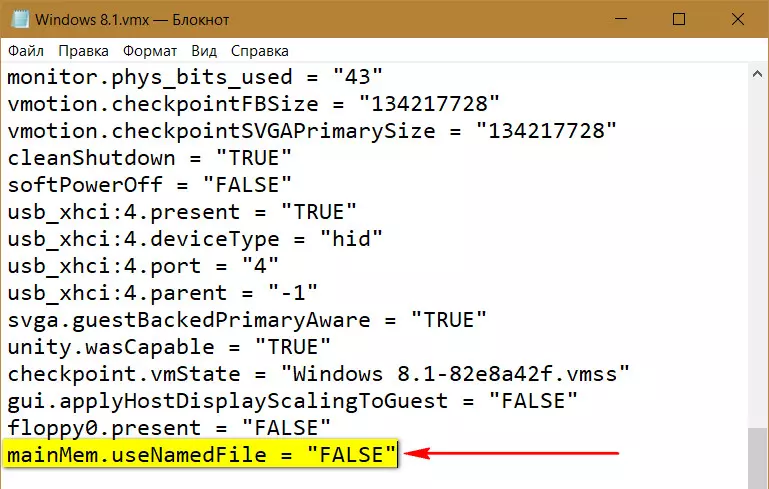
Активная запись в файл «.vmem» сильно нагружает HDD. Назначение такой операции – запуск гостевой ОС в сохранённом состоянии при возможных сбоях в работе ВМ. Нужна ли эта возможность такой ценой – решайте сами. Если не нужна, запись данных в файл «.vmem» можно отключить. И тем самым ускорить переключение между приостановленными ВМ. Для этого необходимо открыть в любом TXT-редакторе файл конфигурации ВМ «.vmx», дописать в конце такую строчку:
mainMem.useNamedFile = «FALSE»
И сохранить файл.
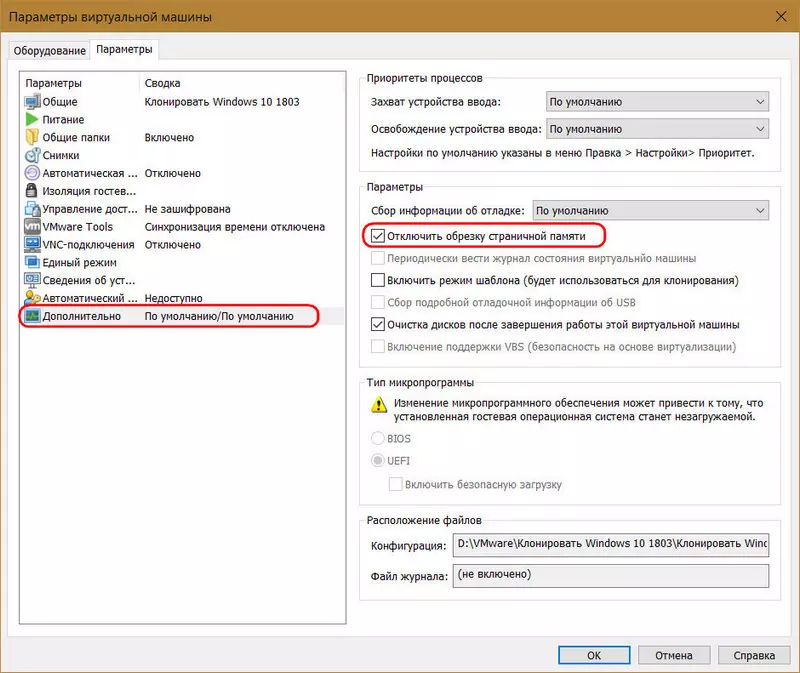
6. Обрезка страничной памяти
В дополнительных параметрах ВМ есть изначально неактивная опция отключения обрезки страничной памяти. Если её активировать, фактическое выделение оперативной памяти ВМ будет происходить быстрее.
7. Плеер VMware
В состав компонентов VMware Workstation входит приложение Player. Это упрощённый вариант гипервизора, ограниченный функционально, но также и более лёгкий. Создавать и настраивать ВМ лучше, конечно же, с использованием основного компонента VMware Workstation. А вот непосредственно проводить работу с гостевыми ОС можно внутри более шустрого плеера.
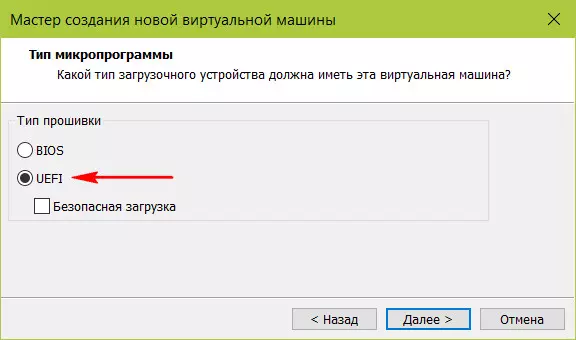
8. ПО EFI
ВМ с ПО EFI эмулируют устройства, соответственно, с BIOS UEFI. Они включаются и перезапускаются немного быстрее, чем ВМ, эмулирующие устройства с обычным BIOS. Плюс к этому, EFI-машины могут быть запущены с UEFI-флешек без помощи сторонних средств.
9. Оптимизация гостевых ОС
Ускорить работу ВМ можно за счёт оптимизации гостевых Windows. В числе таковых в частности: отключение анимации, обоев, неиспользуемых служб, телеметрии, обновлений, Timeline (для версии 10). В качестве платформы для тестирования только стороннего софта можно и вовсе в качестве гостевой ОС выбрать Windows 7 или 8.1 Embedded – урезанные сборки этих версий, заточенные под работу со слабым железом.
В гостевых Windows можно смело работать с отключённым Защитником и без стороннего антивируса. За безопасность будет отвечать антивирус хост-системы. А вот для последней желательно подобрать такой антивирусный продукт, чтобы защищал, но при этом не мешал.
10. Правильный антивирус для хост-системы
Активность ВМ – это непаханое поле азарта для антивирусов. VMware Workstation, как и любой другой гипервизор, активно работает с записью данных. Причём работает с большими объёмами данных. И все эти данные антивирусы проверяют в рамках проактивной защиты. Чтобы не создавать лишней нагрузки при работе с ВМ, для хост-системы желательно подобрать хороший антивирус – эффективный в плане обнаружения реальных угроз, при этом минимально использующий аппаратные ресурсы компьютера.
Источник
OSX 10.10 Yosemite работает медленно на VMware
У меня был OSX Mavericks 10.9 в Vmware. Он работал нормально с установленными VMware Tools и драйверами SVGA. Когда вышел Yosemite, я обновил его из App Store. Я сталкиваюсь со многими проблемами в этом обновлении.
- Графика очень плохая
- Это слишком медленно
Что я попробовал:
- Я обновил последние инструменты VMware с сайта VMware
- Попытка установить драйверы SVGA снова (не удалось найти обновление для драйверов OSX Yosemite SVGA здесь. Эти драйверы хорошо работали с Mavericks и сделали это быстро в vmware в моем предыдущем опыте)
- Разрешения для файлов и папок Rpaired, как с помощью внутренней утилиты Mac OS X, так и с помощью приложения CCleaner.
- Очистил все ненужные файлы (например, временные файлы) с помощью CCleaner
Попытался увеличить размер виртуальной графической памяти, используя файл конфигурации виртуальной машины и добавив в него эту строку
Наткнулся на ссылку в интернете здесь. Было предложено запустить приложение под названием BeamOff (ссылка для скачивания доступна на том же сайте) и добавить его в автозагрузку, чтобы отключить функцию Beam Sync в Mac для улучшения графики
Используя опцию 6, упомянутую выше, когда я запустил приложение BeamOff, оно внезапно сделало графику более плавной. Поэтому я добавил его к элементу входа в систему, чтобы он мог начинаться с входа в систему Mac. Но, к моему разочарованию, это улучшение производительности (графика + скорость и т.д.) Было не таким уж большим, как у меня при использовании OS X Mavericks.
Моя виртуальная машина имеет:
- RAM: 3 ГБ
- Место на жестком диске: 150 ГБ
В чем проблема / Что нужно:
1.Ускорение OS X Yosemite производительность (графика + скорость), как я имел раньше в Mavericks
2. У меня разрешение 1366 * 768, но когда я на экране входа в Mavericks, у меня нет этого разрешения (некоторые черные поля слева и справа выглядят как 1024 * 768). Он изменяется до разрешения 1366 * 768 после завершения входа в систему и загрузки рабочего стола. Пожалуйста, обратите внимание, что он работал нормально, когда у меня были Mavericks (разрешение 1366 * 768 на экране входа и на рабочем столе).
5 ответов 5
В OS X вертикальная синхронизация называется синхронизацией луча.
Использование BeamOff или Quartz Debug для переключения этого параметра может решить проблему задержки пользовательского интерфейса.
Я столкнулся с медлительностью на iMac середины 2011 года в Fusion 7 после обновления до Yosemite. Это был не Fusion, но все гипервизоры пострадали от ошибки, обнаруженной в линейке середины 2011 года.
Если это похоже на ваш Mac, вы можете исправить это, перезапустив после запуска:
Я не уверен, почему это работает, но это делает.
Вот Parallels KB на этом. Вот сообщение сообщества VMware, в котором утверждается, что Apple знает об ошибке. Как пишет JBingham на платах VMware, приведенная выше команда перезапишет любые существующие загрузочные аргументы, поэтому выполните проверку с помощью:
Я считаю, что недавнее появление в разработке для Mac OS X может быть виновным в проблеме, обозначенной:
Согласно нескольким источникам (включая тот, что указан выше), даже наличие VMware Tools не сильно поможет — это способ, которым Mac OS X обрабатывает графику и графический интерфейс.
С появлением OS X Yosemite (и более новых версий) была представлена новая система перерисовки экрана и управления окнами. Это называется синхронизацией луча. В результате Mac OS X теперь использует намного больше физической памяти, но хорошо работает на физическом оборудовании (особенно MacBook, очевидно).
Но это изменение вредит пользователям виртуальных машин — новая система снижает производительность виртуального оборудования. Это потому, что новая система Beam Syncrhronization, по-видимому, не была разработана для пользователей виртуальных машин. Как вы заметили, изменение объема оперативной памяти ничего не изменит. Я даже пытался увеличить количество процессорных ядер, которые мог бы использовать VMware Player — это было практически бесполезно.
В результате предлагается отключить синхронизацию лучей, перейдя в встроенный в Apple инструмент разработчика Quartz Debug и выбрав «Отключить» в меню «Синхронизация лучей». К сожалению, вам придется повторять этот процесс при каждом входе в систему. Мне жаль быть носителем плохих технических новостей.
К счастью, BeamOff — приложение, разработанное JasF для GitHub, было создано для решения этой проблемы. Его единственная цель — отключить Beam Sync, что теоретически должно значительно повысить производительность. Но, если вам не нравится данное решение, я предполагаю, что сценарий оболочки /AppleScript также может быть разработан для данной задачи. Но у меня не было AppleScripted в течение многих лет (с момента выхода Leopard /SnowLeopard), поэтому я не могу помочь в этом деле.
Редактировать. Следует отметить, что исправление, описанное выше, на самом деле является частью Apple XCode Tools и не поставляется с Mac OS X. Поэтому вам придется загрузить его из онлайн-репозитория Apple. В этом случае вам понадобится инструмент из группы графических (оптимизационных) инструментов.
Источник
Оптимизация работы виртуальной инфраструктуры на базе VMWare vSphere

Практика показывает, что любой процесс, в определенной степени, всегда можно оптимизировать. Это вполне можно отнести и к виртуализации. Возможностей оптимизации тут достаточно много, и задача эта многогогранна.
В пределах данной статьи я хочу ознакомить вас с методиками сайзинга виртуальных машин, а так же о методах оптимизации их работы. Материал будет техническим и рекомендуется к ознакомлению всем специалистам по vSphere.
Для начала хотелось бы рассказать о двух технологиях, основным образом влияющих на производительность vSphere. Это технология NUMA и технология работы шедулера гипервизора ESXi.
Про NUMA существует достаточно много подробных статей, пересказывать эту информацию не вижу смысла, ограничусь лишь базовым описанием для целостности материала. Итак, NUMA – Non Uniform Memory Access. На русский язык это можно перевести как Неравноценный Доступ к Памяти.
Современные многосокетные сервера, по сути, представляют собой несколько изолированных односокетных компьютеров, объединенных на одной материнской плате. Каждый процессор монопольно владеет своими слотами оперативной памяти, и только он имеет к ней доступ. Аналогично, каждый процессор имеет свои персональные PCI-E шины, к которым подключены различные устройства материнской платы, а так же слоты расширения PCI-E. Процессоры соединены между собой высокоскоростной шиной обмена данными, по которой они получают доступ к «чужим» устройствам, делая запрос на это соответствующему процессору-хозяину. По понятным причинам, доступ процессора к «своей» памяти происходит гораздо с меньшими накладными расходами, чем к «чужой». Пока это все, что необходимо знать о данной технологии.
vSphere прекрасно знает про NUMA и старается размещать виртуальные ядра машин на тех физических процессорах, в чьей памяти сейчас находится оперативная память виртуальной машины. Но тут возникают подводные камни. Производители серверов любят включать в BIOS по умолчанию эмуляцию NUMA. То есть сервер представляется операционной системе как НЕ NUMA устройство, и vSphere не может использовать свою оптимизацию для управления данной технологией. В документации по vSphere рекомендуется отключать (Disable) данную опцию в BIOS, это позволяет vSphere самостоятельно разбираться с вопросом.
Рассмотрим потенциальные проблемы, которые могу возникнуть с NUMA. Предполагаем, что vSphere его видит и корректно с ним работает. Для примера будем рассматривать 2-процессорную систему, как самый простой вариант NUMA. Предположим, что на физическом сервере 64 GB оперативной памяти, по 32 на каждом сокете.
1. Мы создаем виртуальную машину (ВМ) с одним виртуальным ядром (vCPU). Естественно, такую виртуальную машину сможет исполнить только один физический процессор. Рассмотрим ситуацию, когда ВМ надо дать 48 GB оперативной памяти. 32 GB памяти ВМ заберет у «своего» физического процессора, а еще 16 ей вынужденно придется забрать у «чужого». И при доступе к этим «чужим» гигабайтам мы получаем гарантированно высокие задержки, что ощутимо снизит быстродействие виртуальной машины и увеличит нагрузку на шину передачи данных между физическими процессорами. Исправить ситуацию можно, если дать виртуальной машине 2 виртуальных сокета по 1 ядру каждый. Тогда vSphere распределит 2 vCPU ВМ по разным физическим процессорам, взяв у каждого по 24 GB оперативной памяти. Дав виртуальной машине 1 виртуальный сокет мы лишим её возможности грамотно использовать 2 физических процессора.
2. Вариант, когда мы создаем в плюс к первому пункту вторую ВМ на 10 GB оперативной памяти и один vCPU. Если бы эта ВМ была одна, то никаких проблем нет, она вполне умещается в одну NUMA ноду с 32 GB оперативной памяти. Но у нас уже есть первая машина, которая у обоих нод NUMA отъела по 24 GB памяти, и у каждой ноды осталось свободно всего по 8 GB. В данной ситуации либо первая, либо вторая ВМ начнут использовать часть «чужой» памяти, хотя вроде бы каждая из них сконфигурирована правильно с точки зрения NUMA. Это очень характерная ошибка и необходимо очень досконально просчитывать вашу виртуальную инфраструктуру при проектировании, а так же комплексно подходить к конфигурированию виртуальных машин при эксплуатации.
Хотелось бы отметить, что vSphere имеет свою четкую логику при работе с NUMA и Hyperthreading.
Если у ВМ всего 1 виртуальный сокет, то при увеличении vCPU, исполнение машины будет производиться на одном физическом процессоре исключительно на его физических ядрах без использования технологии Hyperthreading. При превышении количества vCPU над количеством физических ядер процессора, ВМ продолжит исполняться в пределах этого физического процессора, но уже с использование Hyperthreading. Если количество vCPU превысило количество ядер процессора с учетом Hyperthreading, то начнут использоваться ядра соседних NUMA нод (других физических процессоров), что приведет к потере производительности (если указать неверное количество виртуальных сокетов). В случае, когда физический процессор сильно нагружен, и свободных физических ядер не осталось, то в любом случае будет использоваться технология Hyperthreading (если иное не указано в конфигурации виртуальной машины). Если посмотреть на цифры, то в среднем ВМ теряет порядка 30-40% производительности, если она работает на чистом Hyperthreading по сравнению с чистыми физическими ядрами. Но сам физический процессор имеет общую производительность примерно на 30% больше с технологией Hyperthreading, чем без нее (используя только физические ядра). Данный показатель очень зависит от типа нагрузки и оптимизации приложений ВМ к многопоточной работе.
Если у ВМ более одного виртуального сокета, то vSphere будет оптимизировать работу такой ВМ, размещая исполняемые ядра и оперативную память на разных физических процессорах сервера.
По понятным причинам, ситуация с нагрузкой физического сервера постоянно меняется. Зачастую, возникает неравномерность нагрузки на физических процессорах сервера. vSphere следит за этим. Шедулер анализирует положение дел, вычисляет накладные расходы на перемещение ВМ или её части на другую NUMA ноду (перемещение памяти, ядер). Сравнивает эти расходы с потенциальной выгодой от перемещения и принимает решение — оставлять все как есть или же перемещать. Иными словами, при любой ситуации vSphere старается оптимизировать работу виртуальных машин. Наша задача состоит в том, чтобы упростить vSphere эту задачу и не ставить её в безвыходное положение.
О каких потерях может идти речь при неправильной конфигурации машин с NUMA нодами? Руководствуясь собственным опытом, могу сказать, что потери могут доходить до 30% общей производительности физического сервера. Много это или мало – решать вам.
Теперь, когда мы немного разобрались с NUMA и Hyperthreading, мне хотелось бы чуть подробнее рассказать о работе шедулера с ядрами виртуальных машин, vCPU.
Я не буду вдаваться в совсем уж глубины, это мало кому интересно, но постараюсь рассказать про принципы и методику работы данного механизма. Итак, основной механизм гипервизора работает следующим образом. В оперативной памяти постоянно работает процесс, обслуживающий работу виртуальных машин. Этот процесс можно представить как конвейер состояния READY и хранилище состояния WAIT. Опустим другие, менее значимые состояния виртуальных машин, они сейчас не принципиальны.
Для легкости восприятия, предлагаю воспринимать все vCPU виртуальных машин как цепочку. Каждое звено цепи – это ядро vCPU (world, в терминах vSphere). Таких world у машины столько, сколько у нее vCPU. Есть еще 2 невидимых, служебных world, сопутствующих каждой виртуальной машине. Один отвечает за обслуживание машины в целом, второй за её ввод-вывод. Реальное потребление вычислительной мощности этими служебными мирами совершенно незначительное, а потребление ими оперативной памяти можно оценить по показателю overhead у каждой виртуальной машины. Стоит отметить, что при создании ВМ размером в весь физический хост, с равным количеством виртуальных и физических ядер, могут возникнуть некоторые потери производительности. Этого момента я коснусь чуть ниже.
Конвейер READY, это «труба», в которую по очереди сброшены все такие цепочки. Таймслот – это время, в течение которого виртуальные машины исполняются физическим процессором (исполняются их vCPU). На это время виртуальная машина практически без потерь, аналогично физическому серверу, использует физические процессоры аппаратного сервера (pCPU). Максимальная величина таймслота искусственно ограничена величиной порядка 1 миллисекунды. После окончания таймслота, vCPU ВМ принудительно помещаются шедулером в очередь конвейера READY. Шедулер имеет возможность менять очередность виртуальных машин в конвейере READY, приоритет каждой машины вычисляется исходя из её текущей фактической нагрузки, её прав на ресурсы (Shares), как давно машина была на физическом процессоре и еще нескольких менее значимых параметров. Логично предположить, что если ВМ на хосте одна, то она всегда будет проходить конвейер очереди READY без задержек т.к. у нее нет конкурентов на ресурсы со стороны других ВМ.
Каким образом шедулер располагает миры виртуальных машин на физических ядрах? Представим себе таблицу, которая имеет по ширине столько столбцов, сколько ядер у нашего физического сервера (с учетом Hyperthreading). По высоте каждая строка будет соответствовать очередному такту процессора(ов) сервера. Давайте представим себе 2-процессорный сервер, по 6 физических ядер на процессор, + Hyperthreading. Всего получим 24 ядра на сервер. Предположим, что у сервера высокая нагрузка, и vSphere вынуждена использовать Hyperthreading, так будет проще считать. Допустим, у нас есть несколько виртуальных машин:
• 4 штуки по 1 ядру
• 4 штуки по 2 ядра
• 2 штуки по 8 ядер
• 1 штука по 16 ядер
Итак, наступает первый таймслот, шедулер выбирает претендентов. Пусть первой будет машина на 16 ядер. Первые 16 физических ядер (pCPU) заняты, осталось 8. Туда поместились, допустим, 4 машины по 2 ядра (причем машина на 16 ядер должна иметь 2 виртуальных сокета, чтобы корректно работать с NUMA). Всё, таймслот заполнен полностью, это идеальный вариант. Мы не теряем производительность, pCPU не простаивают. Остальные виртуальные машины в это время не работают и находятся в очереди ожидания READY. Предположим, что «счастливые» виртуальные машины получили одинаковый по величине таймслот (хотя в реальности у всех ВМ таймслот разный и зависит от множества факторов). Итак, наступает второй таймслот, и шедулеру надо его заполнить.
Остались не обслуженными машины:
• 4 штуки по 1 ядру
• 2 штуки по 8 ядер
Начинаем заполнять, 2 машины по 8 ядер, 4 машины по 1, осталось 4 свободных pCPU, можно положить туда две 2-ядерных машины, которые уже отработали в первом таймслоте. Больше мы туда уместить ничего не можем, не помещается. Таймслот опять заполнен полностью и мы не теряем мощность.
Аналогичным образом шедулер будет и далее наполнять таймслоты мирами виртуальных машин, стараясь сделать это максимально эффективно, чтобы уменьшить «дыры» в заполнении и повысить КПД виртуальной среды.
Ниже представлен негативный вариант расположения виртуальных машин на хосте. Одна большая машина размером в хост, и одна малая, с 1 vCPU. При равных правах на ресурсы и равных потребностях к производительности эти машины получат одинаковое количество таймслотов, то есть поделят между собой процессорное время. Т.к. обе машины не смогут работать одновременно (не умещаются в один таймслот), то работать они будут по очереди, причем малая машина будет работать в пустом таймслоте, где кроме нее больше никого не будет (таймслот израсходуется практически впустую). Большая машина при всем желании не сможет получить процессорное время, даже если оно этой машине необходимо. Например, при частоте центрального процессора 3 ГГц, обе эти машины смогут максимум получить по 1.5 ГГц.
Виртуализация позволяет создать на хосте несколько виртуальных машин, и может сложиться ситуация, когда суммарное количество vCPU всех машин будет больше количества pCPU физического хоста. Это вполне нормальное явление, но нужно четко осознавать, что одновременно все vCPU не смогут получить 100% от своей завяленной мощности. Иными словами, если у вас на одном хосте виртуализации находятся несколько нагруженных машин и их общее количество vCPU больше чем pCPU хоста, то с высокой долей вероятности эти машины будут мешать друг другу, что снизит их суммарную производительность.
Сейчас хотелось бы вернуться к созданию виртуальной машины величиной в весь хост. Хорошо, пусть такая ВМ заняла собой целиком первый таймслот и отработала его. Теперь вспоминаем про системные миры, сопутствующие этой машине. Их тоже надо исполнять, как надо исполнять сам гипервизор и его собственные системные процессы. То есть надо и им выдавать таймслоты и занимать в них некоторое количество pCPU. А что в это время делать нашей большой ВМ? Правильно, ожидать освобождения ВСЕХ pCPU, чтобы иметь возможность там уместиться. То есть мы гарантированно теряем производительность на служебных задачах гипервизора (таймслотах), а это плохо (вспоминаем пример выше с большой и малой машинами). Для примера, программный iSCSI инициатор под высокой нагрузкой потребляет до 6 ГГц процессорной мощности. Это было бы не так заметно в случае с малыми ВМ т.к. они работали бы параллельно служебным процессам (в этих же таймслотах). А для большой ВМ так не получится т.к. она занимает весь таймслот целиком, все его pCPU, и не может уместиться в таймслот, если хоть один его pCPU уже кем-то занят, пусть и системным процессом.
О каких потерях может идти речь при неправильном конфигурировании виртуальной инфраструктуры и размещении машин по нодам? От нуля до бесконечности (в теории). Все зависит от конкретной ситуации.
Отдельно хотелось бы озвучить главное правило при сайзинге виртуальных машин: давайте виртуальной машине МИНИМАЛЬНО возможные ресурсы, при которых она сможет выполнять свои задачи. Не нужно давать ВМ 2 ядра, если хватает одного. Не нужно давать 4, если хватает 2-х (лишние ядра занимают место в таймслоте). Аналогично с памятью, не стоит выдавать машине лишнего. Возможно, другой машине может не хватить, не говоря уже о возникающих проблемах с живой миграцией (по сути копированием объема памяти ВМ) и NUMA.
Теперь, разобравшись с механизмом размещения vCPU виртуальных машин на pCPU таймслота, давайте вспомним про NUMA и его правила размещения. Для шедулера гипервизора все эти правила имеют значение при заполнении таймслота т.к. pCPU таймслота могут относиться к разным NUMA нодам. Теперь, помимо сложностей учета NUMA при конфигурировании виртуальных машин на хосте, мы получили и ограничения, накладываемые методикой работы шедулера гипервизора с таймслотами. Если мы хотим получить хорошую производительность ВМ, нужно обращать внимание на все подводные камни и руководствоваться следующими правилами:
• Стараться не создавать машины-гиганты (по сравнению с размером хоста)
• Для больших машин надо учитывать ограничения, накладываемые технологией NUMA
• Не стоит злоупотреблять с количеством vCPU по отношению к pCPU хоста
• Несколько мелких или средних машин всегда будут иметь преимущество в гибкости и общей производительности перед огромными машинами
Напоследок хотелось бы сказать о работе шедулера гипервизора с вводом-выводом. При обращении виртуальной машины к своему виртуальному аппаратному обеспечению, гипервизор приостанавливает работу ВМ, снимает её с pCPU и ставит в хранилище WAIT. В таком состоянии машина не работает, она просто ждет. В это время гипервизор трансформирует («подделывает») команды виртуального устройства гостевой машины в реальные команды, соответствующие командам гипервизора, после чего гипервизор возвращает виртуальную машину в конвейер READY. Аналогичная «заморозка» виртуальной машины происходит и при ответе виртуального устройства машине (гипервизору необходимо снова трансформировать ответ, но уже в обратную сторону ). Чем больше команд ввода-вывода производит виртуальная машина, тем чаще она находится в «заморозке» WAIT, и тем меньше её производительность. Чем более «старые» виртуальные устройства ввода-вывода использует виртуальная машина, тем сложнее гипервизору трансформировать команды, и тем дольше ВМ находится в состоянии WAIT.
VMWare прямо и официально не рекомендует виртуализовывать приложения с гиперактивным вводом-выводом. Уменьшить негативное влияние от состояния WAIT можно с помощью использования паравиртуальных устройств для виртуальной машины. Это 10-гигабитная сетевая карта VMXNET3 и паравиртуальный SCSI контроллер жесткого диска PVSCSI. Так же уменьшению влияния WAIT и общему повышению производительности способствует применение в физических серверах аппаратных устройств, предназначенных для ускорения работы виртуальных машин. Это различные сетевые и HBA адаптеры с поддержкой аппаратного iSCSI offload, прямого доступа к памяти, сетевые карты с поддержкой виртуализации и т.д.
На этом я хотел бы остановиться. Надеюсь, информация в данной статье была вам интересна, и вы сможете более эффективно подойти к построению или эксплуатации своей виртуальной инфраструктуры.
Источник



